预测分析(四):面向预测分析的神经网络简介
文章目录
- 面向预测分析的神经网络简介
- 神经网络模型
- 1. 基本概念
- 2. 前馈神经网络
- 3. 常见激活函数
- 4. 循环神经网络(RNN)
- 5. 卷积神经网络(CNN)
- MPL
- 结构
- 工作原理
- 激活函数
- 训练方法
- 基于神经网络的回归——以钻石为例
- 构建预测钻石价格的MLP
- 训练 M L P MLP MLP
- 基于神经网络的分类
面向预测分析的神经网络简介
神经网络模型
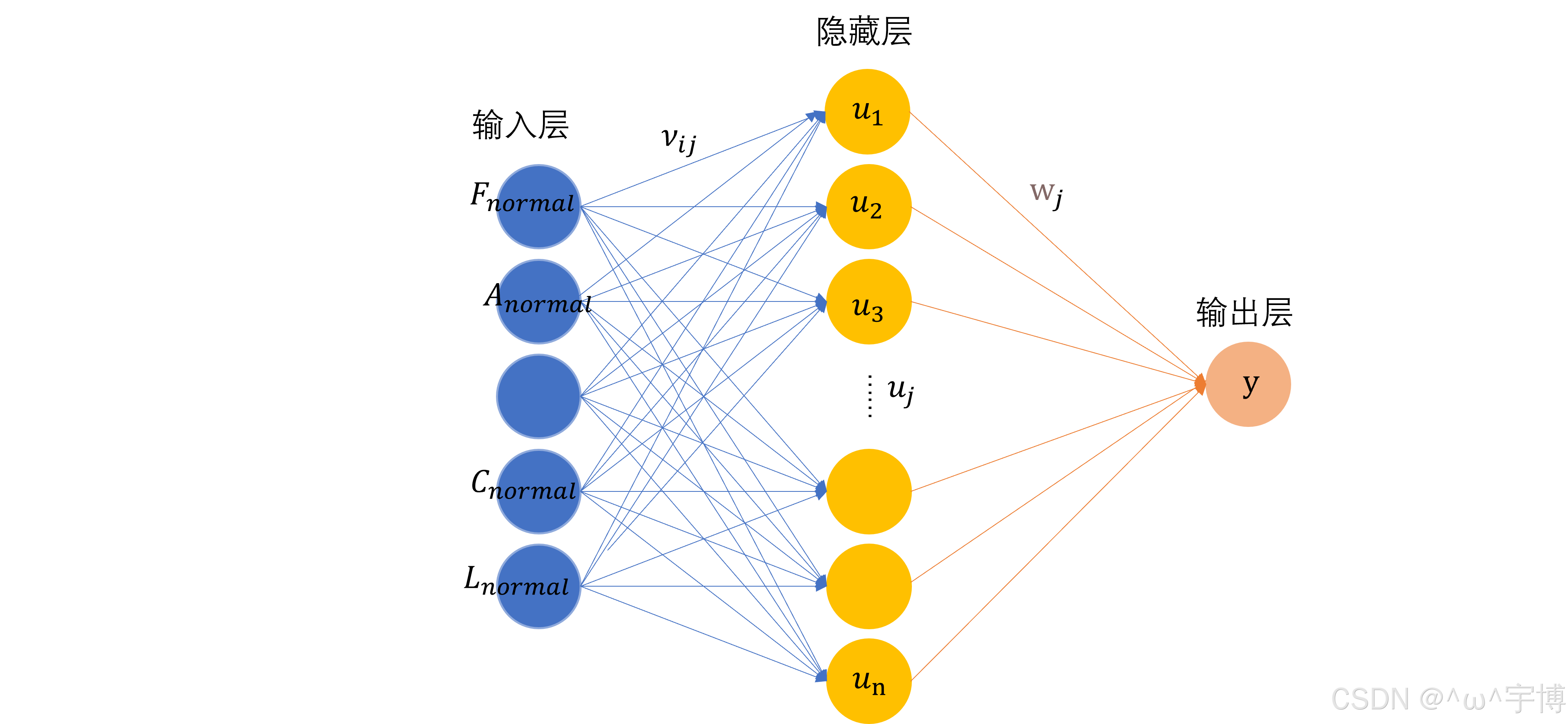
神经网络(Neural Network),也被称为人工神经网络(Artificial Neural Network,ANN),是一种模仿人类神经系统的计算模型,在机器学习和深度学习领域应用广泛。
1. 基本概念
- 神经元:神经网络的基本计算单元,接收多个输入信号,通过激活函数对输入进行非线性变换后输出结果。一个简单的神经元可以表示为 y = f ( ∑ i = 1 n w i x i + b ) y = f(\sum_{i = 1}^{n}w_{i}x_{i}+b) y=f(∑i=1nwixi+b),其中 x i x_i xi 是输入, w i w_i wi 是对应的权重, b b b 是偏置, f f f激活函数。
- 层:多个神经元组成一层,常见的层包括输入层、隐藏层和输出层。输入层接收原始数据;隐藏层对输入数据进行特征提取和转换;输出层给出最终的预测结果。
- 网络结构:不同层之间相互连接形成神经网络的结构,常见的有前馈神经网络(Feed - Forward Neural Network),信息只能从输入层依次向前传递到输出层;还有循环神经网络(Recurrent Neural Network,RNN),它允许信息在网络中循环流动,适合处理序列数据。
2. 前馈神经网络
- 工作原理:输入数据从输入层进入,经过隐藏层的一系列计算和变换,最终在输出层得到预测结果。每一层的神经元将上一层的输出作为输入,通过加权求和和激活函数处理后传递给下一层。
- 训练过程
- 定义损失函数:用于衡量预测结果与真实标签之间的差异,常见的损失函数有均方误差(Mean Squared Error,MSE)用于回归问题,交叉熵损失(Cross - Entropy Loss)用于分类问题。
- 前向传播:将输入数据传入网络,计算得到预测结果。
- 反向传播:根据损失函数的梯度,从输出层开始反向计算每个参数(权重和偏置)的梯度,以确定如何调整参数来减小损失。
- 参数更新:使用优化算法(如随机梯度下降,SGD)根据计算得到的梯度更新网络中的参数。
3. 常见激活函数
- Sigmoid函数:
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1 + e^{-x}} f(x)=1+e−x1
将输入值映射到 (0, 1) 区间,常用于二分类问题的输出层。但它存在梯度消失问题,即当输入值过大或过小时,梯度趋近于 0,导致训练速度变慢。
- ReLU函数:
f ( x ) = max ( 0 , x ) f(x)=\max(0,x) f(x)=max(0,x)
计算简单,能有效缓解梯度消失问题,在隐藏层中应用广泛。
- Softmax函数:
常用于多分类问题的输出层,将输入值转换为概率分布,所有输出值之和为 1。
4. 循环神经网络(RNN)
- 特点:RNN 引入了循环结构,允许信息在不同时间步之间传递,因此能够处理序列数据,如自然语言处理中的文本序列、时间序列分析中的股票价格数据等。
- 局限性:传统的 RNN 存在长期依赖问题,即难以捕捉序列中相隔较远的信息之间的关系。为了解决这个问题,出现了长短期记忆网络(LSTM)和门控循环单元(GRU)等改进模型。
5. 卷积神经网络(CNN)
- 原理:CNN 主要用于处理具有网格结构的数据,如图像。它通过卷积层、池化层和全连接层组成。卷积层使用卷积核在输入数据上滑动进行卷积操作,提取局部特征;池化层用于降低特征图的维度,减少计算量;全连接层将卷积和池化得到的特征进行整合,输出最终的预测结果。
- 优势:CNN 具有参数共享和局部连接的特点,大大减少了模型的参数数量,降低了计算复杂度,同时提高了模型的泛化能力。
MPL
MLP通常指多层感知机(Multilayer Perceptron),它是一种基础且经典的人工神经网络模型,下面从结构、工作原理、激活函数、训练方法、优缺点和应用场景等方面为你详细介绍:
结构
MLP由输入层、一个或多个隐藏层以及输出层组成。
- 输入层:负责接收原始数据,神经元的数量通常等于输入特征的数量。
- 隐藏层:可以有一层或多层,每一层包含多个神经元。隐藏层通过非线性变换对输入数据进行特征提取和转换,是MLP学习复杂模式的关键部分。
- 输出层:输出模型的预测结果,神经元的数量根据具体的任务而定。例如,在二分类问题中,输出层可能只有一个神经元;在多分类问题中,输出层的神经元数量等于类别数。
工作原理
MLP的工作过程分为前向传播和反向传播。
- 前向传播:输入数据从输入层传入,依次经过各个隐藏层,最终到达输出层。在每一层中,神经元会对输入进行加权求和,并通过激活函数进行非线性变换,将结果传递给下一层。
- 反向传播:根据输出层的预测结果与真实标签之间的误差,计算误差关于每个神经元权重的梯度,然后使用优化算法(如梯度下降法)更新权重,以减小误差。
激活函数
激活函数为MLP引入非线性特性,使其能够学习复杂的非线性关系。常见的激活函数有:
- Sigmoid函数:将输入映射到(0, 1)区间,常用于二分类问题的输出层。
- ReLU函数:当输入大于0时,输出等于输入;当输入小于等于0时,输出为0。它计算简单,能有效缓解梯度消失问题,是隐藏层中常用的激活函数。
- Softmax函数:常用于多分类问题的输出层,将输出转换为概率分布。
训练方法
MLP通常使用误差反向传播算法(Backpropagation)进行训练,具体步骤如下:
- 初始化权重:随机初始化MLP中所有神经元之间的连接权重。
- 前向传播:将输入数据传入网络,计算输出结果。
- 计算误差:根据输出结果与真实标签之间的差异,计算损失函数的值。
- 反向传播:计算误差关于每个权重的梯度。
- 更新权重:使用优化算法(如随机梯度下降、Adam等)根据梯度更新权重。
- 重复步骤2 - 5:直到损失函数收敛或达到预设的训练轮数。
基于神经网络的回归——以钻石为例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
%matplotlib inlineDATA_DIR = '../data'
FILE_NAME = 'diamonds.csv'
data_path = os.path.join(DATA_DIR, FILE_NAME)
diamonds = pd.read_csv(data_path)# 数据预处理
diamonds = diamonds.loc[(diamonds['x'] > 0) | (diamonds['y'] > 0)]
diamonds.loc[11182, 'x'] = diamonds['x'].median()
diamonds.loc[11182, 'z'] = diamonds['z'].median()
diamonds = diamonds.loc[~((diamonds['y'] > 30) | (diamonds['z'] > 30))]
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['cut'], prefix='cut', drop_first=True)], axis=1)
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['color'], prefix='color', drop_first=True)], axis=1)
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['clarity'], prefix='clarity', drop_first=True)], axis=1)# 分割数据集
X = diamonds.drop(['cut', 'color', 'clarity', 'price'], axis=1)
y = diamonds['price']from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=123)# PCA降维
from sklearn.decomposition import PCA
pca = PCA(n_components=1, random_state=123)
pca.fit(X_train[['x', 'y', 'z']])
X_train['dim_index'] = pca.transform(X_train[['x', 'y', 'z']]).flatten()
