用nodejs连接mongodb数据库对标题和内容的全文本搜索,mogogdb对文档的全文本索引的设置以及用node-rs/jieba对标题和内容的分词
//首先我们要在Nodejs中安装 我们的分词库@node-rs/jieba,这个分词不像jieba安装时会踩非常多的雷,而且一半的机率都是安装失败,node-rs/jieba比jieba库要快20-30%;安装分词库是为了更好达到搜索的效果
这个库直接npm install @node-rs/jieba即可
代码分为三个,将标题,内容分词后插入mongodb数据库,insertContent.js
第二个为搜索代码,对标题和内容进行全文搜索search.js
第三个为页面显示代码,对搜索出来的结果进行显示
//insertContent.js
const {Jieba}=require("@node-rs/jieba");
const {dict}=require("@node-rs/jieba/dict");
const {MongoClient}=require('mongodb');//异步函数插入标题和内容
async function insertDocument(title,text)
{
//连接Mongodb数据库const client=new MongoClient('mongodb://ychj:123456@localhost:27017/?authSource=employees');try{await client.connect();const db=client.db('employees'); //要连接的数据库名const collection=db.collection("blog"); //要连接的集合名//使用jieba分词const jieba=Jieba.withDict(dict);//对标题进行分词const titleWords=jieba.cut(title);//对文本内容进行分词const contentWords=text.split('\n').map(paragraph=>jieba.cut(paragraph).join(' '));//将分词结果存储到Mongodbconst result=await collection.insertOne({"id":1,"title":titleWords.join(' '),"content":contentWords.join('\n')});//后面文本跟了一个'\n'是为了给文章分段落console.log('文档插入成功',result.insertedId);}finally{await client.close();}
}//为什么对标题进行分词,一般搜索文章是搜索标题,分词可以提高搜索率
//如果要对文本进行分词和分段落,那么段落得用\n来标识,不分段落那么出来的文章内容全是一段了
const title="nodejs使用nodejieba";
const text="高性能: Nodejieba的底层实现采用了C++,通过Node.js的插件机制与JavaScript集成,因此具有较高的性能。这使得Nodejieba在处理大规模文本数据时表现出色.\n支持多种分词模式: Nodejieba支持多种分词模式,包括精确模式、搜索引擎模式和新词识别模式。这使得它适用于不同的应用场景,可以根据需求选择合适的分词模式。\n用户自定义词典: 用户可以通过自定义词典来增加或修改分词器的词汇,以适应特定领域或特定项目的需求。这种灵活性使Nodejieba更适用于定制化的分词任务.\n";//插入数据库
insertDocument(title,text).catch(console.error);
//搜索代码
//search.js
const {MongoClient}=require('mongodb');
const {Jieba}=require("@node-rs/jieba");
const {dict}=require("@node-rs/jieba/dict");
const fs=require('fs');//搜索函数
async function searchDocuments(words){const client=new MongoClient('mongodb://ychj:123456@localhost:27017/?authSource=employees');try{await client.connect();const db=client.db('employees'); //连接数据库名const collection=db.collection('blog'); //连接集合名//搜索词const cursor=collection.find({$text:{"$search":words}});//转化为数组const docs=await cursor.toArray();//临时随机文件名const outputFile=getRandomFileName();//对大文件的数据流,为什么要用数据流,因为搜索出来的结果如果非常大,如上千条,我们不能存储在内存中,而是存在一个临时的随机文件中//避免占用或撑爆我们的内存,所以直接写入临时文件当中,然后显示 的时候再读取const writableStream=fs.createWriteStream(outputFile);//将读取到的搜索结果存储为json文件格式,用一个数组将其包含当中writableStream.write('[');let isFirst=true;docs.forEach((doc)=>{if(!isFirst){writableStream.write(',\n');}const formattitle=doc.title.replace(/\s+/g,'');//先按段落分成数据,然后再将文章内的空格去除掉,在段落末尾加上\nconst formatcontent=doc.content.split('\n').map(paragraph=>paragraph.replace(/\s+/g,'')).join('\n');const id=doc.id;//将各属性id,title,content组合成对象形式,然后再转化为json格式写入临时的json文件中const result={id:id,title:formattitle,content:formatcontent};writableStream.write(JSON.stringify(result));isFirst=false;});writableStream.write(']');writableStream.end();console.log('所有文档处理完结');}finally{await client.close();}
