多GPU训练
写在前面
限于财力不足,本机上只有一个 GPU 可供使用,因此这部分的代码只能够稍作了解,能够使用的 GPU 也只有一个。
多 GPU 的数据并行:有几张卡,对一个小批量数据,有几张卡就分成几块,每个 GPU 分别计算梯度,然后加起来做并行。
从零开始实现
%matplotlib inline
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
简单网络
# 初始化模型参数
scale = 0.01
W1 = torch.randn(size=(20, 1, 3, 3)) * scale
b1 = torch.zeros(20)
W2 = torch.randn(size=(50, 20, 5, 5)) * scale
b2 = torch.zeros(50)
W3 = torch.randn(size=(800, 128)) * scale
b3 = torch.zeros(128)
W4 = torch.randn(size=(128, 10)) * scale
b4 = torch.zeros(10)
params = [W1, b1, W2, b2, W3, b3, W4, b4]# 定义模型
def lenet(X, params):h1_conv = F.conv2d(input=X, weight=params[0], bias=params[1])h1_activation = F.relu(h1_conv)h1 = F.avg_pool2d(input=h1_activation, kernel_size=(2, 2), stride=(2, 2))h2_conv = F.conv2d(input=h1, weight=params[2], bias=params[3])h2_activation = F.relu(h2_conv)h2 = F.avg_pool2d(input=h2_activation, kernel_size=(2, 2), stride=(2, 2))h2 = h2.reshape(h2.shape[0], -1)h3_linear = torch.mm(h2, params[4]) + params[5]h3 = F.relu(h3_linear)y_hat = torch.mm(h3, params[6]) + params[7]return y_hat# 交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction='none')
向多个设备分发参数,并通过将模型参数复制到一个GPU:
def get_params(params, device): # 把一个参数复制到另外一个GPU上去new_params = [p.to(device) for p in params]for p in new_params:p.requires_grad_() #对每一个参数都需要计算梯度return new_paramsnew_params = get_params(params, d2l.try_gpu(0))
print('b1 权重:', new_params[1])
print('b1 梯度:', new_params[1].grad)

