文心一言与 DeepSeek 的竞争分析:技术先发优势为何未能转化为市场主导地位?
目录
引言
第一部分:技术路径的差异——算法创新与工程优化的博弈
1.1 文心一言的技术积累与局限性
1.1.1 早期技术优势
1.1.2 技术瓶颈与局限性
1.2 DeepSeek 的技术突破
1.2.1 算法革命与工程创新
1.2.2 工程成本与效率优势
第二部分:生态策略的分野——开源普惠 vs 闭源垄断
2.1 文心一言的生态闭环困境
2.1.1 早期闭源策略
2.1.2 市场反馈与闭源困境
2.2 DeepSeek 的开源战略优势
2.2.1 技术平权与开放合作
2.2.2 生态构建与市场驱动
第三部分:商业化能力的较量——垂直场景渗透与全球化布局
3.1 文心一言的垂直场景短板
3.1.1 过度依赖搜索场景
3.1.2 国际化布局滞后
3.2 DeepSeek 的行业赋能深度
3.2.1 垂直行业场景突破
3.2.2 全球化战略与多语言支持
第四部分:用户需求响应速度——敏捷迭代与市场感知
4.1 文心一言的迭代瓶颈
4.1.1 大厂惯性与更新模式
4.1.2 用户体验反馈不足
4.2 DeepSeek 的用户驱动开发
4.2.1 快速反馈机制
4.2.2 场景化定制
第五部分:外部环境因素——算力霸权与政策风险
5.1 文心一言的硬件依赖问题
5.1.1 对高端芯片的依赖
5.1.2 成本高昂与技术受限
5.2 DeepSeek 的算力突围策略
5.2.1 算法替代硬件依赖
5.2.2 政策支持与生态优势
第六部分:综合竞争分析与未来展望
6.1 文心一言的先发优势与现存短板
6.2 DeepSeek 的竞争优势与市场驱动力
6.3 未来改进建议
第七部分:外部评价与市场案例综述
7.1 媒体与专家评价
7.2 用户反馈与实际案例
第八部分:结论与未来展望
8.1 竞争本质:生态与效率的博弈
8.2 文心一言的改进路径
8.3 未来展望
总结
参考文献
结语
引言
近年来,随着人工智能技术的迅速发展,大规模预训练语言模型不断涌现,改变了人们与机器交互的方式。作为国内较早推出的中文大模型产品,百度的“文心一言”曾凭借强大的文心大模型(ERNIE)技术积累,在中文自然语言处理领域赢得先机。然而,尽管其在早期获得了技术和市场的双重关注,但在竞争日趋激烈的 AI 领域中,文心一言却逐步显露出诸多不足,无法持续保持市场主导地位。与此同时,DeepSeek 作为后来居上、开源普惠的产品,通过技术创新、敏捷迭代和生态开放,正逐步重塑市场规则。
本报告将详细解析文心一言与 DeepSeek 之间的竞争态势,从技术路径的差异、生态策略的分野、商业化能力的较量、用户需求响应的速度以及外部环境因素等多个角度展开讨论,力图还原文心一言从先发优势到后期困局的全过程,并提出未来改进方向和策略建议。
第一部分:技术路径的差异——算法创新与工程优化的博弈
1.1 文心一言的技术积累与局限性
1.1.1 早期技术优势
自2019年以来,百度通过其文心大模型(ERNIE)在中文自然语言处理领域取得了一定领先地位。通过知识增强、持续学习和多任务预训练,文心系列模型迅速建立了在中文语境下的技术壁垒。特别是2021年推出的 ERNIE 3.0,在引入知识图谱后,在 SuperGLUE 等国际评测中曾有超越人类水平的表现,这为文心一言奠定了坚实的技术基础。
-
知识增强:百度在模型中融合了大量结构化知识,使得模型在理解专业术语和复杂语义时表现优异。
-
持续学习:模型不断迭代更新,具备自我改进的能力,使得早期版本在处理常见任务时具有较高准确率。
-
多任务预训练:文心系列模型通过多任务学习,使其在对话生成、文本摘要、情感分析等多个领域均有所涉猎。
1.1.2 技术瓶颈与局限性
然而,尽管文心一言凭借早期的技术积累获得了一定的先发优势,但其底层架构存在一些固有局限性:
-
传统 Transformer 架构:文心一言主要基于传统 Transformer 模型,这一架构虽然在过去几年取得成功,但随着研究的深入,已暴露出计算效率低、参数堆砌而非结构创新的问题。
-
依赖大规模算力与数据标注:文心一言的模型升级往往依赖于大量数据和算力支撑,其参数扩展主要通过堆砌来提升性能,导致训练成本不断攀升。例如,文心 4.0 Turbo 的训练成本虽未公开,但业内普遍推测远超 10 亿美元,相比之下,DeepSeek-V3 的训练成本仅为557.6万美元,显示出明显的性价比劣势。
-
多模态支持不足:虽然文心 4.5 版本已开始支持多模态输入,但整体在图文、语音等数据融合处理上尚未达到业界最优水平,制约了其在更广泛场景下的应用。
综上所述,文心一言虽然依托百度强大的数据和技术资源,在早期取得了一定的技术优势,但由于底层架构的保守与更新速度滞后,导致其在计算效率、成本控制和多任务适应性上逐步落后于竞争对手 DeepSeek。
1.2 DeepSeek 的技术突破
1.2.1 算法革命与工程创新
DeepSeek 的成功在于其在算法与工程优化方面做出了显著突破:
-
混合专家模型(MoE):DeepSeek 采用了混合专家模型,通过动态稀疏路由技术,仅激活部分参数,从而在不牺牲模型性能的前提下大幅降低计算资源需求。据报道,DeepSeek-R1 在推理效率上提升了40%,使得同样规模的任务能够在更短时间内完成。
-
FP8 混合精度训练:通过引入低精度 FP8 计算,DeepSeek 显著降低了内存占用与算力消耗,同时保持了模型输出的准确性。这种技术在最新一代模型中得到了充分应用,为大规模部署提供了有力支持。
-
GRPO 算法:摒弃传统 RLHF(基于人类反馈的强化学习)模式,DeepSeek 采用 GRPO 算法实现无监督强化学习,有效减少对大规模标注数据的依赖,提升小模型的高性能化能力。
