Airflow+Spark/Flink vs. Kettle
在迁移亿级(单表超过1.3亿)结构化数据(达梦→星环)的场景下,Airflow(结合分布式计算框架)的综合效果优于Kettle,以下是详细对比与方案建议:
一、核心对比:Airflow vs. Kettle
| 维度 | Airflow(+Spark/Flink) | Kettle(单机/集群) |
| 架构定位 | 工作流调度平台(非ETL工具),依赖外部计算框架(Spark/Flink)处理数据。 | 专业ETL工具,内置数据处理逻辑(转换、清洗),支持单机/集群(Kitchen/Carte模式)。 |
| 数据规模 | 分布式处理(Spark/Flink集群),支持亿级数据并行处理(水平扩展)。 | 单机性能有限(百万级),分布式模式(Kettle集群)配置复杂,性能提升有限(受限于JVM内存)。 |
| 稳定性 | 任务失败自动重试(DAG机制),分布式框架(Spark)的容错性(Checkpoint)更强大。 | 单机模式易内存溢出(如60万条报错),集群模式依赖网络稳定性,批量写入易触发数据库锁竞争。 |
| 灵活性 | 支持自定义代码(Python/Java),无缝集成Spark/Flink,适配复杂数据转换(如达梦→星环的类型映射)。 | 图形化界面简单易用,但复杂逻辑需依赖插件(如JSON解析),数据库兼容性依赖内置驱动(需手动添加达梦/JDBC)。 |
| 资源利用 | 计算与调度分离:Airflow轻量(CPU/内存占用低),数据处理由Spark/Flink集群承担(资源按需分配)。 | 单机模式内存瓶颈(如Kettle默认堆内存≤4GB),集群模式需额外部署Carte节点(资源浪费)。 |
| 监控与运维 | 可视化DAG监控(Airflow UI),集成Prometheus监控任务指标(如处理速度、重试次数)。 | 日志文件分析(spoon.log),缺乏实时监控界面,故障排查依赖人工介入。 |
| 兼容性 | 纯Python生态,适配中标麒麟Linux(无需图形界面),轻松加载达梦/星环JDBC驱动(代码级配置)。 | Linux命令行模式(Kitchen)可用,但图形界面(Spoon)在国产化系统中可能兼容性问题(如字体、依赖库)。 |
二、Airflow方案:分布式调度+Spark/Flink处理(推荐)
1. 架构设计
达梦数据库 → Spark Batch(Airflow调度) → Kafka(可选缓冲) → 星环Torc (全量:Spark Bulk Load + 增量:Flink CDC)
2. 核心优势
- 分布式并行处理:
- 使用Spark的
spark.read.jdbc并行读取达梦数据(分区键splitColumn),1.3亿条数据可按id分区(100分区→每分区130万条)。 - 示例Spark SQL:
- 使用Spark的
val df = spark.read.format("jdbc").option("url", "jdbc:dm://dm-host:5236/source_db").option("dbtable", "(SELECT * FROM big_table) AS tmp").option("user", "user").option("password", "pass").option("partitionColumn", "id") // 分区键(主键).option("lowerBound", "1") // 分区下界.option("upperBound", "100000000") // 分区上界.option("numPartitions", "100") // 并行度100.load()
- 批量写入优化:
- 星环Torc支持Spark直接写入(
spark.write.kudu),批量提交(batchSize=100000),避免单条插入。 - 示例:
- 星环Torc支持Spark直接写入(
df.write.format("kudu").option("kudu.master", "torc-host:7051").option("kudu.table", "target_table").option("batchSize", 100000).mode("append").save()
- Airflow调度策略:
- 使用
SparkSubmitOperator提交Spark作业,配置资源(如--executor-memory 16g --executor-cores 4)。 - DAG示例(全量迁移):
- 使用
