如何借助 ArcGIS Pro 高效统计基站 10km 范围内的村庄数量?
在当今数字化时代,地理信息系统(GIS)技术在各个领域都发挥着重要作用。
特别是在通信行业,对于基站周边覆盖范围内的地理信息分析,能够帮助我们更好地进行网络规划、资源分配以及市场分析等工作。
今天,就让我们一起深入探讨如何借助 ArcGIS Pro 这一强大的 GIS 软件,来获取基站 10km 范围内的村庄个数,从而为相关决策提供有力的数据支持。
一、数据准备
在开始分析之前,我们需要准备两部分关键的数据:基站数据和村庄数据。
基站数据应包含基站的位置信息,通常以点要素的形式存储,每个基站点都有其对应的坐标,精确标识了基站的地理位置。
而村庄数据则以面要素的形式呈现,每个村庄面要素代表了一个实际的村庄区域,涵盖了村庄的边界范围等详细信息。
确保数据的准确性和完整性是分析成功的基础,因此在导入数据之前,建议对数据进行仔细的检查和整理,以避免因数据问题导致的分析误差。
二、计算缓冲区
缓冲区分析是 GIS 空间分析中的一种常用方法,它能够帮助我们确定某个地理要素周围的一定距离范围内的区域。
在本案例中,我们需要计算基站周围 10km 的缓冲区,以界定基站的覆盖范围。
(一)打开缓冲区工具
在 ArcGIS Pro 的主界面中,找到并点击顶部菜单栏中的“分析”选项卡。
在下拉菜单中,依次选择“工具箱”>“邻近分析”>“缓冲区”,这将打开缓冲区工具的对话框。

缓冲区工具
该工具对话框包含了进行缓冲区创建所需的各项参数设置选项,用户可以根据具体需求进行灵活配置。
(二)设置缓冲区参数
在缓冲区对话框内,首先需要指定输入要素,这里选择我们之前准备好的基站数据图层。
接下来,设置输出要素类的路径和名称,以便存储即将生成的缓冲区结果。
关键的参数是距离设置,将其设定为 10 千米,以符合我们的分析需求。

缓冲区设置
在方法选择上,我们推荐使用测地线方法,这种方法能够根据地球的曲率计算最短路径,确保缓冲区的形状在地理空间上更加准确和真实,尤其适用于大范围或高精度的分析场景。
此外,融合类型选择未融合,这样可以保证每个基站生成的缓冲区保持独立,不会与其他缓冲区合并,方便后续对每个基站单独进行村庄数量统计。
完成以上参数设置后,点击“运行”按钮,ArcGIS Pro 将开始计算并生成基站周围的 10km 缓冲区。

生成的缓冲区
生成后的缓冲区会以面要素的形式呈现在地图视图中,直观地展示了每个基站周围 10km 范围的区域范围,为后续的村庄数量统计提供了明确的空间边界。
三、统计村庄个数
在成功创建了基站的缓冲区之后,接下来我们需要统计每个缓冲区内包含的村庄个数。
这一过程将借助 ArcGIS Pro 的“范围内汇总”工具来完成,该工具能够高效地对指定范围内的要素进行汇总和统计分析。
(一)打开范围内汇总工具
同样在 ArcGIS Pro 的“分析”选项卡中,点击“工具箱”>“统计数据”>“范围内汇总”,即可打开范围内汇总工具的对话框。

范围内汇总
该工具对话框允许用户指定汇总的范围、被汇总的要素以及输出结果的存储位置等参数,操作简便且功能强大。
(二)设置范围内汇总参数
在范围内汇总对话框内,首先指定输入面为之前生成的缓冲区图层,这是我们要进行汇总分析的范围依据。
然后,选择输入汇总要素为村庄图层,即我们要统计其在缓冲区内数量的村庄数据。
接着,设置输出要素类的路径和名称,用于保存最终的统计结果。
此外,还可以根据实际需求,在工具对话框中选择是否需要计算统计数据,如平均值、总和等,以获取更丰富的分析结果。

范围内汇总设置
在这里,我们重点关注的是村庄的个数统计,因此主要利用“计数”统计类型即可。
完成参数设置后,点击“运行”按钮,ArcGIS Pro 将开始执行范围内汇总操作。

