Ollama+open-webui搭建私有本地大模型详细教程
Ollama+open-webui搭建私有本地大模型详细教程
1. 什么是 Ollama?
1.1. Ollama 简介
Ollama 是一个轻量级的 AI 模型运行时,专注于简化 AI 模型的部署和使用。它支持多种预训练模型(如 Llama、Vicuna、Dolly 等),并且可以在本地运行,无需复杂的基础设施。Ollama 的设计理念是让 AI 模型的使用变得像运行普通程序一样简单,同时确保数据和隐私的安全性。
Ollama 正在不断优化和扩展,未来会支持更多模型类型、更高效的性能优化,以及更友好的用户界面。Ollama的目标是成为 AI 模型部署领域的标准工具,让更多人能够轻松使用 AI 技术。
1.2. 核心特点
-
轻量化:Ollama 的资源占用非常低,适合在本地或小型服务器上运行,即使硬件配置有限也能流畅使用。
-
多模型支持:支持多种主流的预训练模型,用户可以根据需求选择适合的模型。
-
本地运行:所有模型和数据完全在本地运行,无需上传到云端,保护用户隐私。
-
易于部署:安装和启动流程简单,支持 Docker 和二进制文件部署,适合不同环境。
-
交互式使用:提供命令行工具,用户可以通过简单的命令与模型交互,快速获取结果。
-
隐私保护:模型和数据完全在本地运行,无需上传到云端。
1.3. 应用场景
- 个人开发者:快速测试和实验 AI 模型,无需复杂的环境配置。
- 企业用户:在本地运行 AI 模型,确保数据安全,同时满足业务需求。
2. Ollama安装与部署
ollama官方网站:https://ollama.com
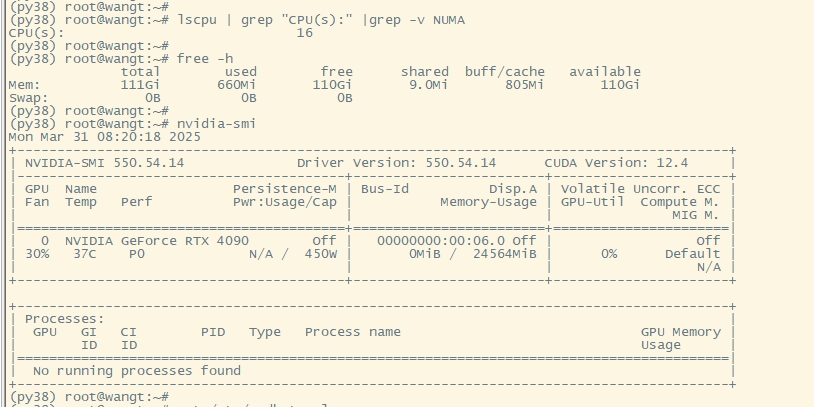
服务器资源准备(GPU服务器)
以实验环境,操作环境为 ubuntu20.04,显卡RTX 4090,配置16C/128G
2.1. 使用官方提供的安装方式(推荐)
官方推荐方式
(py38) root@wangt:~# mkdir ollama
(py38) root@wangt:~# cd ollama/
(py38) root@wangt:~# curl -fsSL https://ollama.com/install.sh | sh
# 等待安装结束即可,非常简单(执行过程中下载安装包比较耗时)# 更改服务默认端口(可选)
(py38) root@wangt:~/ollama# vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/cuda-11.8/bin:/root/miniconda3/envs/py38/bin:/root/miniconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
Environment="OLLAMA_HOST=0.0.0.0:8890"[Install]
WantedBy=default.target
Environment=“OLLAMA_HOST=0.0.0.0:8890”
可以自定义端口,和访问控制,0.0.0.0表示任何网段和环境均可进行访问,8890表示用8890端口启动,不加则默认为11434
(py38) root@wangt:~/ollama# systemctl daemon-reload
(py38) root@wangt:~/ollama# systemctl restart ollama
(py38) root@wangt:~/ollama# netstat -tnlpu|grep 8890
tcp6 0 0 :::8890 :::* LISTEN 3073/ollama
2.2. 手动安装详细介绍(备选项)
官方提供的安装方式,仅适合网络下载速度较快的情况,否则安装容易失败,因为下载包速度慢,很可能下载失败导致脚本运行异常,如果上面安装总是不成功,以下提供下载包手动安装的方式
# 下载安装包可以用梯子下载,传到服务器(windows下载后上传服务器)
(py38) root@wangt:~/ollama# wget https://gh-proxy.com/github.com/ollama/ollama/releases/latest/download/ollama-linux-amd64.tgz# 拉取脚本但不执行
(py38) root@wangt:~# curl -fsSL https://ollama.com/install.sh > install.sh
(py38) root@wangt:~/ollama# chmod +x install.sh
(py38) root@wangt:~/ollama# vim install.sh
需要将脚本中原本下载安装包的相关内容注释,并把tar命令修改到正确位置
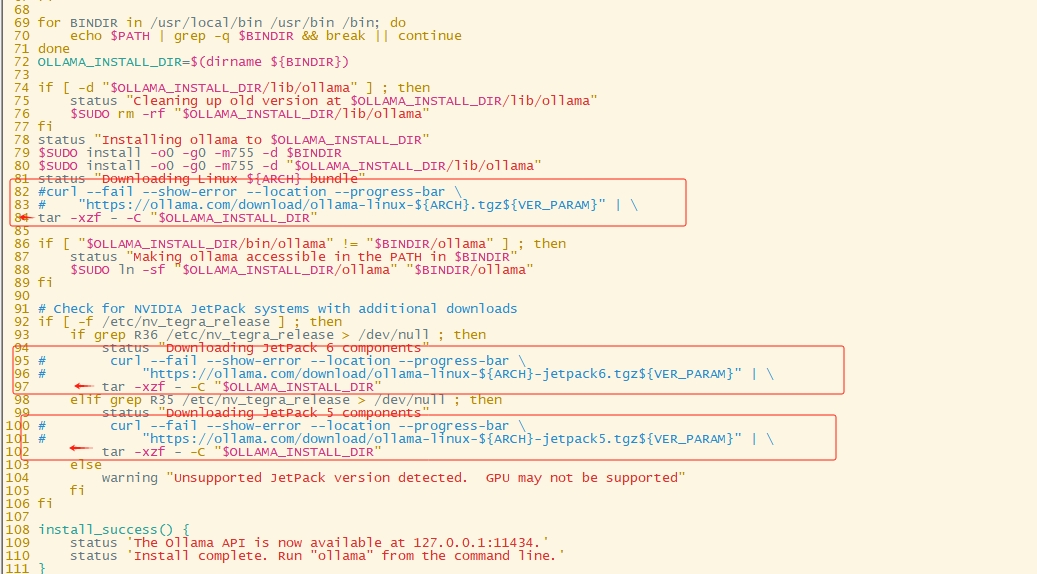
如果担心脚本改错,可以直接复制下面已经改好的脚本内容
#!/bin/sh
# This script installs Ollama on Linux.
# It detects the current operating system architecture and installs the appropriate version of Ollama.set -eured="$( (/usr/bin/tput bold || :; /usr/bin/tput setaf 1 || :) 2>&-)"
plain="$( (/usr/bin/tput sgr0 || :) 2>&-)"status() { echo ">>> $*" >&2; }
error() { echo "${red}ERROR:${plain} $*"; exit 1; }
warning() { echo "${red}WARNING:${plain} $*"; }TEMP_DIR=$(mktemp -d)
cleanup() { rm -rf $TEMP_DIR; }
trap cleanup EXITavailable() { command -v $1 >/dev/null; }
require() {local MISSING=''for TOOL in $*; doif ! available $TOOL; thenMISSING="$MISSING $TOOL"fidoneecho $MISSING
}[ "$(uname -s)" = "Linux" ] || error 'This script is intended to run on Linux only.'ARCH=$(uname -m)
case "$ARCH" inx86_64) ARCH="amd64" ;;aarch64|arm64) ARCH="arm64" ;;*) error "Unsupported architecture: $ARCH" ;;
esacIS_WSL2=falseKERN=$(uname -r)
case "$KERN" in*icrosoft*WSL2 | *icrosoft*wsl2) IS_WSL2=true;;*icrosoft) error "Microsoft WSL1 is not currently supported. Please use WSL2 with 'wsl --set-version <distro> 2'" ;;*) ;;
esacVER_PARAM="${OLLAMA_VERSION:+?version=$OLLAMA_VERSION}"SUDO=
if [ "$(id -u)" -ne 0 ]; then# Running as root, no need for sudoif ! available sudo; thenerror "This script requires superuser permissions. Please re-run as root."fiSUDO="sudo"
fiNEEDS=$(require curl awk grep sed tee xargs)
if [ -n "$NEEDS" ]; thenstatus "ERROR: The following tools are required but missing:"for NEED in $NEEDS; doecho " - $NEED"doneexit 1
fifor BINDIR in /usr/local/bin /usr/bin /bin; doecho $PATH | grep -q $BINDIR && break || continue
done
OLLAMA_INSTALL_DIR=$(dirname ${BINDIR})if [ -d "$OLLAMA_INSTALL_DIR/lib/ollama" ] ; thenstatus "Cleaning up old version at $OLLAMA_INSTALL_DIR/lib/ollama"$SUDO rm -rf "$OLLAMA_INSTALL_DIR/lib/ollama"
fi
status "Installing ollama to $OLLAMA_INSTALL_DIR"
$SUDO install -o0 -g0 -m755 -d $BINDIR
$SUDO install -o0 -g0 -m755 -d "$OLLAMA_INSTALL_DIR/lib/ollama"
status "Downloading Linux ${ARCH} bundle"
#curl --fail --show-error --location --progress-bar \
