Python应用指南:利用高德地图API获取POI数据(关键词版)
都说“为一杯奶茶愿意赴一座城”,曾经不知有多少年轻人为了一口茶颜悦色不惜跨越千里来到长沙打卡,而如今也有不少年轻人被传说中的“奶茶界的海底捞”所吸引,千里迢迢来到安徽只为尝一口卡旺卡奶茶。要说起来这卡旺卡奶茶,尽管这个地方茶饮品牌没有茶颜悦色那么出名,但也同样是本地消费者心头白月光般的存在,简直就是安徽消费者的最爱,作为一家地方茶饮品牌,卡旺卡的门店仅在安徽省营业,尽管门店数量不算多但却格外受安徽省消费者偏爱,曾经甚至创下了一天最多卖出三万杯的佳绩。而卡旺卡之所以这么受欢迎,除了口味好喝外最令人津津乐道的就是它好到离谱的服务了,所以才能被称为“茶饮界海底捞”。
安徽省作为本土茶饮品牌卡旺卡的起源地与核心市场,其门店网络覆盖呈现鲜明的区域深耕特征。自2008年首店于合肥开业以来,卡旺卡凭借“日常、刚好”的产品理念与“朋友式服务”的品牌文化,逐步构建了覆盖全省的直营体系。截至2024年,其门店已扩展至安徽省内17个地市,包括合肥、芜湖、蚌埠、淮南等城市,总数超过260家,其中仅合肥一地便占据150余家门店,形成了“总部辐射全省、重点城市多点渗透”的布局模式。这种密集布点策略不仅体现了品牌对本地消费需求的精准把握,更通过直营模式保障了服务品质的一致性,使其在激烈竞争中稳居区域市场头部地位。近年,卡旺卡以年均30%的增速持续扩张,显示出从区域性品牌向全国市场延伸的野心。本篇文章我们就从其门店数据获取和分布特征为区域茶饮品牌发展路径提供实证参考。
第一步:需要在高德地图开放平台上注册账号,并且申请web服务的AK密钥。注册账号登陆后点击右上角的控制台 ->应用管理 -> 创建应用 -> 添加新key,注意选择web 服务,就得到了一个可以使用web服务的key密钥;

