OpenCV 从入门到精通(day_02)
1. 边缘填充
为什么要填充边缘呢?我们以下图为例:
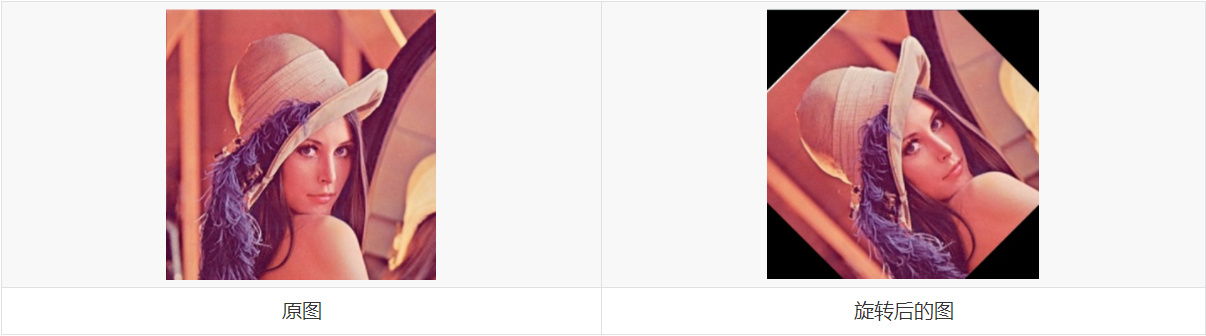
可以看到,左图在逆时针旋转45度之后原图的四个顶点在右图中已经看不到了,同时,右图的四个顶点区域其实是什么都没有的,因此我们需要对空出来的区域进行一个填充。右图就是对空出来的区域进行了像素值为(0,0,0)的填充,也就是黑色像素值的填充。除此之外,后续的一些图像处理方式也会用到边缘填充,这里介绍五个常用的边缘填充方法。
1.1 边界复制(BORDER_REPLICATE)
边界复制会将边界处的像素值进行复制,然后作为边界填充的像素值,如下图所示,可以看到四周的像素值都一样。
语法:
new_img=cv.warpAffine(img,M,(w,h),cv.INTER_LANCZOS4,borderMode=cv.BORDER_REPLICATE)示例图:


示例:
import cv2 as cv# 读取图片
img = cv.imread('./images/face.png')
# 获取图片尺寸
h, w, c = img.shape
# 获取旋转矩阵
M = cv.getRotationMatrix2D((w // 2, h // 2), 0, 0.2)
# 进行仿射
new_img = cv.warpAffine(img, M, (w, h), flags=cv.INTER_LANCZOS4, borderMode=cv.BORDER_REPLICATE) # 边界复制
# 显示图片
cv.imshow('img', img)
cv.imshow('new_img', new_img)
cv.waitKey(0)
cv.destroyAllWindows()1.2 边界反射(BORDER_REFLECT)
语法:
new_img=cv.warpAffine(img,M,(w,h),cv.INTER_LANCZOS4,borderMode=cv.BORDER_REFLECT)示例图:


示例:
import cv2 as cv# 读取图片
img = cv.imread('./images/face.png')
# 获取图片尺寸
h, w, c = img.shape
# 获取旋转矩阵
M = cv.getRotationMatrix2D((w // 2, h // 2), 0, 0.2)
# 进行仿射
new_img_reflect = cv.warpAffine(img, M, (w, h), flags=cv.INTER_LANCZOS4, borderMode=cv.BORDER_REFLECT) # 边界反射
# 显示图片
cv.imshow('img', img)
cv.imshow('new_img_reflect', new_img_reflect)
cv.waitKey(3000)
cv.destroyAllWindows()
1.3 边界反射101(BORDER_REFLECT_101)
语法:
new_img=cv.warpAffine(img,M,(w,h),cv.INTER_LANCZOS4,borderMode=cv.BORDER_REFLECT_101)示例图:


示例:
import cv2 as cv# 读取图片
img = cv.imread('./images/face.png')
# 获取图片尺寸
h, w, c = img.shape
# 获取旋转矩阵
M = cv.getRotationMatrix2D((w // 2, h // 2), 0, 0.2)
# 进行仿射
new_img_reflect_101 = cv.warpAffine(img, M, (w, h), flags=cv.INTER_LANCZOS4,borderMode=cv.BORDER_REFLECT_101) # 边界反射101
# 显示图片
cv.imshow('img', img)
cv.imshow('new_img_reflect_101', new_img_reflect_101)
cv.waitKey(3000)
cv.destroyAllWindows()
1.4 边界常数(BORDER_CONSTANT)
语法:
new_img=cv.warpAffine(img,M,(w,h),cv.INTER_LANCZOS4,borderMode=cv.BORDER_CONSTANT,borderValue=(0,0,255))示例图:


示例:
import cv2 as cv# 读取图片
img = cv.imread('./images/face.png')
# 获取图片尺寸
h, w, c = img.shape
# 获取旋转矩阵
M = cv.getRotationMatrix2D((w // 2, h // 2), 0, 0.2)
# 进行仿射
new_img_constant = cv.warpAffine(img, M, (w, h), flags=cv.INTER_LANCZOS4, borderMode=cv.BORDER_CONSTANT,borderValue=(0, 0, 255)) # 边界常数
# 显示图片
cv.imshow('img', img)
cv.imshow('new_img_constant', new_img_constant)
cv.waitKey(3000)
cv.destroyAllWindows()
1.5 边界包裹(BORDER_WRAP)
语法:
new_img=cv.warpAffine(img,M,(w,h),cv.INTER_LANCZOS4,borderMode=cv.BORDER_WRAP)示例图:


示例:
import cv2 as cv# 读取图片
img = cv.imread('./images/face.png')
# 获取图片尺寸
h, w, c = img.shape
# 获取旋转矩阵
M = cv.getRotationMatrix2D((w // 2, h // 2), 0, 0.2)
# 进行仿射
new_img_wrap = cv.warpAffine(img, M, (w, h), flags=cv.INTER_LANCZOS4, borderMode=cv.BORDER_WRAP) # 边界包裹
# 显示图片
cv.imshow('img', img)
cv.imshow('new_img_wrap', new_img_wrap)
cv.waitKey(3000)
cv.destroyAllWindows()
2. 图像矫正(透视变换)
图像矫正的原理是透视变换,下面来介绍一下透视变换的概念。
听名字有点熟,我们在图像旋转里接触过仿射变换,知道仿射变换是把一个二维坐标系转换到另一个二维坐标系的过程,转换过程坐标点的相对位置和属性不发生变换,是一个线性变换,该过程只发生旋转和平移过程。因此,一个平行四边形经过仿射变换后还是一个平行四边形。
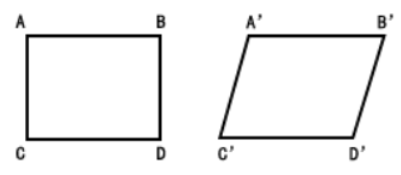
而透视变换是把一个图像投影到一个新的视平面的过程,在现实世界中,我们观察到的物体在视觉上会受到透视效果的影响,即远处的物体看起来会比近处的物体小。透视投影是指将三维空间中的物体投影到二维平面上的过程,这个过程会导致物体在图像中出现形变和透视畸变。透视变换可以通过数学模型来校正这种透视畸变,使得图像中的物体看起来更符合我们的直观感受。通俗的讲,透视变换的作用其实就是改变一下图像里的目标物体的被观察的视角。

如上图所示,图1在经过透视变换后得到了图2的结果,带入上面的话就是图像中的车道线(目标物体)的被观察视角从平视视角变成了俯视视角,这就是透视变换的作用。
假设我们有一个点 (x,y,z)在三维空间中,并且我们想要将其投影到二维平面上。我们可以先将其转换为齐次坐标, (x,y,z),然后进行透视投影,得到了经过透视投影后的二维坐标 (x′,y′)。通过将 X和Y 分别除以Z,我们可以模拟出真实的透视效果。
与仿射变换一样,透视变换也有自己的透视变换矩阵:

即
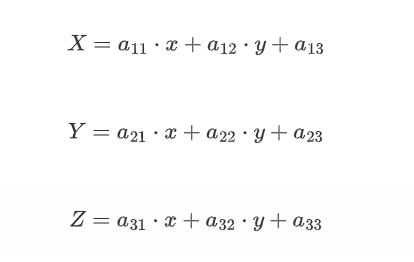
由此可得新的坐标的表达式为:
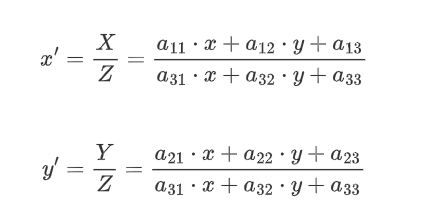
其中x、y是原始图像点的坐标,x'、y'是变换后的坐标,a11,a12,…,a33则是一些旋转量和平移量,由于透视变换矩阵的推导涉及三维的转换,所以这里不具体研究该矩阵,只要会使用就行,而OpenCV里也提供了getPerspectiveTransform()函数用来生成该3*3的透视变换矩阵。
M=getPerspectiveTransform(src,dst)
在该函数中,需要提供两个参数:
src:原图像上需要进行透视变化的四个点的坐标,这四个点用于定义一个原图中的四边形区域。
dst:透视变换后,src的四个点在新目标图像的四个新坐标。
该函数会返回一个透视变换矩阵,得到透视变化矩阵之后,使用warpPerspective()函数即可进行透视变化计算,并得到新的图像。
该函数需要提供如下参数:cv2.warpPerspective(src, M, dsize, flags, borderMode)
src:输入图像。
M:透视变换矩阵。这个矩阵可以通过getPerspectiveTransform函数计算得到。
dsize:输出图像的大小。它可以是一个Size对象,也可以是一个二元组。
flags:插值方法的标记。
borderMode:边界填充的模式。
示例:
import cv2 as cv
import numpy as np# 读取图像
img = cv.imread('./images/3.png')
# 原图中的四个点:左上、右上、左下、右下
point_1 = np.float32([[178, 100], [487, 134], [124, 267], [473, 308]])
point_2 = np.float32([[0, 0], [img.shape[1], 0], [0, img.shape[0]], [img.shape[1], img.shape[0]]])
# 拷贝图像
img_2 = img.copy()
# 框出目标部分
cv.line(img_2, tuple(point_1[0].astype(np.int64)), tuple(point_1[1].astype(np.int64)), (255, 0, 0), 2)
cv.line(img_2, tuple(point_1[0].astype(np.int64)), tuple(point_1[2].astype(np.int64)), (255, 0, 0), 2)
cv.line(img_2, tuple(point_1[3].astype(np.int64)), tuple(point_1[1].astype(np.int64)), (255, 0, 0), 2)
cv.line(img_2, tuple(point_1[3].astype(np.int64)), tuple(point_1[2].astype(np.int64)), (255, 0, 0), 2)
cv.imshow('img', img)
cv.imshow('img_2', img_2)
# 获取透视变换矩阵
M = cv.getPerspectiveTransform(point_1, point_2)
# 进行透视变换
c_img = cv.warpPerspective(img, M, (img.shape[1], img.shape[0]), flags=cv.INTER_LINEAR)
cv.imshow('c_img', c_img)
cv.waitKey(3000)
cv.destroyAllWindows()
3. 图像色彩空间转换
OpenCV中,图像色彩空间转换是一个非常基础且重要的操作,就是将图像从一种颜色表示形式转换为另一种表示形式的过程。通过将图像从一个色彩空间转换到另一个色彩空间,可以更好地进行特定类型的图像处理和分析任务。常见的颜色空间包括RGB、HSV、YUV等。
3.1 RGB颜色空间
RGB颜色模型基于笛卡尔坐标系,如下图所示,RGB原色值位于3个角上,二次色青色、红色和黄色位于另外三个角上,黑色位于原点处,白色位于离原点最远的角上。因为黑色在RGB三通道中表现为(0,0,0),所以映射到这里就是原点;而白色是(255,255,255),所以映射到这里就是三个坐标为最大值的点。
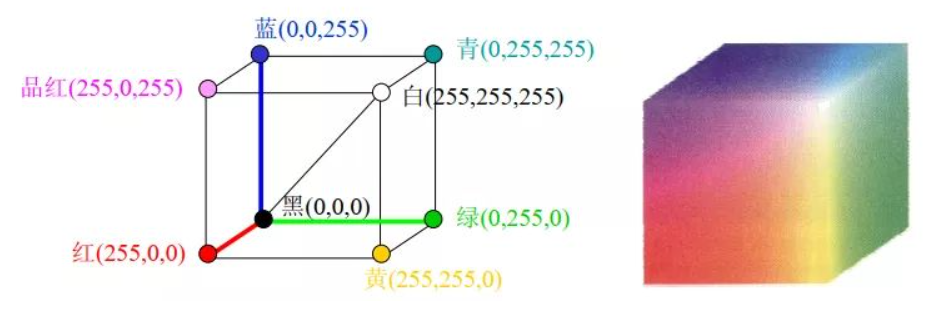
RGB颜色空间可以产生大约1600万种颜色,几乎包括了世界上的所有颜色,也就是说可以使用RGB颜色空间来生成任意一种颜色。
注意:在OpenCV中,颜色是以BGR的方式进行存储的,而不是RGB,这也是上面红色的像素值是(0,0,255)而不是(255,0,0)的原因。
3.2 颜色加法
你可以使用OpenCV的cv.add()函数把两幅图像相加,或者可以简单地通过numpy操作添加两个图像,如res = img1 + img2。两个图像应该具有相同的大小和类型。
OpenCV加法和Numpy加法之间存在差异, OpenCV的加法是饱和操作,而Numpy添加是模运算。
示例:
import cv2 as cv
import numpy as npimg = cv.imread('./images/pig.png')
shape = img.shape
# print(shape,type(shape))
# 创建一个全0矩阵,宽高和原图一样大,单通道
my_gray = np.zeros((shape[0], shape[1]), dtype=np.uint8)
# 遍历原图像素点,拿到三个通道里像素最大值
# 遍历行
for i in range(shape[0]):# 遍历列for j in range(shape[1]):my_gray[i, j] = max(img[i, j]) # OpenCV 加法# my_gray[i, j] = np.uint8(round(wb * pig[i, j, 0] + wg * pig[i, j, 1] + wr * pig[i, j, 2])) # Numpy 加法
cv.imshow('img', img)
cv.imshow('my_gray', my_gray)
cv.waitKey(3000)
cv.destroyAllWindows()
3.3 颜色加权加法
语法:
cv2.addWeighted(src1,alpha,src2,deta,gamma) src1、src2:输入图像;alpha、beta:两张图象权重;gamma:亮度调整值。
这其实也是加法,但是不同的是两幅图像的权重不同,这就会给人一种混合或者透明的感觉。图像混合的计算公式如下:
g(x) = (1−α)f0(x) + αf1(x)
现在我们把两幅图混合在一起。第一幅图的权重是0.7,第二幅图的权重是0.3。函数cv2.addWeighted()可以按下面的公式对图片进行混合操作:
dst = α⋅img1 + β⋅img2 + γ
示例:
import cv2 as cvpig = cv.imread('./images/pig.png')
pig_1 = cv.resize(pig, (480, 480))
cao = cv.imread('./images/cao.png')
cao_1 = cv.resize(cao, (480, 480))
img = cv.add(pig_1, cao_1)
# numpy直接相加
img_2 = pig_1 + cao_1
cv.imshow('img', img)
cv.imshow('img_2', img_2)
# 颜色加权加法cv.addweighted(src1,a,src2,b,r)
img_3 = cv.addWeighted(pig, 0.7, cao, 0.3, 0)
cv.imshow('img_3', img_3)
cv.waitKey(3000)
cv.destroyAllWindows()
3.4 HSV颜色空间
HSV颜色空间指的是HSV颜色模型,这是一种与RGB颜色模型并列的颜色空间表示法。RGB颜色模型使用红、绿、蓝三原色的强度来表示颜色,是一种加色法模型,即颜色的混合是添加三原色的强度。而HSV颜色空间使用色调(Hue)、饱和度(Saturation)和亮度(Value)三个参数来表示颜色,色调H表示颜色的种类,如红色、绿色、蓝色等;饱和度表示颜色的纯度或强度,如红色越纯,饱和度就越高;亮度表示颜色的明暗程度,如黑色比白色亮度低。
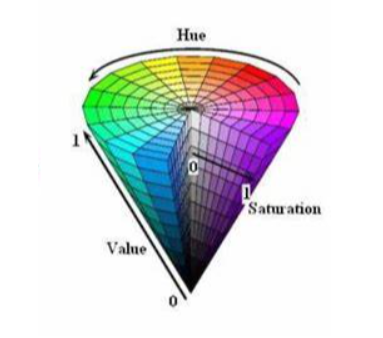
HSV颜色模型是一种六角锥体模型,如下图所示:
色调H:
使用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,紫色为300°。通过改变H的值,可以选择不同的颜色
饱和度S:
饱和度S表示颜色接近光谱色的程度。一种颜色可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例越大,颜色接近光谱色的程度就越高,颜色的饱和度就越高。饱和度越高,颜色就越深而艳,光谱色的白光成分为0,饱和度达到最高。通常取值范围为0%~100%,其中0%表示灰色或无色,100%表示纯色,通过调整饱和度的值,可以使颜色变得更加鲜艳或者更加灰暗。
明度V:
明度表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。通常取值范围为0%(黑)到100%(白),通过调整明度的值,可以使颜色变得更亮或者更暗。
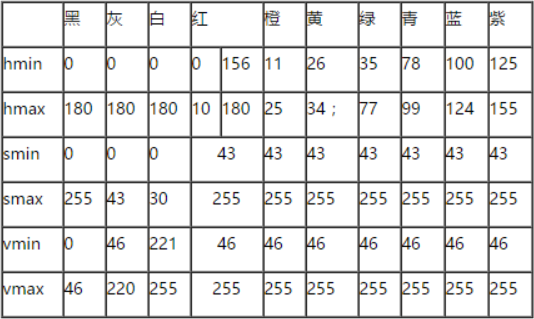
一般对颜色空间的图像进行有效处理都是在HSV空间进行的,然后对于基本色中对应的HSV分量需要给定一个严格的范围,下面是通过实验计算的模糊范围(准确的范围在网上都没有给出):
H: 0— 180
S: 0— 255
V: 0— 255
此处把部分红色归为紫色范围:
为什么有了RGB颜色空间我们还是需要转换成HSV颜色空间来进行图像处理呢?
- 符合人类对颜色的感知方式:人类对颜色的感知是基于色调、饱和度和亮度三个维度的,而HSV颜色空间恰好就是通过这三个维度来描述颜色的。因此,使用HSV空间处理图像可以更直观地调整颜色和进行色彩平衡等操作,更符合人类的感知习惯。
- 颜色调整更加直观:在HSV颜色空间中,色调、饱和度和亮度的调整都是直观的,而在RGB颜色空间中调整颜色不那么直观。例如,在RGB空间中要调整红色系的颜色,需要同时调整R、G、B三个通道的数值,而在HSV空间中只需要调整色调和饱和度即可。
- 降维处理有利于计算:在图像处理中,降维处理可以减少计算的复杂性和计算量。HSV颜色空间相对于RGB颜色空间,减少了两个维度(红、绿、蓝),这有利于进行一些计算和处理任务,比如色彩分割、匹配等。
因此,在进行图片颜色识别时,我们会将RGB图像转换到HSV颜色空间,然后根据颜色区间来识别目标颜色。
3.5 RGB转Gray(灰度)
cv2.cvtColor是OpenCV中的一个函数,用于图像颜色空间的转换。可以将一个图像从一个颜色空间转换为另一个颜色空间,比如从RGB到灰度图,或者从RGB到HSV的转换等。
语法:cv2.cvtColor(img,code)
- 'img':输入图像,可以是一个Numpy数组绘着一个OpenCV的Mat对象;
- 'code':指定转换的类型,可以使用预定义的转换代码。
示例:
import cv2 as cvimg = cv.imread('./images/pig.png', cv.IMREAD_GRAYSCALE)
img2 = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# print(img2.shape)
cv.imshow('img', img)
cv.imshow('img2', img2)
cv.waitKey(3000)
cv.destroyAllWindows()3.6 RGB转HSV
与RGB转Gray(灰度)类似。
示例:
import cv2 as cvimg = cv.imread('./images/pig.png')
img2 = cv.cvtColor(img, cv.COLOR_BGR2HSV)
cv.imshow('img', img)
cv.imshow('img2', img2)
cv.waitKey(3000)
cv.destroyAllWindows()
4. 灰度实验
将彩色图像转换为灰度图像的过程称为灰度化,这种做法在图像处理和计算机视觉领域非常常见。
灰度图与彩色图最大的不同就是:彩色图是由R、G、B三个通道组成,而灰度图只有一个通道,也称为单通道图像,所以彩色图转成灰度图的过程本质上就是将R、G、B三通道合并成一个通道的过程。本实验中一共介绍了三种合并方法,分别是最大值法、平均值法以及加权均值法。
4.1 灰度图
每个像素只有一个采样颜色的图像,这类图像通常显示为从最暗黑色到最亮的白色的灰度,尽管理论上这个采样可以任何颜色的不同深浅,甚至可以是不同亮度上的不同颜色。灰度图像与黑白图像不同,在计算机图像领域中黑白图像只有黑色与白色两种颜色;但是,灰度图像在黑色与白色之间还有许多级的颜色深度。灰度图像经常是在单个电磁波频谱如可见光内测量每个像素的亮度得到的,用于显示的灰度图像通常用每个采样像素8位的非线性尺度来保存,这样可以有256级灰度。

