机器学习-04-分类算法-03KNN算法案例
实验名称
K近邻算法实现葡萄酒分类
实验目的
通过未知品种的拥有13种成分的葡萄酒,应用KNN分类算法,完成葡萄酒分类;
熟悉K近邻算法应用的一般过程;
通过合理选择K值从而提高分类得到正确率;
实验背景
本例实验采用UCI开放的葡萄酒样本数据,数据下载地址为 http://archive.ics.uci.edu/ml/datasets/Wine。该数据记录了意大利同一地区种植的葡萄酿造的3个不同品种的葡萄酒数据,包含了178组葡萄酒经过化学分析后记录的13种成分的数据。
在wine数据集中,这些数据包括了三种酒中13种不同成分的数量。文件中,每行代表一种酒的样本,共有178个样本;一共有14列,其中,第一个属性是类标识符,分别是1/2/3来表示,代表葡萄酒的三个分类。后面的13列为每个样本的对应属性的样本值。剩余的13个属性是,酒精、苹果酸、灰、灰分的碱度、镁、总酚、黄酮类化合物、非黄烷类酚类、原花色素、颜色强度、色调、稀释葡萄酒的OD280/OD315、脯氨酸。其中第1类有59个样本,第2类有71个样本,第3类有48个样本。
wine_data.csv 清洗前的数据
wine_data_clean.csv 清洗后的数据
Attrl~Attr13代表葡萄酒化学分析的13维数据列名标签,LABEL代表葡萄酒种类列名标签
实验原理
KNN算法,是一种非常直观并且容易理解和实现的有监督习方法。该算法既可以用于分类也可以用于回归。该算法的基本思想是对于给定测试样本,先基于指定的距离度量找出训练集中与其最近的k个样本(即k个近邻),然后基于这k个“邻居”的信息来进行预测。该算法被形象地描述为“近朱者赤,近墨者黑”。
通常,在分类任务中采用“投票法”,即在特征空间中选择距离待标记样本 最近的k个已标记样本,通过投票等方式,将占比最高的类别标记作为测试样本分类结果;在回归任务中使用“平均法”,即取k个邻居输出标记的平均值作为预测结果。
实验环境
ubuntu18.04
jupyter 1.0.0
python3.9.17
pandas 2.0.3
numpy 1.25.2
matplotlib 3.7.2
scikit-learn 1.3.1
建议课时
2课时
实验步骤
一、项目准备
打开一个Terminal终端安装实验所需的数据的资源包
pip install ucimlrepo
打开jupyter notebook,点击new新建一个python3文件
from ucimlrepo import fetch_ucirepo # fetch dataset
wine = fetch_ucirepo(id=109) # data (as pandas dataframes)
X = wine.data.features
y = wine.data.targets # metadata
print(wine.metadata) # variable information
print(wine.variables)
输出如下:
{'uci_id': 109, 'name': 'Wine', 'repository_url': 'https://archive.ics.uci.edu/dataset/109/wine', 'data_url': 'https://archive.ics.uci.edu/static/public/109/data.csv', ...', 'citation': None}}name role type demographic \
0 class Target Categorical None
1 Alcohol Feature Continuous None
2 Malicacid Feature Continuous None
3 Ash Feature Continuous None
4 Alcalinity_of_ash Feature Continuous None
5 Magnesium Feature Integer None
6 Total_phenols Feature Continuous None
7 Flavanoids Feature Continuous None
8 Nonflavanoid_phenols Feature Continuous None
9 Proanthocyanins Feature Continuous None
10 Color_intensity Feature Continuous None
11 Hue Feature Continuous None
12 0D280_0D315_of_diluted_wines Feature Continuous None
13 Proline Feature Integer None description units missing_values
0 None None no
1 None None no
2 None None no
3 None None no
4 None None no
5 None None no
6 None None no
...
10 None None no
11 None None no
12 None None no
13 None None no
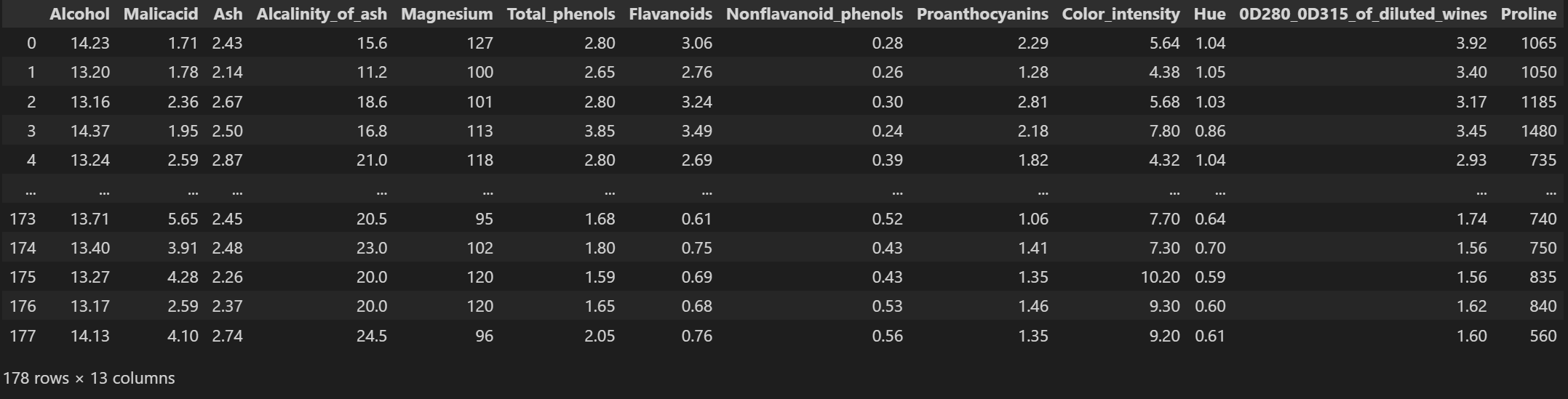
查看特征数据
X
输出为:
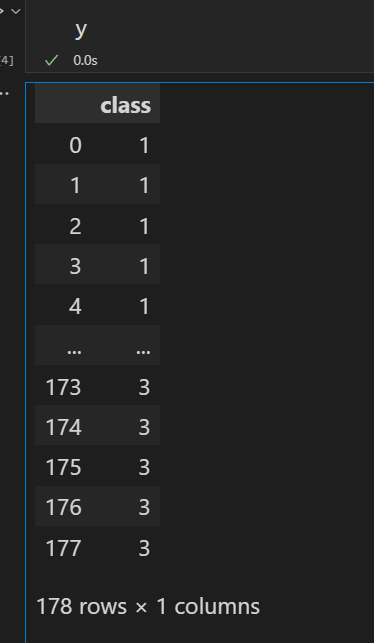
查看标签数据
y
输出为:
二.导入依赖
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
设置列标签名称,Al至A13代表葡萄酒化学分析的13维数据列名标签,即13种成分,LABEL代表葡萄酒种类列名标签。
构建列名的映射
# 构建列名的映射
cols_dict={}
num=0
for i in X.columns:num = num+1# print(i," ","A"+str(num))cols_dict[i]="A"+str(num)
print(cols_dict)输出如下
{‘Alcohol’: ‘A1’, ‘Malicacid’: ‘A2’, ‘Ash’: ‘A3’, ‘Alcalinity_of_ash’: ‘A4’, ‘Magnesium’: ‘A5’, ‘Total_phenols’: ‘A6’, ‘Flavanoids’: ‘A7’, ‘Nonflavanoid_phenols’: ‘A8’, ‘Proanthocyanins’: ‘A9’, ‘Color_intensity’: ‘A10’, ‘Hue’: ‘A11’, ‘0D280_0D315_of_diluted_wines’: ‘A12’, ‘Proline’: ‘A13’}
替换列名
X = X.rename(columns=cols_dict)
X
输出如下:

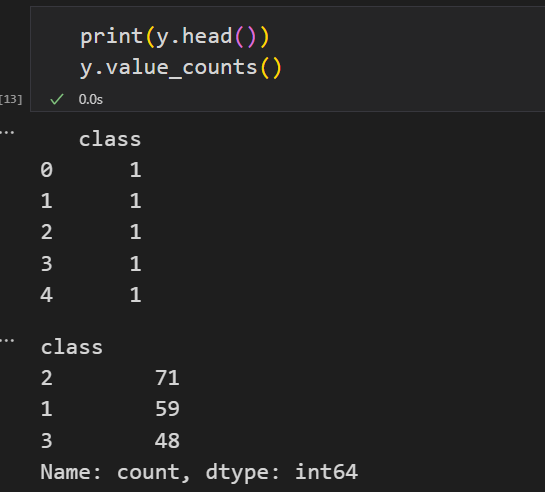
查看y的值
print(y.head())
y.value_counts()
输出如下
构建列名的映射
# 构建列名的映射
cols_dict={}
num=0
for i in X.columns:num = num+1# print(i," ","A"+str(num))cols_dict[i]="A"+str(num)
cols_dict["class"]="LABEL"
print(cols_dict)
输出入下
{‘Alcohol’: ‘A1’, ‘Malicacid’: ‘A2’, ‘Ash’: ‘A3’, ‘Alcalinity_of_ash’: ‘A4’, ‘Magnesium’: ‘A5’, ‘Total_phenols’: ‘A6’, ‘Flavanoids’: ‘A7’, ‘Nonflavanoid_phenols’: ‘A8’, ‘Proanthocyanins’: ‘A9’, ‘Color_intensity’: ‘A10’,
‘Hue’: ‘A11’, ‘0D280_0D315_of_diluted_wines’: ‘A12’, ‘Proline’: ‘A13’, ‘class’: ‘LABEL’}
拼接X和y为df
df = pd.concat([X,y],axis=1)
df
输出如下:

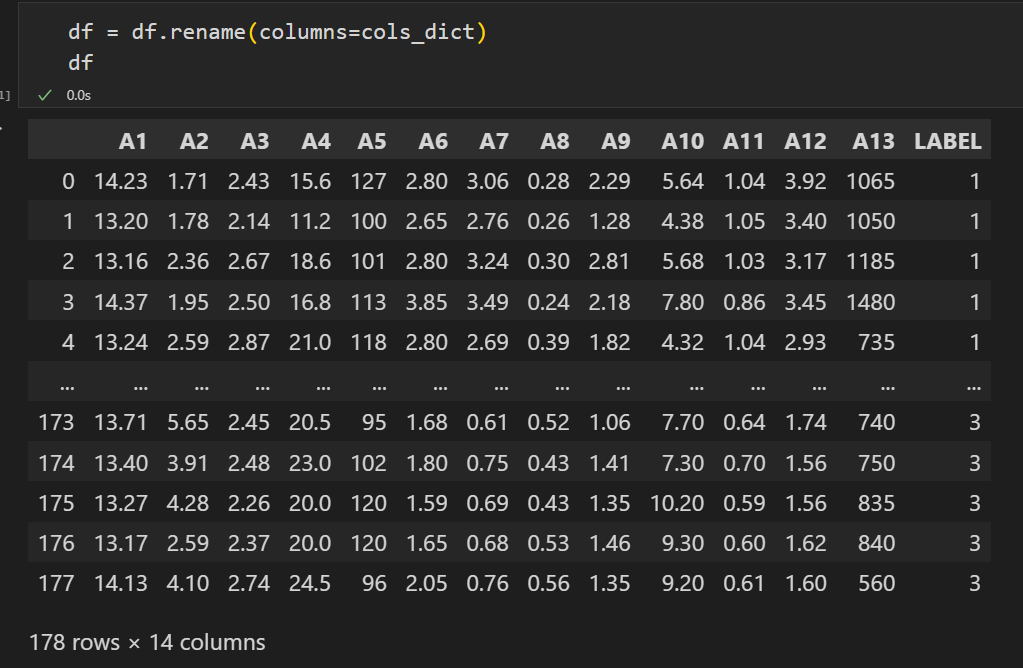
重命名df列名
df = df.rename(columns=cols_dict)
df
输出如下:
三.查看样本基本信息
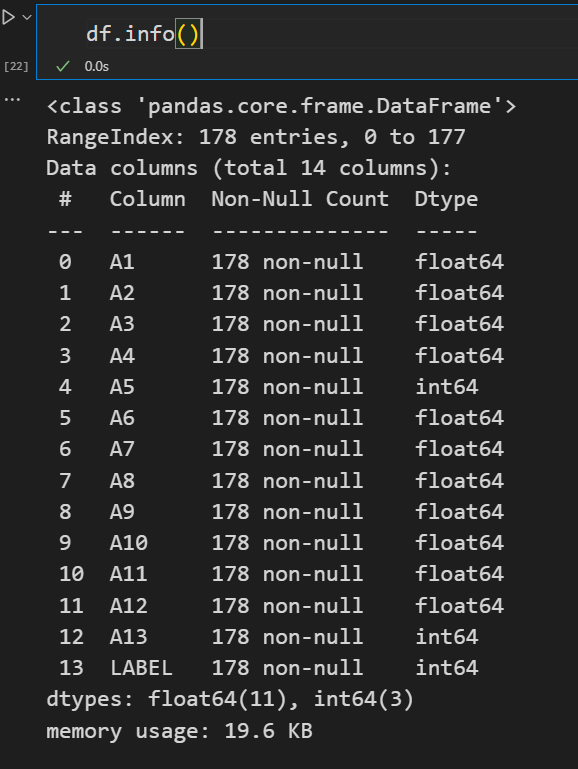
#info()函数用于获取 DataFrame 的简要摘要
df.info()
通过pandas的info()函数查看样本数据的列名、无有空数据、数据类型。
代码为dataset.info(),运行结果如图所示:此图展示了数据的基本信息。
四. 查看数据大致分布
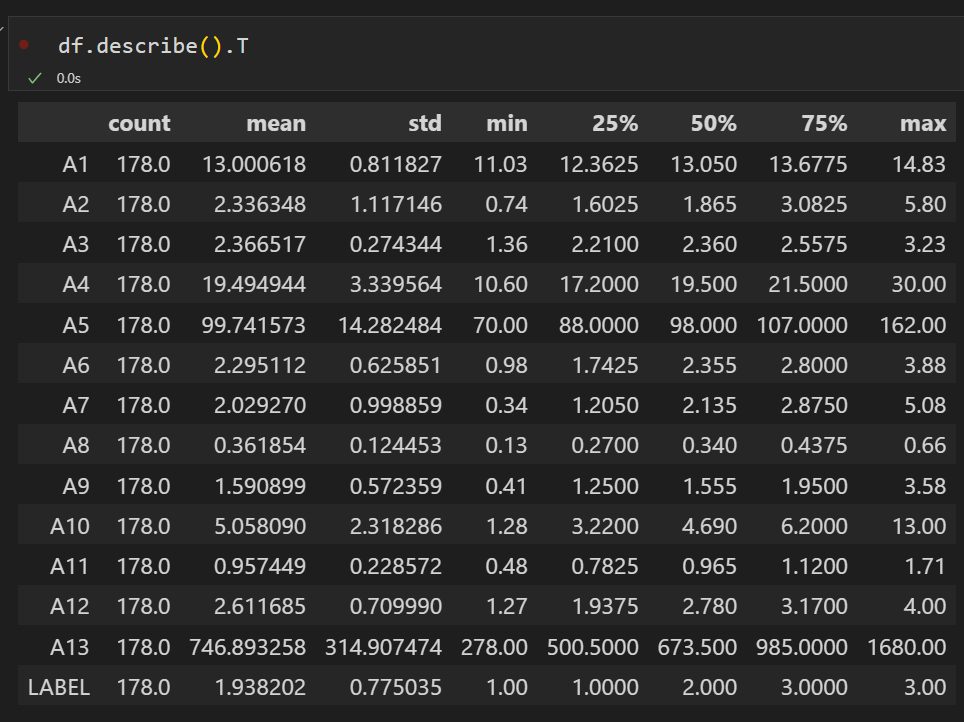
通过pandas的describe ()函数查看样本数据的平均值、方差、最小值25%分位数、50%分位数、75%分位数和最大值,以便了解数据大致分布。
df.describe().T
五.绘制箱线图进行数据分析
为进一步对样本数据的分布进行可视化分析和异常值探测,我们有必要了解一下箱形图。箱形图因形状如箱子而得名,又称为盒须图、盒式图、盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图。
了解箱形图的含义后,对数据进行可视化。通过matplotlib绘制箱线图进一步分析葡萄酒13种成分的统计情况,以便发现样本中有无异常数据,箱形图的可视化代码如下:设置相关图形参数,unicode_minus为正常显示负号,字体大小为12,风格为seaborn的darkgrid,类型kind为箱形图box,且包含子图,不共享x、y坐标轴等。然后展示图片,show。
fig = plt.figure(figsize=(15,10))
# print(plt.style.available)
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.size']=12
plt.style.use('seaborn-v0_8-darkgrid')
p=df.plot(kind='box',subplots=True,layout=(5,5),sharex=False, sharey=False,figsize=(10,10))
plt.show()

