WGAN-GP 原理及实现(pytorch版)
WGAN-GP 原理及实现
- 一、WGAN-GP 原理
- 1.1 WGAN-GP 核心原理
- 1.2 WGAN-GP 实现步骤
- 1.3 总结
- 二、WGAN-GP 实现
- 2.1 导包
- 2.2 数据加载和处理
- 2.3 构建生成器
- 2.4 构建判别器
- 2.5 训练和保存模型
- 2.6 图片转GIF
一、WGAN-GP 原理
Wasserstein GAN with Gradient Penalty (WGAN-GP) 是对原始 WGAN 的改进,通过梯度惩罚(Gradient Penalty)替代权重裁剪(Weight Clipping),解决了 WGAN 训练不稳定、权重裁剪导致梯度消失或爆炸的问题。
1.1 WGAN-GP 核心原理
(1) Wasserstein 距离(Earth-Mover 距离)
- 原始 GAN 的 JS 散度在分布不重叠时梯度消失,而 WGAN 使用 Wasserstein 距离衡量生成分布 P g P_g Pg 和真实分布 P r P_r Pr 的距离:
W ( P r , P g ) = inf γ ∼ Π ( P r , P g ) E ( x , y ) ∼ γ [ ∥ x − y ∥ ] W(P_r, P_g) = \inf_{\gamma \sim \Pi(P_r, P_g)} \mathbb{E}_{(x,y)\sim \gamma} [\|x-y\|] W(Pr,Pg)=infγ∼Π(Pr,Pg)E(x,y)∼γ[∥x−y∥] - 通过 Kantorovich-Rubinstein 对偶形式,转化为:
W ( P r , P g ) = sup ∥ D ∥ L ≤ 1 E x ∼ P r [ D ( x ) ] − E z ∼ P z [ D ( G ( z ) ) ] W(P_r, P_g) = \sup_{\|D\|_L \leq 1} \mathbb{E}_{x \sim P_r}[D(x)] - \mathbb{E}_{z \sim P_z}[D(G(z))] W(Pr,Pg)=sup∥D∥L≤1Ex∼Pr[D(x)]−Ez∼Pz[D(G(z))],其中 D D D 是 1-Lipschitz 函数(梯度范数不超过 1)
(2) 梯度惩罚(Gradient Penalty)
- 原始 WGAN 的问题:通过权重裁剪强制判别器(Critic)满足 Lipschitz 约束,但会导致梯度不稳定或容量下降
- WGAN-GP 的改进:直接对判别器的梯度施加惩罚项,强制其梯度范数接近 1: λ ⋅ E x ^ ∼ P x ^ \lambda \cdot \mathbb{E}_{\hat{x} \sim P_{\hat{x}}} λ⋅Ex^∼Px^ [ ( ∥ ∇ x ^ D ( x ^ ) ∥ 2 − 1 ) 2 ] \left [(\|\nabla_{\hat{x}} D(\hat{x})\|_2 - 1)^2 \right] [(∥∇x^D(x^)∥2−1)2]
- x ^ \hat{x} x^ 是真实数据和生成数据的随机插值点: x ^ = ϵ x + ( 1 − ϵ ) G ( z ) \hat{x} = \epsilon x + (1-\epsilon) G(z) x^=ϵx+(1−ϵ)G(z), ϵ ∼ U [ 0 , 1 ] \epsilon \sim U[0,1] ϵ∼U[0,1]
- λ \lambda λ 是惩罚系数(通常设为 10)
1.2 WGAN-GP 实现步骤
(1) 判别器(Critic)的损失函数
判别器的目标是最大化 Wasserstein 距离,同时满足梯度约束:
L D = E x ∼ P r [ D ( x ) ] − E z ∼ P z [ D ( G ( z ) ) ] ⏟ Wasserstein 距离 + λ ⋅ E x ^ ∼ P x ^ [ ( ∥ ∇ x ^ D ( x ^ ) ∥ 2 − 1 ) 2 ] ⏟ 梯度惩罚 L_D = \underbrace{\mathbb{E}_{x \sim P_r}[D(x)] - \mathbb{E}_{z \sim P_z}[D(G(z))]}_{\text{Wasserstein 距离}} + \underbrace{\lambda \cdot \mathbb{E}_{\hat{x} \sim P_{\hat{x}}} \left[ (\|\nabla_{\hat{x}} D(\hat{x})\|_2 - 1)^2 \right]}_{\text{梯度惩罚}} LD=Wasserstein 距离 Ex∼Pr[D(x)]−Ez∼Pz[D(G(z))]+梯度惩罚 λ⋅Ex^∼Px^[(∥∇x^D(x^)∥2−1)2]
(2) 生成器(Generator)的损失函数
生成器的目标是最小化 Wasserstein 距离: L G = − E z ∼ P z [ D ( G ( z ) ) ] L_G = -\mathbb{E}_{z \sim P_z}[D(G(z))] LG=−Ez∼Pz[D(G(z))]
(3) 训练流程
- 输入:真实数据 x x x,噪声 z ∼ N ( 0 , 1 ) z \sim \mathcal{N}(0,1) z∼N(0,1)
- 生成数据: G ( z ) G(z) G(z)
- 插值采样: x ^ = ϵ x + ( 1 − ϵ ) G ( z ) \hat{x} = \epsilon x + (1-\epsilon) G(z) x^=ϵx+(1−ϵ)G(z), ϵ ∼ U [ 0 , 1 ] \epsilon \sim U[0,1] ϵ∼U[0,1]
- 计算梯度惩罚:
- 对插值样本 x ^ \hat{x} x^ 计算判别器输出 D ( x ^ ) D(\hat{x}) D(x^)
- 求梯度 ∇ x ^ D ( x ^ ) \nabla_{\hat{x}} D(\hat{x}) ∇x^D(x^) 并计算惩罚项
- 更新判别器:最小化 L D L_D LD
- 更新生成器:最小化 L G L_G LG(每 n critic n_{\text{critic}} ncritic 次判别器更新后更新 1 次生成器)
1.3 总结
WGAN-GP 通过梯度惩罚替代权重裁剪,显著提升了 WGAN 的训练稳定性,是生成对抗网络的重要改进之一。实际应用中需注意:
- 判别器架构设计
- 梯度惩罚的正确实现
- 学习率和训练次数的调优
二、WGAN-GP 实现
2.1 导包
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets, transforms
from torchvision.utils import save_image
import numpy as npimport os
import time
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
from torchsummary import summary# 判断是否存在可用的GPU
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 指定存放日志路径
writer=SummaryWriter(log_dir="./runs/wgan_gp")os.makedirs("./img/wgan_gp_mnist", exist_ok=True) # 存放生成样本目录
os.makedirs("./model", exist_ok=True) # 模型存放目录
2.2 数据加载和处理
# 加载 MNIST 数据集
def load_data(batch_size=64,img_shape=(1,28,28)):transform = transforms.Compose([transforms.ToTensor(), # 将图像转换为张量transforms.Normalize(mean=[0.5], std=[0.5]) # 归一化到[-1,1]])# 下载训练集和测试集train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)# 创建 DataLoadertrain_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, num_workers=2,shuffle=True)test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, num_workers=2,shuffle=False)return train_loader, test_loader
2.3 构建生成器
class Generator(nn.Module):"""生成器"""def __init__(self, latent_dim=100,img_shape=(1,28,28)):super(Generator,self).__init__()# 网络块def block(in_feat, out_feat, normalize=True):layers = [nn.Linear(in_feat, out_feat)]if normalize:layers.append(nn.BatchNorm1d(out_feat))layers.append(nn.LeakyReLU(negative_slope=0.2, inplace=True))return layersself.model = nn.Sequential(*block(latent_dim, 128, normalize=False),*block(128, 256),*block(256, 512),*block(512, 1024),nn.Linear(1024, int(np.prod(img_shape))),nn.Tanh() # 输出归一化到[-1,1] )def forward(self,z): # 噪声z,2维[batch_size,latent_dim]gen_img=self.model(z) gen_img=gen_img.view(gen_img.shape[0],*img_shape)return gen_img # 4维[batch_size,1,H,W]
2.4 构建判别器
class Discriminator(nn.Module):"""判别器"""def __init__(self,img_shape=(1,28,28)):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(int(np.prod(img_shape)), 512),nn.LeakyReLU(negative_slope=0.2, inplace=True),nn.Linear(512, 256),nn.LeakyReLU(negative_slope=0.2, inplace=True),nn.Linear(256, 1))def forward(self,img): # 输入图片,4维[batc_size,1,H,W]img=img.view(img.shape[0], -1) pred = self.model(img)return pred # 2维[batch_size,1]
2.5 训练和保存模型
-
WGAN-GP 算法流程

