【Elasticsearch】Elasticsearch 的`path.settings`是用于配置 Elasticsearch 数据和日志存储路径的重要设置
Elasticsearch 的`path.settings`是用于配置 Elasticsearch 数据和日志存储路径的重要设置,这些路径在`elasticsearch.yml`配置文件中定义。以下是关于 Elasticsearch 的路径设置(`path.data`和`path.logs`)以及快照存储库配置的详细说明:
1.`path.data`配置
`path.data`是 Elasticsearch 用于存储索引数据和集群状态的目录。默认情况下,Elasticsearch 将数据存储在`$ES_HOME/data`目录下。
多路径配置
在 7.13 版本之前,Elasticsearch 支持在`path.data`中配置多个路径,允许将数据分散存储到多个磁盘上。例如:
```yaml
path.data: /mnt/disk1,/mnt/disk2,/mnt/disk3
```
这种配置类似于软件级的 RAID-0,可以提高 I/O 性能。然而,Elasticsearch 不会在多个路径之间自动平衡分片的存储,且单个路径的高磁盘使用率可能触发整个节点的高磁盘水位线。
官方建议
从 7.13 版本开始,多路径支持已被弃用,官方建议使用单路径配置,并通过添加新节点来扩展存储容量。
2.`path.logs`配置
`path.logs`是 Elasticsearch 用于存储日志文件的目录。默认情况下,日志存储在`$ES_HOME/logs`目录下。您可以根据需要修改此路径,例如:
```yaml
path.logs: /var/log/elasticsearch
```
3.快照存储库配置
快照存储库是用于存储快照数据的路径或存储服务。在创建快照之前,必须先定义一个存储库。
配置存储库
在`elasticsearch.yml`文件中,通过`path.repo`指定快照存储库的路径。例如:
```yaml
path.repo: ["/data/es_snapshot"]
```
然后,通过 API 创建存储库:
```bash
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/data/es_snapshot"
}
}
```
• `type`:存储库类型,`fs`表示本地文件系统。
• `location`:快照数据的存储路径。
创建快照
定义存储库后,可以通过以下命令创建快照:
```bash
PUT /_snapshot/my_backup/snapshot_1
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": false
}
```
4.注意事项
• 数据安全性:多路径配置类似于软件级 RAID-0,没有数据冗余。如果其中一个磁盘故障,存储在该磁盘上的分片数据将丢失。
• 快照存储库权限:确保 Elasticsearch 有权限访问`path.repo`指定的路径。
• 滚动重启:修改`elasticsearch.yml`文件后,需要滚动重启集群以使配置生效。
