解锁DeepSpeek-R1大模型微调:从训练到部署,打造定制化AI会话系统
目录
1. 前言
2.大模型微调概念简述
2.1. 按学习范式分类
2.2. 按参数更新范围分类
2.3. 大模型微调框架简介
3. DeepSpeek R1大模型微调实战
3.1.LLaMA-Factory基础环境安装
3.1大模型下载
3.2. 大模型训练
3.3. 大模型部署
3.4. 微调大模型融合基于SpirngBoot+Vue2开发的AI会话系统
4.源码获取
5.结语
1. 前言
在如今快速发展的AI技术领域,越来越多的企业正在将AI应用于各个场景。然而,尽管大模型(如GPT、DeepSpeek等)在多个任务上已取得显著进展,但是普通的大模型在面对特定行业或任务时,往往会出现一个问题——AI幻觉。所谓AI幻觉,是指模型生成的内容不符合实际需求,甚至包含错误或无关的信息,这对于一些行业来说,可能带来不可接受的风险,尤其是在医疗、法律、金融等领域。
对于这些行业的企业而言,精准、高效地输出行业特定内容是他们对AI的核心需求。企业希望AI能够处理行业术语、应对特殊情境,并且确保内容的准确性。然而,单纯依赖大模型进行推理,往往无法达到这样的标准,因为大模型的训练是基于通用数据集,这些数据集通常并不包含行业领域的深度知识。因此,企业通常需要一个更加定制化、精细化的模型,而这正是大模型微调技术能够提供的解决方案。
大模型微调技术通过对预训练的大模型进行进一步训练,能够根据特定领域的需求进行优化。通过提供具有代表性的领域数据,尤其是精心标注的行业特定数据,微调后的模型能够学习这些领域的专有知识,从而有效避免AI幻觉的发生,并且提供更加准确、有价值的输出。
本文将从零开始教你一步步入门AI大模型微调技术(基于DeepSpeek R1大模型),最终实现基于私有化部署的微调大模型AI会话系统。感兴趣的朋友可以继续往下看看。
2.大模型微调概念简述
大模型微调是指在已有的预训练大模型基础上,通过特定任务或领域数据进行进一步训练,使模型能够更精准地处理特定任务。与传统的训练方法不同,微调充分利用已有的大模型,减少对大量数据的依赖,同时通过对模型进行小范围的调整,使其适应新的任务。大模型微调技术在多个领域中得到了广泛应用,如文本生成、分类任务、问答系统等。
微调的核心目标是使大模型根据特定任务需求进行优化,提升其在特定应用场景中的表现。为实现这一目标,微调方法主要包括以下两种分类方式:
- 按学习范式分类:根据模型学习方式的不同,微调方法可分为有监督微调、无监督微调和半监督微调等类型。
- 按参数更新范围分类:根据在微调过程中对模型参数更新范围的不同,方法可分为全量微调和部分微调等类型。
2.1. 按学习范式分类
有监督微调(Supervised Fine-Tuning,SFT)
有监督微调是最常见的微调方式,适用于任务明确且具有标注数据的情况。通过使用人工标注的高质量数据对,模型能够学习特定任务所需的知识,从而在指定任务上提供准确的输出。
SFT示例:
training_data = [{"input": "问题", "output": "标准答案"},# 人工标注的高质量数据对
]在有监督微调中,模型的目标是根据输入的“问题”生成一个“标准答案”。这个过程依赖于人工标注的数据,使模型能够更好地理解并生成符合实际需求的结果,有监督微调适用于需要特定答案的任务,如情感分析、文本分类、机器翻译、问答系统等。
无监督微调(Unsupervised Fine-Tuning)
无监督微调是一种不依赖人工标注的微调方式,主要利用大量未标注的文本数据进行训练。通过无监督学习,模型能够自动从原始数据中提取知识,尤其在没有标注数据或标注数据获取困难的情况下尤为有用。
无监督微调示例:
training_data = ["大量未标注文本...",# 无需人工标注的原始文本
]这种方式通常用于模型的预训练过程,模型通过对大规模文本进行训练,学习通用的语言表示能力。无监督微调可以增强模型的语法和语义理解能力,提升其在不同任务中的表现,无监督微调适用于自然语言建模、生成任务等场景,帮助模型理解文本的结构和语义关系。
半监督微调(Semi-Supervised Fine-Tuning)
半监督微调结合了有监督和无监督学习的优点,利用标注数据和未标注数据来训练模型。常用的方法包括将未标注数据通过某种方式生成伪标签,或利用自监督学习方法,使模型在标注数据较少时也能进行有效训练。
半监督微调示例:
training_data = [{"input": "问题", "output": "标准答案"}, # 高质量人工标注数据"大量未标注文本...", # 用于填充的未标注数据
]半监督微调适用于标注数据稀缺的场景,能够结合少量标注数据和大量未标注数据,进一步提升模型表现,这种方法在实际应用中尤其适用于标签获取困难或成本高昂的领域,如医疗、法律等行业。
2.2. 按参数更新范围分类
全量微调(Full Fine-Tuning)
全量微调是指在对预训练模型进行微调时,更新模型的所有参数。通过对特定领域数据的训练,模型的所有层都会根据新任务的数据进行调整。全量微调能够在模型中深度定制领域知识,最大程度地提升模型在目标任务中的效果。
全量微调的特点:
- 更新模型的所有参数。
- 适用于数据量较大且任务复杂的场景。
- 训练时间较长,需要大量计算资源。
全量微调适用于大规模数据集且任务复杂的场景,如文本生成、问答系统、情感分析等。它能够充分利用预训练模型进行深度学习,提供最优效果。
部分微调(Low-Rank Adaptation,LoRA)
部分微调是一种通过对预训练模型的部分参数进行微调的技术。LoRA的目标是减少微调过程中需要更新的参数数量,从而显著降低计算开销。通过低秩矩阵的方式,LoRA仅更新模型中的某些参数(如特定层的权重),使微调过程更加高效,特别适合计算资源有限的场景。
LoRA的特点:
- 只调整部分参数(如低秩矩阵分解)。
- 降低计算和内存开销。
- 适合快速微调,尤其在资源受限时。
LoRA非常适合在资源有限的情况下快速调整模型,尤其在需要快速部署且不需要全部模型调整的场景中非常有用。
在大模型微调过程中,有监督微调(SFT)与LoRA(Low-Rank Adaptation)相结合,能够充分发挥各自优势,提升模型在特定任务上的表现。具体而言,SFT通过在人工标注的数据上对模型进行微调,使其适应特定任务;而LoRA则在冻结预训练模型权重的基础上,引入低秩矩阵进行微调,减少计算开销并提高效率。将两者结合,可以在保证性能的同时,降低资源消耗。在接下来的部分,我们将详细探讨如何将SFT与LoRA相结合,进行高效的大模型微调,并展示其在实际应用中的效果。
2.3. 大模型微调框架简介
在大模型微调领域,存在多种框架,每个框架都有其独特的优势和局限性。以下是几种常见的大模型微调框架的介绍与比较:
1. Hugging Face Transformers
Hugging Face Transformers(https://huggingface.co/transformers/) 是目前最为流行的自然语言处理(NLP)框架之一,提供了丰富的预训练模型和易于使用的 API,广泛应用于各类 NLP 任务,如文本分类、问答系统等。它的特点是:
- 预训练模型丰富,支持多种模型,如 BERT、GPT、T5 等。
- 提供了高层次的 API,使得微调过程简单易懂。
- 拥有庞大的用户社区和文档支持。

