Hive on Spark优化
文章目录
- 第1章集群环境概述
- 1.1 集群配置概述
- 1.2 集群规划概述
- 第2章 Yarn配置
- 2.1 Yarn配置说明
- 2.2 Yarn配置实操
- 第3章 Spark配置
- 3.1 Executor配置说明
- 3.1.1 Executor CPU核数配置
- 3.1.2 Executor内存配置
- 3.1.3 Executor个数配置
- 3.2 Driver配置说明
- 3.3 Spark配置实操
- 第4章 Hive SQL执行计划
- 第5章分组聚合优化
- 5.1 优化前执行计划
- 5.2 优化思路
- 5.3 优化后执行计划
- 第6章 Join优化
- 6.1 Hive Join算法概述
- 6.2 Map Join优化
- 6.2.1 优化前执行计划
- 6.2.2 优化思路
- 6.2.3 优化后执行计划
- 6.3 Sort Merge Bucket Map Join
- 6.3.1 优化说明
- 6.3.2 优化案例
- 第7章数据倾斜优化
- 7.1 数据倾斜说明
- 7.2 分组聚合导致的数据倾斜
- 7.2.1 优化前执行计划
- 7.2.2 优化思路
- 7.3 join导致的数据倾斜
- 7.3.1 优化前的执行计划
- 7.3.2 优化思路
- 第8章任务并行度优化
- 8.1 优化说明
- 8.2 Map阶段并行度
- 8.3 Reduce阶段并行度
- 第9章小文件合并优化
- 9.1 优化说明
- 9.2 Map端输入文件合并
- 9.3 Reduce输出文件合并
- 第10章其他优化
- 参考
第1章集群环境概述
1.1 集群配置概述
本课程所用集群由5台节点构成,其中2台为master节点,用于部署HDFS的NameNode,Yarn的ResourceManager等角色,另外3台为worker节点,用于部署HDFS的DataNode、Yarn的NodeManager等角色。
Master节点配置为16核CPU、64G内存。
Workder节点配置为32核CPU、128G内存。
1.2 集群规划概述
具体集群规划如下图所示:
| hadoop100 | hadoop101 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|---|
| master | master | worker | worker | worker |
| NameNode | NameNode | DataNode | DataNode | DataNode |
| ResourceManager | ResourceManager | NodeManager | NodeManager | NodeManager |
| JournalNode | JournalNode | JournalNode | ||
| Zookeeper | Zookeeper | Zookeeper | ||
| Kafka | Kafka | Kafka | ||
| Hiveserver2 | Metastore | hive-client | hive-client | hive-client |
| Spark | Spark | Spark | Spark | |
| DS-master | DS-master | DS-worker | DS-worker | DS-worder |
| Maxwell | ||||
| mysql | ||||
| flume | flume |
第2章 Yarn配置
2.1 Yarn配置说明
需要调整的Yarn参数均与CPU、内存等资源有关,核心配置参数如下。
(1)yarn.nodemanager.resource.memory-mb
该参数的含义是,一个NodeManager节点分配给Container使用的内存。该参数的配置,取决于NodeManager所在节点的总内存容量和该节点运行的其他服务的数量。
考虑上述因素,此处可将该参数设置为64G,如下:
yarn.nodemanager.resource.memory-mb
65536
(2)yarn.nodemanager.resource.cpu-vcores
该参数的含义是,一个NodeManager节点分配给Container使用的CPU核数。该参数的配置,同样取决于NodeManager所在节点的总CPU核数和该节点运行的其他服务。
考虑上述因素,此处可将该参数设置为16。
yarn.nodemanager.resource.cpu-vcores
16
(3)yarn.scheduler.maximum-allocation-mb
该参数的含义是,单个Container能够使用的最大内存。由于Spark的yarn模式下,Driver和Executor都运行在Container中,故该参数不能小于Driver和Executor的内存配置,推荐配置如下:
yarn.scheduler.maximum-allocation-mb
16384
(4)yarn.scheduler.minimum-allocation-mb
