《Python Web网站部署应知应会》No4:基于Flask的调用AI大模型的高性能博客网站的设计思路和实战(上)
基于Flask的调用AI大模型的高性能博客网站的设计思路和实战(上)
摘要
本文详细探讨了一个基于Flask框架的高性能博客系统的设计与实现,该系统集成了本地AI大模型生成内容的功能。我们重点关注如何在高并发、高负载状态下保持系统的高性能和稳定性.用代码写一个网站现在越来越容易,但是要让网站在实际场景中保持稳定和高性能,尤其在大模型AI接口调用高并发背景下,真的需要一定的技术。文章详细介绍了多层次缓存策略、异步处理机制、请求批处理技术以及全面的性能监控系统的实现。通过多种性能测试工具的实战应用,包括负载测试、缓存性能测试和并发性能测试,我们不仅验证了系统的性能表现,还收集了关键数据指导持续优化。文章同时分享了在开发过程中遇到的各种挑战及解决方案,为类似系统的开发提供了实用的参考。
项目背景
随着内容创作需求的爆发性增长,AI辅助写作成为一种趋势。我们开发的这个Flask博客系统不仅支持传统的内容发布功能,还集成了本地部署的Ollama大模型,提供内容生成服务。然而,AI模型推理往往需要大量计算资源,容易成为系统的性能瓶颈,特别是在面对大量并发请求时。
系统的核心需求包括:
- 支持用户注册、登录、权限管理
- 博客内容的创建、编辑、发布和阅读
- 基于本地Ollama模型的AI内容生成(使用智谱 GLM4-9B模型)
- 在高并发(100+用户同时访问)情况下保持良好响应性
- 实时监控系统健康状态和性能指标
这些需求促使我们思考如何在Flask这样的轻量级框架上,构建一个能够支撑高并发访问、处理计算密集型任务的高性能系统。
网站截图