计算结果
软件会自动分析每个缓冲区内包含的村庄要素,并将统计结果存储到指定的输出要素类中。
生成结果后,打开输出要素类的属性表,即可清晰地看到每个缓冲区对应的村庄个数,以及其他相关的统计信息(如果选择了计算)。
这些数据为我们进一步的分析和决策提供了有力的支持。
四、应用
通过上述步骤,我们成功获取了基站 10km 范围内的村庄个数。
这些数据具有广泛的应用价值。例如,在通信网络规划中,可以根据村庄的分布密度和数量,合理地分配基站资源,优化网络覆盖,确保每个村庄都能获得良好的通信服务。
同时,对于市场分析而言,了解基站周边村庄的数量和分布情况,有助于评估潜在用户规模,制定针对性的市场营销策略,提高市场竞争力。
此外,在应急通信保障方面,掌握村庄的地理分布信息,能够在突发事件发生时,迅速确定需要重点保障的区域,及时提供通信支持,保障居民的生命财产安全和社会稳定。
五、注意事项
在使用 ArcGIS Pro 进行上述分析过程中,需要注意一些细节问题,以确保分析结果的准确性和可靠性。
首先,数据的投影坐标系需要保持一致,否则可能导致缓冲区生成和范围内汇总出现偏差。建议在分析前,对所有数据进行投影转换,统一到相同的坐标系下。
其次,对于数据量较大的情况,如基站数量众多或村庄分布密集,计算速度可能会较慢。
此时,可以考虑优化数据结构,例如对数据进行分块处理或利用空间索引等技术,提高分析效率。
另外,在设置缓冲区距离时,要充分考虑地理环境因素,如地形起伏、障碍物等,可能会对实际覆盖范围产生影响,必要时可以结合实地勘察数据进行调整和校正。
最后,对于统计结果的解读,要结合实际情况进行综合分析,避免单纯依赖数据而忽略了一些潜在的因素,如村庄的发展规划、人口流动等,以确保分析结论的科学性和实用性。
六、总结
综上所述,利用 ArcGIS Pro 获取基站 10km 范围内的村庄个数,主要依赖于缓冲区工具和范围内汇总工具的高效应用。
这一过程相对简单且易于操作,但在实际应用中,仍需注意数据准备、参数设置以及结果解读等环节的细节问题,以确保分析的准确性和可靠性。
随着 GIS 技术的不断发展和应用领域的不断拓展,ArcGIS Pro 将在更多的行业和领域发挥其独特的优势,为地理信息分析和决策支持提供更加强大的工具和平台。
未来,我们可以期待 ArcGIS Pro 在功能优化、性能提升以及与其他技术的融合方面取得更多的突破,为用户带来更加便捷、高效和智能的 GIS 体验,助力各行业的数字化转型和发展。
希望本文的介绍能够对您在使用 ArcGIS Pro 进行相关地理信息分析时提供有益的参考和帮助。
相关文章:
如何借助 ArcGIS Pro 高效统计基站 10km 范围内的村庄数量?
在当今数字化时代,地理信息系统(GIS)技术在各个领域都发挥着重要作用。 特别是在通信行业,对于基站周边覆盖范围内的地理信息分析,能够帮助我们更好地进行网络规划、资源分配以及市场分析等工作。 今天,就…...

Linux网络之数据链路层协议
目录 数据链路层 MAC地址与IP地址 数据帧 ARP协议 NAT技术 代理服务器 正向代理 反向代理 上期我们学习了网络层中的相关协议,为IP协议。IP协议通过报头中的目的IP地址告知了数据最终要传送的目的主机的IP地址,从而指引了数据在网络中的一步…...

如何使用 PyInstaller 打包 Python 脚本?一看就懂的完整教程!
PyInstaller 打包指令教程 1. 写在前面 通常,在用 Python 编写完一个脚本后,需要将它部署并集成到一个更大的项目中。常见的集成方式有以下几种: 使用 PyInstaller 打包。使用 Docker 打包。将 Python 嵌入到 C 代码中,并封装成…...