第二步:通过调用高德地图开放平台的POI关键字搜索与行政区域查询API结合的方式,获取关键字对应的POI数据;
先讲一下方法思路,一共四个步骤;
方法思路
- 脚本会先获取查找的城市(安徽省)下所有的区县;
- 对于每个区县,脚本都会向地图助手发送请求,寻找所有与关键词(卡旺卡)相关的地点;
- 坐标转换——高德坐标系(GCJ-02) to WGS84;
- 数据被另存为,excel或者csv;
脚本逻辑:
首先,脚本初始化时定义了全局配置参数,包括高德地图API密钥AMAP_WEB_KEY、要查询的城市列表CITIES(例如安徽省)、搜索的关键字列表KEYWORDS(如卡旺卡),以及输出文件格式DATA_FILE_FORMAT。这些参数决定了脚本的行为,比如要查询的城市和关键字,以及最终生成的数据文件格式是Excel还是CSV。
主程序入口从if __name__ == '__main__':开始执行,它遍历每个城市和关键字组合,并调用get_data函数处理每一个组合。在get_data函数中,首先尝试通过调用get_areas函数获取城市的行政区划代码(如区县代码)。此过程依赖于get_distrinctNoCache函数,该函数使用高德地图的行政区划API来获取指定城市的区县信息。如果成功获取到区县代码,则将其拆分为单独的区县代码列表,并对每个区县代码分别调用getpois函数以分区域获取POI数据。
getpois函数负责分页获取特定区域内的POI数据。它通过循环调用getpoi_page函数逐页请求数据,直到没有更多数据为止。每次请求后,利用hand函数解析返回的JSON数据,提取有效的POI信息并添加到结果列表中。getpoi_page函数构建API请求URL,发送HTTP请求,并检查API响应的状态确保数据有效。为了避免触发API调用频率限制,这里还加入了0.5秒的延迟。
一旦所有POI数据被收集完毕,get_data函数将根据DATA_FILE_FORMAT选择保存为Excel或CSV格式。对于Excel格式,会调用write_to_excel函数;而对于CSV格式,则调用write_to_csv函数。在这两个函数中,在保存之前会对每个POI的经纬度进行坐标转换,使用gcj02towgs84函数将GCJ02坐标(火星坐标系)转换为WGS84坐标,确保输出数据符合国际标准。
完整代码#运行环境Python 3.11
from urllib.parse import quote
from urllib import request
import json
import os
import xlwt
import pandas as pd
import time
import math# 配置参数
AMAP_WEB_KEY = '你的key'
KEYWORDS = ['卡旺卡']
CITIES = ['安徽省']
# 输出数据文件格式, 1为默认xls格式,2为csv格式
DATA_FILE_FORMAT = 1
POI_SEARCH_URL = "http://restapi.amap.com/v3/place/text"
OFFSET = 25 # 每页结果数量# GCJ02(火星坐标系)转WGS84
x_pi = 3.14159265358979324 * 3000.0 / 180.0
pi = 3.1415926535897932384626 # π
a = 6378245.0 # 长半轴
ee = 0.00669342162296594323 # 扁率def gcj02towgs84(lng, lat):"""GCJ02(火星坐标系)转WGS84:param lng: 火星坐标系的经度:param lat: 火星坐标系纬度:return: WGS84 经度, 纬度"""if out_of_china(lng, lat):return lng, latdlat = transformlat(lng - 105.0, lat - 35.0)dlng = transformlng(lng - 105.0, lat - 35.0)radlat = lat / 180.0 * pimagic = math.sin(radlat)magic = 1 - ee * magic * magicsqrtmagic = math.sqrt(magic)dlat = (dlat * 180.0) / ((a * (1 - ee)) / (magic * sqrtmagic) * pi)dlng = (dlng * 180.0) / (a / sqrtmagic * math.cos(radlat) * pi)mglat = lat + dlatmglng = lng + dlngreturn [lng * 2 - mglng, lat * 2 - mglat]def transformlat(lng, lat):"""计算纬度偏移量:param lng: 经度:param lat: 纬度:return: 纬度偏移量"""ret = -100.0 + 2.0 * lng + 3.0 * lat + 0.2 * lat * lat + 0.1 * lng * lat + 0.2 * math.sqrt(math.fabs(lng))ret += (20.0 * math.sin(6.0 * lng * pi) + 20.0 * math.sin(2.0 * lng * pi)) * 2.0 / 3.0ret += (20.0 * math.sin(lat * pi) + 40.0 * math.sin(lat / 3.0 * pi)) * 2.0 / 3.0ret += (160.0 * math.sin(lat / 12.0 * pi) + 320 * math.sin(lat * pi / 30.0)) * 2.0 / 3.0return retdef transformlng(lng, lat):"""计算经度偏移量:param lng: 经度:param lat: 纬度:return: 经度偏移量"""ret = 300.0 + lng + 2.0 * lat + 0.1 * lng * lng + 0.1 * lng * lat + 0.1 * math.sqrt(math.fabs(lng))ret += (20.0 * math.sin(6.0 * lng * pi) + 20.0 * math.sin(2.0 * lng * pi)) * 2.0 / 3.0ret += (20.0 * math.sin(lng * pi) + 40.0 * math.sin(lng / 3.0 * pi)) * 2.0 / 3.0ret += (150.0 * math.sin(lng / 12.0 * pi) + 300.0 * math.sin(lng / 30.0 * pi)) * 2.0 / 3.0return retdef out_of_china(lng, lat):"""判断是否在国内,不在国内不做偏移:param lng: 经度:param lat: 纬度:return: 是否在国内"""if lng < 72.004 or lng > 137.8347:return Trueif lat < 0.8293 or lat > 55.8271:return Truereturn False# 根据城市名称和分类关键字获取POI数据
def getpois(cityname, keywords):i = 1poilist = []while True: # 使用while循环不断分页获取数据result = getpoi_page(cityname, keywords, i)result = json.loads(result) # 将字符串转换为json# 检查是否包含'count'字段if 'count' not in result or result['count'] == '0':breakhand(poilist, result)# 如果当前页的数据量小于OFFSET,则说明没有更多数据if len(result.get('pois', [])) < OFFSET:breaki += 1return poilist# 数据写入Excel
