【领域】百度OCR识别
一、定义
OCR(Optical Character Recognition,光学字符识别)是计算机视觉重要方向之一。传统定义的OCR一般面向扫描文档类对象,现在我们常说的OCR一般指场景文字识别(Scene Text Recognition,STR),主要面向自然场景。
二、特性
支持多种 OCR 相关前沿算法,在此基础上打造产业级特色模型PP-OCR、PP-Structure和PP-ChatOCRv2,并打通数据生产、模型训练、压缩、预测部署全流程。

三、任务
- 文本检测
- 文本识别
- 端到端文本识别
- 文档分析
PPOCR主要应用于图片中的文字、数字识别,PPstru主要适用于文档级别的页面识别
四、模型
PP-OCR中英文模型
定义
除输入输出外,PP-OCR核心框架包含了3个模块,分别是:文本检测模块、检测框矫正模块、文本识别模块。
- 文本检测模块:核心是一个基于DB检测算法训练的文本检测模型,检测出图像中的文字区域
- 检测框矫正模块:将检测到的文本框输入检测框矫正模块,在这一阶段,将四点表示的文本框矫正为矩形框,方便后续进行文本识别,另一方面会进行文本方向判断和校正,例如如果判断文本行是倒立的情况,则会进行转正,该功能通过训练一个文本方向分类器实现
- 文本识别模块:最后文本识别模块对矫正后的检测框进行文本识别,得到每个文本框内的文字内容,PP-OCR中使用的经典文本识别算法CRNN
PP-OCR模型分为mobile版(轻量版)和server版(通用版),其中mobile版模型主要基于轻量级骨干网络MobileNetV3进行优化,优化后模型(检测模型+文本方向分类模型+识别模型)大小仅8.1M,CPU上平均单张图像预测耗时350ms,T4 GPU上约110ms,裁剪量化后,可在精度不变的情况下进一步压缩到3.5M,便于端侧部署,在骁龙855上测试预测耗时仅260ms。更多的PP-OCR评估数据可参考benchmark。
代码使用
中英文与多语言使用
通过Python脚本使用PaddleOCR whl包,whl包会自动下载ppocr轻量级模型作为默认模型。
检测+方向分类器+识别全流程:
from paddleocr import PaddleOCR, draw_ocr# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):res = result[idx]for line in res:print(line)# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
如果输入是PDF文件,那么可以参考下面代码进行可视化:
from paddleocr import PaddleOCR, draw_ocr# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
PAGE_NUM = 10 # 将识别页码前置作为全局,防止后续打开pdf的参数和前文识别参数不一致 / Set the recognition page number
pdf_path = 'default.pdf'
ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=PAGE_NUM) # need to run only once to download and load model into memory
# ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=PAGE_NUM,use_gpu=0) # 如果需要使用GPU,请取消此行的注释 并注释上一行 / To Use GPU,uncomment this line and comment the above one.
result = ocr.ocr(pdf_path, cls=True)
for idx in range(len(result)):res = result[idx]if res == None: # 识别到空页就跳过,防止程序报错 / Skip when empty result detected to avoid TypeError:NoneTypeprint(f"[DEBUG] Empty page {idx+1} detected, skip it.")continuefor line in res:print(line)
# 显示结果
import fitz
from PIL import Image
import cv2
import numpy as np
imgs = []
with fitz.open(pdf_path) as pdf:for pg in range(0, PAGE_NUM):page = pdf[pg]mat = fitz.Matrix(2, 2)pm = page.get_pixmap(matrix=mat, alpha=False)# if width or height > 2000 pixels, don't enlarge the imageif pm.width > 2000 or pm.height > 2000:pm = page.get_pixmap(matrix=fitz.Matrix(1, 1), alpha=False)img = Image.frombytes("RGB", [pm.width, pm.height], pm.samples)img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)imgs.append(img)
for idx in range(len(result)):res = result[idx]if res == None:continueimage = imgs[idx]boxes = [line[0] for line in res]txts = [line[1][0] for line in res]scores = [line[1][1] for line in res]im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')im_show = Image.fromarray(im_show)im_show.save('result_page_{}.jpg'.format(idx))
要使用滑动窗口进行光学字符识别(OCR),可以使用以下代码片段:
from paddleocr import PaddleOCR
from PIL import Image, ImageDraw, ImageFont# 初始化OCR引擎
ocr = PaddleOCR(use_angle_cls=True, lang="en")img_path = "./very_large_image.jpg"
slice = {'horizontal_stride': 300, 'vertical_stride': 500, 'merge_x_thres': 50, 'merge_y_thres': 35}
results = ocr.ocr(img_path, cls=True, slice=slice)# 加载图像
image = Image.open(img_path).convert("RGB")
draw = ImageDraw.Draw(image)
font = ImageFont.truetype("./doc/fonts/simfang.ttf", size=20) # 根据需要调整大小# 处理并绘制结果
for res in results:for line in res:box = [tuple(point) for point in line[0]]# 找出边界框box = [(min(point[0] for point in box), min(point[1] for point in box)),(max(point[0] for point in box), max(point[1] for point in box))]txt = line[1][0]draw.rectangle(box, outline="red", width=2) # 绘制矩形draw.text((box[0][0], box[0][1] - 25), txt, fill="blue", font=font) # 在矩形上方绘制文本# 保存结果
image.save("result.jpg")PP-Structure文档分析模型
定义
PP-Structure支持版面分析(layout analysis)、表格识别(table recognition)、文档视觉问答(DocVQA)三种子任务。
PP-Structure核心功能点如下:
- 支持对图片形式的文档进行版面分析,可以划分文字、标题、表格、图片以及列表5类区域(与Layout-Parser联合使用)
- 支持文字、标题、图片以及列表区域提取为文字字段(与PP-OCR联合使用)
- 支持表格区域进行结构化分析,最终结果输出Excel文件
- 支持Python whl包和命令行两种方式,简单易用
- 支持版面分析和表格结构化两类任务自定义训练
- 支持VQA任务-SER和RE
代码使用
图像方向分类+版面分析+表格识别
import os
import cv2
from paddleocr import PPStructure,draw_structure_result,save_structure_restable_engine = PPStructure(show_log=True, image_orientation=True)save_folder = './output'
img_path = 'ppstructure/docs/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])for line in result:line.pop('img')print(line)from PIL import Imagefont_path = 'doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result,font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
相关文章:
【领域】百度OCR识别
一、定义 OCR(Optical Character Recognition,光学字符识别)是计算机视觉重要方向之一。传统定义的OCR一般面向扫描文档类对象,现在我们常说的OCR一般指场景文字识别(Scene Text Recognition,STRÿ…...

