Redis 实战篇 ——《黑马点评》(下)
《引言》
(下)篇将记录 Redis 实战篇 最后的一些学习内容,希望大家能够点赞、收藏支持一下 Thanks♪ (・ω・)ノ,谢谢大家。
传送门(上):Redis 实战篇 ——《黑马点评》(上)
传送门(中):Redis 实战篇 ——《黑马点评》(中)
传送门(下):当-前-页

四、好友关注
1.关注和取关
在业务中,用户之间存在着常见的关注功能,通过关注 up主来及时的获取其更新的内容。我们可以关注或取关对应的用户。
想要实现关注与取关功能,首先会在访问页面时查询当前用户与展示的用户之间的关系并展示出来,点击后根据现有关系发送请求进行关注或是取关。
public Result isFollow(Long followUserId) {Long userId = UserHolder.getUser().getId();Integer count = query().eq("user_id", userId).eq("follow_user_id", followUserId).count();return Result.ok(count > 0);
}查询用户之间的关系,先获取当前用户的 Id,通过其进行查询得到个数,如果查询得到的个数大于 0 则存在返回 true 表示状态为已关注,反之则为 false 表示未关注。
public Result follow(Long followUserId, Boolean isFollow) {Long userId = UserHolder.getUser().getId();if (isFollow){//关注Follow follow = new Follow();follow.setUserId(userId);follow.setFollowUserId(followUserId);boolean isSuccess = save(follow);}else {//取消关注remove(new QueryWrapper<Follow>().eq("user_id",userId).eq("follow_user_id",followUserId));}return Result.ok();
}该方法用于进行关注与取关操作,当点击按钮发送请求后,根据传来的 isFollow 值来判断当前进行的操作是关注或是取关。关注操作需要现将其存入数据库中,取关就是根据 Id 从数据库中删除相应的数据。
点击关注后效果如下所示,上方提示操作成功,同时按钮状态变为取消关注,再次点击后取消关注。


2.共同关注
想要实现查看共同关注功能,需要先完善查看其他用户主页的功能,其主要通过查询用户及其发布的博客来展示在用户的主页上。
@GetMapping("/{id}")
public Result queryUserById(@PathVariable("id") Long userId){// 查询详情User user = userService.getById(userId);if (user == null) {return Result.ok();}UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);// 返回return Result.ok(userDTO);
}根据用户 Id 查询用户的信息并返回。
@GetMapping("/of/user")
public Result queryBlogByUserId(@RequestParam(value = "current", defaultValue = "1") Integer current,@RequestParam("id") Long id) {// 根据用户查询Page<Blog> page = blogService.query().eq("user_id", id).page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));// 获取当前页数据List<Blog> records = page.getRecords();return Result.ok(records);
}根据用户 Id 查询用户的博客 信息并返回。
点击其他用户头像可以查看其个人信息,效果如下所示

接下来,就需要实现查看共同关注的功能。而我们可以借助 Redis 中 Set 数据类型的 SINTER 方法来查看两个 Set 集合中的交集部分,我们利用这一点,就可以简单地实现共同关注功能。

首先,我们需要在关注用户时将信息同步的存入到 Redis 的对应用户的集合中,其中存入 Redis 中的 key 前缀为 follows 后接当前用户 Id 以作区分 。所以在原先的关注功能中关注后存入 Redis 中,同样的,在取消关注的操作成功后,将 Redis 中的数据也删除掉。
public Result follow(Long followUserId, Boolean isFollow) {Long userId = UserHolder.getUser().getId();String followKey = "follows:" + userId;if (isFollow){//关注Follow follow = new Follow();follow.setUserId(userId);follow.setFollowUserId(followUserId);boolean isSuccess = save(follow);if(isSuccess){//关注成功后,存入 Redis 中stringRedisTemplate.opsForSet().add(followKey,followUserId.toString());}}else {//取消关注boolean isSuccess = remove(new QueryWrapper<Follow>().eq("user_id",userId).eq("follow_user_id",followUserId));if (isSuccess) {stringRedisTemplate.opsForSet().remove(followKey, followUserId.toString());}}return Result.ok();
}接着,我们就要去实现查询共同关注的功能:
public Result followCommons(Long id) {//获取当前用户Long userId = UserHolder.getUser().getId();String key = "follows:" + userId;String key2 = "follows:" + id;//求交集Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);if (intersect == null || intersect.isEmpty()){return Result.ok(Collections.emptyList());}//解析 IdList<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());//查询用户List<UserDTO> users = userService.listByIds(ids).stream().map(user -> BeanUtil.copyProperties(user, UserDTO.class)).collect(Collectors.toList());return Result.ok(users);
}获取当前用户 Id 后,拼接对应的字符串,分别对应自己与正在查看的用户,后用 intersect 方法求取交集,由于其中可能包含多个 Id,通过 stream 流的方式可以高效便捷的处理查询得到的 Id 并通过其进行查询得到对应的用户信息返回,用于展示在页面上。
最终效果如下所示