def write_to_excel(poilist, cityname, classfield):book = xlwt.Workbook(encoding='utf-8', style_compression=0)sheet = book.add_sheet(classfield, cell_overwrite_ok=True)# 第一行(列标题)headers = ['lon', 'lat', 'name', 'address', 'pname', 'cityname', 'business_area', 'type']for col, header in enumerate(headers):sheet.write(0, col, header)for i, poi in enumerate(poilist):location = poi.get('location')name = poi.get('name')address = poi.get('address')pname = poi.get('pname')cityname = poi.get('cityname')business_area = poi.get('business_area', '')type = poi.get('type')lng, lat = str(location).split(",")# 转换为WGS84坐标wgs84_lng, wgs84_lat = gcj02towgs84(float(lng), float(lat))# 每一行写入sheet.write(i + 1, 0, wgs84_lng)sheet.write(i + 1, 1, wgs84_lat)sheet.write(i + 1, 2, name)sheet.write(i + 1, 3, address)sheet.write(i + 1, 4, pname)sheet.write(i + 1, 5, cityname)sheet.write(i + 1, 6, business_area)sheet.write(i + 1, 7, type)# 保存Excel文件os.makedirs('data', exist_ok=True)book.save(os.path.join('data', f'poi-{cityname}-{classfield}.xls'))# 数据写入CSV文件
def write_to_csv(poilist, cityname, classfield):data_csv = {'lon': [],'lat': [],'name': [],'address': [],'pname': [],'cityname': [],'business_area': [],'type': []}for poi in poilist:location = poi.get('location')name = poi.get('name')address = poi.get('address')pname = poi.get('pname')cityname = poi.get('cityname')business_area = poi.get('business_area', '')type = poi.get('type')lng, lat = str(location).split(",")# 转换为WGS84坐标wgs84_lng, wgs84_lat = gcj02towgs84(float(lng), float(lat))data_csv['lon'].append(wgs84_lng)data_csv['lat'].append(wgs84_lat)data_csv['name'].append(name)data_csv['address'].append(address)data_csv['pname'].append(pname)data_csv['cityname'].append(cityname)data_csv['business_area'].append(business_area)data_csv['type'].append(type)df = pd.DataFrame(data_csv)folder_name = f'poi-{cityname}-{classfield}'folder_name_full = os.path.join('data', folder_name)os.makedirs(folder_name_full, exist_ok=True)file_name = f'poi-{cityname}-{classfield}.csv'file_path = os.path.join(folder_name_full, file_name)df.to_csv(file_path, index=False, encoding='utf_8_sig')return folder_name_full, file_name# 将返回的POI数据装入集合返回
def hand(poilist, result):if 'pois' in result:pois = result['pois']for poi in pois:if 'location' in poi and 'name' in poi:poilist.append(poi)else:print("无效的 POI 数据:", poi)else:print("结果中未找到 POI。")# 单页获取POIs
def getpoi_page(cityname, keywords, page):req_url = f"{POI_SEARCH_URL}?key={AMAP_WEB_KEY}&extensions=all&keywords={quote(keywords)}&city={quote(cityname)}&citylimit=true&offset={OFFSET}&page={page}&output=json"print('============请求url:' + req_url)try:time.sleep(0.5) # 添加延迟避免触发API限制with request.urlopen(req_url) as f:data = f.read().decode('utf-8')result = json.loads(data)# 检查API状态if result.get('status') != '1':print(f"API 返回错误: {result.get('info', '未知错误')}")return json.dumps({"count": "0", "pois": []})return dataexcept Exception as e:print(f"从高德 API 获取数据时发生错误: {e}")return json.dumps({"count": "0", "pois": []})def get_areas(code):print('获取城市的所有区域:code: ' + str(code).strip())data = get_distrinctNoCache(code)print('get_distrinct result:' + data)data = json.loads(data)districts = data['districts'][0]['districts']# 判断是否是直辖市if code.startswith(('重庆', '上海', '北京', '天津')):districts = data['districts'][0]['districts'][0]['districts']area = ",".join(district['adcode'] for district in districts)print(area)return area.strip(',')def get_data(city, keyword):isNeedAreas = Truearea = get_areas(city) if isNeedAreas else Noneall_pois = []if area:area_list = area.split(",")for area in area_list:pois_area = getpois(area, keyword)print(f'当前城区:{area}, 分类:{keyword}, 总的有{len(pois_area)}条数据')all_pois.extend(pois_area)print("所有城区的数据汇总,总数为:" + str(len(all_pois)))else:pois_area = getpois(city, keyword)if DATA_FILE_FORMAT == 2:# 写入CSVfile_folder, file_name = write_to_csv(all_pois, city, keyword)returnreturn write_to_excel(all_pois, city, keyword)def get_distrinctNoCache(code):url = f"https://restapi.amap.com/v3/config/district?subdistrict=2&extensions=all&key={AMAP_WEB_KEY}"req_url = url + "&keywords=" + quote(code)print(req_url)try:with request.urlopen(req_url) as f:data = f.read().decode('utf-8')print(code, data)return dataexcept Exception as e:print(f"获取城市行政区划时发生错误: {e}")return json.dumps({"districts": []})if __name__ == '__main__':for ct in CITIES:for type in KEYWORDS:get_data(ct, type)获取到的数据标签如下,address(详细地址)、cityname(所在城市)、pro(门店标签)、pname(所在省 )、name(门店名称)business area(所在商圈)、lon,lat(坐标信息);

