【零基础学python】python高级语法(四)
接续上面的系列文章:
【零基础学python】python基础语法(一)-CSDN博客
【零基础学python】python基础语法(二)-CSDN博客
【零基础学python】python高级语法(三)-CSDN博客

目录
2,字典
3,集合
4,函数
2,字典
- 字典初始
【1】字典的创建与价值
字典(Dictionary)是一种在Python中用于存储和组织数据的数据结构。元素由键和对应的值组成。其中,键(Key)必须是唯一的,而值(Value)则可以是任意类型的数据。在Python 中,字典使用大括号0来表示,键和值之间使用冒号:进行分隔,多个键值对之间使用逗号,分隔。
info = {"name":"yuanhao", "age":20, "height":120}
print(type(info)) #<class 'dict'>
del info["name"]
print(info)
info["wkrgfwk"] = "zhege"
print(info)- 字典的存储与特点
hash:百度百科
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
字典对象的核心其实是个散列表,而散列表是一个稀疏数组(不是每个位置都有值),每个单元叫做bucket,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用,由于,所有bucket结构和大小一致,我们可以通过偏移量来指定bucket的位置

字典的特点:
无序性:字典中的元素没有特定的顺序,不像列表和元组那样按照索引访问。
通过键来访问和操作字典中的值。
键是唯一的且不可变类型对象:用于标识值。值可以是任意类型的对象,如整数字符串、列表、元组等。
可变性:可以向字典中添加、修改和删除键值对。这使得字典成为存储和操作动态数据的理想选择。
info = {"name":"yuanhao", "age":20, "height":120}
print(bin(hash("age")))
#十进制转换成二进制
#键的要求 #1,字符串 #2,数字 #3,元组 #4,布尔值- 字典的基本操作
# 使用{}创建字典
gf ={"name":"高圆圆","age":32}
print(len(gf)) #(1)查键值
print(gf["name"]) #高圆圆
print(gf["age"]) #32
#(2)添加或修改键值对 注意:如果键存在,则是修改,否则是添加
gf["age"] = 29 # 修改键的值
gf["gender"〕= "female" # 添加键值对
#(3)删除键值对 del 删除命令
print(gf)
del gf["age" ]
print(gf)
del gf
print(gf)
#(4)判断键是否存在某字典中
print("weight" in gf)
#(5)循环
for key in gf: print(key,gf[key])
Python 字典中键(key)的名字不能被修改,我们只能根据键(key)修改值(value)
- 字典的内置方法

gf ={"name":"高圆圆","age":32}
#(1)创建字典
knowledge =〔'语文','数学','英语']
scores= dict.fromkeys(knowledge,60)
print(scores)
#(2)获取某键的值
print(gf.get("name")) #高圆圆
#(3)更新键值:添加或更改
gf.update({"age":18,"weight":"50kg"})
print(gf) #{'name':'高圆圆','age':18,'weight':'50kg'}
#(4)删除weight键值对14
ret = gf.pop("weight") # 返回删除的值
print(gf)
#(5)遍历字典键值对
for k,v in gf.items(): print(k,v)- 可变数据类型之字典
#列表字典的存储方式
l = [1,2,3]
d = {"a":1, "b":2}
#案例1
l1 = [3, 4, 5]
d1 = {"a":1, "b":2, "c":l1}
l1.append(6)
print(d1)
d1["c"][0] = 300
print(l1)
#案例2
d2 = {"a":1, "b":2, "c":3}
d3 = {"x":12, "y":11, "z":d2}
d2["z"] = 30
print(d3)
d3["z"].update({"z":30})
#为d3中增加d2中的成员{"z":30}
print(d3)
d3["z"]["a"] = 100 #等价于
d3["z"].update("a":100)
print(d2)
d3["z"] = 100
print(d3)
#案例3
d4 = {"x":10, "y":20}
l2 = [1, 3, d4]
d4["z"] = 30
print(d4) #{'x': 10, 'y': 20, 'z': 30}
l2[2].pop("y")
print(d4) # {'x': 10, 'z': 30}3,集合
- 集合的基本操作
集合(Set)是Python中的一种无序、不重复的数据结构。集合是由一组元素组成的,这些元素只能是不可变数据类型的,在集合中每个元素都是唯一的,即集合中不存在重复的元素。