Flask博客网站核心文件结构说明
flask_blog/
│
├── app/ # 应用主目录
│ ├── __init__.py # 应用初始化,创建Flask实例和配置
│ ├── models.py # 数据库模型定义(用户、博客文章等)
│ ├── routes.py # 路由和视图函数定义
│ ├── forms.py # Web表单定义(登录、注册、发布博客等)
│ ├── ai_service.py # AI内容生成服务接口
│ ├── cache.py # 缓存管理实现
│ ├── auth.py # 用户认证和授权
│ ├── static/ # 静态文件目录
│ │ ├── css/ # CSS样式文件
│ │ │ └── style.css # 主样式表
│ │ ├── js/ # JavaScript文件
│ │ │ └── main.js # 主JS文件
│ │ └── images/ # 图片资源
│ └── templates/ # HTML模板
│ ├── base.html # 基础布局模板
│ ├── index.html # 首页模板
│ ├── login.html # 登录页面
│ ├── register.html # 注册页面
│ ├── post.html # 博客文章详情页
│ ├── create_post.html # 创建博客页面
│ └── profile.html # 用户资料页面
│
├── instance/ # 实例配置目录(包含本地配置和数据库)
│ └── blog.db # SQLite数据库文件
│
├── config.py # 应用配置类定义
├── reset_db.py # 数据库重置和初始化脚本
├── requirements.txt # 项目依赖包列表
└── README.md # 项目说明文档
文件/文件夹说明
核心应用文件
-
app/init.py: 应用工厂函数,创建和配置Flask应用实例,初始化扩展(如Flask-SQLAlchemy、Flask-Login)。主要功能包括数据库连接配置、登录管理器设置、蓝图注册等。
-
app/models.py: 定义数据库模型,包括User(用户)和Post(博客文章)等实体。User模型包含用户名、密码哈希、电子邮件等字段,Post模型包含标题、内容、创建时间和作者外键等字段。
-
app/routes.py: 定义所有路由和视图函数,处理Web请求。包括首页、登录、注册、博客详情、创建/编辑博客、用户个人资料等路由,以及AI内容生成接口。
-
app/forms.py: 使用Flask-WTF定义表单类,用于处理用户输入验证。包括登录表单、注册表单、博客发布表单以及AI内容生成表单等。
-
app/ai_service.py: 与Ollama模型交互,处理AI内容生成请求。封装了与本地AI模型通信的接口,处理请求参数和流式响应生成。
-
app/cache.py: 实现多层缓存策略,管理内存缓存和Redis缓存。定义缓存键生成、设置缓存内容和过期时间、获取缓存内容等功能,优化高频请求性能。
-
app/auth.py: 处理用户认证和授权,实现登录、注册和会话管理。包括密码哈希处理、用户验证、权限检查等功能。
静态文件和模板
-
app/static/css/style.css: 主要样式表,定义网站的视觉外观和布局。
-
app/static/js/main.js: 主要JavaScript文件,处理客户端交互和动态内容。
-
app/static/images/: 存放网站使用的图标、背景图和其他图像资源。
-
app/templates/base.html: 基础模板,定义网站的公共结构,包括导航栏、页脚等,其他模板继承自它。
-
app/templates/index.html: 首页模板,展示博客文章列表。
-
app/templates/login.html: 用户登录页面模板。
-
app/templates/register.html: 用户注册页面模板。
-
app/templates/post.html: 博客文章详情页模板,显示完整文章内容和评论。
-
app/templates/create_post.html: 创建和编辑博客文章的页面模板。
-
app/templates/profile.html: 用户个人资料页面模板,显示用户信息和发布的文章。
实例配置和数据
- instance/blog.db: SQLite数据库文件,存储所有应用数据,包括用户账户、博客文章和相关内容。
根目录文件
-
config.py: 应用配置类,定义开发、测试和生产环境的不同配置参数,如数据库URI、密钥等。
-
reset_db.py: 重置数据库并创建测试数据的脚本,方便开发和测试过程重新初始化环境。
-
requirements.txt: 项目Python依赖列表,包含所有必需的包及其版本,如Flask、Flask-SQLAlchemy、Flask-Login等。
-
README.md: 项目说明文档,包含安装步骤、使用方法、功能描述等信息。
文件结构采用了Flask官方推荐的应用工厂模式,将功能模块化组织,便于理解和维护。项目使用SQLite作为开发数据库,可以在不需要额外服务的情况下快速启动和测试应用。
核心概念和知识点
1. 高性能Web应用架构设计原则
在设计高性能Web应用时,我们遵循以下原则:
- 关注点分离:将不同功能模块解耦,使系统更易于扩展和维护
- 分层缓存:在多个层级实施缓存策略,减少重复计算和数据库访问
- 异步处理:将计算密集型任务异步化,避免阻塞主线程
- 批处理技术:合并同类请求,减少资源争用和上下文切换
- 实时监控:持续监测系统性能,及时发现并解决问题
2. Flask应用的性能优化技术
Flask作为一个轻量级框架,需要结合多种技术来提升其性能:
- 应用工厂模式:便于配置管理和测试
- 蓝图组织代码:模块化应用结构
- WSGI服务器:使用Gunicorn/uWSGI替代Flask内置服务器
- 数据库优化:合理设计索引、使用连接池
- 代码优化:减少不必要的计算和SQL查询
3. AI模型集成与性能优化
集成AI大模型时的主要挑战是处理其高计算需求:
- 流式响应:逐步返回AI生成内容,提升用户体验
- 推理优化:调整模型参数和批处理大小,平衡速度和质量
- 模型量化:降低模型精度以提高推理速度
- 计算资源管理:合理分配CPU/GPU资源
4. 高并发处理策略
处理高并发请求的核心策略:
- 连接池管理:有效复用数据库连接
- 请求限流:防止系统过载
- 队列机制:平滑处理请求峰值
- 负载均衡:分散请求到多个工作进程
技术实战和代码
1. 多层次缓存策略实现
我们实现了三层缓存策略,显著提升了系统响应速度:
# 内存缓存层
memory_cache = {}# Redis缓存层