3.关注推送
在我们关注某一用户后,当其再次发布新的博客后,系统应将其推送给所有关注他的用户,例如微信的朋友圈。这种方式也称作 Feed 流,可以将内容自动推送给用户。Feed 流有两种常见的模式:
① TimeLine:对内容进行简单的筛选,按照内容发布时间排序,常用于好友或关注。例如朋友圈
- 优点:信息全面,不会有缺失。并且实现也相对简单
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
② 智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容,推送用户感兴趣信息来吸引用户。例如抖音。
- 优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
- 缺点:如果算法不精准,可能起到反作用
这里选择使用 TimeLine 模式来实现关注后推送最新博客的功能,而这种模式的实现方式又分为三种:
- 拉模式:也称做读扩散,被关注者会将消息先存入发件箱中,关注者获取消息时会从发件箱中拉取消息到收件箱中。但这种模式在用户关注大量用户的情况下拉取消息时的延迟较大。
- 推模式:也称作写扩散,被关注者会直接将消息推送到关注者的收件箱中,关注者只需查看收件箱即可。但这种模式在用户被大量用户关注的情况下会发送大量消息,导致内存的大量消耗。适合用户量少,没有大量粉丝的用户的场景。
- 推拉结合模式:根据具体的情况来分配给不同用户不同的模式。对于访问频繁、活跃的用户,对其使用推模式,保证其第一时间获取消息;对于不经常活跃的用户,对其使用拉模式,只有在其登录上线时主动的拉取发件箱的消息到收件箱中。适合用户量庞大,存在拥有大量粉丝的用户的场景。
在了解了上述的三种实现方式的优劣后,选择通过推模式来实现关注推送的功能。而在选择 Redis 中的数据结构来保存消息时,尤其是消息会随着时间不断的更新的情况下,不会选择使用 List 而是使用 SortedSet,因为 List 不支持滚动分页查询,其只支持角标或是首尾查询;而 SortedSet 可以通过分数(score)来排序,支持范围查询和分页查询,更适合处理消息随时间更新的情况。
● 第一步:需要先改造原先的发布博客的部分代码,在发布后将对应博客的 Id 发送给所有粉丝来实现推送。
public Result saveBlog(Blog blog) {// 1.获取登录用户UserDTO user = UserHolder.getUser();blog.setUserId(user.getId());// 2.保存探店博文boolean isSuccess = save(blog);if (!isSuccess){return Result.fail("新增笔记失败");}// 3.查询笔记作者的所有粉丝List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();// 4.推送笔记for (Follow follow : follows) {Long userId = follow.getId();String key = "feed:" + userId;stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMill}// 5.返回idreturn Result.ok(blog.getId());
}首先,获取当前登录用户的 Id 并保存博客信息。接着查询当前用户的所用粉丝信息,循环推送给每一个粉丝。其中 key 为 feed:+ 粉丝 Id 组成,对应每一个粉丝都有一个收件箱,value 为博客的 Id,分数为当前的时间戳,便于在展示时进行排序。
● 第二步:在粉丝查询关注的用户更新的博客时,要实现对于博客内容的分页查询,而由于收件箱中的博客是按照时间来进行排序的,每当有新的内容时,按照角标查询得到的内容可能就会出现重复内容的错误,所以就需要通过分数来进行查询,记录每次查询的最后位置,从该位置继续查询,这样就避免了出现重复内容的错误。
Redis 中的对应指令
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
max:分数的最大值
min:分数的最小值
[WITHSCORES]:可选,查询内容是否带上分数
LIMIT:
offset:偏移量,从小于等于最大值的第 N + 1 个元素开始查。
count:查询的数量