# 集合内的元素必须是不可变的数据类型
s1 = {1,2,3}
print(len(s1))
print(type(s1))
#set类型的数据
#(1)无序:没有索引
print(s1)
#(2)唯一:集合可以去重
s2={1,2,3,3,2,2}
print(s2)
#面试题----将列表去重
l = [1,2,3,3,2,2]
#类型转换:将列表转为set
print(set(l))
#{1,2,3}
print(list(set(l))) #[1,2,3]
#(3)可变类型 列表、字典与集合
s1 = {1,2,3}
#内置方法
#添加
s1.add(5)
print(s1)
s1.update({1,2,3,4,6}) #需要更新再次加上一个集合类型的
print(s1)
#删除
s1.remove(5)
print(s1)
s1.discard(5)
#当删除的元素不存在的时候discard不会报错,而使用remove会导致报错的问题
print(s1)
s1.pop() #删除并返回任意的一个集合元素
print(s1)
s1.clear() #清空集合内的元素
print(s1)无序性:集合中的元素是无序的,即元素没有固定的顺序。因此,不能使用索引来访问集合中的元素。
唯一性:集合中的元素是唯一的,不允许存在重复的元素。如果尝试向集合中添加已经存在的元素,集合不会发生变化。
可变性:集合是可变的,可以通过添加或删除元素来改变集合的内容
- 集合高级操作
s1 = {1,2,3,4}
s2 = {3,4,5,6}
#方式1,交集& 差集- 并集|
print(s1 & s2)
print(s1 | s2)
print(s1 - s2)
#剩下s1有s2没有的
#方式2, 集合的内置方法
s3 = s1.intersection(s2)
#交集
print(s3)
s3 = s1.union(s2)
#并集
print(s3)
s3 = s1.difference(s2)
#差集
print(s3)
s3 = s1.symmetric_difference(s2)
#对称差集 print(s3)4,函数
- 函数的初识
一个程序有些功能代码可能会用到很多次,如果每次都写这样一段重复的代码,不但费时费力、容易出错,而且交给别人时也很麻烦,所以编程语言支持将代码以固定的格式封装(包装)成一个独立的代码块,只要知道这个代码块的名字就可以重复使用它,这个代码块就叫做函数(Function)
函数的本质是一功能代码块组织在一个函数名下,可以反复调用。
去重 (函数可以减少代码的重复性。通过将重复的代码逻辑封装成函数,可以避免在不同的地方重复编写相同的代码)
解耦 (函数对代码的组织结构化可以将代码分成逻辑上独立的模块,提高代码的可读性和可维护性,从而实现解耦)
"""
函数声明 一次声明
def 函数名(): 函数体 函数调用 多次调用
函数名()
"""在编程中,函数的参数指的是函数定义中声明的变量,用于接收函数调用时传递的数据。参数允许我们将值或引用传递给函数,以便在函数内部使用这些值进行计算、操作或处理。
函数参数可以有多个,每个参数都有一个名称和类型。函数定义中的参数称为形式参数(或简称为形参),而函数调用 时传递的实际值称为实际参数(或简称为实参)
函数的参数允许函数在不同的上下文中接收不同的数据,并且增加了函数的灵活性和可复用性。通过合理使用函数参数,可以编写出更通用、灵活的函数。
分为默认参数、位置参数、关键字参数与可变参数
# 函数的参数
def 函数名(函数参数): 函数体
"""
1,函数声明 一次声明
def 函数名(): 函数体 return 任意类型 #默认返回None
2,函数调用 多次调用
函数名()
3,函数的参数
def 函数名(函数参数): 函数体
"""
"""
3.1 位置参数----函数形参与实参要必须一一对应
def 函数名(形参1,形参2,...): 函数体
函数调用 函数名(实参1,实参2,...)
"""
def demo(x,y): print(x+y)
demo(1,2)
"""
3.2 默认参数----函数数声明时默认参数是为参数指定默认值,如果在函数调用时没传递该参数函数,将使用默认值 ----注意:默认参数必须放在位置参数的后面
def 函数名(形参1 = 默认参数,形参2,...): 函数体
函数调用
函数名(实参1,实参2,...)
"""
def demo(x,y=10): print(x+y) demo(100)
"""
3.3 关键字参数----关键字参数是通过指定参数名来传递的参数。调用函数时,可以根据参数名来传递实参,而不必遵循形参的顺序。 ----注意:关键字参数必须放在位置参数的后面
def 函数名(形参1,形参2,...): 函数体
函数调用
函数名(形参2=实参2,实参1=实参1,...)
"""
def demo(x,y): print(x+y)
demo(y=1,x=23)
"""
3.4 关键参数与默认参数同时存在时候的使用用法
