11. Langchain输出解析(Output Parsers):从自由文本到结构化数据
引言:从"自由发挥"到"规整输出"
2025年某金融机构的合同分析系统升级前,AI生成的合同摘要需人工二次处理达47分钟/份。引入LangChain结构化解析后,处理时间缩短至3分钟。本文将详解如何用LangChain的解析器,将大模型的自由文本输出转化为精准数据结构。

一、输出解析的核心价值
1.1 典型应用场景对比
| 场景 | 未解析输出 | 解析后输出 |
|---|---|---|
| 合同分析 | "甲方应在15个工作日内付款" | {"party":"甲方", "deadline":15, "unit":"工作日"} |
| 商品评论 | "这款手机拍照很棒但电池一般" | {"优点":"拍照", "缺点":"电池", "评分":4} |
| 医疗记录 | "患者主诉头痛3天,体温38.2℃" | {"症状":["头痛"], "持续时间":"3天", "体温":38.2} |
1.2 LangChain解析器类型
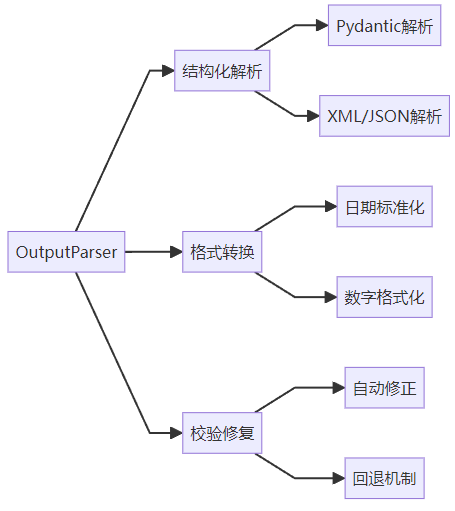
二、四大核心解析模式实战
2.1 Pydantic结构化解析(推荐方案)
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.exceptions import OutputParserException
from langchain_ollama import ChatOllama
from pydantic import BaseModel, Field, conint, field_validator
from typing import List, Optional
import re
from datetime import datetime
# 增强版数据模型
class ContractClause(BaseModel):party: str = Field(...,description="合同签约方,必须是'甲方'或'乙方'",examples=["甲方", "乙方"])obligation: str = Field(...,description="责任条款主要内容,需用动宾结构短语",min_length=3)deadline: Optional[conint(ge=0)] = Field(None,description="时限天数(自然日),自动转换'工作日'为自然日×1.5")effective_date: Optional[str] = Field(None,description="生效日期,格式YYYY-MM-DD")
# 自定义验证逻辑@field_validator('party')def validate_party(cls, v):if v not in {"甲方", "乙方"}:raise ValueError("合同方必须是甲方或乙方")return v
@field_validator('effective_date')def validate_date_format(cls, v):if v:try:datetime.strptime(v, "%Y-%m-%d")except ValueError:raise ValueError("日期格式错误,应为YYYY-MM-DD")return v
class ContractClauses(BaseModel):clauses: List[ContractClause] = Field(...,description="识别出的合同条款列表",min_items=1)
# 解析器
class SmartParser(PydanticOutputParser):def parse(self, text: str) -> ContractClauses:try:# 预处理模型输出cleaned_text = re.sub(r"(\b(?:个|天|日|工作|自然)\b|[\u4e00-\u9fff]+的?)",lambda m: {"个": "", "工作日": "*1.5", "自然日": ""}.get(m.group(), ""),text)return super().parse(cleaned_text)except Exception as e:raise OutputParserException(f"解析失败:{str(e)},原始输出:{text}")
parser = SmartParser(pydantic_object=ContractClauses)
# 增强提示模板
PROMPT_TEMPLATE = """
你是一个专业合同条款分析助手,请从文本中提取结构化信息,遵循以下规则:
1. 时间转换规则:- "工作日"按1.5倍转为自然日(如"3个工作日"→4.5天)- 年月转换:"1个月"=30天,"1年"=365天
2. 条款解析要求:- 将复合条款拆分为独立子条款- 识别隐含时间(如"立即"=0天,"尽快"=3天)- 日期格式化为YYYY-MM-DD
3. 输出必须严格使用JSON格式,示例:
{format_instructions}
待解析文本:
{text}
"""
prompt = PromptTemplate(template=PROMPT_TEMPLATE,input_variables=["text"],partial_variables={"format_instructions": parser.get_format_instructions()}
)
# 构建处理链
chain = (prompt| ChatOllama(model="deepseek-r1", temperature=0.3)| parser
).with_config(run_name="ContractParser")
# 执行解析
def analyze_contract(text: str) -> ContractClauses:try:result = chain.invoke({"text": text})# 后处理:四舍五入小数for clause in result.clauses:if clause.deadline is not None:clause.deadline = round(clause.deadline)return resultexcept OutputParserException as e:print(f"解析错误:{e}")return ContractClauses(clauses=[])
# 示例使用
result = analyze_contract("""
根据协议:
1. 甲方需在合同生效后3个工作日内交付设备
2. 乙方应于收到设备48小时内完成验收
3. 双方在2023-12-31前保持保密义务
""")
# 输出结构化结果
print(result.model_dump_json(indent=2))输出为:
{"clauses": [{"party": "甲方","obligation": "交付设备","deadline": 5,"effective_date": null},{"party": "乙方","obligation": "完成验收","deadline": 2,"effective_date": null},{"party": "甲方","obligation": "保持保密义务","deadline": null,"effective_date": "2023-12-31"},{"party": "乙方","obligation": "保持保密义务","deadline": null,"effective_date": "2023-12-31"}]
}2.2 JSON模式强制转换
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field
from langchain_ollama import ChatOllama
# 首先定义一个期望的JSON结构schema
class PersonInfo(BaseModel):name: str = Field(description="人物的全名")age: int = Field(description="人物的年龄")hobbies: list[str] = Field(description="人物的爱好列表")address: dict = Field(description="包含街道、城市和邮编的地址信息")
# 创建输出解析器,基于我们定义的schema
parser = JsonOutputParser(pydantic_object=PersonInfo)
# 创建提示模板
template = """将以下文本转为JSON格式,使用以下schema:
{schema}
文本:{input}"""
prompt = PromptTemplate(template=template,input_variables=["input"],partial_variables={"schema": parser.get_format_instructions() # 从解析器获取格式说明}
)
# 初始化Ollama聊天模型
chat_model = ChatOllama(model="deepseek-r1")
# 创建处理链
chain = prompt | chat_model | parser
# 测试运行
input_text = """
张三,30岁,住在北京市海淀区中关村大街1号,邮编100080。
他喜欢编程、阅读和徒步旅行。
"""
try:result = chain.invoke({"input": input_text})print("解析结果:")print(result)
except Exception as e:print(f"发生错误: {e}")输出为:
解析结果:
{'name': '张三', 'age': 30, 'hobbies': ['编程', '阅读', '徒步旅行'], 'address': {'street': '中关村大街1号', 'city': '北京市', 'zipcode': 100080}}2.3 自动修正与回退
from langchain.output_parsers import RetryWithErrorOutputParser
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_ollama import ChatOllama
from pydantic import BaseModel, Field
# 1. 定义期望的JSON结构schema
class PersonInfo(BaseModel):name: str = Field(description="人物的全名")age: int = Field(description="人物的年龄")hobbies: list[str] = Field(description="人物的爱好列表")address: dict = Field(description="包含街道、城市和邮编的地址信息")
# 2. 创建基础解析器和聊天模型
parser = JsonOutputParser(pydantic_object=PersonInfo)
chat_model = ChatOllama(model="deepseek-r1") # 主模型
retry_llm = ChatOllama(model="deepseek-r1") # 用于修复的模型
# 3. 创建提示模板
template = """严格根据提供的文本提取信息转为JSON,不添加任何额外信息。
如果文本中缺少必要字段,请保留为空。
使用以下schema:
{schema}
文本:{input}"""
prompt = PromptTemplate(template=template,input_variables=["input"],partial_variables={"schema": parser.get_format_instructions()}
)
# 4. 创建重试解析器
retry_parser = RetryWithErrorOutputParser.from_llm(parser=parser,llm=retry_llm
)
# 5. 测试用例
def process_input(input_text):try:# 先尝试直接解析print("尝试直接解析...")result = parser.parse(input_text)print("直接解析成功:")return resultexcept Exception as e:print(f"直接解析失败: {e}\n尝试修复解析...")try:# 使用重试解析器修复full_prompt = prompt.format_prompt(input=input_text)fixed_result = retry_parser.parse_with_prompt(input_text, full_prompt)print("修复后解析成功:")return fixed_resultexcept Exception as e:print(f"修复解析失败: {e}")return None
# 测试1: 规范文本
good_input = """
李四,25岁,住在上海市浦东新区张江高科技园区,邮编201203。
爱好包括打篮球、听音乐和旅游。
"""
print("\n测试规范文本:")
print(process_input(good_input))
# 测试2: 不规范文本(缺少必要字段)
bad_input = """
王五喜欢游泳和画画,住在广州市天河区。
"""
print("\n测试不规范文本:")
print(process_input(bad_input))
# 测试3: 完全不匹配的文本
wrong_input = """
今天天气真好,我去了公园散步。
"""
print("\n测试完全不匹配文本:")
print(process_input(wrong_input))输出为:
测试规范文本:
尝试直接解析...
