决策树实战:用Python实现智能分类与预测
目录
一、环境准备
二、数据加载与探索
三、数据预处理
四、决策树模型构建
五、模型可视化(生成决策树结构图)
六、模型预测与评估
七、超参数调优(网格搜索)
八、关键知识点解析
九、完整项目开发流程
十、常见问题解决方案
一、环境准备
# 安装必要库
pip install scikit-learn pandas matplotlib graphviz pydotplus二、数据加载与探索
import pandas as pd
from sklearn.datasets import load_iris# 加载鸢尾花数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target# 查看数据基本信息
print(f"数据维度: {df.shape}")
print("\n前5行数据:")
print(df.head())
print("\n类别分布:")
print(df['target'].value_counts())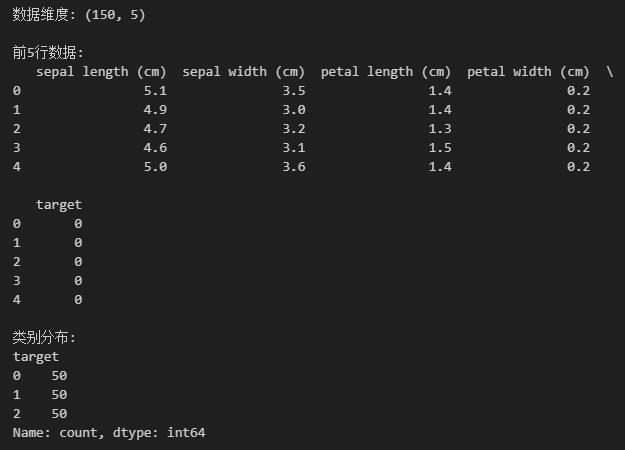
三、数据预处理
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 特征工程
X = df.iloc[:, :-1]
y = df['target']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 标准化处理
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) # 注意:使用训练集的scaler四、决策树模型构建
from sklearn.tree import DecisionTreeClassifier# 初始化决策树分类器
dt_clf = DecisionTreeClassifier(criterion='gini', # 分裂标准(基尼系数)max_depth=3, # 树的最大深度min_samples_split=2, # 节点分裂最小样本数random_state=42
)# 模型训练
dt_clf.fit(X_train_scaled, y_train)
五、模型可视化(生成决策树结构图)
from sklearn.tree import export_graphviz
import pydotplus
from IPython.display import Image# 导出决策树为DOT格式
dot_data = export_graphviz(dt_clf,out_file=None,feature_names=iris.feature_names,class_names=iris.target_names,filled=True,rounded=True,special_characters=True
)# 生成可视化图形
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png()) # 在Jupyter中显示图片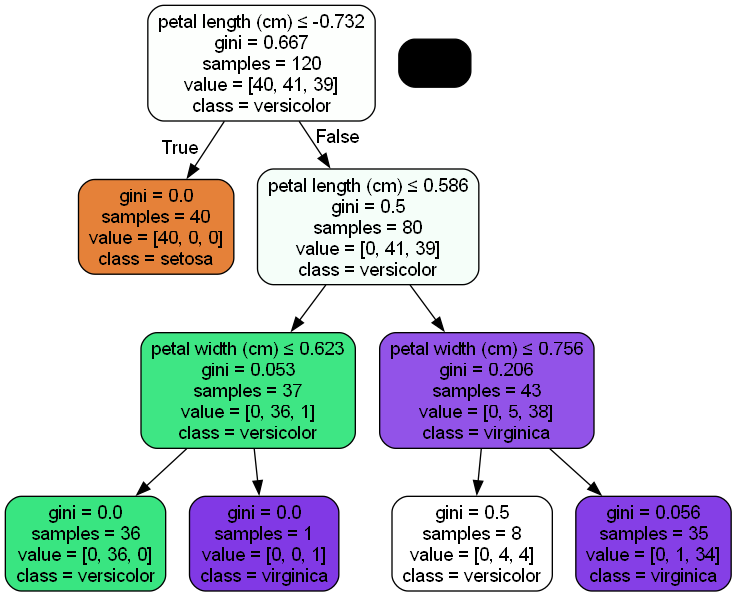
六、模型预测与评估
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report# 预测测试集
y_pred = dt_clf.predict(X_test_scaled)# 评估指标
print(f"准确率: {accuracy_score(y_test, y_pred):.2f}")
print("\n混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))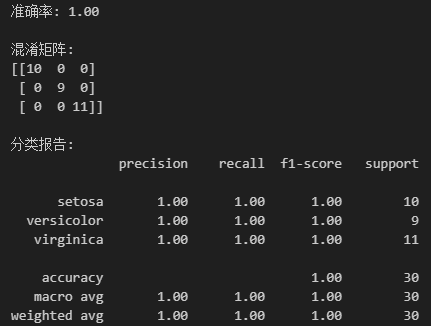
七、超参数调优(网格搜索)
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'max_depth': [2, 3, 4, 5],'min_samples_split': [2, 5, 10],'criterion': ['gini', 'entropy']
}# 网格搜索
grid_search = GridSearchCV(DecisionTreeClassifier(random_state=42),param_grid,cv=5,scoring='accuracy'
)
grid_search.fit(X_train_scaled, y_train)# 输出最优参数
print(f"最佳参数组合: {grid_search.best_params_}")
print(f"最佳验证准确率: {grid_search.best_score_:.2f}")# 使用最优模型预测
best_dt = grid_search.best_estimator_
y_pred_tuned = best_dt.predict(X_test_scaled)
print(f"调优后测试准确率: {accuracy_score(y_test, y_pred_tuned):.2f}")
八、关键知识点解析
特征重要性分析
import matplotlib.pyplot as plt# 获取特征重要性
feature_importances = best_dt.feature_importances_
features = iris.feature_names# 可视化重要性排序