from airflow import DAGfrom airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperatorfrom datetime import datetimedag = DAG("dm_to_torc_migration",start_date=datetime(2024, 1, 1),schedule_interval=None,catchup=False)transfer_task = SparkSubmitOperator(task_id="dm_to_torc",application="/path/to/migration.jar", # Spark作业JARconn_id="spark_default",executor_memory="16g",executor_cores=4,num_executors=20, # 20个Executor并行dag=dag)
3. 性能预估(1.3亿条)
| 阶段 | 工具/配置 | 时间预估(100节点集群) | 说明 |
| 数据读取 | Spark并行读取(100分区) | 20分钟 | 达梦分区键索引优化(如id主键索引) |
| 数据转换 | Spark SQL(简单清洗) | 5分钟 | 空值填充、类型转换 |
| 数据写入 | Torc批量写入(100线程) | 30分钟 | 预分区表(PARTITION BY HASH(id)) |
| 总计 | 55分钟 | 含任务调度与资源初始化 |
三、Kettle方案:传统ETL的局限性
1. 架构设计
达梦数据库 → Kettle(单机/集群) → 星环Torc(JDBC批量写入)
2. 核心劣势
- 单机性能瓶颈:
- Kettle默认堆内存(
-Xmx4g)处理1.3亿条数据必现OOM(内存溢出),需调整为-Xmx16g(受限于单机内存)。 - 批量写入速度:JDBC单线程插入约1000条/秒 → 1.3亿条需36小时(无并行)。
- Kettle默认堆内存(
- 分布式配置复杂:
- Kettle集群(Carte节点)需同步环境(Java、驱动),分布式执行依赖Spoon远程调用,网络开销大(如10节点并行仅提升10倍→3.6小时)。
- 示例集群命令:
# 启动Carte集群./carte.sh start 192.168.1.10:8081# 提交分布式作业./kitchen.sh -file=migration.kjb -remotename=cluster -level=Basic
- 稳定性风险:
- 数据库连接池压力:Kettle多线程JDBC写入易触发星环数据库锁竞争(
error batch up重现)。 - 重试机制弱:任务失败需手动重启,断点续传依赖
last_value(复杂表结构难维护)。
- 数据库连接池压力:Kettle多线程JDBC写入易触发星环数据库锁竞争(
3. 优化后性能(10节点集群)
| 阶段 | 配置 | 时间预估 | 风险点 |
| 数据读取 | 10节点并行(JDBC多线程) | 2小时 | 达梦连接池过载(需增大max_connections) |
| 数据转换 | 内存计算(无分布式缓存) | 1小时 | 大字段(如TEXT)内存溢出 |
| 数据写入 | 批量大小10万条/批,10线程并行 | 6小时 | 星环连接超时(需调整socketTimeout) |
| 总计 | 9小时 | 含节点间同步延迟 |
四、关键决策因素
1. 数据规模(1.3亿条)
- Airflow+Spark:分布式计算(100节点)线性扩展,1小时内完成。
- Kettle:单机/小集群(10节点)需数小时,且稳定性随数据量增长急剧下降。
2. 数据源/目标特性
- 达梦数据库:支持并行查询(需配置
partitionColumn),Airflow+Spark可充分利用。 - 星环Torc:批量写入API(Bulk Load)仅支持Spark/Flink,Kettle需通过JDBC模拟批量(性能差)。
3. 国产化适配(中标麒麟)
- Airflow:纯Python生态,无图形界面依赖,适配中标麒麟Linux(Python 3.8+)。
- Kettle:Spoon图形界面需X Window支持(国产化系统可能缺失),依赖
libswt库(兼容性风险)。
4. 运维成本
- Airflow:可视化DAG监控(成功/失败任务一目了然),集成Prometheus监控(如Spark作业CPU使用率)。
- Kettle:依赖日志文件(
system/logs/migration.log),故障排查需人工分析。