Docker 学习(一)
一、Docker 核心概念 Docker 是一个开源的容器化平台,允许开发者将应用及其所有依赖(代码、运行时、系统工具、库等)打包成一个轻量级、可移植的“容器”,实现 “一次构建,随处运行”。 1、容器(Container…...
学习建议)
15. C++多线程编程-网络编程-GUI编程(如Qt)学习建议
1. 多线程编程 多线程编程允许程序同时执行多个任务,从而提高性能和响应速度。多线程常用于处理并发任务、提高CPU利用率、优化I/O操作等。 学习内容: 线程与进程的区别:理解线程和进程的基本概念及其区别。 线程的创建与管理:…...

【vscode-解决方案】vscode 无法登录远程服务器的两种解决办法
解决方案一: 查找原因 命令 ps ajx | grep vscode 可能会看到一下这堆信息(如果没有大概率不是这个原因导致) 这堆信息的含义:当你使用 vscode 远程登录服务器时,我们远程机器服务端要给你启动一个叫做 vscode serv…...

5个GitHub热点开源项目!!
1.自托管 Moonlight 游戏串流服务:Sunshine 主语言:C,Star:14.4k,周增长:500 这是一个自托管的 Moonlight 游戏串流服务器端项目,支持所有 Moonlight 客户端。用户可以在自己电脑上搭建一个游戏…...

化学工业领域 - 基础化工、精细化工、煤化工极简理解
引入 基础化工、精细化工和煤化工是化学工业中的三个重要分支 它们在原料、产品、工艺、应用方面各有特点 一、基础化工(Basic Chemical Industry) 1、基本介绍 基础化工是指以石油、天然气、煤炭等为原料,生产大宗化学品和基础化学原料的…...

慢sql治理
一、慢SQL的定义与影响 慢SQL通常指的是执行时间超过合理阈值的SQL语句。这个阈值可以根据系统的实际情况进行设定,例如1秒或更长。慢SQL会导致系统响应时间延迟、资源占用增加、数据库连接池被占满、锁竞争增加等一系列问题,严重影响系统的稳定性和用户…...

基于SpringBoot的美妆购物网站系统设计与实现现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

计算机毕业设计Hadoop+Spark+DeepSeek-R1大模型音乐推荐系统 音乐数据分析 音乐可视化 音乐爬虫 知识图谱 大数据毕业设计
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

mysql5.7离线安装及问题解决
这次主要是讲解mysql5.7离线安装教程和一主一从数据库配置 1、去官网下载自己对应的mysql https://downloads.mysql.com/archives/community/2、查看需要安装mysql服务器的linux的类型 uname -a第二步看一下系统有没有安装mysql rpm -qa|grep -i mysql3、上传安装包 用远程…...