1.2.2 工程成本与效率优势
相较于文心一言庞大的训练成本,DeepSeek 在工程优化上更具性价比:
-
低成本训练:DeepSeek-V3 的训练成本仅为557.6万美元,相比文心 4.0 Turbo 的推测成本,成本优势十分明显。这使得 DeepSeek 能够以较低的经济投入实现高效性能,降低了商业应用门槛。
-
模块化架构:DeepSeek 的模型设计更趋向于模块化和开放化,便于开发者在特定场景下进行二次开发和定制化优化。其开源战略也为全球开发者提供了自由改进的可能性,形成了良好的技术生态。
总体而言,DeepSeek 通过在算法上的革命性突破和工程优化,实现了在计算效率、成本控制和扩展性上的优势,这些技术突破为其赢得了市场口碑和开发者青睐,成为后起之秀的重要原因之一。
第二部分:生态策略的分野——开源普惠 vs 闭源垄断
2.1 文心一言的生态闭环困境
2.1.1 早期闭源策略
在最初推出时,文心一言采取了闭源运营策略,这一策略在商业化初期有其合理性:
-
商业利益保障:百度选择闭源模式以保护其核心技术和商业利益,力图通过内部生态形成竞争壁垒。短期内,这种策略吸引了大量企业加入百度生态,据统计,早期加入文心生态的企业数量高达23万家。
-
安全性与控制:闭源模式有助于百度在数据安全、版权保护和内容监管方面保持较高控制权,确保产品输出符合政策和商业要求。
然而,这种策略也带来了不少问题:
-
开发者工具链不完善:闭源运营限制了第三方开发者对底层代码和接口的深入探索,导致工具链和文档支持不足,开发者社区活跃度较低。数据显示,截至2024年,文心一言的开发者数量仅为1070万,相较于OpenAI等竞争对手的生态规模明显处于劣势。
-
生态扩展滞后:直到2025年2月,文心一言才宣布全面开源,但这一举措已经晚于同行近一年的时间,错失了早期开发者红利,进一步影响了生态的活跃程度和创新动力。
2.1.2 市场反馈与闭源困境
用户和行业专家普遍认为,文心一言在技术上虽有突破,但由于生态闭环设计导致其功能扩展和社区支持受限。市场反馈显示:
-
用户在使用过程中常常遇到接口封闭、二次开发受限的问题,无法灵活定制化满足特定场景需求;
-
企业在集成文心一言时,缺乏足够的技术文档和开发支持,影响了系统整体的可维护性与扩展性。
这些生态策略上的局限性,成为文心一言后期市场竞争力下滑的重要因素之一。
2.2 DeepSeek 的开源战略优势
2.2.1 技术平权与开放合作
DeepSeek 倡导技术平权,采取了开放的开源模式:
-
MIT协议开源:DeepSeek 将模型权重与训练代码全部以 MIT 协议开源,允许商业二次开发和自由修改。这种开放模式迅速吸引了全球数十万开发者的参与,形成了一个活跃的协作生态系统。
-
开发者社区繁荣:截至2025年2月,DeepSeek 的开源社区开发者数量突破50万,各类插件、应用和优化方案层出不穷,推动了产品技术的不断迭代与创新。
-
低成本普及:DeepSeek-R1 产品免费开放,API 调用成本仅为同类国际模型的1/100,极大地降低了中小企业和个人开发者的使用门槛,形成了典型的“长尾效应”。
2.2.2 生态构建与市场驱动
通过开源战略,DeepSeek 不仅在技术上实现了突破,更在生态构建上形成了强大优势:
-
全球协作:开放的生态系统促进了全球范围内的技术交流与合作,各国开发者能够迅速适配并优化模型,推动了产品在各个细分市场的广泛应用。
-
用户驱动迭代:通过实时反馈机制,DeepSeek 能够在短时间内根据用户需求进行敏捷迭代,例如在春节假期期间,针对长文本处理的优化在48小时内完成,极大提升了用户满意度。
综上所述,DeepSeek 的开源普惠战略为其构建了一个强大、灵活且不断进化的技术生态,成为其在市场竞争中迅速崛起的重要原因。
第三部分:商业化能力的较量——垂直场景渗透与全球化布局
3.1 文心一言的垂直场景短板
3.1.1 过度依赖搜索场景
文心一言在商业化初期主要依托百度强大的搜索引擎资源,将大量用户引入到智能问答和基础对话场景中:
-
用户活跃度集中:统计数据显示,约70%的文心一言用户活跃度集中在与搜索相关的功能上,这种单一场景的依赖使得产品在拓展其他高价值领域时显得力不从心。
-
功能单一问题:由于过分依赖搜索场景,文心一言在制造、医疗、金融等行业中的应用未能形成深度垂直渗透,导致产品的商业化潜力未能充分释放。
3.1.2 国际化布局滞后
在全球化竞争中,国际化战略显得尤为重要:
-
非中文市场缺乏定制:百度未能推出针对非中文市场的定制模型,导致文心一言在国际市场上竞争力不足。与此形成鲜明对比的是,DeepSeek 通过多语言支持和海外部署(例如与微软、英伟达合作),成功覆盖了全球140多个市场。
-
国际品牌形象塑造不足:文心一言在国际化推广上投入不足,未能形成具有国际影响力的品牌形象,限制了其全球市场份额的扩展。
3.2 DeepSeek 的行业赋能深度
3.2.1 垂直行业场景突破
DeepSeek 针对不同行业推出了定制化解决方案:
-
制造业应用:与富士康、比亚迪等知名企业合作,DeepSeek 在生产线优化和故障预测方面取得显著成效。据报道,其在制造业中的故障预测准确率提升了30%,大幅降低了停机损失。
-
医疗健康领域:在医疗应用中,DeepSeek 支持中医辨证和多模态数据分析。例如,美年健康的“糖豆”AI助手接入 DeepSeek 后,客户的血糖管理效率提升了40%,为患者提供了更为精细化的健康管理方案。
-
教育与内容创作:DeepSeek 针对教育、编程和内容创作等细分领域推出定制产品,帮助用户快速生成代码、撰写报告、优化教学内容,获得了广大开发者和教育工作者的好评。
