从 Credit Metrics 到 CPV:现代信用风险模型的进化与挑战
文章目录
- 一、信用风险基础
- 二、Credit Risk + 模型
- 核心思想
- 关键假设
- 模型框架
- 实施步骤
- 优缺点
- 适用场景
- 三、Credit Metrics 模型
- 核心思想
- 关键假设
- 模型框架
- 实施步骤
- 优缺点
- 适用场景
- 四、Credit Portfolio View 模型
- 核心思想
- 关键假设
- 模型框架
- 实施步骤
- 优缺点
- 适用场景
- 五、总结
一、信用风险基础
信用风险是金融领域极为重要的风险类型,它指的是交易对手因各种主客观因素无法按合同履约,致使经济主体面临损失的风险。其主要特征涵盖潜在性、长期性与破坏性,与市场风险、流动性风险等共同构成了金融机构的风险体系。在风险管理流程中,风险识别、分析、评估及应对等环节至关重要,而信用风险的测量则是其中的关键一环。
传统信用风险测量方式主要依赖专家经验和定性分析,这种方式在面对复杂多变的金融市场时,存在一定的局限性。随着金融市场的发展和风险管理技术的进步,现代风险管理逐渐转向量化手段。信用风险的测量可以从预期损失和非预期损失两个维度展开:预期损失基于历史数据和统计模型,预测风险的长期平均水平;非预期损失则是超出预期损失的波动部分,需通过资本储备来应对。在此背景下,像 Credit Metrics、Credit Risk + 等量化模型逐渐成为主流,它们借助数学建模与大数据分析,有效提升了风险测量的精度与科学性。
二、Credit Risk + 模型
Credit Risk + 模型由瑞士信贷银行开发,是一种基于精算理论的信用风险量化模型。该模型假设贷款违约事件相互独立,且违约概率服从泊松分布,通过计算贷款组合中各贷款违约的概率分布来评估风险。其核心优势在于能够高效处理大规模贷款组合,计算过程相对简便,且对数据要求相对较低,尤其适用于违约率较低的信贷资产组合。然而,该模型也存在一定局限性,例如未考虑信用评级的动态变化以及宏观经济因素对信用风险的影响,在复杂多变的市场环境下,其准确性可能会受到一定影响。
Credit Risk+ 模型是一种用于评估信用组合风险的量化工具,由瑞士信贷(Credit Suisse)于1997年提出。它属于精算类模型(Actuarial Approach),通过分析违约事件的概率分布来估计组合的潜在损失,适用于低违约概率的信用资产组合(如债券、贷款等)。
核心思想
Credit Risk+ 的核心理念是将信用风险建模为违约事件的频率和损失严重程度的组合。与基于资产价值变动的结构化模型(如CreditMetrics)不同,它更关注违约的统计特性,类似于保险业中的损失模型。
关键假设
- 外生违约概率:
- 违约概率(PD)由外部因素(如评级机构)提供,模型本身不预测违约。
- 假设违约事件是随机的,服从泊松分布(Poisson Distribution)。
- 独立性:
- 违约事件之间相互独立(除非引入风险因子)。
- 损失严重程度(LGD,Loss Given Default)与违约概率相互独立。
- 损失严重程度:
- 可以是固定值(如每笔敞口的LGD已知),或通过概率分布建模(如Beta分布)。
模型框架
- 违约概率的泊松近似:
- 每个债务人的违约概率 ( \lambda_i ) 很小,近似服从泊松分布:
P ( N i = k ) = e − λ i λ i k k ! P(N_i = k) = \frac{e^{-\lambda_i} \lambda_i^k}{k!} P(Ni=k)=k!e−λiλik - 组合总违约数 ( N = ∑ N i N = \sum N_i N=∑Ni ),总损失 ( L = ∑ N i × E A D i × L G D i L = \sum N_i \times EAD_i \times LGD_i L=∑Ni×EADi×LGDi ),其中 ( EAD ) 是风险敞口。
- 每个债务人的违约概率 ( \lambda_i ) 很小,近似服从泊松分布:
- 组合损失分布:
- 通过生成函数(Probability Generating Function, PGF)或递推方法计算损失分布。
- 若引入系统性风险因子(如行业、地区),违约概率可分解为:
λ i = λ i 0 × ( 1 + ∑ β i k Y k ) \lambda_i = \lambda_i^0 \times (1 + \sum \beta_{ik} Y_k) λi=λi0×(1+∑βikYk)
其中 ( Y_k ) 是风险因子,( \beta_{ik} ) 是债务人对风险因子的敏感度。
- 风险指标:
- 计算预期损失(EL)和非预期损失(UL),以及组合的VaR(Value at Risk)或ES(Expected Shortfall)。
实施步骤
- 参数设定:
- 输入每个债务人的 ( PD )、( EAD )、( LGD )。
- 选择是否引入风险因子(以捕捉违约相关性)。
- 计算损失分布:
- 使用泊松叠加或Panjer递推算法计算组合损失的频数分布。
- 若存在风险因子,需对系统性风险进行积分(如傅里叶变换)。
- 风险度量:
- 输出损失分布的百分位数(如99.9% VaR),计算经济资本。
优缺点
优点:
- 计算效率高,适合大规模组合。
- 无需复杂的资产相关性假设。
- 透明且易于解释。
缺点:
- 忽略评级迁移风险(仅考虑违约)。
- 独立性假设可能低估尾部风险(需通过风险因子调整)。
- 对低违约概率组合更适用,高违约资产需谨慎使用。
适用场景
- 银行或金融机构的贷款组合。
- 分散化良好的债券投资组合。
- 需要快速评估组合风险的场景(如压力测试)。
三、Credit Metrics 模型
Credit Metrics 模型由 J.P. 摩根于 1997 年推出,是全球首个基于信用评级的证券组合信用风险模型。该模型以信用评级为基础,深入分析借款人信用评级的迁移概率,进而计算贷款或债券在不同信用状态下的价值变化,以此评估组合的违约风险和潜在损失。其创新之处在于巧妙地将信用风险与市场风险相结合,能够全面反映信用资产的市场价值波动。该模型覆盖了传统商业贷款、信用证、衍生产品等多种金融工具,为金融机构提供了统一的风险评估框架。不过,其对历史数据的依赖性较强,且模型本身较为复杂,可能导致实施成本较高,对金融机构的数据基础和专业能力提出了较高要求。
Credit Metrics 模型 是一种广泛使用的信用风险量化工具,由J.P. Morgan于1997年提出。它属于结构化模型(Structural Model),基于公司资产价值变动和违约相关性,评估信用组合的潜在损失。与Credit Risk+不同,Credit Metrics不仅考虑违约风险,还纳入信用评级迁移(Rating Migration)对组合价值的影响,适用于需要动态评估市场风险的金融机构。
核心思想
Credit Metrics 的核心理念是通过模拟债务人信用质量的动态变化(如评级升级或降级)及其对资产价值的影响,计算组合的未来价值分布,进而度量风险。其理论基础源自Merton模型(将公司资产视为看涨期权),认为违约是资产价值低于负债阈值的结果。