其中,我们只需关注 max 和 offset 这两个参数即可。min 默认为 0,count 按照规定确定。max 是当前查询时的时间戳,之后的查询中为上一次查询的数据中最小的得分;offset 在第一次查询时为 0,之后的查询中为 1,表示跳过上次查询的最后一个数据,同时如果出现查询出来得分相同的数据这种状况时,重复出现 n 次,偏移量(offset)就为 n 次。
@Data
public class ScrollResult {private List<?> list;private Long minTime;private Integer offset;
}
首先,创建一个类来存储用于返回滚动分页查询的数据。
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {//1.获取当前用户Long userId = UserHolder.getUser().getId();//2.查询收件箱String key = FEED_KEY + userId;Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, max, offset, 3);//3.解析数据if (typedTuples == null || typedTuples.isEmpty()){return Result.ok();}List<Long> ids = new ArrayList<>(typedTuples.size());long minTime = 0;int os = 1;for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {ids.add(Long.valueOf(tuple.getValue()));long time = tuple.getScore().longValue();if (time == minTime) {os++;}else {minTime = time;os = 1;}}//4.根据 Id 查询 blogString idStr = StrUtil.join(",", ids);List<Blog> blogs = query().in("id", ids).last("order by field(id," + idStr + ")").list();for (Blog blog : blogs) {//查询笔记状态queryBlogUser(blog);isBlogLiked(blog);}//5.封装并返回ScrollResult r = new ScrollResult();r.setList(blogs);r.setOffset(os);r.setMinTime(minTime);return Result.ok(r);
}传入的两个参数分别对应 Redis 命令中的 max 和 offset,获取到当前用户的 id 与前缀进行拼接后查询收件箱得到对应关注用户的更新博客的 id 集合。判断数据非空后对集合进行处理,主要是将其中的 id 存入新的集合中,并用 os 统计其中具有相同最小时间的数据的个数作为下一次查询的 offset。
接着就是根据博客的 id 从数据库中进行查询得到所有博客,但 MP 中普通的 listById 方法是根据 in 来进行查询的,并不能进行排序,所以需要通过 order by 来排序,其中的 idStr 通过 StrUtil 中的 join 方法拼接后得到。
private void queryBlogUser(Blog blog) {Long userId = blog.getUserId();User user = userService.getById(userId);blog.setName(user.getNickName());blog.setIcon(user.getIcon());
}
private void isBlogLiked(Blog blog) {if (UserHolder.getUser() == null) {//用户未登录时无需查询是否点赞return;}Long userId = UserHolder.getUser().getId();String key = BLOG_LIKED_KEY + blog.getId();Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());blog.setIsLike(score != null);
}最后,所有的博客的需要进行状态的判断,用于在页面中展示正确的信息,判断后将数据分装进先前定义好的实体类中返回。
最终效果如下所示