五、最终建议:Airflow+Spark/Flink方案
1. 实施步骤
- 环境准备:
- 中标麒麟安装Airflow(
pip install apache-airflow)、Spark(3.3+)、达梦/JDBC驱动(Class.forName("dm.jdbc.driver.DmDriver"))。 - 配置星环Torc的Kafka/Spark连接器(如
transwarp-connector-torc_2.12-2.0.0.jar)。
- 中标麒麟安装Airflow(
- 全量迁移(Airflow+Spark):
- 使用
SparkJDBCOperator并行读取达梦数据,写入Torc(Bulk Load)。 - 示例任务配置:
python from airflow.providers.apache.spark.operators.spark_sql import SparkSqlOperator bulk_load_task = SparkSqlOperator( task_id="bulk_load_torc", sql=""" INSERT INTO torc.target_table SELECT id, name, amount FROM dm.source_table """, conf={ "spark.sql.jdbc.partitionColumn": "id", "spark.sql.jdbc.numPartitions": "100", "spark.kudu.master": "torc-host:7051" }, dag=dag )
- 使用
- 增量同步(Airflow+Flink CDC):
- 调度Flink作业消费达梦CDC(Debezium),写入Torc(幂等Upsert)。
- 示例Flink SQL:
sql CREATE TABLE dm_cdc ( id BIGINT, name STRING, amount DECIMAL(10,2), op STRING, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'dm-host', 'port' = '5236', 'username' = 'user', 'password' = 'pass', 'database-name' = 'source_db', 'table-name' = 'big_table' ); INSERT INTO torc.target_table SELECT id, name, amount FROM dm_cdc WHERE op = 'c' OR op = 'u';
2. 成本对比
| 方案 | 硬件成本(100节点) | 人力成本(运维/开发) | 时间成本(1.3亿条) |
| Airflow+Spark | 高(需集群) | 低(代码复用性强) | 1小时 |
| Kettle集群 | 中(10节点) | 高(配置复杂) | 9小时 |
六、总结:Airflow的综合优势
| 维度 | Airflow+Spark/Flink | Kettle |
| 数据规模 | ✅ 亿级(分布式) | ❌ 千万级(单机瓶颈) |
| 稳定性 | ✅ 自动重试+Checkpoint | ❌ 易内存溢出/连接中断 |
| 国产化适配 | ✅ 纯命令行,无图形依赖 | ❌ 图形界面兼容性风险 |
| 扩展性 | ✅ 按需扩展Executor(10→1000节点) | ❌ 集群性能线性增长(10节点×10倍) |
| 维护成本 | ✅ 可视化DAG,自动监控 | ❌ 人工日志分析 |
| 结论:对于1.3亿条数据迁移,Airflow结合Spark/Flink的分布式方案是最优选择,尤其在国产化环境(中标麒麟)中,其稳定性、扩展性和运维效率显著优于Kettle。Kettle仅适用于小规模数据(<100万条)或简单场景,大规模迁移需依赖分布式计算框架。 | ||
| 落地建议: |
- 优先使用Airflow调度Spark作业,利用星环Torc的Bulk Load接口(比JDBC快100倍)。
- 增量同步采用Flink CDC(Debezium),避免全量扫描。
- 监控关键指标:Spark作业的
recordsReadPerSecond(≥50万条/秒)、Torc写入延迟(≤100ms/批)。 - 国产化适配验证:在中标麒麟中测试达梦JDBC驱动加载(
Class.forName)和Spark Kerberos认证(如需)。 通过该方案,1.3亿条数据可在1小时内完成全量迁移,增量同步延迟控制在秒级,满足大规模数据迁移的高性能、高可靠需求。
相关文章:

Airflow+Spark/Flink vs. Kettle
在迁移亿级(单表超过1.3亿)结构化数据(达梦→星环)的场景下,Airflow(结合分布式计算框架)的综合效果优于Kettle,以下是详细对比与方案建议: 一、核心对比:Air…...
Cribl 导入文件来检查pipeline 的设定规则(eval 等)
Cribl 导入文件来检查pipeline 的设定规则(eval 等) 从这个页面先下载,或者copy 内容来创建pipeline: Reducing Windows XML Events | Cribl Docs...

[C++面试] new、delete相关面试点
一、入门 1、说说new与malloc的基本用途 int* p1 (int*)malloc(sizeof(int)); // C风格 int* p2 new int(10); // C风格,初始化为10 new 是 C 中的运算符,用于在堆上动态分配内存并调用对象的构造函数,会自动计算所需内存…...

一周学会Pandas2 Python数据处理与分析-Jupyter Notebook安装
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili Jupyter (Project Jupyter | Home)项目是一个非营利性开源项目,于2014年由IPython项目中诞生…...

第30周Java分布式入门 消息队列 RabbitMQ
RabbitMQ章节介绍 一、RabbitMQ概述 RabbitMQ学习内容: 本章节将学习RabbitMQ的概念、安装启动、管理后台、代码实操、交换机工作模式以及Spring Boot整合RabbitMQ。消息队列定义: 消息队列是一种用于在分布式系统中传递消息的机制。消息队列特性: 消息队列具有异步、解耦、削…...

北斗导航 | THE GNSS AMBIGUITY RATIO-TEST REVISITED: A BETTER WAY OF USING IT【论文要点】
THE GNSS AMBIGUITY RATIO-TEST REVISITED: A BETTER WAY OF USING IT 总结该论文的核心贡献及关键方法如下:论文核心内容概述 传统比率测试的局限性 传统比率测试通过比较最优与次优模糊度解的残差平方和比值(即 R = q (...
)
MySQL 面试知识点详解(索引、存储引擎、事务与隔离级别、MVCC、锁机制、优化)
一、索引基础概念 1 索引是什么? 定义:索引是帮助MySQL高效获取数据的有序数据结构,类似书籍的目录。核心作用:减少磁盘I/O次数,提升查询速度(以空间换时间)。 2 索引的优缺点 优点缺点加速…...

Linux / Windows 下 Mamba / Vim / Vmamba 安装教程及安装包索引
目录 背景0. 前期环境查询/需求分析1. Linux 平台1.1 Mamba1.2 Vim1.3 Vmamba 2. Windows 平台2.1 Mamba2.1.1 Mamba 12.1.2 Mamba 2- 治标不治本- 终极版- 高算力版 2.2 Vim- 治标不治本- 终极版- 高算力版 2.3 Vmamba- 治标不治本- 终极版- 高算力版 3. Linux / Windows 双平…...
deepseek v3-0324 Markdown 编辑器 HTML
Markdown 编辑器 HTML 以下是一个美观的 Markdown 编辑器 HTML 页面,支持多种主题切换和实时预览功能: <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&q…...
视频设备轨迹回放平台EasyCVR如何搭建公共娱乐场所远程视频监控系统
一、背景介绍 由于KTV、酒吧、足疗店等服务场所人员流动频繁、环境复杂,一直是治安管理的重点区域。为有效打击 “黄赌毒”、打架斗殴、寻衅滋事等违法犯罪的活动,打造安全有序的娱乐消费环境,我国相关部门将加大对这类场所的清查与管控力度…...
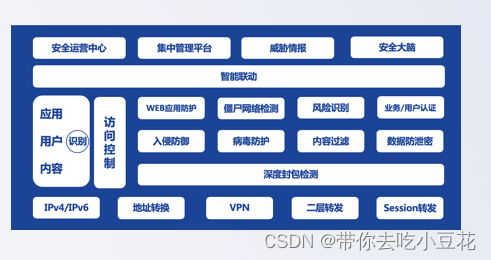
网络安全基础知识总结
什么是网络安全 采取必要措施,来防范对网络的攻击,侵入,干扰,破坏和非法使用,以及防范一些意外事故,使得网络处于稳定可靠运行的状态,保障网络数据的完整性、保密性、可用性的能力(CIA)。 举例…...