# "https://ollama.com/download/ollama-linux-${ARCH}.tgz${VER_PARAM}" | \
tar -xzf /root/ollama/ollama-linux-amd64.tgz -C "$OLLAMA_INSTALL_DIR"if [ "$OLLAMA_INSTALL_DIR/bin/ollama" != "$BINDIR/ollama" ] ; thenstatus "Making ollama accessible in the PATH in $BINDIR"$SUDO ln -sf "$OLLAMA_INSTALL_DIR/ollama" "$BINDIR/ollama"
fi# Check for NVIDIA JetPack systems with additional downloads
if [ -f /etc/nv_tegra_release ] ; thenif grep R36 /etc/nv_tegra_release > /dev/null ; thenstatus "Downloading JetPack 6 components"#curl --fail --show-error --location --progress-bar \# "https://ollama.com/download/ollama-linux-${ARCH}-jetpack6.tgz${VER_PARAM}" | \tar -xzf /root/ollama/ollama-linux-amd64.tgz -C "$OLLAMA_INSTALL_DIR"elif grep R35 /etc/nv_tegra_release > /dev/null ; thenstatus "Downloading JetPack 5 components"#curl --fail --show-error --location --progress-bar \# "https://ollama.com/download/ollama-linux-${ARCH}-jetpack5.tgz${VER_PARAM}" | \tar -xzf /root/ollama/ollama-linux-amd64.tgz -C "$OLLAMA_INSTALL_DIR"elsewarning "Unsupported JetPack version detected. GPU may not be supported"fi
fiinstall_success() {status 'The Ollama API is now available at 127.0.0.1:11434.'status 'Install complete. Run "ollama" from the command line.'
}
trap install_success EXIT# Everything from this point onwards is optional.configure_systemd() {if ! id ollama >/dev/null 2>&1; thenstatus "Creating ollama user..."$SUDO useradd -r -s /bin/false -U -m -d /usr/share/ollama ollamafiif getent group render >/dev/null 2>&1; thenstatus "Adding ollama user to render group..."$SUDO usermod -a -G render ollamafiif getent group video >/dev/null 2>&1; thenstatus "Adding ollama user to video group..."$SUDO usermod -a -G video ollamafistatus "Adding current user to ollama group..."$SUDO usermod -a -G ollama $(whoami)status "Creating ollama systemd service..."cat <<EOF | $SUDO tee /etc/systemd/system/ollama.service >/dev/null
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=$BINDIR/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"[Install]
WantedBy=default.target
EOFSYSTEMCTL_RUNNING="$(systemctl is-system-running || true)"case $SYSTEMCTL_RUNNING inrunning|degraded)status "Enabling and starting ollama service..."$SUDO systemctl daemon-reload$SUDO systemctl enable ollamastart_service() { $SUDO systemctl restart ollama; }trap start_service EXIT;;*)warning "systemd is not running"if [ "$IS_WSL2" = true ]; thenwarning "see https://learn.microsoft.com/en-us/windows/wsl/systemd#how-to-enable-systemd to enable it"fi;;esac
}if available systemctl; thenconfigure_systemd
fi# WSL2 only supports GPUs via nvidia passthrough
# so check for nvidia-smi to determine if GPU is available
if [ "$IS_WSL2" = true ]; thenif available nvidia-smi && [ -n "$(nvidia-smi | grep -o "CUDA Version: [0-9]*\.[0-9]*")" ]; thenstatus "Nvidia GPU detected."fiinstall_successexit 0
fi# Don't attempt to install drivers on Jetson systems
if [ -f /etc/nv_tegra_release ] ; thenstatus "NVIDIA JetPack ready."install_successexit 0
fi# Install GPU dependencies on Linux
if ! available lspci && ! available lshw; thenwarning "Unable to detect NVIDIA/AMD GPU. Install lspci or lshw to automatically detect and install GPU dependencies."exit 0
ficheck_gpu() {# Look for devices based on vendor ID for NVIDIA and AMDcase $1 inlspci)case $2 innvidia) available lspci && lspci -d '10de:' | grep -q 'NVIDIA' || return 1 ;;amdgpu) available lspci && lspci -d '1002:' | grep -q 'AMD' || return 1 ;;esac ;;lshw)case $2 innvidia) available lshw && $SUDO lshw -c display -numeric -disable network | grep -q 'vendor: .* \[10DE\]' || return 1 ;;amdgpu) available lshw && $SUDO lshw -c display -numeric -disable network | grep -q 'vendor: .* \[1002\]' || return 1 ;;esac ;;nvidia-smi) available nvidia-smi || return 1 ;;esac
}if check_gpu nvidia-smi; thenstatus "NVIDIA GPU installed."exit 0
fiif ! check_gpu lspci nvidia && ! check_gpu lshw nvidia && ! check_gpu lspci amdgpu && ! check_gpu lshw amdgpu; theninstall_successwarning "No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode."exit 0
fiif check_gpu lspci amdgpu || check_gpu lshw amdgpu; thenstatus "Downloading Linux ROCm ${ARCH} bundle"#curl --fail --show-error --location --progress-bar \# "https://ollama.com/download/ollama-linux-${ARCH}-rocm.tgz${VER_PARAM}" | \tar -xzf /root/ollama/ollama-linux-amd64.tgz -C "$OLLAMA_INSTALL_DIR"install_successstatus "AMD GPU ready."exit 0