X_train.drop(['x', 'y', 'z'], axis=1, inplace=True)# 标准化数值特征
numerical_features = ['carat', 'depth', 'table', 'dim_index']
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train[numerical_features])
X_train.loc[:, numerical_features] = scaler.transform(X_train[numerical_features])
现在我们完成了神经网络的建模工作。
构建预测钻石价格的MLP
如前面所述,神经网络模型由一系列的层组成,因此Keras有一个类称为Sequential这个类可以用来实例化神经网络模型:
from keras.models import Sequential
nn_reg = Sequential()
现在需要为它添加层——奖使用的层名为全连接层或者稠密层:
from keras.layers import Dense
接下来添加第一层:
n_input=X_train.shape[1]
n_hidden1=32
# 增加第一个隐藏层
nn_reg.add(Dense(units=n_hidden1,activation='relu',input_shape=(n_input,)))
units:这是层中神经元的个数activation:这是每个神经元的激活函数,这里选用:ReLuinput_shape:这是网络接受的输入个数,其值等于数据集合中预测特征的个数。
接下来我们可以添加更多的隐藏层:
n_hidden2=16
n_hidden3=8
nn_reg.add(Dense(units=n_hidden2,activation='relu'))
nn_reg.add(Dense(units=n_hidden3,activation='relu'))
......
注意:这里使用各层的单元个数以 2 2 2的乘方逐次减少。
我们现在还需要添加一个最终层——输出层。对于每个样本来说,这是一个回归问题,需要的结果只有一个。因此添加最后一层:
nn_reg.add(Dense(units=1,activation=None))
接下来就要训练 M L P MLP MLP了,修正这些随机的权重和偏置。
训练 M L P MLP MLP
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error, r2_score# 假设之前的数据预处理代码已经执行,这里接着进行模型训练
# ...之前的数据预处理代码...# 训练MLP模型
mlp = MLPRegressor(hidden_layer_sizes=(100, 50), # 两个隐藏层,分别有100和50个神经元activation='relu', # 使用ReLU激活函数solver='adam', # 使用Adam优化器random_state=123,max_iter=500) # 最大迭代次数mlp.fit(X_train, y_train)# 对测试集进行预测
X_test['dim_index'] = pca.transform(X_test[['x', 'y', 'z']]).flatten()
X_test.drop(['x', 'y', 'z'], axis=1, inplace=True)
X_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])
y_pred = mlp.predict(X_test)# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")all
import numpy as np
import pandas as pd
import os
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.metrics import mean_squared_error, r2_score# 假设之前的数据预处理代码已经执行,这里接着进行模型训练
# ...之前的数据预处理代码...# 创建Sequential模型
nn_reg = Sequential()# 获取输入特征的数量
n_input = X_train.shape[1]
n_hidden1 = 32