Python设计模式:克隆模式
1. 什么是克隆模式 克隆模式的核心思想是通过复制一个已有的对象(原型)来创建一个新的对象(克隆)。这种方式可以避免重复的初始化过程,从而提高效率。克隆模式通常涉及以下几个方面: 原型对象:…...
【工具】在 Visual Studio 中使用 Dotfuscator 对“C# 类库(DLL)或应用程序(EXE)”进行混淆
在 Visual Studio 中使用 Dotfuscator 进行混淆 Dotfuscator 是 Visual Studio 自带的混淆工具(Dotfuscator Community Edition,简称 CE)。它可以混淆 C# 类库(DLL)或应用程序(EXE),…...

积分赛——获取环境温度
设计要求 从DS18B20温度传感器上获取环境温度,并将其温度值显示到数码管上(保留两位小数)。 当“S4”定义为发送按键,按键S4按下时,串口向PC端发送当前采集的温度值; 串口发送格式: Temp:26.…...

LogicFlow获取锚点数据的自定义key并添加的连接的Edge边数据中
1、重写 PolylineEdgeModel 类(其它 EdgeModel 都可以) class CustomNetWorkNodeEdge extends PolylineEdge { } class CustomNetWorkNodeEdgeModel extends PolylineEdgeModel {getData() {const data super.getData();//获取开始锚点自定义属性添加到…...

【python中级】解压whl文件内容
【python中级】解压whl文件内容 1.背景2.解压1.背景 【python中级】关于whl文件的说明 https://blog.csdn.net/jn10010537/article/details/146979236 补充以上博客: 在 旧版 setuptools 中(< v58),如果想生成 .whl,必须先pip install 安装 wheel 三方包! pip inst…...

Xilinx系列FPGA实现HDMI2.1视频收发,支持8K@60Hz分辨率,提供2套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目我已有的4K/8K视频处理解决方案我已有的FPGA图像处理方案 3、详细设计方案设计框图硬件设计架构本HDMI2.1性能参数8K视频输入源Video PHY ControllerHDMI 2.1 Receive…...
如何把网页文章转为pdf保存
fnF12调出右边网页端的控制台 在下面输入代码 1、转CSDN上的文章 (function(){ use strict;var articleBox $("div.article_content");articleBox.removeAttr("style");var head_str ""; var foot_str ""; var olde…...

开源可视化大屏go-view前后端安装
一、后端安装 下载代码 git clone https://gitee.com/MTrun/go-view-serve修改配置 cd go-view-serve/ # 修改application-dev.yml的数据库文件地址 vi ./src/main/resources/application-dev.ymlapplication-dev.yml spring:datasource:driver-class-name: org.sqlite.JDB…...

eventEmitter实现
没有做任何异常处理,简单模拟实现 事件对象的每一个事件都对应一个数组 /*__events {"事件1":[cb1,cb2],"事件2":[cb3,cb4],"事件3":[...],"事件4":[...],};*/class E{__events {};constructor(){}//注册监听回调on(type , callbac…...

自然语言处理|如何用少样本技术提升低资源语言处理?
一、引言 在全球化的背景下,自然语言处理(NLP)技术取得了显著进展,为人们的生活和工作提供了便利。然而,大多数 NLP 研究和应用集中在少数高资源语言上,如英语和中文。据统计,全球存在超过 700…...