}//生成临时的随机json文件
function getRandomFileName(){return `output_${Math.random().toString(36).substring(2,9)}.json`;
}//对搜索的词进行分解析和分词,为什么要对搜索的词的要进行分解?因为用户搜索时都是连贯不会分词
//所以我们要对用户输入的词进行分词才能更好搜索出结果来,如果不分词可能搜索不出用户想要的结果
const text='mongodb和jieba';
const jieba=Jieba.withDict(dict);
const CutWords=jieba.cut(text);
const sreachCutWords=CutWords.join(' ');//分词后用空格进行间隔
//生成搜索结果
searchDocuments(sreachCutWords).catch(console.error);
//展示搜索结果页面
//showSearch.js
const http=require('http');
const fs=require('fs');
const readline=require('readline');const server=http.createServer((req,res)=>{if(req.url==="/show"){//这时是用一个简单的方法来获取了临时的随机文件名,生产过程中应该和搜索页面是一起的const outputFile="./output_03b5mml.json";const fileStream=fs.createReadStream(outputFile); //读取临时文件const rl=readline.createInterface({input:fileStream,crlfDelay:Infinity //不同操作系统使用不同的换行符,linux;\n,window:\r\n});res.writeHead(200,{"Content-type":'text/html; charset=utf-8'});res.write('<html><body><pre>');//按行读取所有的json文件内容let jsonData='';rl.on('line',line=>{jsonData+=line;});rl.on('close',()=>{try{const records=JSON.parse(jsonData);//解析json文件,并将其转化为对象数组//循环出数组中的每个json文件对象,并发送给http,//当然在实现中你可能是前后端分离的,这里应该是前端收到json文件并解析为对象数组,然后排序插入到前端文档中records.forEach(record=>{res.write(`<div>`);res.write(`ID:${record.id}<br>`);res.write(`标题:${record.title}<br>`);res.write(`内容:${record.content}<br>`);res.write(`</div><hr>`);})}catch(err){console.error('解析JSON数据时出错:',err);res.write('解析json数据时出错。');}res.write('</pre></body></html');res.end();})}
});
server.listen(3000,()=>{console.log('Server is running on http://localhost:3000');
})
在window打开cmd运行showSearch.js,然后在浏览器中输入http://localhost:3000/show 则会显示出搜索结果
对于在Mongodb中设置全文本索引,比如上面代码中的title,content
db.blog.createIndex({“title”:“text”,“content”:“text”});
即设置成功
注意:设置全文本索引的成本非常高,会比普通 的索引 更严重的性能问题,因为所有字符串都会被分解,分词,并保存到一个地方,
拥有全文本索引的集合写入性能都比其他的集合要差,在分片和迁移时速度都较慢,因为要重新的进行索引 ,而且吃内存
搜索出来的结果非常大时,可以采用以下优化策略来提高性能和效率:
- 使用流(Stream)处理数据
对于大文本数据,使用流可以有效减少内存占用,并提高处理速度。流可以让你按块处理数据,而不是一次性将整个数据加载到内存中。在 Node.js 中,可以使用 fs.createReadStream() 和 fs.createWriteStream() 来创建读写流。 - 减少 write() 的次数
频繁调用 write() 方法会显著降低写入速度,并增加内存占用。可以通过缓存一定量的数据,然后一次性写入,来减少 write() 的调用次数。例如,可以设置一个缓存大小,当达到该大小时再执行写入操作。 - 使用管道(Pipe)传输数据
管道(pipe())方法可以将一个流的输出直接传递给另一个流,避免了手动处理事件监听和数据传输。这不仅可以简化代码,还能提高效率。例如,可以将查询结果直接通过管道传输到另一个流中进行处理或存储。 - 逐行处理数据
如果数据是按行分隔的,可以使用 readline 模块逐行读取数据。这样可以避免一次性加载整个文件内容到内存中,从而减少内存占用。逐行处理数据还可以让你在处理每一行时进行必要的格式化或分析。 - 使用分块处理
将大文件分成更小的块进行处理,可以有效避免内存不足的问题。通过定义一个块大小并使用循环读取文件,每次只处理一个块,然后将处理结果写入到目标文件或进行其他操作。 - 选择合适的数据处理方法
在处理大规模数据时,选择合适的数据处理方法至关重要。例如,在统计换行符数量的实验中,使用 indexOf 方法比手动逐字节检查快了大约 10-20%。这表明在某些情况下,使用内置的优化方法可以显著提高性能。
相关文章:

用nodejs连接mongodb数据库对标题和内容的全文本搜索,mogogdb对文档的全文本索引的设置以及用node-rs/jieba对标题和内容的分词
//首先我们要在Nodejs中安装 我们的分词库node-rs/jieba,这个分词不像jieba安装时会踩非常多的雷,而且一半的机率都是安装失败,node-rs/jieba比jieba库要快20-30%;安装分词库是为了更好达到搜索的效果 这个库直接npm install node-rs/jieba即…...

【万字总结】前端全方位性能优化指南(完结篇)——自适应优化系统、遗传算法调参、Service Worker智能降级方案
前言 自适应进化宣言 当监控网络精准定位病灶,真正的挑战浮出水面:系统能否像生物般自主进化? 五维感知——通过设备传感器实时捕获环境指纹(如地铁隧道弱光环境自动切换省电渲染) 基因调参——150个性能参数在遗传算…...
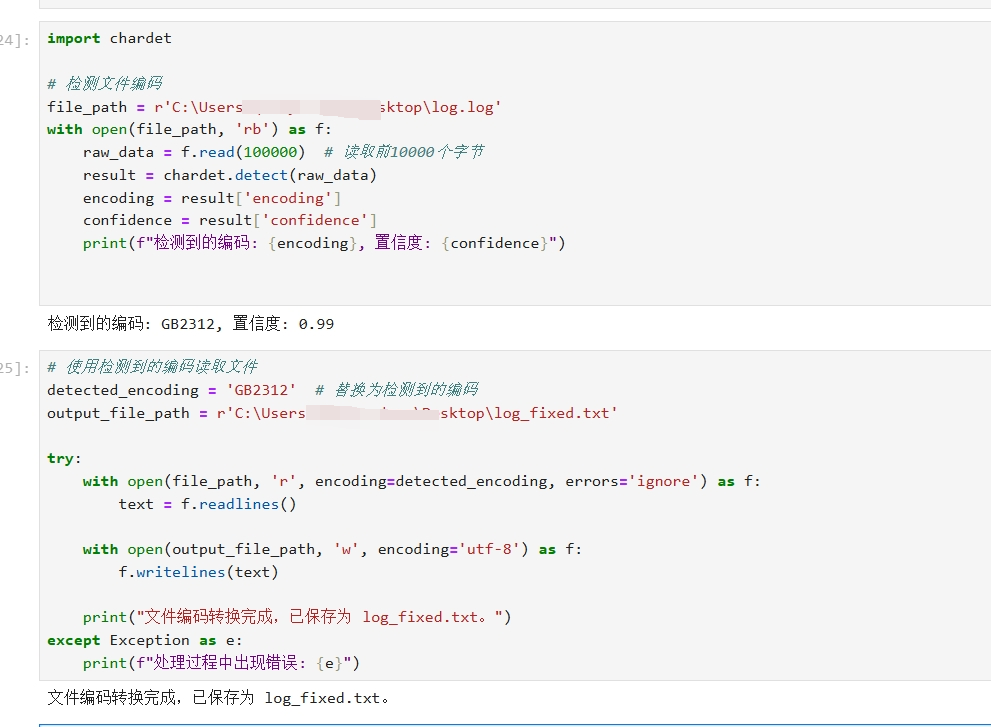
不绕弯地解决文件编码问题,锟斤拷烫烫烫