通过合理配置`path.data`和`path.logs`,以及设置快照存储库,可以优化 Elasticsearch 的数据存储和备份策略,提高集群的性能和可靠性。Elasticsearch 的 path.settings 是用于配置 Elasticsearch 数据和日志存储路径的重要设置。这些设置在 elasticsearch.yml 配置文件中定义,用于指定 Elasticsearch 数据和日志文件的存储位置。以下是关于 Elasticsearch path.settings 的详细说明:1. 默认路径在 Elasticsearch 的默认安装中, data 和 logs 目录通常位于 $ES_HOME 目录下。 $ES_HOME 是 Elasticsearch 的安装根目录。例如: data 目录:存储 Elasticsearch 的索引数据和集群状态信息。 logs 目录:存储应用程序日志,包括集群健康信息、操作日志等。然而,这种默认设置在生产环境中并不推荐,因为 $ES_HOME 目录中的文件可能会在升级过程中被覆盖或删除。2. 推荐的路径设置为了提高数据安全性和灵活性,Elasticsearch 官方建议在生产环境中将 path.data 和 path.logs 配置为 $ES_HOME 之外的路径。例如:yaml复制path:
data: /var/data/elasticsearch
logs: /var/log/elasticsearch
path.data :指定存储 Elasticsearch 数据的目录。 path.logs :指定存储日志文件的目录。通过将数据和日志存储在独立路径中,可以避免在升级或重新安装 Elasticsearch 时丢失数据。3. 支持的路径格式Elasticsearch 支持的路径格式因操作系统而异:Linux 和 macOS:支持 Unix 风格的路径,例如 /var/data/elasticsearch 。Windows:支持 Windows 风格的路径,例如 C:\data\elasticsearch 。4. 多路径支持(已弃用)在早期版本中,Elasticsearch 支持为 path.data 配置多个路径,例如:yaml复制path:
data:
- /mnt/elasticsearch_1
- /mnt/elasticsearch_2
- /mnt/elasticsearch_3
这种配置允许 Elasticsearch 在多个磁盘路径中存储数据,但每个分片的数据会存储在同一个路径中。然而,从 7.13 版本开始,多路径支持已被弃用,并将在未来版本中完全移除。
5. 从多路径迁移到单路径如果您当前使用的是多路径配置,建议迁移到单路径配置。以下是迁移步骤:
1. 创建快照:在迁移之前,创建一个集群快照以保护数据。
2. 使用分配过滤器迁移数据:将数据从目标节点迁移到其他节点。
3. 关闭目标节点:按照滚动重启的步骤关闭目标节点。
4. 确保集群健康状态:确保集群健康状态为 yellow 或 green 。
5. 移除分配过滤器:如果之前设置了分配过滤器,需要移除。
6. 清理数据路径:删除目标节点的数据路径中的内容。
7. 重新配置存储:将多个磁盘合并为一个文件系统(例如使用 LVM 或 RAID)。
8. 重新配置节点:更新 elasticsearch.yml 文件中的 path.data 设置。
9. 启动新节点:启动新配置的节点,并完成滚动重启过程。
10. 验证集群状态:确保集群健康状态为 green ,所有分片已正确分配。
6. 注意事项数据目录的安全性:不要修改数据目录中的内容,也不要运行可能干扰其内容的进程。否则可能会导致数据损坏或丢失。
备份和恢复:不要尝试对数据目录进行文件系统备份。建议使用 Elasticsearch 的快照和恢复功能进行安全备份。
磁盘使用率:Elasticsearch 不会在多个数据路径之间自动平衡磁盘使用率。如果某个路径的磁盘使用率过高,可能会触发整个节点的高磁盘使用率水位线,导致节点拒绝分片分配。
通过合理配置 path.settings ,可以提高 Elasticsearch 的数据安全性和集群的稳定性。在生产环境中,建议始终将数据和日志存储在 $ES_HOME 之外的路径,并避免使用已弃用的多路径配置。
相关文章:

【Elasticsearch】Elasticsearch 的`path.settings`是用于配置 Elasticsearch 数据和日志存储路径的重要设置
Elasticsearch 的path.settings是用于配置 Elasticsearch 数据和日志存储路径的重要设置,这些路径在elasticsearch.yml配置文件中定义。以下是关于 Elasticsearch 的路径设置(path.data和path.logs)以及快照存储库配置的详细说明:…...

Redis 实战篇 ——《黑马点评》(下)
《引言》 (下)篇将记录 Redis 实战篇 最后的一些学习内容,希望大家能够点赞、收藏支持一下 Thanks♪ (・ω・)ノ,谢谢大家。 传送门(上):Redis 实战篇 ——《黑马…...

蓝桥杯自我复习打卡
总复习,打卡1. 一。排序 1。选段排序 太可恶了,直接全排输出,一个测试点都没过。 AC 首先,这个【l,r】区间一定要包含p,或者q,pq一个都不包含的,[l,r]区间无论怎么变,都对ans没有影响。 其次&…...
与过滤器(Filter)详细教程)
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程 目录 概述 什么是拦截器(Interceptor)?什么是过滤器(Filter)?两者的核心区别 使用场景 拦截器的典…...

Java零基础入门笔记:(6)面向对象
前言 本笔记是学习狂神的java教程,建议配合视频,学习体验更佳。 【狂神说Java】Java零基础学习视频通俗易懂_哔哩哔哩_bilibili 第1-2章:Java零基础入门笔记:(1-2)入门(简介、基础知识)-CSDN博客 第3章…...
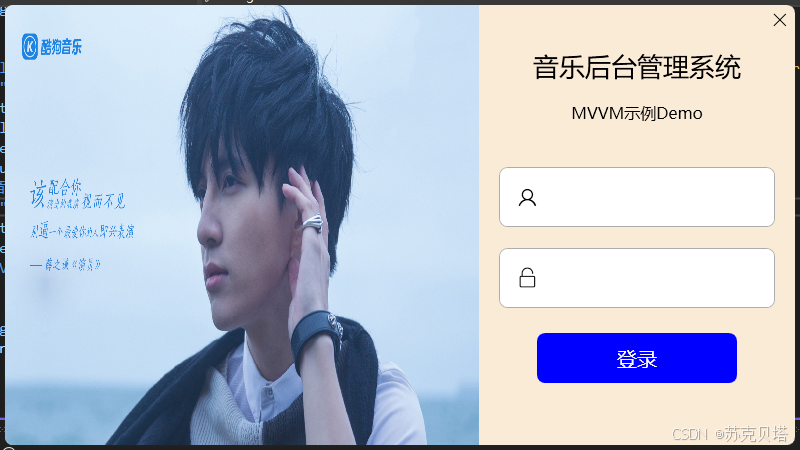
【3天快速入门WPF】13-MVVM进阶
目录 1. 窗体设置2. 字体图标3. 控件模板4. 页面逻辑4.1. 不使用MVVM4.2. MVVM模式实现本篇我们开发一个基于MVVM的登录页面,用来回顾下之前学习的内容 登录页面如下: 窗体取消了默认的标题栏,调整为带阴影的圆角窗体,左侧放一张登录背景图,右边自绘了一个关闭按钮,文本框…...

【MongoDB】在Windows11下安装与使用
官网下载链接:Download MongoDB Community Server 官方参考文档:https://www.mongodb.com/zh-cn/docs/manual/tutorial/install-mongodb-on-windows/#std-label-install-mdb-community-windows 选择custom类型,其他默认 注意,此选…...

Kotlin 5种单例模式
在Kotlin中实现单例模式有多种方法,以下是几种常见的方法: 饿汉式 饿汉式是最简单的一种实现方式,在类加载时就完成了实例的初始化。 //饿汉式 object Singleton1 {fun printMessage() {println("饿汉式")} }懒汉式 懒汉式是延迟…...

C语言复习5:字符串的定义,字符串的常用函数
## 字符串变量的定义方式 - 在C语言中,没有单独的字符串变量,但可以利用字符数组来存字符串 - 占位符:%s - 定义1: 数据类型 变量名[内存占用大小] "字符串"; eg: char s…...

【Multipath网络层协议】MPTCP工作原理
常见网络层多路径协议介绍 MPTCP(Multipath TCP) MPTCP 是在传统 TCP 基础上进行扩展的协议,它允许在源端和目的端之间建立多个 TCP子流,这些子流可以通过不同的网络路径传输数据。 例如,一台笔记本电脑同时连接了 W…...

deepseek使用记录18——文化基因美食篇
子篇:薪火相传的味觉辩证法——从燧人氏到预制菜的文化突围 一、石器时代的启蒙:食物探索中的原始辩证法 在贾湖遗址的陶罐残片上,碳化稻米与蜂蜜的结晶层相互交叠,这是9000年前先民对"甘"与"饱"的首次辩证…...