tips:1、需要获取其他城市或者关键词可以修改KEYWORDS 和CITIES字段,也可以调整行政区层级,比如检索"合肥市";2、个人开发者的关键词搜索的日配额100(次/日),需要注意额度的使用,如果有企业开发者账号,或者通过购买额度的方式除外;

接下来,我们进行看图说话:
首先,我们可以观察到其具有明显的地域集中性和策略性布局。合肥市作为安徽省的省会城市,拥有最多的卡旺卡门店,显示出该品牌对核心城市的高度重视。这些门店不仅集中在市中心区域,还扩展到了周边的区县,表明了卡旺卡致力于覆盖更广泛的消费群体。
其次,除了合肥市之外,卡旺卡也在芜湖、蚌埠、安庆等重要城市设立了多家门店,显示出品牌向省内其他主要经济中心扩张的趋势。这种布局方式有助于卡旺卡进一步巩固其在安徽市场的地位,并利用这些城市的经济活力和人口优势来促进业务增长。
值得注意的是,尽管皖南地区的高铁网络较为发达,有利于交通和物流,但卡旺卡门店的分布并不完全受限于交通便利性。相反,品牌的选址更多考虑了当地的人口密度、消费能力和商业氛围等因素。例如,在一些旅游热点地区,我们也看到了卡旺卡门店的存在,这反映了品牌对不同市场需求的敏锐洞察力。
此外,卡旺卡在皖北地区的布局相对较少,这也与该区域经济发展水平和人口密度低于皖南有关。不过,随着品牌的发展和市场拓展,未来在这一区域增加门店数量也是有可能的。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。
相关文章:
Python应用指南:利用高德地图API获取POI数据(关键词版)
都说“为一杯奶茶愿意赴一座城”,曾经不知有多少年轻人为了一口茶颜悦色不惜跨越千里来到长沙打卡,而如今也有不少年轻人被传说中的“奶茶界的海底捞”所吸引,千里迢迢来到安徽只为尝一口卡旺卡奶茶。要说起来这卡旺卡奶茶,尽管这…...
)
【零基础入门unity游戏开发——2D篇】2D物理系统 —— 2D刚体组件(Rigidbody 2d)
考虑到每个人基础可能不一样,且并不是所有人都有同时做2D、3D开发的需求,所以我把 【零基础入门unity游戏开发】 分为成了C#篇、unity通用篇、unity3D篇、unity2D篇。 【C#篇】:主要讲解C#的基础语法,包括变量、数据类型、运算符、流程控制、面向对象等,适合没有编程基础的…...