"""
#用法1
def demo(x,y,z=0,w=0): print(x+y+z+w)
demo(12,23,w=23)
"""
3.5 可变参数----可变参数允许函数接受不定数量的参数 在函数定义中,可以使用特殊符号来表示可变数量的参数, 如 *args 用于接收任意数量的位置参数, **kwargs用于接收任意数量的关键字参数。 """ def demo(name, *data): print(data)
#最后打印出来的值是一个元组的类型 demo("dwgcqhv",2,33,2,4,34,3,4,5,45)
#注意传值的字典中各个元素的大小得要与函数的传参保持一致
#(1)在函数传值的时候使用
def print_info(name,age): print(name,age) data = {"name":"gsydihcghda", "age":10} print_info(**data)
#(2)在函数声明的时候使用
def print_info(name,**kawgs): str1 = kawgs.get("str1") str2 = kawgs.get("str2") print(name) print(str1) print(str2)
print_info("dhfcjhc",str1 = "qefqefe",str2 = "qefqefe")关于一些加*号的补充语法#===================================
# 补充语法
#(1 关于变量的加*号的序列化接收
x, y, *z = [1,23,5,56,12,324,4,5]
i, j, *k = (1,23,5,56,12,324,4,5)
print(i, j, k)
print(x, y, z)
# (2) 多个字符的累计打印
print("=" * 20)
# (3) 乘法的作用
print(2*12)
# (4) 次方
print(2**3)
# (5) 传参
def foo(x,y): print(x,y)
l = [1,2]
foo(*l)
q = {"name":"yuan","age":12}
foo(**q)
#====================================- 函数的作用域
作用域是指在程序中定义变量或函数时,这些变量或函数可被访问的范围。在不同的作用域中,变量和函数的可见性和访问性是不同的。
当访问一个变量时,Python 会按照 LEGB的顺序进行查找,直到找到第一个匹配的变量,然后停止查找。如果在所有作用域中都找不到变量的定义,就会引发 NameError。
L(Local):局部作用域。包括函数内部定义的变量和参数。在函数内部最先进行变量查找。
E(Enclosing):嵌套函数的父函数的作用域。如果在当前函数内部找不到变量,就会向上一层嵌套的函数中查找。
G(Global):全局作用域。在模块层次定义的变量,对于整个块都是可见的。
B(Built-in):内置作用域。包括 Python 的内置函数和异常。
x = 10 #全局作用域
def demo(): x = 100 #外部函数作用域 def in_demo(x): x = 30 #内部函数作用域 print(x) # 在内部函数中访问变量 in_demo(x)
print(x) #在全局作用域中访问变量 # 函数作用域的两个关键字 global 与 nonlocal# (1) global 的使用方法
y = 100
def demo1(): global y #将一个局部域的变量变为全局域变量 y = 200 print(y)
demo1()
print(y) # (2) nonlocal的使用方法
def demo1(): y = 200 print(y) def demo_in(): nonlocal y #将函数内嵌套的函数中的局部变量可以影响上一层的局部变量 y = 300 demo_in() print(y)
demo1()
print(y)- 函数的返回值
函数的返回值是指函数执行完毕后,通过 return 语句返回给调用者的结果,使用 return 语句可以将一个值或对象作为函数的返回值返回。这个返回值可以是任何有效的Python对象,例如数字、字符串、列表、字典等。函数执行到 return 语句时,会立即结束函数的执行,并将指定的返回值传递给调用者。
如果函内没有return,默认返回None,代表没有什么结果返回
#返回一个值
def demo(x,y): return x+y
print(demo(2,3))
#返回多个值
def demo(): name = "fdjgwfdhjw" age = 56 return name, age #默认会组成一个元组的类型
print(demo())- 匿名函数
#匿名函数 ----只能使用一次
ret = (lambda x,y: x+y)(100,300)
print(ret)- 常用的内置函数