fiCUDA_REPO_ERR_MSG="NVIDIA GPU detected, but your OS and Architecture are not supported by NVIDIA. Please install the CUDA driver manually https://docs.nvidia.com/cuda/cuda-installation-guide-linux/"
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#rhel-7-centos-7
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#rhel-8-rocky-8
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#rhel-9-rocky-9
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#fedora
install_cuda_driver_yum() {status 'Installing NVIDIA repository...'case $PACKAGE_MANAGER inyum)$SUDO $PACKAGE_MANAGER -y install yum-utilsif curl -I --silent --fail --location "https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repo" >/dev/null ; then$SUDO $PACKAGE_MANAGER-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repoelseerror $CUDA_REPO_ERR_MSGfi;;dnf)if curl -I --silent --fail --location "https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repo" >/dev/null ; then$SUDO $PACKAGE_MANAGER config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repoelseerror $CUDA_REPO_ERR_MSGfi;;esaccase $1 inrhel)status 'Installing EPEL repository...'# EPEL is required for third-party dependencies such as dkms and libvdpau$SUDO $PACKAGE_MANAGER -y install https://dl.fedoraproject.org/pub/epel/epel-release-latest-$2.noarch.rpm || true;;esacstatus 'Installing CUDA driver...'if [ "$1" = 'centos' ] || [ "$1$2" = 'rhel7' ]; then$SUDO $PACKAGE_MANAGER -y install nvidia-driver-latest-dkmsfi$SUDO $PACKAGE_MANAGER -y install cuda-drivers
}# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#ubuntu
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#debian
install_cuda_driver_apt() {status 'Installing NVIDIA repository...'if curl -I --silent --fail --location "https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-keyring_1.1-1_all.deb" >/dev/null ; thencurl -fsSL -o $TEMP_DIR/cuda-keyring.deb https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-keyring_1.1-1_all.debelseerror $CUDA_REPO_ERR_MSGficase $1 indebian)status 'Enabling contrib sources...'$SUDO sed 's/main/contrib/' < /etc/apt/sources.list | $SUDO tee /etc/apt/sources.list.d/contrib.list > /dev/nullif [ -f "/etc/apt/sources.list.d/debian.sources" ]; then$SUDO sed 's/main/contrib/' < /etc/apt/sources.list.d/debian.sources | $SUDO tee /etc/apt/sources.list.d/contrib.sources > /dev/nullfi;;esacstatus 'Installing CUDA driver...'$SUDO dpkg -i $TEMP_DIR/cuda-keyring.deb$SUDO apt-get update[ -n "$SUDO" ] && SUDO_E="$SUDO -E" || SUDO_E=DEBIAN_FRONTEND=noninteractive $SUDO_E apt-get -y install cuda-drivers -q
}if [ ! -f "/etc/os-release" ]; thenerror "Unknown distribution. Skipping CUDA installation."
fi. /etc/os-releaseOS_NAME=$ID
OS_VERSION=$VERSION_IDPACKAGE_MANAGER=
for PACKAGE_MANAGER in dnf yum apt-get; doif available $PACKAGE_MANAGER; thenbreakfi
doneif [ -z "$PACKAGE_MANAGER" ]; thenerror "Unknown package manager. Skipping CUDA installation."
fiif ! check_gpu nvidia-smi || [ -z "$(nvidia-smi | grep -o "CUDA Version: [0-9]*\.[0-9]*")" ]; thencase $OS_NAME incentos|rhel) install_cuda_driver_yum 'rhel' $(echo $OS_VERSION | cut -d '.' -f 1) ;;rocky) install_cuda_driver_yum 'rhel' $(echo $OS_VERSION | cut -c1) ;;fedora) [ $OS_VERSION -lt '39' ] && install_cuda_driver_yum $OS_NAME $OS_VERSION || install_cuda_driver_yum $OS_NAME '39';;amzn) install_cuda_driver_yum 'fedora' '37' ;;debian) install_cuda_driver_apt $OS_NAME $OS_VERSION ;;ubuntu) install_cuda_driver_apt $OS_NAME $(echo $OS_VERSION | sed 's/\.//') ;;*) exit ;;esac
fiif ! lsmod | grep -q nvidia || ! lsmod | grep -q nvidia_uvm; thenKERNEL_RELEASE="$(uname -r)"case $OS_NAME inrocky) $SUDO $PACKAGE_MANAGER -y install kernel-devel kernel-headers ;;centos|rhel|amzn) $SUDO $PACKAGE_MANAGER -y install kernel-devel-$KERNEL_RELEASE kernel-headers-$KERNEL_RELEASE ;;fedora) $SUDO $PACKAGE_MANAGER -y install kernel-devel-$KERNEL_RELEASE ;;debian|ubuntu) $SUDO apt-get -y install linux-headers-$KERNEL_RELEASE ;;*) exit ;;esacNVIDIA_CUDA_VERSION=$($SUDO dkms status | awk -F: '/added/ { print $1 }')if [ -n "$NVIDIA_CUDA_VERSION" ]; then$SUDO dkms install $NVIDIA_CUDA_VERSIONfiif lsmod | grep -q nouveau; thenstatus 'Reboot to complete NVIDIA CUDA driver install.'exit 0fi$SUDO modprobe nvidia$SUDO modprobe nvidia_uvm