该参数的含义是,单个Container能够使用的最小内存,推荐配置如下:
yarn.scheduler.minimum-allocation-mb
512
2.2 Yarn配置实操
(1)修改$HADOOP_HOME/etc/hadoop/yarn-site.xml文件
(2)修改如下参数
yarn.nodemanager.resource.memory-mb
65536
yarn.nodemanager.resource.cpu-vcores
16
yarn.scheduler.maximum-allocation-mb
16384
yarn.scheduler.minimum-allocation-mb
512
(3)分发该配置文件
(4)重启Yarn。
第3章 Spark配置
3.1 Executor配置说明
3.1.1 Executor CPU核数配置
单个Executor的CPU核数,由spark.executor.cores参数决定,建议配置为4-6,具体配置为多少,视具体情况而定,原则是尽量充分利用资源。
此处单个节点共有16个核可供Executor使用,则spark.executor.core配置为4最合适。原因是,若配置为5,则单个节点只能启动3个Executor,会剩余1个核未使用;若配置为6,则只能启动2个Executor,会剩余4个核未使用。
3.1.2 Executor内存配置
Spark在Yarn模式下的Executor内存模型如下图所示:
Executor相关的参数有:spark.executor.memory和spark.executor.memoryOverhead。spark.executor.memory用于指定Executor进程的堆内存大小,这部分内存用于任务的计算和存储;spark.executor.memoryOverhead用于指定Executor进程的堆外内存,这部分内存用于JVM的额外开销,操作系统开销等。两者的和才算一个Executor进程所需的总内存大小。默认情况下spark.executor.memoryOverhead的值等于spark.executor.memory*0.1。
以上两个参数的推荐配置思路是,先按照单个NodeManager的核数和单个Executor的核数,计算出每个NodeManager最多能运行多少个Executor。在将NodeManager的总内存平均分配给每个Executor,最后再将单个Executor的内存按照大约10:1的比例分配到spark.executor.memory和spark.executor.memoryOverhead。
根据上述思路,可得到如下关系:
(spark.executor.memory+spark.executor.memoryOverhead)= yarn.nodemanager.resource.memory-mb * (spark.executor.cores/yarn.nodemanager.resource.cpu-vcores)
经计算,此处应做如下配置:
spark.executor.memory 14G
spark.executor.memoryOverhead 2G
3.1.3 Executor个数配置
此处的Executor个数是指分配给一个Spark应用的Executor个数,Executor个数对于Spark应用的执行速度有很大的影响,所以Executor个数的确定十分重要。
一个Spark应用的Executor个数的指定方式有两种,静态分配和动态分配。
1**)静态分配**
可通过spark.executor.instances指定一个Spark应用启动的Executor个数。这种方式需要自行估计每个Spark应用所需的资源,并为每个应用单独配置Executor个数。
2**)动态分配**
动态分配可根据一个Spark应用的工作负载,动态的调整其所占用的资源(Executor个数)。这意味着一个Spark应用程序可以在运行的过程中,需要时,申请更多的资源(启动更多的Executor),不用时,便将其释放。
在生产集群中,推荐使用动态分配。动态分配相关参数如下:
#启动动态分配
spark.dynamicAllocation.enabled true
#启用Spark shuffle服务
spark.shuffle.service.enabled true
#Executor个数初始值
spark.dynamicAllocation.initialExecutors 1
#Executor个数最小值
spark.dynamicAllocation.minExecutors 1
#Executor个数最大值
spark.dynamicAllocation.maxExecutors 12
#Executor空闲时长,若某Executor空闲时间超过此值,则会被关闭
spark.dynamicAllocation.executorIdleTimeout 60s
#积压任务等待时长,若有Task等待时间超过此值,则申请启动新的Executor
spark.dynamicAllocation.schedulerBacklogTimeout 1s
