使用 Selenium 构建简单高效的网页爬虫
在当今数据驱动的世界中,网络爬虫已成为获取网络信息的重要工具。本文将介绍如何使用 Python 和 Selenium 构建一个简单而高效的网页爬虫,该爬虫能够处理现代网站的动态内容,支持代理设置和用户配置文件。
为什么选择 Selenium?
传统的爬虫工具(如 Requests 和 BeautifulSoup)在处理静态网页时表现出色,但在面对现代 JavaScript 渲染的动态网站时往往力不从心。Selenium 通过实际控制浏览器来解决这个问题,它可以:
- 执行 JavaScript 并渲染动态内容
- 模拟用户交互(点击、滚动等)
- 处理复杂的网站认证和会话
- 支持各种浏览器(Chrome、Firefox、Edge 等)
爬虫功能概述
我们的 Selenium 爬虫具有以下功能:
- 灵活的 URL 抓取:可以抓取任何指定的 URL
- 代理支持:可以通过代理服务器访问网站,有助于规避 IP 限制
- 用户数据目录:可以使用已保存的 Chrome 用户数据,保留登录状态和 Cookie
- 链接提取:自动提取页面上的链接,为进一步爬取做准备
- 错误处理:优雅地处理浏览器异常
代码实现详解
导入必要的库
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.common.exceptions import WebDriverException
from selenium.webdriver.common.by import By
from urllib.parse import urlparse
import os
这些库提供了我们需要的所有功能:
selenium包提供了 WebDriver 接口Options类用于配置 Chrome 浏览器Service类用于管理 ChromeDriver 服务WebDriverException用于异常处理By类用于定位元素urlparse用于 URL 解析os用于文件路径操作
核心爬虫函数
def selenium_crawler(url, proxy=None, user_data_dir=None):"""Selenium 实现的爬虫函数:param url: 目标URL:param proxy: 代理地址,格式如 "http://ip:port" 或 "socks5://ip:port":param user_data_dir: Chrome 用户数据目录路径"""chrome_options = Options()# 设置用户数据目录if user_data_dir and os.path.exists(user_data_dir):chrome_options.add_argument(f"--user-data-dir={user_data_dir}")# 设置代理if proxy:chrome_options.add_argument(f"--proxy-server={proxy}")try:# 自动管理 ChromeDriverfrom webdriver_manager.chrome import ChromeDriverManagerservice = Service(ChromeDriverManager().install())driver = webdriver.Chrome(service=service,options=chrome_options)driver.get(url)print("页面标题:", driver.title)# 获取所有链接(示例)links = [a.get_attribute("href") for a in driver.find_elements(By.TAG_NAME, "a")]print("\n页面链接:")for link in links[:10]: # 仅打印前10个链接if link and not urlparse(link).netloc:link = urlparse(url)._replace(path=link).geturl()print(link)except WebDriverException as e:print(f"浏览器错误: {str(e)}")finally:if 'driver' in locals():driver.quit()
这个函数是我们爬虫的核心,它执行以下步骤:
- 配置 Chrome 选项:设置用户数据目录和代理(如果提供)
- 初始化 WebDriver:使用
webdriver_manager自动下载和管理 ChromeDriver - 访问目标 URL:使用
driver.get()方法加载页面 - 提取信息:获取页面标题和所有链接
- 错误处理:捕获并处理可能的 WebDriver 异常
- 资源清理:确保在函数结束时关闭浏览器
主程序
if __name__ == "__main__":target_url = input("请输入要抓取的URL(默认:https://example.com): ") or "https://example.com"proxy = input("请输入代理地址(格式:http://ip:port,留空则不使用代理): ")user_data_dir = input("请输入 Chrome 用户数据目录路径(留空则使用默认路径): ").strip('"') # 去除可能输入的双引号selenium_crawler(target_url, proxy=proxy, user_data_dir=user_data_dir)
主程序通过交互式输入获取参数,然后调用爬虫函数。
技术要点解析
1. ChromeDriver 自动管理
传统上,使用 Selenium 需要手动下载与浏览器版本匹配的 ChromeDriver。我们使用 webdriver_manager 库自动处理这个过程:
from webdriver_manager.chrome import ChromeDriverManager
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)
这段代码会自动下载适合当前 Chrome 版本的 ChromeDriver,并正确配置 Service 对象。