fi# make sure the NVIDIA modules are loaded on boot with nvidia-persistenced
if available nvidia-persistenced; then$SUDO touch /etc/modules-load.d/nvidia.confMODULES="nvidia nvidia-uvm"for MODULE in $MODULES; doif ! grep -qxF "$MODULE" /etc/modules-load.d/nvidia.conf; thenecho "$MODULE" | $SUDO tee -a /etc/modules-load.d/nvidia.conf > /dev/nullfidone
fistatus "NVIDIA GPU ready."
install_success
保存并执行安装脚本
(py38) root@wangt:~/ollama# bash install.sh
# 等待安装结束(py38) root@wangt:~/ollama# vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/cuda-11.8/bin:/root/miniconda3/envs/py38/bin:/root/miniconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
Environment="OLLAMA_HOST=0.0.0.0:8890"[Install]
WantedBy=default.target(py38) root@wangt:~/ollama# systemctl daemon-reload
(py38) root@wangt:~/ollama# systemctl restart ollama
(py38) root@wangt:~/ollama# netstat -tnlpu|grep 8890
tcp6 0 0 :::8890 :::* LISTEN 3073/ollama
2.3. 其它容器安装方式(备选项)
实验环境也可以考虑使用docker安装,不会干扰本地环境,但使用异常排查问题时相对麻烦一些,docker运行需要有NVIDIA显卡支持,需要配置
拉取 Ollama 镜像
docker pull ollama/ollama:latest启动 Ollama 容器
docker run -d --name ollama -p 11434:11434 ollama/ollama:latest验证安装
curl http://localhost:11434/
3. 使用和维护Ollama
3.1 基础维护命令
-
启动服务
systemctl start ollama -
停止服务
systemctl stop ollama -
查看服务状态
systemctl status ollama(py38) root@wangt:~/ollama# curl 127.0.0.1:8890 Ollama is running -
查看版本信息
root@wangt:~/ollama# ollama --version
ollama version is 0.6.2
- 模型存储路径
root@wangt:~# ll /usr/share/ollama/.ollama/models/
total 16
drwxr-xr-x 4 ollama ollama 4096 Apr 1 03:17 ./
drwxr-xr-x 3 ollama ollama 4096 Apr 1 02:58 ../
drwxr-xr-x 2 ollama ollama 4096 Apr 1 04:40 blobs/
drwxr-xr-x 3 ollama ollama 4096 Apr 1 03:17 manifests/
3.2 模型管理命令
ollama官方模型仓库地址:https://ollama.com/library
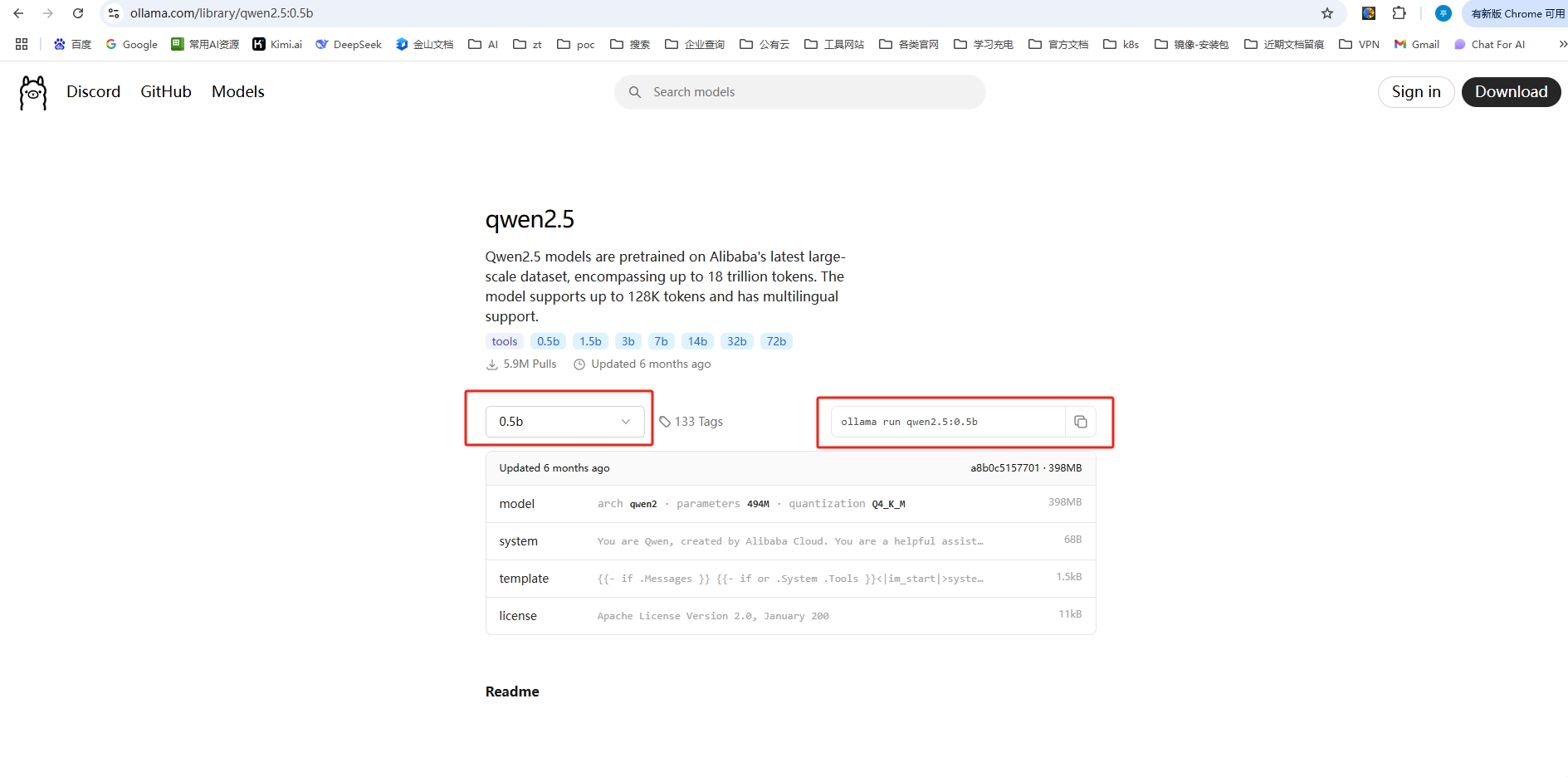
3.2.1 运行模型
在官方模型仓库,找到自己想要的模型进入,根据自己用途情况,选择参数量后,复制右边的运行命令即可,类似于docker的使用方式
root@wangt:~/ollama# OLLAMA_HOST=127.0.0.1:8890 ollama run qwen2.5:0.5b
pulling manifest
pulling c5396e06af29... 100%
verifying sha256 digest
writing manifest
success # 尝试体验,问出问题
>>> 现在股票市场,创业板一共有多少家上市公司?
目前,创业板在A股市场上共设有50家公司。这个数目已经随着市场的变动而有所调整。如果您需要最新的资讯和详细信息,请留意财经新闻、官方网站或其他官方渠道以获取最准确的信息。不过,一般来说,创业板的规模较大,通常与市值相对较高的公司有关,其上市公司的数量较多,
因为它们往往是具有较高知名度和技术实力的企业。>>> Send a message (/? for help)
安装完成会进入到模型交互界面,直接可以和离线模型进行交互提问,使用命令
/?,可以查看操作清单>>> /? Available Commands:/set Set session variables/show Show model information/load <model> Load a session or model/save <model> Save your current session/clear Clear session context/bye Exit/?, /help Help for a command/? shortcuts Help for keyboard shortcutsUse """ to begin a multi-line message.>>> /bye root@wangt:~/ollama#
根据自己需要,可以去下载多个需要使用到的模型,例如再下载安装一个deepseek-r1
当
ollama run运行的模型,会先检查本地model,本地已经存在时,不会重新拉取,直接运行root@wangt:~/ollama# OLLAMA_HOST=127.0.0.1:8890 ollama run deepseek-r1:7b pulling manifest pulling 96c415656d37... 100% verifying sha256 digest writing manifest success >>> 你是什么模型?我是一个AI助手,由中国的深度求索(DeepSeek)公司独立开发,我清楚自己的身份与局限,会始终秉持专业和诚实的态度帮助用户。 >>> /bye
3.2.2 列出可用模型
root@wangt:~/ollama# OLLAMA_HOST=127.0.0.1:8890 ollama list
NAME ID SIZE MODIFIED
deepseek-r1:7b 0a8c26691023 4.7 GB 2 minutes ago
qwen2.5:0.5b a8b0c5157701 397 MB 21 minutes ago
也可以通过接口的方式查看:
root@wangt:~/ollama# curl http://localhost:8890/api/tags {"models": [{"name": "deepseek-r1:7b","model": "deepseek-r1:7b","modified_at": "2025-04-01T03:35:42.956003391Z","size": 4683075271,"digest": "0a8c266910232fd3291e71e5ba1e058cc5af9d411192cf88b6d30e92b6e73163","details": {"parent_model": "","format": "gguf","family": "qwen2","families": ["qwen2"],"parameter_size": "7.6B","quantization_level": "Q4_K_M"}},{"name": "qwen2.5:0.5b","model": "qwen2.5:0.5b","modified_at": "2025-04-01T03:17:35.053991433Z","size": 397821319,"digest": "a8b0c51577010a279d933d14c2a8ab4b268079d44c5c8830c0a93900f1827c67","details": {"parent_model": "","format": "gguf","family": "qwen2","families": ["qwen2"],"parameter_size": "494.03M","quantization_level": "Q4_K_M"}}] }
3.2.3 模型管理
- 查看模型信息