plt.figure(figsize=(10,4))
plt.barh(features, feature_importances)
plt.xlabel('Feature Importance')
plt.title('决策树特征重要性分析')
plt.show()
过拟合诊断方法
-
对比训练集与测试集准确率:
train_acc = best_dt.score(X_train_scaled, y_train)
test_acc = best_dt.score(X_test_scaled, y_test)
print(f"训练集准确率: {train_acc:.2f} vs 测试集准确率: {test_acc:.2f}")输出:
训练集准确率: 0.97 vs 测试集准确率: 1.00
-
若训练准确率显著高于测试准确率(如0.99 vs 0.85),说明过拟合
决策边界可视化(二维示例)
import numpy as np# 选择两个特征进行可视化
X_2d = X_train_scaled[:, [0, 2]] # sepal length 和 petal length# 训练简化模型
dt_2d = DecisionTreeClassifier(max_depth=3)
dt_2d.fit(X_2d, y_train)# 生成网格点
x_min, x_max = X_2d[:, 0].min()-1, X_2d[:, 0].max()+1
y_min, y_max = X_2d[:, 1].min()-1, X_2d[:, 1].max()+1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),np.arange(y_min, y_max, 0.02))# 预测并绘制
Z = dt_2d.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X_2d[:,0], X_2d[:,1], c=y_train, s=20, edgecolor='k')
plt.xlabel('标准化后的花萼长度')
plt.ylabel('标准化后的花瓣长度')
plt.title('决策树分类边界可视化')
plt.show()
九、完整项目开发流程
-
业务场景适配
-
金融风控:客户信用评估
-
医疗诊断:疾病分类预测
-
工业制造:产品质量检测
-
-
生产级代码优化
# 模型持久化
import joblib# 保存标准化器和模型
joblib.dump(scaler, 'std_scaler.pkl')
joblib.dump(best_dt, 'dt_model.pkl')# 新数据预测示例
new_data = [[5.1, 3.5, 1.4, 0.2]] # 原始数据
loaded_scaler = joblib.load('std_scaler.pkl')
loaded_model = joblib.load('dt_model.pkl')scaled_data = loaded_scaler.transform(new_data)
prediction = loaded_model.predict(scaled_data)
print(f"预测类别: {iris.target_names[prediction[0]]}")十、常见问题解决方案
处理类别不平衡问题
# 设置类别权重
balanced_dt = DecisionTreeClassifier(class_weight='balanced', # 自动调整权重max_depth=4,random_state=42
)处理缺失值
from sklearn.impute import SimpleImputer# 在预处理阶段添加缺失值处理
imputer = SimpleImputer(strategy='median')
X_train_imputed = imputer.fit_transform(X_train)
X_test_imputed = imputer.transform(X_test)处理高维数据
# 结合PCA降维
from sklearn.decomposition import PCApca = PCA(n_components=0.95) # 保留95%方差
X_train_pca = pca.fit_transform(X_train_scaled)
X_test_pca = pca.transform(X_test_scaled)实战建议:
-
尝试更换其他数据集(如泰坦尼克生存预测、糖尿病预测)
-
对比不同树模型(随机森林 vs 决策树)
-
部署为Flask/Django API服务
-
使用SHAP库进行模型解释:
pip install shapimport shapexplainer = shap.TreeExplainer(best_dt)
shap_values = explainer.shap_values(X_test_scaled)
shap.summary_plot(shap_values, X_test_scaled, feature_names=iris.feature_names)相关文章:
决策树实战:用Python实现智能分类与预测
目录 一、环境准备 二、数据加载与探索 三、数据预处理 四、决策树模型构建 五、模型可视化(生成决策树结构图) 六、模型预测与评估 七、超参数调优(网格搜索) 八、关键知识点解析 九、完整项目开发流程 十、常见问题解…...