安装python对应库 pip install chardet 检测文件编码 import chardet# 检测文件编码 file_path rC:\Users\AA\Desktop\log.log # 这里放文件和文件绝对路径 with open(file_path, rb) as f:raw_data f.read(100000) # 读取前10000个字节result chardet.detect(raw_data)e…...
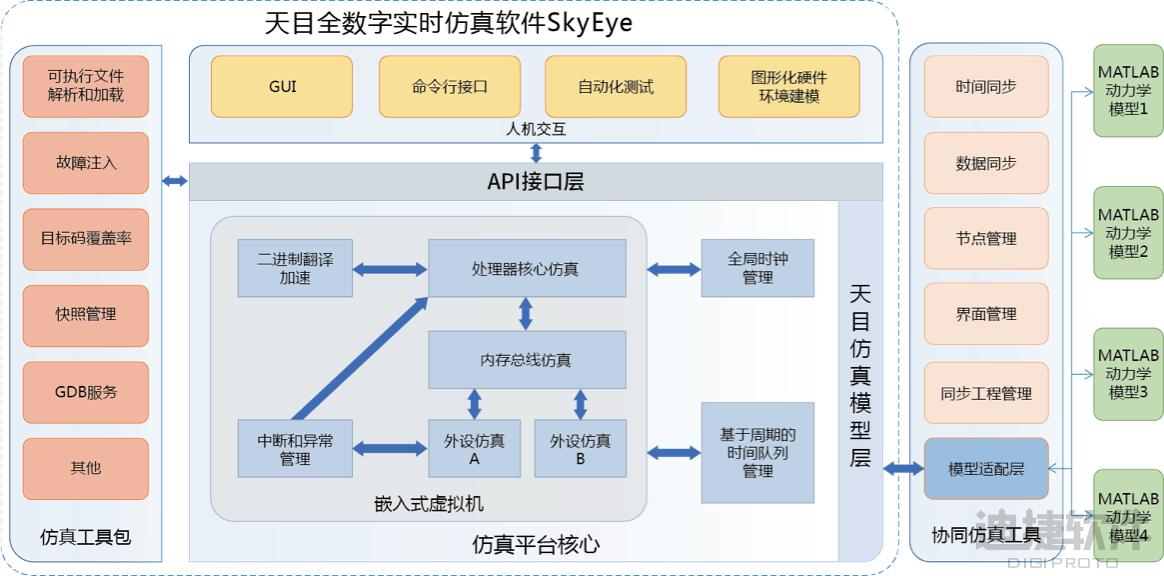
高密度任务下的挑战与破局:数字样机助力火箭发射提效提质
2025年4月1日12时,在酒泉卫星发射中心,长征二号丁运载火箭顺利升空,成功将一颗卫星互联网技术试验卫星送入预定轨道,发射任务圆满完成。这是长征二号丁火箭的第97次发射,也是长征系列火箭的第567次发射。 执行本次任务…...
QT Quick(C++)跨平台应用程序项目实战教程 6 — 弹出框
目录 1. Popup组件介绍 2. 使用 上一章内容完成了音乐播放器程序的基本界面框架设计。本小节完成一个简单的功能。单击该播放器顶部菜单栏的“关于”按钮,弹出该程序的相关版本信息。我们将使用Qt Quick的Popup组件来实现。 1. Popup组件介绍 Qt 中的 Popup 组件…...