通过箱线图展示了葡萄酒13种成分(Al~A13)的数据分布情况,其上四分位、下四分位和中位线的分布不均匀,在A2~A5、A9~A11成分中存在异常数据。
使用matplotlib绘图
fig = plt.figure(figsize=(15,10))
ax = fig.subplots(3,5)
# print(type(ax[0][0]))
# 由于 ax 是一个二维数组,需要使用双重循环遍历
row, col = ax.shape
print(row, col) # 3 5
num = 0
for i in df.columns:if num >= row * col:break# // 表示整除,% 表示取余r = num // colc = num % colax[r, c].boxplot(df[i])num += 1
输出如下:

六.异常值检测
通过箱线图的可视化分析可知,样本数据中是存在异常值的。先使用quantile()计算分位数,然后结合箱线图解释中异常值的定义编码实现。
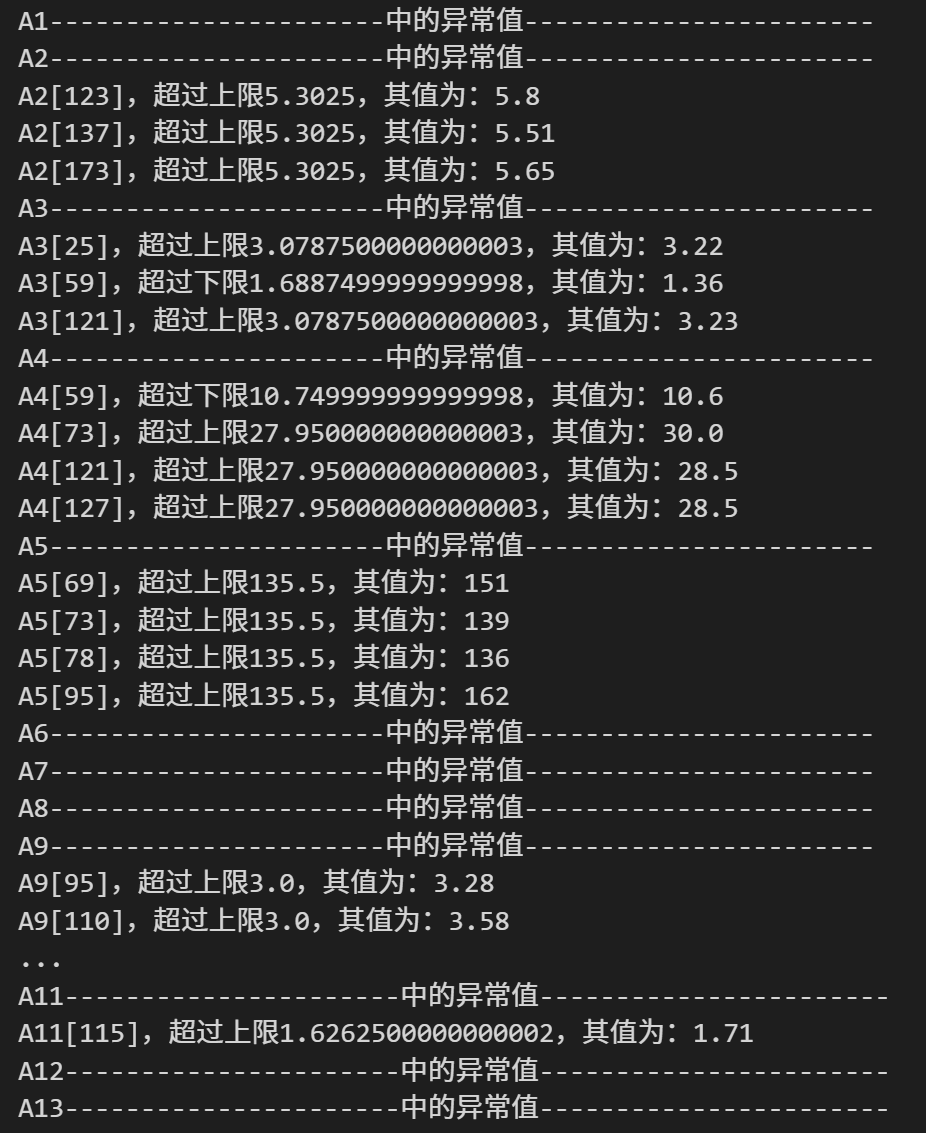
for i in range(1,14):columnName='A{0}'.format(i)columsDatas=df[columnName]#上四分位数qu=columsDatas.quantile(q=0.75)# 下四分位数 ql=columsDatas.quantile(q=0.25)# 计算四分位间距iqr=qu-ql# 上限up = qu + 1.5 * iqr# 下限low = ql - 1.5 * iqrprint(columnName+"中的异常值".center(50,"-"))for (index,value) in zip(columsDatas.index,columsDatas.values):if value>up:print("{0}[{1}],超过上限{2},其值为:{3}".format(columnName,index,up,value))else:if value<low:print("{0}[{1}],超过下限{2},其值为:{3}".format(columnName,index,low,value))通过打印异常值可以看出,A2、A3、A4和A5中存在异常值,且都一一展示其数值
七.数据清洗
此时,需要对异常值进行处理。处理的方法与业务有直接的关系,如果去掉数据对应用模型本身没有影响,则可去掉异常值。否则,需要依据一定的算法对异常值进行更改、替换,如采用邻近数据的平均值、专家的印象值等。这里依据异常样本数据的前后值,进行人为近似估计更改这些异常值,例如,A2异常值5.8前后的数据分别为4.43和4.31,所以估计该异常值为4.37,取前后数据的平均值。代码如下
hasErrorData=False
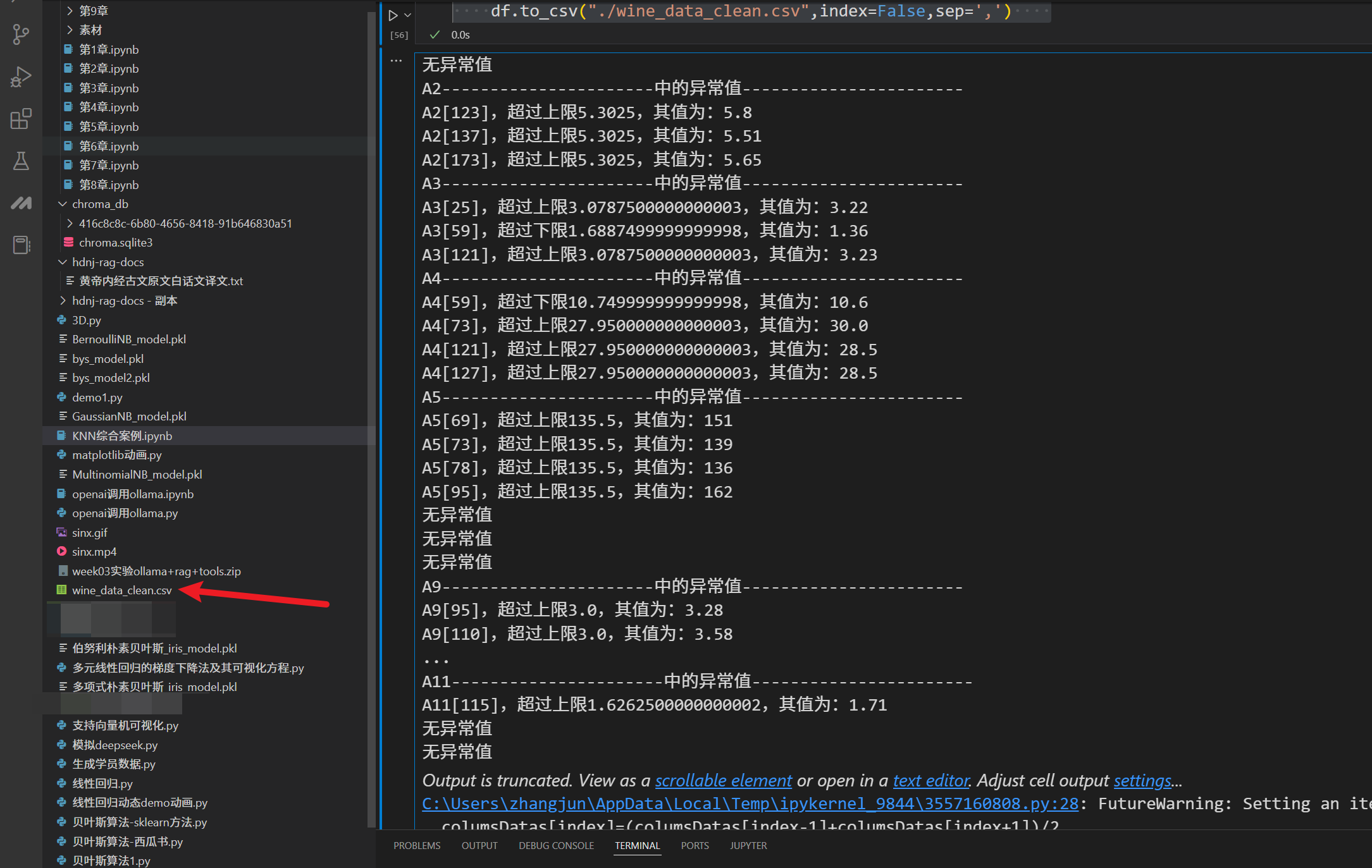
for i in range(1,14):columnName='A{0}'.format(i)columsDatas=df[columnName].copy()#上四分位数qu=columsDatas.quantile(q=0.75)# 下四分位数ql=columsDatas.quantile(q=0.25)# 计算四分位间距iqr=qu-ql# 上限up = qu + 1.5 * iqr# 下限low = ql - 1.5 * iqrif