Crond任务调度
今天我们来看看任务调度,假如我们正在睡觉,突然有个半夜两点的任务要你备份一下数据库,你怎么办?难道从被窝中爬起来吗?显然不合理,此时就需要我们定时任务调度程序了. 原理图: crontab 进行定时任务的调度 概述. 任务调度:是指系统在某个…...

HTML5+CSS3+JS小实例:带滑动指示器的导航图标
实例:带滑动指示器的导航图标 技术栈:HTML+CSS+JS 效果: 源码: 【HTML】 <!DOCTYPE html> <html lang="zh-CN"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, ini…...

MINIQMT学习课程Day7
在上一篇,我们安装好xtquant,qmt以及python后,这一章,我们学习如何使用xtquant 本章学习,如何获取账号的资金使用状况。 首先,打开qmt,输入账号密码,选择独立交易。 进入交易界面&…...
EnumChildWindows+shellcode)
每日一个小病毒(C++)EnumChildWindows+shellcode
这里写目录标题 1. `EnumChildWindows` 的基本用法2. 如何利用 `EnumChildWindows` 执行 Shellcode?关键点:完整 Shellcode 执行示例3. 为什么 `EnumChildWindows` 能执行 Shellcode?4. 防御方法5. 总结EnumChildWindows 是 Windows API 中的一个函数,通常用于枚举所有子窗…...

使用minio客户端mc工具迁移指定文件到本地
如果需要筛选MinIO桶中的特定文件进行迁移,可以使用MinIO Client(mc)工具结合一些命令行技巧来实现。以下是具体步骤: 1、安装 MinIO Client(mc) wget https://dl.min.io/client/mc/release/linux-amd64/…...
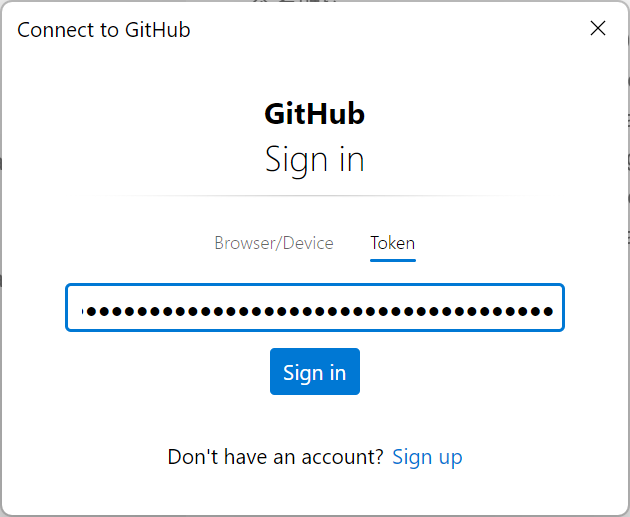
git clone 提示需要登录 github
我们在进行git的时候,可能会弹出让你登陆github的选项,这里我们介绍Token登陆的方法。 正常登陆你的Github 下拉找到 Developer settings按照如下步骤进行操作 填写相关信息,勾选对应选项 返回就能看到token已经被生成,可以使…...