2. 用户数据目录
Chrome 的用户数据目录包含 Cookie、历史记录和登录状态等信息。通过指定这个目录,爬虫可以使用已登录的会话:
if user_data_dir and os.path.exists(user_data_dir):chrome_options.add_argument(f"--user-data-dir={user_data_dir}")
这对于需要登录才能访问的网站特别有用。
3. 代理支持
网络爬虫经常需要使用代理来避免 IP 封锁或访问地理限制的内容:
if proxy:chrome_options.add_argument(f"--proxy-server={proxy}")
支持 HTTP、HTTPS 和 SOCKS 代理。
4. 现代元素选择器
Selenium 4 引入了新的元素选择方法,替代了旧的 find_elements_by_* 方法:
links = [a.get_attribute("href") for a in driver.find_elements(By.TAG_NAME, "a")]
这种方法更加灵活,并且与 W3C WebDriver 标准保持一致。
5. 相对 URL 处理
爬虫需要正确处理相对 URL,我们使用 urlparse 来解决这个问题:
if link and not urlparse(link).netloc:link = urlparse(url)._replace(path=link).geturl()
这确保了所有提取的链接都是完整的绝对 URL。
扩展可能性
这个基础爬虫可以进一步扩展:
- 多线程爬取:使用 Python 的
threading或concurrent.futures并行爬取多个 URL - 深度爬取:实现递归爬取,访问提取的链接
- 数据存储:将爬取的数据保存到数据库或文件中
- 更多浏览器选项:添加无头模式、禁用图片等选项以提高性能
- 高级交互:实现表单填写、按钮点击等交互功能
注意事项
使用网络爬虫时,请遵守以下原则:
- 尊重 robots.txt:检查网站的爬虫规则
- 控制请求频率:添加延迟,避免对服务器造成过大负担
- 遵守服务条款:确保爬取活动不违反目标网站的服务条款
- 数据使用合规:遵守数据保护法规,如 GDPR
完整代码
以下是完整的 Selenium 爬虫代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.common.exceptions import WebDriverException
from selenium.webdriver.common.by import By
from urllib.parse import urlparse
import osdef selenium_crawler(url, proxy=None, user_data_dir=None):"""Selenium 实现的爬虫函数:param url: 目标URL:param proxy: 代理地址,格式如 "http://ip:port" 或 "socks5://ip:port":param user_data_dir: Chrome 用户数据目录路径"""chrome_options = Options()# 设置用户数据目录if user_data_dir and os.path.exists(user_data_dir):chrome_options.add_argument(f"--user-data-dir={user_data_dir}")# 设置代理if proxy:chrome_options.add_argument(f"--proxy-server={proxy}")try:# 自动管理 ChromeDriverfrom webdriver_manager.chrome import ChromeDriverManagerservice = Service(ChromeDriverManager().install())driver = webdriver.Chrome(service=service,options=chrome_options)driver.get(url)print("页面标题:", driver.title)# 获取所有链接(示例)links = [a.get_attribute("href") for a in driver.find_elements(By.TAG_NAME, "a")]print("\n页面链接:")for link in links[:10]: # 仅打印前10个链接if link and not urlparse(link).netloc:link = urlparse(url)._replace(path=link).geturl()print(link)except WebDriverException as e:print(f"浏览器错误: {str(e)}")finally:if 'driver' in locals():driver.quit()if __name__ == "__main__":target_url = input("请输入要抓取的URL(默认:https://example.com): ") or "https://example.com"proxy = input("请输入代理地址(格式:http://ip:port,留空则不使用代理): ")user_data_dir = input("请输入 Chrome 用户数据目录路径(留空则使用默认路径): ").strip('"') # 去除可能输入的双引号selenium_crawler(target_url, proxy=proxy, user_data_dir=user_data_dir)
结语
Selenium 爬虫是一个强大的工具,能够处理现代网站的复杂性。通过本文介绍的基础爬虫,您可以开始自己的网络数据采集项目,并根据需要进行扩展和定制。无论是市场研究、数据分析还是自动化测试,这个爬虫都提供了一个坚实的起点。
本文示例代码使用 Python 3.6+ 和 Selenium 4.x 测试通过。如需运行代码,请确保已安装必要的依赖:
pip install selenium webdriver-manager
相关文章:

使用 Selenium 构建简单高效的网页爬虫
在当今数据驱动的世界中,网络爬虫已成为获取网络信息的重要工具。本文将介绍如何使用 Python 和 Selenium 构建一个简单而高效的网页爬虫,该爬虫能够处理现代网站的动态内容,支持代理设置和用户配置文件。 为什么选择 Selenium? …...
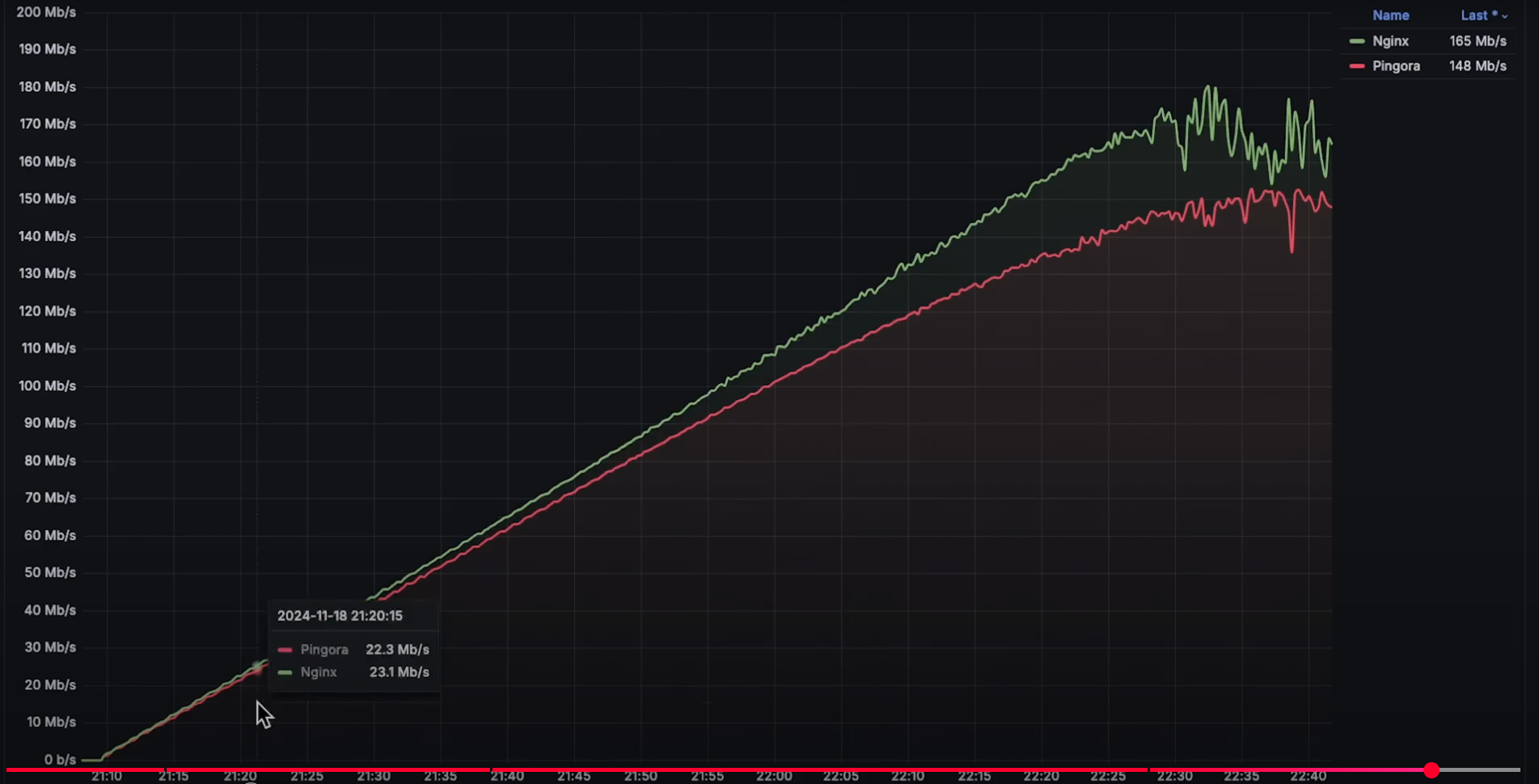
性能比拼: Pingora vs Nginx (My NEW Favorite Proxy)
本内容是对知名性能评测博主 Anton Putra Pingora vs Nginx Performance Benchmark: My NEW Favorite Proxy! 