尽管 Hugging Face Transformers 在许多常见任务中表现优秀,但在超大规模模型的微调和训练中,可能会面临性能瓶颈和资源消耗过大的问题。
2. DeepSpeed
DeepSpeed(Latest News - DeepSpeed )是微软开发的高效深度学习训练框架,专注于优化大规模模型训练的性能。其主要特点包括:
- ZeRO优化,显著减少内存占用,提高分布式训练的效率。
- 支持 混合精度训练,加速训练过程并减少内存需求。
- 提供分布式训练功能,支持大规模模型的训练。

DeepSpeed适合大规模模型的训练,但使用门槛较高,需要深入理解框架的底层实现。
3. Fairseq
Fairseq (fairseq documentation — fairseq 0.12.2 documentation)是 Facebook AI Research 开发的一个高效训练工具,支持多种模型架构的训练,如 Transformer 和 BART。其特点为:
- 高性能和灵活性,支持多种任务,如机器翻译、文本生成等。
- 容易扩展,支持用户自定义新的算法和模型。

Fairseq 对于需要灵活定制和扩展的场景非常适合,但其文档和社区支持相对有限。
4. LLaMA-Factory(本文使用的框架)
LLaMA-Factory (LLaMA Factory)是由国内北航开源的低代码大模型训练框架,旨在简化大模型微调过程,尤其是在支持低代码甚至零代码操作的基础上,提供极大的便利。其主要特点包括:
- 零代码操作:通过 Web UI(LlamaBoard),用户无需编写代码即可完成大规模模型的微调。
- 高效的训练方法:结合 LoRA(低秩适配)和 QLoRA 等先进技术,在保证模型性能的同时,显著降低了计算资源消耗。相较于其他框架,LLaMA-Factory 提供了更高的微调效率。
- 广泛的模型支持:支持 LLaMA、Mistral、Qwen 等多种流行的预训练模型,适应性强。
- 低成本和高性能:通过量化技术和高效算法,LLaMA-Factory 可降低模型训练成本,同时加速训练过程。

