【机器学习】超参数的选择,以kNN算法为例
分类准确度
- 一、摘要
- 二、超参数的概念
- 三、调参的方法
- 四、实验搜索超参数
- 五、扩展搜索范围
- 六、考虑距离权重的kNN算法
- 七、距离的计算方法及代码实现
- 八、明可夫斯基距离的应用
- 九、网格搜索超参数
一、摘要
本博文讲解了机器学习中的超参数问题,以K近邻算法为例,介绍了超参数的概念及其重要性。讲解了如何通过实验搜索确定最佳的超参数值,如k值的选择,并介绍了距离权重的考虑和明可夫斯基距离的计算方法。同时,探讨了如何通过网格搜索策略来寻找最优的超参数组合。最后,强调了机器学习工程师在进行调参时需要考虑领域知识和经验数值的重要性。
二、超参数的概念
- 超参数是在
运行机器学习算法之前需要指定的参数。 - kNN算法中的
k是一个典型的超参数。 - 超参数与模型参数的
区别在于,超参数在算法运行前决定,而模型参数在算法过程中学习。
三、调参的方法
- 调参的目标是找到最好的超参数。
- 领域知识和经验数值是寻找超参数的重要途径。
- 对于具体问题,最好的超参数可能不同于经验数值,需要通过实验搜索确定。
四、实验搜索超参数
- 通过循环测试不同k值,找到最佳的k值。
- 初始化最佳准确率和最佳k值,循环遍历k的取值范围。
- 对每个k值,创建kNN分类器并计算准确率,更新最佳准确率和最佳k值。
五、扩展搜索范围
- 如果找到的最佳k值在搜索范围的边界上,建议扩展搜索范围以寻找更好的值。
六、考虑距离权重的kNN算法
- kNN算法可以考虑距离的权重,通常使用距离的倒数作为权重。
- 距离越近,权重越大。
- 考虑距离权重可以更好地解决
平票问题。 - 权重weight的选择:
- kNN分类器中有一个
weight参数,默认值为uniform,表示不考虑距离权重。 - 将位次参数设置为
distance时,会考虑距离权重,可使用明可夫斯基距离。 - 通过实验搜索找到最佳的weight参数。
- kNN分类器中有一个
七、距离的计算方法及代码实现
- 距离的计算方法包括
欧拉距离和曼哈顿距离。 欧拉距离是每个维度上差值的平方和的平方根。

曼哈顿距离是每个维度上差值的绝对值的和。

明可夫斯基距离是每个维度上差值的绝对值的p次方和的p次方根。

- 三者的关系
p=1时,明可夫斯基距离为曼哈顿距离;p=2时,为欧拉距离。

- 通过寻找kNN超参数,利用手写数字数据集作为训练集和测试集
-
准备手写数字数据集,并调用scikit-learn中的kNN算法在指定k值的得分或表现
import numpy as np from sklearn import datasets# 准备数据集 digits = datasets.load_digits() X = digits.data y = digits.target# 将数据集拆分为训练集和测试集 from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=666)# 指定sklearn中kNN中的k值为3 from sklearn.neighbors import KNeighborsClassifier knn_clf = KNeighborsClassifier(n_neighbors=3) knn_clf.fit(X_train,y_train) knn_clf.score(X_test,y_test)在Jupyter中执行过程及结果如下:

-
寻找最佳的k的超参数值
from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=666)best_score = 0.0 # 设置默认准确度 best_k = -1 # 设置默认值 for k in range(1,11):knn_clf = KNeighborsClassifier(n_neighbors = k)knn_clf.fit(X_train,y_train)score= knn_clf.score(X_test,y_test) # 调用score函数得出knn算法准确度# 判断当前的score是否大于当前的best_score,如果是,则重新赋值if score > best_score:best_k = kbest_score = score print("best_k = ",best_k) print("best_score = ",best_score)在Jupyter中执行过程及结果如下:

-
考虑距离权重的kNN算法调用得到最佳超参数
# 当单纯使用KNN距离远近来作为分类的依据时,会存在离得近的点总数少于离得稍微远的点的总数,到时分类错误。可使用权重参数,通过选择一个合理的method方法来解决。 # 当投票时出现平票时,需要考虑使用距离的权重来解决; from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=666)best_method = None # kNN的一个超参数 best_score = 0.0 # 设置默认准确度 best_k = -1 # 设置默认值,为kNN默认的超参数 for method in ["uniform","distance"]:for k in range(1,11):knn_clf = KNeighborsClassifier(n_neighbors = k,weights=method) # weights 就是权重knn_clf.fit(X_train,y_train)score= knn_clf.score(X_test,y_test) # 调用score函数得出knn算法准确度# 判断当前的score是否大于当前的best_score,如果是,则重新赋值if score > best_score:best_k = kbest_score = scorebest_method = methodprint("best_k = ",best_k) print("best_score = ",best_score) print("best_method = ",best_method)在jupyter中执行过程及结果如下:

-
考虑使用明可夫斯基距离来搜索kNN最佳超参数
%%timefrom sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=666)best_p = -1 # kNN的一个超参数 best_score = 0.0 # 设置默认准确度 best_k = -1 # 设置默认值,为kNN默认的超参数 for k in range(1,11):for p in range(1,6):knn_clf = KNeighborsClassifier(n_neighbors = k,weights="distance",p=p) # 使用明可夫斯基距离时,weights必须是distanceknn_clf.fit(X_train,y_train)score= knn_clf.score(X_test,y_test) # 调用score函数得出knn算法准确度# 判断当前的score是否大于当前的best_score,如果是,则重新赋值if score > best_score:best_k = kbest_score = scorebest_p = pprint("best_k = ",best_k) print("best_score = ",best_score) print("best_p = ",best_p)在jupyter中执行的过程和结果如下所示:

-
八、明可夫斯基距离的应用
- 明可夫斯基距离可以表示多种距离计算方法。
- 通过搜索不同的p值,找到最适合当前问题的距离计算方法。
九、网格搜索超参数
- 网格搜索是一种系统搜索超参数的方法。
- 通过遍历所有可能的超参数组合,找到最佳组合。
- 代码实现:
执行结果如下:# 准备测试数据集 import numpy as np from sklearn import datasets digits = datasets.load_digits() X = digits.data y = digits.target from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=666)from sklearn.neighbors import KNeighborsClassifierknn_clf = KNeighborsClassifier(n_neighbors=3)# 定义网格参数 param_grid = [{'weights': ['uniform'],'n_neighbors': [ i for i in range(1,11)]},{'weights': ['distance'],'n_neighbors': [i for i in range(1,11)],'p' : [i for i in range(1,6)]} ] # 引入GridSearchCV 网格搜索 from sklearn.model_selection import GridSearchCV grid_search = GridSearchCV(knn_clf,param_grid) grid_search = GridSearchCV(knn_clf,param_grid,n_jobs=-1,verbose=2) grid_search.fit(X_train,y_train) # 查看相关参数 grid_search.best_estimator_ grid_search.best_score_ grid_search.best_params_
fit函数执行效果:


best_estimator_结果:

best_score_ 结果:

best_params_ 超参数的结果:

相关文章:
【机器学习】超参数的选择,以kNN算法为例
分类准确度 一、摘要二、超参数的概念三、调参的方法四、实验搜索超参数五、扩展搜索范围六、考虑距离权重的kNN算法七、距离的计算方法及代码实现八、明可夫斯基距离的应用九、网格搜索超参数 一、摘要 本博文讲解了机器学习中的超参数问题,以K近邻算法为例&#…...

哪吒闹海!SCI算法+分解组合+四模型原创对比首发!SGMD-FATA-Transformer-LSTM多变量时序预测
哪吒闹海!SCI算法分解组合四模型原创对比首发!SGMD-FATA-Transformer-LSTM多变量时序预测 目录 哪吒闹海!SCI算法分解组合四模型原创对比首发!SGMD-FATA-Transformer-LSTM多变量时序预测效果一览基本介绍程序设计参考资料 效果一览…...

Django开发入门 – 3.用Django创建一个Web项目
Django开发入门 – 3.用Django创建一个Web项目 Build A Web Based Project With Django By JacksonML 本文简要介绍如何利用最新版Python 3.13.2来搭建Django环境,以及创建第一个Django Web应用项目,并能够运行Django Web服务器。 创建该Django项目需…...

2025.2.8——二、Confusion1 SSTI模板注入|Jinja2模板
题目来源:攻防世界 Confusion1 目录 一、打开靶机,整理信息 二、解题思路 step 1:查看网页源码信息 step 2:模板注入 step 3:构造payload,验证漏洞 step 4:已确认为SSTI漏洞中的Jinjia2…...

