第三阶段-产品方面的技术疑难
一、虚拟机和容器的区别?
虚拟机(Virtual Machine,VM)和容器(Container)都是用于隔离和运行应用程序的技术,但它们在实现方式、性能、资源消耗和适用场景上有显著区别。以下是虚拟机和容器的主要区别:
1. 隔离机制
-
虚拟机(VM):
-
原理:虚拟机通过虚拟化技术在物理硬件上创建一个完整的虚拟计算机环境,包括虚拟的CPU、内存、存储和网络设备。
-
隔离性:每个虚拟机都运行一个完整的操作系统(Guest OS),并且与其他虚拟机完全隔离。虚拟机之间的隔离是通过硬件虚拟化技术(如Hypervisor)实现的。
-
优点:完全隔离,安全性高,适合运行不同操作系统的应用程序。
-
缺点:资源消耗大,启动时间长,管理复杂。
-
-
容器(Container):
-
原理:容器是基于操作系统级别的虚拟化技术,通过共享宿主机的操作系统内核,为每个容器提供独立的用户空间。
-
隔离性:容器之间的隔离是通过操作系统级别的资源隔离技术(如Linux的Namespace和Cgroups)实现的。虽然隔离性不如虚拟机强,但在大多数情况下足够安全。
-
优点:轻量级,启动速度快,资源消耗低,适合运行相同操作系统的应用程序。
-
缺点:隔离性较弱,依赖于宿主机的操作系统。
-
2. 资源消耗
-
虚拟机:
-
每个虚拟机都需要一个完整的操作系统实例,这意味着每个虚拟机都要占用一定的CPU、内存和存储资源。
-
例如,运行10个虚拟机可能需要10个完整的操作系统实例,资源消耗较大。
-
-
容器:
-
容器共享宿主机的操作系统内核,不需要运行完整的操作系统实例。
-
因此,容器的资源消耗非常低,可以高效利用宿主机的资源。例如,一台服务器可以运行数百个容器,而资源占用远低于运行相同数量虚拟机的情况。
-
3. 启动速度
-
虚拟机:
-
启动虚拟机需要加载完整的操作系统,启动时间通常在几分钟到十几分钟不等,具体取决于虚拟机的配置和操作系统。
-
-
容器:
-
容器不需要加载完整的操作系统,启动时间通常在几秒甚至更短。容器的快速启动特性使其非常适合微服务架构和动态扩展场景。
-
4. 适用场景
-
虚拟机:
-
多操作系统支持:适合运行不同操作系统的应用程序。
-
高安全性需求:由于完全隔离,适合对安全性要求极高的场景,如金融、医疗等领域。
-
传统应用迁移:适合将传统应用程序迁移到虚拟化环境中,而无需修改代码。
-
-
容器:
-
微服务架构:适合将应用程序拆分为多个微服务,每个微服务运行在一个容器中。
-
DevOps和CI/CD:容器的轻量级和快速启动特性使其非常适合开发、测试和持续集成/持续部署(CI/CD)场景。
-
云原生应用:容器是云原生应用(如Kubernetes)的基础,适合在云环境中运行和管理应用程序。
-
5. 管理和工具
-
虚拟机:
-
管理工具:VMware vSphere、Microsoft Hyper-V、Citrix XenServer等。
-
配置复杂,管理成本较高。
-
-
容器:
-
管理工具:Docker、Kubernetes、Rancher等。
-
配置简单,管理成本较低,适合大规模部署和自动化管理。
-
6. 依赖和兼容性
-
虚拟机:
-
每个虚拟机运行独立的操作系统和应用程序,因此对底层硬件和操作系统的依赖较小。
-
适合运行对操作系统版本有严格要求的应用程序。
-
-
容器:
-
容器依赖于宿主机的操作系统内核,因此容器内的应用程序必须与宿主机的操作系统兼容。
-
适合运行基于同一操作系统的应用程序。
-
总结
| 特性 | 虚拟机(VM) | 容器(Container) |
|---|---|---|
| 隔离性 | 完全隔离,运行独立操作系统 | 操作系统级隔离,共享宿主机内核 |
| 资源消耗 | 高,每个虚拟机运行完整操作系统 | 低,共享宿主机内核,资源利用率高 |
| 启动速度 | 慢,通常需要几分钟 | 快,通常在几秒内启动 |
| 适用场景 | 多操作系统支持、高安全性需求 | 微服务架构、DevOps、云原生应用 |
| 管理工具 | VMware vSphere、Hyper-V等 | Docker、Kubernetes等 |
| 依赖性 | 对底层硬件和操作系统依赖小 | 依赖宿主机操作系统内核 |
选择建议
-
如果你需要运行不同操作系统的应用程序,或者对安全性要求极高,建议选择虚拟机。
-
如果你需要快速部署、灵活扩展,并且应用程序基于同一操作系统,建议选择容器。
容器和虚拟机并不是互斥的技术,它们可以结合使用,例如在虚拟机中运行容器(如Kubernetes on VM),以充分利用两者的优点。
二、价值性销售?
**价值性销售(Value-Based Selling)**是一种以客户为中心的销售策略,其核心在于通过深入了解客户需求,为客户创造并传递超出产品本身的价值,从而建立竞争优势并促成交易。
定义与核心思想
价值性销售强调的不仅仅是销售产品,而是通过产品和服务为客户解决实际问题,提供独特的价值和好处。它将销售人员定位为“价值的创造者”,而不仅仅是交易的促成者。这种方法论认为,客户购买的不仅是产品,更是产品所能带来的价值和解决方案。
价值性销售的关键要素
-
客户价值的创造:
-
价值性销售要求销售人员不仅关注产品本身,还要通过专业知识和定制化服务为客户创造额外价值。
-
销售人员需要深入了解客户的需求、痛点和目标,从而提供针对性的解决方案。
-
-
价值的传递:
-
价值性销售强调将产品和服务的价值清晰地传递给客户,使客户认识到购买决策带来的实际收益。
-
传递价值的过程中,销售人员需要影响客户的认知,让客户感受到所获得的价值远大于付出的成本。
-
-
客户价值的衡量:
-
客户价值的衡量公式为:客户价值 = 实际价值 × 客户认知。
-
成交的关键在于确保客户感知的价值大于其付出的成本,即 客户价值 - 客户成本 > 0。
-
应用场景与优势
-
应对价格竞争:
-
在竞争激烈的市场中,价值性销售通过强调产品和服务的独特价值,帮助企业在不降价的情况下赢得客户。
-
-
建立长期客户关系:
-
通过为客户创造实际价值,企业能够与客户建立更深厚的信任关系,从而实现长期合作。
-
-
提升销售效率:
-
价值性销售方法论包含一系列系统化的流程和工具,帮助销售人员更高效地识别商机、引导客户需求并促成交易。
-
实践方法
-
深入了解客户需求:
-
销售人员需要通过调研、访谈等方式深入了解客户的业务目标、痛点和期望。
-
-
定制化解决方案:
-
根据客户的具体需求,提供定制化的解决方案,而不仅仅是标准化的产品。
-
-
价值传递与沟通:
-
在销售过程中,销售人员需要清晰地向客户展示产品和服务的价值,通过案例、数据等方式增强客户对价值的认知。
-
-
持续优化:
-
价值性销售是一个动态过程,需要根据客户的反馈和市场变化不断优化解决方案。
-
总结
价值性销售是一种以客户为中心的销售策略,通过创造和传递超出产品本身的价值,帮助企业在竞争激烈的市场中赢得客户信任并实现销售目标。这种方法不仅关注产品的功能和价格,更注重客户的需求和价值感知,从而实现双赢的交易。
三、云和虚拟化的区别?
云(云计算)和虚拟化是现代IT领域中两个密切相关但又有所区别的概念。它们都旨在提高资源利用率、降低成本和增强灵活性,但它们的实现方式、应用场景和目标有所不同。以下是对云和虚拟化的详细对比:
1. 定义
-
虚拟化(Virtualization):
-
虚拟化是一种技术,通过将物理资源(如服务器、存储、网络)抽象为逻辑资源,使用户可以在单个物理硬件上创建多个独立的虚拟环境(如虚拟机或容器)。虚拟化的核心是通过软件模拟硬件的功能,从而实现资源的高效利用和隔离。
-
虚拟化技术可以应用于计算(如服务器虚拟化)、存储(如存储虚拟化)和网络(如网络虚拟化)等多个层面。
-
-
云计算(Cloud Computing):
-
云计算是一种基于互联网的计算模式,通过共享的资源池(如服务器、存储、网络)提供按需分配的计算资源和服务。用户可以通过网络访问这些资源,而无需直接管理底层硬件。
-
云计算的核心是资源的动态分配、弹性扩展和按需付费,常见的服务模式包括IaaS(基础设施即服务)、PaaS(平台即服务)和SaaS(软件即服务)。
-
2. 技术实现
-
虚拟化:
-
技术基础:虚拟化依赖于虚拟化软件(如Hypervisor),将物理资源抽象为虚拟资源,创建虚拟机(VM)或容器。
-
资源管理:虚拟化技术通过资源池化和动态分配,提高硬件资源的利用率。
-
隔离性:虚拟化提供了强隔离性,每个虚拟机或容器独立运行,互不干扰。
-
-
云计算:
-
技术基础:云计算通常基于虚拟化技术实现,但更侧重于资源的动态管理和自动化交付。
-
资源管理:云计算通过云管理平台(如OpenStack、AWS管理控制台)实现资源的自动化分配、监控和扩展。
-
弹性扩展:云计算支持按需扩展资源,用户可以根据需求动态调整资源的使用量。
-
3. 应用场景
-
虚拟化:
-
服务器整合:通过在一台物理服务器上运行多个虚拟机,减少硬件数量,降低能耗和管理成本。
-
开发和测试环境:快速创建和销毁虚拟环境,支持多种操作系统和配置。
-
灾难恢复:通过虚拟化技术快速恢复故障系统,提高业务连续性。
-
-
云计算:
-
IaaS(基础设施即服务):提供虚拟服务器、存储和网络资源,用户可以按需使用和付费。
-
PaaS(平台即服务):提供开发平台和运行环境,支持应用程序的开发、部署和管理。