关键假设
- 资产价值驱动违约:
- 公司违约由其资产价值与负债的对比决定,资产价值服从几何布朗运动。
- 资产价值波动率影响违约概率和信用价差。
- 评级迁移矩阵:
- 使用历史数据构建评级迁移矩阵,描述不同信用评级间的转移概率(如AAA级降为AA级的概率)。
- 评级变化直接影响债项的市场价值(通过信用价差变动)。
- 相关性建模:
- 债务人之间的违约相关性通过资产价值相关性间接建模(如行业、地区因子)。
- 使用多因子模型(如权益收益率相关性)捕捉系统性风险。
模型框架
- 单笔敞口估值:
- 根据当前评级、剩余期限和利率曲线,计算债项在未来的现值。
- 若评级迁移,重新估值(如降级导致信用价差扩大,现值下降)。
- 组合损失分布:
- 通过蒙特卡洛模拟生成资产价值路径,模拟评级迁移和违约事件。
- 对每笔敞口重新估值后,汇总组合总价值,构建未来价值分布。
- 风险指标:
- 计算组合的VaR(给定置信水平下的最大损失)或CVaR(条件VaR)。
- 输出信用风险的资本要求(如99.9%置信水平的资本覆盖)。
实施步骤
- 输入参数:
- 债务人的当前评级、敞口金额、期限、回收率(LGD)。
- 评级迁移矩阵、无风险利率曲线、信用价差曲线。
- 相关性建模:
- 使用行业分类或因子模型(如权益收益率)估计资产价值相关性。
- 蒙特卡洛模拟:
- 生成系统性风险因子(如宏观经济变量)的随机路径。
- 对每个债务人模拟资产价值变动,判断是否触发评级迁移或违约。
- 计算组合在模拟路径下的总价值。
- 风险度量:
- 从价值分布中提取百分位数损失(VaR)和尾部损失期望(CVaR)。
优缺点
优点:
- 动态捕捉评级迁移风险(非违约损失),更贴近市场风险。
- 提供基于市场价值的风险度量(如VaR),适用于交易账户。
- 系统性风险通过相关性建模,避免独立性假设的偏差。
缺点:
- 计算复杂度高,依赖大量数据(如评级迁移矩阵、相关性估计)。
- 对资产价值模型假设敏感(如几何布朗运动的合理性)。
- 忽略流动性风险和极端事件(需通过压力测试补充)。
适用场景
- 银行交易账户中的债券、CDS等可交易信用产品。
- 需要评估评级迁移对组合市值影响的场景(如投资组合优化)。
- 资本充足率计算(如Basel II/III的内部评级法)。
四、Credit Portfolio View 模型
Credit Portfolio View 模型由麦肯锡公司开发,是一种结合宏观经济因素的动态信用风险模型。与传统模型仅依赖历史数据不同,该模型创新性地引入宏观经济变量,如 GDP 增长率、失业率、利率等,通过模拟宏观经济周期对信用违约概率的影响,更真实、动态地反映信用风险的变化。尤其适用于分析经济周期波动下信用风险集中爆发的问题,能够帮助金融机构提前预警系统性风险,提前做好风险防范和应对措施。然而,该模型对宏观经济数据的质量和预测准确性要求较高,实际应用中需要结合多种数据源进行校准,以确保模型输出结果的可靠性。
Credit Portfolio View(CPV)模型 是由麦肯锡公司(McKinsey)于1997年提出的信用风险量化模型,属于宏观经济驱动型模型。其核心思想是通过捕捉宏观经济变量(如GDP、失业率、利率等)对违约概率和信用质量的影响,动态评估信用组合的风险。与Credit Metrics和Credit Risk+不同,CPV强调经济周期对信用风险的驱动作用,适用于分析系统性风险和经济压力情景下的组合表现。
核心思想
CPV模型认为,违约概率和信用迁移并非静态,而是随着宏观经济环境的变化而波动。例如,经济衰退时违约率上升,而经济复苏时违约率下降。CPV通过建立宏观经济变量与违约概率之间的统计关系,模拟不同经济情景下的信用组合损失分布。
关键假设
- 宏观经济驱动违约:
- 违约概率(PD)是宏观经济变量(如GDP增长率、利率、失业率)的函数。
- 模型使用历史数据拟合宏观经济变量与违约率的统计关系(如Logit模型)。
- 多阶段建模:
- 阶段一:建立宏观经济模型,预测未来经济变量的路径。
- 阶段二:将经济变量映射到违约概率和评级迁移概率(条件迁移矩阵)。
- 阶段三:基于模拟的违约和迁移路径,计算组合损失。
- 动态调整:
- 违约概率和迁移矩阵随经济周期动态调整,而非固定不变。
模型框架
- 宏观经济建模:
- 使用向量自回归(VAR)模型或因子模型预测宏观经济变量的未来路径。
- 例如,建立失业率 ( U_t ) 与GDP增长率 ( G_t ) 的关系:
U t = α + β G t − 1 + ϵ t U_t = \alpha + \beta G_{t-1} + \epsilon_t Ut=α+βGt−1+ϵt
- 违约概率建模:
- 将宏观经济变量映射到违约概率。例如,使用Logit模型:
P D t = 1 1 + e − ( a + b ⋅ G t + c ⋅ U t ) PD_t = \frac{1}{1 + e^{-(a + b \cdot G_t + c \cdot U_t)}} PDt=1+e−(a+b⋅Gt+c⋅Ut)1 - 经济衰退时,( G_t )下降、( U_t )上升,导致 ( PD_t ) 增加。
- 将宏观经济变量映射到违约概率。例如,使用Logit模型:
- 条件迁移矩阵:
- 根据经济状态调整评级迁移概率。例如,经济恶化时,AAA级债券降级概率上升。
- 组合损失模拟:
- 基于模拟的宏观经济路径和条件违约概率,生成组合的损失分布。
实施步骤
- 数据准备:
- 收集历史宏观经济数据(GDP、利率、失业率等)和违约数据。
- 划分经济周期阶段(扩张、衰退等)。
- 建立宏观经济模型:
- 使用时间序列模型(如VAR)预测未来经济变量。
- 可能加入行业或地区特定因子(如房地产价格指数)。
- 违约概率与迁移矩阵校准:
- 通过回归或机器学习方法拟合宏观经济变量与违约率的关系。
- 调整评级迁移矩阵以反映经济压力情景。
- 蒙特卡洛模拟:
- 生成大量宏观经济情景路径。
- 对每条路径计算违约概率和迁移概率,并评估组合损失。
- 风险度量:
- 计算压力情景下的VaR、预期损失(EL)和经济资本。
优缺点
优点:
- 捕捉系统性风险:直接建模宏观经济冲击对信用风险的影响。
- 动态适应性:适用于压力测试和逆周期资本管理。
- 灵活性:可针对行业、地区定制宏观经济因子。
缺点:
- 数据需求高:依赖长期、高质量的历史经济与违约数据。
- 模型复杂性:需同时处理宏观经济预测和信用风险建模。
- 前瞻性偏差:历史经济关系可能在未来失效(如结构突变)。
适用场景
- 压力测试:评估经济衰退、金融危机等极端事件的组合损失。
- 跨周期风险管理:逆周期调整资本缓冲(如Basel III要求)。
- 跨国金融机构:管理不同国家/地区的宏观经济风险敞口。
- 行业分析:分析特定行业(如房地产、能源)对宏观经济的敏感性。
五、总结
现代信用风险模型借助量化分析与科学建模手段,极大地提升了风险管理的精细化水平。不同模型各具优劣,金融机构在选择时应综合考虑自身业务特点、数据基础以及风险偏好等因素,灵活选择合适的模型,或结合多种模型构建全面的风险评估体系,以此来有效应对复杂多变的市场环境,实现稳健经营与可持续发展。
相关文章:

从 Credit Metrics 到 CPV:现代信用风险模型的进化与挑战
文章目录 一、信用风险基础二、Credit Risk 模型核心思想关键假设模型框架实施步骤优缺点适用场景 三、Credit Metrics 模型核心思想关键假设模型框架实施步骤优缺点适用场景 四、Credit Portfolio View 模型核心思想关键假设模型框架实施步骤优缺点适用场景 五、总结 一、信用…...
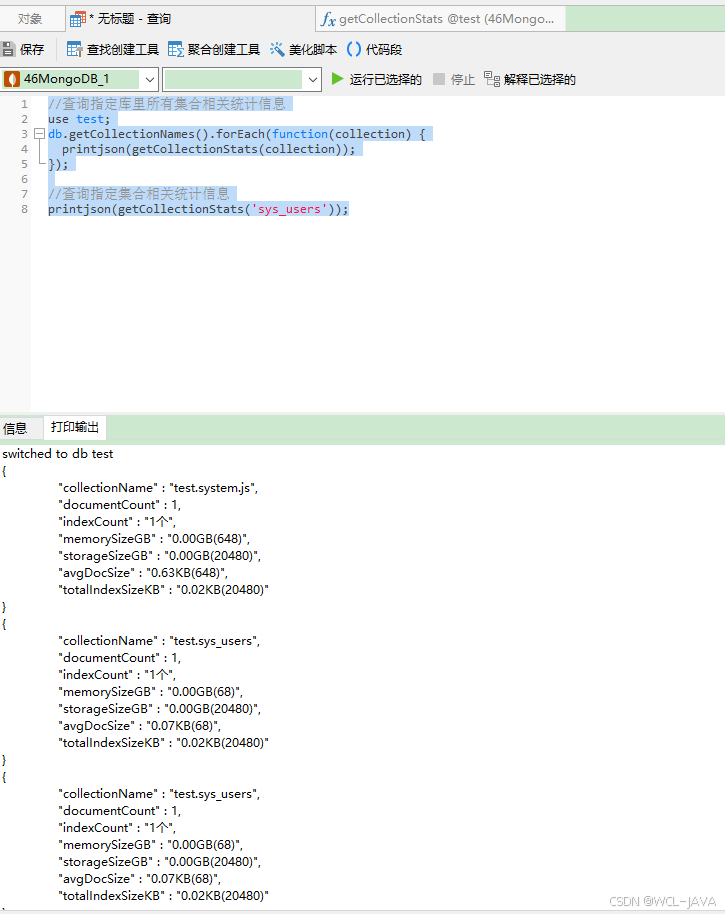
Docker快速安装MongoDB并配置主从同步
目录 一、创建相关目录及授权 二、下载并运行MongoDB容器 三、配置主从复制 四、客户端远程连接 五、验证主从同步 六、停止和恢复复制集 七、常用命令 一、创建相关目录及授权 创建主节点mongodb数据及日志目录并授权 mkdir -p /usr/local/mongodb/mongodb1/data mkdir …...