#spark shuffle老版本协议
spark.shuffle.useOldFetchProtocol true
说明:Spark shuffle服务的作用是管理Executor中的各Task的输出文件,主要是shuffle过程map端的输出文件。由于启用资源动态分配后,Spark会在一个应用未结束前,将已经完成任务,处于空闲状态的Executor关闭。Executor关闭后,其输出的文件,也就无法供其他Executor使用了。需要启用Spark shuffle服务,来管理各Executor输出的文件,这样就能关闭空闲的Executor,而不影响后续的计算任务了。
3.2 Driver配置说明
Driver主要配置内存即可,相关的参数有spark.driver.memory和spark.driver.memoryOverhead。
spark.driver.memory用于指定Driver进程的堆内存大小,spark.driver.memoryOverhead用于指定Driver进程的堆外内存大小。默认情况下,两者的关系如下:spark.driver.memoryOverhead=spark.driver.memory*0.1。两者的和才算一个Driver进程所需的总内存大小。
一般情况下,按照如下经验进行调整即可:假定yarn.nodemanager.resource.memory-mb设置为X,
若X>50G,则Driver可设置为12G,
若12G<X<50G,则Driver可设置为4G。
若1G<X<12G,则Driver可设置为1G。
此处yarn.nodemanager.resource.memory-mb为64G,则Driver的总内存可分配12G,所以上述两个参数可配置为。
spark.driver.memory 10G
spark.yarn.driver.memoryOverhead 2G
3.3 Spark配置实操
1**)修改spark-defaults.conf文件**
(1)修改$HIVE_HOME/conf/spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://myNameService1/spark-history
spark.executor.cores 4
spark.executor.memory 14g
spark.executor.memoryOverhead 2g
spark.driver.memory 10g
spark.driver.memoryOverhead 2g
spark.dynamicAllocation.enabled true
spark.shuffle.service.enabled true
spark.dynamicAllocation.executorIdleTimeout 60s
spark.dynamicAllocation.initialExecutors 1
spark.dynamicAllocation.minExecutors 1
spark.dynamicAllocation.maxExecutors 12
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.shuffle.useOldFetchProtocol true
2**)配置Spark shuffle服务**
Spark Shuffle服务的配置因Cluster Manager(standalone、Mesos、Yarn)的不同而不同。此处以Yarn作为Cluster Manager。
(1)拷贝$SPARK_HOME/yarn/spark-3.0.0-yarn-shuffle.jar到
$HADOOP_HOME/share/hadoop/yarn/lib
(2)分发$HADOOP_HOME/share/hadoop/yarn/lib/yarn/spark-3.0.0-yarn-shuffle.jar
(3)修改$HADOOP_HOME/etc/hadoop/yarn-site.xml文件
yarn.nodemanager.aux-services
mapreduce_shuffle,spark_shuffle
yarn.nodemanager.aux-services.spark_shuffle.class
org.apache.spark.network.yarn.YarnShuffleService
(4)分发$HADOOP_HOME/etc/hadoop/yarn-site.xml文件
(5)重启Yarn
第4章 Hive SQL执行计划
Hive SQL的执行计划,可由Explain查看。
Explain呈现的执行计划,由一系列Stage组成,这个Stage具有依赖关系,每个Stage对应一个MapReduce Job或者Spark Job,或者一个文件系统操作等。
每个Stage由一系列的Operator组成,一个Operator代表一个逻辑操作,例如TableScan Operator,Select Operator,Join Operator等。
Stage与Operator的对应关系如下图:

Explain****相关资料
1.https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain
2.https://cwiki.apache.org/confluence/download/attachments/44302539/hos_explain.pdf?version=1&modificationDate=1425575903211&api=v2
第5章分组聚合优化
示例SQL语句如下
hive>
select
coupon_id,
count(*)
from dwd_trade_order_detail_inc
where dt=‘2020-06-16’
group by coupon_id;
5.1 优化前执行计划

5.2 优化思路
优化思路为map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成分区内的、部分的聚合,然后将部分聚合的结果,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
map-side 聚合相关的参数如下:
–启用map-side聚合
set hive.map.aggr=true;
–hash map占用map端内存的最大比例
set hive.map.aggr.hash.percentmemory=0.5;
–用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
–map-side聚合所用的HashTable,占用map任务堆内存的最大比例,若超出该值,则会对HashTable进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
5.3 优化后执行计划

第6章 Join优化
6.1 Hive Join算法概述
Hive拥有多种join算法,包括common join,map join,sort Merge Bucket Map Join等。下面对每种join算法做简要说明:
1**)**common join
Map端负责读取参与join的表的数据,并按照关联字段进行分区,将其发送到Reduce端,Reduce端完成最终的关联操作。

2**)**map join
若参与join的表中,有n-1张表足够小,Map端就会缓存小表全部数据,然后扫描另外一张大表,在Map端完成关联操作。

3**)**Sort Merge Bucket Map Join
若参与join的表均为分桶表,且关联字段为分桶字段,且分桶字段是有序的,且大表的分桶数量是小表分桶数量的整数倍。此时,就可以以分桶为单位,为每个Map分配任务了,Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶。
6.2 Map Join优化
示例SQL语句如下
hive>
select
*
from
(
select
*
from dwd_trade_order_detail_inc
where dt=‘2020-06-16’
)fact
left join
(
select
*
from dim_sku_full
where dt=‘2020-06-16’
)dim
on fact.sku_id=dim.id;
6.2.1 优化前执行计划

6.2.2 优化思路
上述参与join的两表一大一小,可考虑map join优化。
Map Join相关参数如下:
–启用map join自动转换
set hive.auto.convert.join=true;
–common join转map join小表阈值
set hive.auto.convert.join.noconditionaltask.size
6.2.3 优化后执行计划

6.3 Sort Merge Bucket Map Join
6.3.1 优化说明
Sort Merge Bucket Map Join相关参数:
–启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;
–使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;
6.3.2 优化案例
1**)示例SQL语句**
hive (default)>
select
*
from(
select
*
from dim_user_zip
where dt=‘9999-12-31’
)duz
join(
select
*
from dwd_trade_order_detail_inc
where dt=‘2020-06-16’
)dtodi
on duz.id=dtodi.user_id;
2**)优化前**
上述SQL语句共有两张表一次join操作,故优化前的执行计划应包含一个Common Join任务,通过一个MapReduce Job实现。
3**)优化思路**
经分析,参与join的两张表,数据量如下
| 表名 | 大小 |
|---|---|
| dwd_trade_order_detail_inc | 162900000000(约160g) |
| dim_user_zip | 12320000000 (约12g) |
两张表都相对较大,可以考虑采用SMBSMB Map Join对分桶大小是没有要求的。下面演示如何使用SMB Map Join。
首先需要依据源表创建两个的有序的分桶表,dwd_trade_order_detail_inc建议分36个bucket,dim_user_zip建议分6个bucket,注意**分桶个数的倍数关系以及分桶字段和排序字段**。
–****订单明细表
hive (default)>
drop table if exists dwd_trade_order_detail_inc_bucketed;
create table dwd_trade_order_detail_inc_bucketed(
id string,
order_id string,
user_id string,
sku_id string,
province_id string,
activity_id string,
activity_rule_id string,
coupon_id string,
date_id string,
create_time string,
source_id string,
source_type_code string,
source_type_name string,
sku_num bigint,
split_original_amount decimal(16,2),
split_activity_amount decimal(16,2),
split_coupon_amount decimal(16,2),
split_total_amount decimal(16,2)
)
clustered by (user_id) sorted by(user_id) into 36 buckets
row format delimited fields terminated by ‘\t’;
–****用户表
hive (default)>
drop table if exists dim_user_zip_bucketed;
create table dim_user_zip_bucketed(
id string,
login_name string,
nick_name string,
name string,
phone_num string,
email string,
user_level string,
birthday string,
gender string,
create_time string,
operate_time string,
start_date string,
end_date string,
dt string
)
clustered by (id) sorted by(id) into 6 buckets
row format delimited fields terminated by ‘\t’;
然后向两个分桶表导入数据。
–****订单明细分桶表
hive (default)>
insert overwrite table dwd_trade_order_detail_inc_bucketed
select
id ,
order_id ,
user_id ,
sku_id ,
province_id ,
activity_id ,
activity_rule_id ,
coupon_id ,
date_id ,
create_time ,
source_id ,
source_type_code ,
source_type_name ,
sku_num ,
split_original_amount ,
split_activity_amount ,
split_coupon_amount,
split_total_amount
from dwd_trade_order_detail_inc
where dt=‘2020-06-16’;
–****用户分桶表
hive (default)>
insert overwrite table dim_user_zip_bucketed
select
id,
login_name,
nick_name,
name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
start_date,
end_date,
dt
from dim_user_zip
where dt=‘9999-12-31’;
然后设置以下参数:
–启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;
–使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;
最后在重写SQL语句,如下:
hive (default)>
select
*
from dwd_trade_order_detail_inc_bucketed od
join dim_user_zip_bucketed duser
on od.user_id = duser.id;
优化后的执行计如图所示:

第7章数据倾斜优化
7.1 数据倾斜说明
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
Hive中的数据倾斜常出现在分组聚合和join操作的场景中,下面分别介绍在上述两种场景下的优化思路。
7.2 分组聚合导致的数据倾斜
示例SQL语句如下
hive>
select
province_id,
count(*)
from dwd_trade_order_detail_inc
where dt=‘2020-06-16’
group by province_id;
7.2.1 优化前执行计划

7.2.2 优化思路
由分组聚合导致的数据倾斜问题主要有以下两种优化思路:
1**)启用map-side聚合**
相关参数如下:
–启用map-side聚合
set hive.map.aggr=true;
–hash map占用map端内存的最大比例
set hive.map.aggr.hash.percentmemory=0.5;
启用map-side聚合后的执行计划如下图所示

2**)启用skew groupby优化**
其原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合。
相关参数如下:
–启用分组聚合数据倾斜优化
set hive.groupby.skewindata=true;
启用skew groupby优化后的执行计划如下图所示

7.3 join导致的数据倾斜
示例SQL语句如下。
hive>
select
*
from
(
select
*
from dwd_trade_order_detail_inc
where dt=‘2020-06-16’
)fact
join
(
select
*
from dim_province_full
where dt=‘2020-06-16’
)dim
on fact.province_id=dim.id;
7.3.1 优化前的执行计划

7.3.2 优化思路
由join导致的数据倾斜问题主要有以下两种优化思路:
1**)使用****map join**
相关参数如下:
–启用map join自动转换
set hive.auto.convert.join=true;
–common join转map join小表阈值
set hive.auto.convert.join.noconditionaltask.size
使用map join优化后执行计划如下图。

2**)启用skew join优化**
其原理如下图

相关参数如下:
–启用skew join优化
set hive.optimize.skewjoin=true;
–触发skew join的阈值,若某个key的行数超过该参数值,则触发
set hive.skewjoin.key=100000;
需要注意的是,skew join只支持Inner Join。
启动skew join优化后的执行计划如下图所示:

第8章任务并行度优化
8.1 优化说明
对于一个分布式的计算任务而言,设置一个合适的并行度十分重要。在Hive中,无论其计算引擎是什么,所有的计算任务都可分为Map阶段和Reduce阶段。所以并行度的调整,也可从上述两个方面进行调整。
8.2 Map阶段并行度
Map端的并行度,也就是Map的个数。是由输入文件的切片数决定的。一般情况下,Map端的并行度无需手动调整。Map端的并行度相关参数如下:
–可将多个小文件切片,合并为一个切片,进而由一个map任务处理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
–一个切片的最大值
set mapreduce.input.fileinputformat.split.maxsize=256000000;
8.3 Reduce阶段并行度
Reduce端的并行度,相对来说,更需要关注。默认情况下,Hive会根据Reduce端输入数据的大小,估算一个Reduce并行度。但是在某些情况下,其估计值不一定是最合适的,故需要人为调整其并行度。
Reduce并行度相关参数如下:
–指定Reduce端并行度,默认值为-1,表示用户未指定
set mapreduce.job.reduces;
–Reduce端并行度最大值
set hive.exec.reducers.max;
–单个Reduce Task计算的数据量,用于估算Reduce并行度
set hive.exec.reducers.bytes.per.reducer;
Reduce端并行度的确定逻辑为,若指定参数mapreduce.job.reduces的值为一个非负整数,则Reduce并行度为指定值。否则,Hive会自行估算Reduce并行度,估算逻辑如下:
假设Reduce端输入的数据量大小为totalInputBytes
参数hive.exec.reducers.bytes.per.reducer的值为bytesPerReducer
参数hive.exec.reducers.max的值为maxReducers
则Reduce端的并行度为:

其中,Reduce端输入的数据量大小,是从Reduce上游的Operator的Statistics(统计信息)中获取的。为保证Hive能获得准确的统计信息,需配置如下参数:
–执行DML语句时,收集表级别的统计信息
set hive.stats.autogather=true;
–执行DML语句时,收集字段级别的统计信息
set hive.stats.column.autogather=true;
–计算Reduce并行度时,从上游Operator统计信息获得输入数据量
set hive.spark.use.op.stats=true;
–计算Reduce并行度时,使用列级别的统计信息估算输入数据量
set hive.stats.fetch.column.stats=true;
第9章小文件合并优化
9.1 优化说明
小文件合并优化,分为两个方面,分别是Map端输入的小文件合并,和Reduce端输出的小文件合并。
9.2 Map端输入文件合并
合并Map端输入的小文件,是指将多个小文件划分到一个切片中,进而由一个Map Task去处理。目的是防止为单个小文件启动一个Map Task,浪费计算资源。
相关参数为:
–可将多个小文件切片,合并为一个切片,进而由一个map任务处理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
9.3 Reduce输出文件合并
合并Reduce端输出的小文件,是指将多个小文件合并成大文件。目的是减少HDFS小文件数量。
相关参数为:
–开启合并Hive on Spark任务输出的小文件
set hive.merge.sparkfiles=true;
第10章其他优化
参考资料:
1.https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/admin_hos_tuning.html#hos_tuning
2.https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
参考
Spark性能调优完整版
相关文章:
Hive on Spark优化
文章目录 第1章集群环境概述1.1 集群配置概述1.2 集群规划概述 第2章 Yarn配置2.1 Yarn配置说明2.2 Yarn配置实操 第3章 Spark配置3.1 Executor配置说明3.1.1 Executor CPU核数配置3.1.2 Executor内存配置3.1.3 Executor个数配置 3.2 Driver配置说明3.3 Spark配置实操 第4章 Hi…...

【实践案例】基于大语言模型的海龟汤游戏
文章目录 项目背景提示词构建海龟汤主持人真相判断专家 具体实现流程文心一言大语言模型“海龟汤”插件参考 项目背景 “海龟汤”作为一种聚会类桌游,又称情境推理游戏,是一种猜测情境还原事件真相的智力游戏。其玩法是由出题者提出一个难以理解的事件&…...

汽车自动驾驶AI
汽车自动驾驶AI是当前汽车技术领域的前沿方向,以下是关于汽车自动驾驶AI的详细介绍: 技术原理 感知系统:自动驾驶汽车通过多种传感器(如激光雷达、摄像头、雷达、超声波传感器等)收集周围环境的信息。AI算法对这些传感…...

解决vscode扩展插件开发webview中的请求跨域问题
在webview中是无法发送跨域请求的,可以通过消息机制,在插件中发请求,然后将请求结果传递给webview 我的代码是基于vscode-webview-ui-toolkit-samples-vue来写的 webview vue组件中的代码示例 async function initData() {// 向插件发送消…...

P3078[USACO13MAR] Poker Hands S
P3078[USACO13MAR] Poker Hands S https://www.luogu.com.cn/problem/P3078 前言 学习差分后写的第一道题,直接给我干懵逼,题解都看不懂……吃了个晚饭后开窍写出来了,遂成此篇。 题目 翻译版本 Bessie 和她的朋友们正在玩一种独特的扑克游…...