-
定义梯度惩罚函数
def compute_gradient_penalty(critic, real, fake, device):batch_size = real.shape[0]epsilon = torch.rand(batch_size, 1, 1, 1).to(device) # 随机插值系数interpolates = (epsilon * real + (1 - epsilon) * fake).requires_grad_(True)critic_interpolates = critic(interpolates)# 计算梯度gradients = torch.autograd.grad(outputs=critic_interpolates,inputs=interpolates,grad_outputs=torch.ones_like(critic_interpolates),create_graph=True,retain_graph=True,)[0]gradients = gradients.view(gradients.shape[0], -1)gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()return gradient_penalty
- 训练和保存
# 设置超参数
batch_size = 64
epochs = 200
lr= 0.0002
latent_dim=100 # 生成器输入噪声向量的长度(维数)
sample_interval=400 #每400次迭代保存生成样本# WGAN的特别设置
num_iter_critic = 5
lambda_gp = 10# 设置图片形状1*28*28
img_shape = (1,28,28)# 加载数据
train_loader,_= load_data(batch_size=batch_size,img_shape=img_shape)# 实例化生成器G、判别器D
G=Generator().to(device)
D=Discriminator().to(device)# 设置优化器
optimizer_G = torch.optim.Adam(G.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D = torch.optim.Adam(D.parameters(), lr=lr, betas=(0.5, 0.999))# 开始训练
batches_done=0
loader_len=len(train_loader) #训练集加载器的长度
for epoch in range(epochs):# 进入训练模式G.train()D.train()loop = tqdm(train_loader, desc=f"第{epoch+1}轮")for i, (real_imgs, _) in enumerate(loop):real_imgs=real_imgs.to(device) # [B,C,H,W]# -----------------# 训练判别器# -----------------# 获取噪声样本[B,latent_dim)z=torch.normal(0,1,size=(real_imgs.shape[0],latent_dim),device=device) #从正态分布中抽样# Step-1 计算判断器损失=判断真实图片损失+判断生成图片损失+惩罚项fake_imgs=G(z).detach()gradient_penalty=compute_gradient_penalty(D, real_imgs, fake_imgs, device)dis_loss=-torch.mean(D(real_imgs)) + torch.mean(D(fake_imgs))+lambda_gp*gradient_penalty# Step-2 更新判别器参数optimizer_D.zero_grad() # 梯度清零dis_loss.backward() #反向传播,计算梯度optimizer_D.step() #更新判别器 # -----------------# 训练生成器# -----------------# 判别器每迭代 num_iter_critic 次,生成器迭代一次if i % num_iter_critic ==0 :gen_imgs=G(z).detach()# 更新生成器参数optimizer_G.zero_grad() #梯度清零gen_loss=-torch.mean(D(gen_imgs))gen_loss.backward() #反向传播,计算梯度optimizer_G.step() #更新生成器 # 更新进度条loop.set_postfix(gen_loss=f"{gen_loss:.8f}",dis_loss=f"{dis_loss:.8f}")# 每 sample_interval 次迭代保存生成样本if batches_done % sample_interval == 0:save_image(gen_imgs.data[:25], f"./img/wgan_gp_mnist/{epoch}_{i}.png", nrow=5, normalize=True)batches_done += 1print('总共训练用时: %.2f min' % ((time.time() - start_time)/60))#仅保存模型的参数(权重和偏置),灵活性高,可以在不同的模型结构之间加载参数
torch.save(G.state_dict(), "./model/WGAN-GP_G.pth")
torch.save(D.state_dict(), "./model/WGAN-GP_D.pth")
2.6 图片转GIF
from PIL import Imagedef create_gif(img_dir="./img/wgan_gp_mnist", output_file="./img/wgan_gp_mnist/wgan_gp_figure.gif", duration=100):images = []img_paths = [f for f in os.listdir(img_dir) if f.endswith(".png")]# 自定义排序:按 "x_y.png" 的 x 和 y 排序img_paths_sorted = sorted(img_paths,key=lambda x: (int(x.split('_')[0]), # 第一个数字(如 0_400.png 的 0)int(x.split('_')[1].split('.')[0]) # 第二个数字(如 0_400.png 的 400)))for img_file in img_paths_sorted:img = Image.open(os.path.join(img_dir, img_file))images.append(img)images[0].save(output_file, save_all=True, append_images=images[1:], duration=duration, loop=0)print(f"GIF已保存至 {output_file}")
create_gif()