-
SaaS(软件即服务):通过互联网提供软件应用,用户无需安装和维护软件,按需使用。
-
4. 用户角色和控制权
-
虚拟化:
-
用户角色:虚拟化通常由企业的IT部门管理,管理员负责配置和管理虚拟化环境。
-
控制权:用户对底层硬件有较高的控制权,可以自定义虚拟机的配置和资源分配。
-
-
云计算:
-
用户角色:云计算的用户通常是企业或个人用户,通过云服务提供商的平台访问资源。
-
控制权:用户对底层硬件的控制权较低,但可以通过云管理平台灵活配置和管理资源。
-
5. 成本和管理
-
虚拟化:
-
成本:虚拟化需要购买虚拟化软件(如VMware vSphere)和硬件设备,初始投资较高,但长期运行成本较低。
-
管理:虚拟化环境需要专业的IT人员进行管理和维护,管理复杂度较高。
-
-
云计算:
-
成本:云计算采用按需付费的模式,用户只需为实际使用的资源付费,初始投资较低。
-
管理:云计算的管理相对简单,用户可以通过云管理平台进行资源的配置和监控。
-
6. 安全性和隔离性
-
虚拟化:
-
安全性:虚拟化提供了强隔离性,每个虚拟机独立运行,互不干扰。
-
风险:如果虚拟化平台(如Hypervisor)出现漏洞,可能影响所有虚拟机的安全性。
-
-
云计算:
-
安全性:云计算的安全性取决于云服务提供商的管理水平和技术能力。云服务提供商通常会提供多层次的安全措施,但用户也需要承担部分安全责任。
-
隔离性:云计算通过虚拟化技术实现资源隔离,但共享资源池的特性可能带来一定的安全风险。
-
总结
| 特性 | 虚拟化(Virtualization) | 云计算(Cloud Computing) |
|---|---|---|
| 定义 | 将物理资源抽象为虚拟资源,创建虚拟环境 | 通过互联网提供按需分配的计算资源和服务 |
| 技术实现 | 基于虚拟化软件(如Hypervisor) | 基于虚拟化技术,但更侧重于自动化和弹性 |
| 应用场景 | 服务器整合、开发测试、灾难恢复 | IaaS、PaaS、SaaS |
| 用户角色 | 企业IT部门管理,用户对硬件有较高控制权 | 云服务提供商管理,用户通过平台访问资源 |
| 成本 | 初始投资高,长期运行成本低 | 初始投资低,按需付费 |
| 管理 | 管理复杂度高,需要专业IT人员 | 管理简单,通过云管理平台操作 |
| 安全性 | 强隔离性,但Hypervisor漏洞可能带来风险 | 安全性取决于云服务提供商,用户需共担责任 |
选择建议
-
如果你需要对底层硬件有较高控制权,或者希望通过服务器整合降低成本,虚拟化是更好的选择。
-
如果你需要快速部署、弹性扩展,并且希望降低管理复杂度,云计算是更合适的选择。
在实际应用中,虚拟化和云计算可以结合使用,例如在企业数据中心中使用虚拟化技术构建私有云,或者将虚拟化环境扩展到公有云中,实现混合云架构。
四、什么是分布式存储?
分布式存储是一种将数据分散存储在多个独立存储设备上的架构,这些设备通常通过网络连接在一起,形成一个统一的存储资源池。与传统的集中式存储不同,分布式存储通过软件定义的方式管理数据,能够提供更高的扩展性、灵活性和容错能力。
分布式存储的核心特点
-
分布式架构:
-
数据被分散存储在多个节点(通常是服务器或存储设备)上,而不是集中存储在一个大型存储设备中。
-
每个节点既可以存储数据,也可以参与数据的管理和处理。
-
-
高扩展性:
-
分布式存储系统可以通过增加存储节点来动态扩展存储容量,理论上没有容量上限。
-
扩展过程通常不需要停机,支持在线扩展。
-
-
高可用性和容错性:
-
数据通过冗余存储(如副本或纠删码)分布在多个节点上,即使部分节点故障,数据仍然可用。
-
系统能够自动检测故障节点并进行数据恢复,确保数据的完整性和可用性。
-
-
性能优化:
-
数据存储和处理分布在多个节点上,可以并行读写,从而提高整体性能。
-
通过数据本地化(将计算任务分配到存储数据的节点上)减少数据传输开销。
-
-
软件定义存储(SDS):
-
分布式存储通常基于软件定义的方式实现,存储功能由软件控制,硬件设备可以是通用服务器。
-
支持灵活的存储策略和动态资源管理。
-
分布式存储的工作原理
-
数据分布:
-
数据被分割成多个块(chunks),并分散存储在不同的存储节点上。
-
数据块的分布可以通过哈希算法、一致性哈希或元数据管理来实现。
-
-
冗余机制:
-
为了保证数据的可靠性,分布式存储通常采用以下冗余机制:
-
副本(Replication):将数据块的多个副本存储在不同的节点上。
-
纠删码(Erasure Coding):通过计算校验码,将数据分割成多个片段并存储在不同节点上。相比副本,纠删码在存储效率上更高,但恢复数据时计算复杂度较高。
-
-
-
元数据管理:
-
分布式存储系统需要一个元数据管理系统来记录数据块的位置、大小和状态等信息。
-
元数据可以集中存储或分布式存储,具体取决于系统的架构。
-
-
数据访问与一致性:
-
客户端通过分布式存储系统提供的接口访问数据。
-
系统需要确保数据的一致性,常见的策略包括强一致性、最终一致性等。
-
分布式存储的类型
-
分布式文件系统(DFS):
-
例如Hadoop分布式文件系统(HDFS)、Google File System(GFS)。
-
适用于大规模数据存储,支持高吞吐量的读写操作。
-
-
分布式对象存储:
-
例如Amazon S3、Ceph、Swift。
-
以对象为存储单元,支持高扩展性和灵活的访问策略。
-
-
分布式块存储:
-
例如Ceph RBD、Google Persistent Disk。
-
提供块级存储,适用于虚拟化环境和高性能计算。
-
分布式存储的优势
-
高扩展性:通过增加节点动态扩展存储容量,适合大规模数据存储。
-
高可用性:通过冗余机制保证数据的高可用性。
-
性能优化:支持并行读写,提高数据处理效率。
-
灵活性:基于软件定义的方式,支持灵活的存储策略和动态资源管理。
-
成本效益:可以使用通用硬件设备,降低硬件成本。
分布式存储的挑战
-
数据一致性:在分布式环境下,确保数据的一致性是一个复杂问题。
-
网络延迟:数据分布在多个节点上,网络延迟可能影响性能。
-
故障恢复:虽然分布式存储具有容错能力,但故障恢复过程可能复杂且耗时。
-
管理复杂性:分布式存储系统的管理比传统存储系统更复杂,需要专业的运维人员。
应用场景
-
大数据处理:Hadoop分布式文件系统(HDFS)广泛应用于大数据存储和处理。
-
云计算:分布式存储为云服务提供商提供了高扩展性和高可用性的存储解决方案。
-
高性能计算(HPC):分布式块存储支持高性能计算环境中的大规模数据存储。
-
企业级存储:Ceph等分布式存储系统被用于企业级存储,提供灵活的存储解决方案。
总结
分布式存储是一种通过多个节点分散存储数据的架构,具有高扩展性、高可用性和性能优化的特点。它适用于大规模数据存储和高性能计算场景,是现代数据中心和云计算环境中的重要技术。
五、混闪和全闪的区别?
全闪存存储(All-Flash Storage)和混合闪存存储(Hybrid Flash Storage)是两种常见的存储架构,它们在性能、成本、适用场景等方面有显著区别。以下是两者的详细对比:
1. 定义
-
全闪存存储:全闪存存储完全基于闪存介质(如SSD),所有数据都存储在闪存中。这种架构旨在提供极高的性能、低延迟和高IOPS(每秒输入输出操作次数),适合对性能要求极高的场景。
-
混合闪存存储:混合闪存存储结合了闪存(SSD)和传统硬盘(HDD),通过将高频访问的“热数据”存储在闪存中,低频访问的“冷数据”存储在HDD中,以实现性能和成本的平衡。
2. 性能
-
全闪存存储:提供极高的IOPS和低延迟,通常延迟在1毫秒以下。适合高负载、高并发的场景,如在线交易处理(OLTP)和大数据分析。
-
混合闪存存储:性能介于全闪存和传统HDD之间,依赖于闪存和HDD的结合。适合一般性工作负载。
3. 成本
-
全闪存存储:由于完全使用闪存介质,成本较高,但随着技术发展,其价格正在逐渐下降。
-
混合闪存存储:通过结合闪存和HDD,提供了更均衡的成本效益,适合预算有限的场景。
4. 数据冗余
-
全闪存存储:通常需要单独实施冗余机制,如RAID。
-
混合闪存存储:通常内置数据冗余机制,如RAID和自动分层存储。
5. 适用场景
-
全闪存存储:适用于对性能要求极高的场景,如金融交易系统、实时数据分析和高性能计算。
-
混合闪存存储:适用于需要平衡性能和成本的场景,如中小型企业存储、常规办公应用和数据备份。
6. 扩展性
-
全闪存存储:扩展性较好,但通常需要更多的硬件投资。
-
混合闪存存储:扩展性灵活,可以通过增加闪存或HDD来调整性能和容量。
7. 功耗与可靠性
-
全闪存存储:功耗较低,工作温度范围更广,可靠性高。
-
混合闪存存储:由于包含机械硬盘,功耗和可靠性相对较低。
总结
全闪存存储和混合闪存存储各有优势,选择哪种架构应根据具体的业务需求、预算和预期增长来决定。全闪存存储适合追求极致性能的场景,而混合闪存存储在性能和成本之间提供了良好的平衡。
六、什么是主存储和镜像存储?
1. 主存储(Primary Storage)
主存储是指存储系统中用于直接支持日常操作和关键业务数据的核心存储资源。它是存储架构中的主要部分,通常用于存储频繁访问的数据和应用程序所需的资源。
特点
-