创建前端项目的方法
目录 一、创建前端项目的方法 1.前提:安装Vue CLI 2.方式一:vue create项目名称 3.方式二:vue ui 二、Vue项目结构 三、修改Vue项目端口号的方法 一、创建前端项目的方法 1.前提:安装Vue CLI npm i vue/cli -g 2.方式一&…...

Java 大数据与区块链的融合:数据可信共享与溯源(45)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

【建站】专栏目录
建站专栏的想法有很多,想写穷鬼如何快速低成本部署前后端项目让用户能访问到,如何将网站收录到百度,bing,google并优化seo让搜索引擎搜索到网站,想写如何把网站加入google广告或者接入stripe信用卡首款平台收款&#x…...

STM32单片机学习记录(2.2)
一、STM32 13.1 - PWR简介 1. PWR(Power Control)电源控制 (1)PWR负责管理STM32内部的电源供电部分,可以实现可编程电压监测器和低功耗模式的功能; (2)可编程电压监测器(…...

nlp文章相似度
1. 基于词袋模型(Bag of Words) 方法: 将文本表示为词频向量(如TF-IDF),通过余弦相似度计算相似性。 优点:简单快速,适合短文本或主题明显的场景。 缺点:忽略词序和语…...

ROS应用之SwarmSim在ROS 中的协同路径规划
SwarmSim 在 ROS 中的协同路径规划 前言 在多机器人系统(Multi-Robot Systems, MRS)中,SwarmSim 是一个常用的模拟工具,可以对多机器人进行仿真以实现复杂任务的协同。除了任务分配逻辑以外,SwarmSim 在协同路径规划方…...
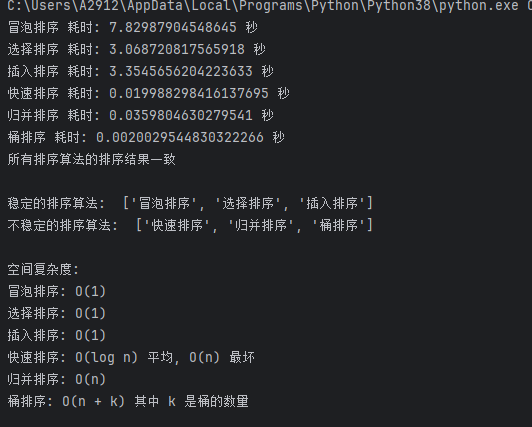
蓝桥杯python基础算法(2-1)——排序
目录 一、排序 二、例题 P3225——宝藏排序Ⅰ 三、各种排序比较 四、例题 P3226——宝藏排序Ⅱ 一、排序 (一)冒泡排序 基本思想:比较相邻的元素,如果顺序错误就把它们交换过来。 (二)选择排序 基本思想…...

深度学习中常用的评价指标方法
深度学习中常用的评价指标方法因任务类型(如分类、回归、分割等)而异。以下是一些常见的评价指标: 1. 分类任务 准确率(Accuracy) 定义:正确预测的样本数占总样本数的比例。 公式:AccuracyTPT…...

linux 进程补充
环境变量 基本概念 环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数 如:我们在编写C/C代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪 里,但是照样可以链接成功&#…...

Django框架的全面指南:从入门到高级
Django框架的全面指南:从入门到高级 目录 引言Django简介安装与配置创建第一个Django项目Django的MVT架构模型(Model)视图(View)模板(Template)URL路由表单处理用户认证与权限Django Admin高级…...

C基础寒假练习(8)
一、终端输入10个学生成绩,使用冒泡排序对学生成绩从低到高排序 #include <stdio.h> int main(int argc, const char *argv[]) {int arr[10]; // 定义一个长度为10的整型数组,用于存储学生成绩int len sizeof(arr) / sizeof(arr[0]); // 计算数组…...

Python爬虫:1药城店铺爬虫(完整代码)
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…...