五、附近商户
1.Redis 中的 GEO 数据结构
GEO 就是 Geolocation 的简写形式,代表地理坐标。Redis 在 3.2 版本中加入了对 GEO 的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
- GEOADD:添加一个地理空间信息,包含:经度(longitude) 、纬度(latitude) 、值(member)
- GEODIST:计算指定的两个点之间的距离并返回
- GEOHASH:将指定 member 的坐标转为hash字符串形式并返回
- GEOPOS:返回指定 member 的坐标
- GEORADIUS:指定圆心、半径,找到该圆内包含的所有 member,并按照与圆心之间的距离排序后返回。
- GEOSEARCH:在指定范围内搜索 member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。
- GEOSEARCHSTORE:与 GEOSEARCH 功能一致,不过可以把结果存储到一个指定的 key。
利用 Redis 中 GEO 这种数据结构,可以简单的实现查询附近商铺这种与地理位置信息有关的需求,并且可以根据用户当前位置获取附近商铺的信息。
2.附近商户搜索

在原先的页面中查看商铺时选择根据距离进行查询时就需要根据地理位置来进行搜索,并在每个商铺右边显示出相距的距离大小,我们可以使用 Redis 中的 GEO 来十分简单的实现这个功能。
@Test
void loadShopData() {//1.查询店铺信息List<Shop> list = shopService.list();//2.根据类型分组,得到类型id与店铺的映射关系(stream流)Map<Long, List<Shop>> map = list.stream().collect(Collectors.groupingBy(Shop::getTypeId));for (Map.Entry<Long, List<Shop>> entry : map.entrySet()) {Long typeId = entry.getKey();String key = "shop:geo:" + typeId;List<Shop> value = entry.getValue();List<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>(value.size());//3.写入redisfor (Shop shop : value) {locations.add(new RedisGeoCommands.GeoLocation<>(shop.getId().toString(),new Point(shop.getX(), shop.getY())));}stringRedisTemplate.opsForGeo().add(key, locations);}
}而我们需要先将数据库中商铺的信息存入 Redis 中,并且根据商铺的类型(typeId)分别进行存储,这样在查询时也避免了需要先分类再进行查询,直接按照类型进行查询即可。
(注意:因为版本的问题,Redis 中 GEO 类型的一些命令是 6.2 版本后提供的,所以需要保证 SpringBoot 中 SpringDataRedis 的版本支持这些命令)
@Override
public Result queryShopByTypeId(Integer typeId, Integer current, Double x, Double y) {// 检查输入坐标是否为null,如果是,则执行类型分页查询if (x == null || y == null){// 根据类型分页查询Page<Shop> page = query().eq("type_id", typeId).page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));// 返回数据return Result.ok(page.getRecords());}// 计算查询的起始和结束范围int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE;int end = current * SystemConstants.DEFAULT_PAGE_SIZE;...在 Impl 层中,首先对传入的坐标进行判断,不为空则接着计算分页的参数。
...
// 拼接Redis地理信息键名String key = SHOP_GEO_KEY + typeId;// 使用Redis地理信息命令,查询指定坐标附近的商店GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo().search(key,GeoReference.fromCoordinate(new Point(x, y)),new Distance(5000),RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end));// 如果查询结果为空,返回空列表if (results == null){return Result.ok(Collections.emptyList());}List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent();// 检查结果列表是否足够覆盖查询的起始范围if (list.size() <= from){return Result.ok(Collections.emptyList());}
...接着,将商铺类型 id 与前缀进行拼接后进行查询得到地理位置信息,其中 Distance 表示查询的范围。对得到的结果进行非空判断,然后检查结果是否小于起始值,因为这个分页查询是先查询出总数据后按照范围取出数据展示,如果起始值大于总数,则会造成程序出错。
...// 初始化商店ID列表和距离映射List<Long> ids = new ArrayList<>(list.size());Map<String, Distance> distanceMap = new HashMap<>(list.size());// 遍历结果列表,提取商店ID和距离信息list.stream().skip(from).forEach(result -> {String shopIdStr = result.getContent().getName();ids.add(Long.valueOf(shopIdStr));Distance distance = result.getDistance();distanceMap.put(shopIdStr, distance);});String idStr = StrUtil.join(",", ids);// 根据商店ID查询商店信息List<Shop> shops = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();// 为每个商店设置距离信息for (Shop shop : shops) {shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());}// 返回return Result.ok(shops);
}最后将商店 Id 列表和距离初始化后遍历查询结果并将其存入先前初始化好的列表中。再利用 query 方法根据商铺 Id 查询商铺信息,最后将数据返回即可。
最终效果如下所示

六、用户签到
1.BitMap
签到功能作为一个耳熟能详的功能常常出现在一些游戏和软件中,作为其中的常客,其主要是通过一些签到奖励来激励用户登录。使用数据库实现时其每个用户每天的签到情况会产生大量的数据,而在 Redis 中可以使用 String 类型来实现 BitMap(位图)这种思路,来简单的存储用户的签到信息。

通过上面的结构,我们可以简单的用少量的内存存储大量的签到信息。、
BitMap的操作命令有:
- SETBIT:向指定位置(offset)存入一个 0 或 1
- GETBIT:获取指定位置(offset)的 bit 值
- BITCOUNT:统计 BitMap 中值为 1 的 bit 位的数量
- BITFIELD:操作(查询、修改、自增) BitMap 中 bit 数组中的指定位置(offset)的值
- BITFIELD_RO:获取 BitMap 中 bit 数组,并以十进制形式返回
- BITOP:将多个 BitMap 的结果做位运算(与、或、异或)
- BITPOS:查找 bit 数组中指定范围内第一个 0 或 1 出现的位置
其中用到的主要是 SETBIT 和 BITFIELD。
SETBIT:

操作如上图所示,需要注意需要选择 Binary 才能看到对应的格式。
BITFIELD:
![]()
其中 type 表示获取的数量,offset 表示从第几个开始。
2.实现签到功能
通过 Redis 来实现签到功能,不需要任何参数,只需通过用户 Id 与当前时间进行拼接后作为 key 来存储即可。
public Result sign() {//1.获取当前登录用户Long userId = UserHolder.getUser().getId();//2.获取日期LocalDateTime now = LocalDateTime.now();//3.拼接 KeyString keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));String key = USER_SIGN_KEY + userId + keySuffix;//4.获取今天是本月的第几天int dayOfMonth = now.getDayOfMonth();//5.写入 RedisstringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);return Result.ok();
}首先获取当前登录用户的 Id 以及当前时间。拼接后再获取今天是本月的第几天,用于确定在 BitMap 中签到的位置,且注意 getDayOfMonth 方法获取的数是从 1 开始的,而 BitMap 的下标是从 0 开始的,所以方法结果需要 - 1 后再写入。
最终效果如下所示
发送签到请求后成功的写入到了 Redis 中。注意需要在请求头中添加 authorization 参数否则请求会失败。

3.统计连续签到次数
· 想要统计从本月开始到今天为止的连续签到次数,就需要先先获取本月到今天为止的所有签到信息,然后遍历信息,统计连续签到的次数。其中,可以使用位运算来实现遍历功能,完成连续签到次数的统计。
public Result signCount() {//1.获取当前登录用户Long userId = UserHolder.getUser().getId();//2.获取日期LocalDateTime now = LocalDateTime.now();//3.拼接 KeyString keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));String key = USER_SIGN_KEY + userId + keySuffix;//4.获取今天是本月的第几天int dayOfMonth = now.getDayOfMonth();List<Long> result = stringRedisTemplate.opsForValue().bitField(key,BitFieldSubCommands.create().get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0));...首先还是获取到当前登录的用户 Id 和当前时间,拼接后查询从本月的第一天到今天的所有签到信息。其中 bitField 中包含两个参数,一个是 key,一个是子命令。子命令中设置范围。
...if (result == null || result.isEmpty()){return Result.ok(0);}Long num = result.get(0);if (num == null){return Result.ok(0);}int count = 0;while(true){if((num & 1) == 0) {//为 0 未签到,结束break;}else {//不为 0 已签到,计数器++count++;}//将数字无符号右移一位抛弃最后一个 bit 位num >>>= 1;}return Result.ok(count);
}之后对查询得到的数据进行非空校验,通过后开始遍历。与 1 进行与运算获取最后一位并对其进行判断,为 0 则直接退出循环,不为 0 则计数后将数字右移移除最后一位数继续循环。结束统计后直接返回计数结果。
最终效果如下所示
测试后可以看到成功统计出了本月的连续签到次数。

七、UV 统计
首先,需要了解什么是 UV:
- UV:全称 Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
- PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
想要统计这种大量的数据,就需要使用到 Redis 中的 HyperLogLog 了。其基于 String 类型实现,其占用的内存极小,而代价就是其测量的结果是概率性的,但对于 UV 统计这种大数据量来说误差是可以忽略的。

根据上图可知,HyperLogLog 不会将重复的内容统计。
(后续的测试 o(´^`)o跳过)
【下】完结
传送门(上):Redis 实战篇 ——《黑马点评》(上)
传送门(中):Redis 实战篇 ——《黑马点评》(中)
相关文章:
Redis 实战篇 ——《黑马点评》(下)
《引言》 (下)篇将记录 Redis 实战篇 最后的一些学习内容,希望大家能够点赞、收藏支持一下 Thanks♪ (・ω・)ノ,谢谢大家。 传送门(上):Redis 实战篇 ——《黑马…...

蓝桥杯自我复习打卡
总复习,打卡1. 一。排序 1。选段排序 太可恶了,直接全排输出,一个测试点都没过。 AC 首先,这个【l,r】区间一定要包含p,或者q,pq一个都不包含的,[l,r]区间无论怎么变,都对ans没有影响。 其次&…...
与过滤器(Filter)详细教程)
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程 目录 概述 什么是拦截器(Interceptor)?什么是过滤器(Filter)?两者的核心区别 使用场景 拦截器的典…...