4.2-3 fiddler抓取手机接口
安卓: 长按手机连接的WiFi,点击修改网络 把代理改成手动,服务器主机选择自己电脑的IP地址,端口号为8888(在dos窗口输入ipconfig查询IP地址,为ipv4) 打开手机浏览器,输入http://自己…...
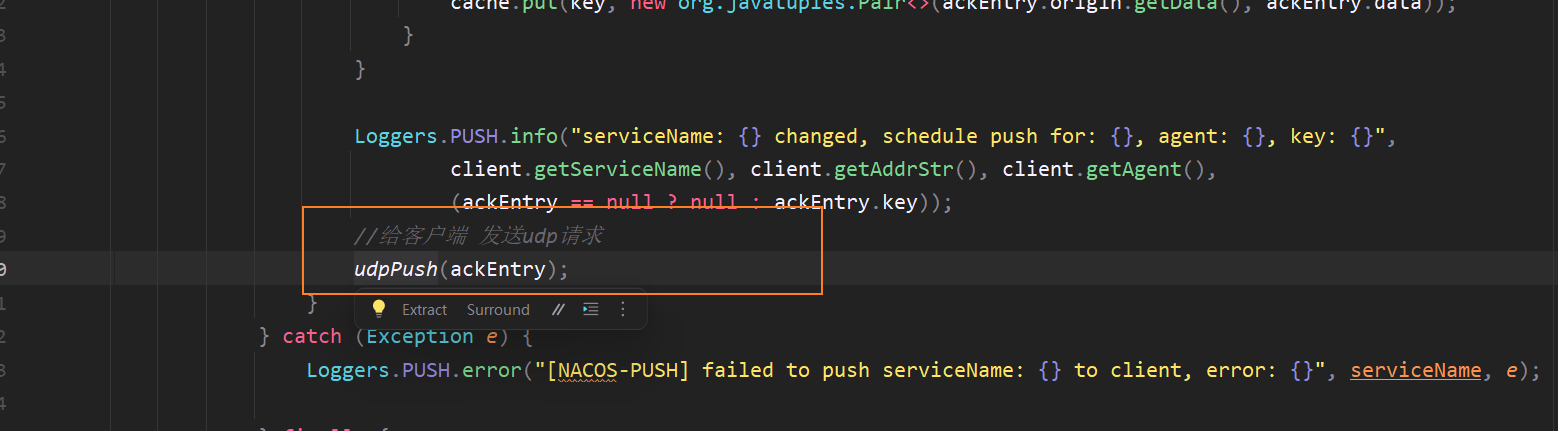
Nacos注册中心AP模式核心源码分析(单机模式)
文章目录 概述一、客户端启动主线流程源码分析1.1、客户端与Spring Boot整合1.2、注册实例(服务注册)1.3、发送心跳1.4、拉取服务端实例列表(服务发现) 二、服务端接收请求主线流程源码分析2.1、接收注册请求2.1.1、初始化注册表2…...

【进收藏夹吃灰】机器学习学习指南
博客标题URL【机器学习】线性回归(506字)https://blog.csdn.net/from__2025_03_16/article/details/146303423...

【Web 服务器】的工作原理
🌐 Web 服务器的工作原理 Web 服务器的主要作用是 接收客户端请求(通常是浏览器发出的 HTTP/HTTPS 请求),处理请求,并返回相应的数据(如网页、图片、API 响应等)。 📌 工作流程 1️…...