# 增加第一个隐藏层
nn_reg.add(Dense(units=n_hidden1, activation='relu', input_shape=(n_input,)))# 添加更多的隐藏层
n_hidden2 = 16
n_hidden3 = 8
nn_reg.add(Dense(units=n_hidden2, activation='relu'))
nn_reg.add(Dense(units=n_hidden3, activation='relu'))# 添加输出层
nn_reg.add(Dense(units=1, activation=None))# 编译模型
nn_reg.compile(optimizer='adam', # 使用Adam优化器loss='mse', # 使用均方误差作为损失函数metrics=['mse']) # 监控均方误差# 训练模型
history = nn_reg.fit(X_train, y_train,epochs=50, # 训练的轮数batch_size=32, # 每个批次的样本数validation_split=0.1, # 用于验证集的比例verbose=1)# 对测试集进行预测
X_test['dim_index'] = pca.transform(X_test[['x', 'y', 'z']]).flatten()
X_test.drop(['x', 'y', 'z'], axis=1, inplace=True)
X_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])
y_pred = nn_reg.predict(X_test)# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")# 绘制训练和验证损失曲线
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()基于神经网络的分类
类似的,这里先水一下:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from sklearn.metrics import accuracy_score# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 数据预处理
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)# 标签编码
encoder = OneHotEncoder(sparse_output=False)
y = encoder.fit_transform(y.reshape(-1, 1))# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建模型
model = Sequential()
model.add(Dense(16, activation='relu', input_shape=(X_train.shape[1],)))
model.add(Dense(8, activation='relu'))
model.add(Dense(3, activation='softmax'))# 编译模型
model.compile(optimizer=Adam(learning_rate=0.001),loss='categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=50, batch_size=16, validation_split=0.1)# 评估模型
y_pred = model.predict(X_test)
y_pred_classes = np.argmax(y_pred, axis=1)
y_test_classes = np.argmax(y_test, axis=1)
accuracy = accuracy_score(y_test_classes, y_pred_classes)
print(f"模型准确率: {accuracy}")相关文章:
预测分析(四):面向预测分析的神经网络简介
文章目录 面向预测分析的神经网络简介神经网络模型1. 基本概念2. 前馈神经网络3. 常见激活函数4. 循环神经网络(RNN)5. 卷积神经网络(CNN) MPL结构工作原理激活函数训练方法 基于神经网络的回归——以钻石为例构建预测钻石价格的M…...