高性能:主存储通常需要具备高IOPS(每秒输入输出操作次数)和低延迟,以支持关键业务应用的高效运行。
-
高可用性:主存储通常具备高可用性设计,如冗余硬件、自动故障切换和数据保护机制(如RAID)。
-
数据一致性:主存储中的数据是最新和最准确的,用于支持实时业务操作。
-
成本较高:由于对性能和可用性的要求较高,主存储通常使用高性能的存储介质(如SSD)和高端存储设备。
应用场景
-
关键业务应用:如数据库、ERP系统、在线交易处理(OLTP)等。
-
高性能计算:需要快速读写数据的场景。
-
企业核心存储:存储企业的核心数据和关键应用。
2. 镜像存储(Mirror Storage)
镜像存储是一种通过数据复制技术实现的存储方式,用于创建主存储数据的完整副本。镜像存储的主要目的是提供数据冗余和灾难恢复能力,确保在主存储发生故障时,数据可以快速恢复。
特点
-
数据冗余:镜像存储通过实时或定期复制主存储中的数据,创建一个完全一致的副本。
-
高可用性:镜像存储通常用于灾难恢复和高可用性场景,确保在主存储故障时,业务可以无缝切换到镜像存储。
-
同步与异步复制:
-
同步镜像:数据在主存储和镜像存储之间实时同步,确保两者数据完全一致。适用于对数据一致性要求极高的场景。
-
异步镜像:数据在主存储和镜像存储之间定期同步,可能存在一定的数据延迟。适用于对性能要求较高且可以容忍一定数据延迟的场景。
-
-
成本效益:镜像存储可以使用较低成本的存储设备,因为其主要功能是数据冗余,而不是高性能。
应用场景
-
灾难恢复:在主存储发生故障时,镜像存储可以快速接管业务,确保数据不丢失。
-
高可用性:通过镜像存储,企业可以在数据中心之间实现数据的冗余备份,提高系统的整体可用性。
-
数据备份:镜像存储可以作为数据备份的一部分,用于恢复历史数据或进行数据迁移。
主存储与镜像存储的区别
| 特性 | 主存储(Primary Storage) | 镜像存储(Mirror Storage) |
|---|---|---|
| 功能 | 存储核心业务数据,支持日常操作 | 提供数据冗余和灾难恢复能力 |
| 性能要求 | 高性能、低延迟 | 对性能要求较低,主要关注数据一致性 |
| 可用性 | 高可用性设计,支持实时业务 | 高可用性设计,用于故障切换和恢复 |
| 数据一致性 | 数据是最新的,用于实时操作 | 数据是主存储的副本,可能存在延迟 |
| 成本 | 成本较高,使用高性能存储介质 | 成本较低,可以使用较低性能的存储设备 |
| 应用场景 | 关键业务应用、高性能计算 | 灾难恢复、高可用性、数据备份 |
总结
-
主存储是存储系统的核心部分,用于支持企业的核心业务和关键应用,强调高性能和高可用性。
-
镜像存储是主存储的副本,用于提供数据冗余和灾难恢复能力,确保在主存储发生故障时,数据可以快速恢复。
在实际应用中,主存储和镜像存储通常结合使用,以实现数据的高可用性和可靠性。例如,企业可以在本地数据中心使用主存储,同时在异地数据中心配置镜像存储,以实现灾难恢复和数据备份。
七、在云计算领域中,什么是克隆并且它还分为什么?
在云计算领域中,克隆是指通过复制现有虚拟机或云服务器实例的配置、数据和应用程序,快速创建一个完全相同的副本。克隆技术广泛应用于云计算环境中,用于快速部署、测试、备份和扩展资源。根据实现方式和应用场景的不同,克隆可以分为以下几种类型:
1. 完整克隆(Full Clone)
完整克隆是指创建一个与原始虚拟机或云服务器完全独立的副本。它复制了原始实例的所有磁盘内容、配置信息和数据,生成一个全新的虚拟机或服务器实例。
特点
-
独立性:克隆后的实例完全独立,与原始实例互不影响。
-
性能:克隆实例的性能与原始实例相同,因为它们拥有独立的磁盘空间。
-
存储占用:需要较多的存储空间,因为每个克隆实例都是一个完整的副本。
应用场景
-
适用于需要完全独立的测试环境或开发环境。
-
用于创建备份实例,确保数据安全。
2. 链接克隆(Linked Clone)
链接克隆是一种更节省存储空间的克隆方式。它通过共享原始虚拟机或云服务器的大部分磁盘数据来创建新的实例,只记录与原始实例的差异部分。
特点
-
存储占用:由于共享原始数据,链接克隆所需的存储空间较少。
-
依赖性:克隆实例依赖于原始实例或其快照数据,原始实例的修改可能影响克隆实例。
-
创建速度:创建速度更快,因为不需要复制整个磁盘数据。
应用场景
-
适用于需要快速创建大量相似实例的场景,如云桌面、公共电脑室等。
-
用于临时测试环境,当原始实例的数据不会频繁变化时。
3. 云服务器克隆
云服务器克隆是指在云计算环境中,通过复制现有云服务器的镜像或快照,快速创建一个完全相同的新云服务器实例。
特点
-
快速部署:可以在短时间内完成新服务器的创建,无需手动配置。
-
一致性:确保新服务器与原始服务器具有相同的操作系统、软件和配置。
-
灵活性:可以根据需要调整新服务器的规格(如CPU、内存、存储)。
应用场景
-
用于快速扩展云资源,满足业务增长需求。
-
用于灾备和容错,通过克隆创建备用服务器。
4. 虚拟机克隆
虚拟机克隆是指在虚拟化环境中,通过复制现有虚拟机的配置和磁盘数据,创建新的虚拟机实例。
特点
-
自动化部署:通过虚拟化平台(如KVM、VMware)快速创建多个虚拟机。
-
资源优化:可以灵活调整虚拟机的资源配置。
应用场景
-
用于开发和测试环境,快速创建多个相似的虚拟机。
-
用于数据中心的资源池化,提高资源利用率。
5. 块存储卷克隆
块存储卷克隆是指创建现有存储卷的完全副本,通常用于数据备份和迁移。
特点
-
高效复制:可以基于现有存储卷或快照进行克隆。
-
数据一致性:确保克隆卷与原始卷的数据完全一致。
应用场景
-
用于数据备份和恢复。
-
用于创建多个相同的数据卷,支持大规模数据处理。
总结
在云计算领域,克隆技术提供了快速部署、备份和扩展资源的能力。根据需求和资源限制,可以选择以下克隆方式:
-
完整克隆:适用于需要完全独立实例的场景。
-
链接克隆:适用于需要快速创建大量相似实例且对存储空间有限制的场景。
-
云服务器克隆:适用于快速扩展云资源和灾备场景。
-
虚拟机克隆:适用于开发、测试和数据中心资源池化。
-
块存储卷克隆:适用于数据备份和大规模数据处理。
通过合理选择克隆方式,可以有效提高云计算环境中的资源利用率和管理效率。
八、什么是NAS存储?
NAS(Network Attached Storage,网络附加存储)是一种通过网络连接到计算机系统的存储设备,它允许用户通过标准的网络协议(如NFS、SMB/CIFS)访问和共享存储资源。NAS存储通常被设计为一个独立的设备,可以直接连接到局域网(LAN)或广域网(WAN),为多个用户和设备提供集中化的存储服务。
NAS存储的核心特点
-
网络连接:
-
NAS设备通过以太网接口连接到网络,通常使用TCP/IP协议进行通信。
-
它可以部署在局域网内,也可以通过VPN或互联网实现远程访问。
-
-
文件级存储:
-
NAS提供文件级存储服务,用户可以通过标准的文件协议(如NFS、SMB/CIFS)访问和共享文件。
-
它主要用于存储和管理文件数据,而不是块级存储(如SAN存储)。
-
-
集中化管理:
-
NAS存储设备通常提供集中化的管理界面,支持多用户访问和权限管理。
-
管理员可以通过Web界面或管理工具配置存储资源、用户权限和数据备份策略。
-
-
高可用性和冗余:
-
NAS设备通常支持冗余设计,如RAID(磁盘阵列)技术,以提高数据的可靠性和容错能力。
-
高端NAS设备还支持双控制器、热插拔硬盘等特性,确保系统的高可用性。
-
-
扩展性:
-
NAS存储可以通过增加硬盘或扩展柜来扩展存储容量。
-
一些NAS设备还支持集群技术,实现多设备的协同工作。
-
NAS存储的工作原理
-
硬件组成:
-
NAS设备通常包括一个或多个硬盘驱动器、网络接口、处理器和内存。
-
高端NAS设备可能支持多种硬盘接口(如SATA、SAS)和高性能处理器。
-
-
文件系统:
-
NAS设备内部运行一个文件系统(如EXT4、XFS、Btrfs),用于管理存储在硬盘上的数据。
-
它通过网络协议将文件系统暴露给客户端设备,使用户可以像访问本地文件系统一样访问NAS存储。
-
-
网络协议:
-
NAS设备支持多种网络文件协议,常见的有:
-
NFS(Network File System):主要用于Unix和Linux系统。
-
SMB/CIFS(Server Message Block/Common Internet File System):主要用于Windows系统。
-
AFP(Apple Filing Protocol):用于Mac OS系统。
-
-
用户可以通过这些协议从不同的操作系统访问NAS存储。
-
-
数据访问:
-
客户端设备通过网络连接到NAS设备,并通过上述协议访问存储在NAS上的文件。
-
用户可以像操作本地文件系统一样,进行文件的读写、复制、删除等操作。
-
NAS存储的类型
-
家用NAS:
-
通常用于家庭网络环境,提供简单的文件共享和备份功能。
-
支持多设备访问,适合家庭用户存储照片、视频和文档。
-
-
中小企业NAS:
-
提供更高级的管理功能,如用户权限管理、数据备份和恢复。
-
适用于中小企业存储业务数据和文档。
-
-
企业级NAS:
-
提供高性能、高可用性和大规模扩展能力。
-
适用于大型企业存储关键业务数据和文件共享。
-