4.2 最大值法
对于彩色图像的每个像素,它会从R、G、B三个通道的值中选出最大的一个,并将其作为灰度图像中对应位置的像素值。
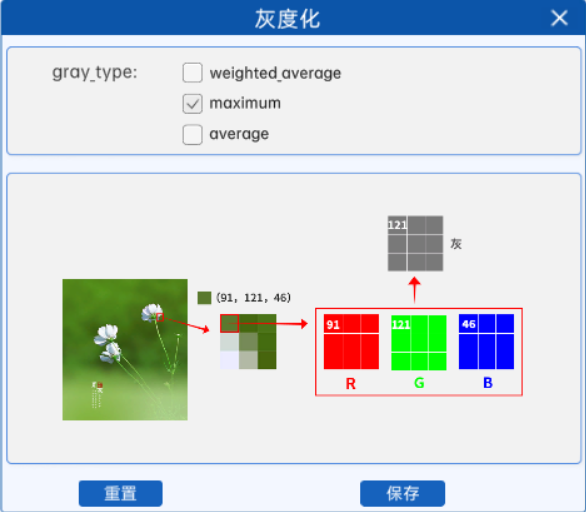
例如某图像中某像素点的像素值如上图所示,那么在使用最大值法进行灰度化时,就会从该像素点对应的RGB通道中选取最大的像素值作为灰度值,所以在灰度图中的对应位置上,该像素点的像素值就是121。
示例:
import cv2 as cv
import numpy as npimg = cv.imread('./images/pig.png')
shape = img.shape
# print(shape,type(shape))
# 创建一个全0矩阵,宽高和原图一样大,单通道
my_gray = np.zeros((shape[0], shape[1]), dtype=np.uint8)
# 遍历原图像素点,拿到三个通道里像素最大值
# 遍历行
for i in range(shape[0]):# 遍历列for j in range(shape[1]):my_gray[i, j] = max(img[i, j])
cv.imshow('img', img)
cv.imshow('my_gray', my_gray)
cv.waitKey(3000)
cv.destroyAllWindows()
4.3 平均值法
对于彩色图像的每个像素,它会将R、G、B三个通道的像素值全部加起来,然后再除以三,得到的平均值就是灰度图像中对应位置的像素值。
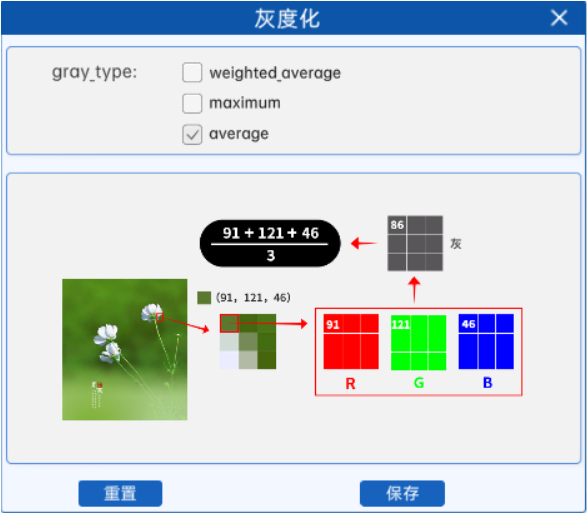
例如某图像中某像素点的像素值如上图所示,那么在使用平均值进行灰度化时,其计算结果就是(91+121+46)/3=86(对结果进行取整),所以在灰度图中的对应位置上,该像素点的像素值就是86。
示例:
import cv2 as cv
import numpy as nppig = cv.imread('./images/pig.png')
shape = pig.shape
# 创建一个大小一致的单通道图像
gray = np.zeros((shape[0], shape[1]), dtype=np.uint8)
# 遍历行
for i in range(shape[0]):# 遍历列for j in range(shape[1]):# 取平均值,int转换为更大的数据类型,避免溢出,再进行相加和除法gray[i, j] = np.uint8((int(pig[i, j, 0]) + int(pig[i, j, 1]) + int(pig[i, j, 2])) // 3)
cv.imshow('pig', pig)
cv.imshow('gray', gray)
cv.waitKey(3000)
cv.destroyAllWindows()
4.4 加权均值法
对于彩色图像的每个像素,它会按照一定的权重去乘以每个通道的像素值,并将其相加,得到最后的值就是灰度图像中对应位置的像素值。本实验中,权重的比例为: R乘以0.299,G乘以0.587,B乘以0.114,这是经过大量实验得到的一个权重比例,也是一个比较常用的权重比例。
所使用的权重之和应该等于1。这是为了确保生成的灰度图像素值保持在合理的亮度范围内,并且不会因为权重的比例不当导致整体过亮或过暗。
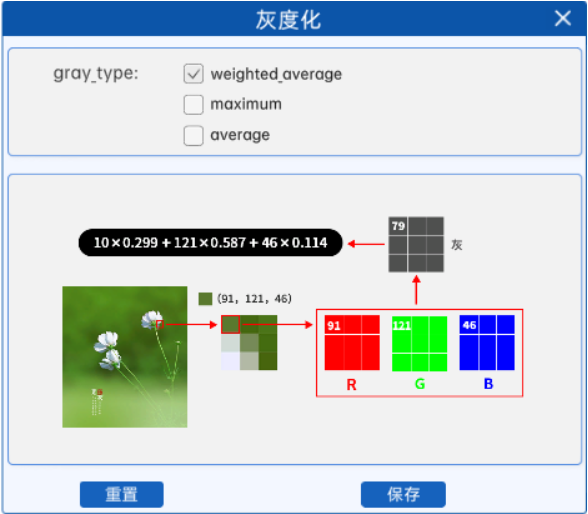
例如某图像中某像素点的像素值如上图所示,那么在使用加权平均值进行灰度化时,其计算结果就是10\*0.299+121\*0.587+46\*0.114=79。所以在灰度图中的对应位置上,该像素点的像素值就是79。
示例:
import cv2 as cv
import numpy as nppig = cv.imread('./images/pig.png')
shape = pig.shape
# 创建一个大小一致的单通道图像
gray = np.zeros((shape[0], shape[1]), dtype=np.uint8)
# 定义每个通道的权重值
wr, wg, wb = 0.299, 0.587, 0.114
# 遍历行
for i in range(shape[0]):# 遍历列for j in range(shape[1]):gray[i, j] = np.uint8(round(wb * pig[i, j, 0] + wg * pig[i, j, 1] + wr * pig[i, j, 2]))cv.imshow('pig', pig)
cv.imshow('gray', gray)
cv.waitKey(3000)
cv.destroyAllWindows()
4.5 两个极端的灰度值
在灰度图像中,“极端”的灰度值指的是亮度的两个极端:最暗和最亮的值。
- 最暗的灰度值:0。这代表完全黑色,在灰度图像中没有任何亮度。
- 最亮的灰度值:255。这代表完全白色,在灰度图像中具有最大亮度。

5. 图像二值化处理
将某张图像的所有像素改成只有两种值之一。
二值图像:一幅二值图像的二维矩阵仅由0、1两个值构成,“0”代表黑色,“1”代白色。由于每一像素(矩阵中每一元素)取值仅有0、1两种可能,所以计算机中二值图像的数据类型通常为1个二进制位。二值图像通常用于文字、线条图的扫描识别(OCR)和掩膜图像的存储。

其操作的图像也必须是灰度图。也就是说,二值化的过程,就是将一张灰度图上的像素根据某种规则修改为0和maxval(maxval表示最大值,一般为255,显示白色)两种像素值,使图像呈现黑白的效果,能够帮助我们更好地分析图像中的形状、边缘和轮廓等特征。
- 简便:降低计算量和计算需求,加快处理速度。
- 节约资源:二值图像占用空间远小于彩色图。
- 边缘检测:二值化常作为边缘检测的预处理步骤,因为简化后的图易于识别出轮廓和边界。
5.1~5.5:全局阈值法。
代码:
_,binary = cv2.threshold(img,thresh,maxval,type)-
-
img:输入图像,要进行二值化处理的灰度图。 -
thresh:设定的阈值。当像素值大于(或小于,取决于阈值类型)thresh时,该像素被赋予的值。 -
type:阈值处理的类型。 -
返回值:
-
第一个值(通常用下划线表示):计算出的阈值,若使用自适应阈值法,会根据算法自动计算出这个值。
-
第二个值(binary):二值化后的图像矩阵。与输入图像尺寸相同。
-
-
在本实验中,使用了六种不同的方式来对灰度图进行二值化。
5.1 阈值法(THRESH_BINARY)
阈值法就是通过设置一个阈值,将灰度图中的每一个像素值与该阈值进行比较,小于等于阈值的像素就被设置为0(通常代表背景),大于阈值的像素就被设置为maxval(通常代表前景)。对于我们的8位图像(0~255)来说,通常是设置为255。
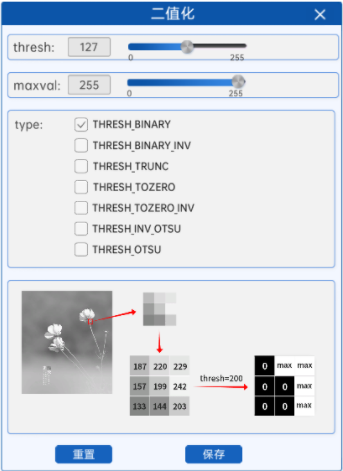

如上图所示,在灰度图中像素值较高的地方,如花瓣、花茎等地方的像素值比阈值高,那么在生成的二值化图中的对应位置的像素值就会被设置为255,也就是纯白色。
示例:
import cv2 as cv# 读为灰度图
gray = cv.imread('./images/flower1.png', cv.IMREAD_GRAYSCALE)
gray = cv.resize(gray, (480, 480))
# 二值化:阈值法
_, binary = cv.threshold(gray, 127, 255, cv.THRESH_BINARY)cv.imshow('gray', gray)
cv.imshow('binary', binary)
cv.waitKey(3000)
cv.destroyAllWindows()
5.2 反阈值法(THRESH_BINARY_INV)
顾名思义,就是与阈值法相反。反阈值法是当灰度图的像素值大于阈值时,该像素值将会变成0(黑),当灰度图的像素值小于等于阈值时,该像素值将会变成maxval。
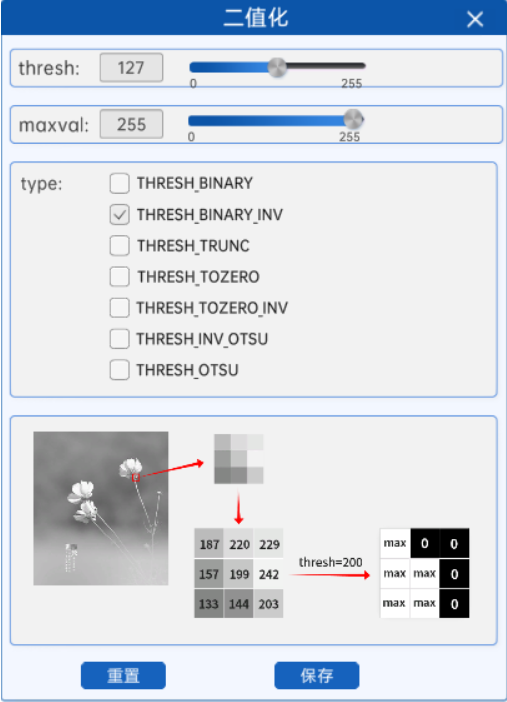