root@wangt:~/ollama# OLLAMA_HOST=127.0.0.1:8890 ollama show qwen2.5:0.5bModelarchitecture qwen2 parameters 494.03M context length 32768 embedding length 896 quantization Q4_K_M SystemYou are Qwen, created by Alibaba Cloud. You are a helpful assistant. LicenseApache License Version 2.0, January 2004
- 下载模型
root@wangt:~/ollama# OLLAMA_HOST=127.0.0.1:8890 ollama pull deepseek-r1:14b
使用到这里,命令总是加OLLAMA_HOST参数并不是很方便,我们可以增加
alias,来简化命令root@wangt:~/ollama# alias ollama='OLLAMA_HOST=127.0.0.1:8890 ollama'
root@wangt:~/ollama# ollama list
NAME ID SIZE MODIFIED
deepseek-r1:14b ea35dfe18182 9.0 GB 25 minutes ago
deepseek-r1:7b 0a8c26691023 4.7 GB 58 minutes ago
qwen2.5:0.5b a8b0c5157701 397 MB About an hour ago
- 删除模型
root@wangt:~/ollama# ollama rm qwen2.5:0.5b
deleted 'qwen2.5:0.5b'
root@wangt:~/ollama# ollama list
NAME ID SIZE MODIFIED
deepseek-r1:14b ea35dfe18182 9.0 GB 32 minutes ago
deepseek-r1:7b 0a8c26691023 4.7 GB About an hour ago
- 模型复制拷贝
root@wangt:~/ollama# ollama cp deepseek-r1:14b deepseek-r1_bak20250401:14b
copied 'deepseek-r1:14b' to 'deepseek-r1_bak20250401:14b'
root@wangt:~/ollama# ollama list
NAME ID SIZE MODIFIED
deepseek-r1_bak20250401:14b ea35dfe18182 9.0 GB 5 seconds ago
deepseek-r1:14b ea35dfe18182 9.0 GB 37 minutes ago
deepseek-r1:7b 0a8c26691023 4.7 GB About an hour ago
- 列出正在运行的模型
# 运行一个model
root@wangt:~# ollama run deepseek-r1:14b
>>> Send a message (/? for help)# 另起一个会话窗口查看
root@wangt:~# ollama ps
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:14b ea35dfe18182 11 GB 100% GPU 3 minutes from now
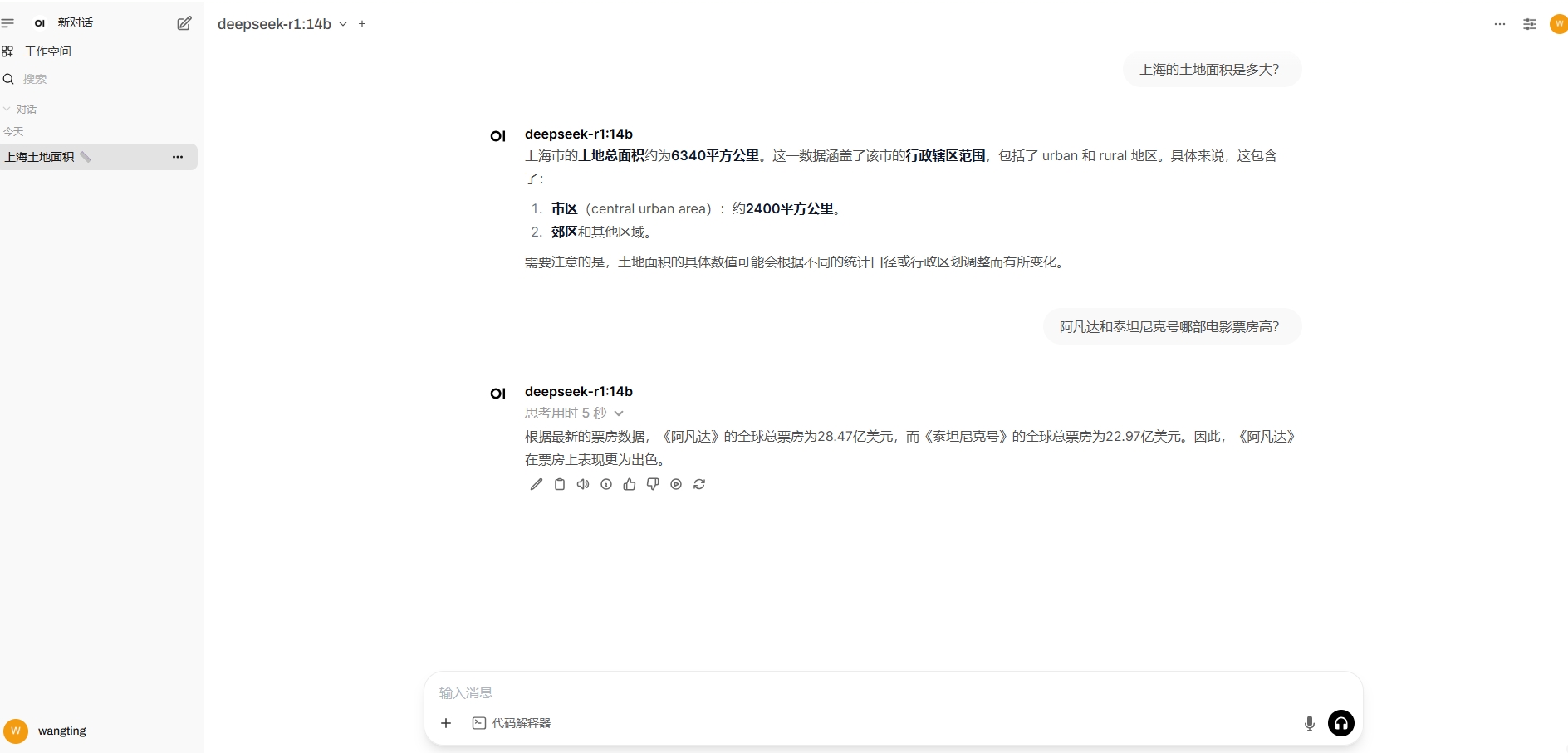
- 非交互式查询大模型
root@wangt:~/ollama# echo "上海的土地面积是多大?" | ollama run deepseek-r1:14b上海市的市域总面积约为6340平方公里。
root@wangt:~/ollama#
3.2.4 通过调接口方式查询ollama大模型
# 格式如下
curl -X POST http://localhost:8890/api/generate -d '{"model": "deepseek-r1:14b","prompt": "上海的土地面积是多大?","stream": false
}'# 返回
{"model":"deepseek-r1:14b","created_at":"2025-04-01T06:14:56.00815753Z","response":"\u003cthink\u003e\n\n\u003c/think\u003e\n\n截至2023年,上海市的**土地总面积**约为**6,340平方公里**。这一数据包括了市辖区、郊县等区域的土地面积。具体来说:\n\n- **市区**(包括黄浦、静安、长宁、徐汇、杨浦、虹口、普陀、闸北、浦东新区等区)面积较小,约为**500平方公里**。\n- **郊区和远郊地区**面积较大,约占总面积的绝大部分。\n\n需要注意的是,上海市的土地利用情况复杂,包括建设用地、农用地、生态保护区等多种类型。如果您需要更详细的数据或具体区域的面积信息,可以参考当地统计局或自然资源部门发布的官方资料。","done":true,"done_reason":"stop","context":[151644,100633,109633,100210,20412,42140,26288,11319,151645,151648,271,151649,271,102219,17,15,17,18,7948,3837,105425,9370,334,101962,111603,334,107679,334,21,11,18,19,15,107231,334,1773,100147,20074,100630,34187,22697,103022,5373,103074,24342,49567,101065,109633,100210,1773,100398,99883,48443,12,3070,105587,334,9909,100630,99789,101465,5373,99541,50285,5373,45861,99503,5373,101957,99833,5373,101058,101465,5373,101522,39426,5373,99537,103441,5373,107964,48309,5373,112407,104879,49567,23836,7552,100210,109413,3837,107679,334,20,15,15,107231,334,8997,12,3070,117074,33108,99427,103074,100361,334,100210,104590,3837,115085,111603,9370,113604,3407,107916,100146,3837,105425,109633,100152,99559,102181,3837,100630,115138,5373,99288,102763,5373,100171,113891,107860,31905,1773,106870,85106,33126,100700,105918,57191,100398,101065,9370,100210,27369,3837,73670,101275,100198,112997,57191,110130,99667,105645,100777,101111,1773],"total_duration":2058396882,"load_duration":16299691,"prompt_eval_count":10,"prompt_eval_duration":13808729,"eval_count":150,"eval_duration":2027756646}
3.3 加载自定义模型(按需使用场景)
如果有需要加载一些自定义的模型,操作方式如下
-
其它途径下载的模型文件
将模型文件(如.bin或.gguf格式)下载到本地。 -
加载模型
ollama create <model_name> --file <model_file>
4. 界面化操作-Ollama WebUI
4.1 安装Open WebUI
(原 Ollama WebUI)
- docker方式部署
docker run -d -p 8891:8080 -e OLLAMA_BASE_URL=http://140.210.92.250:8890 -v open-webui:/app/backend/data --name ollama-web --restart always ghcr.io/open-webui/open-webui:main
注意:
-p 8891:8080,表示web-ui通过8891端口进行访问,本容器则表示ui地址:http://140.210.92.250:8891OLLAMA_API_BASE_URL=http://140.210.92.250:8890,这里需要改成自己的ollama服务地址
4.2 使用Open WebUI
第一次登录,需要注册,且这个注册账号为管理员,注册完成后登录即可
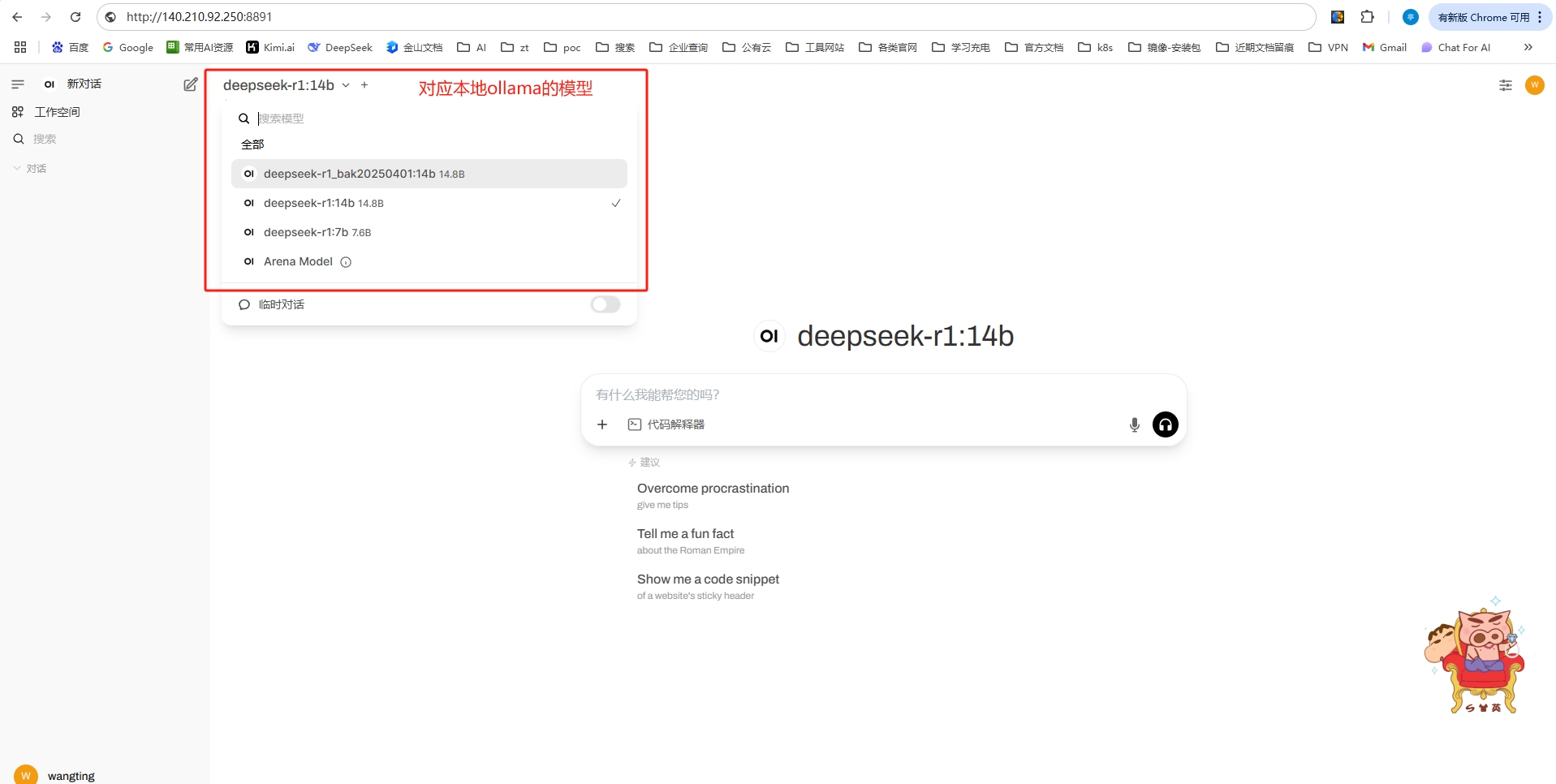
截止到这里,相当于一个离线的大模型+web-ui查询的整个环境就算完成了,选择一个模型,尝试使用一下。
只要本地资源充足,可以通过ollama下载更大的模型进行使用
相关文章:
Ollama+open-webui搭建私有本地大模型详细教程
Ollamaopen-webui搭建私有本地大模型详细教程 1. 什么是 Ollama? 1.1. Ollama 简介 Ollama 是一个轻量级的 AI 模型运行时,专注于简化 AI 模型的部署和使用。它支持多种预训练模型(如 Llama、Vicuna、Dolly 等),…...