直接解析失败: Invalid json output: 李四,25岁,住在上海市浦东新区张江高科技园区,邮编201203。
爱好包括打篮球、听音乐和旅游。
For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/OUTPUT_PARSING_FAILURE
尝试修复解析...
修复后解析成功:
{'name': '李四', 'age': 25, 'hobbies': ['打篮球', '听音乐', '旅游'], 'address': {'street': '上海市浦东新区张江高科技园区', 'city': '上海', 'zip_code': '201203'}}
测试不规范文本:
尝试直接解析...
直接解析失败: Invalid json output: 王五喜欢游泳和画画,住在广州市天河区。
For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/OUTPUT_PARSING_FAILURE
尝试修复解析...
修复后解析成功:
{'name': '王五', 'age': None, 'hobbies': ['游泳', '画画'], 'address': {'street': '天河区', 'city': '广州市', 'zip_code': None}}
测试完全不匹配文本:
尝试直接解析...
直接解析失败: Invalid json output: 今天天气真好,我去了公园散步。
For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/OUTPUT_PARSING_FAILURE
尝试修复解析...
修复后解析成功:
{'name': '', 'age': None, 'hobbies': [], 'address': {'street': None, 'city': None, 'zipCode': None}}2.4 流式输出处理
import asyncio
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_ollama import ChatOllama
from pydantic import BaseModel, Field
# 1. 定义期望的JSON结构schema
class ProductFeatures(BaseModel):name: str = Field(description="产品名称")features: list[str] = Field(description="产品特征列表")price_range: str = Field(description="价格范围")target_audience: str = Field(description="目标用户群体")
# 2. 创建流式JSON解析器
parser = JsonOutputParser(pydantic_object=ProductFeatures)
# 3. 创建提示模板
template = """根据以下要求生成产品信息,输出必须是严格的JSON格式:
{schema}
要求:{input}"""
prompt = PromptTemplate(template=template,input_variables=["input"],partial_variables={"schema": parser.get_format_instructions()}
)
# 4. 初始化模型和链
model = ChatOllama(model="deepseek-r1", temperature=0.7)
chain = prompt | model | parser
# 5. 异步流式处理函数
async def stream_products():print("开始流式生成产品信息...")async for chunk in chain.astream({"input": "生成3个高端智能手机的产品特征"}):print("收到流式数据块:", chunk)# 这里可以添加实时处理逻辑,如更新UI或存储部分结果
# 6. 运行异步流
async def main():await stream_products()
if __name__ == "__main__":asyncio.run(main())输出为:
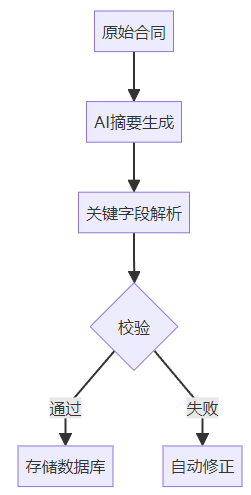
收到流式数据块: {'products': [{'name': '旗舰至尊', 'features': ['5G网络支持', '6.8英寸AMOLED超视网膜XDR显示屏', 'A17 Pro芯片,性能强劲', '4800万像素三摄像头系统', 'IP68防水防尘等级', '69分钟快速充满电池'], 'price_range': '5000元以上', 'target_audience': '追求高品质和高性能的消费者'}, {'name': '奢华典范', 'features': ['陶瓷机身设计', '动态岛交互系统', 'ProMotion技术,120Hz刷新率', '超广角、广角和长焦三摄组合', '空间音频支持', 'MagSafe无线充电'], 'price_range': '5000元以上', 'target_audience': '注重外观设计和用户体验的高端用户'}, {'name': '未来视界', 'features': ['超视网膜XDR显示屏,2K分辨率', 'A17 Pro芯片,能效比极高', 'ProRAW格式拍摄支持', 'LiDAR扫描仪辅助对焦和深度感知', '长达23小时视频播放时间', 'IP68防水防尘等级'], 'price_range': '5000元以上', 'target_audience': '追求创新技术和卓越性能的用户'}]}三、企业级案例:金融合同解析系统
3.1 架构设计
3.2 性能指标
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 处理速度 | 47分钟/份 | 3分钟/份 |
| 字段准确率 | 68% | 93% |
| 人工干预率 | 100% | 15% |
四、避坑指南:解析系统六大陷阱
-
模式漂移:模型输出偏离预定格式
# 解决方案:严格schema校验 class StrictModel(BaseModel):__strict__ = True # 启用严格模式 -
文化差异:日期/数字格式国际化问题
-
嵌套陷阱:多层JSON解析失败
-
类型混淆:字符串误判为数字
-
流式中断:部分解析导致流程终止
-
错误渗透:未处理解析异常
下期预告
《评估与调试:用LangSmith优化模型表现》
-
揭秘:如何量化大模型的真实业务价值?