【C语言标准库函数】标准输入输出函数详解[5]:格式化文件输入输出
目录 一、fprintf() 函数 1.1. 函数简介 1.2. fprintf使用场景 1.3. 注意事项 1.4. 示例 二、fscanf() 函数 2.1. 函数简介 2.2. fscanf使用场景 2.3. 注意事项 2.3. 示例 三、总结 在 C 语言中,格式化文件输入输出函数能够让我们以特定的格式对文件进行…...

【故障处理】 - 12C ADG备库密码文件的MD5值不断变化
【故障处理】 - 12C ADG备库密码文件的MD5值不断变化 一、概述二、报错原因:三、处理过程 一、概述 12C版本以后,密码文件的MD5值会持续变化。 二、报错原因: Oracle 数据库软件版本12.2 开始,当以具有管理权限的用户身份执行与数…...

【LeetCode Hot100 多维动态规划】最小路径和、最长回文子串、最长公共子序列、编辑距离
多维动态规划 机器人路径问题思路代码实现 最小路径和问题动态规划思路状态转移方程边界条件 代码实现 最长回文子串思路代码实现 最长公共子序列(LCS)题目描述解决方案 —— 动态规划1. 状态定义2. 状态转移方程3. 初始化4. 代码实现 编辑距离ÿ…...

【PG】DROP TABLE ... CASCADE
问题 ERROR: cannot drop table wx_user_tag because other objects depend on it DETAIL: default value for column id of table wx_user_tag depends on sequence wx_user_tag_id_seq HINT: Use DROP … CASCADE to drop the dependent objects too. 解决 这个错误消息表…...

青少年编程与数学 02-009 Django 5 Web 编程 04课题、应用创建
青少年编程与数学 02-009 Django 5 Web 编程 04课题、应用创建 一、项目及应用创建 Django 项目创建 Django 应用配置和测试 二、数据库的设置步骤 1: 创建 Django 项目步骤 2: 配置数据库PostgreSQLMySQL 步骤 3: 安装必要的数据库驱动步骤 4: 进行数据库迁移步骤 5: 创建应用…...

速度超越DeepSeek!Le Chat 1100tok/s闪电回答,ChatGPT 4o和DeepSeek R1被秒杀?
2023年,当全球科技界还在ChatGPT引发的AI狂潮中沉浮时,一场来自欧洲的"静默革命"正悄然改变游戏规则。法国人工智能公司Mistral AI推出的聊天机器人Le Chat以"比ChatGPT快10倍"的惊人宣言震动业界,其背后承载的不仅是技术…...

【详细版】DETR系列之Deformable DETR(2021 ICLR)
论文标题Deformable DETR: Deformable Transformers for End-to-End Object Detection论文作者Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai发表日期2021年03月01日GB引用> Xizhou Zhu, Weijie Su, Lewei Lu, et al. Deformable DETR: Deformable T…...

c++----函数重载
目录标题 为什么会有函数重载函数重载的概念函数重载的例子第一个:参数的类型不同第二个:参数的个数不同第三种:类型的顺序不同函数重载的奇异性重载函数的底层原理有关函数重载的一个问题 为什么会有函数重载 大家在学c语言的时候有没有发现…...

从云原生到 AI 原生,谈谈我经历的网关发展历程和趋势
作者:谢吉宝(唐三) 编者按: 云原生 API 网关系列教程即将推出,欢迎文末查看教程内容。本文整理自阿里云智能集团资深技术专家,云原生产品线中间件负责人谢吉宝(唐三) 在云栖大会的精…...

前端开发中,如何判断一个元素是否在可视区域中?
在前端开发中,判断一个元素是否在可视区域中是一个常见的需求,比如实现懒加载图片、无限滚动加载更多内容等功能。下面我将详细阐述这个问题。 一、判断元素是否在可视区域的方法 1. 使用 getBoundingClientRect 方法 getBoundingClientRect 方法返回…...

【干活分享】2025年可以免费问答的一些GPT网站-deepseek等免费gpt
2025年已经到来,大家也都陆续回归到忙碌的工作中。在新的一年里,如何更高效地完成工作任务,提升工作效率,是很多人关心的问题。今天,就为大家分享一些实用性很强的GPT网站,帮助大家在工作中事半功倍。 Dee…...
)
使用Redis实现业务信息缓存(缓存详解,缓存更新策略,缓存三大问题)
一、什么是缓存? 缓存是一种高效的数据存储方式,它通过将数据保存在内存中来提供快速的读写访问。这种机制特别适用于需要高速数据访问的应用场景,如网站、应用程序和服务。在处理大量数据和高并发请求时, 缓存能显著提高性能和用户体验。 Redis就是一款常用的缓存中间件。…...