def get_from_cache(key):# 先尝试从内存缓存获取if key in memory_cache:CACHE_HIT.inc() # Prometheus指标return memory_cache[key]# 再尝试从Redis缓存获取cached_data = redis_client.get(key)if cached_data:# 同时更新内存缓存memory_cache[key] = cached_dataCACHE_HIT.inc()return cached_dataCACHE_MISS.inc()return None# 数据库查询缓存装饰器
def cache_query(ttl=3600):def decorator(f):@wraps(f)def decorated_function(*args, **kwargs):# 生成缓存键key = f"query_{f.__name__}_{str(args)}_{str(kwargs)}"result = get_from_cache(key)if result is None:# 缓存未命中,执行查询start = time.time()result = f(*args, **kwargs)query_time = time.time() - startDB_QUERY_TIME.observe(query_time) # 记录查询时间# 存入缓存set_in_cache(key, result, ttl)return resultreturn decorated_functionreturn decorator
2. AI生成内容的流式响应实现
为提高用户体验,我们实现了AI内容的流式响应:
@app.route('/generate-blog', methods=['POST'])
def generate_blog():title = request.form.get('title')# 检查缓存cache_key = f"blog_gen_{title}"cached_result = get_from_cache(cache_key)if cached_result:return cached_result# 未命中缓存,调用AI模型def generate():start_time = time.time()INFERENCE_COUNT.inc() # 增加推理计数prompt = f"写一篇关于'{title}'的博客文章,包含引言、主体和总结。"# 流式生成内容for chunk in ollama_client.generate(prompt=prompt, model="llama2"):yield chunk# 记录生成时间generation_time = time.time() - start_timeAI_GENERATION_TIME.observe(generation_time)# 异步保存到缓存(完整内容需在流式传输后组装)# 此处使用线程避免阻塞响应threading.Thread(target=lambda: save_complete_content_to_cache(title, complete_content)).start()return Response(generate(), mimetype='text/plain')
3. 异步任务处理与请求批处理
对于计算密集型任务,我们使用异步队列和批处理技术:
# 使用Redis作为任务队列
task_queue = redis_client.StrictRedis(host='localhost', port=6379, db=1)# 提交生成任务
def submit_generation_task(title, callback_url):task_id = str(uuid.uuid4())task_data = {'task_id': task_id,'title': title,'callback_url': callback_url,'status': 'pending','timestamp': time.time()}task_queue.lpush('generation_tasks', json.dumps(task_data))return task_id# 批处理worker
def batch_processing_worker():while True:# 收集短时间内积累的任务tasks = []start_time = time.time()# 批量收集任务,最多等待100mswhile time.time() - start_time < 0.1 and len(tasks) < 10:task_data = task_queue.rpop('generation_tasks')if task_data:tasks.append(json.loads(task_data))else:time.sleep(0.01)if not tasks:time.sleep(0.1)continue# 批量处理任务batch_process_tasks(tasks)
4. 性能监控系统集成
我们使用Prometheus和Grafana构建了全面的监控系统:
from prometheus_client import Counter, Histogram, Gauge, Summary, start_http_server# 指标定义
REQUEST_COUNT = Counter("request_count", "Total number of requests", ["status"])
REQUEST_LATENCY = Histogram("request_latency_seconds", "Request latency in seconds")
INFERENCE_COUNT = Counter("inference_count", "Total number of AI inferences")
CACHE_HIT = Counter("cache_hit_count", "Cache hits")
CACHE_MISS = Counter("cache_miss_count", "Cache misses")
ACTIVE_USERS = Gauge("active_users", "Number of active users")
DB_QUERY_TIME = Summary("db_query_seconds", "Database query time")
BLOG_CREATE_COUNT = Counter("blog_create_count", "Blog creation count")