NAS存储的应用场景
-
文件共享:
-
NAS设备可以为多个用户和设备提供集中化的文件存储和共享服务。
-
例如,企业内部的文档共享、团队协作项目文件管理等。
-
-
数据备份:
-
NAS设备可以作为备份目标,存储重要数据的备份副本。
-
它支持定期备份和版本管理,确保数据的安全性和可恢复性。
-
-
多媒体存储:
-
NAS设备可以存储大量的多媒体文件(如照片、视频、音乐),并通过网络流媒体服务(如DLNA、Plex)进行播放。
-
适用于家庭影院系统和多媒体服务器。
-
-
云存储网关:
-
NAS设备可以作为云存储的本地缓存或网关,实现本地存储与云存储的结合。
-
例如,将本地数据同步到云存储服务,同时提供本地缓存以提高访问速度。
-
NAS存储的优势
-
集中化管理:
-
提供集中化的存储管理界面,简化了存储资源的配置和管理。
-
支持多用户访问和权限管理,确保数据的安全性。
-
-
高可用性和冗余:
-
通过RAID技术提供数据冗余,确保数据的可靠性和容错能力。
-
高端NAS设备支持双控制器和热插拔硬盘,进一步提高系统的可用性。
-
-
灵活性和扩展性:
-
NAS设备可以通过增加硬盘或扩展柜来扩展存储容量。
-
支持多种网络协议和操作系统,适用于不同的应用场景。
-
-
成本效益:
-
NAS设备通常比传统的SAN存储系统更经济实惠,适合中小企业和家庭用户。
-
NAS存储的局限性
-
性能瓶颈:
-
NAS设备的性能通常受到网络带宽的限制,对于高带宽需求的应用(如大型数据库)可能不够理想。
-
高端NAS设备可以通过支持10G以太网或更高带宽的网络接口来缓解这一问题。
-
-
复杂性:
-
对于大型企业或高性能需求的场景,NAS设备的管理和配置可能较为复杂。
-
需要专业的IT人员进行管理和维护。
-
-
安全性:
-
NAS设备通过网络共享存储资源,可能存在安全风险。
-
需要通过加密、访问控制等措施确保数据的安全性。
-
总结
NAS存储是一种通过网络连接的存储设备,主要用于文件共享、数据备份和多媒体存储。它支持多种网络协议和操作系统,提供集中化的管理和高可用性设计。NAS存储适用于家庭用户、中小企业和大型企业,广泛应用于文件共享、数据备份和多媒体存储等场景。通过合理选择NAS设备,可以有效提高存储资源的利用率和管理效率。
九、什么是本地存储?
本地存储的定义
**本地存储(Local Storage)**是指直接连接到计算机或服务器的存储设备,用于存储数据和应用程序。它与网络存储(如NAS或SAN)不同,本地存储不依赖于网络连接,而是直接与主机系统相连,通常通过内部或外部接口(如SATA、SAS、USB等)实现数据传输。
本地存储的特点
-
高性能:
-
本地存储通常具有较低的延迟和较高的数据传输速率,因为数据访问不需要通过网络。
-
例如,SSD(固态硬盘)和高性能HDD(机械硬盘)可以直接连接到主机,提供快速的读写速度。
-
-
低延迟:
-
由于本地存储直接连接到主机,数据访问的延迟非常低,适合对性能要求较高的应用(如数据库、实时处理等)。
-
-
独立性:
-
本地存储不依赖于网络,因此不受网络带宽或网络故障的影响,数据访问更加稳定。
-
-
管理简单:
-
本地存储的管理相对简单,通常由主机操作系统直接管理,无需复杂的网络配置或存储管理软件。
-
-
成本效益:
-
对于小型企业和个人用户,本地存储通常比网络存储更具成本效益,因为不需要额外的网络设备或存储服务器。
-
-
安全性:
-
本地存储的数据存储在本地设备上,不会通过网络传输,因此在物理隔离的情况下,数据安全性较高。
-
本地存储的类型
-
内部硬盘(Internal Hard Drives):
-
机械硬盘(HDD):通过旋转磁盘和移动磁头读写数据,容量大,成本低。
-
固态硬盘(SSD):使用闪存芯片存储数据,读写速度快,无机械部件,抗震性强。
-
-
外部硬盘(External Hard Drives):
-
通过USB、Thunderbolt或eSATA等接口连接到主机,便于携带和扩展存储容量。
-
-
固态存储(SSD):
-
包括M.2接口、NVMe接口的固态硬盘,适用于高性能需求的场景。
-
-
USB闪存驱动器(USB Flash Drives):
-
小巧便携,通过USB接口连接,适合临时存储和数据传输。
-
-
RAID阵列(RAID Arrays):
-
通过将多个硬盘组合成一个逻辑单元,提供数据冗余(如RAID 1、RAID 5)或性能提升(如RAID 0)。
-
本地存储的应用场景
-
个人计算机:
-
存储操作系统、应用程序和个人文件。
-
例如,C盘通常用于安装操作系统,D盘用于存储用户数据。
-
-
服务器:
-
存储关键业务数据、应用程序和操作系统。
-
服务器通常使用高性能的SSD或RAID阵列来提高数据的可靠性和读写性能。
-
-
工作站:
-
用于存储专业软件(如Adobe Photoshop、AutoCAD)和项目文件。
-
高性能的本地存储可以显著提升工作效率。
-
-
嵌入式设备:
-
存储设备固件和运行数据,如路由器、智能电视等。
-
本地存储的优势
-
高性能:适合对读写速度要求较高的应用。
-
低延迟:数据访问延迟低,适合实时处理。
-
独立性:不依赖网络,数据访问更稳定。
-
管理简单:由主机操作系统直接管理,无需复杂配置。
-
安全性:数据存储在本地,物理隔离,安全性高。
本地存储的局限性
-
扩展性有限:
-
本地存储的扩展通常受到主机接口数量和物理空间的限制。
-
例如,一台普通计算机的硬盘插槽数量有限。
-
-
共享性差:
-
本地存储通常仅供单个主机使用,不适合多用户共享。
-
对于需要多用户访问的场景,需要额外的网络存储解决方案。
-
-
容错能力有限:
-
单个硬盘故障可能导致数据丢失,需要通过RAID等技术提高可靠性。
-
与网络存储相比,本地存储的容错能力较弱。
-
-
备份复杂:
-
本地存储的数据备份需要手动操作或额外的备份软件支持。
-
对于大规模数据备份,本地存储的管理较为复杂。
-
总结
本地存储是一种直接连接到计算机或服务器的存储方式,具有高性能、低延迟和管理简单的特点。它适用于个人计算机、服务器和工作站等场景,适合对性能要求较高且不需要多用户共享的应用。然而,本地存储在扩展性、共享性和容错能力方面存在一定的局限性,对于需要大规模数据共享和高可用性的场景,通常需要结合网络存储(如NAS或SAN)来实现更灵活的解决方案。
十、什么是SAN存储?
SAN存储(Storage Area Network)
SAN存储(Storage Area Network,存储区域网络)是一种高速网络,专门用于连接计算机和存储设备。SAN通过专用的网络基础设施(如光纤通道或以太网)将存储资源(如磁盘阵列、磁带库等)与服务器连接起来,提供高性能、高可用性和高扩展性的存储解决方案。
SAN存储的核心特点
-
高性能:
-
SAN使用专用的高速网络(如光纤通道)或高速以太网(如10G以太网、25G以太网)进行数据传输,支持高带宽和低延迟。
-
适用于对性能要求极高的应用,如数据库、虚拟化环境和高性能计算。
-
-
块级存储:
-
SAN提供块级存储服务,直接将存储资源分配给服务器,服务器可以像访问本地硬盘一样访问SAN存储。
-
与文件级存储(如NAS)不同,SAN存储不涉及文件系统管理,数据传输效率更高。
-
-
高可用性和冗余:
-
SAN存储通常支持多种冗余机制,如多路径I/O(MPIO)、冗余控制器和冗余网络连接。
-
提供高可用性,确保在硬件故障或网络问题时,数据访问不受影响。
-
-
集中化管理:
-
SAN存储设备通常提供集中化的管理工具,支持存储资源的动态分配和管理。
-
管理员可以通过统一的管理界面监控和配置存储资源。
-
-
扩展性:
-
SAN存储可以通过增加存储设备或扩展柜来扩展存储容量。
-
支持大规模存储环境,适用于企业级应用。
-
-
协议支持:
-
SAN存储支持多种协议,如光纤通道(FC)、iSCSI(Internet Small Computer Systems Interface)和FCoE(Fibre Channel over Ethernet)。
-
其中,光纤通道是SAN的主流协议,提供高性能和高可靠性;iSCSI则通过以太网传输存储数据,成本较低。
-
SAN存储的工作原理
-
硬件组成:
-
SAN存储系统通常包括以下组件:
-
存储设备:如磁盘阵列(DAS)、固态硬盘(SSD)阵列、磁带库等。
-
网络设备:如光纤通道交换机、以太网交换机。
-
主机适配器:如光纤通道HBA(Host Bus Adapter)或iSCSI HBA,用于连接服务器和SAN网络。
-
存储控制器:管理存储设备,提供数据管理、缓存和冗余功能。
-
-
-
数据传输:
-
SAN存储通过专用的网络协议(如FC或iSCSI)将数据块从存储设备传输到服务器。
-
服务器通过主机适配器访问SAN存储,操作系统将SAN存储识别为本地硬盘。
-
-
存储管理:
-
SAN存储设备通常提供集中化的管理工具,支持存储资源的分配、监控和维护。
-
管理员可以通过管理界面配置存储卷、设置用户权限和监控性能。
-
SAN存储的类型
-
光纤通道SAN(FC-SAN):
-
使用光纤通道协议,提供高性能和高可靠性。
-
适用于对性能要求极高的企业级应用,如数据库和虚拟化环境。
-
-
iSCSI SAN:
-
使用以太网传输存储数据,成本较低。