关于uint8_t、uint16_t、uint32_t、uint64_t的区别与分析
一、类型定义与字节大小 uint8_t、uint16_t、uint32_t、uint64_t 是 C/C 中定义的无符号整数类型,通过 typedef 对基础类型起别名实现。位宽(bit)和字节数严格固定: uint8_t:8 位,占用 1 字节ÿ…...

Linux命令-grep
grep 是一种强大的命令行工具,用于在一个或多个输入文件中搜索与正则表达式匹配的行,并将匹配的行标准输出。 1.基本搜索 参数 说明 -i 忽略大小写进行匹配 -w 只匹配完整的单词 -x 只匹配与整行完全匹配的行 -v 反向匹配,显示不匹配的行…...

【Cursor】设置语言
Ctrl Shift P 搜索 configure display language选择“中文-简体”...

k8s 1.30 安装ingress-nginx
一、下载 # wget https://mirrors.chenby.cn/https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/static/provider/cloud/deploy.yaml 二、过滤镜像 修改 三、部署 四、检查: 五、扩充副本数 # kubectl scale --replicas3 deployment/ingr…...
很简单 的 将字幕生成视频的 方法
一、一键将字幕生成视频的 方法 1、下载任性动图 10.7 以上版本 2、设置背景 1)背景大小 拉伸背景到合适大小,或者选择右侧比例 2)、直接空背景,设置背景颜色等详细信息 3)、或者 复制或者突然图片做背景 3、设置文…...

OpenCv(二)——边界填充、阈值处理
目录 一、边界填充 (1)constant边界填充,填充指定宽度的像素 (2)REFLECT镜像边界填充 (3)REFLECT_101镜像边界填充改进 (4) REPLICATE使用最边界的像素值代替 (5)WRAP上下左右边依次替换 二…...
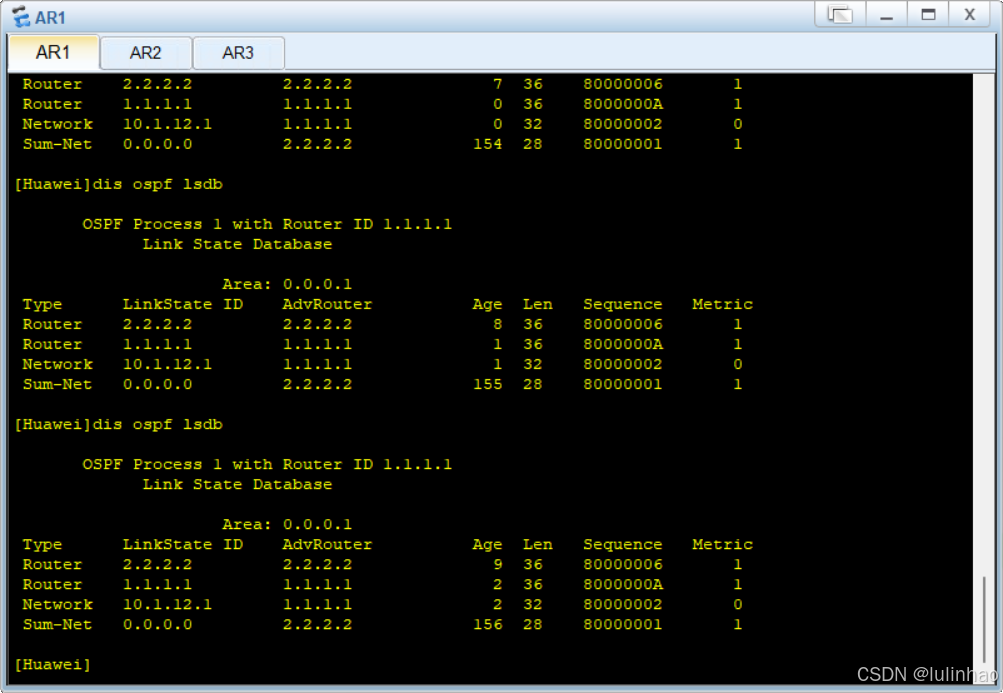
理解OSPF Stub区域和各类LSA特点
之前学习到OSPF特殊区域和各类类型LSA的分析后,一直很混乱,在网上也难找到详细的解释,在看了 HCNP书本内容后,对这块类容理解更加清晰,本次内容,我们使用实验示例,来对OSPF特殊区域和各 类型LSA…...