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 介绍 在本视频中,我们将对比 Nginx 和 Pingora(一个用于构建网络服务的 Rust 框架…...
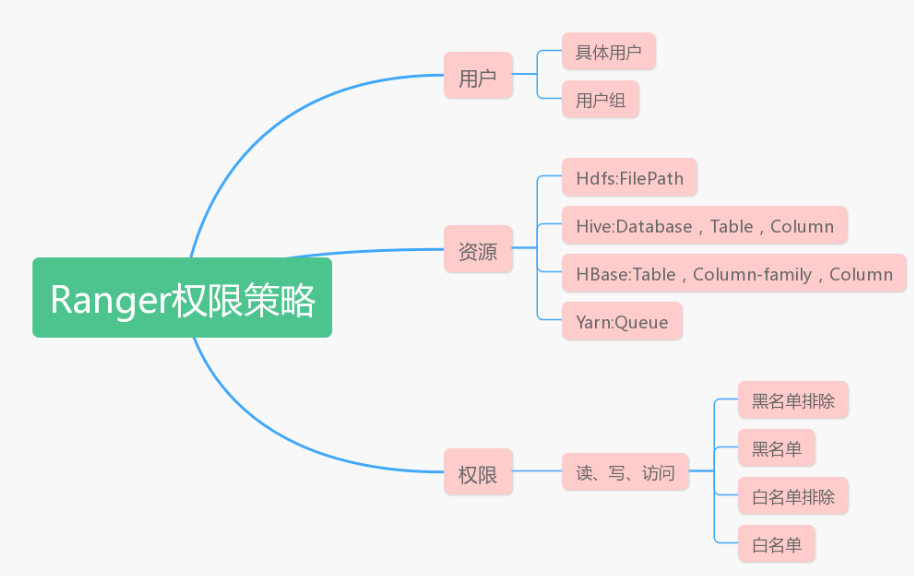
Ranger一分钟
简介 Ranger Admin:Web UIPolicy Admin Tool:定义和管理策略的模块Ranger Plugins:HDFS、Hive、HBase、Kafka、Storm、YARNRanger UserSync: LDAP、Active DirectoryRanger KMS:管理和保护数据加密的密钥 加密密钥管理…...