系统安全——文件监控-FileMonitor
namespace FileSystemWatcherDemo {public partial class Form1 : Form{ public Form1(){InitializeComponent();UsingFileSystemWatcher();} /// <summary>/// 使用FileSystemWatcher方法/// </summary>void UsingFileSystemWatcher(){//6.2//FileSystemWa…...
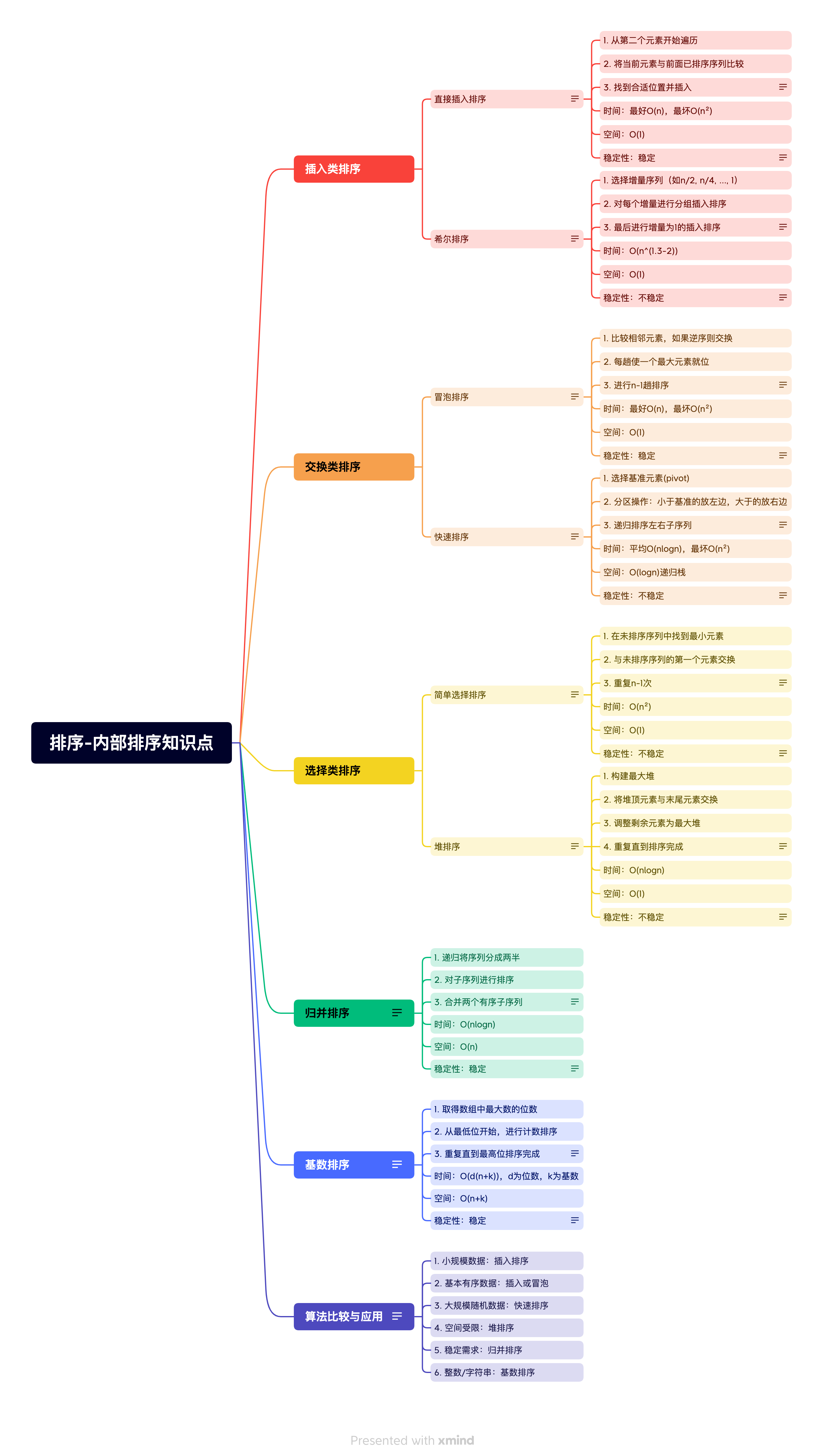
07-01-自考数据结构(20331)- 排序-内部排序知识点
内部排序算法是数据结构核心内容,主要包括插入类(直接插入、希尔)、交换类(冒泡、快速)、选择类(简单选择、堆)、归并和基数五大类排序方法。 知识拓扑 知识点介绍 直接插入排序 定义:将每个待排序元素插入到已排序序列的适当位置 算法步骤: 从第二个元素开始遍历…...
)
Unity:平滑输入(Input.GetAxis)
目录 1.为什么需要Input.GetAxis? 2. Input.GetAxis的基本功能 3. Input.GetAxis的工作原理 4. 常用参数和设置 5. 代码示例:用GetAxis控制角色移动 6. 与Input.GetAxisRaw的区别 7.如何优化GetAxis? 1.为什么需要Input.GetAxis&…...
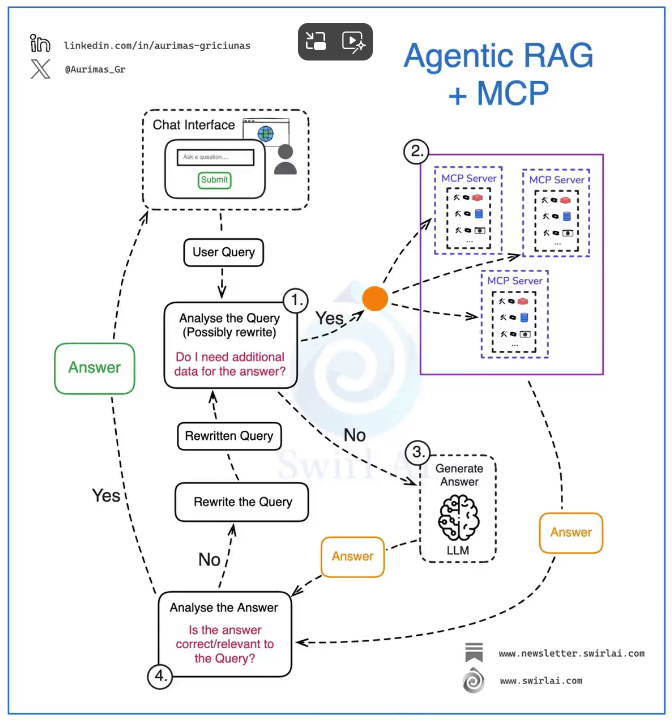
【AI学习】MCP的简单快速理解
最近,AI界最火热的恐怕就是MCP了。作为一个新的知识点,学习的开始,先摘录一些信息,从发展历程、通俗介绍到具体案例,这样可以快速理解MCP。 MCP发展历程 来自i陆三金 Anthropic 开发者关系负责人 Alex Albert&#…...
单机快速部署开源、免费的分布式任务调度系统——DolphinScheduler
看了DolphinScheduler的介绍,不知道有没有引起你的兴趣,有没有想要上手体验一番呢。本文则主要为大家介绍DolphinScheduler的单机部署方式,方便大家快速体验。 环境准备 需要Java环境,这是一个老生常谈的问题,关于Ja…...