AI_GENERATION_TIME = Histogram("ai_generation_seconds", "AI content generation time",buckets=[0.1, 0.5, 1.0, 2.0, 5.0, 10.0, 30.0, 60.0])def init_metrics(app):@app.before_requestdef before_request():request.start_time = time.time()@app.after_requestdef after_request(response):process_time = time.time() - request.start_timestatus = "success" if response.status_code < 400 else "failure"REQUEST_COUNT.labels(status=status).inc()REQUEST_LATENCY.observe(process_time)return response# 启动指标服务器start_http_server(8001)
5. 并发性能测试工具
我们开发了专门的并发测试工具,评估系统在不同并发级别下的表现:
class ConcurrencyTester:"""并发性能测试工具"""def __init__(self, base_url="http://127.0.0.1:5000"):self.base_url = base_urlself.concurrency_levels = [1, 5, 10, 20, 50, 100]self.results = {}self.endpoints = [{"name": "首页", "url": "/", "method": "get", "data": None},{"name": "博客详情", "url": "/post/1", "method": "get", "data": None},{"name": "AI生成", "url": "/generate-blog", "method": "post", "data": lambda i: {"title": f"并发测试博客 {i}"}}]async def run_test(self, endpoint, concurrency):"""运行特定端点和并发级别的测试"""async with aiohttp.ClientSession() as session:tasks = []for i in range(concurrency):tasks.append(self.make_request(session, endpoint, i))durations = await asyncio.gather(*tasks)# 过滤出非None值durations = [d for d in durations if d is not None]return durationsasync def test_all_levels(self):"""测试所有端点在所有并发级别下的性能"""for endpoint in self.endpoints:endpoint_name = endpoint["name"]self.results[endpoint_name] = {}for level in self.concurrency_levels:durations = await self.run_test(endpoint, level)if durations:self.results[endpoint_name][level] = {"avg": np.mean(durations),"median": np.median(durations),"max": np.max(durations),"min": np.min(durations),"p95": np.percentile(durations, 95),"throughput": level / np.sum(durations),"error_rate": (level - len(durations)) / level}else:print(" 所有请求均失败")
疑难点与解决方案
1. AI模型推理延迟问题
问题:AI内容生成的平均响应时间达到3秒以上,严重影响用户体验。
解决方案:
- 实现流式响应,使用户能立即看到部分输出
- 调整模型参数,减少tokens生成总量
- 对常见主题预先生成内容并缓存
- 实现模型量化,用精度换取速度
优化后的代码:
def generate_blog_content(title):# 检查是否是热门主题,优先使用模板template = get_template_for_topic(extract_topic(title))if template:# 使用模板+少量自定义替换热门主题请求return customize_template(template, title)# 调整生成参数,限制tokensparams = {"model": "llama2-7b-chat-q4", # 量化版模型"prompt": f"写一篇关于'{title}'的简短博客...","max_tokens": 800, # 限制生成长度"temperature": 0.7 # 调整创造性}# 流式响应return stream_generate(params)
2. 缓存一致性问题
问题:多层缓存导致数据不一致,用户看到过期内容。
解决方案:
- 实现缓存失效传播机制
- 使用版本号标记缓存内容
- 为不同类型内容设置合理的TTL策略
缓存管理核心代码:
def invalidate_cache(key_pattern):"""使某一类缓存失效"""# 找到所有匹配的键matched_keys = redis_client.keys(key_pattern)# 清除Redis缓存if matched_keys:redis_client.delete(*matched_keys)# 清除内存缓存for k in list(memory_cache.keys()):if re.match(key_pattern, k):del memory_cache[k]# 发布缓存失效消息,通知其他服务器节点redis_client.publish('cache_invalidation', key_pattern)
3. 数据库连接池耗尽
问题:高并发下数据库连接池被耗尽,导致服务不可用。
解决方案:
- 优化连接池配置,增加最大连接数
- 减少长连接占用时间
- 实现连接租用超时和健康检查
- 增加慢查询监控
连接池优化代码:
# 数据库连接池配置
app.config['SQLALCHEMY_ENGINE_OPTIONS'] = {'pool_size': 30, # 连接池大小'max_overflow': 15, # 最大允许溢出连接数'pool_timeout': 30, # 等待获取连接的超时时间'pool_recycle': 1800, # 连接回收时间'pool_pre_ping': True # 使用前ping测试连接健康
}# 监控数据库连接使用情况
@app.after_request
def track_db_connections(response):conn_info = db.engine.pool.status()POOL_USED_CONNECTIONS.set(conn_info['used'])POOL_AVAILABLE_CONNECTIONS.set(conn_info['available'])return response
4. 内存泄漏问题
问题:长时间运行后,内存占用持续增加,最终导致OOM。
解决方案:
- 使用内存分析工具(如memory-profiler)找出泄漏点
- 优化内存缓存管理,实现LRU淘汰策略
- 定期清理不使用的资源
- 增加内存使用监控
内存管理代码:
class LRUCache:"""有大小限制的LRU缓存实现"""def __init__(self, capacity=1000):self.cache = OrderedDict()self.capacity = capacitydef get(self, key):if key not in self.cache:return None# 将访问的元素移至末尾,表示最近使用self.cache.move_to_end(key)return self.cache[key]def put(self, key, value):if key in self.cache:# 更新现有键值self.cache.move_to_end(key)elif len(self.cache) >= self.capacity:# 移除最不常用的元素self.cache.popitem(last=False)self.cache[key] = value# 替换全局内存缓存
memory_cache = LRUCache(capacity=10000)# 定期清理任务
def cleanup_resources():while True:try:gc.collect() # 触发垃圾回收# 记录当前内存使用情况MEMORY_USAGE.set(get_process_memory_info())time.sleep(300) # 每5分钟执行一次except Exception as e:print(f"清理任务出错: {e}")
性能优化成果
通过综合应用上述技术和策略,我们在系统性能上取得了显著成果:
-
响应时间:
- 普通页面请求从平均250ms降至50ms
- AI生成内容从3.5秒降至平均1.2秒(感知延迟降至0.3秒)
-
吞吐量:
- 系统每秒峰值请求处理能力从50提升至280
- AI生成接口并发处理能力从10提升至50
-
缓存效率:
- 缓存命中率从最初的40%提升至85%
- 数据库查询减少了65%
-
系统稳定性:
- 能够稳定处理100+用户的持续访问
- 错误率从峰值5%降至0.2%以下
- 内存使用趋于稳定,不再出现泄漏问题
总结和扩展思考
通过这个项目,我们成功构建了一个既具备传统内容管理功能,又能提供AI生成服务的高性能博客系统。这种结合传统Web应用和AI技术的系统代表了当前应用开发的一个重要趋势。
关键经验总结
- 分层设计的重要性:清晰的层次结构让优化工作更有针对性
- 监控先行:完善的监控系统是发现问题和评估优化效果的基础
- 多层缓存的效果显著:不同层次的缓存共同作用,极大提升了系统性能
- 用户体验优先:流式响应虽然没有减少总处理时间,但大幅提升了用户体验
- 性能测试的系统化:建立全面的测试体系,能持续指导优化方向
未来扩展方向
-
微服务化:将AI处理拆分为独立服务,实现更好的扩展性
+--------------+ +------------------+ +-------------+ | Flask Web | <--> | API Gateway | <--> | AI Service | | Application | | Load Balancer | | (Scalable) | +--------------+ +------------------+ +-------------+ -
混合部署模式:根据需求灵活选择本地或云端AI模型
def select_ai_model(request_params):"""根据请求复杂度选择本地或云端模型"""if is_complex_request(request_params):return cloud_ai_clientreturn local_ai_client -
个性化缓存策略:基于用户行为分析的智能缓存预热
def preload_cache_for_trending_topics():"""预先生成热门话题的内容并缓存"""trending_topics = analyze_trending_topics()for topic in trending_topics:submit_generation_task(topic, cache_only=True) -
边缘计算:将部分计算和缓存下沉到更接近用户的节点
+-------------+ +---------------+ +--------------+ | User Device | --> | Edge Node | --> | Central | | (Browser) | | (Cache+Basic | | Application | +-------------+ | Processing) | +--------------++---------------+
适用场景与价值
这种高性能博客系统架构特别适用于以下场景:
- 内容创作平台:需要AI辅助内容生成的创作系统
- 教育平台:需要生成教学内容和示例的教育网站
- 企业知识库:需要智能搜索和内容推荐的知识管理系统
- 媒体网站:需要快速内容生成和发布的新闻媒体平台
最后,高性能Web应用的开发是一个持续迭代的过程。通过科学的测量、分析和优化循环,我们能够不断提升系统性能,为用户提供更好的体验。本项目中使用的技术和方法,可以作为其他融合AI功能的Web应用的参考模型。
相关文章:
《Python Web网站部署应知应会》No4:基于Flask的调用AI大模型的高性能博客网站的设计思路和实战(上)
基于Flask的调用AI大模型的高性能博客网站的设计思路和实战(上) 摘要 本文详细探讨了一个基于Flask框架的高性能博客系统的设计与实现,该系统集成了本地AI大模型生成内容的功能。我们重点关注如何在高并发、高负载状态下保持系统的高性能和…...