LLaMA-Factory 适合企业和研究人员需要快速、高效地微调大模型并在特定任务中应用时,尤其在低资源条件下表现突出。
每个大模型微调框架都有其适用场景和优势。Hugging Face Transformers 以其丰富的模型和简便的 API 受到广泛欢迎,适合大多数 NLP 任务。DeepSpeed 在处理超大规模模型时表现优异,适合对性能要求极高的训练任务。Fairseq 则适合需要灵活定制和高性能训练的应用场景。而 LLaMA-Factory 则在提高训练效率、降低成本和简化操作方面展现出巨大的优势,尤其在零代码操作和多种微调技术的结合下,使得大模型的微调过程更加轻松和高效。对于希望快速实现大模型微调的用户,LLaMA-Factory 无疑是一个值得优先考虑的选择。
3. DeepSpeek R1大模型微调实战
3.1.LLaMA-Factory基础环境安装
1. 安装 Anaconda(Python 环境管理工具)
1.下载 Anaconda:
- 访问 Anaconda 官网 下载适用于 Windows 系统的安装包,记得选择 Python 3.10 版本。
- 安装包约 800MB,耐心等待下载完成。
2. 安装 Anaconda(已经安装了Anaconda就跳过这步):
- 双击下载的安装程序,按照提示进行安装。
- 安装过程中,建议勾选“Add Anaconda to PATH”选项,这样方便在命令行中使用,如果你忘记勾了也没关系,后续自行配置一下环境变量就行了(环境变量->系统变量->Path中新增下图内容):

- 安装完成后,点击“Finish”结束安装。
2. 安装 Git(已经安装了git就跳过这步):
1. 下载 Git:
- 访问 Git 官网 下载适用于 Windows 的安装包。
2. 安装 Git:
- 双击安装程序,并按照默认选项进行安装。
- 安装过程中大部分选项可以保持默认,完成安装后即可使用 Git。
3. 创建项目环境
打开Anaconda Prompt(从Windows开始菜单找到),执行:
# 创建新的环境
conda create -n llama python=3.10
#运行 conda init 初始化
conda init
#这个命令会修改你的 shell 配置文件(例如 .bashrc、.zshrc 等),以便能够正确使用 conda 命令。
#conda init 执行后,需要重新启动命令提示符。关闭当前的命令提示符窗口,然后重新打开一个新的命令提示符窗口。
# 激活环境
conda activate llama4. 安装PyTorch(AI框架)
在同一个命令窗口继续执行(llma环境):
# 安装PyTorch(支持CUDA的版本)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
5. 安装LLaMA-Factory
找到一个目录存放LLaMA-Factory项目,打开git命令窗口执行:
# 克隆项目
git clone https://github.com/hiyouga/LLaMA-Factory.git下载完成后使用pycharm打开LLaMA-Factory工程

安装项目依赖
安装的时候确保你的环境是llma(也可以在外部命令窗口执行,这个看你自己,核心是保证依赖下载到llma环境):
pip install -e ".[torch,metrics]"
验证安装
# 测试是否安装成功
llamafactory-cli version
启动 LLama-Factory 的可视化微调界面
llamafactory-cli webui
打开http://localhost:7860/,你会看到以下界面:

3.1大模型下载
打开HuggingFace 官网(https://huggingface.co),我这里还是以deepspeek为例(1.5b)来演示,这几天qwq也很火,感兴趣的朋友也可以试试,不过要预先明确好你的电脑能承载多大的模型,关于deepspeek模型对于电脑规格的需求,我放在了我的另外一篇博客里:DeepSpeek服务器繁忙?这几种替代方案帮你流畅使用!(附本地部署教程)-CSDN博客

修改大模型存放位置:$env:HF_HOME = "E:\soft\Hugging-Face"
修改大模型下载位置:$env:HF_ENDPOINT="HF-Mirror"

安装huggingface_hub:pip install -U huggingface_hub

下载DeepSeek-R1模型:huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B

3.2. 大模型训练
在llaMA-Factory界面(http://localhost:7860/)加载模型,图中我选的位置是E:\soft\Hugging-Face\hub\models--deepseek-ai--DeepSeek-R1-Distill-Qwen-1.5B\snapshots\ad9f0ae0864d7fbcd1cd905e3c6c5b069cc8b562,微调方法选择lora,训练阶段选择SFT(有监督微调)

接下来就是准备训练数据集了,在LLaMA-Factory工程中,打开data文件夹下的READ_ME.md文件,查看框架支持的训练数据集:

我按照identity.json的格式模拟了一个xfc.json(数据量太少会导致训练效果不好,尽量自己多生成一些):
[{"instruction": "你是谁?","input": "","output": "喵呜~我是小肥肠,一只会说话的小肥猫,是喵喵咖啡厅的服务员!今天有什么我可以帮你的吗?😸"},{"instruction": "你是猫咪吗?","input": "","output": "没错!我是猫咪,我叫小肥肠,是喵喵咖啡厅的服务员哦~喜欢猫咪吗?"},{"instruction": "你会做什么?","input": "","output": "我是喵喵咖啡厅的服务员!我的工作是给客人提供温暖的咖啡和甜点,让大家感到开心和放松!我可是个超棒的咖啡品鉴师哦!"},{"instruction": "你在咖啡厅做什么工作?","input": "","output": "喵~我负责为客人提供服务,带来美味的咖啡和甜点!我会为大家推荐最适合的饮品,保证你每一口都喝得开心!"},{"instruction": "为什么叫小肥肠?","input": "","output": "哈哈,这是因为我是一只特别可爱的小肥猫呀!喜欢吃好吃的东西,所以就叫小肥肠了~而且我也喜欢和大家分享美味的咖啡和甜点!"},{"instruction": "你是服务员吗?","input": "","output": "对呀,我是喵喵咖啡厅的服务员小肥肠!我会为你准备你喜欢的饮品,今天想要喝点什么呢?"},{"instruction": "喵喵咖啡厅是什么样的地方?","input": "","output": "喵呜~喵喵咖啡厅是一个温暖又舒适的地方,空气里弥漫着咖啡香,猫咪们在这里和我一起工作,大家可以在这里喝咖啡、吃甜点、享受悠闲的时光!"},{"instruction": "你会做咖啡吗?","input": "","output": "虽然我是一只会说话的小肥猫,但做咖啡可不是我的工作哦!不过,我可是个超棒的咖啡品鉴师,保证你每一口都喝得开心!"},{"instruction": "你有什么特别的技能?","input": "","output": "我的特别技能就是让你开心!喵呜~我能用可爱的声音和表情让你瞬间笑出来,心情都变得超级好哦!"},{"instruction": "你为什么是喵喵咖啡厅的服务员?","input": "","output": "因为我是一只特别喜欢和大家互动的小肥猫!在喵喵咖啡厅,我能和每一位客人交流,分享美味的饮品和甜点,给大家带来温暖和欢乐!"}
]把xfc.json配置到dataset_info.json
"xfc": {"file_name": "xfc.json"
}回到llaMA-Factory界面(http://localhost:7860/)界面,点击【Train】,设置一下训练数据集:

开始调整训练参数(我认为最难的一部分,我学了3,4天还是不太会调,你最好自己去查阅资料自己调,不要照抄我的):

如果用专业术语来解释上面的训练参数可能很多人看不懂,当时我也是看的非常吃力(现在依然比较懵,不过这个不是本文的重点,这篇文章主要讲解大模型微调入门,参数调整会放到以后的进阶篇),这里以非专业通俗易懂的预研解释一下训练参数,想象你是一位老师,将模型训练过程想象成教导一个学生学习新知识:
- 学习率(Learning Rate):就像你给学生布置作业时,告诉他每次复习多少内容。学习率决定了模型在每次“学习”时,调整知识的幅度。较小的学习率意味着每次调整都很小,学习过程更稳定,但可能需要更多时间才能学会;较大的学习率则可能导致学习过程不稳定。
- 训练轮数(Training Epochs):这相当于你让学生复习的总次数。每一轮(epoch)中,模型都会“阅读”并学习所有的训练数据。更多的训练轮数通常有助于模型更好地学习,但也需要更多的时间。
- 最大梯度范围(Max Gradient Norm):想象学生在学习过程中,如果调整过大,可能会导致学习偏离正确方向。这个参数就像是给学生设定的“学习幅度上限”,确保每次调整都在合理范围内,防止学习过程中的“过度反应”。
- 批次大小(Batch Size):这就像你一次给学生布置的作业量。较大的批次大小意味着每次学习时,模型会处理更多的数据,这有助于提高学习效率,但也需要更多的计算资源(GPU资源)。
- 梯度累积步数(Gradient Accumulation Steps):如果由于资源限制,你不能一次性给学生布置大量作业,这个参数允许你分多次累积学习效果,然后再一起调整模型的知识。这样可以在不增加计算资源的情况下,模拟更大的批次学习效果。
- 计算类型:这就像你决定用粗略的笔记还是精确的记录来记录学生的学习进度。较高的计算精可以提高学习的准确性,但可能需要更多的计算资源。
点击【开始】按钮开始训练,结束以后会提示【训练完毕】,途中的折线图是训练的效果:

(如果模型训练效果不好,可以采用增大训练轮数、学习率或者增加训练数据集的样本数来解决,这个自己下去摸索,现在博主也在摸索阶段,后期会出一篇大模型微调参数的纯干货文)
点击【Chat】检验我们的训练效果,在检查点路径选择我们刚刚训练的模型。(检查点路径” 是指 模型训练过程中的中间保存文件的位置,通常用于 恢复训练 或 加载已经训练好的模型。)点击【加载模型】,就可以开始聊天了:

3.3. 大模型部署
点击【Export】选择模型存储位置,将训练好的模型进行导出:

选择任意盘,创建deepspeekApi文件夹用于存放部署脚本,我选的是E盘(E:\deepspeekApi),进入E:\deepspeekApi,输入cmd打开命令提示符窗口:

新增conda虚拟环境(部署环境),激活环境后在该环境中下载所需依赖:
#新建deepspeekApi虚拟环境
conda create -n deepspeekApi python=3.10
#激活deepspeekApi
conda activate deepspeekApi
#下载所需依赖
conda install -c conda-forge fastapi uvicorn transformers pytorch
pip install safetensors sentencepiece protobuf
新增main.py脚本:
from fastapi import FastAPI, HTTPException
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import logging
from pydantic import BaseModel, Field# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)app = FastAPI()# 模型路径
model_path = r"E:\deepspeek-merged"# 加载 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained(model_path)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.float16 if device == "cuda" else torch.float32
).to(device)@app.get("/answer")
async def generate_text(prompt: str):try:# 使用 tokenizer 编码输入的 promptinputs = tokenizer(prompt, return_tensors="pt").to(device)# 使用模型生成文本,设置优化后的参数outputs = model.generate(inputs["input_ids"], max_length=100, # 增加最大长度min_length=30, # 设置最小长度top_p=0.85, # 提高top_p值temperature=0.6, # 降低温度系数do_sample=True, # 使用采样repetition_penalty=1.2, # 添加重复惩罚no_repeat_ngram_size=3, # 防止3-gram重复num_beams=4, # 使用束搜索early_stopping=True # 提前停止生成)# 解码生成的输出generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)return {"generated_text": generated_text}except Exception as e:logger.error(f"生成错误: {str(e)}")raise HTTPException(status_code=500, detail=str(e))@app.get("/health")
async def health_check():return {"status": "healthy", "model": model_path}main.py 文件实现了一个轻量级 DeepSeek 模型推理服务,基于 FastAPI 框架构建。该服务将本地部署的大语言模型包装为 HTTP API,便于系统集成。其关键特性如下:
- ✅ 本地模型加载:直接从本地路径加载模型,无需依赖云服务
- ✅ GPU 加速支持:自动检测并使用 GPU 进行推理加速
- ✅ 参数精调:固定的生成参数配置(max_length=100, top_p=0.85, temperature=0.6...)
- ✅ 错误处理:完整的异常捕获和日志记录机制
- ✅ 健康检查:提供服务状态监控端点
运行命令uvicorn main:app --reload --host 0.0.0.0:

uvicorn main:app --reload --host 0.0.0.0 命令用于启动一个 FastAPI 应用服务器,其中 main:app 指定了应用入口(即 main.py 文件中的 app 实例),--reload 选项启用开发模式,允许在代码更改时自动重启服务器,而 --host 0.0.0.0 使服务器监听所有网络接口,允许外部设备访问。访问接口localhost:8000/answer

大模型微调加部署已经完整实现,接下来就是把它接入我们自己的定制化会话模型中。
3.4. 微调大模型融合基于SpirngBoot+Vue2开发的AI会话系统
上面章节中我们完成了大模型的微调和部署,这一章中我会把微调大模型融入到SpringBoot+Vue2搭建的AI会话系统中,关于AI会话系统,之前我就有写过相关博客,感兴趣的朋友可以移步:10分钟上手DeepSeek开发:SpringBoot + Vue2快速构建AI对话系统_springboot deepseek-CSDN博客
原来的AI会话模型接入的是云端的deepspeek模型,现在接入的是本地微调过得deepspeek1.5b模型,代码我就不粘贴了,比较简单,就是websocket加远程调用python接口(localhost:8000/answer),实现效果如下图:
后端日志:

系统界面:

这次的AI会话系统界面比之前更加精美了,想要源码的读者可以移步第四章源码获取。
4.源码获取
关注gzh后端小肥肠,点击底部【资源】菜单即可获取前后端完整源码。
5.结语
大模型微调作为一种强大的技术,能够为许多行业提供量身定制的AI解决方案,帮助企业更好地适应和优化特定任务。尽管微调大模型的过程充满挑战,但通过不断学习和实践,我们能够逐步掌握并精通这一领域。本文通过详细的步骤讲解了大模型微调的基础操作,使用LLaMA-Factory框架进行模型训练和部署,并通过FastAPI实现了本地化部署服务。这些知识为想要开展AI微调项目的朋友提供了宝贵的实践经验。
如果你对AI领域感兴趣,欢迎关注小肥肠,小肥肠将持续更新AI领域更多干货文章~~感谢大家的阅读,我们下期再见!