Kafka 中的事务
Kafka 中的 事务(Transactions) 是为了解决 消息处理的原子性和幂等性问题,确保一组消息要么全部成功写入、要么全部失败,不出现中间状态或重复写入。事务机制尤其适合于 “精确一次(Exactly-Once)” 的处理…...

C++ 内存访问模式优化:从架构到实践
内存架构概览:CPU 与内存的 “速度博弈” 层级结构:从寄存器到主存 CPU 堪称计算的 “大脑”,然而它与内存之间的速度差距,宛如高速公路与乡间小路。现代计算机借助多级内存体系来缓和这一矛盾,其核心思路是…...

Golang系列 - 内存对齐
Golang系列-内存对齐 常见类型header的size大小内存对齐空结构体类型参考 摘要: 本文将围绕内存对齐展开, 包括字符串、数组、切片等类型header的size大小、内存对齐、空结构体类型的对齐等等内容. 关键词: Golang, 内存对齐, 字符串, 数组, 切片 常见类型header的size大小 首…...

SOMEIP通信矩阵解读
目录 1 摘要2 SOME/IP通信矩阵详细属性定义与示例2.1 服务基础属性2.2 数据类型定义2.3 服务实例与网络配置参数2.4 SOME/IP-SD Multicast 配置(SOME/IP服务发现组播配置)2.5 SOME/IP-SD Unicast 配置2.6 SOME/IP-SD ECU 配置参数详解 3 总结 1 摘要 本…...

Excel + VBA 实现“准实时“数据的方法
Excel 本身是静态数据处理工具,但结合 VBA(Visual Basic for Applications) 可以实现 准实时数据更新,不过严格意义上的 实时数据(如毫秒级刷新)仍然受限。以下是详细分析: 1. Excel + VBA 实现“准实时”数据的方法 (1) 定时刷新(Timer 或 Application.OnTime) Appl…...

网络原理 - HTTP/HTTPS
1. HTTP 1.1 HTTP是什么? HTTP (全称为 “超文本传输协议”) 是⼀种应用非常广泛的应用层协议. HTTP发展史: HTTP 诞生于1991年. 目前已经发展为最主流使用的⼀种应用层协议 最新的 HTTP 3 版本也正在完善中, 目前 Google / Facebook 等公司的产品已经…...