相关文章:
WGAN-GP 原理及实现(pytorch版)
WGAN-GP 原理及实现 一、WGAN-GP 原理1.1 WGAN-GP 核心原理1.2 WGAN-GP 实现步骤1.3 总结 二、WGAN-GP 实现2.1 导包2.2 数据加载和处理2.3 构建生成器2.4 构建判别器2.5 训练和保存模型2.6 图片转GIF 一、WGAN-GP 原理 Wasserstein GAN with Gradient Penalty (WGAN-GP) 是对…...
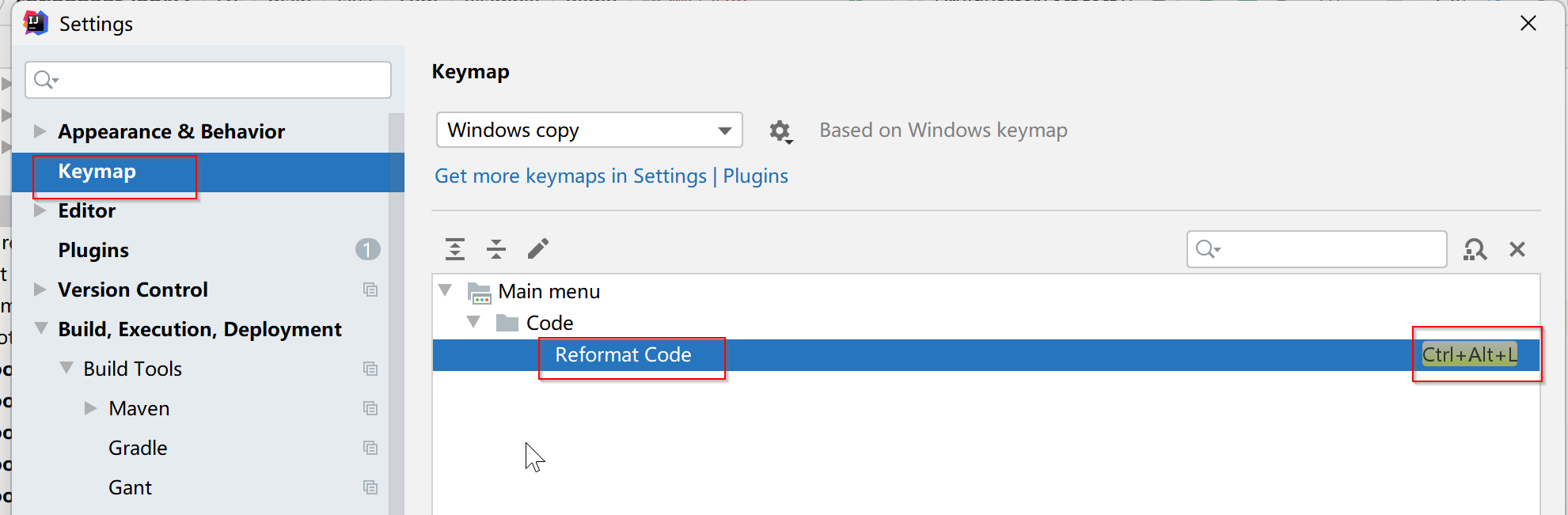
IntelliJ IDEA使用技巧(json字符串格式化)
文章目录 一、IDEA自动格式化json字符串二、配置/查找格式化快捷键 本文主要讲述idea中怎么将json字符串转换为JSON格式的内容并且有层级结构。 效果: 转换前: 转换后: 一、IDEA自动格式化json字符串 步骤一:首先创建一个临…...