Debezium日常分享系列之:Debezium 3.1.0.Final发布
Debezium日常分享系列之:Debezium 3.1.0.Final发布 重大改变Debezium Core事件源块现在带有版本号稀疏向量逻辑类型重命名更改了模式历史配置的默认值 Debezium Storage moduleJDBC 存储配置命名约定变更 Debezium for Oracle多个 Oracle LogMiner JMX 指标被移除重…...

LLaMA-Factory大模型微调全流程指南
该文档为LLaMA-Factory大模型微调提供了完整的技术指导,涵盖了从环境搭建到模型训练、推理和合并模型的全流程,适用于需要进行大模型预训练和微调的技术人员。 一、docker 容器服务 请参考如下资料制作 docker 容器服务,其中,挂…...

为什么芯片半导体行业需要全星APQP系统?--行业研发项目管理软件系统
为什么芯片半导体行业需要全星APQP系统?--行业研发项目管理软件系统 在芯片半导体行业,严格的合规性要求、复杂的供应链协同及高精度质量管理是核心挑战。全星研发项目管理APQP系统专为高门槛制造业设计,深度融合APQP五大阶段(从设…...

Linux make 检查依赖文件更新的原理
1. 文件的时间戳 make 主要依靠文件的时间戳来判断依赖文件是否有更新。每个文件在文件系统中都有一个时间戳,记录了文件的三种重要时间: 访问时间(Accesstime):文件最后一次被访问的时间。修改时间&…...

vulkanscenegraph显示倾斜模型(5.6)-vsg::RenderGraph的创建
前言 上一章深入分析了vsg::CommandGraph的创建过程及其通过子场景遍历实现Vulkan命令录制的机制。本章将在该基础上,进一步探讨Vulkan命令录制中的核心封装——vsg::RenderGraph。作为渲染流程的关键组件,RenderGraph封装了vkCmdBeginRenderPass和vkCmd…...
深度解析与优化之道)
解锁 Python 多线程的潜力:全局解释器锁(GIL)深度解析与优化之道
解锁 Python 多线程的潜力:全局解释器锁(GIL)深度解析与优化之道 引言 Python,这门以简洁和优雅著称的编程语言,自诞生以来在 Web 开发、数据分析、人工智能等领域大放异彩。然而,Python 的多线程性能却常被诟病,其核心原因之一便是全局解释器锁(Global Interpreter …...

基于阿里云可观测产品构建企业级告警体系的通用路径与最佳实践
前言 1.1 日常生活中的告警 任何连续稳定运行的生产系统都离不开有效的监控与报警机制。通过监控,我们可以实时掌握系统和业务的运行状态;而报警则帮助我们及时发现并响应监控指标及业务中的异常情况。 在日常生活中,我们也经常遇到各种各样…...
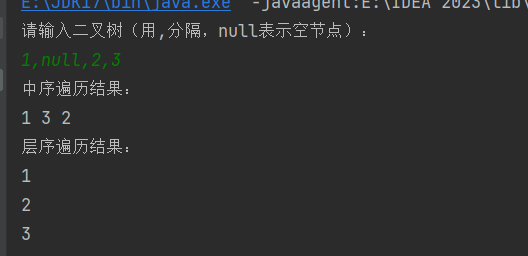
二叉树的ACM板子(自用)
package 二叉树的中序遍历;import java.util.*;// 定义二叉树节点 class TreeNode {int val; // 节点值TreeNode left; // 左子节点TreeNode right; // 右子节点// 构造函数TreeNode(int x) {val x;} }public class DMain {// 构建二叉树(层序遍历方式&…...