C++设计模式-解释器模式:从基本介绍,内部原理、应用场景、使用方法,常见问题和解决方案进行深度解析
一、解释器模式的基本介绍 1.1 模式定义与核心思想 解释器模式(Interpreter Pattern)是一种行为型设计模式,其核心思想是为特定领域语言(DSL)定义语法规则,并构建一个解释器来解析和执行该语言的句子。它…...
OCC Shape 操作
#pragma once #include <iostream> #include <string> #include <filesystem> #include <TopoDS_Shape.hxx> #include <string>class GeometryIO { public:// 加载几何模型:支持 .brep, .step/.stp, .iges/.igsstatic TopoDS_Shape L…...

深度学习入门(四):误差反向传播法
文章目录 前言链式法则什么是链式法则链式法则和计算图 反向传播加法节点的反向传播乘法节点的反向传播苹果的例子 简单层的实现乘法层的实现加法层的实现 激活函数层的实现ReLu层Sigmoid层 Affine层/SoftMax层的实现Affine层Softmax层 误差反向传播的实现参考资料 前言 上一篇…...
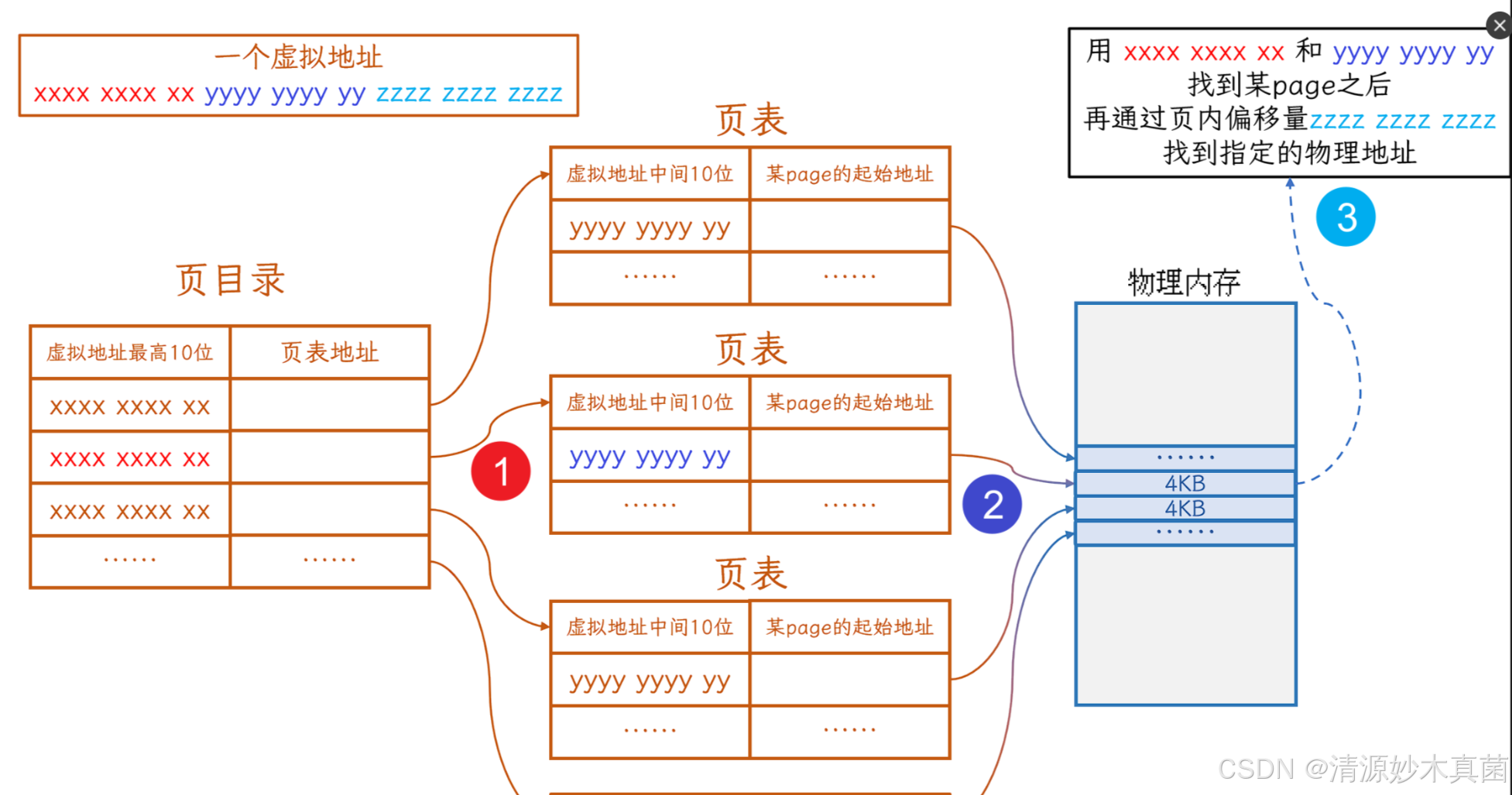
Linux:页表详解(虚拟地址到物理地址转换过程)
文章目录 前言一、分页式存储管理1.1 虚拟地址和页表的由来1.2 物理内存管理与页表的数据结构 二、 多级页表2.1 页表项2.2 多级页表的组成 总结 前言 在我们之前的学习中,我们对于页表的认识仅限于虚拟地址到物理地址转换的桥梁,然而对于具体的转换实现…...