Java零基础入门笔记:(6)面向对象
前言 本笔记是学习狂神的java教程,建议配合视频,学习体验更佳。 【狂神说Java】Java零基础学习视频通俗易懂_哔哩哔哩_bilibili 第1-2章:Java零基础入门笔记:(1-2)入门(简介、基础知识)-CSDN博客 第3章…...
【3天快速入门WPF】13-MVVM进阶
目录 1. 窗体设置2. 字体图标3. 控件模板4. 页面逻辑4.1. 不使用MVVM4.2. MVVM模式实现本篇我们开发一个基于MVVM的登录页面,用来回顾下之前学习的内容 登录页面如下: 窗体取消了默认的标题栏,调整为带阴影的圆角窗体,左侧放一张登录背景图,右边自绘了一个关闭按钮,文本框…...

【MongoDB】在Windows11下安装与使用
官网下载链接:Download MongoDB Community Server 官方参考文档:https://www.mongodb.com/zh-cn/docs/manual/tutorial/install-mongodb-on-windows/#std-label-install-mdb-community-windows 选择custom类型,其他默认 注意,此选…...

Kotlin 5种单例模式
在Kotlin中实现单例模式有多种方法,以下是几种常见的方法: 饿汉式 饿汉式是最简单的一种实现方式,在类加载时就完成了实例的初始化。 //饿汉式 object Singleton1 {fun printMessage() {println("饿汉式")} }懒汉式 懒汉式是延迟…...

C语言复习5:字符串的定义,字符串的常用函数
## 字符串变量的定义方式 - 在C语言中,没有单独的字符串变量,但可以利用字符数组来存字符串 - 占位符:%s - 定义1: 数据类型 变量名[内存占用大小] "字符串"; eg: char s…...

【Multipath网络层协议】MPTCP工作原理
常见网络层多路径协议介绍 MPTCP(Multipath TCP) MPTCP 是在传统 TCP 基础上进行扩展的协议,它允许在源端和目的端之间建立多个 TCP子流,这些子流可以通过不同的网络路径传输数据。 例如,一台笔记本电脑同时连接了 W…...

deepseek使用记录18——文化基因美食篇
子篇:薪火相传的味觉辩证法——从燧人氏到预制菜的文化突围 一、石器时代的启蒙:食物探索中的原始辩证法 在贾湖遗址的陶罐残片上,碳化稻米与蜂蜜的结晶层相互交叠,这是9000年前先民对"甘"与"饱"的首次辩证…...

2025学年安徽省职业院校技能大赛 “信息安全管理与评估”赛项 比赛样题任务书
2024-2025 学年广东省职业院校技能大赛 “信息安全管理与评估”赛项 技能测试试卷(五) 第一部分:网络平台搭建与设备安全防护任务书第二部分:网络安全事件响应、数字取证调查、应用程序安全任务书任务1 :内存取证&…...
在 Ansys Maxwell 中分析磁场
在 Ansys Maxwell 中分析磁场 分析磁场的能力对于理解电磁系统至关重要。Ansys Maxwell 为工程师提供了强大的工具,帮助他们探索磁场数据并从中提取有价值的见解。在本指南中,我将深入研究 Ansys Maxwell 中的几种基本技术和方法,以有效地分…...

springboot项目Maven打包遇到的问题总结
java -jar 执行报错中没有主清单属性 Spring Boot的可执行JAR需要依赖该插件生成正确的主清单属性。在 pom.xml 的 部分添加以下配置: <build><plugins><!-- 必须配置此插件才能生成可执行的Spring Boot JAR --><plugin><groupId>o…...
DeepSeek FlashMLA:用技术创新破解大模型落地难题
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 DeepSeek大模型技术系列十四DeepSeek大模型技术系列十四》DeepS…...

[补充]原码、反、补、移码的转换
近期在学习Java的类型转换的知识,强制类型转换的时候会遇到数据(丢失)溢出的问题。 最后在IDEA控制台输出的时候,出现了负数。了解了一下强制类型转换在计算机中的原理,随后就复习了一下原码、反、补、移码的转换的知…...