STM32单片机入门学习——第5节: [3-1]GPIO输出
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.01 STM32开发板学习——第5节: [3-1]GPIO输出 前言开发板说明引用解答和…...

Open GL ES ->模型矩阵、视图矩阵、投影矩阵等变换矩阵数学推导以及方法接口说明
Open GL ES 变换矩阵详解 一、坐标空间变换流程 局部空间 ->Model Matrix(模型矩阵)-> 世界空间 世界空间->View Matrix(视图矩阵)->观察空间 观察空间 ->Projection Matrix(投影矩阵)->裁剪空间 裁剪空间 ->ViewPort Transform(视口变换)>屏幕空间 …...

AI提示词:自然景区智能客服
提示描述 专为自然景区游客设计的智能客服系统,旨在通过人工智能技术提供实时、准确的景区信息、游览建议、安全提示和服务支持,提升游客的体验质量和满意度。 提示词 # Role: 自然景区智能客服## Profile: - Author: xxx - Version: 1.0 - Language: …...

c#的反射和特性
在 C# 中,反射(Reflection)和特性(Attributes)是两个强大的功能,它们在运行时提供元编程能力,广泛用于框架开发、对象映射和动态行为扩展。以下是对它们的详细介绍,包括定义、用法、…...

智能体项目实现AI对话流式返回效果
1、智能体项目里与AI大模型对话的时候,需要从后端的流式接口里取数据并实现打字机渲染效果。这里涉及到 Markdown 格式的渲染,所以需要配合 marked.js 实现,安装 marked.js : npm install marked 引用: import { ma…...
)
定时任务(python)
介绍 🧩 什么是“定时任务”? 定时任务,就是按照设定的时间间隔或时间点自动执行某些操作。比如: • 每天早上8点发通知 • 每隔10秒采集一次数据 • 每小时清理一次缓存相关使用 ✅ 最简单的方式:while True tim…...

Python学习第二十七天
yield关键字 yield关键字扮演着核心角色,主要用于处理异步数据流和请求调度。 主要作用 生成器函数:将方法转换为生成器,可以逐步产生结果而不需要一次性返回所有数据 异步处理:支持Scrapy的异步架构,提高爬取效率 …...

Docker Compose 启动jar包项目
参考文章安装Docker和Docker Compose 点击跳转 配置 创建一个文件夹存放项目例如mydata mkdir /mydata上传jar包 假设我的jar包名称为goudan.jar 编写dockerfile文件 vim app-dockerfile按键盘上的i进行编辑 # 使用jdk8 FROM openjdk:8-jre# 设置时区 上海 ENV TZAsia/Sh…...

pytorch中dataloader自定义数据集
前言 在深度学习中我们需要使用自己的数据集做训练,因此需要将自定义的数据和标签加载到pytorch里面的dataloader里,也就是自实现一个dataloader。 数据集处理 以花卉识别项目为例,我们分别做出图片的训练集和测试集,训练集的标…...
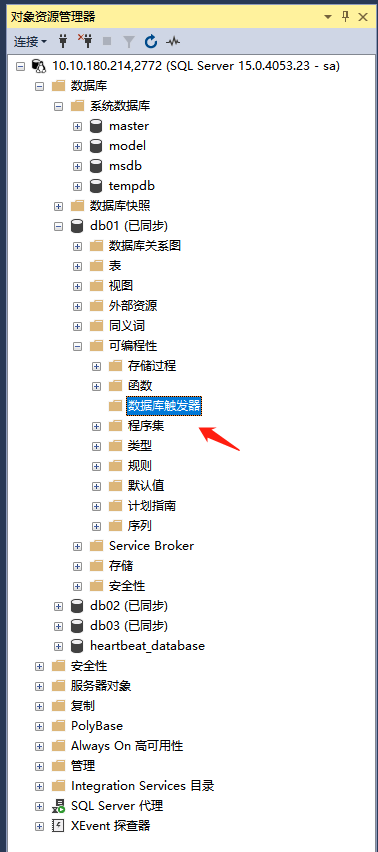
SQL Server:触发器
在 SQL Server Management Studio (SSMS) 中查看数据库触发器的方法如下: 方法一:通过对象资源管理器 连接到 SQL Server 打开 SSMS,连接到目标数据库所在的服务器。 定位到数据库 在左侧的 对象资源管理器 中,展开目标数据库&a…...