ORB-SLAM3源码的学习:Atlas.cc②: Atlas:: CreateNewMap创建新地图
前言 简单总结一下地图是何时创建的: 构建slam系统时还没有地图就需要创建,当时间戳不对劲时影响数据的同步时需要创建,当跟踪的第一和第二阶段都为失败时都要分别创建,且满足一定要求的地图会保留作为非活跃地图。 1.创建新地…...

多头自注意力中的多头作用及相关思考
文章目录 1. num_heads2. pytorch源码演算 1. num_heads 将矩阵的最后一维度进行按照num_heads的方式进行切割矩阵,具体表示如下: 2. pytorch源码演算 pytorch 代码 import torch import torch.nn as nn import torch.nn.functional as Ftorch.set…...

常用的python库-安装与使用
常用的python库函数 yield关键字openslide库openslide库的安装-linuxopenslide的使用openslide对象的常用属性 cv2库numpy库ASAP库-multiresolutionimageinterface库ASAP库的安装ASAP库的使用 concurrent.futures.ThreadPoolExecutorxml.etree.ElementTree库skimage库PIL.Image…...

对接DeepSeek
其实,整个对接过程很简单,就四步,获取key,找到接口文档,接口测试,代码对接。 获取 KEY https://platform.deepseek.com/transactions 直接付款就是了(现在官网暂停充值2025年2月7日࿰…...

DevOps工具链概述
1. DevOps工具链概述 1.1 DevOps工具链的定义 DevOps工具链是支持DevOps实践的一系列工具的集合,这些工具覆盖了软件开发的整个生命周期,包括需求管理、开发、测试、部署和运维等各个环节。它旨在通过工具的集成和自动化,打破开发与运维之间…...

ChatGPT提问技巧:行业热门应用提示词案例-文案写作
ChatGPT 作为强大的 AI 语言模型,已经成为文案写作的得力助手。但要让它写出真正符合你需求的文案,关键在于如何与它“沟通”,也就是如何设计提示词(Prompt)。以下是一些实用的提示词案例,帮助你解锁 ChatG…...

分享如何通过Mq、Redis、XxlJob实现算法任务的异步解耦调度
一、背景 1.1 产品简介 基于大模型塔斯,整合传统的多项能力(NLP、OCR、CV等),构建以场景为中心的新型智能文档平台。通过文档审阅,实现结构化、半结构化和非结构化文档的信息获取、处理及审核,同时基于大…...

力扣-栈与队列-239 滑动窗口的最大值
双指针思路 每移动一次,可以比较上一次窗口的最大值和被移除的值,如果被移除的值小于最大值,则说明最大值仍在新的区间,但是最后超时了 双指针超时代码 class Solution { public:vector<int> maxSlidingWindow(vector<…...

在 MySQL 中,通过存储过程结合条件判断来实现添加表字段时,如果字段已存在则不再重复添加
-- 创建存储过程 DELIMITER $$ CREATE PROCEDURE add_column(IN db_name VARCHAR(255),IN table_name VARCHAR(255),IN column_name VARCHAR(255),IN column_definition VARCHAR(255),IN column_comment VARCHAR(255) ) BEGINDECLARE column_exists INT;-- 检查字段是否存在SEL…...

8.flask+websocket
http是短连接,无状态的。 websocket是长连接,有状态的。 flask中使用websocket from flask import Flask, request import asyncio import json import time import websockets from threading import Thread from urllib.parse import urlparse, pars…...