3.2.2 全球化战略与多语言支持
-
国际市场开拓:DeepSeek 积极布局海外市场,通过与全球领先企业的合作,实现了跨国技术输出和市场推广。其多语言支持使产品不仅在中文领域占据优势,也在英语、法语、德语等多种语言环境中表现出色。
-
合作生态扩展:与微软、英伟达等国际巨头建立战略合作伙伴关系,使得 DeepSeek 在技术、资源和市场上均获得了有力支撑,推动了其全球化布局的全面展开。
第四部分:用户需求响应速度——敏捷迭代与市场感知
4.1 文心一言的迭代瓶颈
4.1.1 大厂惯性与更新模式
文心一言作为大型企业的产品,在版本更新上存在一定的惯性:
-
固定更新周期:虽然文心一言每月更新一次,但多数版本更新仅集中于参数调优和性能优化,缺乏颠覆性创新。最新推出的X1模型虽试图对标 DeepSeek-R1,但市场反响平淡,用户对其迭代速度和更新深度不甚满意。
-
研发流程僵化:由于内部审批流程和资源分配问题,文心一言在用户需求响应和功能迭代上未能做到快速闭环,导致在面对不断变化的市场需求时反应较慢。
4.1.2 用户体验反馈不足
-
反馈渠道不畅:闭源模式下,文心一言的用户反馈渠道相对单一,开发者社区活跃度较低,使得产品改进难以及时反映用户实际需求。
-
迭代更新滞后:在多轮对话和复杂任务场景中,用户反馈文心一言常出现逻辑断层和响应延迟,产品迭代未能迅速修复这些关键问题。
4.2 DeepSeek 的用户驱动开发
4.2.1 快速反馈机制
DeepSeek 借助开源社区的力量,实现了高效的用户反馈和敏捷迭代:
-
实时需求收集:通过 GitHub、论坛及社交媒体,DeepSeek 团队能够迅速收集用户反馈。例如,在春节假期用户需求激增期间,团队在48小时内完成了长文本处理能力的优化,极大提升了用户体验。
-
持续迭代更新:基于开源社区的协作模式,DeepSeek 的更新频率远超竞争对手,开发者和用户可以在第一时间获得最新版本,确保产品始终保持技术前沿。
4.2.2 场景化定制
-
多产品线战略:DeepSeek 不仅推出了基础版本的 DeepSeek-R1,还推出了 Janus-Pro 等多模态生成产品,以满足教育、编程、智能客服等各类细分市场的需求。
-
精准市场定位:根据不同行业场景的需求,DeepSeek 提供定制化服务,确保产品功能与用户需求高度契合,形成了良好的市场口碑和用户粘性。
第五部分:外部环境因素——算力霸权与政策风险
5.1 文心一言的硬件依赖问题
5.1.1 对高端芯片的依赖
文心一言在训练和推理过程中依赖大量高端算力资源:
-
依赖英伟达H800集群:百度的文心一言需要依赖英伟达高性能 GPU 集群,这使得其训练资源极为昂贵,同时也受制于国际芯片供应链的不确定性。
-
出口管制压力:受美国对高端芯片出口管制的影响,百度在采购高性能 GPU 时面临一定风险,进而影响了模型训练的持续性和规模化应用。
5.1.2 成本高昂与技术受限
-
训练成本难以承受:文心 4.0 Turbo 的训练成本虽未公开,但业内普遍推测可能超过10亿美元,这不仅在经济上形成巨大压力,也使得技术更新和应用部署变得更为谨慎。
-
技术更新受制:由于高昂的训练成本和算力依赖,文心一言在进行算法创新和架构调整时面临较大阻力,无法像 DeepSeek 那样迅速实现技术突破。
5.2 DeepSeek 的算力突围策略
5.2.1 算法替代硬件依赖
DeepSeek 通过一系列算法创新,成功降低了对高端硬件的依赖:
-
结构化稀疏注意力:该技术使得模型在保持性能的同时,仅需激活部分参数,从而在同等性能下减少80%的 GPU 消耗,极大降低了硬件成本。
-
国产化适配:DeepSeek 优化了 PTX 编程技术,积极适配国产 GPU,使其在政策上获得更多支持,降低了对英伟达芯片的依赖风险。
5.2.2 政策支持与生态优势
-
国产化战略:随着国家对国产芯片和软硬件生态的扶持政策不断出台,DeepSeek 通过优化算法和技术架构,获得了政策和资本的双重支持,为其进一步市场扩张奠定了基础。
-
全球合作:同时,DeepSeek 与国际知名厂商合作,确保在全球范围内构建灵活、高效的计算资源网络,使其在面对国际制裁和市场波动时更具韧性。
第六部分:综合竞争分析与未来展望
6.1 文心一言的先发优势与现存短板
文心一言在最早期凭借技术沉淀和品牌效应,曾在中文 AI 领域取得了领先地位。然而,随着市场和技术的不断演进,其先发优势未能转化为持久的市场主导力。主要原因包括:
-
技术路径保守:基于传统 Transformer 架构,缺乏底层算法的突破与创新,导致模型在计算效率和多任务适应性方面逐渐落后。
-
生态闭环局限:闭源模式限制了开发者的参与和社区的活跃度,生态扩展滞后,无法快速响应市场多样化需求。
-
商业化战略不够精准:过度依赖搜索场景和单一应用领域,未能在高价值垂直市场(如制造、医疗、教育)实现深度赋能和国际化布局。
-
硬件依赖与成本压力:高昂的训练和算力成本使得产品更新缓慢,市场竞争中处于劣势。
6.2 DeepSeek 的竞争优势与市场驱动力
相比之下,DeepSeek 通过以下策略迅速获得市场优势:
-
技术创新与工程优化:通过混合专家模型、动态稀疏路由以及低精度计算等技术,大幅降低算力需求和训练成本,实现高效推理。
-
开放与开源策略:采用 MIT 协议全面开源,形成庞大开发者社区和全球协作生态,使得产品能够快速迭代并满足不同场景的定制需求。
-
多场景覆盖与国际化布局:在制造、医疗、教育等多个领域深入布局,同时通过多语言支持和海外部署,构建全球市场网络,增强了产品竞争力。
-