Hue 编译异常:ImportError: cannot import name ‘six‘ from ‘urllib3.packages‘
个人博客地址:Hue 编译异常:ImportError: cannot import name six from urllib3.packages | 一张假钞的真实世界 在编译Hue的时候出现错误信息如下: Running /home/zhangjc/ysten/git/ysten-hue/build/env/bin/hue makemigrations --noinpu…...
)
【Maven】将普通Eclipse项目改造为Maven项目(非SpringBoot项目)
文章目录 将普通Eclipse项目改造为Maven项目(非SpringBoot项目)Maven安装与配置项目结构改造父子Pom.xml文件配置(继承与集成)父项目下的pom.xml文件配置普通子模块下的pom.xml配置启动模块的pom.xml配置 多模块编译总结 Maven插件…...
安装Node.js
1.打开官网,下载安装包 2.安装过程中,全部默认,next. 3.在安装根目录下,新建两个文件夹【node_cache】和【node_global】 4.检测是否安装成功 打开控制台,node -v, npm -v, 显示版本号。 5.配置环境变量 1>从no…...

物联网同RFID功能形态 使用场景的替代品
在物联网(IoT)和自动识别技术领域,除了RFID标签外,还有一些其他技术产品可以在形态和大小上与RFID标签相似,同时提供类似或更强大的功能。以下是几种能够替代RFID标签的产品: 一、NFC标签 NFC(…...

【力扣】堆相关总结
priority_queue std::priority_queue 是 C 标准库中的一个容器适配器,提供了堆(Heap)数据结构的功能。它通常用于实现优先队列,允许你高效地插入元素和访问最大或最小元素。 头文件 #include <queue> 基本定义 std::pri…...

【前端基础】3、HTML的常用元素(h、p、img、a、iframe、div、span)、不常用元素(strong、i、code、br)
HTML结构 一个HTML包含以下部分: 文档类型声明html元素 head元素body元素 例(CSDN): 一、文档类型声明 HTML最一方的文档称为:文档类型声明,用于声明文档类型。即:<!DOCTYPE html>…...
【漫话机器学习系列】113.逻辑回归(Logistic Regression) VS 线性回归(Linear Regression)
逻辑回归 vs 线性回归:详解对比 在机器学习和统计学中,逻辑回归(Logistic Regression) 和 线性回归(Linear Regression) 都是非常常见的模型。尽管它们的数学表达式有一定的相似性,但它们的应用…...

3 算法1-3 回文质数
题目描述 因为 151 既是一个质数又是一个回文数(从左到右和从右到左是看一样的),所以 151 是回文质数。 写一个程序来找出范围 [a,b](5≤a<b≤100,000,000)(一亿)间的所有回文质数。 输入格式 第一行输入两个正…...

Redis---缓存穿透,雪崩,击穿
文章目录 缓存穿透什么是缓存穿透?缓存穿透情况的处理流程是怎样的?缓存穿透的解决办法缓存无效 key布隆过滤器 缓存雪崩什么是缓存雪崩?缓存雪崩的解决办法 缓存击穿什么是缓存击穿?缓存击穿的解决办法 区别对比 在如今的开发中&…...

联合省选 2025 游记
Day 1 不会 LCT,不会字符串,不会博弈 快进到考场 t 1 t1 t1 很快想到枚举中位数再 check,然后就会了,思路很清晰写的很快 t 2 t2 t2 干想 1h 编出来 n m 2 3 nm^{\frac{2}{3}} nm32,然后认为 t 3 t3 t3 会和去年…...