架构思维:查询分离 - 表数据量大查询缓慢的优化方案
文章目录 Pre引言案例何谓查询分离?何种场景下使用查询分离?查询分离实现思路1. 如何触发查询分离?方式一: 修改业务代码:在写入常规数据后,同步建立查询数据。方式二:修改业务代码:…...

Qt进阶开发:QFileSystemModel的使用
文章目录 一、QFileSystemModel的基本介绍二、QFileSystemModel的基本使用2.1 在 QTreeView 中使用2.2 在 QListView 中使用2.3 在 QTableView 中使用 三、QFileSystemModel的常用API3.1 设置根目录3.2 过滤文件3.2.1 仅显示文件3.2.2 只显示特定后缀的文件3.2.3 只显示目录 四…...

后端开发常见的面试问题
目录 编程语言 python Linux环境 web框架 数据处理与分析 数据库 图数据库 什么是图数据库?它与传统关系型数据库有什么区别? 图数据库中的节点、边和属性分别代表什么? 常见的图数据库有哪些?它们各自有什么特点&#…...

List结构之非实时榜单实战
像京东、淘宝等电商系统一般都会有热销的商品榜单,比如热销手机榜单,热销电脑榜单,这些都是非实时的榜单。为什么是非实时的呢?因为完全实时的计算和排序对于资源消耗较大,尤其是当涉及大量交易数据时。 一般来说&…...
【C语言】字符串处理函数:strtok和strerror
在C语言中,字符串处理是编程的基础之一。本文将详细讲解两个重要的字符串处理函数:strtok和strerror 一、strtok函数 strtok函数用于将字符串分割成多个子串,这些子串由指定的分隔符分隔。其原型定义如下: char *strtok(char *s…...

如何提升后端开发效率:从Spring Boot到微服务架构
在现代软件开发中,后端开发的效率直接决定了项目的成败。随着技术的快速发展,Spring Boot、微服务架构、Docker等工具和技术已经成为提升后端开发效率的核心利器。在这篇文章中,我们将探讨如何通过使用Spring Boot及微服务架构来提升开发效率…...

go语言:开发一个最简单的用户登录界面
1.用deepseek生成前端页面: 1.提问:请你用html帮我设计一个用户登录页面,要求特效采用科技感的背景渲染加粒子流动,用css、div、span标签,并给出最终合并后的代码。 生成的完整代码如下: <!DOCTYPE h…...

基于 .NET 8 + Lucene.Net + 结巴分词实现全文检索与匹配度打分实战指南
文章目录 前言一、技术选型与优势1.1 技术栈介绍1.2 方案优势 二、环境搭建与配置2.1 安装 NuGet 包2.2 初始化核心组件 三、索引创建与文档管理3.1 构建索引3.2 动态更新策略 四、搜索与匹配度排序4.1 执行搜索4.2 自定义评分算法(扩展) 五、高级优化技…...

Docker安装、配置Nacos
1.如果没有docker-compose.yml文件的话,先创建docker-compose.yml 配置文件一般长这个样子 version: 3services:nacos:image: nacos/nacos-server:v2.1.1container_name: nacos2ports:- "8848:8848"- "9848:9848"environment:- MODEstandalone…...
《Maven高级应用:继承聚合设计与私服Nexus实战指南》
一、 Maven的继承和聚合 1.什么是继承 Maven 的依赖传递机制可以一定程度上简化 POM 的配置,但这仅限于存在依赖关系的项目或模块中。当一个项目的多个模块都依赖于相同 jar 包的相同版本,且这些模块之间不存在依赖关系,这就导致同一个依赖…...