敏捷用户驱动:依靠开源社区和实时反馈机制,DeepSeek 能迅速响应用户需求和市场变化,保持了较高的更新频率和产品活力。
6.3 未来改进建议
为了重新夺回市场主导地位,文心一言需要在以下几个方向上进行改进:
-
加速技术民主化:深化开源战略,逐步开放接口和部分源码,吸引第三方开发者参与创新,提升产品灵活性和扩展性。
-
聚焦高价值场景:由通用大模型向行业专用模型转型,针对制造、医疗、金融等高价值领域推出定制化解决方案,实现精准赋能。
-
突破算力桎梏:联合国产芯片厂商和软硬件供应链优化训练框架,降低对国际高端 GPU 的依赖,提升整体算力效率和稳定性。
-
提升用户体验:加强多轮对话连续性和逻辑推理能力,优化文本生成细腻度和代码编辑功能,缩小与国际先进产品之间的差距。
-
构建全球生态:加大国际化推广力度,开发针对非中文市场的定制模型,提升品牌国际影响力,构建跨国协作生态。
第七部分:外部评价与市场案例综述
7.1 媒体与专家评价
多家科技媒体和行业专家在评测中指出,文心一言作为国内首批大模型产品,曾凭借雄厚的数据积累和技术沉淀取得领先优势,但近年来在国际竞争中逐渐暴露出技术更新滞后和生态封闭的问题。部分评论提到:
-
“文心一言的文本生成虽具中国特色,但在逻辑连贯性和创新性上明显不及国际同类产品。”
-
“在高并发应用场景下,文心一言的响应速度和稳定性成为用户诟病的焦点。”
-
“生态闭源限制了开发者的自由,导致创新活力不足,这是文心一言后期竞争力下降的重要原因。”
7.2 用户反馈与实际案例
在实际应用中,不少企业和开发者反馈文心一言在日常对话和基础任务中尚能满足需求,但在复杂应用场景(如高级代码生成、深度数据分析)中表现欠佳:
-
某金融企业在引入文心一言进行客服自动化时,发现系统在处理专业问题时常出现回答不够准确和响应延迟的情况,最终选择引入 DeepSeek 辅助优化。
-
部分开发者在使用文心一言进行代码生成时,认为生成代码在结构和注释方面欠缺细致,调试成本较高,而转而采用开放的 DeepSeek 进行二次开发。
总体来看,用户普遍认为文心一言的早期优势已无法支撑其在高端市场的竞争力,而 DeepSeek 的开源、灵活和高效则更符合当前快速迭代的市场需求。
第八部分:结论与未来展望
8.1 竞争本质:生态与效率的博弈
AI 竞争的核心不仅在于模型参数的多少,更在于生态系统的建设与整体应用效率的提升。文心一言早期凭借雄厚技术积累和品牌效应曾取得领先,但随着全球 AI 技术的快速发展,其传统架构与封闭生态逐渐显露短板。而 DeepSeek 通过技术革新、开源普惠和敏捷迭代,重塑了 AI 行业规则,在成本、效率和扩展性方面形成了独特竞争优势。
8.2 文心一言的改进路径
针对当前存在的不足,文心一言未来的改进方向应集中在:
-
技术革新:更新底层架构,引入先进的混合专家模型和低精度计算技术,降低算力消耗,提升推理效率;
-
生态开放:逐步开放部分核心接口和源码,构建开发者友好的生态系统,吸引全球协作;
-
多场景应用:从单一的搜索对话扩展到制造、医疗、金融等高价值领域,实现垂直场景深度赋能;
-
国际化布局:推出针对非中文市场的定制版本,提升全球竞争力,借助国际合作拓宽市场份额;
-
用户体验优化:提升对话连续性、文本生成逻辑和代码编辑准确率,确保用户在实际应用中的高效体验。
8.3 未来展望
随着技术的不断进步和生态的逐步完善,未来的 AI 竞争将更为激烈。文心一言若能在保持中文处理优势的同时,加快技术创新步伐、开放生态系统,并聚焦高价值垂直场景,将有望重拾市场主导地位。与此同时,DeepSeek 及其他国际先进产品将持续推动行业技术升级,整体市场格局将向更加开放、多元和协同的方向发展。
从长远看,AI 竞赛的本质在于技术与生态的协同演进,只有不断突破算力、算法和应用边界,才能真正实现智能化、普惠化和全球化。百度文心一言若能在未来不断改进和突破,其潜力仍不可小觑,而 DeepSeek 的崛起也为整个行业树立了新的标杆。
总结
本文从技术路径、生态策略、商业化能力、用户响应以及外部环境等多个维度,详细分析了文心一言为何在早期凭借技术先发优势进入市场,但在后续竞争中未能转化为市场主导地位。主要原因包括:传统 Transformer 架构的局限、依赖大规模算力和数据标注、封闭生态系统导致开发者参与不足、商业化应用单一以及国际竞争环境加剧等方面。与此同时,DeepSeek 通过混合专家模型、开源普惠战略、敏捷迭代和多场景定制,在技术与生态上实现了突破,成为市场竞争的新亮点。
未来,百度应在加速技术创新、开放生态合作、拓展垂直场景和国际化布局方面加大投入,以破解现有困局,实现从先发优势向市场主导地位的转变。只有在生态、效率与用户体验等多重维度形成协同效应,文心一言才能在全球 AI 竞赛中重塑辉煌。
参考文献
-
百度文心一言官方文档与产品介绍
-
行业内专家对 ERNIE 3.0 与文心一言的技术评测报告
-
多家科技媒体对文心一言和 DeepSeek 竞品的综合评论
-
国际大模型技术前沿文章与开源社区讨论记录
-
市场调研报告和用户反馈统计数据
结语
通过本报告的全面剖析,我们可以看出,文心一言虽曾凭借早期技术积累和品牌效应获得先机,但在后续激烈的市场竞争中,由于技术更新缓慢、生态封闭、商业化策略不足以及国际化布局滞后等原因,未能稳固其市场主导地位。DeepSeek 则凭借技术革新、开源普惠和敏捷迭代,成功抢占了更多细分场景和国际市场,形成了显著的竞争优势。
未来,百度若能正视现有问题,加快开放步伐、提升技术水平并深耕高价值应用场景,将有望在全球 AI 竞争中重新赢得优势。希望本报告能为广大行业从业者和技术爱好者提供有价值的参考,共同推动人工智能技术的不断进步与普惠发展。
相关文章:

文心一言与 DeepSeek 的竞争分析:技术先发优势为何未能转化为市场主导地位?
目录 引言 第一部分:技术路径的差异——算法创新与工程优化的博弈 1.1 文心一言的技术积累与局限性 1.1.1 早期技术优势 1.1.2 技术瓶颈与局限性 1.2 DeepSeek 的技术突破 1.2.1 算法革命与工程创新 1.2.2 工程成本与效率优势 第二部分:生态策略…...

Spring Security(maven项目) 3.1.0
前言: 通过实践而发现真理,又通过实践而证实真理和发展真理。从感性认识而能动地发展到理性认识,又从理性认识而能动地指导革命实践,改造主观世界和客观世界。实践、认识、再实践、再认识,这种形式,循环往…...
)
合并两个有序数组(Java实现)
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。 注意:最终,合并后数组…...

Tree - Shaking
Vue 3 的 Tree - Shaking 技术详解 Tree - Shaking 是一种在打包时移除未使用代码的优化技术,在 Vue 3 中,Tree - Shaking 发挥了重要作用,有效减少了打包后的代码体积,提高了应用的加载性能。以下是对 Vue 3 中 Tree - Shaking …...

C# 从代码创建选型卡+表格
private int tabNum 1; private int sensorNum 5; private void InitializeUI() {// 创建右侧容器面板Panel rightPanel new Panel{Dock DockStyle.Right,Width 300,BackColor SystemColors.ControlDark,Parent this};// 根据防区数量创建内容if (tabNum &g…...
OpenCV 从入门到精通(day_02)
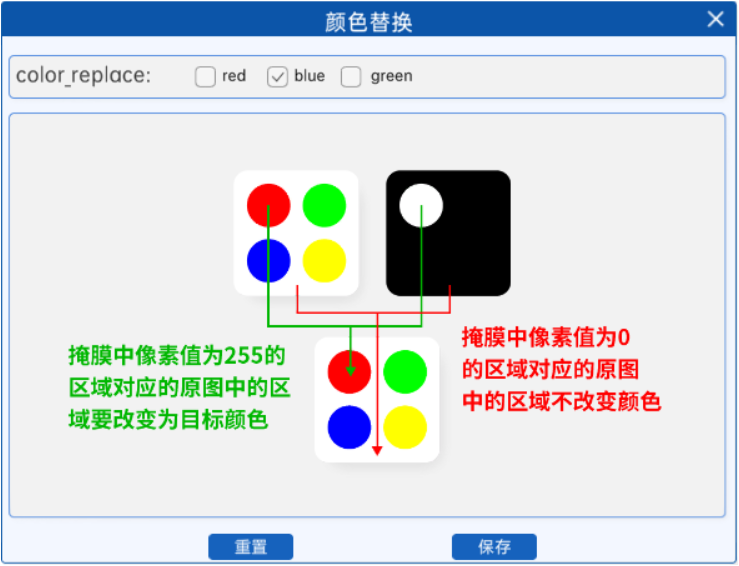
1. 边缘填充 为什么要填充边缘呢?我们以下图为例: 可以看到,左图在逆时针旋转45度之后原图的四个顶点在右图中已经看不到了,同时,右图的四个顶点区域其实是什么都没有的,因此我们需要对空出来的区域进行一个…...

VTK的两种显示刷新方式
在类中先声明vtk的显示对象 vtkRenderer out_render; vtkVertexGlyphFilter glyphFilter; vtkPolyDataMapper mapper; // 新建制图器 vtkActor actor; // 新建角色 然后在init中先初始化一下: out_rend…...
Ceph异地数据同步之-RBD异地同步复制(上)
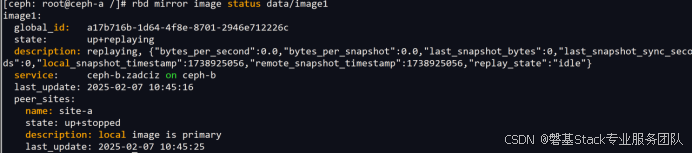
#作者:闫乾苓 文章目录 前言基于快照的模式(Snapshot-based Mode)工作原理单向同步配置步骤单向同步复制测试双向同步配置步骤双向同步复制测试 前言 Ceph的RBD(RADOS Block Device)支持在两个Ceph集群之间进行异步镜…...

【C++】STL库_stack_queue 的模拟实现
栈(Stack)、队列(Queue)是C STL中的经典容器适配器 容器适配器特性 不是独立容器,依赖底层容器(deque/vector/list)通过限制基础容器接口实现特定访问模式不支持迭代器操作(无法遍历…...