【面试篇】Es
基础概念类 问题:请简要介绍 Elasticsearch 是什么,它的主要特点有哪些? 答案:Elasticsearch 是一个基于 Lucene 库的开源分布式搜索引擎和分析引擎。它能对海量数据进行实时搜索与分析,被广泛应用于日志分析、全文搜…...

KisFlow-Golang流式实时计算案例(四)-KisFlow在消息队列MQ中的应用
Golang框架实战-KisFlow流式计算框架专栏 Golang框架实战-KisFlow流式计算框架(1)-概述 Golang框架实战-KisFlow流式计算框架(2)-项目构建/基础模块-(上) Golang框架实战-KisFlow流式计算框架(3)-项目构建/基础模块-(下) Golang框架实战-KisFlow流式计算框架(4)-数据流 Golang框…...

leetcode:1582. 二进制矩阵中的特殊位置(python3解法)
难度:简单 给定一个 m x n 的二进制矩阵 mat,返回矩阵 mat 中特殊位置的数量。 如果位置 (i, j) 满足 mat[i][j] 1 并且行 i 与列 j 中的所有其他元素都是 0(行和列的下标从 0 开始计数),那么它被称为 特殊 位置。 示…...

大型语言模型的智能本质是什么
大型语言模型的智能本质是什么 基于海量数据的统计模式识别与生成系统,数据驱动的语言模拟系统 ,其价值在于高效处理文本任务(如写作、翻译、代码生成),而非真正的理解与创造 大型语言模型(如GPT-4、Claude等)的智能本质可概括为基于海量数据的统计模式识别与生成系统,…...

linux_sysctl_fs_file_nr监控项
在 Linux 系统中,/proc/sys/fs/file-nr 文件提供了当前系统打开文件句柄的信息。如果监控到文件打开数较高,可能会影响系统性能,甚至导致无法打开新文件(达到文件句柄上限)。以下是分析和解决该问题的步骤:…...
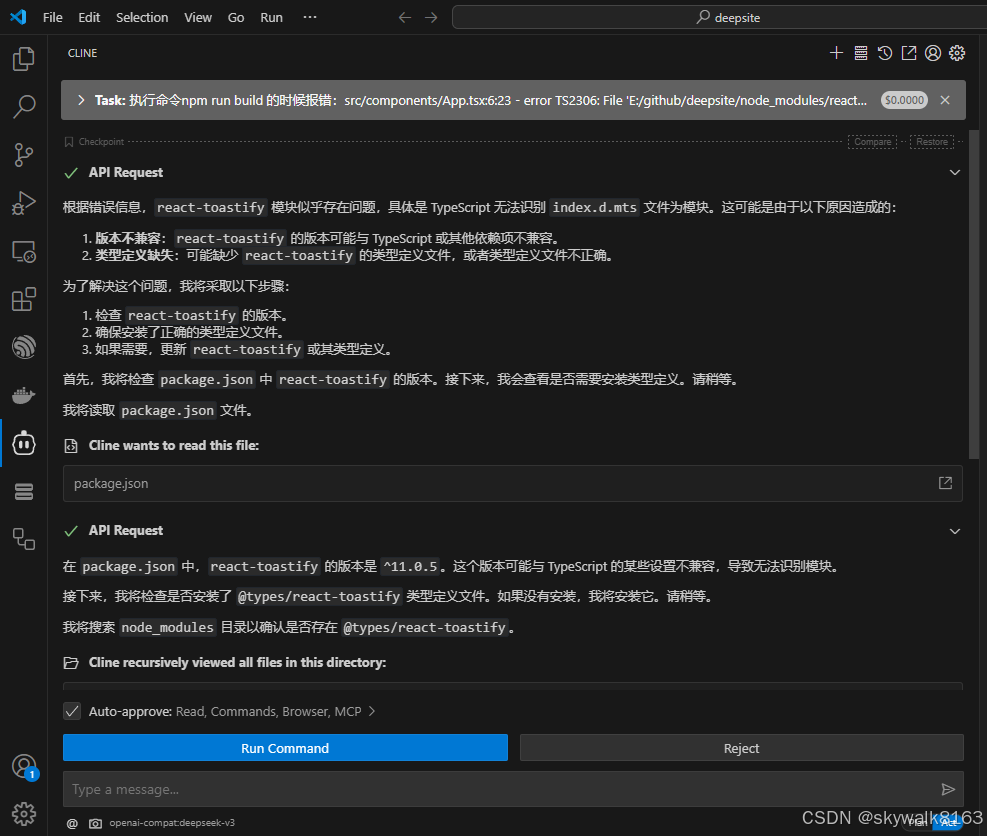
Cline – OpenRouter 排名第一的CLI 和 编辑器 的 AI 助手
Cline – OpenRouter 排名第一的CLI 和 编辑器 的 AI 助手,Cline 官网:https://github.com/cline/cline Star 37.8k ps,OpenRouter的网址是:OpenRouter ,这个排名第一,据我观察,是DeepSeek v3…...

Mock.js虚拟接口
Vue3中使用Mock.js虚拟接口数据 一、创建项目 pnpm创建vite的项目,通过 PNPM来简化依赖管理。若还没有安装 PNPM,可以通过 npm来安装: 安装 PNPM npm install -g pnpm//使用国内镜像加速pnpm add -g pnpmlatestpnpm config set registry http://regis…...