【大模型实战】使用Ollama+Chatbox实现本地Deepseek R1模型搭建
下载安装Ollama Ollama官方链接:https://ollama.com/,打开链接后就可以看到大大的下载按钮,如下图: 我选择用Win的安装。将Ollama的安装包下载到本地,如果下载慢可以复制链接到迅雷里面,提高下载速度,如下图: 双击之后,就可以开始安装了,如下图: 默认安装到C盘,…...
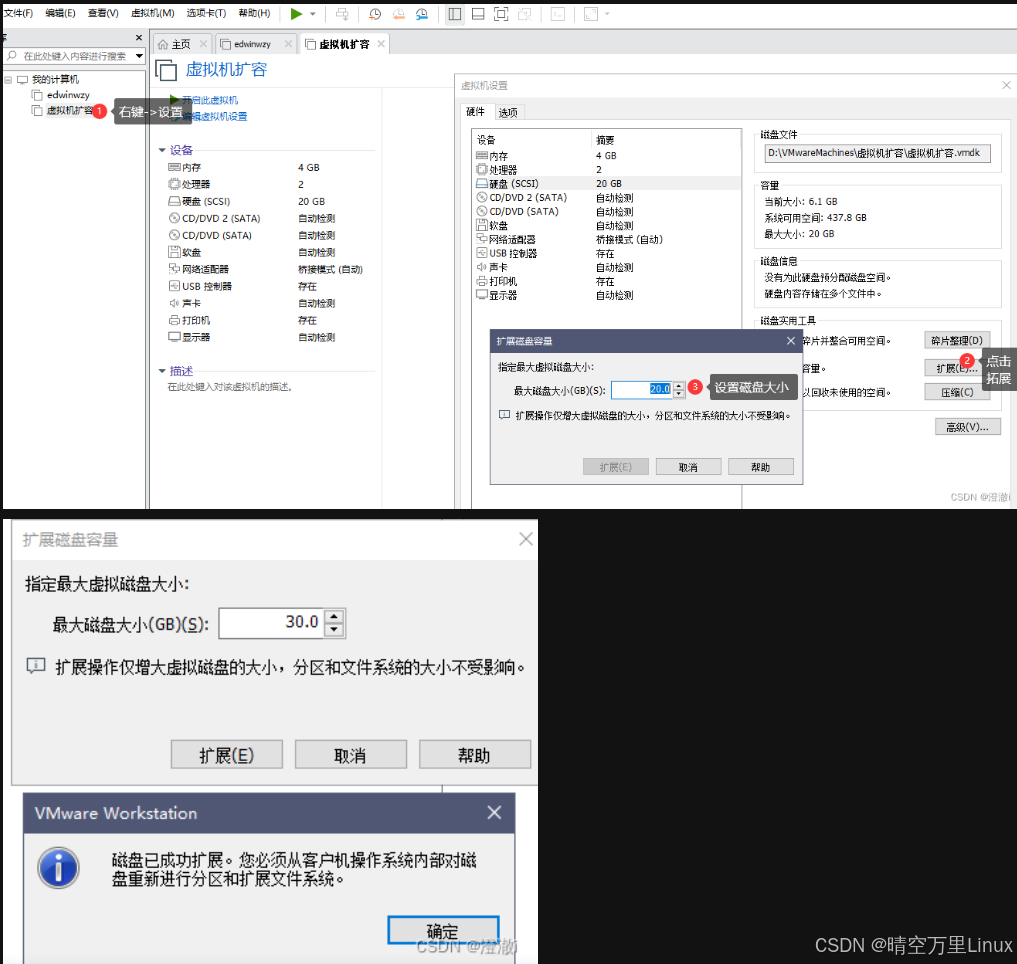
VMware 虚拟机 ubuntu 20.04 扩容工作硬盘
一、关闭虚拟机 关闭虚拟机参考下图,在vmware 调整磁盘容量 二、借助工具fdisk testubuntu ~ $ df -h Filesystem Size Used Avail Use% Mounted on udev 1.9G 0 1.9G 0% /dev tmpfs 388M 3.1M 385M 1% /run /dev/sda5 …...

ZooKeeper 和 Dubbo 的关系:技术体系与实际应用
引言 在现代微服务架构中,服务治理和协调是至关重要的环节。ZooKeeper 和 Dubbo 是两个在分布式系统中常用的技术工具,它们之间有着紧密的联系。本文将详细探讨 ZooKeeper 和 Dubbo 的关系,从基础概念、技术架构、具体实现到实际应用场景&am…...
(Go 语言实现))
【LeetCode 热题100】74:搜索二维矩阵(二分、线性两种方式 详细解析)(Go 语言实现)
🚀 力扣热题 74:搜索二维矩阵(详细解析) 📌 题目描述 力扣 74. 搜索二维矩阵 给你一个满足下述两条属性的 m x n 整数矩阵 matrix : 每行中的整数从左到右按非递减顺序排列。每行的第一个整数大于前一行的…...