Linux网络相关概念和重要知识(2)(UDP套接字编程、聊天室的实现、观察者模式)
目录 1.UDP套接字编程 (1)socket编程 (2)UDP的使用 ①socket ②bind ③recvfrom ④sendto 2.聊天室的实现 (1)整体逻辑 (2)对sockaddr_in的封装 (3)…...

机器学习之条件概率
1. 引言 概率模型在机器学习中广泛应用于数据分析、模式识别和推理任务。本文将调研几种重要的概率模型,包括EM算法、MCMC、朴素贝叶斯、贝叶斯网络、概率图模型(CRF、HMM)以及最大熵模型,介绍其基本原理、算法流程、应用场景及优势。 2. EM算法(Expectation-Maximizati…...

国科云:浅谈DNS在IPv6改造过程中的重要性
在IPv6改造过程中,DNS(域名系统)起着至关重要的作用,主要体现在以下几个方面: 地址解析与映射 IPv6地址采用128位的地址空间,与IPv4的32位地址相比,地址长度大大增加,这使得手动记…...

JVM 03
今天是2025/03/24 15:21 day 11 总路线请移步主页Java大纲相关文章 今天进行JVM 5,6 个模块的归纳 首先是JVM的相关内容概括的思维导图 5. 优化技术 JVM通过多种优化技术提升程序执行效率,核心围绕热点代码检测和编译优化实现动态性能提升。 热点代码检测 JVM…...

【VUE】day07 路由
【VUE】day07 路由 1. 路由2. 前端路由的工作方式3. 实现简易的前端路由4. 安装和配置路由4.1 安装vue-router包4.2 创建路由模块4.3 导入并挂在路由模块 5. 在路由模块中声明路由的对应关系5.1 router-view 1. 路由 在 Vue.js 中,路由(Routing…...
内网穿透的应用-本地部署ChatTTS教程:Windows搭建AI语音合成服务的全流程配置
文章目录 前言1. 下载运行ChatTTS模型2. 安装Cpolar工具3. 实现公网访问4. 配置ChatTTS固定公网地址 前言 各位开发者小伙伴们!今天我要给大家推荐一个超级火的AI项目——ChatTTS。这个开源文本转语音(TTS)项目的火爆程度简直让人难以置信&a…...
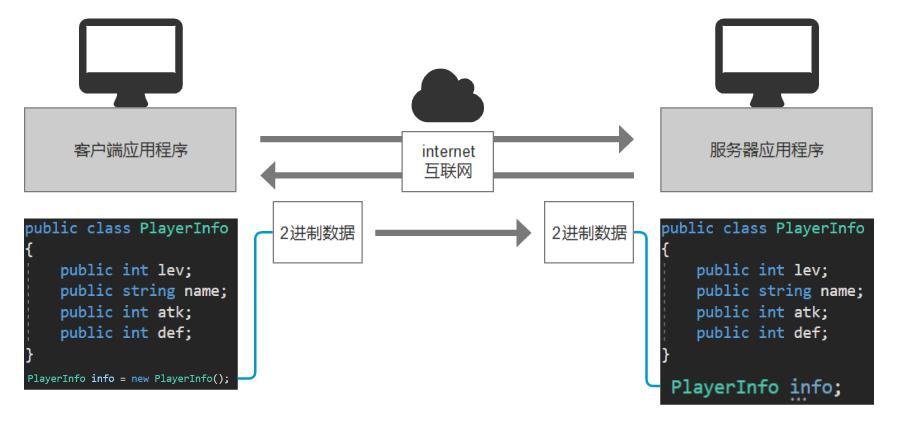
2025-03-21 Unity 网络基础3——TCP网络通信准备知识
文章目录 1 IP/端口类1.1 IPAddress1.2 IPEndPoint 2 域名解析2.1 IPHostEntry2.2 Dns 3 序列化与反序列化3.1 序列化3.1.1 内置类型 -> 字节数组3.1.2 字符串 -> 字节数组3.1.3 类对象 -> 字节数组 3.2 反序列化3.2.1 字节数组 -> 内置类型3.2.2 字节数组 -> 字…...