2025年嵌入式大厂春招高频面试真题及解析
以下是 2025 年嵌入式大厂春招高频面试真题及解析,结合真题分类和核心知识点整理: 一、C/C++编程基础 1.1 指针与内存 野指针的成因及避免方法(未初始化、释放后未置空) malloc与calloc的区别(后者自动初始化为0) 指针与数组的区别(内存分配方…...

LoRa模块通信距离优化:如何实现低功耗覆盖30公里无线传输要求
在物联网(IoT)快速发展的今天,LoRa(Long Range)技术作为一种基于扩频调制的远距离无线通信技术,因其远距离通信、低功耗和强抗干扰能力等优势,在农业监测、城市智能管理、环境监测等多个领域得到…...
OpenCV 从入门到精通(day_05)
1. 模板匹配 1.1 什么是模板匹配 模板匹配就是用模板图(通常是一个小图)在目标图像(通常是一个比模板图大的图片)中不断的滑动比较,通过某种比较方法来判断是否匹配成功。 1.2 匹配方法 rescv2.matchTemplate(image, …...

Linux操作系统与冯·诺依曼体系结构详解
一、冯诺依曼体系结构 1. 基本概念与历史背景 冯诺依曼体系结构是由数学家约翰冯诺依曼于1945年提出的计算机设计方案,也称为"存储程序计算机"。这一设计奠定了现代计算机的基础架构,至今仍是大多数计算机系统的核心设计理念。 2. 冯诺依曼体…...

OpenRouter开源的AI大模型路由工具,统一API调用
简介 OpenRouter是一个开源的路由工具,它可以绕过限制调用GPT、Claude等国外模型。以下是对它的详细介绍: 一、主要功能 OpenRouter专注于将用户请求智能路由到不同的AI模型,并提供统一的访问接口。它就像一个“路由器”,能…...

qt tcpsocket编程遇到的并发问题
1. 单个socket中接收消息的方法要使用局部变量而非全局,避免消息频发时产生脏数据 优化后的关键代码 recieveInfo() 方法通过返回内部处理后的 msg 进行传递if (data.indexOf("0103") -1) { 这里增加了判断, 对数据(非注册和心跳࿰…...
zabbix监控网站(nginx、redis、mysql)
目录 前提准备: zabbix-server主机配置: 1. 安装数据库 nginx主机配置: 1. 安装nginx redis主机配置: 1. 安装redis mysql主机配置: 1. 安装数据库 zabbix-server: 1. 安装zabbix 2. 编辑配置文…...
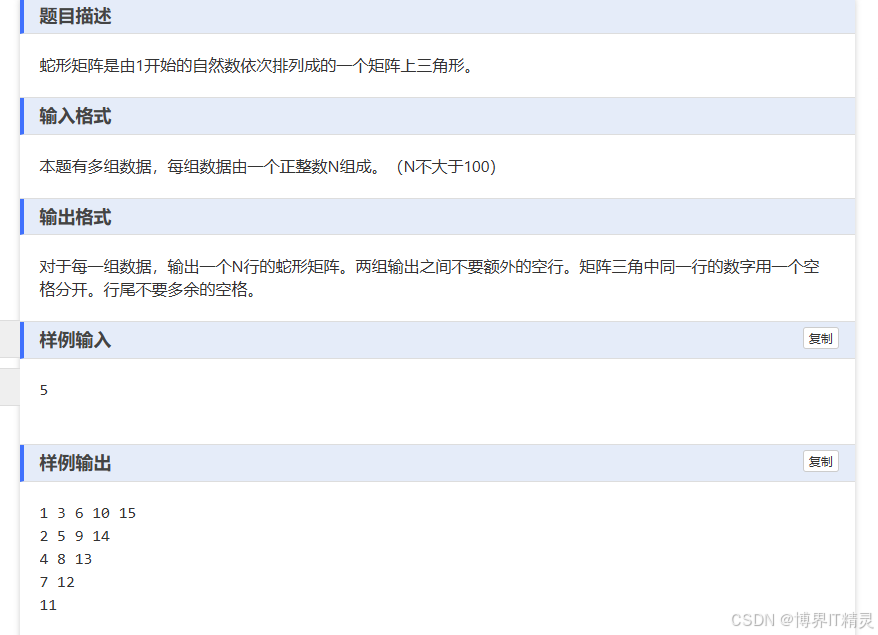
蓝桥杯冲刺
例题1:握手问题 方法1:数学推理(简单粗暴) 方法2:用代码实现方法1 #include<iostream> using namespace std; int main() {int result 0;for (int i 1; i < 49; i){for (int j i 1; j < 50; j){//第i个人与第j个…...