AF3 OpenFoldDataLoader类解读
AlphaFold3 data_modules 模块的 OpenFoldDataLoader 类继承自 PyTorch 的 torch.utils.data.DataLoader。该类主要对原始 DataLoader 做了批数据增强与控制循环迭代次数(recycling)相关的处理。 源代码: class OpenFoldDataLoader(torch.utils.data.DataLoader):def __in…...

初见TypeScript
类型语言,在代码规模逐渐增大时,类型相关的错误难以排查。TypeScript 由微软开发,它本质上是 JavaScript 的超集,为 JavaScript 添加了静态类型系统,让开发者在编码阶段就能发现潜在类型错误,提升代码质量&…...

常见的 JavaScript 框架和库
在现代前端开发中,JavaScript框架和库成为了构建高效、可维护应用程序的关键工具。本文将介绍四个常见的JavaScript框架和库:React、Vue.js、Angular 和 Node.js,并探讨它们的特点、使用场景及适用场合。 1. React — 构建用户界面的JavaScri…...

机器学习代码基础——ML2 使用梯度下降的线性回归
ML2 使用梯度下降的线性回归 牛客网 描述 编写一个使用梯度下降执行线性回归的 Python 函数。该函数应将 NumPy 数组 X(具有一列截距的特征)和 y(目标)作为输入,以及学习率 alpha 和迭代次数,并返回一个…...
PostgreSQL 一文从安装到入门掌握基本应用开发能力!
本篇文章主要讲解 PostgreSQL 的安装及入门的基础开发能力,包括增删改查,建库建表等操作的说明。navcat 的日常管理方法等相关知识。 日期:2025年4月6日 作者:任聪聪 一、 PostgreSQL的介绍 特点:开源、免费、高性能、关系数据库、可靠性、稳定性。 官网地址:https://w…...
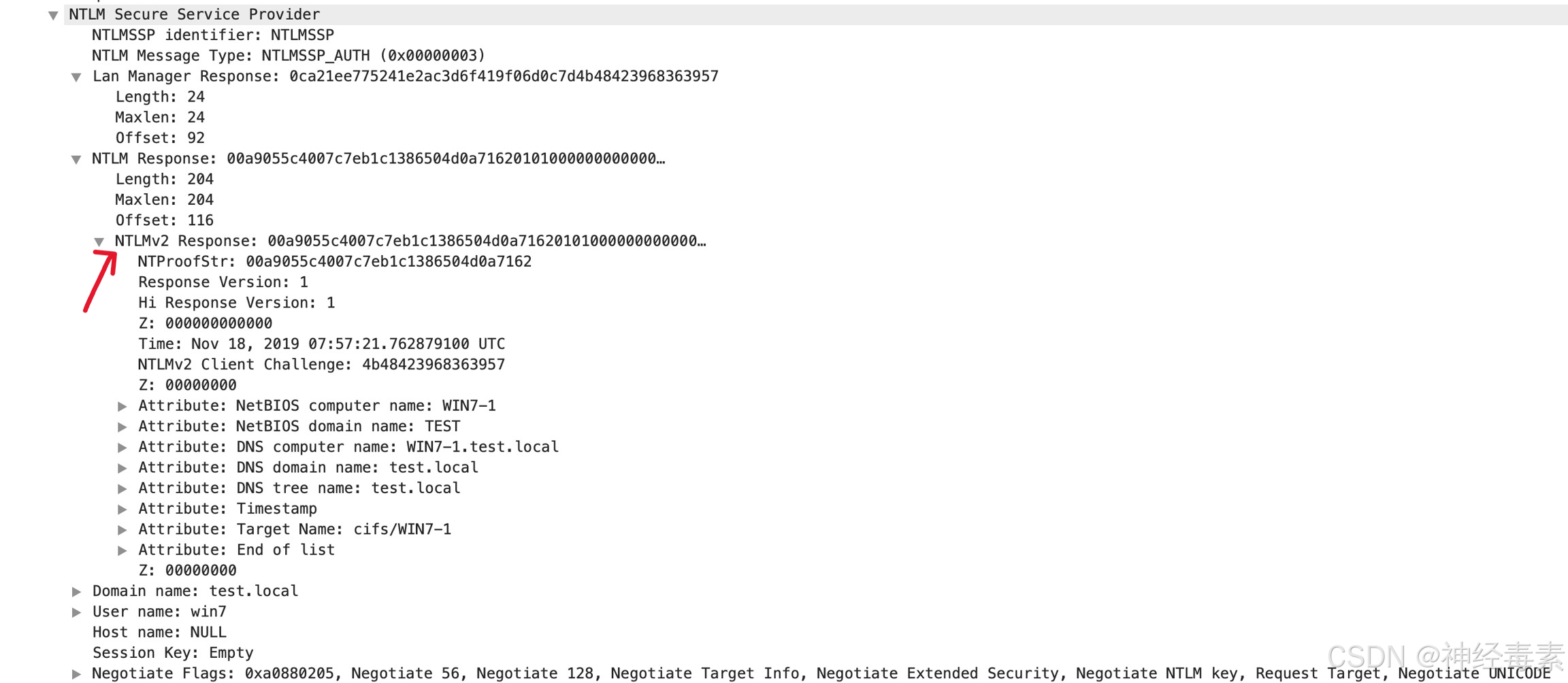
WEB安全--内网渗透--LMNTLM基础
一、前言 LM Hash和NTLM Hash是Windows系统中的两种加密算法,不过LM Hash加密算法存在缺陷,在Windows Vista 和 Windows Server 2008开始,默认情况下只存储NTLM Hash,LM Hash将不再存在。所以我们会着重分析NTLM Hash。 在我们内…...