相关文章:
【零基础学python】python高级语法(四)
接续上面的系列文章: 【零基础学python】python基础语法(一)-CSDN博客 【零基础学python】python基础语法(二)-CSDN博客 【零基础学python】python高级语法(三)-CSDN博客 目录 2,…...

HarmonyOS 之 @Require 装饰器自学指南
在 HarmonyOS 应用开发工作中,我频繁碰到组件初始化传参校验的难题。在复杂的组件嵌套里,要是无法确保必要参数在构造时准确传入,就极易引发运行时错误,而且排查起来费时费力。一次偶然的机会,我接触到了 Require 装饰…...

Redis Cluster 详解
Redis Cluster 详解 1. 为什么需要 Redis Cluster? Redis 作为一个高性能的内存数据库,在单机模式下可能会遇到以下问题: 单机容量受限:Redis 是基于内存存储的,单机的内存资源有限,单实例的 Redis 只能…...

基于CNN的FashionMNIST数据集识别6——ResNet模型
前言 之前我们在cnn已经搞过VGG和GoogleNet模型了,这两种较深的模型出现了一些问题: 梯度传播问题 在反向传播过程中,梯度通过链式法则逐层传递。对于包含 L 层的网络,第 l 层的梯度计算为: 其中 a(k) 表示第 k层的…...

0323-B树、B+树
多叉树---->B树(磁盘)、B树 磁盘由多个盘片组成,每个盘片分为多个磁道和扇区。数据存储在这些扇区中,扇区之间通过指针链接,形成链式结构。 内存由连续的存储单元组成,每个单元有唯一地址,数…...

深度学习3-pytorch学习
深度学习3-pytorch学习 Tensor 定义与 PyTorch 操作 1. Tensor 定义: Tensor 是 PyTorch 中的数据结构,类似于 NumPy 数组。可以通过不同方式创建 tensor 对象: import torch# 定义一个 1D Tensor x1 torch.Tensor([3, 4])# 定义一个 Fl…...

【工作记录】F12查看接口信息及postman中使用
可参考 详细教程:如何从前端查看调用接口、传参及返回结果(附带图片案例)_f12查看接口及参数-CSDN博客 1、接口信息 接口基础知识2:http通信的组成_接口请求信息包括-CSDN博客 HTTP类型接口之请求&响应详解 - 三叔测试笔记…...

正则表达式-万能表达式
1、正则 正则表达式是一组由字母和符号组成的特殊文本, 它可以用来从文本中找 出满足你想要的格式的句子. {“basketId”: 0, “count”: 1, “prodId”: #prodId#, “shopId”: 1, “skuId”: #skuId#} #prodId# re相关的文章: https://www.cnblogs.com/Simple-S…...