电销行业机器人外呼话术设计:关键注意事项与实践指南
随着人工智能技术的普及,电话营销行业(电销)逐渐引入智能外呼机器人以提升效率、降低成本。然而,机器人外呼的实际效果高度依赖话术设计的合理性。若话术生硬、缺乏策略,不仅可能导致客户反感,还可能引发合…...

GPT-4o 原生图像生成技术解析:从模型架构到吉卜力梦境的实现
最近不少 AI 爱好者、设计师、Vlogger 在社交平台晒出了 GPT-4o 生成的梦幻图像,尤其是吉卜力风格的作品——柔和光影、日系构图、治愈色彩、富有情感的角色表达,一下子击中了无数人的“童年回忆 审美舒适区”。 🎨 下面是一些 GPT-4o 实际生…...

测试cursor-AI编辑器
Cursor是一个免费的,内置AI插件的编辑器,在vscode基础上开发,可以创建和分析代码,还能提出修改建议。官网是 https://www.cursor.com/cn 载入SFTP的方式跟vscode是一样的,但是会有这样的报错: 报错&#x…...

web网站页面测试点---添加功能测试
添加 一、创建新的申请时,关闭网络查看数据是否存在,并提示网络错位相关提示语 二、在文本框内输入数据 1.在文本框内输入空格,查看文本内容前后是否存在空格 2.在文本框内输入最大长度,查看能否正确提交 3.在文本框内输入最大长…...