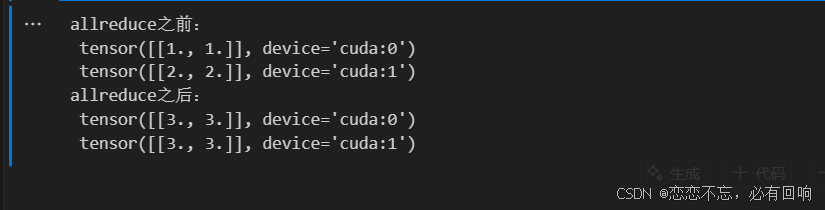
allreduce函数将所有向量相加,并将结果广播给所有GPU
def allreduce(data):for i in range(1, len(data)):data[0][:] += data[i].to(data[0].device)for i in range(1, len(data)):data[i][:] = data[0].to(data[i].device)data = [torch.ones((1, 2), device=d2l.try_gpu(i)) * (i + 1) for i in range(2)]
print('allreduce之前:\n', data[0], '\n', data[1])
allreduce(data)
print('allreduce之后:\n', data[0], '\n', data[1])
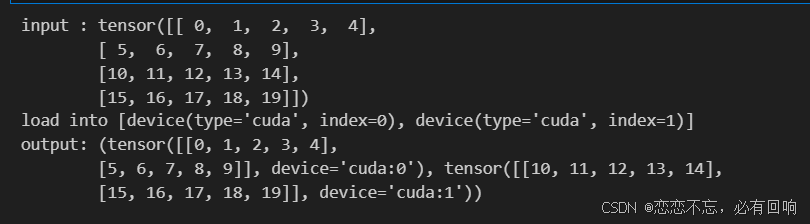
将一个小批量数据均匀地分布在多个 GPU 上
data = torch.arange(20).reshape(4, 5)
devices = [torch.device('cuda:0'), torch.device('cuda:1')]
split = nn.parallel.scatter(data, devices)
print('input :', data)
print('load into', devices)
print('output:', split)
#@save
def split_batch(X, y, devices):"""将X和y拆分到多个设备上"""assert X.shape[0] == y.shape[0]return (nn.parallel.scatter(X, devices),nn.parallel.scatter(y, devices))
在一个小批量上实现多GPU训练
def train_batch(X, y, device_params, devices, lr):X_shards, y_shards = split_batch(X, y, devices)# 在每个GPU上分别计算损失ls = [loss(lenet(X_shard, device_W), y_shard).sum()for X_shard, y_shard, device_W in zip(X_shards, y_shards, device_params)]for l in ls: # 反向传播在每个GPU上分别执行l.backward()# 将每个GPU的所有梯度相加,并将其广播到所有GPUwith torch.no_grad():for i in range(len(device_params[0])):allreduce([device_params[c][i].grad for c in range(len(devices))])# 在每个GPU上分别更新模型参数for param in device_params:d2l.sgd(param, lr, X.shape[0]) # 在这里,我们使用全尺寸的小批量
定义训练模型:
def train(num_gpus, batch_size, lr):train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)devices = [d2l.try_gpu(i) for i in range(num_gpus)]# 将模型参数复制到num_gpus个GPUdevice_params = [get_params(params, d) for d in devices]num_epochs = 10animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])timer = d2l.Timer()for epoch in range(num_epochs):timer.start()for X, y in train_iter:# 为单个小批量执行多GPU训练train_batch(X, y, device_params, devices, lr)torch.cuda.synchronize()timer.stop()# 在GPU0上评估模型animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(lambda x: lenet(x, device_params[0]), test_iter, devices[0]),))print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'f'在{str(devices)}')
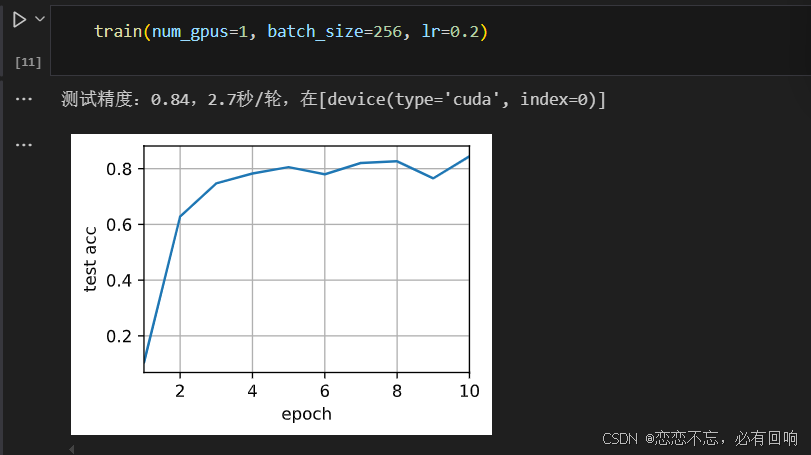
在单个 GPU 上运行:
增加为 2 个 GPU
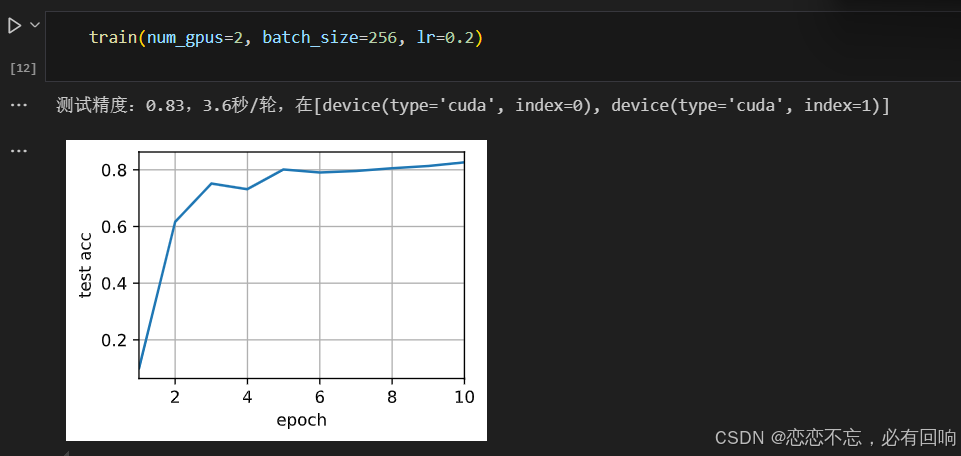
并行后并没有变快,可能有以下原因:
- Data 读取比较慢
- GPU 增加了,但是 batch_size 没有增加