静态时序分析:SDC约束命令set_min_pulse_width详解
相关阅读 静态时序分析https://blog.csdn.net/weixin_45791458/category_12567571.html?spm1001.2014.3001.5482 最小脉冲宽度检查用于确保一个单元的时钟引脚和异步置位/复位引脚的的脉冲宽度满足最小要求,如果违反该要求,则可能出现功能错误。严格意…...

推荐1款简洁、小巧的实用收音机软件,支持手机和电脑
聊一聊 没想到现在还有人喜欢听广播。 我一直以为听广播必须要用那种小广播机才可以。 原来手机或电脑上也是可以的。 今天给大家分享一款可以在电脑和手机上听广播的软件。 软件介绍 龙卷风收音机 电台广播收音机分电脑和手机两个版本。 电脑端无需安装,下载…...

HO与OH差异之Navigation
在上一篇的内容中我们进一步的了解了Navigation的用法,但是既然写到这里了我就再来扩充一下有关Navigation的内容。 HarmonyOS与OpenHarmony之间有些写法与内容是有差异的,就比如Navigation的跳转。以下内容中HarmonyOS我都简称为HO,OpenHar…...

盖泽 寻边器 帮助类
EA系列 Aligner晶圆校准器 晶圆校准器是一种应用于晶圆加工中的晶圆预对准装置,通过利用晶圆上的缺口(notch)将晶圆调整至预设位置,以确保晶圆的位置及方向,方便后续工艺的进行。产品广泛应用于半导体制造过程中的各个阶段,可集成至各类半导体设备中使用。 通讯方式 串口 …...

模糊规则激活方法详解(python实例对比)
前文我们已经了解了多种隶属函数,如三角形、梯形、高斯型、S型和Z型,并且讨论了模糊推理的基本过程,包括模糊化、规则评估、聚合和解模糊化。我们还了解了如何生成模糊规则的方法,比如专家经验、聚类分析、决策树、遗传算法和ANFI…...

value-key 的作用
在 el-autocomplete 组件中,value-key 是一个非常重要的属性,它用于指定选项对象中作为值的字段名。当选项列表是一个包含多个属性的对象数组时,value-key 能帮助组件明确哪个属性是实际要使用的值。比如,选项列表为 [{id: 01, na…...

venv 和 conda 哪个更适合管理python虚拟环境
在 Python 开发中,管理虚拟环境是避免依赖冲突和提高项目可复现性的关键。venv(Python 内置)和 conda(第三方工具)各有优劣,选择取决于你的具体需求。以下是详细对比和推荐场景: 1. venv&#x…...

论文阅读:2023 arxiv Provable Robust Watermarking for AI-Generated Text
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 Provable Robust Watermarking for AI-Generated Text https://arxiv.org/pdf/2306.17439 https://github.com/XuandongZhao/Unigram-Watermark https://www.doubao.com/chat/211092…...

kube-vip实践
kube-vip 是一款专为 Kubernetes 设计的轻量级高可用(HA)和负载均衡工具,通过虚拟 IP(VIP)机制实现控制平面和服务的高可用性。以下从核心原理、部署实践到高级配置进行全面解析。 一、核心原理与模式 kube-vip 通过…...

python 中match...case 和 C switch case区别
文章目录 语法结构匹配模式的灵活性穿透特性缺省情况处理 在 Python 3.10 及以后的版本中引入了 match...case 语句,它和其他编程语言里的 switch...case 语句有相似之处,但也存在不少区别, 语法结构 match...case(Python&…...