Matlab 大量接单
分享一个matlab接私活、兼职的平台 1、技术方向满足任一即可 2、技术要求 3、最后 技术方向满足即可 MATLAB:熟练掌握MATLAB编程语言,能够使用MATLAB进行数据处理、机器学习和深度学习等相关工作。 机器学习、深度学习、强化学习、仿真、复现、算法、…...
)
C++数据结构之数组(详解)
1.介绍 在C中,数组是一种基本的数据结构,用于存储相同类型的元素的集合。数组的元素在内存中是连续存储的,可以通过索引访问。下面将详细介绍C数组的相关内容。 2.数组的定义 数组的定义需要指定元素的类型和数组的大小。 type arrayName[a…...

AWS API Gateway灰度验证实现
在微服务架构中,灰度发布(金丝雀发布)是验证新版本稳定性的核心手段。通过将小部分流量(如 10%)导向新版本服务,可以在不影响整体系统的情况下快速发现问题。AWS API Gateway 原生支持流量按比例分配功能,无需复杂编码即可实现灰度验证。本文将详细解析其实现方法、最佳…...

【Elasticsearch】Elasticsearch 的`path.settings`是用于配置 Elasticsearch 数据和日志存储路径的重要设置
Elasticsearch 的path.settings是用于配置 Elasticsearch 数据和日志存储路径的重要设置,这些路径在elasticsearch.yml配置文件中定义。以下是关于 Elasticsearch 的路径设置(path.data和path.logs)以及快照存储库配置的详细说明:…...

Redis 实战篇 ——《黑马点评》(下)
《引言》 (下)篇将记录 Redis 实战篇 最后的一些学习内容,希望大家能够点赞、收藏支持一下 Thanks♪ (・ω・)ノ,谢谢大家。 传送门(上):Redis 实战篇 ——《黑马…...

蓝桥杯自我复习打卡
总复习,打卡1. 一。排序 1。选段排序 太可恶了,直接全排输出,一个测试点都没过。 AC 首先,这个【l,r】区间一定要包含p,或者q,pq一个都不包含的,[l,r]区间无论怎么变,都对ans没有影响。 其次&…...
与过滤器(Filter)详细教程)
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程 目录 概述 什么是拦截器(Interceptor)?什么是过滤器(Filter)?两者的核心区别 使用场景 拦截器的典…...

Java零基础入门笔记:(6)面向对象
前言 本笔记是学习狂神的java教程,建议配合视频,学习体验更佳。 【狂神说Java】Java零基础学习视频通俗易懂_哔哩哔哩_bilibili 第1-2章:Java零基础入门笔记:(1-2)入门(简介、基础知识)-CSDN博客 第3章…...
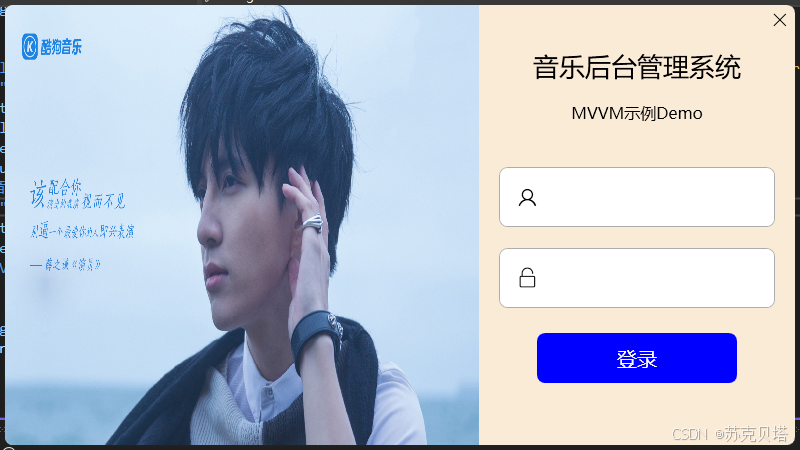
【3天快速入门WPF】13-MVVM进阶
目录 1. 窗体设置2. 字体图标3. 控件模板4. 页面逻辑4.1. 不使用MVVM4.2. MVVM模式实现本篇我们开发一个基于MVVM的登录页面,用来回顾下之前学习的内容 登录页面如下: 窗体取消了默认的标题栏,调整为带阴影的圆角窗体,左侧放一张登录背景图,右边自绘了一个关闭按钮,文本框…...

【MongoDB】在Windows11下安装与使用
官网下载链接:Download MongoDB Community Server 官方参考文档:https://www.mongodb.com/zh-cn/docs/manual/tutorial/install-mongodb-on-windows/#std-label-install-mdb-community-windows 选择custom类型,其他默认 注意,此选…...

Kotlin 5种单例模式
在Kotlin中实现单例模式有多种方法,以下是几种常见的方法: 饿汉式 饿汉式是最简单的一种实现方式,在类加载时就完成了实例的初始化。 //饿汉式 object Singleton1 {fun printMessage() {println("饿汉式")} }懒汉式 懒汉式是延迟…...