[首发]烽火HG680-KD-海思MV320芯片-2+8G-安卓9.0-强刷卡刷固件包
烽火HG680-KD-海思MV320芯片-28G-安卓9.0-强刷卡刷固件包 U盘强刷刷机步骤: 1、强刷刷机,用一个usb2.0的8G以下U盘,fat32,2048块单分区格式化(强刷对U盘非常非常挑剔,usb2.0的4G U盘兼容的多&a…...

Spring Boot 快速入手
前言:为什么选择 Spring Boot? 🚀 在现代 Java 开发中,Spring Boot 已成为最流行的后端框架之一。无论是小型 Web 应用、企业级系统,还是微服务架构,Spring Boot 都能提供快速开发、自动配置、轻量级部署的…...
OpenAI最近放出大新闻,准备在接下来的几个月内推出一款“开放”的语言模型
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

数据结构值ST表的详细讲解浅显易懂
定义与原理 ST表,即Sparse Table(稀疏表),是一种基于倍增思想的数据结构。它主要用于在**O(1)**时间复杂度内查询给定区间的最值(最大值或最小值)。其原理是通过预处理,利用倍增的思想…...
基于PyQt5的自动化任务管理软件:高效、智能的任务调度与执行管理
基于PyQt5的自动化任务管理软件:高效、智能的任务调度与执行管理 相关资源文件已经打包成EXE文件,可双击直接运行程序,且文章末尾已附上相关源码,以供大家学习交流,博主主页还有更多Python相关程序案例,秉着…...

自动驾驶---学术论文的常客:nuScenes数据集的使用
1 前言 nuScenes 数据集在大模型训练中应用广泛,在很多CVPR或者其它论文中经常能看到使用nuScenes 数据集达到SOTA水平。 在之前的博客《自动驾驶---学术论文的常客:nuScenes 数据集》中,笔者主要介绍了nuScenes数据集的来源和下载方式&#…...

使用大语言模型进行Python图表可视化
Python使用matplotlib进行可视化一直有2个问题,一是代码繁琐,二是默认模板比较丑。因此发展出seaborn等在matplotlib上二次开发,以更少的代码进行画图的和美化的库,但是这也带来了定制化不足的问题。在大模型时代,这个…...
C#调用ACCESS数据库,解决“Microsoft.ACE.OLEDB.12.0”未注册问题
C#调用ACCESS数据库,解决“Microsoft.ACE.OLEDB.12.0”未注册问题 解决方法: 1.将C#采用的平台从AnyCpu改成X64 2.将官网下载的“Microsoft Access 2010 数据库引擎可再发行程序包AccessDatabaseEngine_X64”文件解压 3.安装解压后的文件 点击下载安…...

el-select+el-tree实现下拉树形选择
主要实现el-select下使用树结构,支持筛选功能 封装的组件 composeTree.vue <template><el-select :popper-class"popperClass"v-model"selectedList"placeholder"请选择"filterable:filter-method"handleFilter" multiple:c…...

android studio 安装flutter插件
在 Android Studio 中安装 Flutter 插件 Flutter 是 Google 开发的一个开源 UI 软件开发工具包,主要用于构建高质量的跨平台应用。然而,要在 Android Studio 中开发 Flutter 应用,首先需要安装 Flutter 插件。本文将详细介绍安装 Flutter 插…...

利用 Excel 函数随机抽取(附示例)
RANDARRAY 是 Excel 365 和 Excel 2021 引入的一个函数,用于生成一个随机数数组。它的语法如下: RANDARRAY([rows], [columns], [min], [max], [whole_number])参数详解 rows(可选) 要生成的行数(默认值为 1ÿ…...

部分国产服务器CPU及内存性能测试情况
近日对部分国产服务器进行了CPU和内存的性能测试, 服务器包括华锟振宇、新华三和中兴三家,CPU包括鲲鹏、海光和Intel,初步测试结果如下: 服务器厂商四川华锟振宇新华三中兴中兴服务器HuaKun TG225 B1R4930 G5R5930 G2R5300 G4操作…...
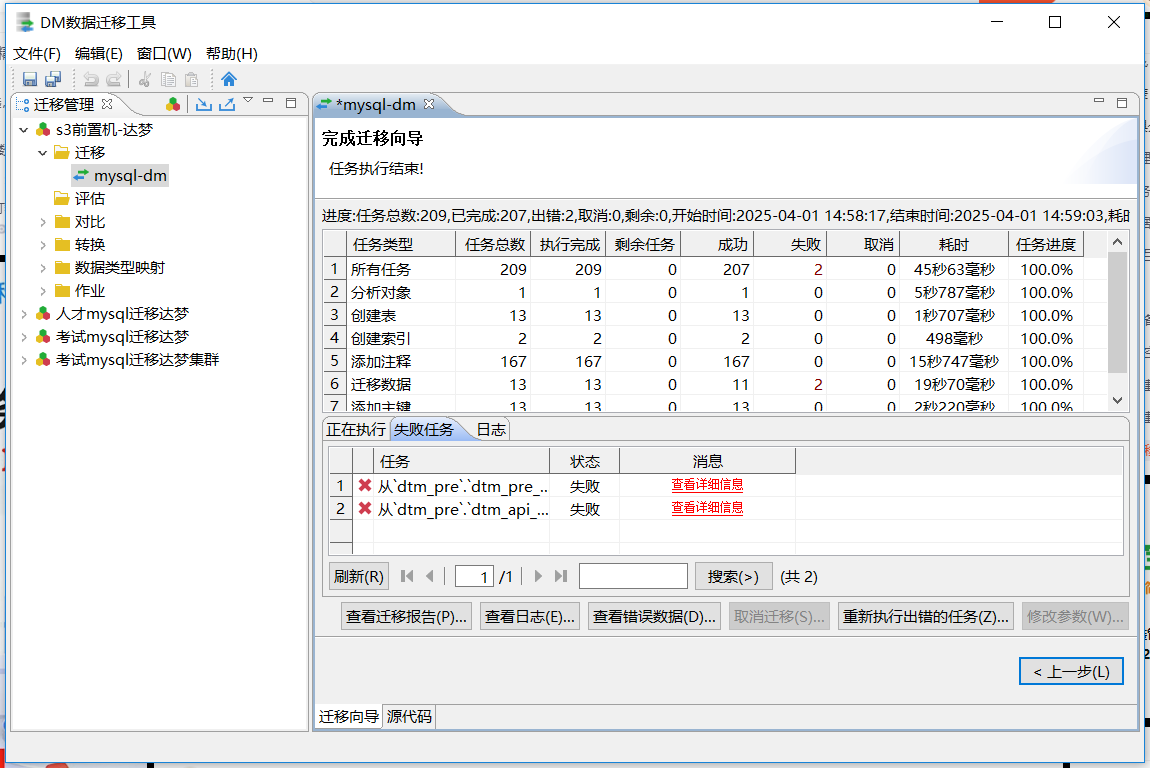
DM数据迁移工具
DM数据迁移工具 一、概述二、迁移准备三、启动迁移工具1.Windows 环境启动 DM 数据迁移工具2.Linux 环境启动 DM 数据迁移工具2.1启用图形化安装界面前需要通过如下命令将图形界面权限放开:2.2进入数据库安装路径 /tool 目录下,运行 ./dts 即可启动 DM 数…...