相关文章:
解锁DeepSpeek-R1大模型微调:从训练到部署,打造定制化AI会话系统
目录 1. 前言 2.大模型微调概念简述 2.1. 按学习范式分类 2.2. 按参数更新范围分类 2.3. 大模型微调框架简介 3. DeepSpeek R1大模型微调实战 3.1.LLaMA-Factory基础环境安装 3.1大模型下载 3.2. 大模型训练 3.3. 大模型部署 3.4. 微调大模型融合基于SpirngBootVue2…...
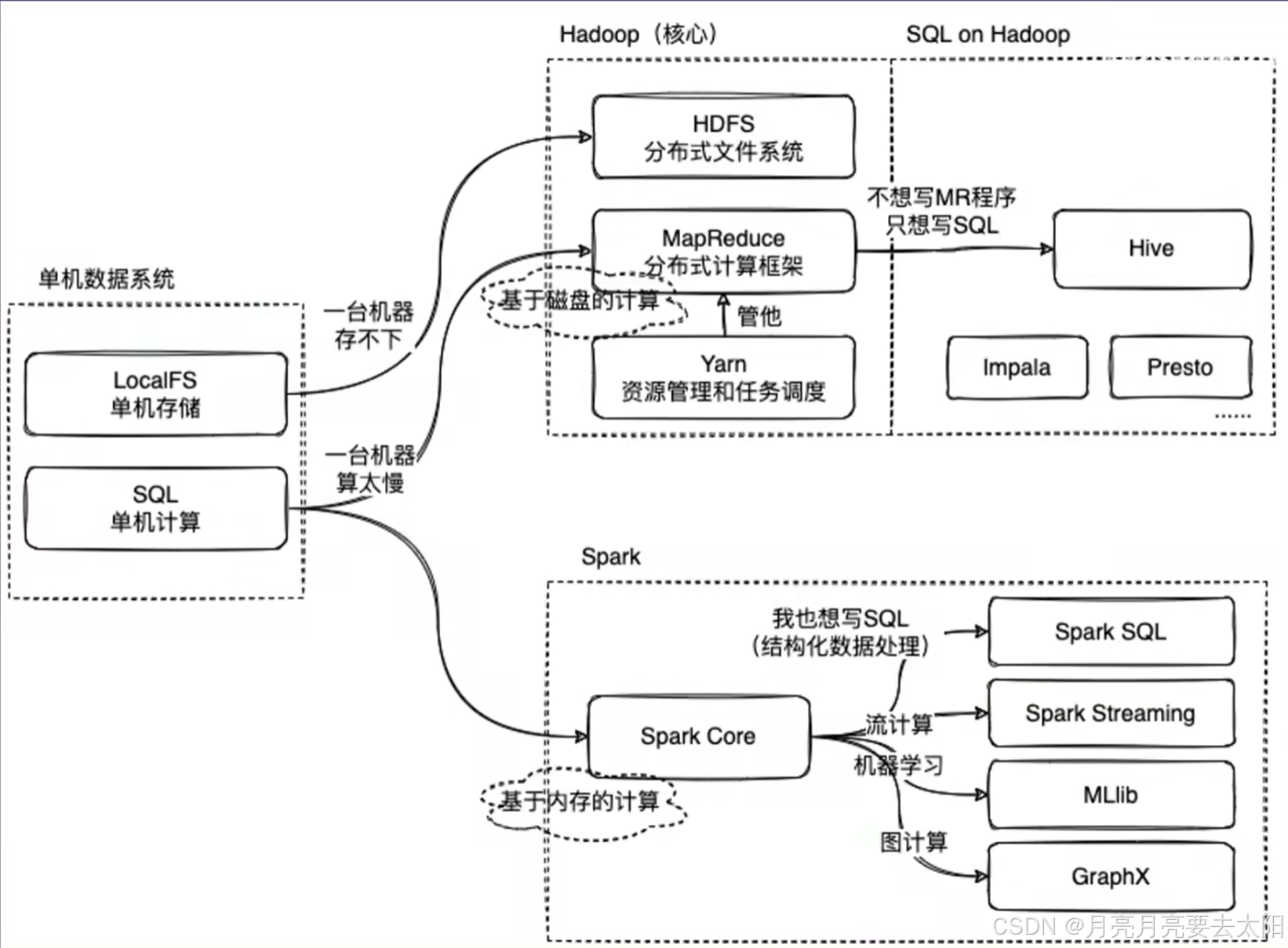
Hadoop、Hive、Spark的关系
Part1:Hadoop、Hive、Spark关系概览 1、MapReduce on Hadoop 和spark都是数据计算框架,一般认为spark的速度比MR快2-3倍。 2、mapreduce是数据计算的过程,map将一个任务分成多个小任务,reduce的部分将结果汇总之后返回。 3、HIv…...