多 GPU 的简洁实现
import torch
from torch import nn
from d2l import torch as d2l
简单网络
#@save
def resnet18(num_classes, in_channels=1):"""稍加修改的ResNet-18模型"""def resnet_block(in_channels, out_channels, num_residuals,first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(d2l.Residual(in_channels, out_channels,use_1x1conv=True, strides=2))else:blk.append(d2l.Residual(out_channels, out_channels))return nn.Sequential(*blk)# 该模型使用了更小的卷积核、步长和填充,而且删除了最大汇聚层net = nn.Sequential(nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(64),nn.ReLU())net.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))net.add_module("resnet_block2", resnet_block(64, 128, 2))net.add_module("resnet_block3", resnet_block(128, 256, 2))net.add_module("resnet_block4", resnet_block(256, 512, 2))net.add_module("global_avg_pool", nn.AdaptiveAvgPool2d((1,1)))net.add_module("fc", nn.Sequential(nn.Flatten(),nn.Linear(512, num_classes)))return netnet = resnet18(10)
# 获取GPU列表
devices = d2l.try_all_gpus()
# 我们将在训练代码实现中初始化网络
训练
def train(net, num_gpus, batch_size, lr):train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)devices = [d2l.try_gpu(i) for i in range(num_gpus)]def init_weights(m):if type(m) in [nn.Linear, nn.Conv2d]:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)# 在多个GPU上设置模型net = nn.DataParallel(net, device_ids=devices)trainer = torch.optim.SGD(net.parameters(), lr)loss = nn.CrossEntropyLoss()timer, num_epochs = d2l.Timer(), 10animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])for epoch in range(num_epochs):net.train()timer.start()for X, y in train_iter:trainer.zero_grad()X, y = X.to(devices[0]), y.to(devices[0])l = loss(net(X), y)l.backward()trainer.step()timer.stop()animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(net, test_iter),))print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'f'在{str(devices)}')
在单个 GPU 上训练网络
train(net, num_gpus=1, batch_size=256, lr=0.1)
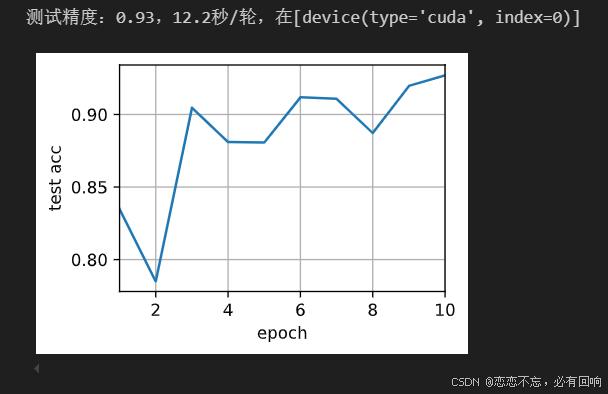
使用2个GPU进行训练
train(net, num_gpus=2, batch_size=512, lr=0.2)
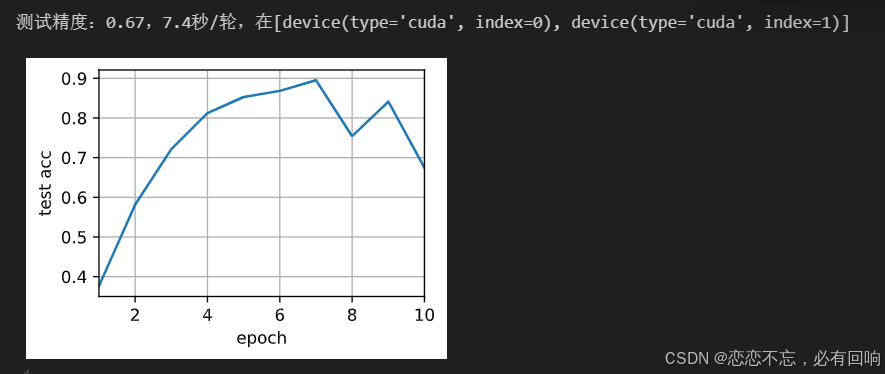
QA 思考
Q1:验证集准确率震荡较大是哪个参数影响最大呢?
A1:lr
Q2:为什么batch_size调的比较小,比如8,精度会一直在0.1左右,一直不怎么变化
A2:因为batch_size调的比较小的时候,lr 不能太大。
相关文章:
多GPU训练
写在前面 限于财力不足,本机上只有一个 GPU 可供使用,因此这部分的代码只能够稍作了解,能够使用的 GPU 也只有一个。 多 GPU 的数据并行:有几张卡,对一个小批量数据,有几张卡就分成几块,每个 …...