2024年认证杯SPSSPRO杯数学建模B题(第二阶段)神经外科手术的定位与导航全过程文档及程序
2024年认证杯SPSSPRO杯数学建模 B题 神经外科手术的定位与导航 原题再现: 人的大脑结构非常复杂,内部交织密布着神经和血管,所以在大脑内做手术具有非常高的精细和复杂程度。例如神经外科的肿瘤切除手术或血肿清除手术,通常需要…...

Android 12系统源码_系统启动(二)Zygote进程
前言 Zygote(意为“受精卵”)是 Android 系统中的一个核心进程,负责 孵化(fork)应用进程,以优化应用启动速度和内存占用。它是 Android 系统启动后第一个由 init 进程启动的 Java 进程,后续所有…...

MOSN(Modular Open Smart Network)-05-MOSN 平滑升级原理解析
前言 大家好,我是老马。 sofastack 其实出来很久了,第一次应该是在 2022 年左右开始关注,但是一直没有深入研究。 最近想学习一下 SOFA 对于生态的设计和思考。 sofaboot 系列 SOFAStack-00-sofa 技术栈概览 MOSN(Modular O…...

Flink介绍与安装
Apache Flink是一个在有界数据流和无界数据流上进行有状态计算分布式处理引擎和框架。Flink 设计旨在所有常见的集群环境中运行,以任意规模和内存级速度执行计算。 一、主要特点和功能 1. 实时流处理: 低延迟: Flink 能够以亚秒级的延迟处理数据流,非常…...

【gradio】从零搭建知识库问答系统-Gradio+Ollama+Qwen2.5实现全流程
从零搭建大模型问答系统-GradioOllamaQwen2.5实现全流程(一) 前言一、界面设计(计划)二、模块设计1.登录模块2.注册模块3. 主界面模块4. 历史记录模块 三、相应的接口(前后端交互)四、实现前端界面的设计co…...

PowerBI,用度量值实现表格销售统计(含合计)的简单示例
假设我们有产品表 和销售表 我们想实现下面的效果 表格显示每个产品的信息,以及单个产品的总销量 有一个切片器能筛选各个门店的产品销量 还有一个卡片图显示所筛选条件下,所有产品的总销量 实现方法: 1.我们新建一个计算表,把…...

Mac 常用命令
一、文件操作(必知必会) 1. 快速导航 cd ~/Documents # 进入文档目录 cd .. # 返回上级目录 pwd # 显示当前路径 2. 文件管理 touch new_file.txt # 创建空文件 mkdir -p project/{src,docs} # 递归创建目录 cp …...

26考研——查找_树形查找_二叉排序树(BST)(7)
408答疑 文章目录 三、树形查找二叉排序树(BST)二叉排序树中结点值之间的关系二叉树形查找二叉排序树的查找过程示例 向二叉排序树中插入结点插入过程示例 构造二叉排序树的过程构造示例 二叉排序树中删除结点的操作情况一:被删除结点是叶结点…...

美摄科技开启智能汽车车内互动及娱乐解决方案2.0
在科技飞速发展的今天,汽车已不再仅仅是简单的代步工具,而是逐渐演变为集出行、娱乐、社交于一体的智能移动空间。美摄科技,作为前沿视觉技术与人工智能应用的领航者,凭借其卓越的技术实力和创新精神,携手汽车行业&…...

【行驶证识别】批量咕嘎OCR识别行驶证照片复印件图片里的文字信息保存表格或改名字,基于QT和腾讯云api_ocr的实现方式
项目背景 在许多业务场景中,如物流管理、车辆租赁、保险理赔等,常常需要处理大量的行驶证照片复印件。手动录入行驶证上的文字信息,像车主姓名、车辆型号、车牌号码等,不仅效率低下,还容易出现人为错误。借助 OCR(光学字符识别)技术,能够自动识别行驶证图片中的文字信…...

Vue-admin-template安装教程
#今天配置后台管理模板发现官方文档的镜像网站好像早失效了,自己稍稍总结了一下方法# 该项目环境需要node17及以下,如果npm install这一步报错可能是这个原因 git clone https://github.com/PanJiaChen/vue-admin-template.git cd vue-admin-template n…...