synchronized锁升级详解
synchronized锁升级详解 synchronized是Java中实现线程同步的关键字,它在JVM内部实现了锁的升级机制,从偏向锁到轻量级锁再到重量级锁,这种优化是为了减少锁操作带来的性能开销。 1. 锁的四种状态 Java对象头中的Mark Word会记录锁的状态&…...

MCP基础学习一:MCP概述与基础
MCP概述与基础 什么是MCP? MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司于2024年11月推出的一种开放协议,旨在实现大型语言模型(LLM)与外部数据源和工具的无缝集成。MCP通过…...
SvelteKit 最新中文文档教程(18)—— 浅层路由和 Packaging
前言 Svelte,一个语法简洁、入门容易,面向未来的前端框架。 从 Svelte 诞生之初,就备受开发者的喜爱,根据统计,从 2019 年到 2024 年,连续 6 年一直是开发者最感兴趣的前端框架 No.1: Svelte …...
集成nacos2.2.1出现的错误汇总
总结 1.jdk问题 jdk要一致 2.idea使用问题 idea启动nacos要配置,idea启动类要启动两次,并配置两次vm参数 3.项目依赖问题 依赖要正确添加,有的模块就是不能用公共模块的pom配置,需要独立配置,先后启动顺序也要注意…...

DFS 蓝桥杯
最大数字 问题描述 给定一个正整数 NN 。你可以对 NN 的任意一位数字执行任意次以下 2 种操 作: 将该位数字加 1 。如果该位数字已经是 9 , 加 1 之后变成 0 。 将该位数字减 1 。如果该位数字已经是 0 , 减 1 之后变成 9 。 你现在总共可以执行 1 号操作不超过 A…...
LabVIEW 开发如何降本增效
在 LabVIEW 开发领域,如何在确保项目质量的同时降低开发成本,是众多企业和开发者共同关注的焦点。这不仅关乎资源的高效利用,更影响项目的投资回报率和市场竞争力。下面,我们将从多个维度深入剖析降本策略,并结合具体案…...

Tomcat 负载均衡
目录 二、Tomcat Web Server 2.1 Tomcat 部署 2.1.1 Tomcat 介绍 2.1.2 Tomcat 安装 2.2 Tomcat 服务管理 2.2.1 Tomcat 启停 2.2.2 目录说明 2.2.3编辑主页 2.3 Tomcat管理控制台 2.3.1开启远程管理 2.3.2 配置远程管理密码 三、负载均衡 3.1 重新编译Nginx 3.1.1 确…...
)
【AI学习】AI Agent(人工智能体)
1,AI agent 1)定义 是一种能够感知环境、基于所感知到的信息进行推理和决策,并通过执行相应动作来影响环境、进而实现特定目标的智能实体。 它整合了多种人工智能技术,具备自主学习、自主行动以及与外界交互的能力,旨…...