使用 Docker Compose 在单节点部署多容器
Docker Compose 是什么 Docker Compose 是一个用于运行多容器应用的工具, 通过一个docker-compose.yml文件, 配置应用的服务、网络和卷,然后使用简单的命令启动或停止所有服务 为什么需要 Docker Compose 当你有一个包含多个相互依赖的容器应用时,手动…...

STM32_HAL开发环境搭建【Keil(MDK-ARM)、STM32F1xx_DFP、 ST-Link、STM32CubeMX】
安装Keil(MDK-ARM)【集成开发环境IDE】 我们会在Keil(MDK-ARM)上去编写代码、编译代码、烧写代码、调试代码。 Keil(MDK-ARM)的安装方法: 教学视频的第02分03秒开始看。 安装过程中请修改一下下面两个路径,避免占用C盘空间。 Core就是Keil(MDK-ARM)的…...

在 React 中,组件之间传递变量的常见方法
目录 1. **通过 Props 传递数据**2. **通过回调函数传递数据**3. **通过 Context API 传递数据**4. **通过 Redux 管理全局状态**5. **通过事件总线(如 Node.js 的 EventEmitter)**6. **通过 Local Storage / Session Storage**7. **通过 URL 查询参数传…...

拦截器和过滤器详解
在 Java Web 开发中,拦截器(Interceptor)和过滤器(Filter)是两种常见的请求处理机制,它们用于对请求和响应进行预处理和后处理 1. 过滤器(Filter) 1.1 作用 Filter 主要用于对 请求…...

多线程—JUC(java.util.concurrent)
上篇文章: 多线程—synchronized原理https://blog.csdn.net/sniper_fandc/article/details/146713129?fromshareblogdetail&sharetypeblogdetail&sharerId146713129&sharereferPC&sharesourcesniper_fandc&sharefromfrom_link 目录 1 Calla…...
)
软件工程面试题(十二)
1、文件和目录(i/o)操作,怎么列出某目录下所有文件?某目录下所有子目录,怎么判断文件或目录是否存在?如何读写文件? 列出某目录下所有文件:调用listFile(),然后判断每个File对象是否是文件可以调用 isFile(),判断是否是文件夹可以调用isDirectory(),判断文件或目…...

从零开始跑通3DGS教程:(三)坐标系与尺度编辑(CloudCompare)
写在前面 本文内容 本文所属《从零开始跑通3DGS教程》系列文章; sfm重建的点云已经丢掉了尺度信息,并且坐标系跟图像数据有关(SFM初始化选择的图像),所以如果想恢复物理真实尺度,以及在想要的视角下渲染,那么需要对尺度…...

多线程 - 线程安全引入
写一个代码,让主线程创建一个新的线程,由新的线程负责完成一系列的运算(比如:1 2 3 ... 1000),再由主线程负责获取到最终结果。 但打印结果为 result 0,略微思考,明白了要让 t 线…...

笔记:基于环境语义的通感融合技术,将传统通信由“被动接收”转为“主动感知”
《基于计算机视觉的感知通信融合理论与关键技术研发进展》 介绍了联合研发的基于环境语义的通感融合技术研发进展。 观点:利用环境感知信息或环境语义辅助通信的通感融合技术成为6G重要方向之一 产出:基于环境感知的毫米波波束管理方案,并…...

【面试八股】:CAS指令
一、CAS 面试题 1. 说说CAS、CAS有什么问题(ABA)?(美团一面) Compare And Swap 对比交换(原子指令) CAS是 CPU指令 操作系统原生 API,JVM对它进行了封装(C),供我们使用。 通过判断 内存 和 …...

matplot显示中文
import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties 指定字体文件路径 font_path ‘/usr/share/fonts/SIMHEI.TTF’ font_prop FontProperties(fnamefont_path) 示例代码 plt.plot([1, 2, 3], [4, 5, 6]) plt.title(‘示例图表’, fon…...

mac部署CAT监控服务
在 Mac 上部署美团点评开源的 CAT 监控服务端,可以按照以下步骤操作: 1. 环境准备 1.1 安装依赖 确保已安装以下工具: JDK 8(建议 OpenJDK 11) MySQL 5.7(存储监控数据)(8.0不支持…...
)
实变函数:集合与子集合一例(20250329)
题目 设 r , s , t r, s, t r,s,t 是三个互不相同的数,且 A { r , s , t } A \{r, s, t\} A{r,s,t}, B { r 2 , s 2 , t 2 } B \{r^2, s^2, t^2\} B{r2,s2,t2}, C { r s , s t , r t } C \{rs, st, rt\} C{rs,st,rt} 若 A B C A B C ABC 则 { r , s…...
)
软件工程之需求工程(需求获取、分析、验证)
一、需求获取(Requirements Elicitation) 1. 定义与目标 需求获取是通过与用户、利益相关者等交互,识别并捕获系统需求的过程,目标是明确用户意图与业务目标,避免后期因需求偏差导致返工。 2. 主要方法 问卷法&…...
)
c++第三课(基础c)
1.前文 2.break 3.continue 4.return 0 1.前文 上次写文章到现在,有足足这么多天(我也不知道,自己去数吧) 开始吧 2.break break是结束循环的意思 举个栗子 #include<bits/stdc.h> using namespace std; int main(…...