21.Excel自动化:如何使用 xlwings 进行编程
一 将Excel用作数据查看器 使用 xlwings 中的 view 函数。 1.导包 import datetime as dt import xlwings as xw import pandas as pd import numpy as np 2.view 函数 创建一个基于伪随机数的DataFrame,它有足够多的行,使得只有首尾几行会被显示。 df …...

LabVIEW FPGA与Windows平台数据滤波处理对比
LabVIEW在FPGA和Windows平台均可实现数据滤波处理,但两者的底层架构、资源限制、实时性及应用场景差异显著。FPGA侧重硬件级并行处理,适用于高实时性场景;Windows依赖软件算法,适合复杂数据处理与可视化。本文结合具体案例&#x…...

【NLP 48、大语言模型的神秘力量 —— ICL:in context learning】
目录 一、ICL的优势 1.传统做法 2.ICL做法 二、ICL的发展 三、ICL成因的两种看法 1.meta learning 2.Bayesian Inference 四、ICL要点 ① 语言模型的规模 ② 提示词prompt中提供的examples数量和顺序 ③ 提示词prompt的形式(format) 五、fine-tune VS I…...

vue 中渲染 markdown 格式的文本
文章目录 需求分析第一步:安装依赖第二步:创建 Markdown 渲染组件第三步,使用实例扩展功能1. 代码高亮:2. 自定义渲染规则:需求 渲染 markdown 格式的文本 分析 在Vue 3中实现Markdown渲染的常见方法。通常有两种方式:使用现有的Markdown解析库,或者自己编写解析器…...

工业4G路由器赋能智慧停车场高效管理
工业4G路由器作为智慧停车场管理系统通信核心,将停车场内的各个子系统连接起来,包括车牌识别系统、道闸控制系统、车位检测系统、收费系统以及监控系统等。通过4G网络,将这些系统采集到的数据传输到云端服务器或管理中心,实现信息…...
)
卡尔曼滤波入门(二)
核心思想 卡尔曼滤波的核心就是在不确定中寻找最优,那么怎么定义最优呢?答案是均方误差最小的,便是最优。 卡尔曼滤波本质上是一种动态系统状态估计器,它回答了这样一个问题: 如何从充满噪声的观测数据中,…...

企业如何平稳实现从Tableau到FineBI的信创迁移?
之前和大家分享了《如何将Tableau轻松迁移到Power BI》。但小编了解到,如今有些企业更愿意选择国产BI平台。为此,小编今天以Fine BI为例子,介绍如何从Tableau轻松、低成本地迁移到国产BI平台。 在信创政策全面推进的背景下,企业数…...