【贪心算法篇】:“贪心”之旅--算法练习题中的智慧与策略(一)
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:贪心算法篇–CSDN博客 文章目录 一.贪心算法1.什么是贪心算法2.贪心算法的特点 二.例题1.柠…...

Rust 变量特性:不可变、和常量的区别、 Shadowing
Rust 变量特性:不可变、和常量的区别、 Shadowing Rust 是一门以安全性和性能著称的系统编程语言,其变量系统设计独特且强大。本文将从三个角度介绍 Rust 变量的核心特性:可变性(Mutability)、变量与常量的区别&#…...

基于Springboot框架的学术期刊遴选服务-项目演示
项目介绍 本课程演示的是一款 基于Javaweb的水果超市管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套系统 3.该项目附…...

方法一:将私钥存入环境变量,环境变量指什么//spring中,rsa私钥应该怎么处置
环境变量(Environment Variables)是操作系统提供的一种机制,用于存储和传递配置信息或敏感数据(如密钥、密码等)。每个进程都可以访问一组环境变量,这些变量在操作系统级别定义,可以被应用程序读…...
钩子和函数式组件底层渲染流程详解)
React中useState()钩子和函数式组件底层渲染流程详解
useState()钩子底层渲染流程 React中useState的底层渲染机理。首先,我知道useState是React Hooks的一部分,用于在函数组件中添加状态。但底层是如何工作的呢?可能涉及到React的调度器、Fiber架构以及闭包等概念。 首先,React使用F…...

Cocos Creator 3.8 2D 游戏开发知识点整理
目录 Cocos Creator 3.8 2D 游戏开发知识点整理 1. Cocos Creator 3.8 概述 2. 2D 游戏核心组件 (1) 节点(Node)与组件(Component) (2) 渲染组件 (3) UI 组件 3. 动画系统 (1) 传统帧动画 (2) 动画编辑器 (3) Spine 和 …...

Java创建对象有几种方式?
大家好,我是锋哥。今天分享关于【Java创建对象有几种方式?】面试题。希望对大家有帮助; Java创建对象有几种方式? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 Java 中,创建对象有几种常见的方式,具体如下&…...

R 字符串:深入理解与高效应用
R 字符串:深入理解与高效应用 引言 在R语言中,字符串是数据处理和编程中不可或缺的一部分。无论是数据清洗、数据转换还是数据分析,字符串的处理都是基础技能。本文将深入探讨R语言中的字符串概念,包括其基本操作、常见函数以及高效应用方法。 字符串基本概念 字符串定…...

基于Flask的全国星巴克门店可视化分析系统的设计与实现
【FLask】基于Flask的全国星巴克门店可视化分析系统的设计与实现(完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 该系统采用Python作为主要开发语言,结合Flask框架进行后端开发&…...

pytorch实现半监督学习
人工智能例子汇总:AI常见的算法和例子-CSDN博客 半监督学习(Semi-Supervised Learning,SSL)结合了有监督学习和无监督学习的特点,通常用于部分数据有标签、部分数据无标签的场景。其主要步骤如下: 1. 数…...

Golang :用Redis构建高效灵活的应用程序
在当前的应用程序开发中,高效的数据存储和检索的必要性已经变得至关重要。Redis是一个快速的、开源的、内存中的数据结构存储,为各种应用场景提供了可靠的解决方案。在这个完整的指南中,我们将学习什么是Redis,通过Docker Compose…...

deepseek+vscode自动化测试脚本生成
近几日Deepseek大火,我这里也尝试了一下,确实很强。而目前vscode的AI toolkit插件也已经集成了deepseek R1,这里就介绍下在vscode中利用deepseek帮助我们完成自动化测试脚本的实践分享 安装AI ToolKit并启用Deepseek 微软官方提供了一个针对AI辅助的插件,也就是 AI Toolk…...

49【服务器介绍】
服务器和你的电脑可以说是一模一样的,只不过用途不一样,叫法就不一样了 物理服务器和云服务器的区别 整台设备眼睛能够看得到的,我们一般称之为物理服务器。所以物理服务器是比较贵的,不是每一个开发者都能够消费得起的。 …...