基于Elasticsearch的个性化内容推荐技术实践
近期开发了一款新的app,并深度参与的全流程的构建及开发,在开发首页内容推荐的时候,写了一套通过ES实现的推荐算法,小有所得,写此博客记录一下。 一、Elasticsearch在推荐系统中的核心作用 1.1 实时索引与检索 Elast…...

el-radio-group 中 el-radio-button value未能绑定上数值数据
这样绑定到admin后不会随着admin的值显示 在value加上 : 后成功显示...

Python Cookbook-4.13 获取字典的一个子集
任务 你有一个巨大的字典,字典中的一些键属于一个特定的集合,而你想创建一个包含这个键集合及其对应值的新字典。 解决方案 如果你不想改动原字典: def sub_dict(somedict,somekeys,default None):return dict([(k, somedict.get(k,default)) for k…...

JSP(实验):带验证码的用户登录
[实验目的] 1.掌握应用request对象获取表单提交的数据。 2.掌握解决获取表单提交数据产生中文乱码的问题。 3.掌握使用response对象进行定时跳转功能。 4.掌握使用session对象完成登录和注销功能。 [实验要求] 设计带验证码…...

自然语言模型的演变与未来趋势:从规则到多模态智能的跨越
自然语言模型的演变与未来趋势:从规则到多模态智能的跨越 自然语言处理(NLP)作为人工智能领域最具挑战性的分支之一,在过去几十年经历了翻天覆地的变化。从最初基于规则的系统到如今拥有万亿参数的大型语言模型(LLMs),这一技术革新不仅彻底改…...
集多功能为一体的软件,支持批量操作。
今天我给大家分享一个超实用的小工具,真的是太好用了!这个软件是吾爱大神无知灰灰制作的,它能直接一键把webp格式的图片转换成png格式。 webp转为png 一键操作,支持压缩 其实,作者最近在工作中经常遇到webp格式的图片…...

linux压缩指令
今天我们来了解一下linux压缩指令,压缩是我们文件传输的一种重要手段,对此,我们是必须学习压缩指令的,那么话不多说,来看. 1.grep过滤查找,管道符,“|”,表示将前一个命令的处理结果输出传递给后面的命令处理。 基本语法&#x…...

C++细节知识for面试
1. linux上C程序可用的栈和堆大小分别是多少,为什么栈大小小于堆? 1. 栈(Stack)大小 栈默认为8MB,可修改。 为什么是这个大小: 安全性:限制栈大小可防止无限递归或过深的函数调用导致内存…...

Appium中元素定位的注意点
应用场景 了解这些注意点可以以后在出错误的时候,更快速的定位问题原因。 示例 使用 find_element_by_xx 或 find_elements_by_xx 的方法,分别传入一个没有的“特征“会是什么结果呢? 核心代码 driver.find_element_by_id("xxx") drive…...