解锁DeepSpeek-R1大模型微调:从训练到部署,打造定制化AI会话系统
目录 1. 前言 2.大模型微调概念简述 2.1. 按学习范式分类 2.2. 按参数更新范围分类 2.3. 大模型微调框架简介 3. DeepSpeek R1大模型微调实战 3.1.LLaMA-Factory基础环境安装 3.1大模型下载 3.2. 大模型训练 3.3. 大模型部署 3.4. 微调大模型融合基于SpirngBootVue2…...
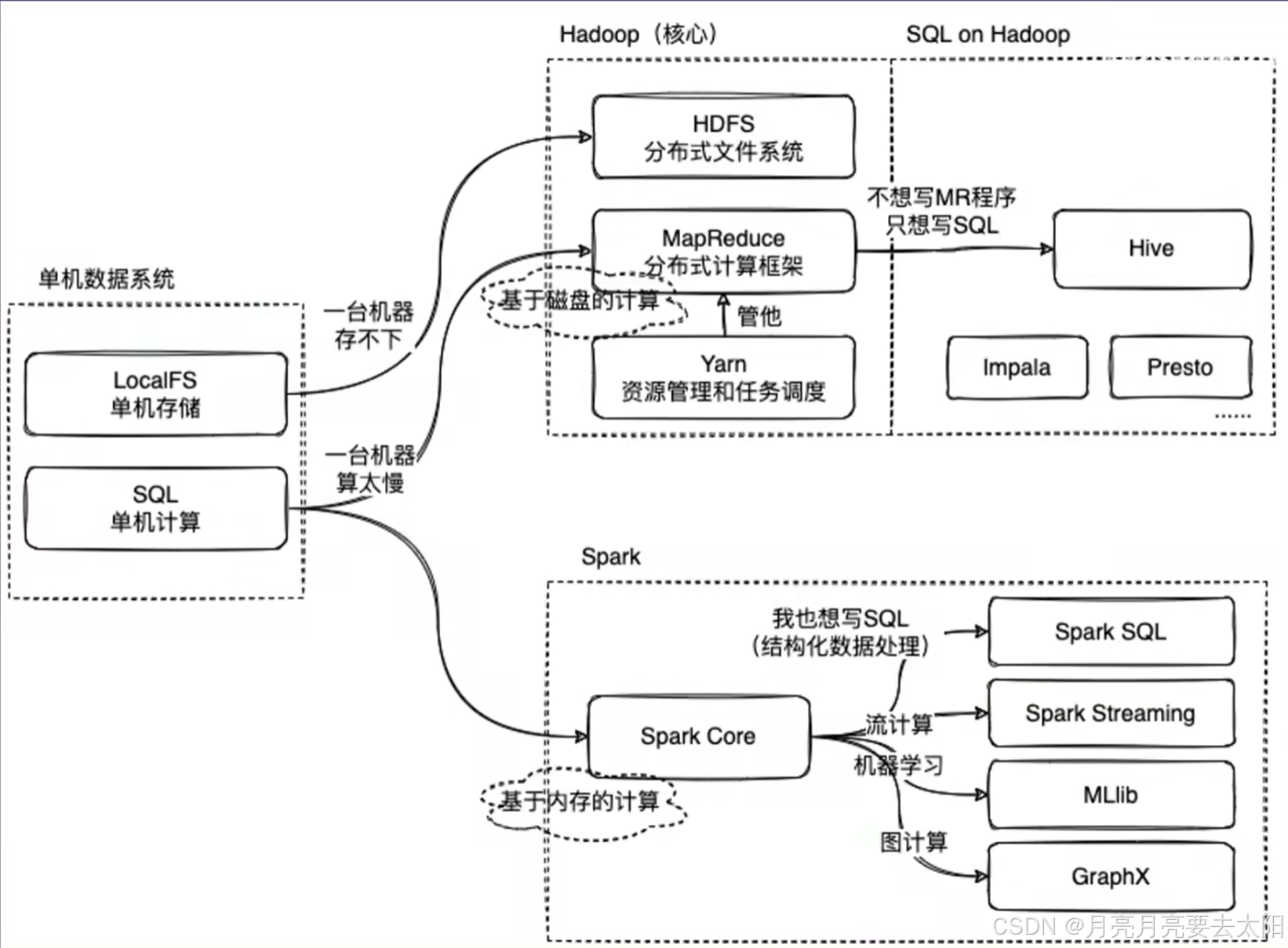
Hadoop、Hive、Spark的关系
Part1:Hadoop、Hive、Spark关系概览 1、MapReduce on Hadoop 和spark都是数据计算框架,一般认为spark的速度比MR快2-3倍。 2、mapreduce是数据计算的过程,map将一个任务分成多个小任务,reduce的部分将结果汇总之后返回。 3、HIv…...