如上图所示,使用反阈值法对灰度图进行二值化时,会将灰度图中像素值大于阈值的地方置为0(也就是黑),将灰度图中像素值小于阈值的地方置为255(也就是白)。
示例:
import cv2 as cv# 读为灰度图
gray = cv.imread('./images/flower1.png', cv.IMREAD_GRAYSCALE)
gray = cv.resize(gray, (480, 480))
# 二值化:反阈值法
_, binary_inv = cv.threshold(gray, 127, 255, cv.THRESH_BINARY_INV)cv.imshow('gray', gray)
cv.imshow('binary_inv', binary_inv)
cv.waitKey(3000)
cv.destroyAllWindows()
5.3 截断阈值法(THRESH_TRUNC)
截断阈值法,指将灰度图中的所有像素与阈值进行比较,像素值大于阈值的部分将会被修改为阈值,小于等于阈值的部分不变。
换句话说,经过截断阈值法处理过的二值化图中的最大像素值就是阈值。
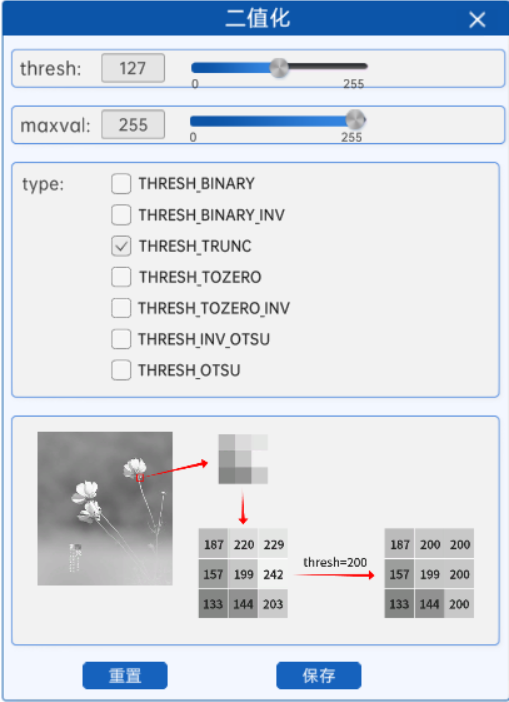
当截断阈值为255时,如上图所示,可以看到灰度图与二值化图没有任何的区别。
示例:
import cv2 as cv# 读为灰度图
gray = cv.imread('./images/flower1.png', cv.IMREAD_GRAYSCALE)
gray = cv.resize(gray, (480, 480))
# 二值化:截断阈值法,最大像素就是阈值
_, binary_trunc = cv.threshold(gray, 127, 255, cv.THRESH_TRUNC)cv.imshow('gray', gray)
cv.imshow('binary_trunc', binary_trunc)
cv.waitKey(3000)
cv.destroyAllWindows()
使用截断阈值法进行图像二值化处理时,设置的`maxval`参数实际上是不起作用的。
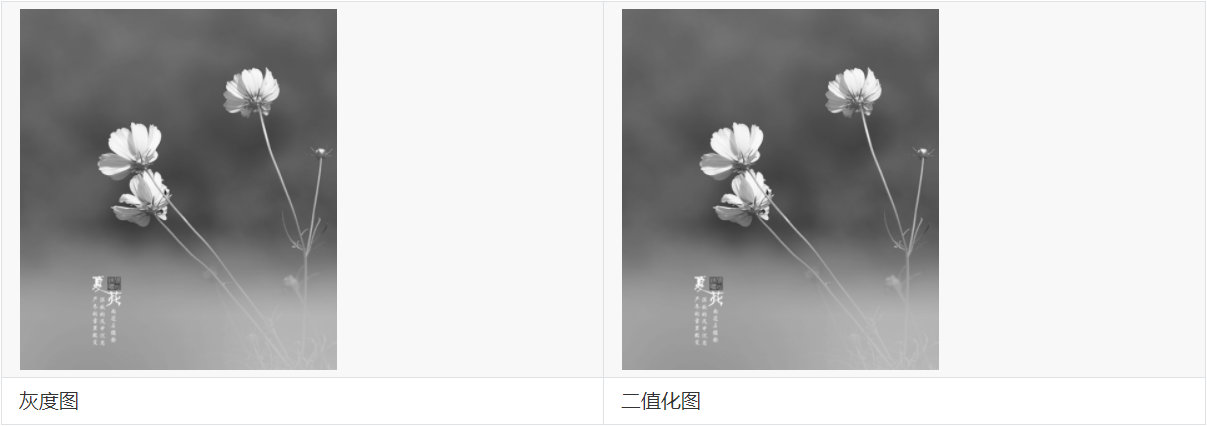
5.4 低阈值零处理(THRESH_TOZERO)
低阈值零处理,字面意思,就是像素值小于等于阈值的部分被置为0(也就是黑色),大于阈值的部分不变。

如上图所示,在灰度图中较亮的部分,其像素值比阈值大,所以在二值化后其像素值并没有发生变化。而灰度图中较暗的部分,也就是像素值较低的地方,由于像素值比阈值小,就会被置为0,对应二值化图中的黑色部分。
示例:
import cv2 as cv# 读为灰度图
gray = cv.imread('./images/flower1.png', cv.IMREAD_GRAYSCALE)
gray = cv.resize(gray, (480, 480))
# 二值化:低阈值零处理,小于阈值设为零大于部分不改变
_, binary_tozero = cv.threshold(gray, 127, 255, cv.THRESH_TOZERO)cv.imshow('gray', gray)
cv.imshow('binary_tozero', binary_tozero)
cv.waitKey(3000)
cv.destroyAllWindows()
5.5 超阈值零处理(THRESH_TOZERO_INV)
超阈值零处理就是将灰度图中的每个像素与阈值进行比较,像素值大于阈值的部分置为0(也就是黑色),像素值小于等于阈值的部分不变。


如上图所示,在灰度图中较亮的部分,其像素值比阈值大,所以在二值化后其像素值会被置为0(也就是黑色),对应二值化图中的黑色部分。而灰度图中较暗的部分,也就是像素值较低的地方,由于像素值比阈值小,将不会发生改变。
以上介绍的二值化方法都需要手动设置阈值,但是在不同的环境下,摄像头拍摄的图像可能存在差异,导致手动设置的阈值并不适用于所有图像,这可能会导致二值化效果不理想。
因此,我们需要一种能自动计算每张图片阈值的二值化方法,能够根据每张图像的特点自动计算出适合该图像的二值化阈值,从而达到更好的二值化效果。这种二值化方法可以在不同环境下适用,提高图像处理的准确性和鲁棒性。
import cv2 as cv# 读为灰度图
gray = cv.imread('./images/flower1.png', cv.IMREAD_GRAYSCALE)
gray = cv.resize(gray, (480, 480))
# 二值化:超阈值零处理,与低阈值零处理相反
_, binary_tozero_inv = cv.threshold(gray, 127, 255, cv.THRESH_TOZERO_INV)cv.imshow('gray', gray)
cv.imshow('binary_tozero_inv', binary_tozero_inv)
cv.waitKey(3000)
cv.destroyAllWindows()
5.6 OTSU阈值法
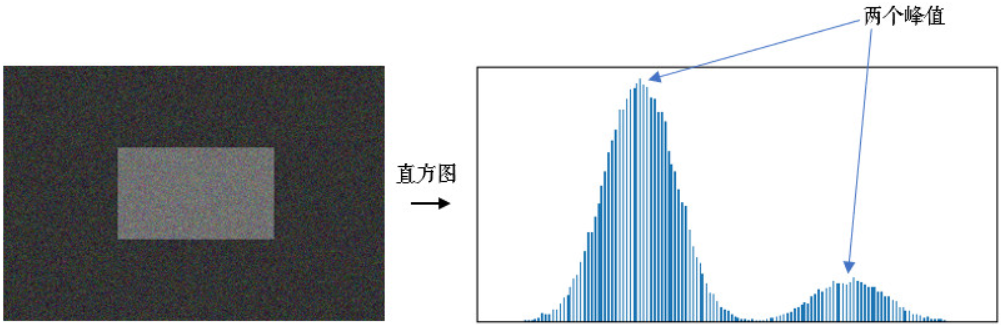
在介绍OTSU阈值法之前,我们首先要了解一下双峰图片的概念。
双峰图片就是指灰度图的直方图上有两个峰值,直方图就是对灰度图中每个像素值的点的个数的统计图,如下图所示。
-
灰度图直方图的基础概念
-
灰度级:
-
在灰度图像中,每个像素的值代表其亮度,通常范围是 0 到 255(对于 8 位灰度图像)。
-
0 表示黑色,255 表示白色,中间的值表示不同程度的灰色。
-
-
直方图定义:
-
直方图是一个柱状图,其中 x 轴表示灰度级(从 0 到 255),y 轴表示对应灰度级在图像中出现的次数(频率)。
-
每个柱子的高度代表该灰度级在图像中出现的像素数量。
-
OTSU算法是通过一个值将这张图分前景色和背景色(也就是灰度图中小于这个值的是一类,大于这个值的是一类。),通过统计学方法(最大类间方差)来验证该值的合理性,当根据该值进行分割时,使用最大类间方差计算得到的值最大时,该值就是二值化算法中所需要的阈值。通常该值是从灰度图中的最小值加1开始进行迭代计算,直到灰度图中的最大像素值减1,然后把得到的最大类间方差值进行比较,来得到二值化的阈值。以下是一些符号规定:

下面举个例子,有一张大小为4×4的图片,假设阈值T为1,那么:

也就是这张图片根据阈值1分为了前景(像素为2的部分)和背景(像素为0)的部分,并且计算出了OTSU算法所需要的各个数据,根据上面的数据,我们给出计算类间方差的公式:
![]()
g就是前景与背景两类之间的方差,这个值越大,说明前景和背景的差别就越大,效果就越好。OTSU算法就是在灰度图的像素值范围内遍历阈值T,使得g最大,基本上双峰图片的阈值T在两峰之间的谷底。
通过OTSU算法得到阈值之后,就可以结合上面的方法根据该阈值进行二值化,在本实验中有THRESH_OTSU和THRESH_INV_OTSU两种方法,就是在计算出阈值后结合了阈值法和反阈值法。
注意:使用OTSU算法计算阈值时,组件中的thresh参数将不再有任何作用。
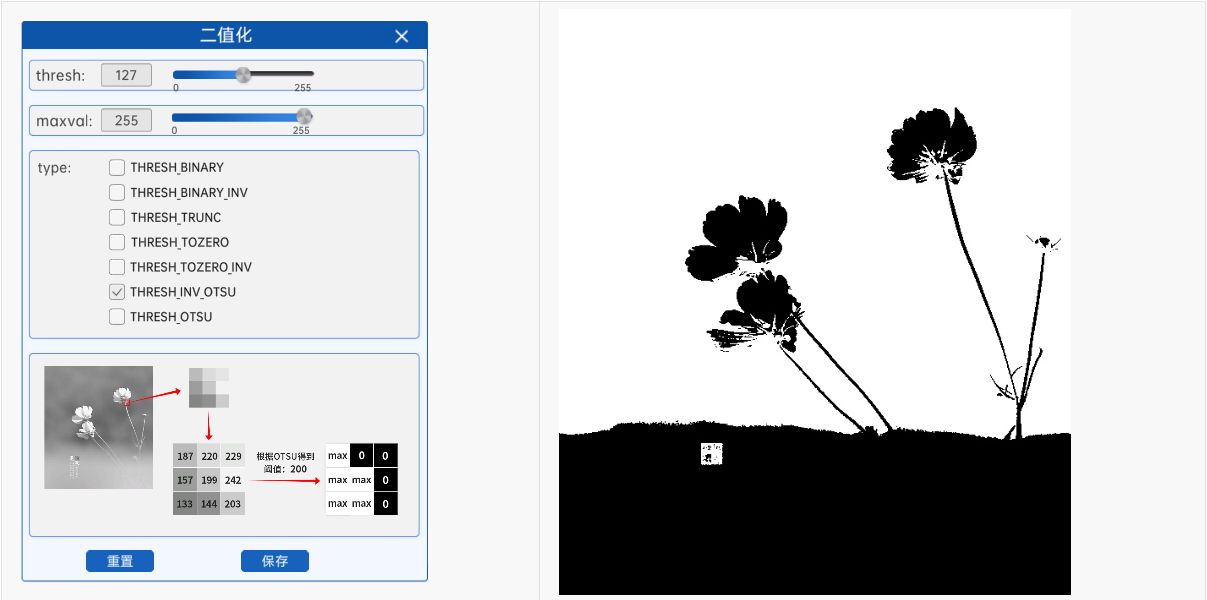
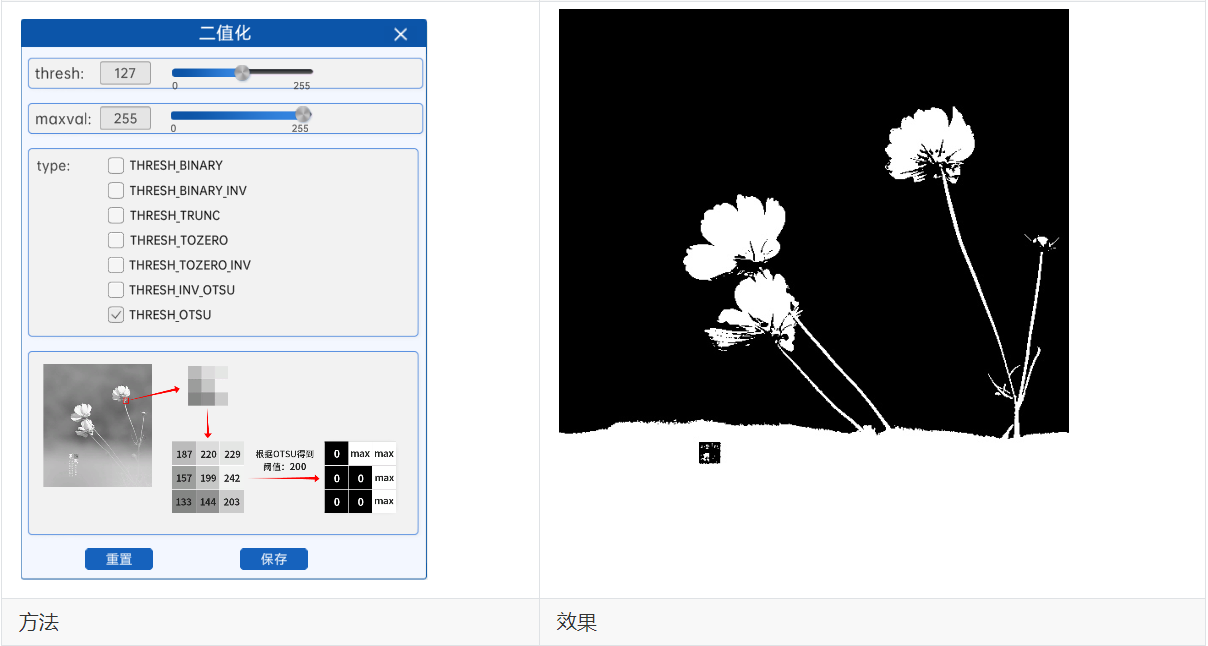
示例:
import cv2 as cvflower = cv.imread('./images/flower1.png', cv.IMREAD_GRAYSCALE)
# OTSU默认结合cv.THRESH_BINARY
thresh, img = cv.threshold(flower, 127, 255, cv.THRESH_BINARY + cv.THRESH_OTSU)
# OTSU还可以结合反阈值法使用
thresh, img_1 = cv.threshold(flower, 127, 255, cv.THRESH_BINARY_INV + cv.THRESH_OTSU)
# print(thresh)
cv.imshow('flower', flower)
cv.imshow('img', img)
cv.imshow('img_1', img_1)
cv.waitKey(0)
cv.destroyAllWindows()
5.7 自适应二值化
自适应二值化方法会对图像中的所有像素点计算其各自的阈值,这样能够更好的保留图片里的一些信息。自适应二值化组件内容如下图所示:
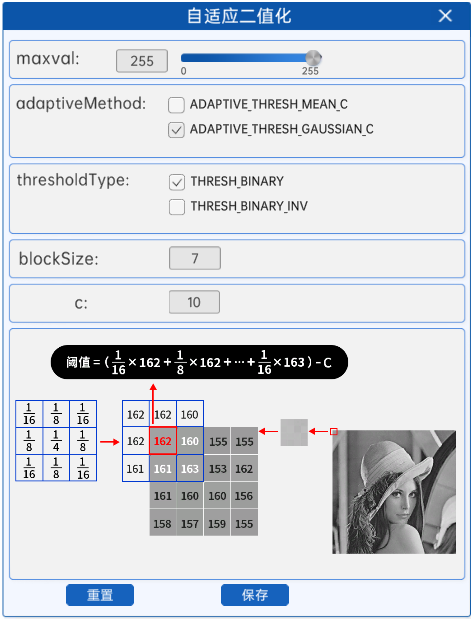
参考代码:
cv2.adaptiveThreshold(image_np_gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 7, 10) 其中各个参数的含义如下:
maxval:最大阈值,一般为255;
adaptiveMethod:小区域阈值的计算方式;
ADAPTIVE_THRESH_MEAN_C:小区域内取均值;
ADAPTIVE_THRESH_GAUSSIAN_C:小区域内加权求和,权重是个高斯核;
thresholdType:二值化方法,只能使用THRESH_BINARY、THRESH_BINARY_INV,也就是阈值法和反阈值法;
blockSize:选取的小区域的面积,如7就是7*7的小块;
c:最终阈值等于小区域计算出的阈值再减去此值。
下面介绍一下这两种方法。
5.7.1 取均值
比如一张图片的左上角像素值如下图所示:
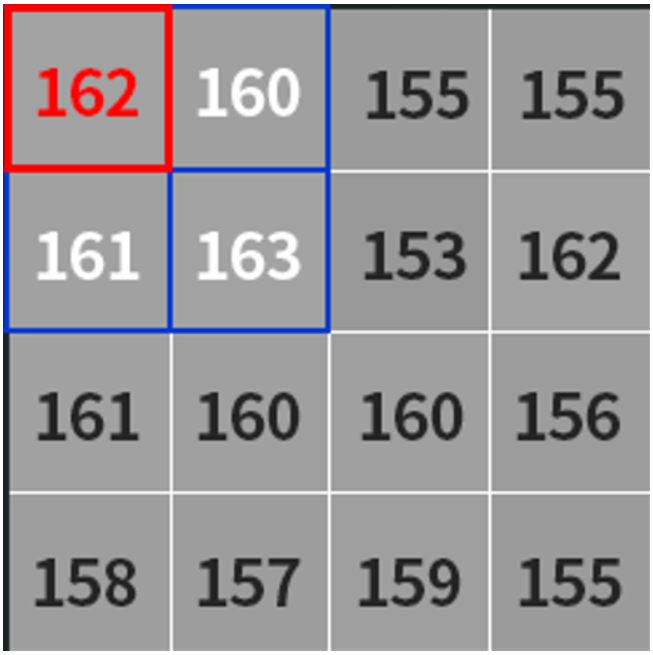
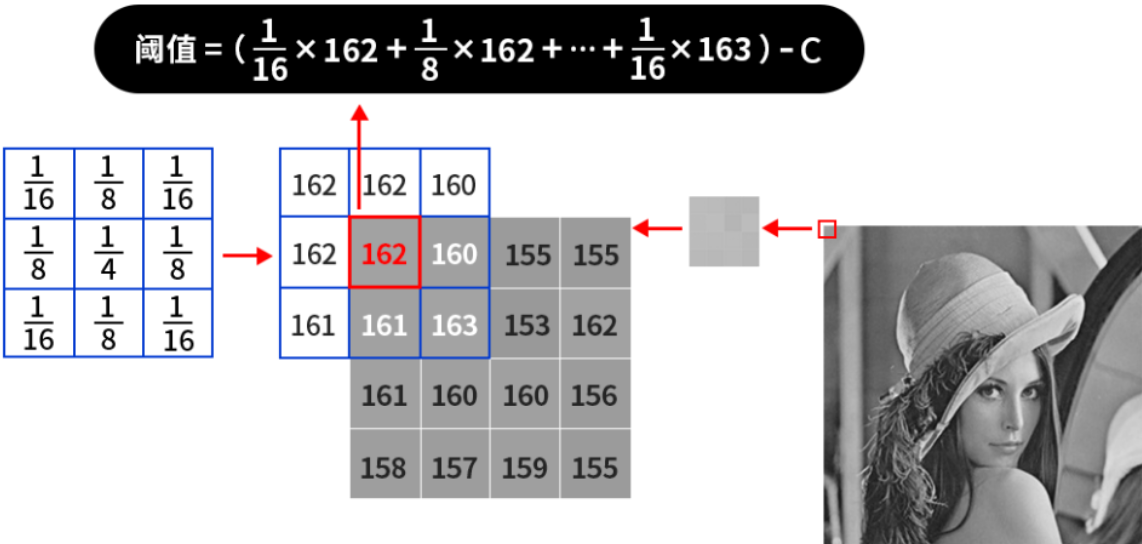
假如我们使用的小区域是3\*3的,那么就会从图片的左上角开始(也就是像素值为162的地方)计算其邻域内的平均值,如果处于边缘地区就会对边界进行填充,填充值就是边界的像素点,如下图所示:
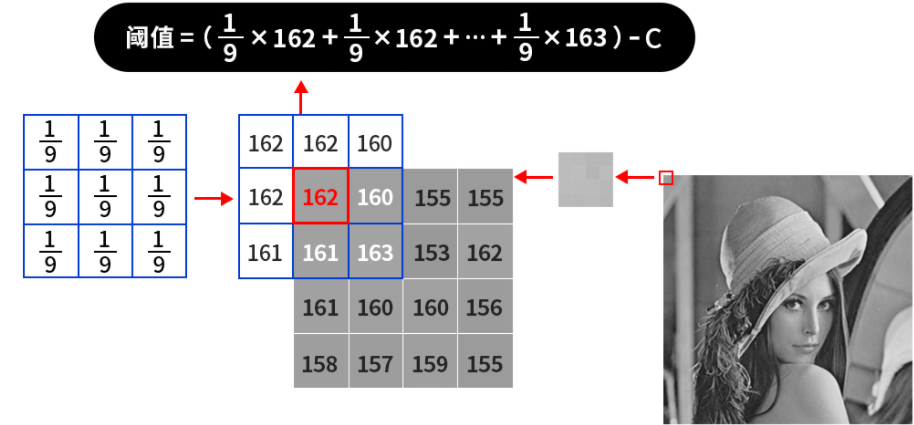
那么对于左上角像素值为162的这个点,161(也就是上图中括号内的计算结果,结果会进行取整)就是根据平均值计算出来的阈值,接着减去一个固定值C,得到的结果就是左上角这个点的二值化阈值了,接着根据选取的是阈值法还是反阈值法进行二值化操作。紧接着,向右滑动计算每个点的邻域内的平均值,直到计算出右下角的点的阈值为止。我们所用到的不断滑动的小区域被称之为核,比如3*3的小区域叫做3*3的核,并且核的大小都是奇数个,也就是3*3、5*5、7*7等。
示例:
import cv2 as cvflower = cv.imread('./images/flower1.png', cv.IMREAD_GRAYSCALE)
# 平均值法
img = cv.adaptiveThreshold(flower, 255, cv.ADAPTIVE_THRESH_MEAN_C, cv.THRESH_BINARY, 7, 10)cv.imshow('flower', flower)
cv.imshow('img', img)
cv.waitKey(0)
cv.destroyAllWindows()
5.7.2 加权求和
对小区域内的像素进行加权求和得到新的阈值,其权重值来自于高斯分布,高斯分布,通过概率密度函数来定义高斯分布,一维高斯概率分布函数为:
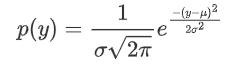
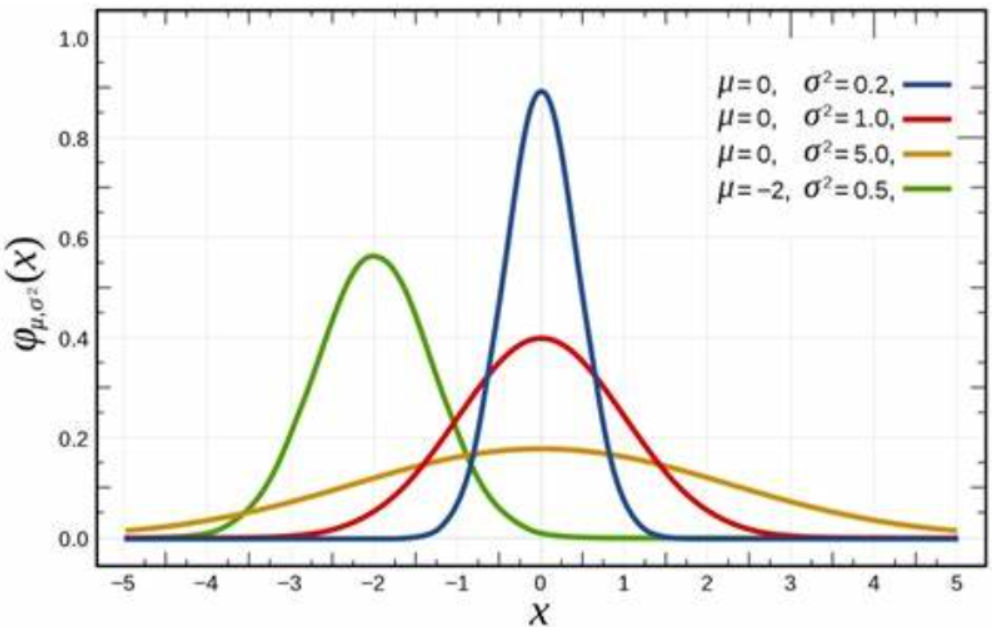
通过改变函数中和的值,我们可以得到如下图像,其中均值为,标准差为。
此时我们拓展到二维图像,一般情况下我们使x轴和y轴的相等并且,此时我们可以得到二维高斯函数的表达式为:
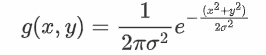
高斯概率函数是相对于二维坐标产生的,其中(x,y)为点坐标,要得到一个高斯滤波器模板,应先对高斯函数进行离散化,将得到的值作为模板的系数。例如:要产生一个3*3的高斯权重核,以核的中心位置为坐标原点进行取样,其周围的坐标如下图所示(x轴水平向右,y轴竖直向上)
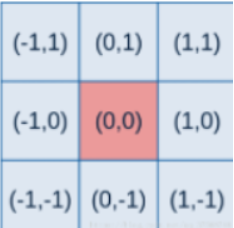
将坐标带入上面的公式中,即可得到一个高斯权重核。
而在opencv里,当kernel(小区域)的尺寸为1、3、5、7并且用户没有设置sigma的时候(sigma \<= 0),核值就会取固定的系数,这是一种默认的值是高斯函数的近似。
| kernel尺寸 | 核值 |
|---|---|
| 1 | [1] |
| 3 | [0.25, 0.5, 0.25] |
| 5 | [0.0625, 0.25, 0.375, 0.25, 0.0625] |
| 7 | [0.03125, 0.109375, 0.21875, 0.28125, 0.21875, 0.109375, 0.03125] |
比如kernel的尺寸为3\*3时,使用