重要头文件下的函数
1、<cctype> #include<cctype>加入这个头文件就可以调用以下函数: 1、isalpha(x) 判断x是否为字母 isalpha 2、isdigit(x) 判断x是否为数字 isdigit 3、islower(x) 判断x是否为小写字母 islower 4、isupper(x) 判断x是否为大写字母 isupper 5、isa…...
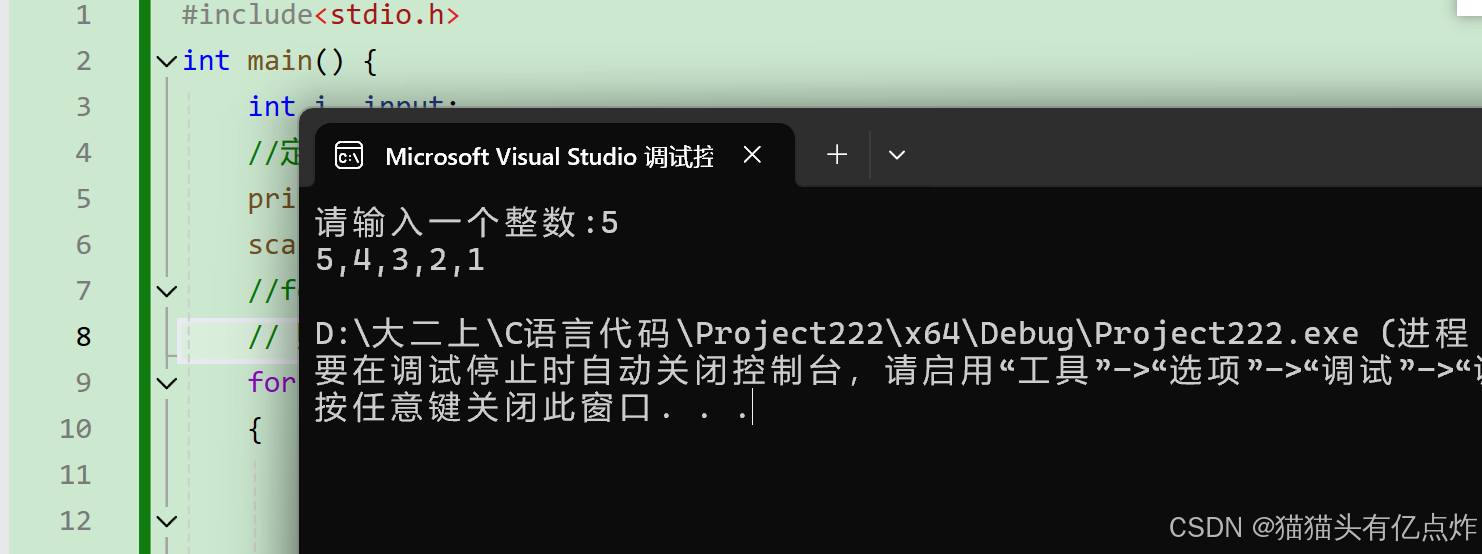
C语言数字分隔题目
一、题目引入 编写一个程序,打印出从用户输入的数字开始,递减到1的序列。要求每次打印一行,数字之间用逗号分隔,最后一个数字后面没有逗号。 二、代码展示 三、运行结果 四、思路分析 1.先用一个for循环对输入的数字进行递减 2.再对for循环里面的数字进行筛选 如果大于1 …...

DigitalOcean 发布 AMD Instinct MI300X GPU 裸金属服务器
DigitalOcean 宣布现已提供 AMD Instinct MI300X GPU,并搭载 ROCm 软件,以支持用户的 AI 任务。 在 DigitalOcean,我们致力于为你的项目提供更多选择。AMD Instinct MI300X 是目前带宽最高的 GPU 之一(5.3 TB/s 的 HBM3 内存带宽&…...
)
CentOS 7 镜像源失效解决方案(2025年)
执行 yum update 报错: yum install -y yum-utils \ > device-mapper-persistent-data \ > lvm2 --skip-broken 已加载插件:fastestmirror, langpacks Loading mirror speeds from cached hostfile Could not retrieve mirrorlist http://mirror…...