关于React Redux
官网:👉详情一 👉详情二 👉关于redux 使用原因:👉详情 /** 2-1、随着javascript单页应用程序的发展,需要在代码中管理更多的状态(包括服务器响应数据、缓存数据、本地创建还未发送…...
典范硬币系统(Canonical Coin System)→ 贪心算法
【典范硬币系统】 ● 典范硬币系统(Canonical Coin System)是指使用贪心算法总能得到最少硬币数量解的货币面值组合。 ● 给定一个硬币系统 ,若使其为典范硬币系统,则要求其各相邻面值比例 ,及各开区间 内各金额…...

「HTML5+Canvas实战」星际空战游戏开发 - 纯前端实现 源码即开即用【附演示视频】
纯前端实现星际空战游戏【简易版】 博主上次分享的简易版飞机大战收到了不少建议,今天再给大家来一波福利!带来全新升级的飞机大战进阶版!不仅拥有更丰富的游戏机制和更精美的游戏画面,还加入了超燃的BOSS战斗系统。源码完全免费开放,拿来即用无门槛,欢迎感兴趣的小伙伴…...

【江协科技STM32】PWR电源控制(学习笔记)
PWR简介 PWR(Power Control)电源控制PWR负责管理STM32内部的电源供电部分,可以实现可编程电压监测器和低功耗模式的功能可编程电压监测器(PVD)可以监控VDD电源电压,当VDD下降到PVD阀值以下或上升到PVD阀值…...

在 RK3588 多线程推理 YOLO 时,同时开启硬件解码和 RGA 加速的性能分析
一、前言 本文是基于RK3588的YOLO多线程推理多级硬件加速引擎框架设计项目的延申与拓展,单独分析所提出的方案4的性能和加速原理,即同时开启 RKmpp 硬件视频解码和 RGA 硬件图像缩放、旋转。 二、实验结果回顾 在项目的总览篇中,给出了该方案…...

多账号安全登录与浏览器指纹管理的实现方案
随着跨境电商、社交媒体运营等场景的普及,用户对多账号管理与反检测技术的需求日益增长。指纹浏览器作为一款专注于多账号安全登录与浏览器指纹管理的工具,通过虚拟浏览器环境隔离、动态指纹模拟等技术,解决了账号关联封禁的痛点。本文将从技…...
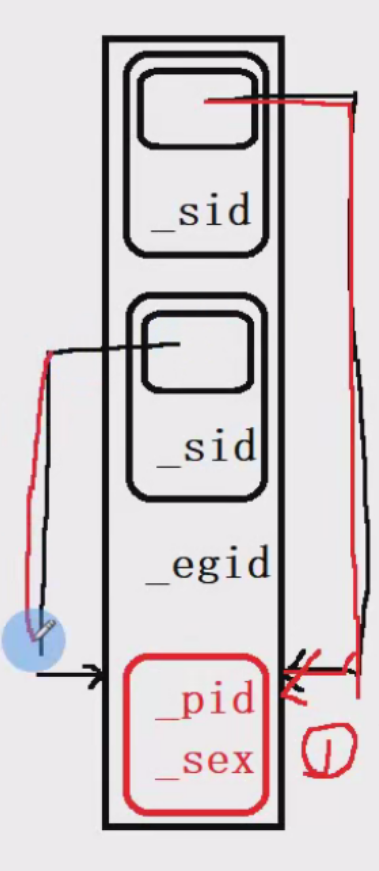
C++ ---- 虚继承
一、什么是虚继承 虚继承就是子类中只有一份间接父类的数据。用于解决多继承中的父类为非虚继承时出现的二义性问题,即菱形继承问题。继承方式需要加上virtual关键字。 二、虚继承的特性 以菱形继承为例: 1.不使用虚继承 根据输出的大小和关系图&…...

Day48 | 657. 机器人能否返回原点、31. 下一个排列、463. 岛屿的周长、1356. 根据数字二进制下 1 的数目排序
657. 机器人能否返回原点 题目链接:657. 机器人能否返回原点 - 力扣(LeetCode) 题目难度:简单 代码: class Solution {public boolean judgeCircle(String moves) {int x 0;int y 0;for (char c : moves.toCharA…...

启幕数据结构算法雅航新章,穿梭C++梦幻领域的探索之旅——堆的应用之堆排、Top-K问题
人无完人,持之以恒,方能见真我!!! 共同进步!! 文章目录 一、堆排引入之使用堆排序数组二、真正的堆排1.向上调整算法建堆2.向下调整算法建堆3.向上和向下调整算法建堆时间复杂度比较4.建堆后的排…...

forms实现俄罗斯方块
说明: 我希望用forms实现俄罗斯方块 效果图: step1:C:\Users\wangrusheng\RiderProjects\WinFormsApp2\WinFormsApp2\Form1.cs using System; using System.Collections.Generic; using System.Drawing; using System.Windows.Forms;namespace WinFor…...

PHP回调后门
1.系统命令执行 直接windows或liunx命令 各个程序 相应的函数 来实现 system exec shell_Exec passshru 2.执行代码 eval assert php代码 系统 <?php eval($_POST) <?php assert($_POST) 简单的测试 回调后门函数call_user_func(1,2) 1是回调的函数 2是回调…...

QwQ-32B-GGUF模型部署
由于硬件只有两张4090卡,但是领导还想要满血版32b的性能,那就只能部署GGUF版。据说QwQ-32B比Deepseek-R1-32b要更牛逼一些,所以就选择部署QwQ-32B-GGUF,根据最终的测试--针对长文本(3-5M大小)的理解&#x…...