Java面试黄金宝典33
1. 什么是存取控制、 触发器、 存储过程 、 游标 存取控制 定义:存取控制是数据库管理系统(DBMS)为保障数据安全性与完整性,对不同用户访问数据库对象(如表、视图等)的权限加以管理的机制。它借助定义用户…...

如何在 Linux 上安装 Python
本指南介绍如何在Linux机器上安装 Python。Python 已成为开发人员、数据科学家和系统管理员必不可少的编程语言。它用于各种应用,包括 Web 开发、数据科学、自动化和机器学习。 本综合指南将引导您完成在 Linux 系统上安装Python的过程,涵盖从基本包管理…...

系统与网络安全------Windows系统安全(6)
资料整理于网络资料、书本资料、AI,仅供个人学习参考。 共享文件夹 发布共享文件夹 Windows共享概述 微软公司推出的网络文件/打印机服务系统 可以将一台主机的资源发布给其他主机共有 共享访问的优点 方便、快捷相比光盘 U盘不易受文件大小限制 可以实现访问…...

解决 Spring Boot 返回日期格式问题
springboot项目有个属性这样注解 DateTimeFormat(pattern "yyyy-MM-dd") private Date createTime; 表中是 create_time datetime DEFAULT NULL 只使用了 DateTimeFormat 注解来处理输入格式,但没有配置输出格式。返回给前端还是 createTime: "2…...

复古千禧Y2风格霓虹发光酸性镀铬金属短片音乐视频文字标题动画AE/PR模板
踏入时光机,重温 21 世纪初大胆、未来主义和超光彩的美学!这是一个动态的 After Effects 模板,旨在重现千禧年的标志性视觉效果——铬反射、霓虹灯发光、闪亮的金属和流畅的动态图形。无论您是在制作时尚宣传片、怀旧音乐视频还是时尚的社交媒…...

linux 安装 mysql记录
sudo apt-get install mysql-server 一直报错,按照下面的终于安装出来了 这个链接 https://cn.linux-console.net/?p13784 第 1 步:要删除 MySQL 及其所有依赖项,请执行以下命令: sudo apt-get remove --purge mysql* 第 2 步…...
如何设计一个本地缓存
想获取更多高质量的Java技术文章?欢迎访问Java技术小馆官网,持续更新优质内容,助力技术成长 Java技术小馆官网https://www.yuque.com/jtostring 如何设计一个本地缓存 随着系统的复杂性和数据量的增加,如何快速响应用户请求、减…...