蓝桥与力扣刷题(蓝桥 蓝桥骑士)
题目:小明是蓝桥王国的骑士,他喜欢不断突破自我。 这天蓝桥国王给他安排了 N 个对手,他们的战力值分别为 a1,a2,...,an,且按顺序阻挡在小明的前方。对于这些对手小明可以选择挑战,也可以选择避战。 身为高傲的骑士&a…...
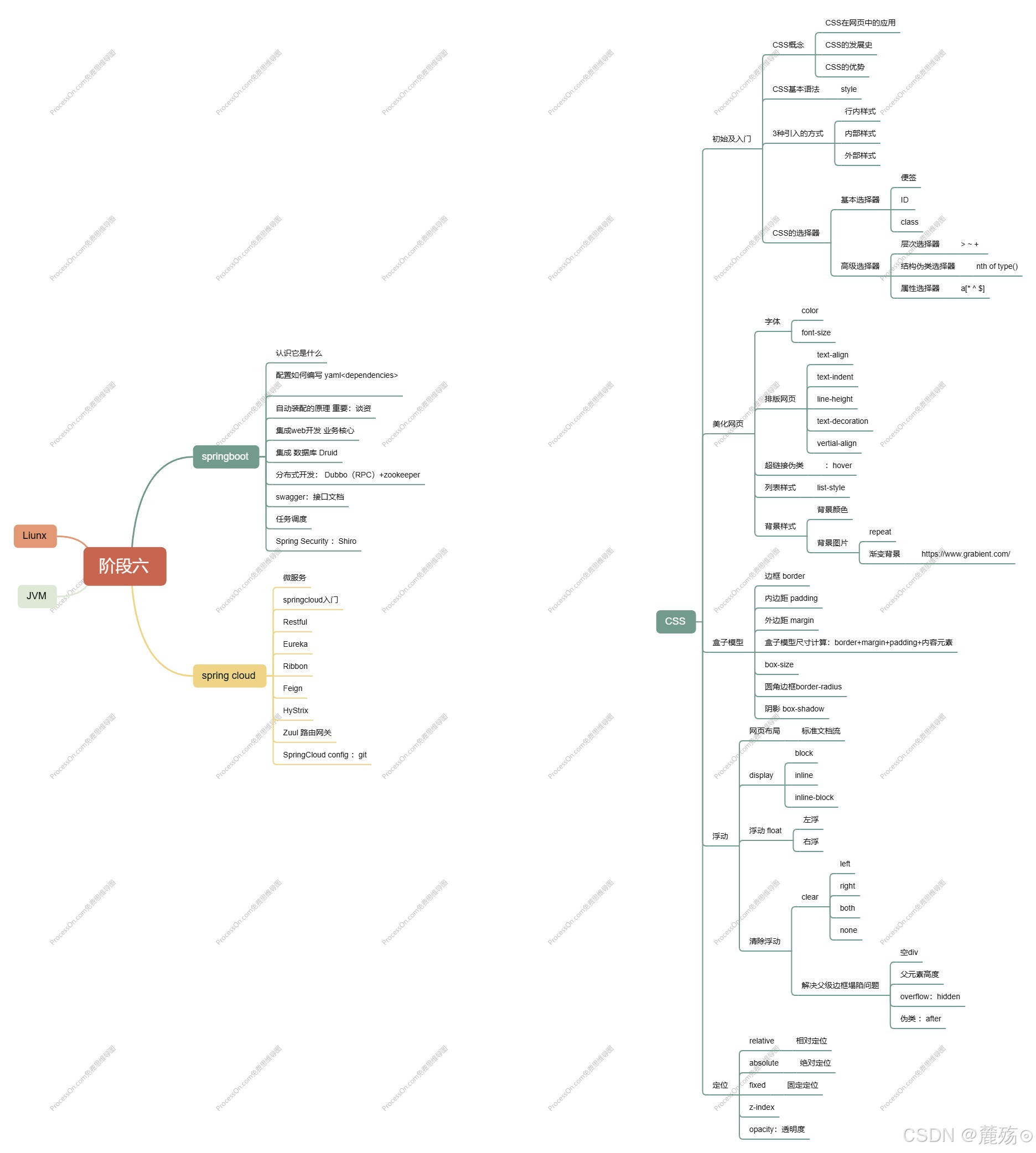
前端学习笔记--CSS
HTMLCSSJavaScript 》 结构 表现 交互 如何学习 1.CSS是什么 2.CSS怎么用? 3.CSS选择器(重点,难点) 4.美化网页(文字,阴影,超链接,列表,渐变。。。) 5…...

阶段一:Java基础语法
目标:掌握Java的基本语法,理解变量、数据类型、运算符、控制结构等。 1. Java开发环境搭建 安装JDK配置环境变量编写第一个Java程序 代码示例: // HelloWorld.java public class HelloWorld { // 定义类名为 HelloWorldpublic static vo…...

31天Python入门——第15天:日志记录
你好,我是安然无虞。 文章目录 日志记录python的日志记录模块创建日志处理程序并配置输出格式将日志内容输出到控制台将日志写入到文件 logging更简单的一种使用方式 日志记录 日志记录是一种重要的应用程序开发和维护技术, 它用于记录应用程序运行时的关键信息和…...