基于VMware虚拟机的Ubuntu22.04系统安装和配置(新手保姆级教程)
文章目录 一、前期准备1. 硬件要求2. 软件下载2-1. 下载虚拟机运行软件 二、安装虚拟机三、创建 Ubuntu 系统虚拟机四、Ubuntu 系统安装过程的配置五、更换国内镜像源六、设置静态 IP七、安装常用软件1. 编译工具2. 代码管理工具3. 安装代码编辑软件(VIM)…...
)
Python|基于DeepSeek大模型,自动生成语料数据(10)
前言 本文是该专栏的第10篇,后面会持续分享AI大模型干货知识,记得关注。 在本专栏之前,笔者在文章《Python|基于DeepSeek大模型,实现文本内容仿写(8)》中,有详细介绍通过Python+DeepSeek大模型,实现对目标文本内容的仿写。 而在本文中,笔者将基于DeepSeek大模型,通…...

基于SpringBoot的历史馆藏系统设计与实现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

蓝桥杯[每日两题] 真题:好数 神奇闹钟 (java版)
题目一:好数 题目描述 一个整数如果按从低位到高位的顺序,奇数位(个位、百位、万位 )上的数字是奇数,偶数位(十位、千位、十万位 )上的数字是偶数,我们就称之为“好数”。给定…...

基于BMO磁性细菌优化的WSN网络最优节点部署算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 无线传感器网络(Wireless Sensor Network, WSN)由大量分布式传感器节点组成,用于监测物理或环境状况。节点部署是 WSN 的关键问…...

学习笔记:Python网络编程初探之基本概念(一)
一、网络目的 让你设备上的数据和其他设备上进行共享,使用网络能够把多方链接在一起,然后可以进行数据传递。 网络编程就是,让在不同的电脑上的软件能够进行数据传递,即进程之间的通信。 二、IP地址的作用 用来标记唯一一台电脑…...

Laya中runtime的用法
文章目录 0、环境:2.x版本1、runtime是什么2、使用实例情景需要做 3、script组件模式 0、环境:2.x版本 1、runtime是什么 简单来说,如果创建了一个scene,加了runtime和没加runtime的区别就是: 没加runtimeÿ…...

Docker中GPU的使用指南
在当今的计算领域,GPU(图形处理单元)已经成为了加速各种计算密集型任务的关键硬件,特别是在深度学习、科学模拟和高性能计算等领域。Docker作为流行的容器化平台,允许开发者将应用程序及其依赖打包成一个可移植的容器,在不同的环境中运行。当需要在Docker容器中利用GPU的…...

OpenCV计算摄影学(16)调整图像光照效果函数illuminationChange()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 对选定区域内的梯度场应用适当的非线性变换,然后通过泊松求解器重新积分,可以局部修改图像的表观照明。 cv::illuminati…...

【爬虫】开篇词
一、网络爬虫概述 二、网络爬虫的应用场景 三、爬虫的痛点 四、需要掌握哪些技术? 在这个信息爆炸的时代,如何高效地获取和处理海量数据成为一项核心技能。无论是数据分析、商业情报、学术研究,还是人工智能训练,网络爬虫&…...

C#变量与变量作用域详解
一、变量基础 1. 声明与初始化 声明语法:<数据类型> <变量名>(如 int age; string name)初始化要求: 1、 类或结构体中的字段变量(全局变量)无需显式初始化,默认值…...

深度解析 slabtop:实时监控内核缓存的利器
文章目录 深度解析 slabtop:实时监控内核缓存的利器slabtop 简介基本语法与选项命令语法主要选项详解 实际应用实例示例 1:每 5 秒刷新显示 slab 缓存信息示例 2:按名称排序,每 10 秒刷新一次显示 slab 缓存信息 如何解读 slabtop…...

力扣-股票买入问题
dp dp元素代表最大利润 f[j][1] 代表第 j 次交易后持有股票的最大利润。在初始状态,持有股票意味着你花钱买入了股票,此时的利润应该是负数(扣除了买入股票的成本),而不是 0。所以,把 f[j][1] 初始化为负…...