NLP/大模型八股专栏结构解析
1.transformer 结构相关 (1)transformer的基本结构有哪些,分别的作用是什么,代码实现。 NLP高频面试题(一)——Transformer的基本结构、作用和代码实现 (2)LSTM、GRU和Transformer结…...

grep命令: 过滤
[rootxxx ~]# grep root /etc/passwd [rootxxx ~]# grep -A 2 root /etc/passwd -A #匹配行后两行 [rootxxx ~]# grep -B 2 root /etc/passwd -B #匹配行前两行 [rootxxx ~]# grep -C 2 root /etc/passwd -C #前后2行 [rootxxx ~]# grep -n root /…...
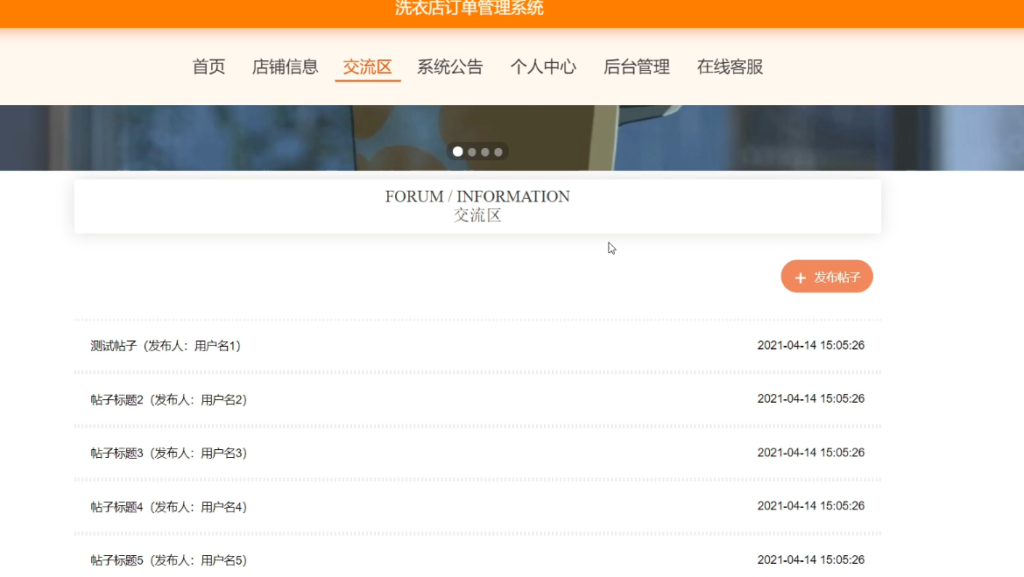
SpringBoot洗衣店订单管理系统设计与实现
一个基于SpringBoot的洗衣店订单管理系统的设计与实现。 系统概述 支持管理员管理顾客与店家信息、店家管理店铺与洗衣信息,以及顾客预约、查看洗衣信息与交流等功能。 部分功能模块 1. 管理员模块 顾客信息管理 店家信息管理 2. 店家模块 店铺信息管 …...