Vue3命名规范指南
在 Vue 3 中,遵循一致的命名规范可以提高代码的可读性和维护性。以下是常见的命名规范和实践建议: 1. 组件命名 PascalCase(大驼峰式) 单文件组件(.vue 文件)和组件引用时推荐使用 PascalCase,便…...

【大模型系列篇】大模型基建工程:基于 FastAPI 自动构建 SSE MCP 服务器
今天我们将使用FastAPI来构建 MCP 服务器,Anthropic 推出的这个MCP 协议,目的是让 AI 代理和你的应用程序之间的对话变得更顺畅、更清晰。FastAPI 基于 Starlette 和 Uvicorn,采用异步编程模型,可轻松处理高并发请求,尤…...

springcloud configClient获取configServer信息失败导致启动configClient注入失败报错解决
目录 一、问题现象 二、解决方案 三、运行结果 四、代码地址 一、问题现象 springcloud configClient获取configServer信息失败导致启动configClient注入失败 报错堆栈信息 org.springframework.beans.factory.BeanCreationException: Error creating bean with name scop…...

HarmonyOS-ArkUI Rcp模块类关系梳理
前言 本文重点解决的是,按照官网学习路径学习Tcp模块内容时,越看越混乱的问题。仿照官网案例,书写代码时,产生的各种疑惑。比如,类与类之间的关系,各种配置信息究竟有多少,为什么越写越混乱。那…...