4月8日日记
今天抖音刷到一个视频 记了一下笔记 想做自媒体,直播,抖音是最大的平台,但是我的号之前因为跟人互喷被封号了 今天想把实名认证转移到新号上,试了一下竟然这次成功了,本以为能开直播了但是 还是因为之前的号有违规记…...
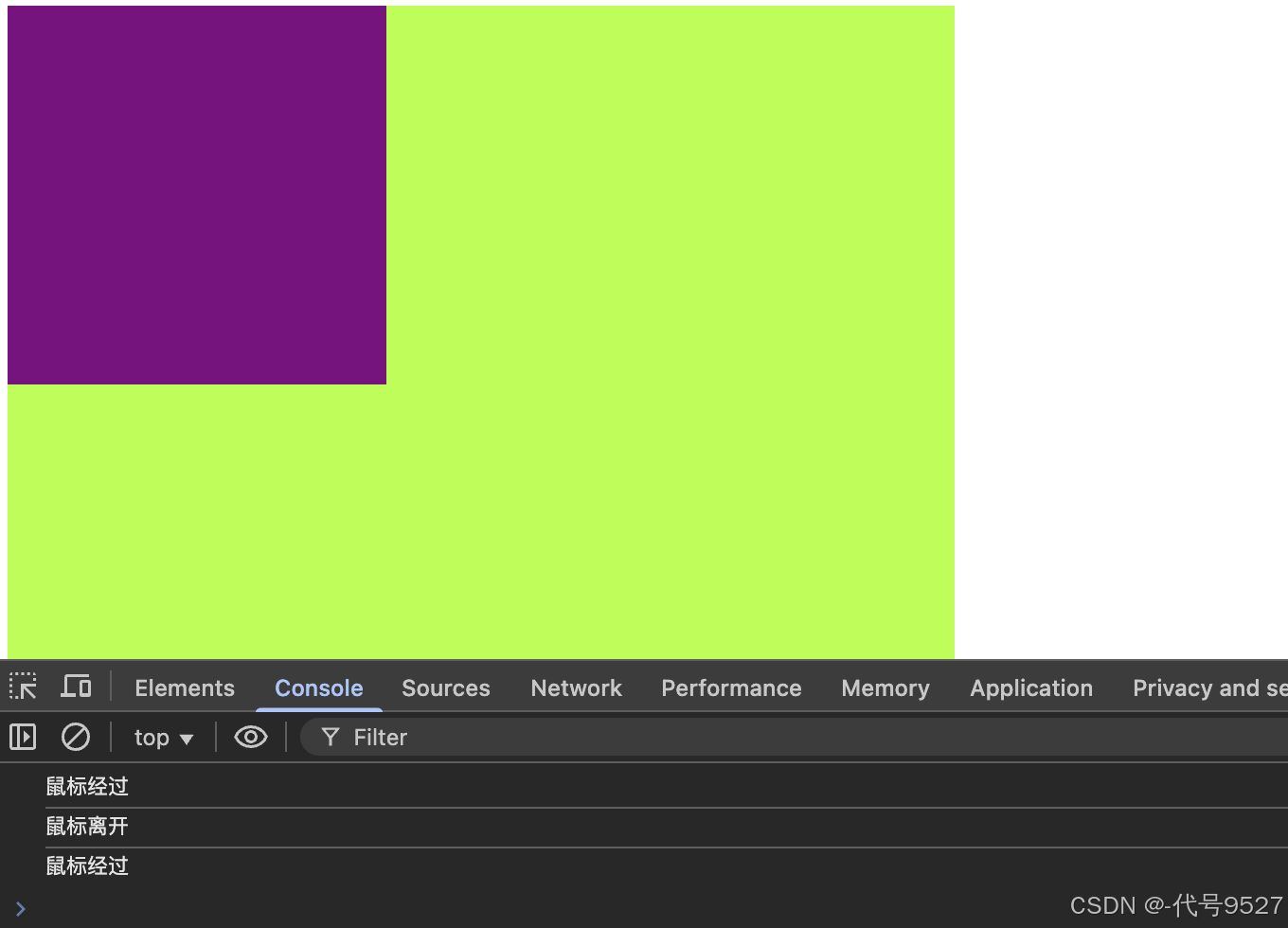
【JavaScript】十六、事件捕获和事件冒泡
文章目录 1、事件流2、事件捕获3、事件捕获4、阻止冒泡5、解绑事件6、鼠标经过事件的区别7、两种事件注册语法的区别 1、事件流 先举个形象的例子:你去西安大雁塔旅游 出发找目的地时:先从你家出发,到陕西省西安市,再到雁塔区&a…...

MyBatis的第四天学习笔记下
10.MyBatis参数处理 10.1 项目信息 模块名:mybatis-007-param数据库表:t_student表结构: id: 主键name: 姓名age: 年龄height: 身高sex: 性别birth: 出生日期 sql文件: create table t_student ( id bigint auto_increm…...
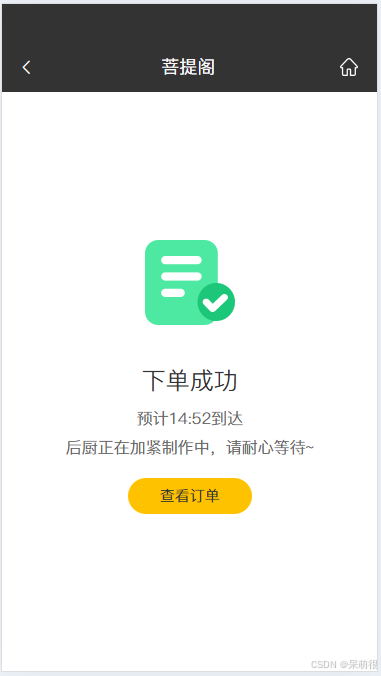
基于 Spring Boot 瑞吉外卖系统开发(一)
基于 Spring Boot 瑞吉外卖系统开发(一) 系统概述 系统功能 技术选型 初始项目和数据准备 初始项目和SQL文件下载 创建数据库并导入数据 打开reggie项目 运行效果 主函数启动项目,访问URL: http://127.0.0.1:8080/backend/pag…...
)
Baumer工业相机堡盟工业相机如何处理偶发十万分之一或百万分之一几率出现的黑图现象(C#)
Baumer工业相机堡盟工业相机如何处理偶发十万分之一或百万分之一几率出现的黑图现象(C#) Baumer工业相机Baumer工业相机出现黑图的技术背景硬件层面软件层面环境因素 实际案例演示:BaumerVCXG-53M.I.XT 防护相机项目使用环境项目反馈问题项目…...