模版的特性及其编译分离
1.模版的分类 模版参数分为 类型形参 和 非类型形参 类型形参:出现在模版参数列表中,跟在class和typename之后的参数类型名称 非类型形参:就是用一个常量作为类(函数)模版的一个参数,在类(函…...
的完整安装指南)
基于 Ubuntu 24.04 LTS(Noble Numbat)的完整安装指南
以下是基于 Ubuntu 24.04 LTS(Noble Numbat)的完整安装指南,整合了多平台安装方法与优化建议,涵盖物理机、虚拟机及服务器场景: 一、准备工作 1. 系统要求 硬件配置: CPU:2 GHz双核或更高 内存…...
)
7-12 最长对称子串(PTA)
对给定的字符串,本题要求你输出最长对称子串的长度。例如,给定Is PAT&TAP symmetric?,最长对称子串为s PAT&TAP s,于是你应该输出11。 输入格式: 输入在一行中给出长度不超过1000的非空字符串。 输出格式&…...
NO.66十六届蓝桥杯备战|基础算法-贪心-区间问题|凌乱的yyy|Rader Installation|Sunscreen|牛栏预定(C++)
区间问题是另⼀种⽐较经典的贪⼼问题。题⽬⾯对的对象是⼀个⼀个的区间,让我们在每个区间上做出取舍。 这种题⽬的解决⽅式⼀般就是按照区间的左端点或者是右端点排序,然后在排序之后的区间上,根据题⽬要求,制定出相应的贪⼼策略&…...

搭建redis主从同步实现读写分离(原理剖析)
搭建redis主从同步实现读写分离(原理剖析) 文章目录 搭建redis主从同步实现读写分离(原理剖析)前言一、搭建主从同步二、同步原理 前言 为什么要学习redis主从同步,实现读写分析。因为单机的redis虽然是基于内存,单机并发已经能支撑很高。但是随着业务量…...
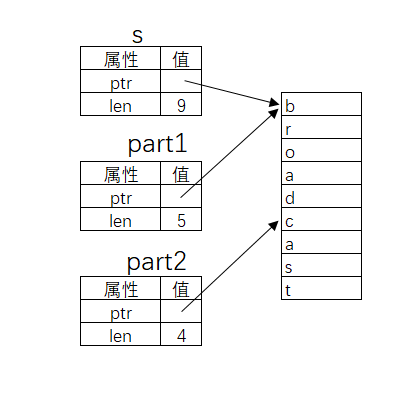
Rust切片、结构体、枚举
文章目录 切片类型字符串切片其他结构的切片 结构体结构体实例元组结构体结构体所有权输出结构体结构体的方法结构体关联函数单元结构体 枚举match语法Option枚举类if let 语句 切片类型 切片(Slice)是对数据值的部分“引用” 我们可以从一个数据集合中…...

使用人车关系核验API快速核验车辆一致性
一、 引言 随着车辆交易的日益频繁,二手车市场和金融领域的汽车抵押业务蓬勃发展。然而,欺诈和盗窃行为也时有发生,给行业带来了不小的冲击。例如,3月20日央视曝光的“新能源车虚假租赁骗补”产业链,以及某共享汽车平…...

【学习笔记】深度学习环境部署相关
文章目录 [AI硬件科普] 内存/显存带宽,从 NVIDIA 到苹果 M4[工具使用] tmux 会话管理及会话持久性[A100 02] GPU 服务器压力测试,gpu burn,cpu burn,cuda samples[A100 01] A100 服务器开箱,超微平台,gpu、…...

股票日数据使用_未复权日数据生成前复权日周月季年数据
目录 前置: 准备 代码:数据库交互部分 代码:生成前复权 日、周、月、季、年数据 前置: 1 未复权日数据获取,请查看 https://blog.csdn.net/m0_37967652/article/details/146435589 数据库使用PostgreSQL。更新日…...