污水处理厂人员定位方案-UWB免布线高精度定位
1. 方案概述 本方案采用免布线UWB基站与北斗卫星定位融合技术,结合UWBGNSS双模定位工卡,实现污水处理厂室内外人员高精度定位(亚米级)。系统通过低功耗4G传输数据,支持实时位置监控、电子围栏、聚集预警、轨迹回放等功…...
)
蓝桥刷题note11(好数)
1,好数 一个整数如果按从低位到高位的顺序,奇数位 (个位、百位、万位 ⋯⋯ ) 上的数字是奇数,偶数位 (十位、千位、十万位 ⋯⋯ ) 上的数字是偶数,我们就称之为 “好数”。 给定一个正整数 NN,请计算从 1 到 NN 一共…...
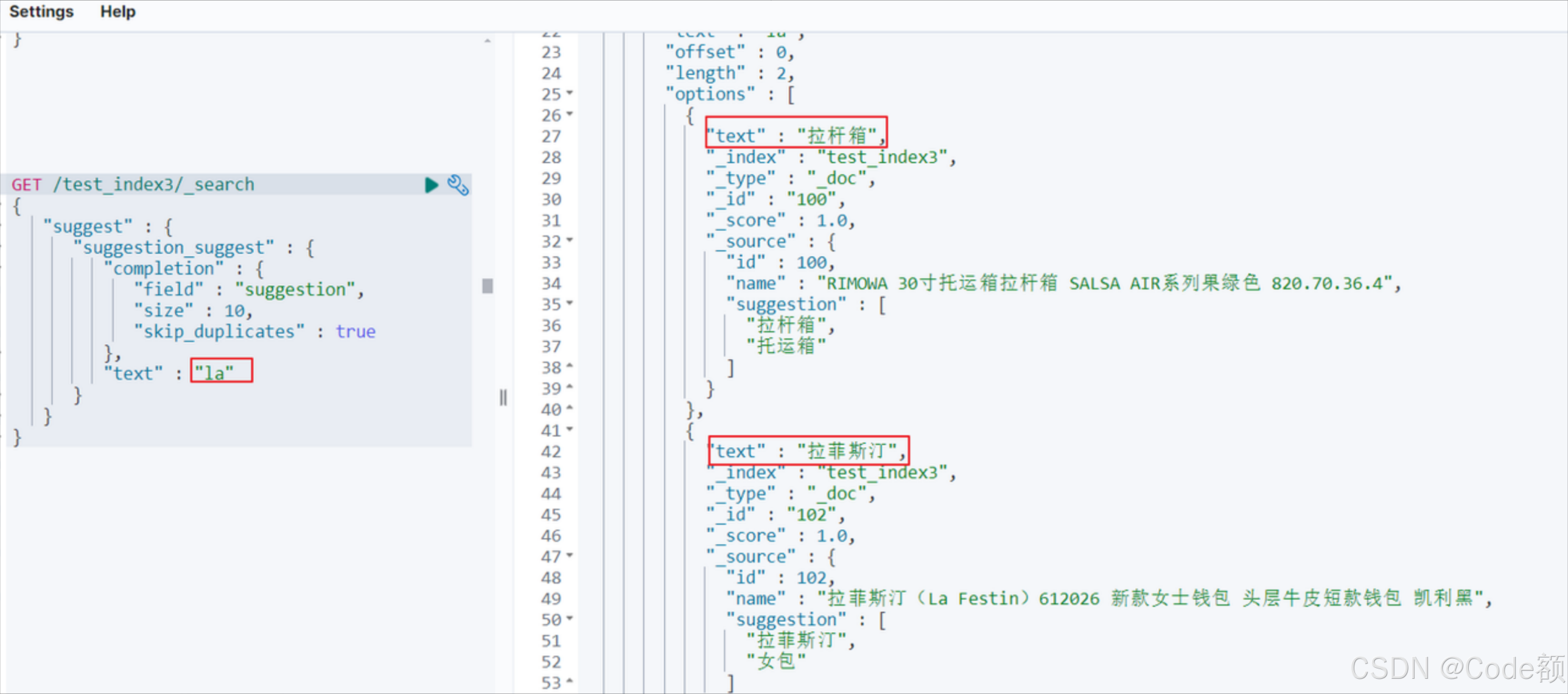
Elasticsearch 高级
Elasticsearch 高级 建议阅读顺序: Elasticsearch 入门Elasticsearch 搜索Elasticsearch 搜索高级Elasticsearch高级(本文) 1. nested 类型 1.1 介绍 Elasticsearch 中的 nested 类型允许你在文档内存储复杂的数据结构,比如一个…...

SQL Server 2022常见问题解答
以下是SQL Server 2022的常见问题解答,按主题分类整理: 一、安装与升级 SQL Server 2022的系统要求是什么? 支持的操作系统:Windows Server 2016及以上、Linux(Ubuntu 20.04/22.04, RHEL 8/9等)。内存:至少4GB(建议8GB+)。磁盘空间:6GB以上,具体取决于安装组件。如何…...

基于LLM的实时信息检索汇总分析系统
基于用户需求和技术发展趋势,设计基于LLM的实时信息检索汇总分析系统,方案如下: 一、系统架构设计 1. 分层多模态数据采集层 动态渲染适配引擎 采用混合爬虫技术: 静态页面:优化Scrapy框架,集成XPath模板库…...