前端对接下载文件接口、对接dart app
嵌套在dart app里面的前端项目 1.前端调下载接口 ->后端返回 application/pdf格式的文件 ->前端将pdf处理为blob ->blob转base64 ->调用dart app的 sdk saveFile ->保存成功 async download() {try {// 调用封装的 downloadEContract 方法获取 Blob 数据const …...
一周学会Pandas2 Python数据处理与分析-编写Pandas2 HelloWord项目
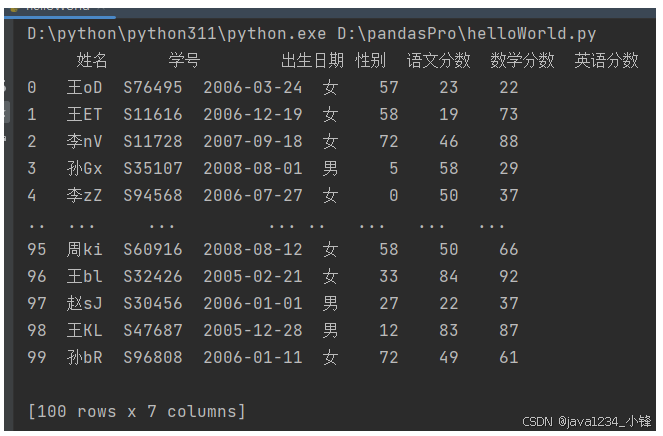
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili 我们首先准备一个excel文件,用来演示pandas操作数据集(数据的集合)。excel文件属于数据集的一种…...
【易订货-注册/登录安全分析报告】
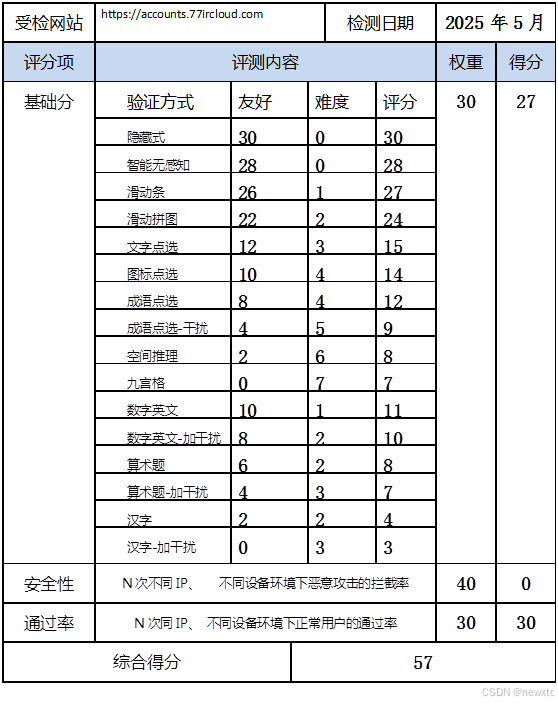
前言 由于网站注册入口容易被机器执行自动化程序攻击,存在如下风险: 暴力破解密码,造成用户信息泄露,不符合国家等级保护的要求。短信盗刷带来的拒绝服务风险 ,造成用户无法登陆、注册,大量收到垃圾短信的…...

AI赋能股票:流通股本与总股本:定义、区别及投资意义解析
一、基本定义 总股本(Total Shares Outstanding) 指一家公司已发行的所有股票数量,包括流通股和非流通股(如限售股、员工持股计划股票等)。总股本反映公司的整体股权结构,是计算市值(总股本 股…...
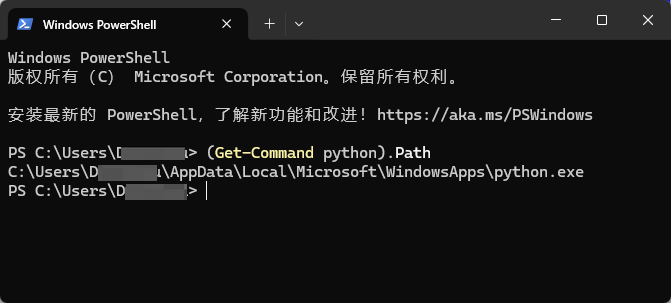
如何在Windows上找到Python安装路径?两种方法快速定位
原文:如何在Windows上找到Python安装路径?两种方法快速定位 | w3cschool笔记 在 Windows 系统上找到 Python 的安装路径对于设置环境变量或排查问题非常重要。本文将介绍两种方法,帮助你找到 Python 的安装路径:一种是通过命令提…...

第五课:高清修复和放大算法
文章目录 Part.01 高清修复(Hi-Res Fix)Part.02 SD放大(SD Upscale)Part.03 附加功能放大Part.01 高清修复(Hi-Res Fix) 文生图中的高清修复/高分辨率修复/超分辨率修复先低分辨率抽卡,再高分辨率修复。不能突破显存限制放大重绘幅度安全范围是0.3-0.5,如果想让AI更有想象力0…...

lvgl避坑记录
一、log调试 #if LV_USE_LOG && LV_LOG_LEVEL > LV_LOG_LEVEL_INFOswitch(src_type) {case LV_IMG_SRC_FILE:LV_LOG_TRACE("lv_img_set_src: LV_IMG_SRC_FILE type found");break;case LV_IMG_SRC_VARIABLE:LV_LOG_TRACE("lv_img_set_src: LV_IMG_S…...
简介)
Java 8 的流(Stream API)简介
Java 8 引入的 Stream API 是一个强大的工具,用于处理集合(如 List、Set)中的元素。它支持各种操作,包括过滤、排序、映射等,并且能够以声明式的方式表达复杂的查询操作。流操作可以是中间操作(返回流以便进…...