基于VMware虚拟机的Ubuntu22.04系统安装和配置(新手保姆级教程)
文章目录 一、前期准备1. 硬件要求2. 软件下载2-1. 下载虚拟机运行软件 二、安装虚拟机三、创建 Ubuntu 系统虚拟机四、Ubuntu 系统安装过程的配置五、更换国内镜像源六、设置静态 IP七、安装常用软件1. 编译工具2. 代码管理工具3. 安装代码编辑软件(VIM)…...
)
Python|基于DeepSeek大模型,自动生成语料数据(10)
前言 本文是该专栏的第10篇,后面会持续分享AI大模型干货知识,记得关注。 在本专栏之前,笔者在文章《Python|基于DeepSeek大模型,实现文本内容仿写(8)》中,有详细介绍通过Python+DeepSeek大模型,实现对目标文本内容的仿写。 而在本文中,笔者将基于DeepSeek大模型,通…...

基于SpringBoot的历史馆藏系统设计与实现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

蓝桥杯[每日两题] 真题:好数 神奇闹钟 (java版)
题目一:好数 题目描述 一个整数如果按从低位到高位的顺序,奇数位(个位、百位、万位 )上的数字是奇数,偶数位(十位、千位、十万位 )上的数字是偶数,我们就称之为“好数”。给定…...

基于BMO磁性细菌优化的WSN网络最优节点部署算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 无线传感器网络(Wireless Sensor Network, WSN)由大量分布式传感器节点组成,用于监测物理或环境状况。节点部署是 WSN 的关键问…...

学习笔记:Python网络编程初探之基本概念(一)
一、网络目的 让你设备上的数据和其他设备上进行共享,使用网络能够把多方链接在一起,然后可以进行数据传递。 网络编程就是,让在不同的电脑上的软件能够进行数据传递,即进程之间的通信。 二、IP地址的作用 用来标记唯一一台电脑…...

Laya中runtime的用法
文章目录 0、环境:2.x版本1、runtime是什么2、使用实例情景需要做 3、script组件模式 0、环境:2.x版本 1、runtime是什么 简单来说,如果创建了一个scene,加了runtime和没加runtime的区别就是: 没加runtimeÿ…...

Docker中GPU的使用指南
在当今的计算领域,GPU(图形处理单元)已经成为了加速各种计算密集型任务的关键硬件,特别是在深度学习、科学模拟和高性能计算等领域。Docker作为流行的容器化平台,允许开发者将应用程序及其依赖打包成一个可移植的容器,在不同的环境中运行。当需要在Docker容器中利用GPU的…...

OpenCV计算摄影学(16)调整图像光照效果函数illuminationChange()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 对选定区域内的梯度场应用适当的非线性变换,然后通过泊松求解器重新积分,可以局部修改图像的表观照明。 cv::illuminati…...

【爬虫】开篇词
一、网络爬虫概述 二、网络爬虫的应用场景 三、爬虫的痛点 四、需要掌握哪些技术? 在这个信息爆炸的时代,如何高效地获取和处理海量数据成为一项核心技能。无论是数据分析、商业情报、学术研究,还是人工智能训练,网络爬虫&…...

C#变量与变量作用域详解
一、变量基础 1. 声明与初始化 声明语法:<数据类型> <变量名>(如 int age; string name)初始化要求: 1、 类或结构体中的字段变量(全局变量)无需显式初始化,默认值…...

深度解析 slabtop:实时监控内核缓存的利器
文章目录 深度解析 slabtop:实时监控内核缓存的利器slabtop 简介基本语法与选项命令语法主要选项详解 实际应用实例示例 1:每 5 秒刷新显示 slab 缓存信息示例 2:按名称排序,每 10 秒刷新一次显示 slab 缓存信息 如何解读 slabtop…...

力扣-股票买入问题
dp dp元素代表最大利润 f[j][1] 代表第 j 次交易后持有股票的最大利润。在初始状态,持有股票意味着你花钱买入了股票,此时的利润应该是负数(扣除了买入股票的成本),而不是 0。所以,把 f[j][1] 初始化为负…...

微服务保护:Sentinel
home | Sentinelhttps://sentinelguard.io/zh-cn/ 微服务保护的方案有很多,比如: 请求限流 线程隔离 服务熔断 服务故障最重要原因,就是并发太高!解决了这个问题,就能避免大部分故障。当然,接口的并发…...