-
适用于中小企业和对成本敏感的应用场景。
-
-
FCoE SAN:
-
将光纤通道协议封装在以太网中,结合了光纤通道的高性能和以太网的低成本。
-
适用于需要高性能和高扩展性的数据中心。
-
SAN存储的应用场景
-
企业级存储:
-
SAN存储广泛应用于企业数据中心,支持关键业务应用(如ERP、CRM)和数据库。
-
提供高性能、高可用性和高扩展性,满足企业级需求。
-
-
虚拟化环境:
-
在虚拟化环境中,SAN存储为虚拟机提供高性能的存储资源。
-
支持虚拟机的动态迁移和资源分配。
-
-
高性能计算(HPC):
-
SAN存储为高性能计算提供低延迟、高带宽的存储服务。
-
适用于科学计算、数据分析和图形处理等场景。
-
-
灾难恢复和备份:
-
SAN存储支持数据的远程复制和备份,确保在灾难情况下数据的安全性和可恢复性。
-
SAN存储的优势
-
高性能:提供高带宽和低延迟的数据传输,适合对性能要求极高的应用。
-
高可用性:通过冗余设计和多路径I/O,确保数据访问的高可用性。
-
集中化管理:提供集中化的管理工具,简化存储资源的配置和维护。
-
扩展性:支持大规模存储环境,可以通过增加设备或扩展柜进行扩展。
-
灵活性:支持多种协议和存储设备,适用于不同的应用场景。
SAN存储的局限性
-
成本较高:SAN存储的硬件设备(如光纤通道交换机、HBA)和软件管理工具成本较高。
-
复杂性:SAN存储的部署和管理需要专业的知识和技能,管理复杂度较高。
-
依赖网络:SAN存储的性能和可用性依赖于网络基础设施,网络故障可能影响数据访问。
总结
SAN存储是一种高性能、高可用性和高扩展性的存储解决方案,适用于企业级应用和对性能要求极高的场景。它通过专用的网络协议(如光纤通道或iSCSI)将存储资源与服务器连接起来,提供块级存储服务。SAN存储广泛应用于企业数据中心、虚拟化环境和高性能计算等领域。
十一、存储性能的关键指标?
存储性能是衡量存储系统在处理数据读写操作时的效率和能力的重要指标。在评估存储系统(如硬盘、SSD、NAS、SAN等)时,以下是一些关键的性能指标:
1. IOPS(每秒输入输出操作次数)
-
定义:IOPS表示存储系统在单位时间内可以完成的输入输出操作次数。它是衡量存储系统性能的核心指标之一。
-
重要性:IOPS反映了存储系统在处理大量小文件或随机读写操作时的性能。高IOPS值意味着存储系统能够快速响应多个并发请求,适合数据库、虚拟化环境等对性能要求较高的场景。
-
影响因素:IOPS受存储介质(如SSD比HDD性能更高)、RAID配置、缓存策略等因素影响。
2. 吞吐量(Throughput)
-
定义:吞吐量表示存储系统在单位时间内可以传输的数据量,通常以MB/s或GB/s为单位。
-
重要性:吞吐量反映了存储系统在处理大文件或连续读写操作时的性能。高吞吐量意味着存储系统能够快速传输大量数据,适合视频编辑、大数据分析等场景。
-
影响因素:吞吐量受存储介质的带宽、网络带宽(对于网络存储)、数据块大小等因素影响。
3. 延迟(Latency)
-
定义:延迟表示从发起数据请求到数据传输完成之间的时间间隔,通常以毫秒(ms)或微秒(μs)为单位。
-
重要性:低延迟意味着存储系统能够快速响应请求,减少等待时间,提高用户体验。低延迟对于实时应用(如在线交易、实时数据分析)至关重要。
-
影响因素:延迟受存储介质类型(SSD通常延迟更低)、存储架构(如本地存储与网络存储)、网络延迟等因素影响。
4. 数据块大小(Block Size)
-
定义:数据块大小是指每次读写操作中传输的数据量大小,通常以字节(如4KB、8KB)为单位。
-
重要性:数据块大小对存储性能有显著影响。小块数据适合随机读写操作(如数据库),大块数据适合顺序读写操作(如视频流)。
-
影响因素:存储介质的特性、文件系统的设计以及应用程序的需求都会影响数据块大小的选择。
5. 缓存命中率(Cache Hit Rate)
-
定义:缓存命中率表示存储系统缓存中命中(即找到所需数据)的次数与总请求次数的比率,通常以百分比表示。
-
重要性:高缓存命中率可以显著提高存储系统的性能,因为缓存访问速度远高于磁盘访问速度。
-
影响因素:缓存大小、缓存算法(如LRU、FIFO)以及数据访问模式都会影响缓存命中率。
6. 存储容量(Capacity)
-
定义:存储容量表示存储系统可以存储的数据总量,通常以GB、TB或PB为单位。
-
重要性:虽然容量本身不直接反映性能,但足够的容量是存储系统能够正常运行的基础。容量不足可能导致性能瓶颈。
-
影响因素:存储介质的数量和类型、RAID配置(如RAID 5、RAID 6)等因素会影响可用容量。
7. 可扩展性(Scalability)
-
定义:可扩展性表示存储系统在不显著降低性能的情况下,增加存储容量或性能的能力。
-
重要性:可扩展性决定了存储系统是否能够适应未来业务增长的需求。
-
影响因素:存储架构(如分布式存储、SAN)、硬件设计(如支持扩展柜)、软件功能(如动态资源分配)等因素会影响可扩展性。
8. 可用性(Availability)
-
定义:可用性表示存储系统在正常运行时间内可以访问数据的比例,通常以百分比表示(如99.99%)。
-
重要性:高可用性确保数据在硬件故障、网络问题或其他意外情况下仍然可用。
-
影响因素:冗余设计(如RAID、多路径I/O)、故障切换机制、备份和恢复策略等因素会影响可用性。
9. 数据一致性(Data Consistency)
-
定义:数据一致性表示存储系统在多个副本之间保持数据同步和一致性的能力。
-
重要性:数据一致性对于分布式存储系统(如NAS、SAN)和多副本环境(如数据库集群)至关重要,确保数据的准确性和完整性。
-
影响因素:同步机制(如同步复制、异步复制)、缓存策略、网络延迟等因素会影响数据一致性。
10. 能耗(Power Consumption)
-
定义:能耗表示存储系统在运行过程中消耗的电能,通常以瓦特(W)为单位。
-
重要性:低能耗意味着更低的运营成本和更高的能效比,对于大规模数据中心尤为重要。
-
影响因素:存储介质的类型(SSD比HDD能耗更低)、硬件设计、节能模式等因素会影响能耗。
总结
存储性能的评估需要综合考虑多个关键指标,包括IOPS、吞吐量、延迟、数据块大小、缓存命中率、存储容量、可扩展性、可用性、数据一致性和能耗。不同的应用场景对这些指标的重视程度可能不同。例如:
-
数据库和虚拟化环境:更关注IOPS和低延迟。
-
大数据和视频编辑:更关注吞吐量和数据块大小。
-
企业级存储:更关注可用性、可扩展性和数据一致性。
在选择存储系统时,应根据具体需求和预算,权衡这些性能指标,以选择最适合的存储解决方案。
十二、什么是IPMI?
IPMI(Intelligent Platform Management Interface,智能平台管理接口) 是一种标准化的硬件接口规范,用于管理和监控服务器及其他计算设备的硬件状态。IPMI允许系统管理员在操作系统之外的层级上对服务器进行远程管理和故障排除,即使在操作系统崩溃或无法启动时,也能通过IPMI进行操作。
IPMI的主要功能
-
硬件监控:
-
监控服务器的硬件状态,包括温度、电压、风扇转速、电源状态等。
-
提供系统事件日志(SEL),记录硬件事件和错误,帮助管理员快速定位问题。
-
-
远程管理:
-
支持远程开关机、重启、设置BIOS等操作。
-
提供虚拟控制台访问功能,允许管理员远程访问服务器的控制台。
-
-
带外管理:
-
IPMI通过独立的网络接口(如RJ45网口)进行通信,与服务器的主网络接口分离,即使服务器操作系统无法启动,IPMI仍然可以正常工作。
-
-
固件更新:
-
允许通过网络更新系统固件和BIOS。
-
-
安全性:
-
支持多种身份验证机制和加密通信,确保远程管理的安全性。
-
IPMI的优势
-
独立于操作系统:IPMI在主机系统外部运行,不受操作系统状态的影响。
-
远程管理能力:管理员可以通过网络远程访问服务器,进行日常维护和故障排查。
-
提高可靠性:即使操作系统崩溃,管理员仍然可以通过IPMI访问和管理服务器。
-
减少宕机时间:快速诊断和解决问题,减少系统停机时间。
-
节能与成本效益:通过实时监控服务器状态,IPMI可以帮助管理员优化能源使用,降低运营成本。
IPMI的应用场景
-
数据中心管理:管理员可以通过IPMI远程管理大量服务器,减少现场干预需求。
-
故障诊断:在服务器硬件故障或操作系统崩溃时,IPMI可以提供远程诊断工具。
-
操作系统安装:通过IPMI的虚拟介质功能,管理员可以远程加载ISO镜像文件并进行操作系统的安装。
-
电源管理:IPMI可以远程控制服务器电源,进行安全关机或重启操作。
IPMI的安全性
虽然IPMI提供了强大的管理功能,但也存在安全风险,如未经授权的访问和数据泄露。因此,IPMI接口通常会引入多种安全特性,包括:
-
身份验证和访问控制:支持基于角色的访问控制,限制未授权访问。
-
加密通信:使用SSL/TLS等加密协议保护数据传输。
-
日志记录和监控:记录所有管理操作,便于追踪和分析潜在的安全问题。
总结
IPMI是一种用于服务器硬件管理和监控的标准接口,提供了远程监控、硬件监控、带外管理等功能,广泛应用于数据中心和企业级服务器管理中。它通过独立于操作系统的管理通道,显著提高了服务器的可靠性和可用性,同时也提供了多种安全机制以保护管理接口。
相关文章:

第三阶段-产品方面的技术疑难
一、虚拟机和容器的区别? 虚拟机(Virtual Machine,VM)和容器(Container)都是用于隔离和运行应用程序的技术,但它们在实现方式、性能、资源消耗和适用场景上有显著区别。以下是虚拟机和容器的主…...

safetensors PyTorchModelHubMixin 加载模型
2025.03.03测试ok from safetensors.torch import load_fileimport yamlwith open("configs/maggie_image.yaml", r, encodingutf8) as file: # utf8可识别中文data yaml.safe_load(file)class Config:def __init__(self, **kwargs):for key, value in kwargs.item…...

解锁GPM 2.0「卡顿帧堆栈」|代码示例与实战分析
每个游戏开发者都有一个共同的愿望,那就是能够在无需复现玩家反馈的卡顿现象时,快速且准确地定位卡顿的根本原因。为了实现这一目标,UWA GPM 2.0推出了全新功能 - 卡顿帧堆栈,旨在为开发团队提供高效、精准的卡顿分析工具。在这篇…...
Transformer架构
核心原理 自注意力机制 通过计算输入序列中每个位置与其他位置的关联权重(Query-Key匹配),动态聚合全局信息,解决了传统RNN/CNN的长距离依赖问题。 实现公式:Attention(Q,K,V)softmax(QKTdk)VAttention(…...
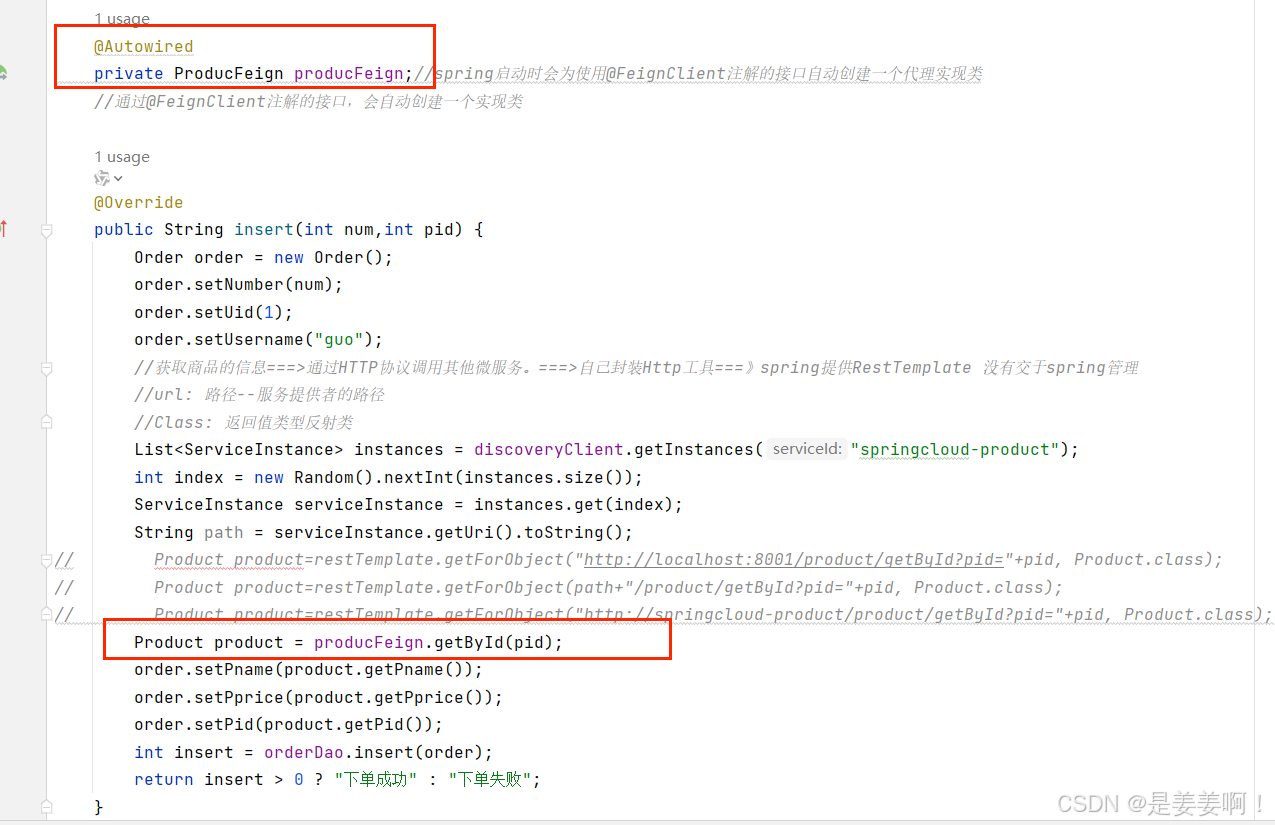
微服务,服务治理nacos,负载均衡LOadBalancer,OpenFeign
1.微服务 简单来说,微服务架构风格[1]是一种将一个单一应用程序开发为一组小型服务的方法,每个服务运行在 自己的进程中,服务间通信采用轻量级通信机制(通常用HTTP资源API)。这些服务围绕业务能力构建并 且可通过全自动部署机制独立部署。这…...