2025学年安徽省职业院校技能大赛 “信息安全管理与评估”赛项 比赛样题任务书
2024-2025 学年广东省职业院校技能大赛 “信息安全管理与评估”赛项 技能测试试卷(五) 第一部分:网络平台搭建与设备安全防护任务书第二部分:网络安全事件响应、数字取证调查、应用程序安全任务书任务1 :内存取证&…...
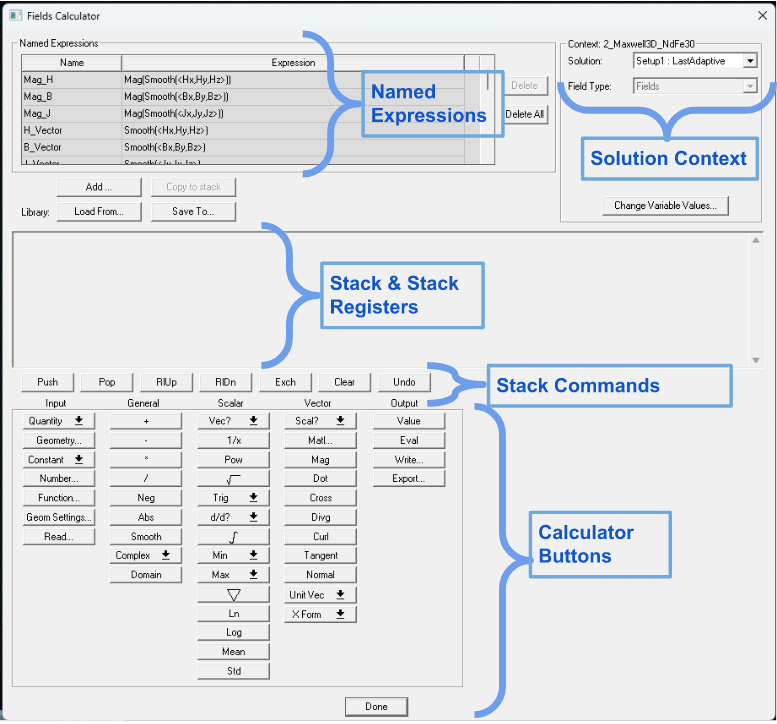
在 Ansys Maxwell 中分析磁场
在 Ansys Maxwell 中分析磁场 分析磁场的能力对于理解电磁系统至关重要。Ansys Maxwell 为工程师提供了强大的工具,帮助他们探索磁场数据并从中提取有价值的见解。在本指南中,我将深入研究 Ansys Maxwell 中的几种基本技术和方法,以有效地分…...

springboot项目Maven打包遇到的问题总结
java -jar 执行报错中没有主清单属性 Spring Boot的可执行JAR需要依赖该插件生成正确的主清单属性。在 pom.xml 的 部分添加以下配置: <build><plugins><!-- 必须配置此插件才能生成可执行的Spring Boot JAR --><plugin><groupId>o…...
DeepSeek FlashMLA:用技术创新破解大模型落地难题
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 DeepSeek大模型技术系列十四DeepSeek大模型技术系列十四》DeepS…...

[补充]原码、反、补、移码的转换
近期在学习Java的类型转换的知识,强制类型转换的时候会遇到数据(丢失)溢出的问题。 最后在IDEA控制台输出的时候,出现了负数。了解了一下强制类型转换在计算机中的原理,随后就复习了一下原码、反、补、移码的转换的知…...

Hue 编译异常:ImportError: cannot import name ‘six‘ from ‘urllib3.packages‘
个人博客地址:Hue 编译异常:ImportError: cannot import name six from urllib3.packages | 一张假钞的真实世界 在编译Hue的时候出现错误信息如下: Running /home/zhangjc/ysten/git/ysten-hue/build/env/bin/hue makemigrations --noinpu…...
)
【Maven】将普通Eclipse项目改造为Maven项目(非SpringBoot项目)
文章目录 将普通Eclipse项目改造为Maven项目(非SpringBoot项目)Maven安装与配置项目结构改造父子Pom.xml文件配置(继承与集成)父项目下的pom.xml文件配置普通子模块下的pom.xml配置启动模块的pom.xml配置 多模块编译总结 Maven插件…...
安装Node.js
1.打开官网,下载安装包 2.安装过程中,全部默认,next. 3.在安装根目录下,新建两个文件夹【node_cache】和【node_global】 4.检测是否安装成功 打开控制台,node -v, npm -v, 显示版本号。 5.配置环境变量 1>从no…...