微服务保护:Sentinel
home | Sentinelhttps://sentinelguard.io/zh-cn/ 微服务保护的方案有很多,比如: 请求限流 线程隔离 服务熔断 服务故障最重要原因,就是并发太高!解决了这个问题,就能避免大部分故障。当然,接口的并发…...

蓝桥杯刷题周计划(第二周)
目录 前言题目一题目代码题解分析 题目二题目代码题解分析 题目三题目代码题解分析 题目四题目代码题解分析 题目五题目代码题解分析 题目六题目代码题解分析 题目七题目代码题解分析 题目八题目题解分析 题目九题目代码题解分析 题目十题目代码题解分析 题目十一题目代码题解分…...

【C++】C++11部分
目录 一、列表初始化 1.1 {}初始化 1.2 initializer_list 二、变量类型推导 2.1 auto 2.2 decltype 三、STL中一些变化 3.1 新增容器 四、lambda表达式 4.1 C98中的一个例子 4.2 lambda表达式 4.3 函数对象与lambda表达式 五、包装器 5.1 function包装器 5.2 fu…...

【分布式】聊聊分布式id实现方案和生产经验
对于分布式Id来说,在面试过程中也是高频面试题,所以主要针对分布式id实现方案进行详细分析下。 应用场景 对于无论是单机还是分布式系统来说,对于很多场景需要全局唯一ID, 数据库id唯一性日志traceId 可以方便找到日志链&#…...

[MERN] 使用 socket.io 实现即时通信功能
[MERN] 使用 socket.io 实现即时通信功能 效果实现如下: MERN-socket.io 实现即时聊天 Github 项目地址:https://github.com/GoldenaArcher/messenger-mern 项目使用了 MERN(MongoDB, Express, React, Node.js) socket.io 实现即时通信功能,并且使用了…...

c#面试题整理6
1.String类能否被继承,为什么 可以看到String类的修饰符是sealed,即是密封类,故不可被继承 2.一个对象的方法是否只能由一个线程访问 不是,但是可通过同步机制,确保同一个时间只有一个线程访问 3.计算2*8ÿ…...

简洁实用的3个免费wordpress主题
高端大气动态炫酷的免费企业官网wordpress主题 非常简洁的免费wordpress主题,安装简单、设置简单,几分钟就可以搭建好一个wordpress网站。 经典风格的免费wordpress主题 免费下载 https://www.fuyefa.com/wordpress...

Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
一:背景 1. 讲故事 前面跟大家分享过一篇 C# 调用 C代码引发非托管内存泄露 的文章,这是一个故意引发的正向泄露,这一篇我们从逆向的角度去洞察引发泄露的祸根代码,这东西如果在 windows 上还是很好处理的,很多人知道…...

【HDLbits--counter】
HDLbits--counter 在IC设计中,counter是十分普遍和重要的设计内容; 题目:基础计数器 module top_module (input clk,input reset,output [9:0] q);always (posedge clk) beginif(reset) beginq < 0;end else beginif(q999) beginq < 0…...

nvm 让 Node.js 版本切换更灵活
有很多小伙伴前端开发进程中,我们常常会遇到不同项目依赖不同版本 Node.js 的情况。我们不可能去卸载重新安装适应的版本去安装依赖或者启动项目。为了避免版本冲突带来的一系列麻烦,在这里给大家推荐一款Node.js 版本管理工具——nvm(Node V…...

双向选择排序算法
一 概述 双向选择排序(又称鸡尾酒选择排序)是选择排序的优化版本,核心改进在于每轮遍历同时确定未排序部分的最小值和最大值,分别交换到序列两端,从而减少遍历轮数。 二 时间复杂度 时间复杂度为(O(n^2)),但实际比较次数约为标准选择排序的 (1/2)。 三 C++实现代…...

美畅物联丨P2P系列之STUN服务器:助力网络穿透
在当今WebRTC等实时通信应用广泛兴起的复杂网络环境下,如何在NAT(网络地址转换)环境中实现高效、稳定的点对点(P2P)连接成为关键。STUN(Session Traversal Utilities for NAT)服务器作为应对这一…...