Java程序设计第1章:概述
一、Hello World 1.代码: public class HelloWorld {public static void main(String[] args){System.out.println("Hello World!");} } 2.运行结果: Hello World! 二、输出姓名、学号、班级 1.题目: 编写一个Application&a…...
【LeetCode Solutions】LeetCode 146 ~ 150 题解
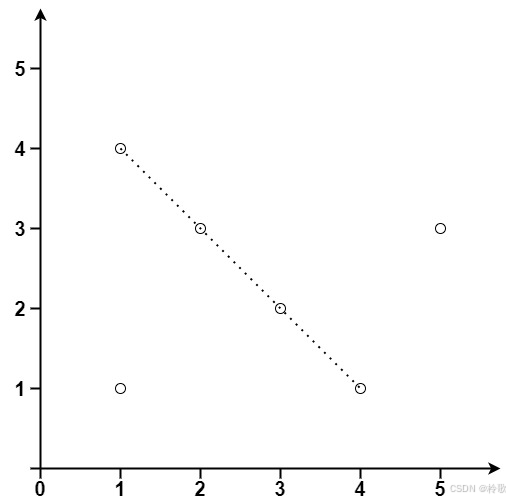
CONTENTS LeetCode 146. LRU 缓存(中等)LeetCode 147. 对链表进行插入排序(中等)LeetCode 148. 排序链表(中等)LeetCode 149. 直线上最多的点数(困难)LeetCode 150. 逆波兰表达式求值…...

《 如何更高效地学习》
🚀个人主页:BabyZZの秘密日记 📖收入专栏:个人谈心 🌍文章目入 一、明确学习目标二、制定学习计划三、选择合适的学习方法(一)主动学习(二)分散学习(三&#…...

常用中间件合集
简介 在游戏或者web服务器开发过程中 难免会使用一些中间件 正所谓有现成的 就没必要重复造轮子了 以下大概介绍下常用的中间件nginx etcd nats docker k8s nginx 简介 Nginx是一个 轻量级/高性能的反向代理Web服务器,他实现非常高效的反向代理、负载平衡,他可以处理2-3万…...