any(columsDatas>up) or any( columsDatas<low):print(columnName+"中的异常值".center(50,"-"))for (index,value) in zip(columsDatas.index,columsDatas.values):if value>up:print("{0}[{1}],超过上限{2},其值为:{3}".format(columnName,index,up,value))else:if value<low:print("{0}[{1}],超过下限{2},其值为:{3}".format(columnName,index,low,value))for (index,value) in zip(columsDatas.index,columsDatas.values):if value>up or value< low:#使用前后值方式对数据进行清理columsDatas[index]=(columsDatas[index-1]+columsDatas[index+1])/2#将清理后的数据写回DataFrame中df[columnName]=columsDatashasErrorData=Trueelse:print('无异常值')#如有异常数据,则将清洗后的数据另存为wine_data_clean.csv
if hasErrorData:df.to_csv("./wine_data_clean.csv",index=False,sep=',')
输出如下
八.数据标准化,从清洗后的文件中获取数据
数据清洗完毕后,则是数据标准化,在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。数据标准化的目的就是在不影响各维度间数量关系的情况下,收敛数据间大小的差异(如将数据映射到0~1范围之内)。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
通过数据切片分别获得葡萄酒的13个特征数据,以及葡萄酒的分类数据,然后数据标准化处理,获得13个特征数据的标准化数据。
names =[ 'A1', 'A2', 'A3', 'A4', 'A5', 'A6', 'A7','A8', 'A9', 'A10', 'A11', 'A12', 'A13', 'LABEL']
#此处使用已清洗过的数据
df=pd.read_csv('./wine_data_clean.csv',names=names,skiprows=1)
# 获得葡萄酒的13个特征数据
x_datas=df.iloc[:,:13]
# 获得葡萄酒的分类数据
y_datas=df.iloc[:,13]
# 数据标准化
sc=StandardScaler()
sc.fit(x_datas)
x_datas=sc.transform(x_datas)
# x_datas=sc.fit_transform(x_datas) 不要这么用 要获得fit的结果
print(x_datas[0])
""" [ 1.51861254 -0.56906271 0.26128041 -1.24987992 2.28925387 0.808997391.03481896 -0.65956311 1.3408019 0.299684 0.39346131 1.847919571.01300893]
"""
x_datas.shape # (178, 13)
输出如下:

九.分割数据集
为了提高分类的准确率,需要对训练集和测试集进行划分。本节将数据集按1:3的分割,其中25%作为测试集,75%作为训练集。分割后的数据集应用于KNN模型,通过性能分析及交叉验证,求取最合理的k值。
代码如下:首先通过train_test_split函数分割数据,并通过序列解包的方式赋值给变量。
# 此处特别注意 x_train,x_test,y_train,y_test的书写顺序
x_train,x_test,y_train,y_test= train_test_split(x_datas,y_datas,test_size=0.25,random_state=9)
print('x_train训练集样本数:',len(x_train))
print('y_train训练集样本数:',len(y_train))
print('x_test测试集样本数:',len(x_test))
print('y_test测试集样本数:',len(y_test))
通过数据打印可以看到,训练数据与测试数据的数量分别是133和45,符合1:3的分割比例。
x_train训练集样本数: 133
y_train训练集样本数: 133
x_test测试集样本数: 45
y_test测试集样本数: 45
十.建立KNN分类模型
模型这里还是采用KNN分类模型,基于欧氏距离,建立模型,并使用x_test数据测试模型性能,代码如下,邻近值设置为3
knn=KNeighborsClassifier(n_neighbors=3)
knn.fit(x_train,y_train)
print('准确率为:',knn.score(x_test,y_test))
输出如下:
准确率为1.0
十一.利用5折交叉验证寻找最佳k值
刚才的代码只是给定一个邻居数k的结果,但是我们不知道的是,这k是不是最佳值。因此我们再利验证寻找最佳k值。
首先将k取值范围设定在用10折交叉1到15之间,间隔为2,然后定义k_scores列表变量,用于存储验证结果。接下来则是针对每个k值进行KNN分类,并通过cross_val_score函数进行10折验证,计算k的评分,并保存结果。
# k_range=1,3,5...19
k_range=list(range(1,16,2))
# 用于存放第一个k值所对应的评分
k_scores=[]
for k in k_range:#使用k定义分类器testKnn=KNeighborsClassifier(k)#使用5折验证,计算k的评分testKnnScore= cross_val_score(testKnn,x_train,y_train,cv=10)#取5折评分结果的均值k_scores.append(testKnnScore.mean())
print(*zip(k_range,k_scores))
程序运行结果如图所示,从数据中容易发现,当k值为11时,评分最高。
输出如下:
(1, 0.9406593406593406) (3, 0.9483516483516483) (5, 0.9703296703296704) (7, 0.9631868131868131) (9, 0.9626373626373625) (11, 0.9774725274725276) (13, 0.9697802197802197) (15, 0.962087912087912)
十二.对验证结果进行可视化
如果数据较多,查看结果会比较困难,那么我们可以通过可视化方式展示结果。
# 指定默认字体:解决plot不能显示中文问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.size']=12
plt.xticks(k_range)
plt.ylim(0.9,1)
plt.xlabel('k取值')
plt.ylabel('交叉验证的准确率')
plt.scatter(k_range,k_scores)
plt.plot(k_range,k_scores)
for (k,score) in zip(k_range,k_scores):plt.text(k,score,round(score,2))
plt.grid(visible=True,axis='both',linestyle='--')
plt.show()
如果数据较多,查看结果会比较费劲,那么我们可以通过可视化方式展示结果。

十三.葡萄酒分类预测
测试全部数据
经过之前葡萄酒数据的分析与验证,针对本次样本数据,当k=11时,分类效果较好。下面基于欧氏距离建模,使用Sklearn工具进行葡萄酒KNN分类器的程序编写与实现。
k=11
knn=KNeighborsClassifier(n_neighbors=k)
knn.fit(x_train,y_train.values.ravel())
y_predict=knn.predict(x_test)
print('k=',k,'时,x_test数据集葡萄酒预测分类为:')
print(y_predict)
print('k=',k,'时,x_test数据集葡萄酒实际分类为:')
print(y_test.values)
代码运行结果如图所示,当k=11时,将测试数据的预测分类与实际分类都展示了出来。

测试单个数据
names =[ 'A1', 'A2', 'A3', 'A4', 'A5', 'A6', 'A7','A8', 'A9', 'A10', 'A11', 'A12', 'A13', 'LABEL']
#此处使用已清洗过的数据
df=pd.read_csv('./wine_data_clean.csv',names=names,skiprows=1)
# 获得葡萄酒的13个特征数据
x_datas_one=df.iloc[0:1,:13]
# 获得葡萄酒的分类数据
y_datas_one=df.iloc[0:1,13]
print(x_datas_one)
print("----")
print(y_datas_one)输出如下:
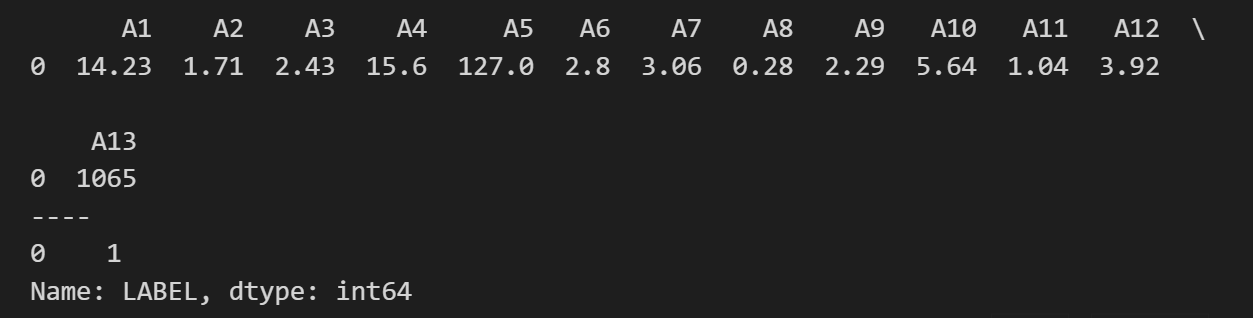
处理特征数据
# 数据标准化
# 数据标准化
# sc=StandardScaler()
x_datas_one=sc.transform(x_datas_one)
print(x_datas_one)
输出如下:
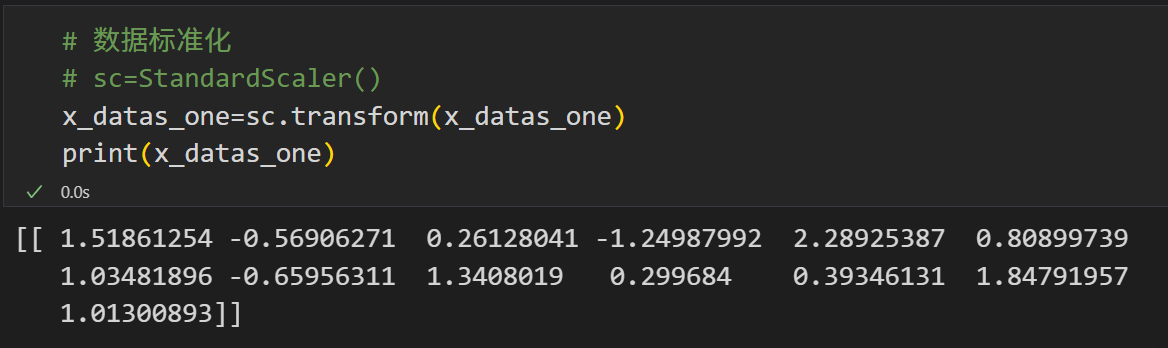
基于模型预测结果
knn.predict(x_datas_one)
输出如下:
array([1], dtype=int64)
实验总结
本次实验学习了K近邻算法应用的一般过程,包含数据准备、清洗、标准化、建模与结果分析。最终的KNN葡萄酒分类器模型,在基于欧氏距离及k=11的情况下,分类结果与实际数据分类情况100%吻合。实际项目中,很难遇到这种情况,也说明本次数据具有极强的代表性。希望同学们课下多加练习。
相关文章:
机器学习-04-分类算法-03KNN算法案例
实验名称 K近邻算法实现葡萄酒分类 实验目的 通过未知品种的拥有13种成分的葡萄酒,应用KNN分类算法,完成葡萄酒分类; 熟悉K近邻算法应用的一般过程; 通过合理选择K值从而提高分类得到正确率; 实验背景 本例实验…...