Skywalking介绍,Skywalking 9.4 安装,SpringBoot集成Skywalking
一.Skywalking介绍 Apache SkyWalking是一个开源的分布式追踪与性能监视平台,特别适用于微服务架构、云原生环境以及基于容器(如Docker、Kubernetes)的应用部署。该项目由吴晟发起,并已加入Apache软件基金会的孵化器,…...
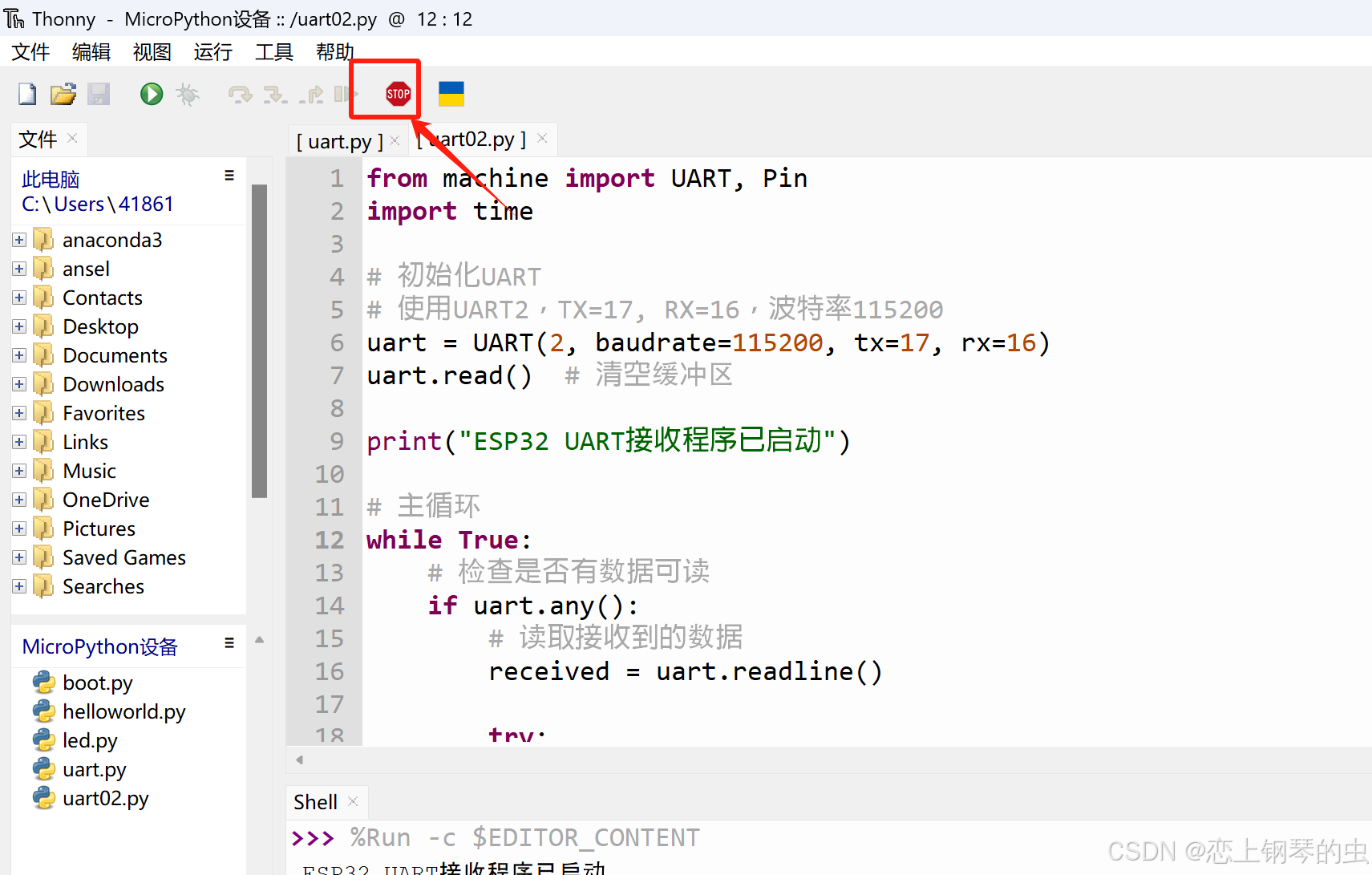
Thonny+MicroPython+ESP32开发环境搭建
1、下载&安装Thonny 安装成功后,会在桌面生成快捷键 双击快捷键,打开程序,界面如下 2、下载MicroPython 下载地址:MicroPython - Python for microcontrollers v1.19版(推荐,此版本稳定): https://do…...

数据结构:反射 和 枚举
目录 一、反射 1、定义 2、反射相关的类 3、Class类 (2)常用获得类中属性相关的方法: (3)获得类中注解相关的方法: (4)获得类中构造器相关的方法: (…...

前缀和算法 算法4
算法题中帮助复习的知识 vector<int > dp( n ,k); n为数组大小 ,k为初始化 哈希表unordered_map<int ,int > hash; hash.find(k)返回值是迭代器 ,找到k返回其迭代器 没找到返回hash.end() hash.count(k)返回值是数字 ,找到k返回1 ,没找到返回0. C和java中 负数…...
USRP7440-通用软件无线电平台
1、产品描述 USRP7440基于第三代XILINX Zynq UltraScale RFSoC架构,它将射频ADC、DAC、ARM、FPGA等集成一体,瞬时带宽可以达到2.5GHz,尤其适合于射频直采应用,比如通信与雷达。 第一代RFSOC高达4GHz • 8x 或 16x 6.554GSPS DAC…...