进行矩阵的乘法,就会得到如下的权重值,其他的类似。

通过这个高斯核,即可对图片中的每个像素去计算其阈值,并将该阈值减去固定值得到最终阈值,然后根据二值化规则进行二值化。
而当kernels尺寸超过7的时候,如果sigma设置合法(用户设置了sigma),则按照高斯公式计算.当sigma不合法(用户没有设置sigma),则按照如下公式计算sigma的值:
![]()
某像素点的阈值计算过程如下图所示:
首先还是对边界进行填充,然后计算原图中的左上角(也就是162像素值的位置)的二值化阈值,其计算过程如上图所示,再然后根据选择的二值化方法对左上角的像素点进行二值化,之后核向右继续计算第二个像素点的阈值,第三个像素点的阈值…直到右下角(也就是155像素值的位置)为止。
当核的大小不同时,仅仅是核的参数会发生变化,计算过程与此是一样的。
示例:
import cv2 as cvflower = cv.imread('./images/flower1.png', cv.IMREAD_GRAYSCALE)
# 平均值法
img = cv.adaptiveThreshold(flower, 255, cv.ADAPTIVE_THRESH_MEAN_C, cv.THRESH_BINARY, 7, 10)
# 加权均值法,高斯核
img2 = cv.adaptiveThreshold(flower, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, 7, 10)cv.imshow('flower', flower)
cv.imshow('img', img)
cv.imshow('img2', img2)
cv.waitKey(0)
cv.destroyAllWindows()
cv2.adaptiveThreshold参数解释:
1. image_np_gray: 输入图像,这里必须是灰度图像(单通道)。
2. 255: 输出图像的最大值。在二值化后,超过自适应阈值的像素会被设置为该最大值,通常为255表示白色;未超过阈值的像素将被设置为0,表示黑色。
3. cv2.ADAPTIVE_THRESH_GAUSSIAN_C: 自适应阈值类型。在这个例子中,使用的是高斯加权的累计分布函数(CDF),并添加一个常数 C 来计算阈值。另一种可选类型是 cv2.ADAPTIVE_THRESH_MEAN_C,它使用邻域内的平均值加上常数 C 计算阈值。
4. cv2.THRESH_BINARY: 输出图像的类型。这意味着输出图像将会是一个二值图像(binary image),其中每个像素要么是0要么是最大值(在这里是255)。另外还有其他选项如 cv2.THRESH_BINARY_INV 会得到相反的二值图像。
5. blockSize 参数,表示计算每个像素阈值时所考虑的7x7邻域大小(正方形区域的宽度和高度),其值必须是奇数。
6. C 参数,即上面提到的常数值,在计算自适应阈值时与平均值或高斯加权值相加。正值增加阈值,负值降低阈值,具体效果取决于应用场景。
6. 图像掩膜
6.1 制作掩膜
掩膜(Mask)是一种在图像处理中常见的操作,它用于选择性地遮挡图像的某些部分,以实现特定任务的目标。掩膜通常是一个二值化图像,并且与原图像的大小相同,其中目标区域被设置为1(或白色),而其他区域被设置为0(或黑色),并且目标区域可以根据HSV的颜色范围进行修改,如下图就是制作红色掩膜的过程:
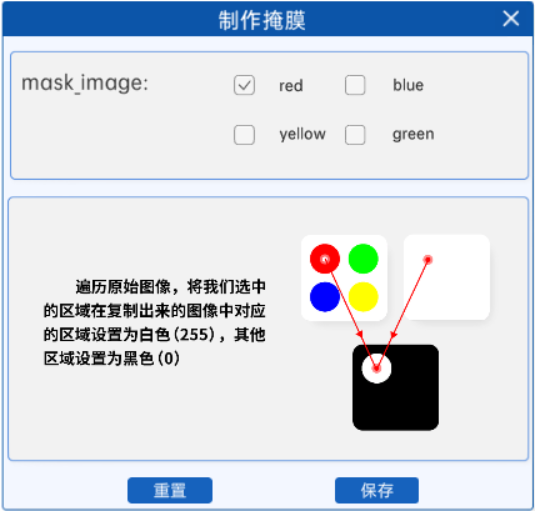
通过这个掩膜,我们就可以对掩膜中的白色区域所对应的原图中的区域进行处理与操作。
示例:
import cv2 as cv
import numpy as np# 读取图像
img = cv.imread('./images/demo.png')
# 调整图像大小
img = cv.resize(img, (480, 480))
# 转HSV颜色空间
img_hsv = cv.cvtColor(img, cv.COLOR_BGR2HSV)
# maxk=cv.inRange(hsv图像,(hmin,smin,vmin),(hmax,smax,vmax)),比较颜色范围,生成二值图像
# 范围内:白色,不在范围内:将像素值设为0
# 创建黄色掩膜
color_low = np.array([26, 43, 46])
color_high = np.array([34, 255, 255])
# 创建掩膜
mask = cv.inRange(img_hsv, color_low, color_high)
cv.imshow('img', img)
cv.imshow('hsv', img_hsv)
cv.imshow('mask', mask)
cv.waitKey(0)
cv.destroyAllWindows()
6.2 与运算
我们在高中时学过逻辑运算中的“与”运算,其规则是当两个命题都是真时,其结果才为真。而在图像处理中,“与”运算被用来对图像的像素值进行操作。具体来说,就是将两个图像中所有的对应像素值一一进行“与”运算,从而得到新的图像。从上面的图片我们可以看出,掩膜中有很多地方是黑色的,其像素值为0,那么在与原图像进行“与”运算的时候,得到的新图像的对应位置也是黑色的,如下图所示:
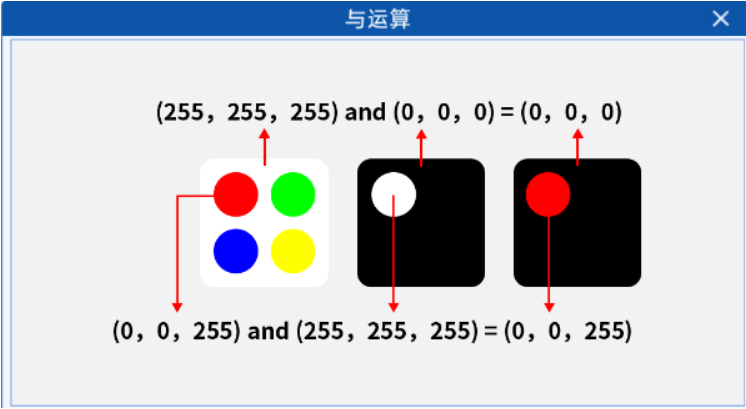
通过掩膜与原图的与运算,我们就可以提取出图像中被掩膜覆盖的区域(扣图)。
代码:
cv2.bitwise_and(src1,src2[,mask])-
src1:第一个输入数组。通常是输入的原始图像。 -
src2:第二个输入数组。它可以是另一个图像、一个常数值或者与src1相同的图像。-
当应用掩膜时,这个参数经常就是
src1本身;即对同一个图像进行操作。 -
如果对两个不同的图像执行按位与操作(例如,将两张图片的某些部分组合在一起),可以分别将它们作为
src1和src2输入到cv2.bitwise_and()函数中,创建复杂的图像效果或进行图像合成。
-
-
mask:掩膜(可选)。输入数组元素只有在该掩膜非零时才被处理。是一个8位单通道的数组,尺寸必须与src1和src2相同。 -
返回值:输出数组,应用掩膜后的图像,与输入数组大小和类型相同。
示例:
import cv2 as cv
import numpy as np# 读取图像
img = cv.imread('./images/demo.png')
# 调整图像大小
img = cv.resize(img, (480, 480))
# 转HSV颜色空间
img_hsv = cv.cvtColor(img, cv.COLOR_BGR2HSV)
# maxk=cv.inRange(hsv图像,(hmin,smin,vmin),(hmax,smax,vmax)),比较颜色范围,生成二值图像
# 范围内:白色,不在范围内:将像素值设为0
# 创建黄色掩膜
color_low = np.array([26, 43, 46])
color_high = np.array([34, 255, 255])
# 创建掩膜
mask = cv.inRange(img_hsv, color_low, color_high)
# 与运算:cv2.bitwise_and(src1,src2[,mask])
yellow_img = cv.bitwise_and(img, img, mask=mask)
cv.imshow('img', img)
cv.imshow('hsv', img_hsv)
cv.imshow('mask', mask)
cv.imshow('yellow_img', yellow_img)
cv.waitKey(3000)
cv.destroyAllWindows()
6.3 颜色替换
前一个实验中,我们已经能够识别到图像中的某一种颜色,那么我们就可以对识别到的颜色进行一个操作,比如将其替换成别的颜色,其原理就是在得到原图的掩膜之后,对掩膜中的白色区域所对应的原图中的区域进行一个像素值的修改即可。
由于掩膜与原图的大小相同,并且像素位置一一对应,那么我们就可以得到掩膜中白色(也就是像素值为255)区域的坐标,并将其带入到原图像中,即可得到原图中的红色区域的坐标,然后就可以修改像素值了,这样就完成了颜色的替换,如下图所示:
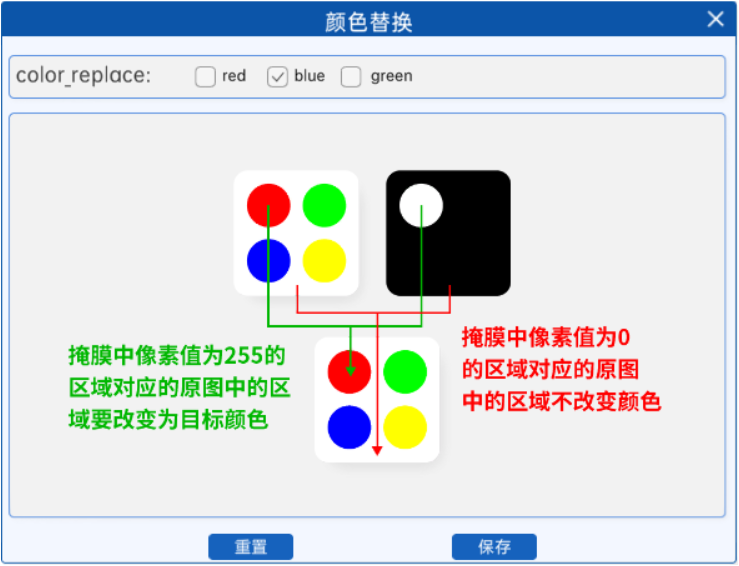
示例:
import cv2 as cv
import numpy as np# 读取图像
img = cv.imread('./images/demo.png')
# 调整图像大小
img = cv.resize(img, (480, 480))
# 转HSV颜色空间
img_hsv = cv.cvtColor(img, cv.COLOR_BGR2HSV)
# maxk=cv.inRange(hsv图像,(hmin,smin,vmin),(hmax,smax,vmax)),比较颜色范围,生成二值图像
# 范围内:白色,不在范围内:将像素值设为0
# 创建黄色掩膜
color_low = np.array([0, 43, 46])
color_high = np.array([10, 255, 255])
# 创建掩膜
mask = cv.inRange(img_hsv, color_low, color_high)
# 颜色替换
img[mask == 255] = (0, 255, 0)
cv.imshow('img', img)
cv.waitKey(3000)
cv.destroyAllWindows()
# img[...] = (0, 255, 0)
相关文章:
OpenCV 从入门到精通(day_02)
1. 边缘填充 为什么要填充边缘呢?我们以下图为例: 可以看到,左图在逆时针旋转45度之后原图的四个顶点在右图中已经看不到了,同时,右图的四个顶点区域其实是什么都没有的,因此我们需要对空出来的区域进行一个…...