AIP-213 通用组件
编号213原文链接AIP-213: Common components状态批准创建日期2018-08-17更新日期2018-08-17 根据AIP-215规定,除使用“通用组件”包之外,API必须是独立的。通用组件包是给多个API使用的。 通用组件包有两种类型: 组织特定的通用组件&#…...
:用 Go 写一个 RESTful API 服务!)
Go语言-初学者日记(七):用 Go 写一个 RESTful API 服务!
👷 实践是最好的学习方式!这一篇我们将用 Go Gin 框架从零开始开发一个用户管理 API 服务。你将学到: 如何初始化项目并引入依赖如何组织目录结构如何用 Gin 实现 RESTful 接口如何通过 curl 测试 API进阶功能拓展建议 🧰 一、项…...
Java 搭建 MC 1.18.2 Forge 开发环境
推荐使用 IDEA 插件 Minecraft Development 进行创建项目 创建完成后即可进行 MOD 开发。 但是关于 1.18.2 的开发教程太少,因此自己研究了一套写法,写法并非是最优的但是是探索开发MOD中的一次笔记和记录 GITHUB: https://github.com/zimoyin/zhenfa…...
计算机网络知识点汇总与复习——(三)数据链路层
Preface 计算机网络是考研408基础综合中的一门课程,它的重要性不言而喻。然而,计算机网络的知识体系庞大且复杂,各类概念、协议和技术相互关联,让人在学习时容易迷失方向。在进行复习时,面对庞杂的的知识点,…...

Verilog HDL 100道面试题及参考答案
目录 Verilog HDL 的四种基本逻辑值是什么? 关键字 reg 和 wire 的主要区别是什么? 解释阻塞赋值(=)与非阻塞赋值(<=)的区别,并举例说明。 如何声明一个双向端口(inout)? 位拼接操作符是什么?举例说明其用法。 拼接信号和常量 拼接常量和信号 重复拼接 以…...
渗透测试流程和模拟测试day--5--Windows和Linux的提权)
内网(域)渗透测试流程和模拟测试day--5--Windows和Linux的提权
前景: 小知识: 认识一下土豆家族 是指一系列利用 Windows 系统漏洞实现提权的工具或方法,起源于 JuicyPotato。这些工具大多利用 COM 对象和服务中的权限提升漏洞,主要用于在 Windows 环境中从中低权限(如普通用户&…...
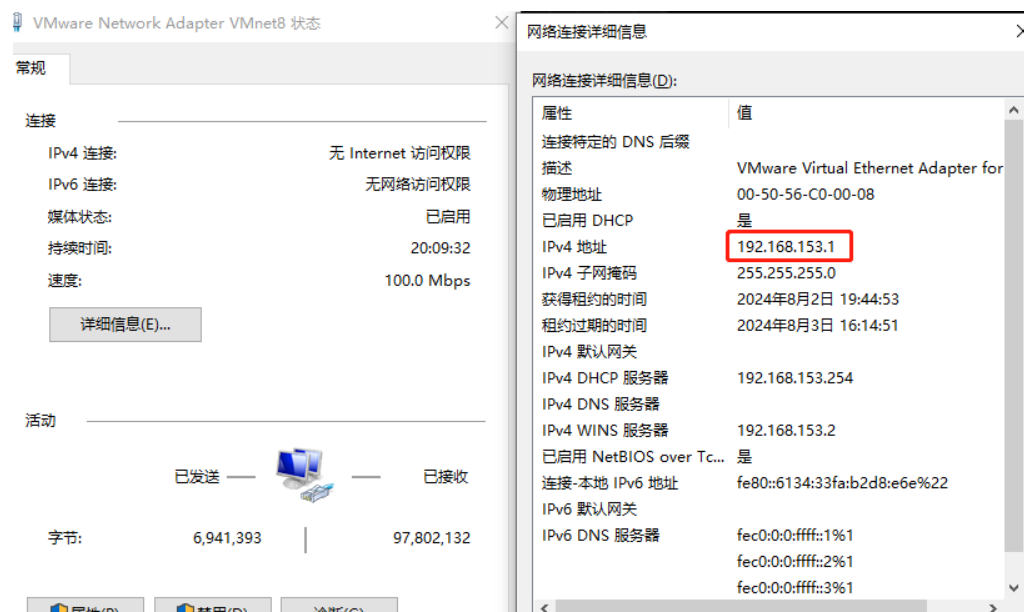
主机和虚拟机间的网络通信
参考:Vmware虚拟机三种网络模式详解 - 林加欣 - 博客园 (cnblogs.com) 虚拟机配置 一般额外配置有线和无线网络 桥接模式 虚拟机和主机之间是同一个网络,用一根线连接了虚拟机和物理机的网卡,可以选择桥接的位置,默认情况下是自动桥接&…...
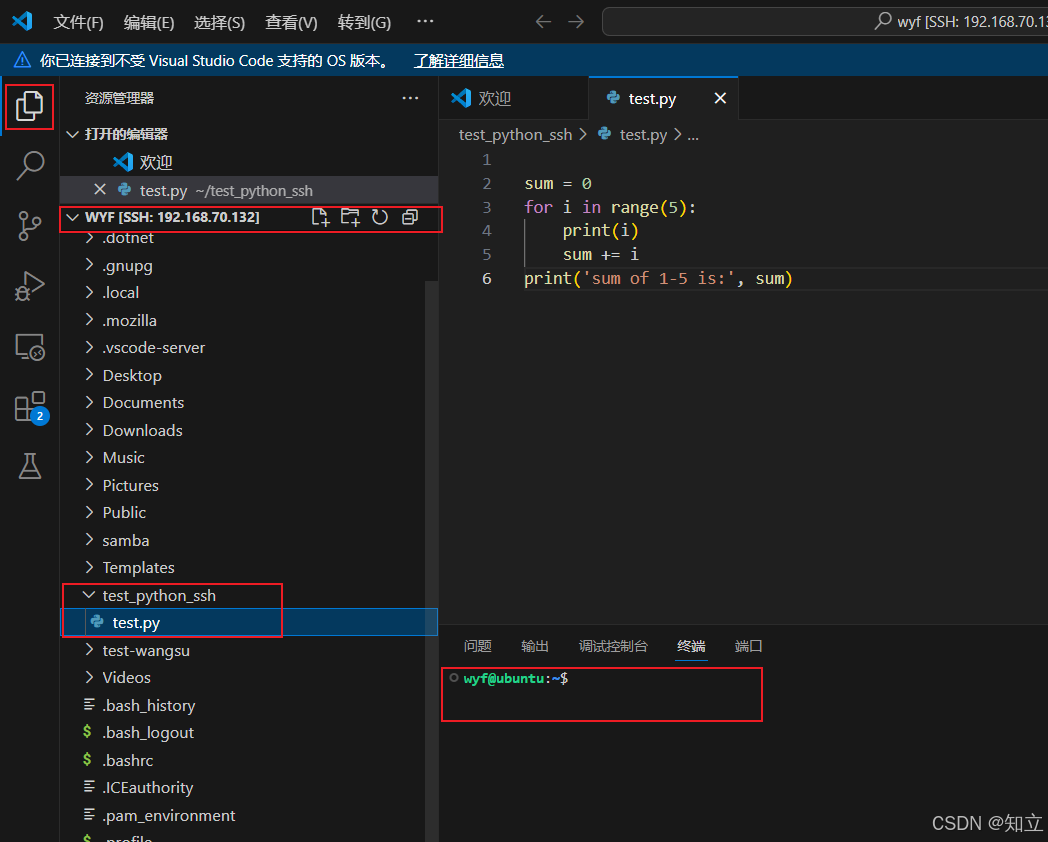
嵌入式Linux开发环境搭建,三种方式:虚拟机、物理机、WSL
目录 总结写前面一、Linux虚拟机1 安装VMware、ubuntu18.042 换源3 改中文4 中文输入法5 永不息屏6 设置 root 密码7 安装 terminator8 安装 htop(升级版top)9 安装 Vim10 静态IP-虚拟机ubuntu11 安装 ssh12 安装 MobaXterm (SSH)…...
说清楚单元测试
在团队中推行单元测试的时候,总是会被成员问一些问题: 这种测试无法测试数据库的SQL(或者是ORM)是否执行正确?这种测试好像没什么作用?关联的对象要怎么处理呢?…借由本篇,来全面看一看单元测试。 单元测试是软件开发中一种重要的测试方法,其核心目的是验证代码的最小…...