物联网同RFID功能形态 使用场景的替代品
在物联网(IoT)和自动识别技术领域,除了RFID标签外,还有一些其他技术产品可以在形态和大小上与RFID标签相似,同时提供类似或更强大的功能。以下是几种能够替代RFID标签的产品: 一、NFC标签 NFC(…...

【力扣】堆相关总结
priority_queue std::priority_queue 是 C 标准库中的一个容器适配器,提供了堆(Heap)数据结构的功能。它通常用于实现优先队列,允许你高效地插入元素和访问最大或最小元素。 头文件 #include <queue> 基本定义 std::pri…...

【前端基础】3、HTML的常用元素(h、p、img、a、iframe、div、span)、不常用元素(strong、i、code、br)
HTML结构 一个HTML包含以下部分: 文档类型声明html元素 head元素body元素 例(CSDN): 一、文档类型声明 HTML最一方的文档称为:文档类型声明,用于声明文档类型。即:<!DOCTYPE html>…...
【漫话机器学习系列】113.逻辑回归(Logistic Regression) VS 线性回归(Linear Regression)
逻辑回归 vs 线性回归:详解对比 在机器学习和统计学中,逻辑回归(Logistic Regression) 和 线性回归(Linear Regression) 都是非常常见的模型。尽管它们的数学表达式有一定的相似性,但它们的应用…...

3 算法1-3 回文质数
题目描述 因为 151 既是一个质数又是一个回文数(从左到右和从右到左是看一样的),所以 151 是回文质数。 写一个程序来找出范围 [a,b](5≤a<b≤100,000,000)(一亿)间的所有回文质数。 输入格式 第一行输入两个正…...

Redis---缓存穿透,雪崩,击穿
文章目录 缓存穿透什么是缓存穿透?缓存穿透情况的处理流程是怎样的?缓存穿透的解决办法缓存无效 key布隆过滤器 缓存雪崩什么是缓存雪崩?缓存雪崩的解决办法 缓存击穿什么是缓存击穿?缓存击穿的解决办法 区别对比 在如今的开发中&…...

联合省选 2025 游记
Day 1 不会 LCT,不会字符串,不会博弈 快进到考场 t 1 t1 t1 很快想到枚举中位数再 check,然后就会了,思路很清晰写的很快 t 2 t2 t2 干想 1h 编出来 n m 2 3 nm^{\frac{2}{3}} nm32,然后认为 t 3 t3 t3 会和去年…...