VTK的两种显示刷新方式
在类中先声明vtk的显示对象 vtkRenderer out_render; vtkVertexGlyphFilter glyphFilter; vtkPolyDataMapper mapper; // 新建制图器 vtkActor actor; // 新建角色 然后在init中先初始化一下: out_rend…...
Ceph异地数据同步之-RBD异地同步复制(上)
#作者:闫乾苓 文章目录 前言基于快照的模式(Snapshot-based Mode)工作原理单向同步配置步骤单向同步复制测试双向同步配置步骤双向同步复制测试 前言 Ceph的RBD(RADOS Block Device)支持在两个Ceph集群之间进行异步镜…...

【C++】STL库_stack_queue 的模拟实现
栈(Stack)、队列(Queue)是C STL中的经典容器适配器 容器适配器特性 不是独立容器,依赖底层容器(deque/vector/list)通过限制基础容器接口实现特定访问模式不支持迭代器操作(无法遍历…...

前端对接下载文件接口、对接dart app
嵌套在dart app里面的前端项目 1.前端调下载接口 ->后端返回 application/pdf格式的文件 ->前端将pdf处理为blob ->blob转base64 ->调用dart app的 sdk saveFile ->保存成功 async download() {try {// 调用封装的 downloadEContract 方法获取 Blob 数据const …...
一周学会Pandas2 Python数据处理与分析-编写Pandas2 HelloWord项目
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili 我们首先准备一个excel文件,用来演示pandas操作数据集(数据的集合)。excel文件属于数据集的一种…...
【易订货-注册/登录安全分析报告】
前言 由于网站注册入口容易被机器执行自动化程序攻击,存在如下风险: 暴力破解密码,造成用户信息泄露,不符合国家等级保护的要求。短信盗刷带来的拒绝服务风险 ,造成用户无法登陆、注册,大量收到垃圾短信的…...

AI赋能股票:流通股本与总股本:定义、区别及投资意义解析
一、基本定义 总股本(Total Shares Outstanding) 指一家公司已发行的所有股票数量,包括流通股和非流通股(如限售股、员工持股计划股票等)。总股本反映公司的整体股权结构,是计算市值(总股本 股…...
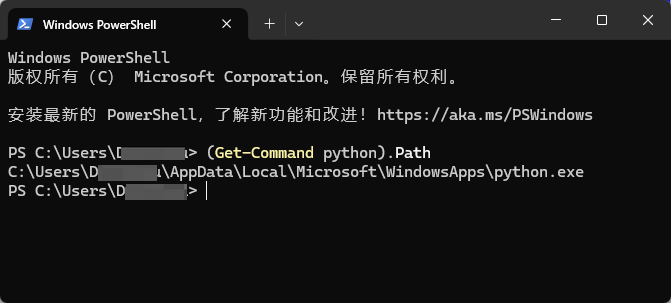
如何在Windows上找到Python安装路径?两种方法快速定位
原文:如何在Windows上找到Python安装路径?两种方法快速定位 | w3cschool笔记 在 Windows 系统上找到 Python 的安装路径对于设置环境变量或排查问题非常重要。本文将介绍两种方法,帮助你找到 Python 的安装路径:一种是通过命令提…...

第五课:高清修复和放大算法
文章目录 Part.01 高清修复(Hi-Res Fix)Part.02 SD放大(SD Upscale)Part.03 附加功能放大Part.01 高清修复(Hi-Res Fix) 文生图中的高清修复/高分辨率修复/超分辨率修复先低分辨率抽卡,再高分辨率修复。不能突破显存限制放大重绘幅度安全范围是0.3-0.5,如果想让AI更有想象力0…...

lvgl避坑记录
一、log调试 #if LV_USE_LOG && LV_LOG_LEVEL > LV_LOG_LEVEL_INFOswitch(src_type) {case LV_IMG_SRC_FILE:LV_LOG_TRACE("lv_img_set_src: LV_IMG_SRC_FILE type found");break;case LV_IMG_SRC_VARIABLE:LV_LOG_TRACE("lv_img_set_src: LV_IMG_S…...
简介)
Java 8 的流(Stream API)简介
Java 8 引入的 Stream API 是一个强大的工具,用于处理集合(如 List、Set)中的元素。它支持各种操作,包括过滤、排序、映射等,并且能够以声明式的方式表达复杂的查询操作。流操作可以是中间操作(返回流以便进…...

液态神经网络技术指南
一、引言 1.从传统神经网络到液态神经网络 神经网络作为深度学习的核心工具,在图像识别、自然语言处理、推荐系统等领域取得了巨大成功。尤其是卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LS…...
element-plus中,表单校验的使用
目录 一.案例1:给下面的表单添加校验 1.目的要求 2.步骤 ①给需要校验的el-form-item项,添加prop属性 ②定义一个表单校验对象,里面存放了每一个prop的检验规则 ③给el-form组件,添加:rules属性 ④给el-form组件࿰…...

PyTorch复现线性模型
【前言】 本专题为PyTorch专栏。从本专题开始,我将通过使用PyTorch编写基础神经网络,带领大家学习PyTorch。并顺便带领大家复习以下深度学习的知识。希望大家通过本专栏学习,更进一步了解人更智能这个领域。 材料来源:2.线性模型_…...