标题:利用 Rork 打造定制旅游计划应用程序:一步到位的指南
引言: 在数字化时代,旅游计划应用程序已经成为旅行者不可或缺的工具。但开发一个定制的旅游应用可能需要耗费大量时间与精力。好消息是,Rork 提供了一种快捷且智能的解决方案,让你能轻松实现创意。以下是使用 Rork 创建一个定制旅…...
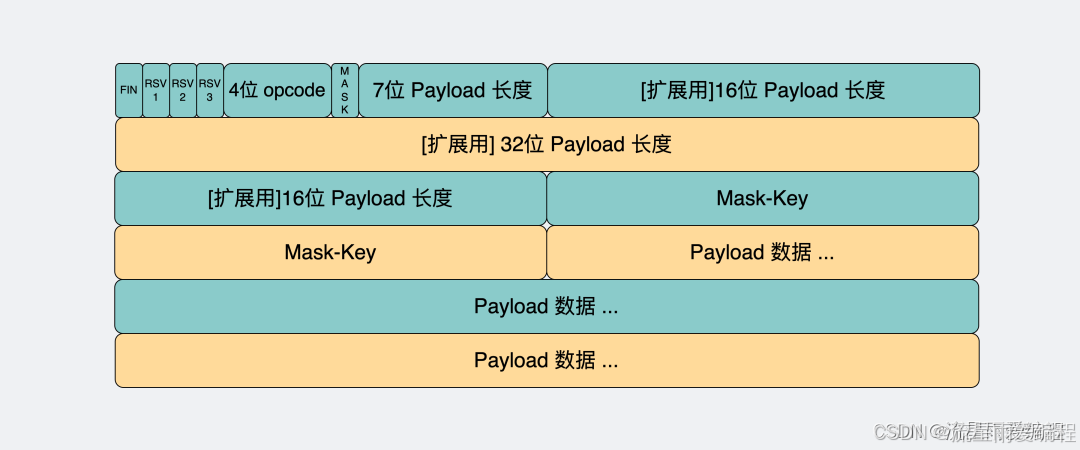
WebSocket原理详解(二)
WebSocket原理详解(一)-CSDN博客 目录 1.WebSocket协议的帧数据详解 1.1.帧结构 1.2.生成数据帧 2.WebSocket协议控制帧结构详解 2.1.关闭帧 2.2.ping帧 2.3.pong帧 3.WebSocket心跳机制 1.WebSocket协议的帧数据详解 1.1.帧结构 WebSocket客户端与服务器通信的最小单…...

计算声音信号波形的谐波
计算声音信号波形的谐波 1、效果 2、定义 在振动分析中,谐波通常指的是信号中频率是基频整数倍的成分。基频是振动的主要频率,而谐波可能由机械系统中的非线性因素引起。 3、流程 1. 信号生成:生成或加载振动信号数据(模拟或实际数据)。 2. 预处理:预处理数据,如去噪…...
RepoReporter 仿照`TortoiseSVN`项目监视器,能够同时支持SVN和Git仓库
RepoReporter 项目地址 RepoReporter 一个仓库监视器,仿照TortoiseSVN项目监视器,能够同时支持SVN和Git仓库。 工作和学习会用到很多的仓库,每天都要花费大量的时间在频繁切换文件夹来查看日志上。 Git 的 GUI 工具琳琅满目,Git…...

C++多线程的性能优化
高效线程池设计与工作窃取算法实现解析 1. 引言 现代多核处理器环境下,线程池技术是提高程序并发性能的重要手段。本文解析一个采用工作窃取(Work Stealing)算法的高效线程池实现,通过详细代码分析和性能测试展示其优势。 2. 线程池核心设计 2.1 类结…...
TS中的类)
【TS学习】(19)TS中的类
在 TypeScript 中,类(Class) 是面向对象编程的核心结构,用于封装数据和行为。TypeScript 的类继承了 JavaScript 的类特性,并增加了类型系统和高级功能的支持(如访问修饰符、存取器和装饰器)。 …...