Skywalking介绍,Skywalking 9.4 安装,SpringBoot集成Skywalking
一.Skywalking介绍 Apache SkyWalking是一个开源的分布式追踪与性能监视平台,特别适用于微服务架构、云原生环境以及基于容器(如Docker、Kubernetes)的应用部署。该项目由吴晟发起,并已加入Apache软件基金会的孵化器,…...
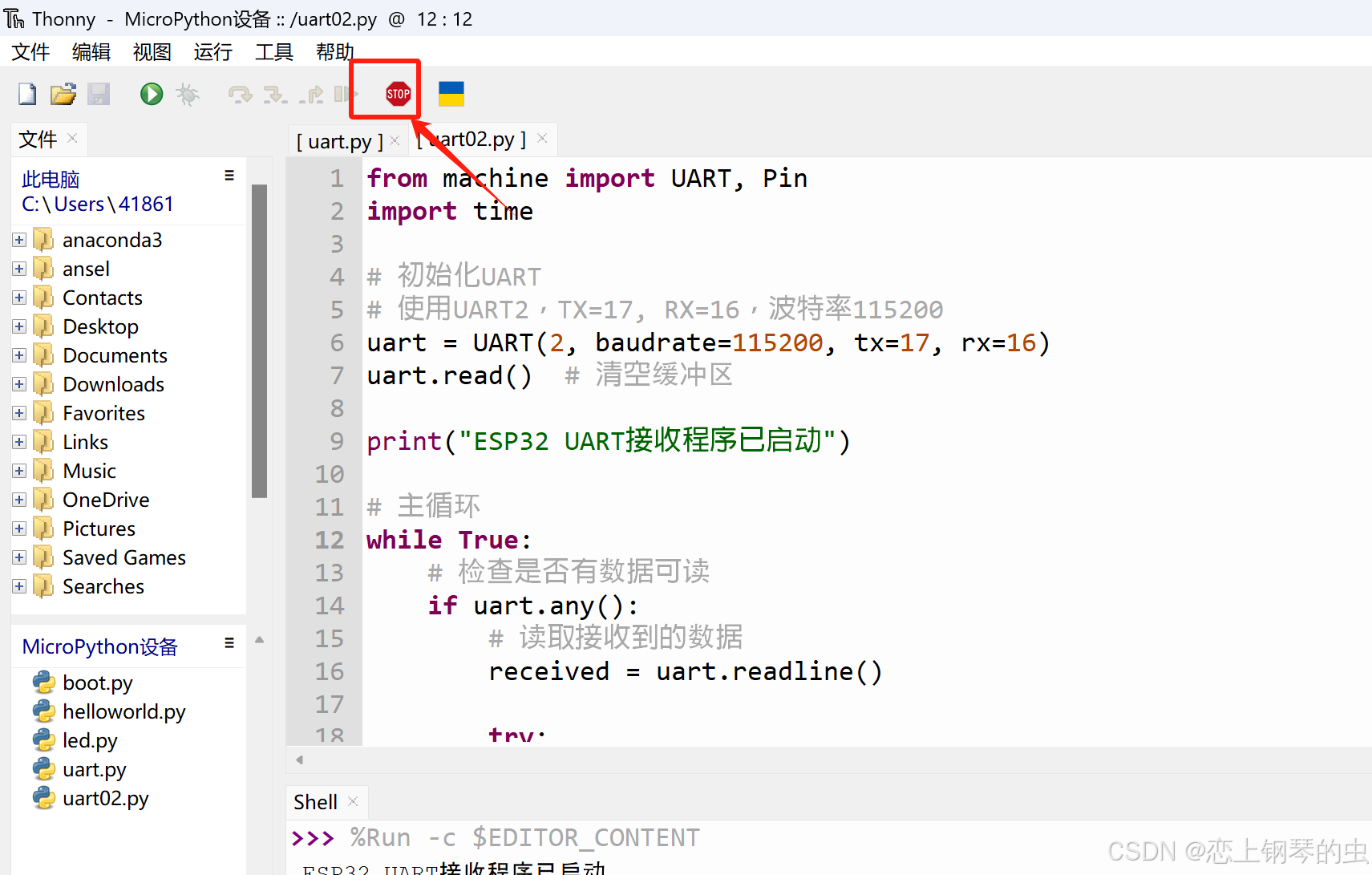
Thonny+MicroPython+ESP32开发环境搭建
1、下载&安装Thonny 安装成功后,会在桌面生成快捷键 双击快捷键,打开程序,界面如下 2、下载MicroPython 下载地址:MicroPython - Python for microcontrollers v1.19版(推荐,此版本稳定): https://do…...

数据结构:反射 和 枚举
目录 一、反射 1、定义 2、反射相关的类 3、Class类 (2)常用获得类中属性相关的方法: (3)获得类中注解相关的方法: (4)获得类中构造器相关的方法: (…...

前缀和算法 算法4
算法题中帮助复习的知识 vector<int > dp( n ,k); n为数组大小 ,k为初始化 哈希表unordered_map<int ,int > hash; hash.find(k)返回值是迭代器 ,找到k返回其迭代器 没找到返回hash.end() hash.count(k)返回值是数字 ,找到k返回1 ,没找到返回0. C和java中 负数…...