查询条件与查询数据的ajax拼装
下面我将介绍如何使用 AJAX 动态拼装查询条件和获取查询数据,包括前端和后端的完整实现方案。 一、前端实现方案 1. 基础 HTML 结构 html 复制 <div class"query-container"><!-- 查询条件表单 --><form id"queryForm">…...
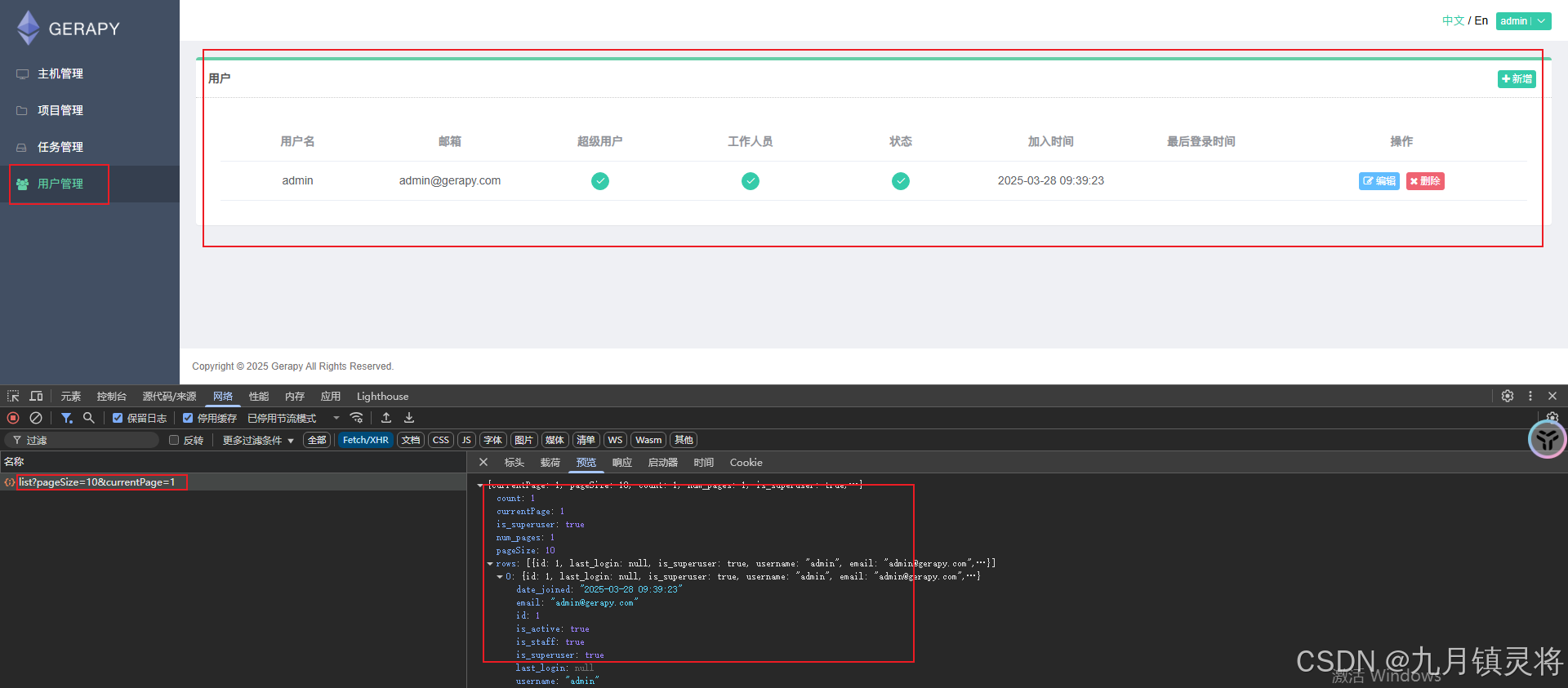
8.用户管理专栏主页面开发
用户管理专栏主页面开发 写在前面用户权限控制用户列表接口设计主页面开发前端account/Index.vuelangs/zh.jsstore.js 后端Paginator概述基本用法代码示例属性与方法 urls.pyviews.py 运行效果 总结 欢迎加入Gerapy二次开发教程专栏! 本专栏专为新手开发者精心策划了…...