液态神经网络技术指南
一、引言 1.从传统神经网络到液态神经网络 神经网络作为深度学习的核心工具,在图像识别、自然语言处理、推荐系统等领域取得了巨大成功。尤其是卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LS…...
element-plus中,表单校验的使用
目录 一.案例1:给下面的表单添加校验 1.目的要求 2.步骤 ①给需要校验的el-form-item项,添加prop属性 ②定义一个表单校验对象,里面存放了每一个prop的检验规则 ③给el-form组件,添加:rules属性 ④给el-form组件࿰…...

PyTorch复现线性模型
【前言】 本专题为PyTorch专栏。从本专题开始,我将通过使用PyTorch编写基础神经网络,带领大家学习PyTorch。并顺便带领大家复习以下深度学习的知识。希望大家通过本专栏学习,更进一步了解人更智能这个领域。 材料来源:2.线性模型_…...

Kafka+Zookeeper从docker部署到spring boot使用完整教程
文章目录 一、Kafka1.Kafka核心介绍:核心架构核心特性典型应用 2.Kafka对 ZooKeeper 的依赖:3.去 ZooKeeper 的演进之路:注:(本文采用ZooKeeper3.8 Kafka2.8.1) 二、Zookeeper1.核心架构与特性2.典型…...
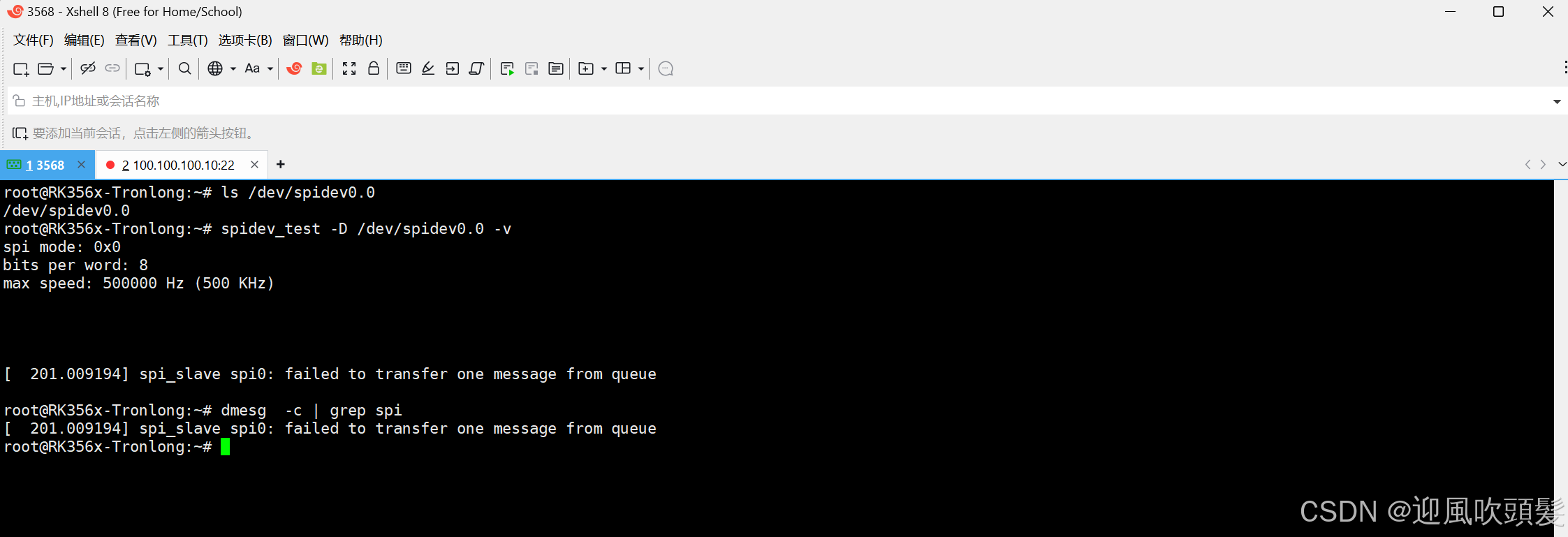
RK3568驱动 SPI主/从 配置
一、SPI 控制器基础配置(先说主的配置,后面说从的配置) RK3568 集成高性能 SPI 控制器,支持主从双模式,最高传输速率 50MHz。设备树配置文件路径通常为K3568/rk356x_linux_release_v1.3.1_20221120/kernel/arch/arm64/boot/dts/rockchip。 …...