Web前端考核 JavaScript知识点详解
一、JavaScript 基础语法 1.1 变量声明 关键字作用域提升重复声明暂时性死区var函数级✅✅❌let块级❌❌✅const块级❌❌✅ 1.1.1变量提升的例子 在 JavaScript 中,var 声明的变量会存在变量提升的现象,而 let 和 const 则不会。变量提升是指变量的声…...

Spring Boot3 配置文件
统一配置文件管理 SpringBoot工程下,进行统一的配置管理,你想设置的任何参数(端口号、项目根路径、数据库连接信息等等)都集中到一个固定位置和命名的配置文件(application.properties或application.yml)中࿰…...

消防设施操作员考试:巧用时间高效备考攻略
合理规划时间是备考消防设施操作员考试的关键,能让学习事半功倍。 一、制定详细时间表 根据备考时间和考试内容,制定每日、每周的学习计划。将学习时间合理分配给理论知识学习、技能实操练习和模拟考试。例如,每天安排 3 - 4 小时学习理…...

机器学习之KMeans算法
文章目录 引言1. KMeans算法简介2. KMeans算法的数学原理3. KMeans算法的步骤3.1 初始化簇中心3.2 分配数据点3.3 更新簇中心3.4 停止条件 4. KMeans算法的优缺点4.1 优点4.2 缺点 5. KMeans算法的应用场景5.1 图像分割5.2 市场细分5.3 文档聚类5.4 异常检测 6. Python实现KMea…...

深度学习技术与应用的未来展望:从基础理论到实际实现
深度学习作为人工智能领域的核心技术之一,近年来引起了极大的关注。它不仅在学术界带来了革命性的进展,也在工业界展现出了广泛的应用前景。从图像识别到自然语言处理,再到强化学习和生成对抗网络(GAN),深度…...

FastStoneCapture下载安装教程(附安装包)专业截图工具
文章目录 前言FastStoneCapture下载FastStoneCapture安装步骤FastStoneCapture使用步骤 前言 在日常工作与学习里,高效截图工具至关重要。本教程将为你呈现FastStoneCapture下载安装教程,助你轻松拥有。 FastStoneCapture下载 FastStone Capture 是一款…...

基于AWS Endpoint Security的合规性保障
设计AWS云架构方案实现基于AWS Endpoint Security(EPS)的合规性保障,使用EPS持续收集终端设备的安全状态数据(如补丁版本、密码策略),并通过CloudWatch生成合规性报告。企业可利用这些数据满足GDPR、HIPAA等法规对终端设备的安全审…...

26考研——图_图的遍历(6)
408答疑 文章目录 三、图的遍历图的遍历概述图的遍历算法的重要性图的遍历与树的遍历的区别图的遍历过程中的注意事项避免重复访问遍历算法的分类遍历结果的不唯一性 广度优先搜索广度优先搜索(BFS)概述BFS 的特点广度优先遍历的过程示例图遍历过程 BFS …...

C++类与对象的第一个简单的实战练习-3.24笔记
在哔哩哔哩学习的这个老师的C面向对象高级语言程序设计教程(118集全)讲的真的很不错 实战一: 情况一:将所有代码写到一个文件main.cpp中 #include<iostream> //不知道包含strcpy的头文件名称是什么,问ai可知 #include<…...

4.1 C#获取目录的3个方法的区别
C#中常用有如下3个获取目录的方式如下 1.Directory.GetCurrentDirectory():获取当前工作目录,工作目录可能被用户或其他代码修改。尽量少用。(似乎只要在运行中使用另存为或者打开某个文件夹,当前工作目录就修改) 2.Application…...
)
架构设计之自定义延迟双删缓存注解(上)
架构设计之自定义延迟双删缓存注解(上) 小薛博客官方架构设计之自定义延迟双删缓存注解(上)地址 1、业务场景问题 在多线程并发情况下,假设有两个数据库修改请求,为保证数据库与redis的数据一致性,修改请求的实现中需要修改数据库后&#…...