【Python中读取并显示遥感影像】
在Python中读取并显示遥感影像,可以使用rasterio库读取影像数据,并结合matplotlib库进行可视化。以下是一个完整的示例代码: import rasterio import matplotlib.pyplot as plt# 打开遥感影像文件 with rasterio.open(path/to/your/image.ti…...
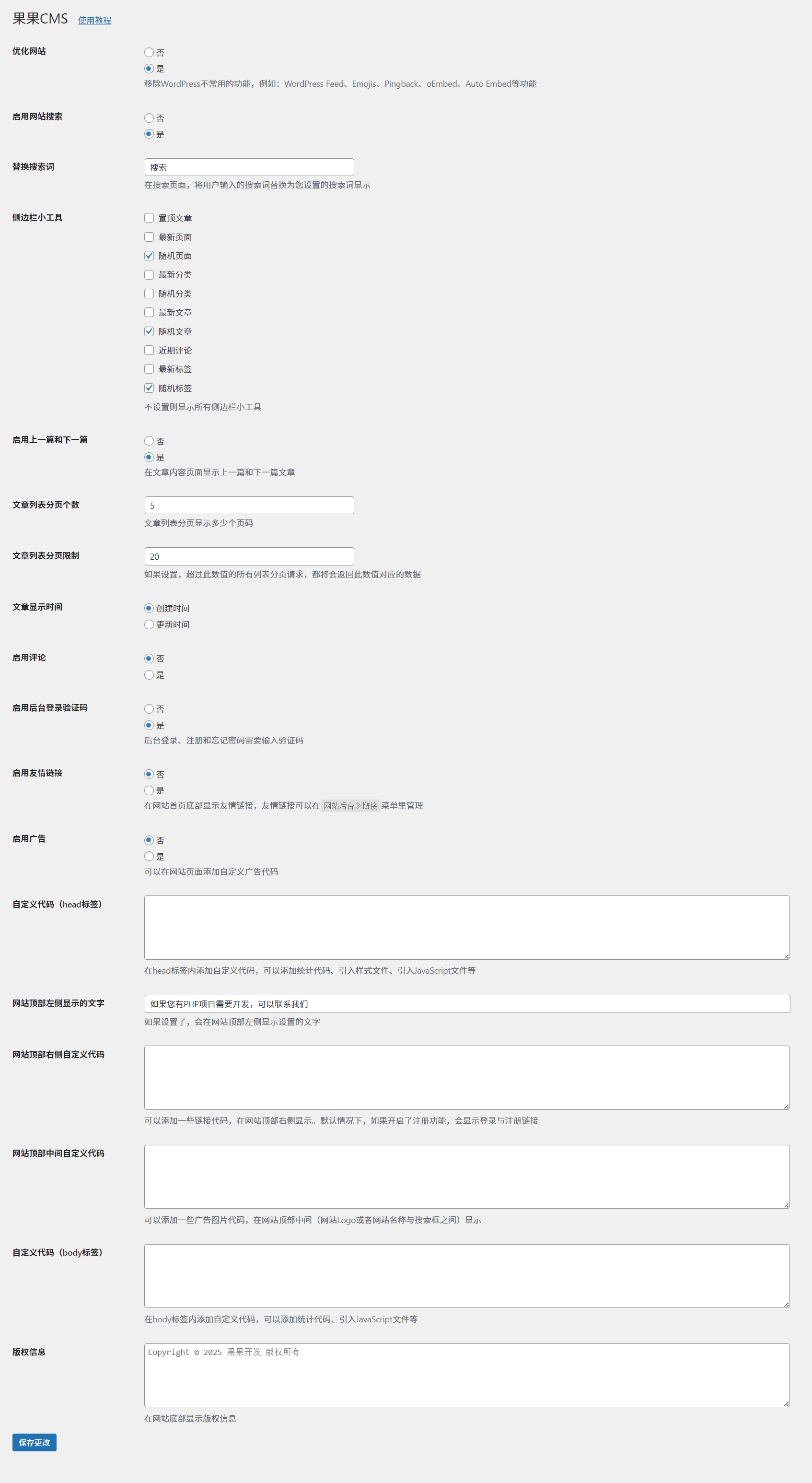
WordPress超简洁的主题:果果CMS主题
果果CMS是基于WordPress开发的超精简的一款主题,它在原有的特性上添加了许多新特性,例如:随机文章、随机标签、随机分类、广告、友情链接等。 新版特性: 小:主题安装包文件大小只有140.48KB。少:主题最小…...

leetcode13.罗马数字转整数
遍历,下一个值不大于当前值就加上当前值,否则就减去当前值 class Solution {public int romanToInt(String s) {Map<Character, Integer> map Map.of(I, 1,V, 5,X, 10,L, 50,C, 100,D, 500,M, 1000);int sum 0;for (int i 0; i < s.length(…...

CSS 学习提升网站或者项目
有几个不错的开源项目可以帮助你练习和提升CSS技能: CSS-Tricks CSS-Tricks 提供了很多关于CSS的技巧和教程,可以通过实践它们来提高CSS技能。你可以在CSS-Tricks上找到很多有趣的项目和代码示例。 Frontend Mentor Frontend Mentor 是一个非常适合练习…...
线程安全问题的原因与解决方案总结
目录 一 什么是线程安全? 二 线程安全问题的实例 三 线程安全问题的原因 1.多个线程修改共享数据 2.抢占式执行 3.修改操作不是原子的 4.内存可见性问题 5.指令重排序 四 解决方案 1.同步代码块 2.同步方法 3.加锁lock解决问题 一 什么是线程安全&…...