服务器租用:静态BGP和动态BGP分别指什么?
今天小编主要来带大家一起了解一下静态BGP和动态BGP分别是指什么? BGP主要是用在不同网络之间进行交换路由信息的协议,通常是用在互联网当中,而静态BGP和动态BGP是两种不同的方法来配置BGP路由,静态BGP路由是由手动配置的…...

栈和队列的模拟实现
文章目录 一. 回顾栈和队列二. stack的模拟实现stack.hstack.cpp 三. queue的模拟实现queue.htest.cpp 四. 了解dequeuevector和list都有各自的缺陷deque 总结 一. 回顾栈和队列 回顾一下栈和队列 栈:stack:后进先出 _ 队列:queue…...
:从写作到个人IP的体系化构建(完结篇))
CSDN博客写作教学(五):从写作到个人IP的体系化构建(完结篇)
导语 (第一篇)Markdown编辑器基础 (第二篇)Markdown核心语法 (第三篇)文章结构化思维 (第四篇)标题优化与SEO实战 通过前四篇教程,你已掌握技术写作的“术”——排版、标题、流量与数据。但真正的价值在于将技能升维为“道”:用技术博客为支点,撬动个人品牌与职业发…...

Django 项目模块化开发指南:实现 Vue 风格的组件化
在 Django 项目中,我们经常需要 复用 HTML 代码,避免重复编写相同的模板。例如,博客系统中,博客列表页 和 文章详情页 可能都有相同的 导航栏、模态框、页脚 等。如何像 Vue 一样进行 模块化开发,让代码更加清晰、可维护呢? 本文将详细介绍 Django 的模板继承 和 {% incl…...