鸿蒙 ——选择相册图片保存到应用
photoAccessHelper // entry/src/main/ets/utils/file.ets import { fileIo } from kit.CoreFileKit; import { photoAccessHelper } from kit.MediaLibraryKit; import { bundleManager } from kit.AbilityKit;// 应用在本设备内部存储上通用的存放默认长期保存的文件路径&am…...

pat学习笔记
two pointers 双指针 给定一个递增的正整数序列和一个正整数M,求序列中的两个不同位置的数a和b,使得它们的和恰好为M,输出所有满足条件的方案。例如给定序列{1,2,3,4,5,6}和正整数M 8,就存在268和358成立。 容易想到࿱…...

Gson修仙指南:谷歌大法的佛系JSON渡劫手册
各位在代码世界打坐修行的道友们!今天我们要参悟Google出品的JSON心法——Gson!这货就像代码界的扫地僧,表面朴实无华,实则内力深厚,专治各种JSON不服!准备好迎接"万物皆可JSON"的顿悟时刻了吗&a…...

我的世界1.20.1forge模组开发进阶教程——TerraBlender
TerraBlender介绍 从模组开发者的视角来看,TerraBlender为Minecraft生物群系类模组的开发提供了全方位的技术支持,显著降低了开发门槛并提升了模组的质量与扩展性: 跨平台兼容性架构支持Forge/Fabric/Quilt/NeoForge四大主流加载器,开发者无需为不同平台单独适配代码客户端…...

判断HiveQL语句为ALTER TABLE语句的识别函数
写一个C#字符串解析程序代码,逻辑是从前到后一个一个读取字符,遇到匹配空格、Tab和换行符就继续读取下一个字符,遇到大写或小写的字符a,就读取后一个字符并匹配是否为大写或小写的字符l,以此类推,匹配任意字…...

CAN/FD CAN总线配置 最新详解 包含理论+实战(附带源码)
看前须知:本篇文章不会说太多理论性的内容(重点在理论结合实践),顾及实操,应用,一切理论内容支撑都是为了后续实际操作进行铺垫,重点在于读者可以看完文章应用。(也为节约读者时间&a…...

DE2-115分秒计数器
一、模块设计 如若不清楚怎么模块化,请看https://blog.csdn.net/szyugly/article/details/146379170?spm1001.2014.3001.5501 1.1顶层模块 module top_counter(input wire CLOCK_50, // 50MHz时钟input wire KEY0, // 暂停/继续按键out…...