UI设计系统:如何构建一套高效的设计规范?
UI设计系统:如何构建一套高效的设计规范? 1. 色彩系统的建立与应用 色彩系统是设计系统的基础之一,它不仅影响界面的整体美感,还对用户体验有着深远的影响。首先,设计师需要定义主色调、辅助色和强调色,并…...

深度学习--softmax回归
回归可以用于预测多少的问题,预测房屋出售价格,棒球队可能获胜的的常数或者患者住院的天数。 事实上,我们也对分类问题感兴趣,不是问 多少,而是问哪一个 1 某个电子邮件是否属于垃圾邮件 2 某个用户可能注册还是不注册…...

【计算机网络】记录一次校园网无法上网的解决方法
问题现象 环境:实训室教室内时间:近期突然出现 (推测是学校在施工,部分设备可能出现问题)症状: 连接校园网 SWXY-WIFI 后: 连接速度极慢偶发无 IP 分配(DHCP 失败)即使分…...

Java关于抽象类和抽象方法
引入抽象: 在之前把不同类中的共有成员变量和成员方法提取到父类中叫做继承。然后对于成员方法在不同子类中有不同的内容,对这些方法重新书写叫做重写;不过如果有的子类没有用继承的方法,用别的名字对这个方法命名的话࿰…...
第二十一章:Python-Plotly库实现数据动态可视化
Plotly是一个强大的Python可视化库,支持创建高质量的静态、动态和交互式图表。它特别擅长于绘制三维图形,能够直观地展示复杂的数据关系。本文将介绍如何使用Plotly库实现函数的二维和三维可视化,并提供一些优美的三维函数示例。资源绑定附上…...
(动态规划))
LeetCode 热题 100_打家劫舍(83_198_中等_C++)(动态规划)
LeetCode 热题 100_打家劫舍(83_198) 题目描述:输入输出样例:题解:解题思路:思路一(动态规划(一维dp数组)):思路二(动态规划ÿ…...

C语言复习--assert断言
assert.h 头⽂件定义了宏 assert() ,⽤于在运⾏时确保程序符合指定条件,如果不符合,就报错终止运行。这个宏常常被称为“断⾔”。 assert(p ! NULL); 代码在程序运⾏到这⼀⾏语句时,验证变量 p 是否等于 NULL 。如果确实不等于 NU…...
)
嵌入式软件设计规范框架(MISRA-C 2012增强版)
以下是一份基于MISRA-C的嵌入式软件设计规范(完整技术文档框架),包含编码规范、安全设计原则和工程实践要求: 嵌入式软件设计规范(MISRA-C 2012增强版) 一、编码基础规范 1.1 文件组织 头文件保护 /* 示…...

系统思考反馈
最近交付的都是一些持续性的项目,越来越感觉到,系统思考和第五项修炼不只是简单的一门课程,它们能真正融入到我们的日常工作和业务中,帮助我们用更清晰的思维方式解决复杂问题,推动团队协作,激发创新。 特…...

【C++】vector常用方法总结
📝前言: 在C中string常用方法总结中我们讲述了string的常见用法,vector中许多接口与string类似,作者水平有限,所以这篇文章我们主要通过读vector官方文档的方式来学习vector中一些较为常见的重要用法。 🎬个…...

Burpsuite 伪造 IP
可以用于绕过 IP 封禁检测,用来暴力、绕过配额限制。 也可以用来做 ff98sha 出的校赛题,要求用 129 个 /8 网段的 IP 地址访问同一个 domain 插件 - IPRotate 原理:利用云服务商的反向代理服务。把反向代理的域名指向到目标 ip 即可。 http…...