如何分析 jstat 统计来定位 GC?
全文目录: 开篇语前言摘要概述jstat 的核心命令与参数详解基本命令格式示例 jstat 输出解读主要字段含义 典型 GC 问题分析案例案例 1:年轻代 GC 过于频繁案例 2:老年代发生频繁 Full GC案例 3:元空间(Metaspace&#…...
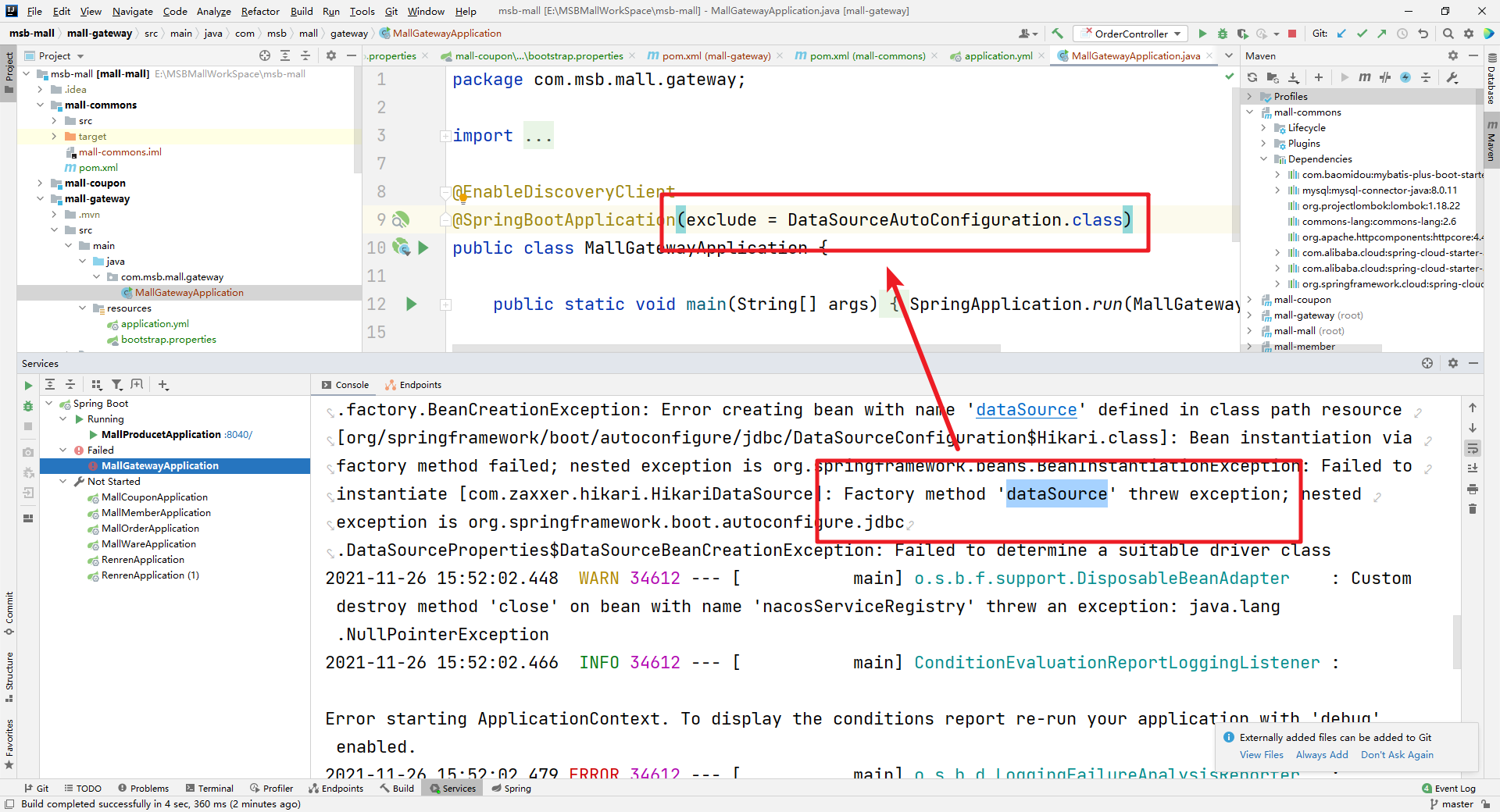
电商---part02 项目环境准备
1.虚拟机环境 可以通过VMWare来安装,但是通过VMWare安装大家经常会碰到网络ip连接问题,为了减少额外的环境因素影响,Docker内容会通过VirtualBox结合Vagrant来安装虚拟机。 VirtualBox官网:https://www.virtualbox.org/ Vagran…...
LabVIEW提升程序响应速度
LabVIEW 程序在不同计算机上的响应速度可能存在较大差异,这通常由两方面因素决定:计算机硬件性能和程序本身的优化程度。本文将分别从硬件配置对程序运行的影响以及代码优化方法进行详细分析,帮助提升 LabVIEW 程序的执行效率。 一、计算机硬…...

工业领域网络安全技术发展路径洞察报告发布 | FreeBuf咨询
工业网络安全已成为国家安全、经济稳定和社会运行的重要基石。随着工业互联网、智能制造和关键基础设施的数字化升级,工业系统的复杂性和互联性显著提升,针对工业领域的网络攻击朝着目标多样化、勒索攻击产业化、攻击技术持续升级的方向发展,…...

WPF 登录页面
效果 项目结构 LoginWindow.xaml <Window x:Class"PrismWpfApp.Views.LoginWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml"xmlns:d"http://schemas.…...

【数学建模】动态规划算法(Dynamic Programming,简称DP)详解与应用
动态规划算法详解与应用 文章目录 动态规划算法详解与应用引言动态规划的基本概念动态规划的设计步骤经典动态规划问题1. 斐波那契数列2. 背包问题3. 最长公共子序列(LCS) 动态规划的优化技巧动态规划的应用领域总结 引言 动态规划(Dynamic Programming,简称DP)是一…...

leetcode-代码随想录-链表-移除链表元素
题目 链接:203. 移除链表元素 - 力扣(LeetCode) 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 输入:head [1,2,6,3,4,5,6], val 6 …...

低成本训练垂直领域文娱大模型的技术路径
标题:低成本训练垂直领域文娱大模型的技术路径 内容:1.摘要 在文娱产业快速发展且对智能化需求日益增长的背景下,为降低垂直领域文娱大模型的训练成本,本研究旨在探索低成本训练的有效技术路径。采用对现有开源模型进行微调、利用轻量化模型架构以及优化…...

Spring Boot 3.4.3 基于 Caffeine 实现本地缓存
在现代企业级应用中,缓存是提升系统性能和响应速度的关键技术。通过减少数据库查询或复杂计算的频率,缓存可以显著优化用户体验。Spring Boot 3.4.3 提供了强大的缓存抽象支持,而 Caffeine 作为一款高性能的本地缓存库,因其优异的吞吐量和灵活的配置,成为许多开发者的首选…...