unity pico开发 四 物体交互 抓取 交互层级
文章目录 手部设置物体交互物体抓取添加抓取抓取三种类型抓取点偏移抓取事件抓取时不让物体吸附到手部 射线抓取交互层级 手部设置 为手部(LeftHandController)添加XRDirInteractor脚本 并添加一个球形碰撞盒,勾选isTrigger,调整大小为0.1 …...

opencv 模板匹配方法汇总
在OpenCV中,模板匹配是一种在较大图像中查找特定模板图像位置的技术。OpenCV提供了多种模板匹配方法,通过cv2.matchTemplate函数实现,该函数支持的匹配方式主要有以下6种,下面详细介绍每种方法的原理、特点和适用场景。 1. cv2.T…...

【PromptCoder + Cursor】利用AI智能编辑器快速实现设计稿
【PromptCoder Cursor】利用AI智能编辑器快速实现设计稿 官网:PromptCoder 在现代前端开发中,将设计稿转化为可运行的代码是一项耗时的工作。然而,借助人工智能工具,这一过程可以变得更加高效和简单。本文将介绍如何结合 Promp…...

MySQL面试01
MySQL 索引的最左原则 🍰 最左原则本质 ͟͟͞͞( •̀д•́) 想象复合索引是电话号码簿! 索引 (a,b,c) 的排列顺序: 先按a排序 → a相同按b排序 → 最后按c排序 生效场景三连: 1️⃣ WHERE a1 ✅ 2️⃣ WHERE a1 AND b2 ✅ 3️…...

webpack一篇
目录 一、构建工具 1.1简介 二、Webpack 2.1概念 2.2使用步骤 2.3配置文件(webpack.config.js) mode entry output loader plugin devtool 2.4开发服务器(webpack-dev-server) grunt/glup的对比 三、Vite 3.1概念 …...

健康饮食,健康早餐
营养早餐最好包含4大类食物:谷薯类;碳水;蛋白质;膳食纤维。 1.优质碳水 作用:提供持久的能量,避免血糖大幅波动等 例如:全麦面包、红薯🍠、玉米🌽、土豆🥔、…...

常见的排序算法 【复习笔记】
注意: 1. 后面的排序算法实现都只考虑升序,对于逆序,只有知道原理,实现很容易 2. 案例题: 题目描述:将读入的 N 个数从小到大输出 ( 1 < N <10e5) 输入描述:第一行一个正整数 N 第二行…...

【经验分享】Ubuntu20.04 vmware虚拟机存储空间越来越小问题(已解决)
【经验分享】Ubuntu20.04 vmware虚拟机存储空间越来越小问题(已解决) 前言一、问题分析二、解决方案 前言 我们在使用虚拟机过程中,经常会碰到即使删除了一些文件,但是存储空间还是越来越小的问题。今天我们来解决下这个问题。 一…...

Jenkins-自动化部署-通知
场景 使用jenkins部署,但有时不能立马部署,需要先通知相关人员,再部署,如果确实不能部署,可以留时间撤销。 方案 1.开始前我们添加,真正开始执行的等待时间;可供选择(Choice Param…...

Qt 文件操作+多线程+网络
文章目录 1. 文件操作1.1 API1.2 例子1,简单记事本1.3 例子2,输出文件的属性 2. Qt 多线程2.1 常用API2.2 例子1,自定义定时器 3. 线程安全3.1 互斥锁3.2 条件变量 4. 网络编程4.1 UDP Socket4.2 UDP Server4.3 UDP Client4.4 TCP Socket4.5 …...

《基于Hadoop的青岛市旅游景点游客行为分析系统设计与实现》开题报告
目录 一、选题依据 1.选题背景 2.国内外研究现状 (1)国内研究现状 (2)国外研究现状 3.发展趋势 4.应用价值 二、研究内容 1.学术构想与思路 2. 拟解决的关键问题 3. 拟采取的研究方法 4. 技术路线 (1)旅游前准备阶段 …...

pycharm debug卡住
pycharm debug时一直出现 collecting data, 然后点击下一行就卡住。 勾选 Gevent compatible解决 https://stackoverflow.com/questions/39371676/debugger-times-out-at-collecting-data...

MyBatis-Plus 元对象处理器 @TableField注解 反射动态赋值 实现字段自动填充
目录 🌰 举个直观例子 🛠️ 核心作用原理 📜 代码级工作流程 📜 完整代码 🔍 关键概念拆解 ⚠️ 常见问题排查 🌟 设计意义 🌰 举个直观例子 package work.dduo.ans.domain;import com.b…...

ISP 常见流程
1.sensor输出:一般为raw-OBpedestal。加pedestal避免减OB出现负值,同时保证信号超过ADC最小电压阈值,使信号落在ADC正常工作范围。 2. pedestal correction:移除sensor加的基底,确保后续处理信号起点正确。 3. Linea…...

Python Cookbook-2.27 从微软 Word 文档中抽取文本
任务 你想从 Windows 平台下某个目录树中的各个微软 Word 文件中抽取文本,并保存为对应的文本文件。 解决方案 借助 PyWin32 扩展,通过COM 机制,可以利用 Word 来完成转换: import fnmatch,os,sys,win32com.client wordapp w…...

java数据结构_Map和Set(一文理解哈希表)_9.3
目录 5. 哈希表 5.1 概念 5.2 冲突-概念 5.3 冲突-避免 5.4 冲突-避免-哈希函数的设计 5.5 冲突-避免-负载因子调节 5.6 冲突-解决 5.7 冲突-解决-闭散列 5.8 冲突-解决-开散列 / 哈希桶 5.9 冲突严重时的解决办法 5. 哈希表 5.1 概念 顺序结构以及平衡树中&#x…...

基于SpringBoot的“数据驱动的资产管理系统站”的设计与实现(源码+数据库+文档+PPT)
基于SpringBoot的“数据驱动的资产管理系统站”的设计与实现(源码数据库文档PPT) 开发语言:Java 数据库:MySQL 技术:SpringBoot 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 系统功能结构图 局部E-R图 系统登录界…...

excel 斜向拆分单元格
右键-合并单元格 右键-设置单元格格式-边框 在设置好分割线后,你可以开始输入文字。 需要注意的是,文字并不会自动分成上下两行。 为了达到你期望的效果,你可以通过 同过左对齐、上对齐 空格键或使用【AltEnter】组合键来调整单元格中内容的…...

深入理解推理语言模型(RLM)
大语言模型从通用走向推理,万字长文解析推理语言模型,建议收藏后食用。 本文基于苏黎世联邦理工学院的论文《Reasoning Language Models: A Blueprint》进行整理,你将会了解到: 1、RLM的演进与基础:RLM融合LLM的知识广…...

2025年具有百度特色的软件测试面试题
百度业务场景 如何测试一个高并发的搜索系统(如百度搜索)?如何测试一个在线地图服务(如百度地图)?如何测试一个大型推荐系统(如百度推荐)的性能?百度技术栈 你对百度的 PaddlePaddle 框架有了解吗?如何测试基于 PaddlePaddle 的服务?如何测试百度云的 API 服务?你对…...

HOW - 在Windows浏览器中模拟MacOS的滚动条
目录 一、原生 CSS 代码实现模拟 macOS 滚动条额外优化应用到某个特定容器 二、使用第三方工具/扩展 如果你想让 Windows 里的滚动条 模拟 macOS 的效果(细窄、圆角、隐藏默认轨道)。 可以使用以下几种方案: 一、原生 CSS 代码实现 模拟 m…...