Kafka+Zookeeper从docker部署到spring boot使用完整教程
文章目录 一、Kafka1.Kafka核心介绍:核心架构核心特性典型应用 2.Kafka对 ZooKeeper 的依赖:3.去 ZooKeeper 的演进之路:注:(本文采用ZooKeeper3.8 Kafka2.8.1) 二、Zookeeper1.核心架构与特性2.典型…...
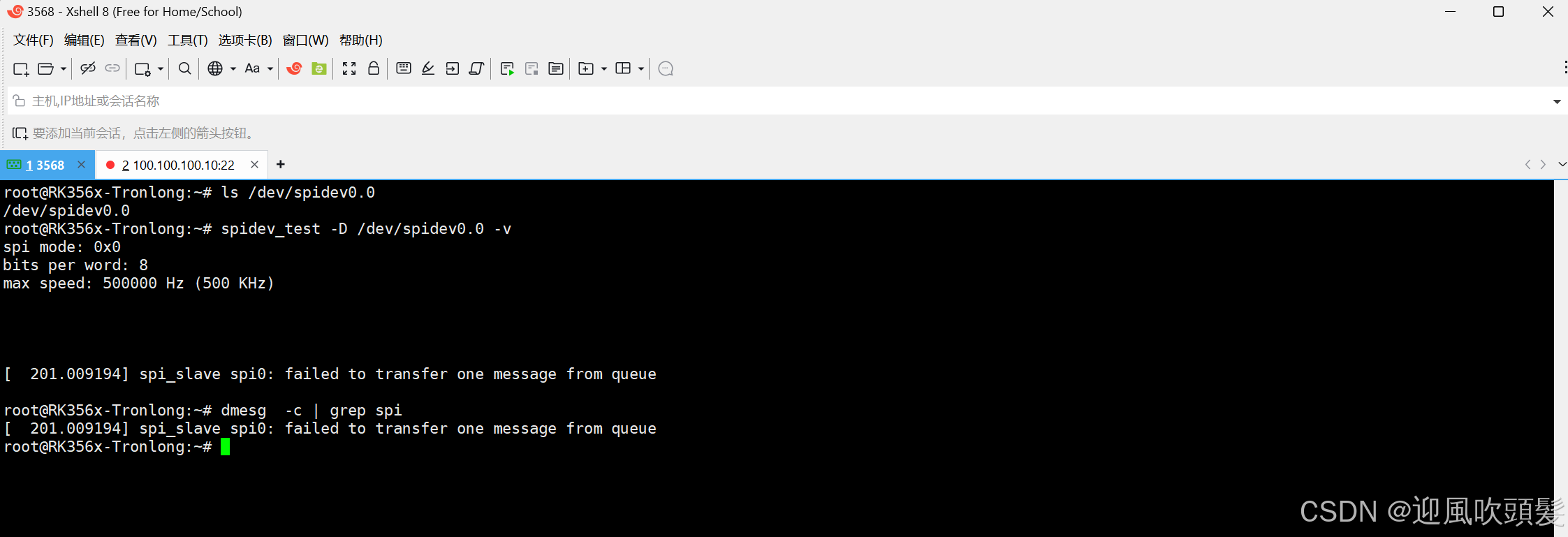
RK3568驱动 SPI主/从 配置
一、SPI 控制器基础配置(先说主的配置,后面说从的配置) RK3568 集成高性能 SPI 控制器,支持主从双模式,最高传输速率 50MHz。设备树配置文件路径通常为K3568/rk356x_linux_release_v1.3.1_20221120/kernel/arch/arm64/boot/dts/rockchip。 …...

【全队项目】智能学术海报生成系统PosterGenius--风格个性化调整
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏🏀大模型实战训练营 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 1.前言 PosterGenius致力于开发一套依托DeepSeek…...
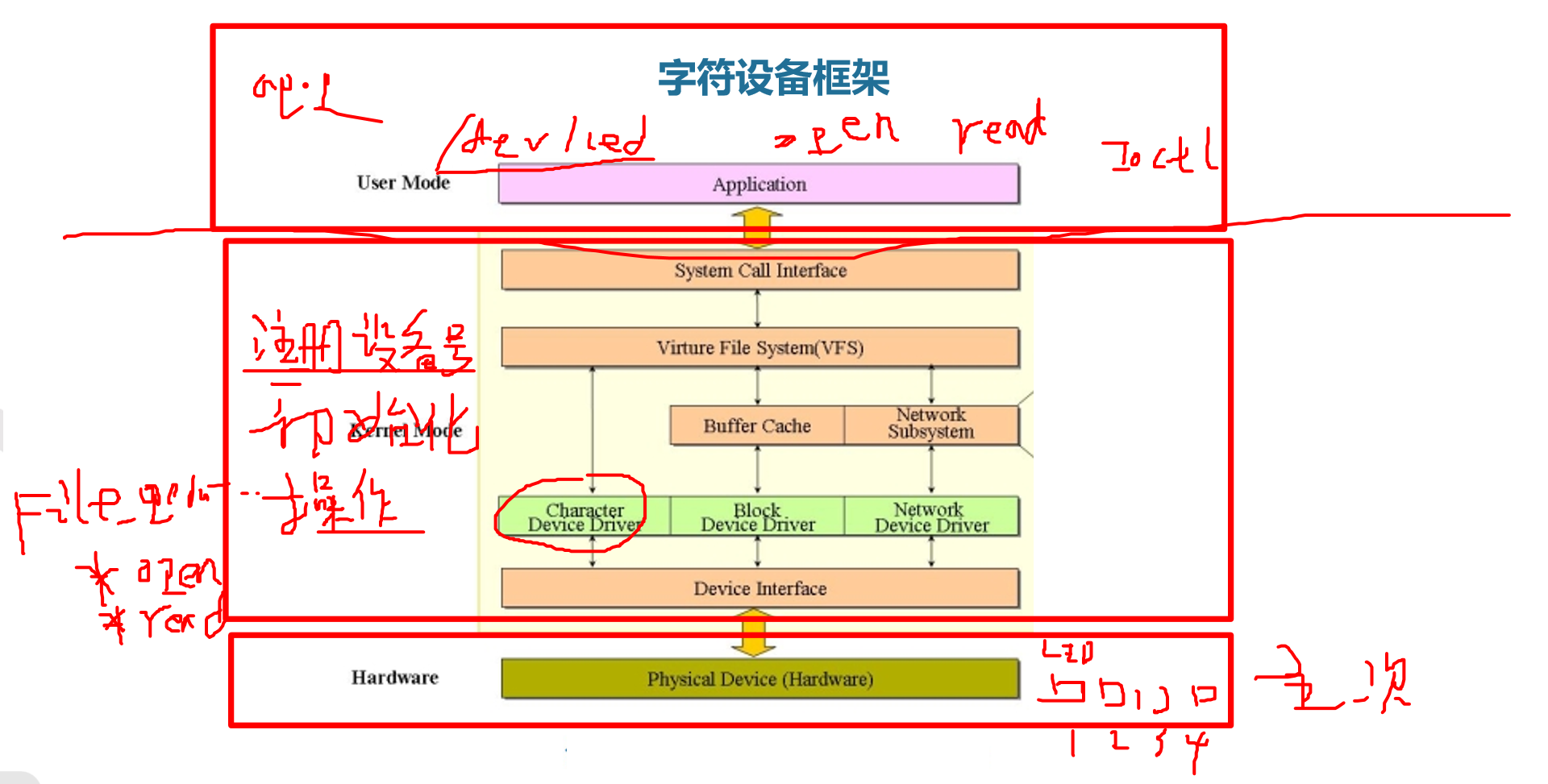
【系统移植】(六)第三方驱动移植
【系统移植】(六)第三方驱动移植 文章目录 【系统移植】(六)第三方驱动移植1.编译驱动进内核方法一:编译makefile方法二:编译kconfig方法三:编译成模块 2.字符设备框架 编译驱动进内核a. 选择驱…...
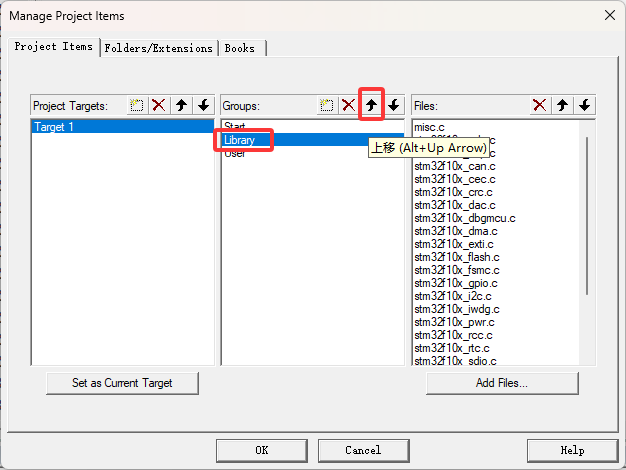
STM32实现一个简单电灯
新建工程的步骤 建立工程文件夹,Keil中新建工程,选择型号工程文件夹里建立Start、Library、User等文件夹,复制固件库里面的文件到工程文件夹工程里对应建立Start、Library、User等同名称的分组,然后将文件夹内的文件添加到工程分组…...

【shiro】shiro反序列化漏洞综合利用工具v2.2(下载、安装、使用)
1 工具下载 shiro反序列化漏洞综合利用工具v2.2下载: 链接:https://pan.baidu.com/s/1kvQEMrMP-PZ4K1eGwAP0_Q?pwdzbgp 提取码:zbgp其他工具下载: 除了该工具之外,github上还有其他大佬贡献的各种工具,有…...
vue进度条组件
<div class"global-mask" v-if"isProgress"><div class"contentBox"><div class"progresstitie">数据加载中请稍后</div><el-progress class"progressStyle" :color"customColor" tex…...
:矩阵加减法与SIMD集成)
【C++游戏引擎开发】《线性代数》(2):矩阵加减法与SIMD集成
一、矩阵加减法数学原理 1.1 定义 逐元素操作:运算仅针对相同位置的元素,不涉及矩阵乘法或行列变换。交换律与结合律: 加法满足交换律(A + B = B + A)和结合律( ( A + B ) + C = A + ( B + C ) )。 减法不满足交换律(A − B ≠ B − A)。1.2 公式 C i j = …...

UE5Actor模块源码深度剖析:从核心架构到实践应用
UE5 Actor模块源码深度剖析:从核心架构到实践应用 a. UE5 Actor模块架构概述 在UE5引擎中,Actor扮演着至关重要的角色,它是整个游戏世界中各类可交互对象的基础抽象。从本质上来说,所有能够被放置到关卡中的对象都属于Actor的范畴,像摄像机、静态网格体以及玩家起始位置…...

【3.软件工程】3.6 W开发模型
W模型全解析:开发与测试并行的质量保障框架 ⚡ 一、W模型核心流程图 #mermaid-svg-YfU8WQvqa6iDUKz3 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-YfU8WQvqa6iDUKz3 .error-icon{fill:#552222;}#merm…...

基于大模型的主动脉瓣病变预测及治疗方案研究报告
目录 一、引言 1.1 研究背景 1.2 研究目的 1.3 研究意义 二、大模型预测主动脉瓣病变原理 2.1 大模型介绍 2.2 数据收集与处理 2.3 模型训练与优化 三、术前预测与评估 3.1 主动脉瓣病变类型及程度预测 3.2 患者整体状况评估 3.3 手术风险预测 四、术中应用与监测…...

CSRF跨站请求伪造——入门篇【DVWA靶场low级别writeup】
CSRF跨站请求伪造——入门篇 0. 前言1. 什么是CSRF2. 一次完整的CSRF攻击 0. 前言 本文将带你实现一次完整的CSRF攻击,内容较为基础。需要你掌握的基础知识有: 了解cookie;已经安装了DVWA的靶场环境(本地的或云的)&am…...
)
拦截、限流,针对场景详细信息(一)
以下是一个基于Java Spring Boot Redis 的完整限流实现案例,针对同一接口前缀(如 /one/ )的IP访问频率控制: 场景:用户不用登录即可访问接口,网站会有被攻击的风险 URL:one/two/three one/…...

Qt基础:主界面窗口类QMainWindow
QMainWindow 1. QMainWindow1.1 菜单栏添加菜单项菜单项信号槽 1.2 工具栏添加工具按钮工具栏的属性设置 1.3 状态栏1.4 停靠窗口(Dock widget) 1. QMainWindow QMainWindow是标准基础窗口中结构最复杂的窗口, 其组成如下: 提供了菜单栏, 工具栏, 状态…...

第十四届蓝桥杯大赛软件赛省赛Python 研究生组:4.互质数的个数
题目1 互质数的个数 给定 a,b,求 1≤x<ab 中有多少个 x 与 ab 互质。 由于答案可能很大,你只需要输出答案对 998244353 取模的结果。 输入格式 输入一行包含两个整数分别表示 a,b,用一个空格分隔。 输出格式 输出一行包含一个整数表…...