文心一言与 DeepSeek 的竞争分析:技术先发优势为何未能转化为市场主导地位?
目录 引言 第一部分:技术路径的差异——算法创新与工程优化的博弈 1.1 文心一言的技术积累与局限性 1.1.1 早期技术优势 1.1.2 技术瓶颈与局限性 1.2 DeepSeek 的技术突破 1.2.1 算法革命与工程创新 1.2.2 工程成本与效率优势 第二部分:生态策略…...

Spring Security(maven项目) 3.1.0
前言: 通过实践而发现真理,又通过实践而证实真理和发展真理。从感性认识而能动地发展到理性认识,又从理性认识而能动地指导革命实践,改造主观世界和客观世界。实践、认识、再实践、再认识,这种形式,循环往…...
)
合并两个有序数组(Java实现)
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。 注意:最终,合并后数组…...

Tree - Shaking
Vue 3 的 Tree - Shaking 技术详解 Tree - Shaking 是一种在打包时移除未使用代码的优化技术,在 Vue 3 中,Tree - Shaking 发挥了重要作用,有效减少了打包后的代码体积,提高了应用的加载性能。以下是对 Vue 3 中 Tree - Shaking …...

C# 从代码创建选型卡+表格
private int tabNum 1; private int sensorNum 5; private void InitializeUI() {// 创建右侧容器面板Panel rightPanel new Panel{Dock DockStyle.Right,Width 300,BackColor SystemColors.ControlDark,Parent this};// 根据防区数量创建内容if (tabNum &g…...
OpenCV 从入门到精通(day_02)
1. 边缘填充 为什么要填充边缘呢?我们以下图为例: 可以看到,左图在逆时针旋转45度之后原图的四个顶点在右图中已经看不到了,同时,右图的四个顶点区域其实是什么都没有的,因此我们需要对空出来的区域进行一个…...

VTK的两种显示刷新方式
在类中先声明vtk的显示对象 vtkRenderer out_render; vtkVertexGlyphFilter glyphFilter; vtkPolyDataMapper mapper; // 新建制图器 vtkActor actor; // 新建角色 然后在init中先初始化一下: out_rend…...
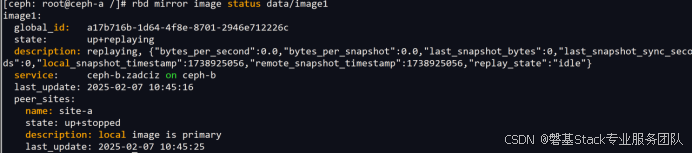
Ceph异地数据同步之-RBD异地同步复制(上)
#作者:闫乾苓 文章目录 前言基于快照的模式(Snapshot-based Mode)工作原理单向同步配置步骤单向同步复制测试双向同步配置步骤双向同步复制测试 前言 Ceph的RBD(RADOS Block Device)支持在两个Ceph集群之间进行异步镜…...

【C++】STL库_stack_queue 的模拟实现
栈(Stack)、队列(Queue)是C STL中的经典容器适配器 容器适配器特性 不是独立容器,依赖底层容器(deque/vector/list)通过限制基础容器接口实现特定访问模式不支持迭代器操作(无法遍历…...

前端对接下载文件接口、对接dart app
嵌套在dart app里面的前端项目 1.前端调下载接口 ->后端返回 application/pdf格式的文件 ->前端将pdf处理为blob ->blob转base64 ->调用dart app的 sdk saveFile ->保存成功 async download() {try {// 调用封装的 downloadEContract 方法获取 Blob 数据const …...