实时比分更新系统的搭建
搭建一个实时比分更新系统需要考虑多个技术环节,以下是一个完整的实现方案: 一、系统架构 1.数据获取层 比分数据API接入(如熊猫比分、API-Football等) 网络爬虫(作为备用数据源) 2.数据处理层 …...
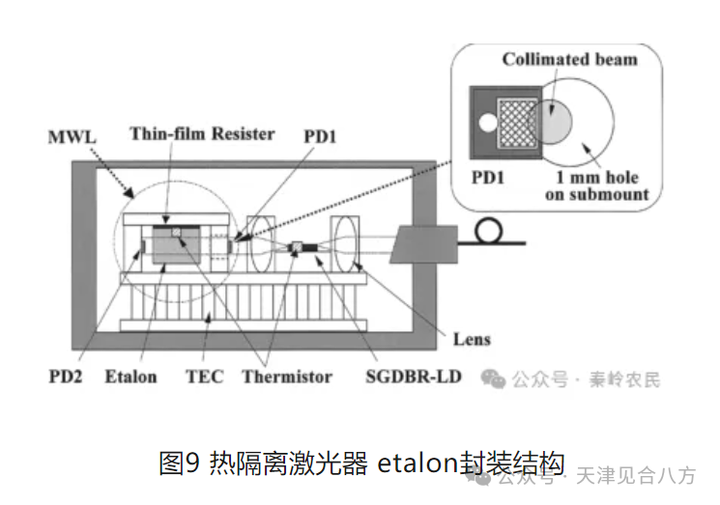
Tunable laser激光器的前向和后向锁波长方案
----转载自秦岭农民的文章 Tunable laser可调激光器的锁波长方案 激光器锁波长技术是指通过各种手段将激光器的输出波长稳定在某一特定值或范围内,以满足高精度应用的需求。这些技术包括Etalon、波长计/光谱仪反馈、波长参考源、温度控制、电流控制、锁相环&#…...

flink iceberg写数据到hdfs,hive同步读取
1、组件版本 名称版本hadoop3.4.1flink1.20.1hive4.0.1kafka3.9.0zookeeper3.9.3tez0.10.4spark(hadoop3)3.5.4jdk11.0.13maven3.9.9 环境变量配置 vim编辑保存后,要执行source /etc/profile LD_LIBRARY_PATH/usr/local/lib export LD_LIBR…...
蓝桥杯:日期统计
文章目录 问题描述解法一递归解法二:暴力破解 问题描述 首先我们要了解什么是子序列,就是一个序列之中可以忽略元素但是不能改变顺序之后获得的序列就叫做子序列。 如"123"就是"11234"的子序列而不是"11324"的子序列 解法…...
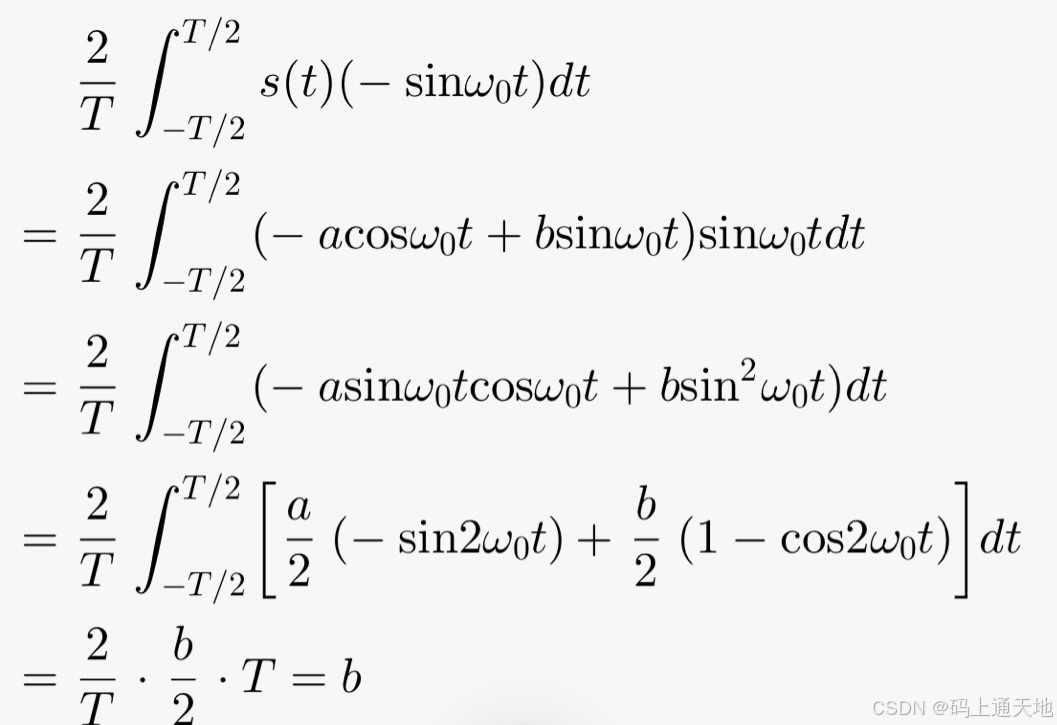
IQ解调原理#通信原理系列
IQ解调原理:接收端收到s(t)信号后,分为两路: 一路信号乘以cosω₀t再积分,就可以得到a: 另一路乘以 -sinω₀t再积分,就可以得到b:...