室内指路机器人是否支持与第三方软件对接?
嘿,你知道吗?叁仟室内指路机器人可有个超厉害的技能,那就是能和第三方软件 “手牵手” 哦,接下来就带你一探究竟! 从技术魔法角度看哈:好多室内指路机器人都像拥有超能力的小魔法师,采用开放式…...

Apache BookKeeper Ledger 的底层存储机制解析
Apache BookKeeper 的 ledger(账本)是其核心数据存储单元,底层存储机制结合了日志追加(append-only)、分布式存储和容错设计。Ledger 的数据存储在 Bookie 节点的磁盘上,具体实现涉及 Journal(日…...

从代码上深入学习GraphRag
网上关于该算法的解析都停留在大概流程上,但是具体解析细节未知,由于代码是PipeLine形式因此阅读起来比较麻烦,本文希望通过阅读项目代码来解析其算法的具体实现细节,特别是如何利用大模型来完成图谱生成和检索增强的实现细节。 …...

通俗地讲述DDD的设计
通俗地讲述DDD的设计 前言为什么要使用DDDDDD架构分层重构实践关键问题解决方案通过领域事件机制解耦服务依赖:防止逻辑下沉 领域划分电商场景下的领域划分 结语完结撒花,如有需要收藏的看官,顺便也用发财的小手点点赞哈,…...
【Redis】通用命令
使用者通过redis-cli客户端和redis服务器交互,涉及到很多的redis命令,redis的命令非常多,我们需要多练习常用的命令,以及学会使用redis的文档。 一、get和set命令(最核心的命令) Redis中最核心的两个命令&…...

网络安全技术文档
网络安全技术文档 1. 概述 网络安全是指通过技术手段和管理措施,保护网络系统的硬件、软件及其数据不受偶然或恶意破坏、更改、泄露,确保系统连续可靠运行,网络服务不中断。 2. 常见网络威胁 2.1 攻击类型 DDoS攻击:分布式拒…...
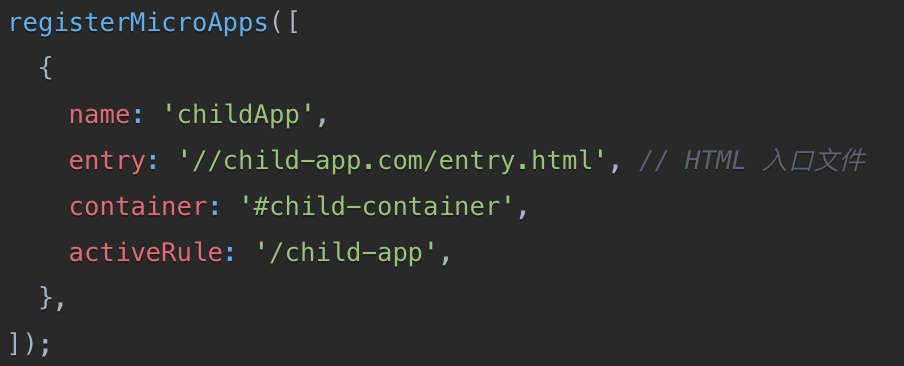
微前端随笔
✨ single-spa: js-entry 通过es-module 或 umd 动态插入 js 脚本 ,在主应用中发送请求,来获取子应用的包, 该子应用的包 singleSpa.registerApplication({name: app1,app: () > import(http://localhost:8080/app1.js),active…...

【36期获取股票数据API接口】如何用Python、Java等五种主流语言实例演示获取股票行情api接口之沪深A股当天逐笔大单交易数据及接口API说明文档
在量化分析领域,实时且准确的数据接口是成功的基石。经过多次实际测试,我将已确认可用的数据接口分享给正在从事量化分析的朋友们,希望能够对你们的研究和工作有所帮助,接下来我会用Python、JavaScript(Node.js&…...
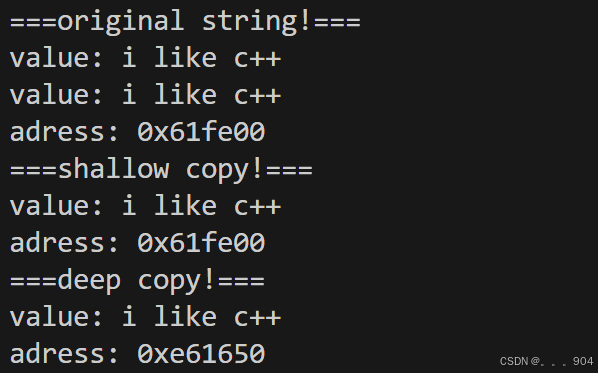
C++中的浅拷贝和深拷贝
浅拷贝只是将变量的值赋予给另外一个变量,在遇到指针类型时,浅拷贝只会把当前指针的值,也就是该指针指向的地址赋予给另外一个指针,二者指向相同的地址; 深拷贝在遇到指针类型时,会先将当前指针指向地址包…...

二叉树与红黑树核心知识点及面试重点
二叉树与红黑树核心知识点及面试重点 一、二叉树 (Binary Tree) 1. 基础概念 定义:每个节点最多有两个子节点(左子节点和右子节点) 术语: 根节点:最顶层的节点 叶子节点:没有子节点的节点 深度…...