C语言复习5:字符串的定义,字符串的常用函数
## 字符串变量的定义方式 - 在C语言中,没有单独的字符串变量,但可以利用字符数组来存字符串 - 占位符:%s - 定义1: 数据类型 变量名[内存占用大小] "字符串"; eg: char s…...

【Multipath网络层协议】MPTCP工作原理
常见网络层多路径协议介绍 MPTCP(Multipath TCP) MPTCP 是在传统 TCP 基础上进行扩展的协议,它允许在源端和目的端之间建立多个 TCP子流,这些子流可以通过不同的网络路径传输数据。 例如,一台笔记本电脑同时连接了 W…...

deepseek使用记录18——文化基因美食篇
子篇:薪火相传的味觉辩证法——从燧人氏到预制菜的文化突围 一、石器时代的启蒙:食物探索中的原始辩证法 在贾湖遗址的陶罐残片上,碳化稻米与蜂蜜的结晶层相互交叠,这是9000年前先民对"甘"与"饱"的首次辩证…...

2025学年安徽省职业院校技能大赛 “信息安全管理与评估”赛项 比赛样题任务书
2024-2025 学年广东省职业院校技能大赛 “信息安全管理与评估”赛项 技能测试试卷(五) 第一部分:网络平台搭建与设备安全防护任务书第二部分:网络安全事件响应、数字取证调查、应用程序安全任务书任务1 :内存取证&…...
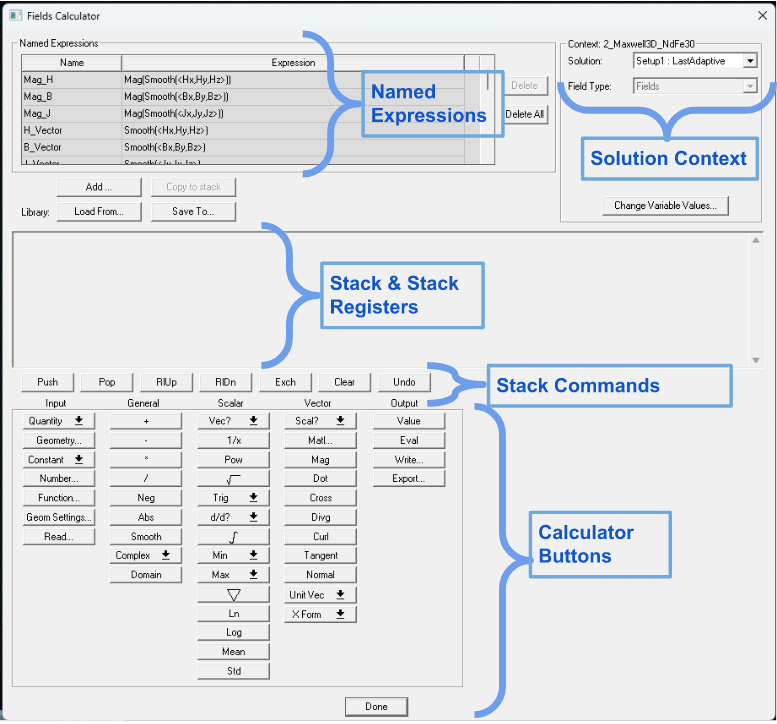
在 Ansys Maxwell 中分析磁场
在 Ansys Maxwell 中分析磁场 分析磁场的能力对于理解电磁系统至关重要。Ansys Maxwell 为工程师提供了强大的工具,帮助他们探索磁场数据并从中提取有价值的见解。在本指南中,我将深入研究 Ansys Maxwell 中的几种基本技术和方法,以有效地分…...

springboot项目Maven打包遇到的问题总结
java -jar 执行报错中没有主清单属性 Spring Boot的可执行JAR需要依赖该插件生成正确的主清单属性。在 pom.xml 的 部分添加以下配置: <build><plugins><!-- 必须配置此插件才能生成可执行的Spring Boot JAR --><plugin><groupId>o…...
DeepSeek FlashMLA:用技术创新破解大模型落地难题
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 DeepSeek大模型技术系列十四DeepSeek大模型技术系列十四》DeepS…...

[补充]原码、反、补、移码的转换
近期在学习Java的类型转换的知识,强制类型转换的时候会遇到数据(丢失)溢出的问题。 最后在IDEA控制台输出的时候,出现了负数。了解了一下强制类型转换在计算机中的原理,随后就复习了一下原码、反、补、移码的转换的知…...

Hue 编译异常:ImportError: cannot import name ‘six‘ from ‘urllib3.packages‘
个人博客地址:Hue 编译异常:ImportError: cannot import name six from urllib3.packages | 一张假钞的真实世界 在编译Hue的时候出现错误信息如下: Running /home/zhangjc/ysten/git/ysten-hue/build/env/bin/hue makemigrations --noinpu…...