C++蓝桥杯实训篇(三)
片头 嗨!小伙伴们,大家好~ 今天我们来学习前缀和与差分相关知识,准备好了吗?咱们开始咯! 一、一维前缀和 以上,是我们用数学知识求解区间和,现在我们使用前缀和来求解: 我们知道&am…...
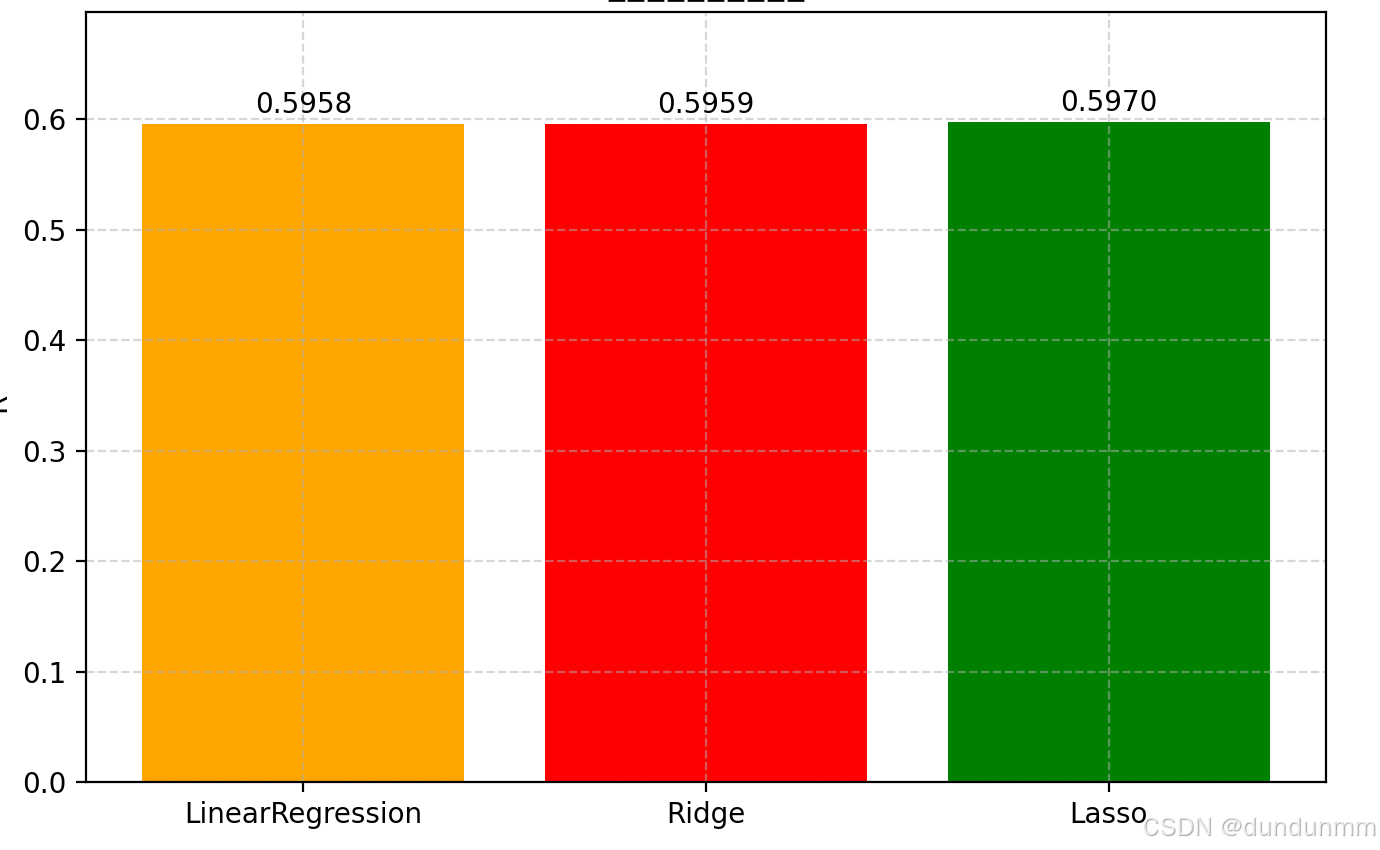
【数据挖掘】岭回归(Ridge Regression)和线性回归(Linear Regression)对比实验
这是一个非常实用的 岭回归(Ridge Regression)和线性回归(Linear Regression)对比实验,使用了 scikit-learn 中的 California Housing 数据集 来预测房价。 📦 第一步:导入必要的库 import num…...

前言:为什么要学习爬虫和逆向,该如何学习?
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、为什么要学习爬虫与逆向?1.1 核心价值1.2 爬虫和应用场景对比1.3 逆向工程的应用场景二、爬虫技术学习路径2.1 基础阶段:包括原理、采集、解析和入库整套流程2.2 中级阶段:反爬对抗2.3 高级阶段:高效爬虫三、逆…...

CExercise_07_1指针和数组_1编写函数交换数组中两个下标的元素
题目: 要求编写函数将数组作为参数传递来实现: 1.编写函数交换数组中两个下标的元素。函数声明如下:void swap(int *arr, int i, int j) 。要求不使用[]运算符,将[]还原成解引用运算符和指针加法来完成。 关键点 通过指针交换数组…...

塔能科技:智能路灯物联运维产业发展现状与趋势分析
随着智慧城市建设的推进,智能路灯物联运维产业正经历快速发展,市场规模持续扩大。文章探讨了智能路灯物联运维的技术体系、市场机遇和挑战,并预测了未来发展趋势,为行业发展提供参考。 关键词 智能路灯;物联运维&#…...