手机为电脑提供移动互联网络的3种方式
写作目的 在当今数字化时代,电脑已成为人们日常工作和生活中不可或缺的工具,而网络连接更是其核心功能之一。无论是处理工作任务、进行在线学习、还是享受娱乐资源,稳定的网络环境都是保障这些活动顺利开展的关键。然而,在实际使用过程中,电脑网络驱动故障时有发生,这可…...

论文阅读Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
原文框架图: 官方代码: https://github.com/phizaz/diffae/blob/master/interpolate.ipynb 主要想记录一下模型的推理过程 : %load_ext autoreload %autoreload 2 from templates import * device cuda:1 conf ffhq256_autoenc() # pri…...

Python集合(五)
集合一: 跟字典一样,最大的特性就是唯一性,集合中的所有的元素都是独一无二的,并且还是无序的 创建集合 第一种: 第二种:集合推导式: 第三种:使用类型构造器: 集合是无…...
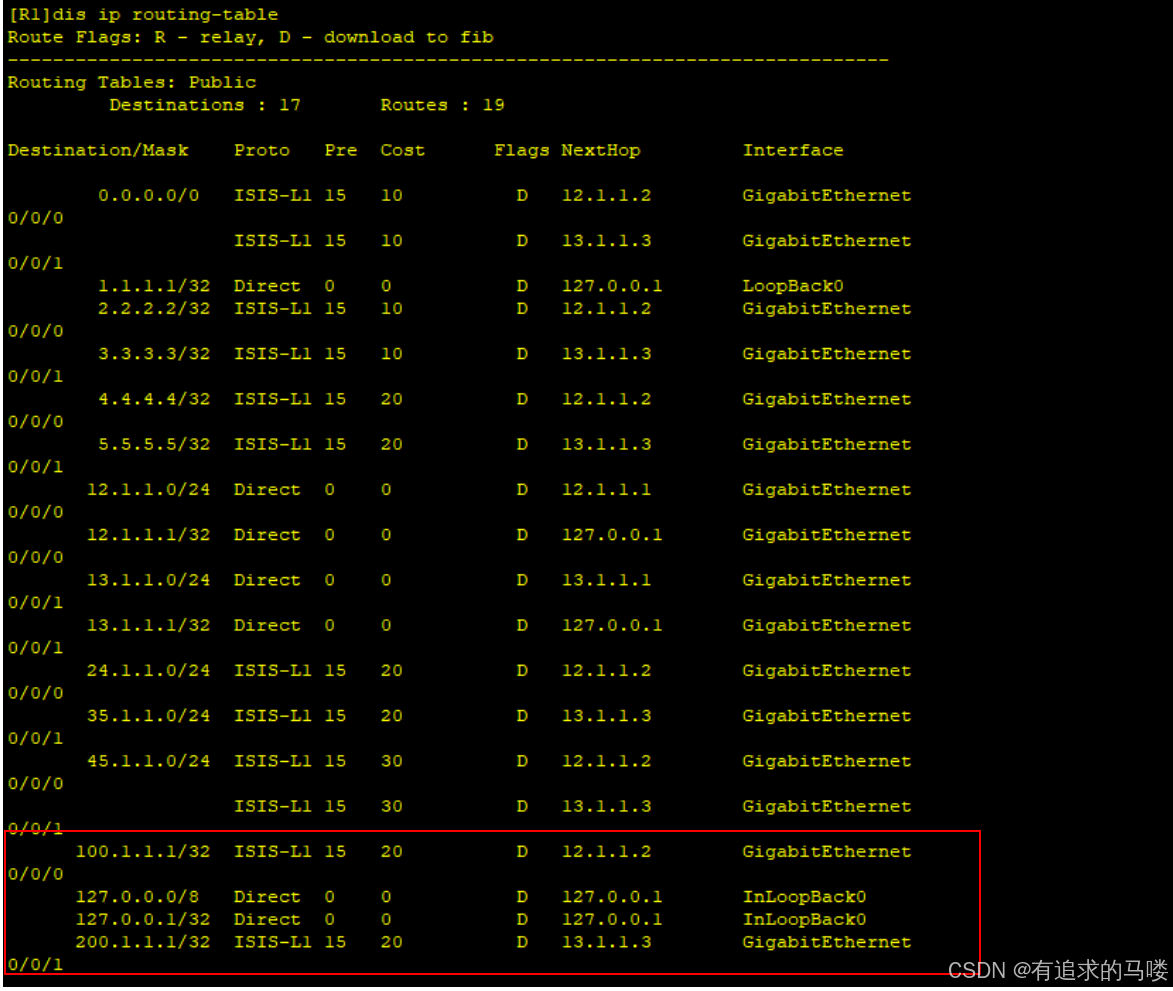
ISIS多区域配置
一、什么是ISIS多区域 ISIS(Intermediate System to Intermediate System)多区域是指网络被划分为多个逻辑区域(Areas),不同区域之间通过特定的ISIS路由器(Level-1-2)进行路由交互。多区域设计提…...

2025-04-04 Unity 网络基础5——TCP分包与黏包
文章目录 1 分包与黏包2 解决方案2.1 数据接口2.2 定义消息2.3 NetManager2.4 分包、黏包处理 3 测试3.1 服务端3.2 客户端3.3 直接发送3.4 黏包发送3.5 分包发送3.6 分包、黏包发送3.7 其他 1 分包与黏包 分包、黏包指在网络通信中由于各种因素(网络环境、API …...

Leetcode——150. 逆波兰表达式求值
题解一 思路 和上一期1047. 删除字符串中的所有相邻重复项没差太多,基本思想都一样,就是读取输入的数据,如果是运算符,就进行相应的运算,然后把运算结果压栈。 代码 class Solution {public int evalRPN(String[] …...
)
【Node】一文掌握 Express 的详细用法(Express 备忘速查)
文章目录 入门Hello Worldexpress -hexpress()RouterApplicationRequest属性方法 Response属性方法 示例RouterResponseRequestres.end()res.json([body])app.allapp.deleteapp.disable(name)app.disabled(name)app.engine(ext, callback)app.listen([port[, host[, backlog]]]…...
chromium魔改——绕过无限debugger反调试
在进行以下操作之前,请确保已完成之前文章中提到的 源码拉取及编译 部分。 如果已顺利完成相关配置,即可继续执行后续操作。 在浏览器中实现“无限 debugger”的反调试技术是一种常见的手段,用于防止他人通过开发者工具对网页进行调试或逆向…...

Spring 核心技术解析【纯干货版】- XVI:Spring 网络模块 Spring-WebMvc 模块精讲
在现代 Web 开发中,高效、稳定、可扩展的框架至关重要。Spring WebMvc 作为 Spring Framework 的核心模块之一,为开发人员提供了强大的 MVC 体系支持,使得 Web 应用的构建更加便捷和规范。无论是传统的 JSP 视图渲染,还是基于 RES…...

【GPT入门】第33课 从应用场景出发,区分 TavilyAnswer 和 TavilySearchResults,代码实战
【GPT入门】第33课 从应用场景出发,区分 TavilyAnswer 和 TavilySearchResults,代码实战 1. 区别应用场景 2. 代码使用3.代码执行效果 在langchain_community.tools.tavily_search中,TavilyAnswer和TavilySearchResults有以下区别和应用场景&…...
JS dom修改元素的style样式属性
1通过样式属性修改 第三种 toggle有就删除 没就加上...