应对高并发的根本挑战:思维转变【大模型总结】
以下是对这篇技术总结的详细解析,以分步说明的形式呈现,帮助理解亿万并发场景下的核心策略与创新思维: 一、应对高并发的根本挑战:思维转变 1. 传统架构的局限 问题:传统系统追求零故障和强一致性,但在海…...

ARM-外部中断,ADC模数转换器
根据您提供的图片,我们可以看到一个S3C2440微控制器的中断处理流程图。这个流程图展示了从中断请求源到CPU的整个中断处理过程。以下是流程图中各个部分与您提供的寄存器之间的关系: 请求源(带sub寄存器): 这些是具体的…...
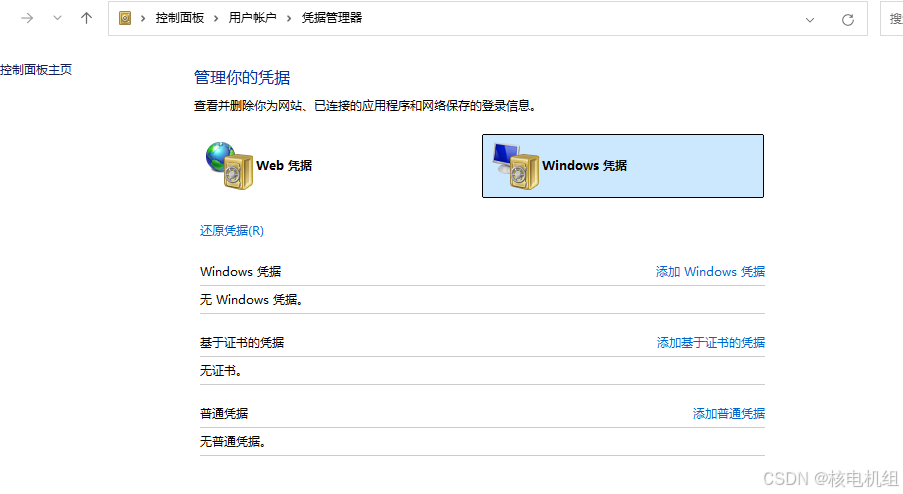
git克隆数据失败
场景:当新到一家公司,然后接手了上一个同时的电脑,使用git克隆代码一直提示无法访问,如图 原因:即使配置的新的用户信息。但是window记录了上一个同事的登录信息,上一个同事已经被剔除权限,再拉…...
自动化备份全网服务器数据平台
自动化备份全网服务器数据平台 项目背景知识 总体需求 某企业里有一台Web服务器,里面的数据很重要,但是如果硬盘坏了数据就会丢失,现在领导要求把数据做备份,这样Web服务器数据丢失在可以进行恢复。要求如下:1.每天0…...

大模型如何优化数字人的实时交互与情感表达
标题:大模型如何优化数字人的实时交互与情感表达 内容:1.摘要 随着人工智能技术的飞速发展,数字人在多个领域的应用愈发广泛,其实时交互与情感表达能力成为提升用户体验的关键因素。本文旨在探讨大模型如何优化数字人的实时交互与情感表达。通过分析大模…...

AI Agent系列(八) -基于ReAct架构的前端开发助手(DeepSeek)
AI Agent系列【八】 项目目标一、核心功能设计二、技术栈选择三、Python实现3.1 设置基础环境3.2 定义AI前端生成的类3.4 实例化3.5 Flask路由3.6 主程序执行 四、 功能测试 项目目标 开发一个能够协助HTMLJSCSS前端设计的AI Agent,通过在网页中输入相应的问题&am…...

二级索引详解
二级索引详解 二级索引(Secondary Index)是数据库系统中除主键索引外的附加索引结构,用于加速基于非主键列的查询操作。以下是关于二级索引的全面解析: 一、核心概念 特性主键索引 (Primary Index)二级索引 (Secondary Index)唯一性必须唯一可以唯一或非唯一数量每表只有…...