【全队项目】智能学术海报生成系统PosterGenius--风格个性化调整
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏🏀大模型实战训练营 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 1.前言 PosterGenius致力于开发一套依托DeepSeek…...
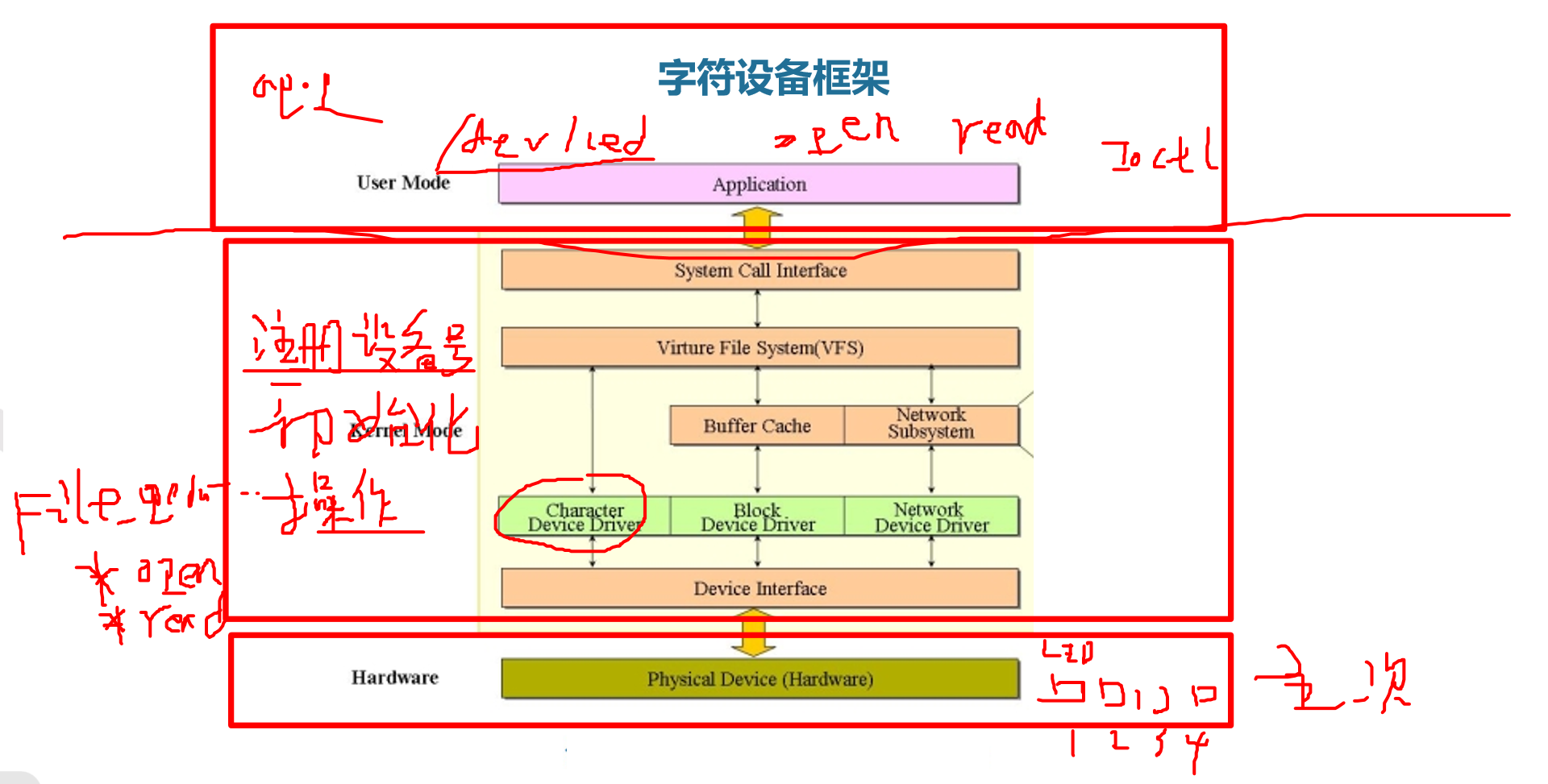
【系统移植】(六)第三方驱动移植
【系统移植】(六)第三方驱动移植 文章目录 【系统移植】(六)第三方驱动移植1.编译驱动进内核方法一:编译makefile方法二:编译kconfig方法三:编译成模块 2.字符设备框架 编译驱动进内核a. 选择驱…...
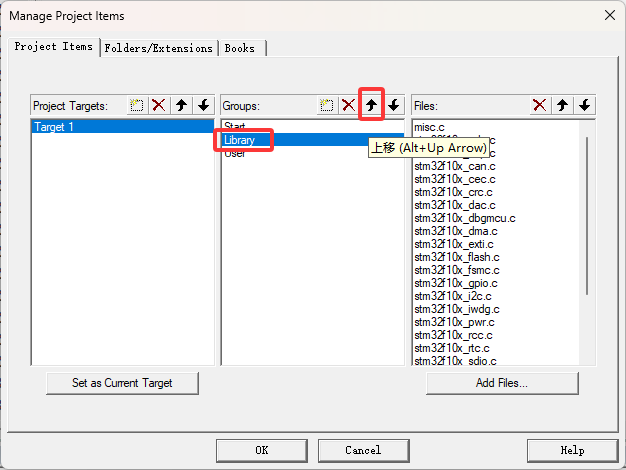
STM32实现一个简单电灯
新建工程的步骤 建立工程文件夹,Keil中新建工程,选择型号工程文件夹里建立Start、Library、User等文件夹,复制固件库里面的文件到工程文件夹工程里对应建立Start、Library、User等同名称的分组,然后将文件夹内的文件添加到工程分组…...

【shiro】shiro反序列化漏洞综合利用工具v2.2(下载、安装、使用)
1 工具下载 shiro反序列化漏洞综合利用工具v2.2下载: 链接:https://pan.baidu.com/s/1kvQEMrMP-PZ4K1eGwAP0_Q?pwdzbgp 提取码:zbgp其他工具下载: 除了该工具之外,github上还有其他大佬贡献的各种工具,有…...
vue进度条组件
<div class"global-mask" v-if"isProgress"><div class"contentBox"><div class"progresstitie">数据加载中请稍后</div><el-progress class"progressStyle" :color"customColor" tex…...
:矩阵加减法与SIMD集成)
【C++游戏引擎开发】《线性代数》(2):矩阵加减法与SIMD集成
一、矩阵加减法数学原理 1.1 定义 逐元素操作:运算仅针对相同位置的元素,不涉及矩阵乘法或行列变换。交换律与结合律: 加法满足交换律(A + B = B + A)和结合律( ( A + B ) + C = A + ( B + C ) )。 减法不满足交换律(A − B ≠ B − A)。1.2 公式 C i j = …...

UE5Actor模块源码深度剖析:从核心架构到实践应用
UE5 Actor模块源码深度剖析:从核心架构到实践应用 a. UE5 Actor模块架构概述 在UE5引擎中,Actor扮演着至关重要的角色,它是整个游戏世界中各类可交互对象的基础抽象。从本质上来说,所有能够被放置到关卡中的对象都属于Actor的范畴,像摄像机、静态网格体以及玩家起始位置…...

【3.软件工程】3.6 W开发模型
W模型全解析:开发与测试并行的质量保障框架 ⚡ 一、W模型核心流程图 #mermaid-svg-YfU8WQvqa6iDUKz3 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-YfU8WQvqa6iDUKz3 .error-icon{fill:#552222;}#merm…...