分布式数据一致性场景与方案处理分析|得物技术
一、引言 在经典的CAP理论中一致性是指分布式或多副本系统中数据在任一时刻均保持逻辑与物理状态的统一,这是确保业务逻辑正确性和系统可靠性的核心要素。在单体应用单一数据库中可以直接通过本地事务(ACID)保证数据的强一致性。 然而随着微服务架构的普及和业务场…...
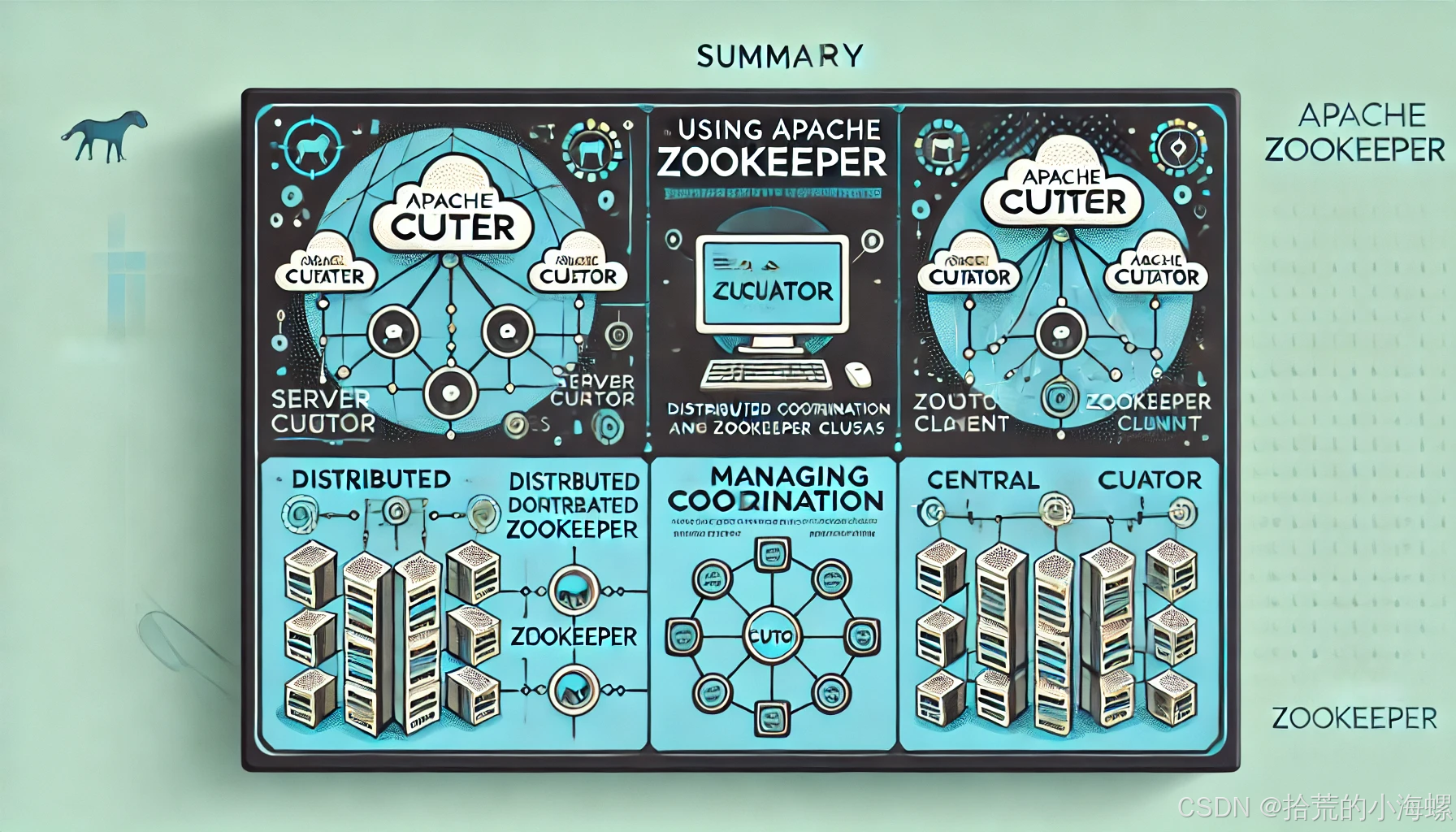
JAVA:使用 Curator 进行 ZooKeeper 操作的技术指南
1、简述 Apache Curator 是一个基于 ZooKeeper 的 Java 客户端库,它极大地简化了使用 ZooKeeper 的开发工作。Curator 提供了高层次的 API,封装了很多复杂的 ZooKeeper 操作,例如连接管理、分布式锁、Leader 选举等。 在分布式系统中&#…...
)
C++ - 宏基础(简单常量替换宏、函数样式的宏、多行宏、预定义宏、字符串化宏、连接宏、可变参数日志宏)
宏概述 在编程中,宏(Macro)是一种预处理器指令 宏可以让程序员在源代码中定义一段值或代码的别名,在编译程序之前,预处理器会查找这些宏,并将其替换为相应的值或代码 C 宏 在 C 中,宏可以通过…...
Linux中的调试器gdb与冯·诺伊曼体系
一、Linux中的调试器:gdb 1.1安装与版本查看 可以使用yum进行安装: yum install -y gdb 版本查看:使用指令 gdb --version 1.2调试的先决条件:release版本与debug版本的切换 debug版本:含有调试信息 release版本…...
STM32 + keil5 跑马灯
硬件清单 1. STM32F407VET6 2. STLINK V2下载器(带线) 环境配置 1. 安装ST-LINK 2. 安装并配置 keil5 https://blog.csdn.net/qq_36535414/article/details/108947292 https://blog.csdn.net/weixin_43732386/article/details/117375266 3. 接线并下载 点击"LOAD“&a…...

Ruby语言的代码重构
Ruby语言的代码重构:探索清晰、可维护与高效的代码 引言 在软件开发的过程中,代码的质量直接影响到项目的可维护性、扩展性和整体性能。随着时间的推移,系统的需求变化,代码可能会变得混乱和难以理解,因此࿰…...