蓝桥杯刷题周计划(第二周)
目录 前言题目一题目代码题解分析 题目二题目代码题解分析 题目三题目代码题解分析 题目四题目代码题解分析 题目五题目代码题解分析 题目六题目代码题解分析 题目七题目代码题解分析 题目八题目题解分析 题目九题目代码题解分析 题目十题目代码题解分析 题目十一题目代码题解分…...

【C++】C++11部分
目录 一、列表初始化 1.1 {}初始化 1.2 initializer_list 二、变量类型推导 2.1 auto 2.2 decltype 三、STL中一些变化 3.1 新增容器 四、lambda表达式 4.1 C98中的一个例子 4.2 lambda表达式 4.3 函数对象与lambda表达式 五、包装器 5.1 function包装器 5.2 fu…...

【分布式】聊聊分布式id实现方案和生产经验
对于分布式Id来说,在面试过程中也是高频面试题,所以主要针对分布式id实现方案进行详细分析下。 应用场景 对于无论是单机还是分布式系统来说,对于很多场景需要全局唯一ID, 数据库id唯一性日志traceId 可以方便找到日志链&#…...

[MERN] 使用 socket.io 实现即时通信功能
[MERN] 使用 socket.io 实现即时通信功能 效果实现如下: MERN-socket.io 实现即时聊天 Github 项目地址:https://github.com/GoldenaArcher/messenger-mern 项目使用了 MERN(MongoDB, Express, React, Node.js) socket.io 实现即时通信功能,并且使用了…...

c#面试题整理6
1.String类能否被继承,为什么 可以看到String类的修饰符是sealed,即是密封类,故不可被继承 2.一个对象的方法是否只能由一个线程访问 不是,但是可通过同步机制,确保同一个时间只有一个线程访问 3.计算2*8ÿ…...

简洁实用的3个免费wordpress主题
高端大气动态炫酷的免费企业官网wordpress主题 非常简洁的免费wordpress主题,安装简单、设置简单,几分钟就可以搭建好一个wordpress网站。 经典风格的免费wordpress主题 免费下载 https://www.fuyefa.com/wordpress...

Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
一:背景 1. 讲故事 前面跟大家分享过一篇 C# 调用 C代码引发非托管内存泄露 的文章,这是一个故意引发的正向泄露,这一篇我们从逆向的角度去洞察引发泄露的祸根代码,这东西如果在 windows 上还是很好处理的,很多人知道…...

【HDLbits--counter】
HDLbits--counter 在IC设计中,counter是十分普遍和重要的设计内容; 题目:基础计数器 module top_module (input clk,input reset,output [9:0] q);always (posedge clk) beginif(reset) beginq < 0;end else beginif(q999) beginq < 0…...

nvm 让 Node.js 版本切换更灵活
有很多小伙伴前端开发进程中,我们常常会遇到不同项目依赖不同版本 Node.js 的情况。我们不可能去卸载重新安装适应的版本去安装依赖或者启动项目。为了避免版本冲突带来的一系列麻烦,在这里给大家推荐一款Node.js 版本管理工具——nvm(Node V…...

双向选择排序算法
一 概述 双向选择排序(又称鸡尾酒选择排序)是选择排序的优化版本,核心改进在于每轮遍历同时确定未排序部分的最小值和最大值,分别交换到序列两端,从而减少遍历轮数。 二 时间复杂度 时间复杂度为(O(n^2)),但实际比较次数约为标准选择排序的 (1/2)。 三 C++实现代…...

美畅物联丨P2P系列之STUN服务器:助力网络穿透
在当今WebRTC等实时通信应用广泛兴起的复杂网络环境下,如何在NAT(网络地址转换)环境中实现高效、稳定的点对点(P2P)连接成为关键。STUN(Session Traversal Utilities for NAT)服务器作为应对这一…...

基于SpringBoot的“积分制零食自选销售平台”的设计与实现(源码+数据库+文档+PPT)
基于SpringBoot的“积分制零食自选销售平台”的设计与实现(源码数据库文档PPT) 开发语言:Java 数据库:MySQL 技术:SpringBoot 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 系统总体结构图 局部E-R图 系统首页界面…...

DeepSeek-V3 技术报告解读
DeepSeek火了有一段时间了,春节假期因为没时间,所以关于deepseek大模型一系列的技术报告一直没看,新年开工后,抽一点时间把之前的坑补起来,关于DeepSeek-V3技术报告的解读已经有很多了,但我相信不同的人去读…...

Spring使用@Scheduled注解的参数详解
在现代Java开发中,定时任务是一个常见的需求。Spring框架提供了Scheduled注解,让我们能够以简单、直观的方式定义和管理这些定时任务。接下来,我们来深入探讨这个注解的使用,以及它的参数都有哪些含义和作用。 Scheduled注解可以…...