MoE Align Sort在医院AI医疗领域的前景分析(代码版)
MoE Align & Sort技术通过优化混合专家模型(MoE)的路由与计算流程,在医疗数据处理、模型推理效率及多模态任务协同中展现出显著优势,其技术价值与应用意义从以下三方面展开分析: 一、方向分析 1、提升医疗数据处理效率 在医疗场景中,多模态数据(如医学影像、文本…...
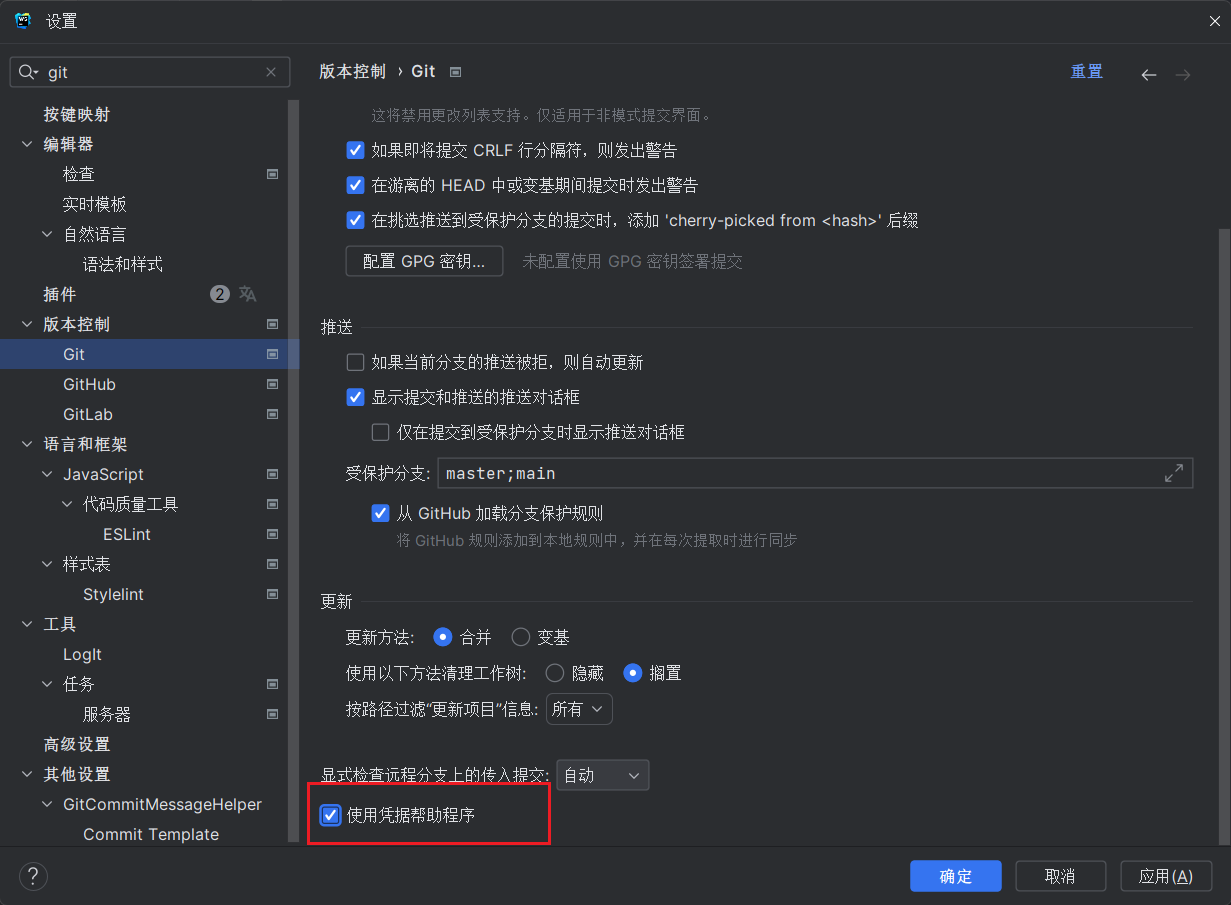
【已解决】Webstorm 每次使用 git pull/push 都要输入令牌/密码登录
解决办法:勾上【使用凭据帮助程序】(英文:Use credential helper)...

阅读分析Linux0.11 /boot/setup.s
目录 第一部分第二部分第三部分 该源文件功能分为三部分: (1)源文件开始部分是通过各种中断指令, 初始化计算机的组成硬件,获得硬件的参数,然后保存到段空间0X9000。该空间原来是保存加载到内存的引导扇区内…...

Cmake:Win10 如何编译 midifile C++应用程序
先从 Microsoft C Build Tools - Visual Studio 下载 1.73GB 安装 "Microsoft C Build Tools“ 下载:midifile 项目 , 将 midifile-master.zip 解压到 D:\Music-soft 参阅: cmake超详细入门教程 CMake是一个跨平台的自动化建构系统,它使用一个名为 CMakeLi…...
)
QEMU源码全解析 —— 块设备虚拟化(14)
接前一篇文章:QEMU源码全解析 —— 块设备虚拟化(13) 本文内容参考: 《趣谈Linux操作系统》 —— 刘超,极客时间 《QEMU/KVM源码解析与应用》 —— 李强,机械工业出版社 特此致谢! 上一回开始解析VirtioDeviceClass的realize函数virtio_blk_device_realize(),再来回…...