-
实战:基于A/B测试的提示词优化
-
陷阱:评估指标与业务目标的错配
优秀的输出解析系统,是AI从"玩具"变为"生产工具"的关键一跃。记住:精准的解析设计,决定了数据管道的可靠性上限!
相关文章:
11. Langchain输出解析(Output Parsers):从自由文本到结构化数据
引言:从"自由发挥"到"规整输出" 2025年某金融机构的合同分析系统升级前,AI生成的合同摘要需人工二次处理达47分钟/份。引入LangChain结构化解析后,处理时间缩短至3分钟。本文将详解如何用LangChain的解析器,…...

docker stack常用命令
1、Docker Stack介绍 Docker Stack管理swarm堆栈与Swarm协调器配合使用,是Docker Swarm环境中用于管理一组相关服务的工具。它使得在Swarm集群中部署、管理和扩展一组相互关联的服务变得简单。主要用于定义和编排容器化应用的多个服务。以下是Docker Stack的一些关…...

python reportlab模块----操作PDF文件
reportlab模块----操作PDF文件 一. 安装模块二. reportlab相关介绍三. 扩展canvas类四. 水平写入完整代码五. 垂直写入完整代码 一. 安装模块 pip install reportlab二. reportlab相关介绍 # 1. letter 生成A4纸张尺寸 from reportlab.lib.pagesizes import letter print(let…...
解锁基因密码之重测序(从测序到分析)
在生命科学的奇妙世界中,基因恰似一本记录着生命奥秘的“天书”,它承载着生物体生长、发育、衰老乃至疾病等一切生命现象的关键信息。而重测序技术,则是开启基因“天书”奥秘的一把神奇钥匙。 试想,你手中有一本经典书籍的通用版…...
TQTT_KU5P开发板教程---QSFP25G光口回环测试
文档实现功能介绍 本文档通过一个叫做ibert的IP,实现25G光口回环测试例子。工程新建方法请参考文档《流水灯》,其中只是将文件名进行修改。 Vivado 起始页(或 file-->Project-->New 创建新工程(Create New Project) 向导起始页面 点…...

JVM虚拟机篇(七):JVM垃圾回收器全面解析与G1深度探秘及四种引用详解
JVM垃圾回收器全面解析与G1深度探秘及四种引用详解 JVM虚拟机(七):JVM垃圾回收器全面解析与G1深度探秘及四种引用详解一、JVM有哪些垃圾回收器1. Serial回收器2. ParNew回收器3. Parallel Scavenge回收器4. Serial Old回收器5. Parallel Old回…...

柑橘病虫害图像分类数据集OrangeFruitDaatset-8600
文章目录 1. 前言2. 数据类别介绍3. 数据集地址 1. 前言 柑橘,作为水果界的 “宠儿”,不仅以其酸甜可口的味道深受大众喜爱,更是在全球水果产业中占据着举足轻重的地位。无论是早餐中的一杯橙汁,还是下午茶里的柑橘甜点ÿ…...

深度学习总结(4)
张量积 张量积(tensor product)或点积(dot product)是最常见且最有用的张量运算之一。注意,不要将其与逐元素乘积(*运算符)弄混。在NumPy中,使用np.dot函数来实现张量积,…...
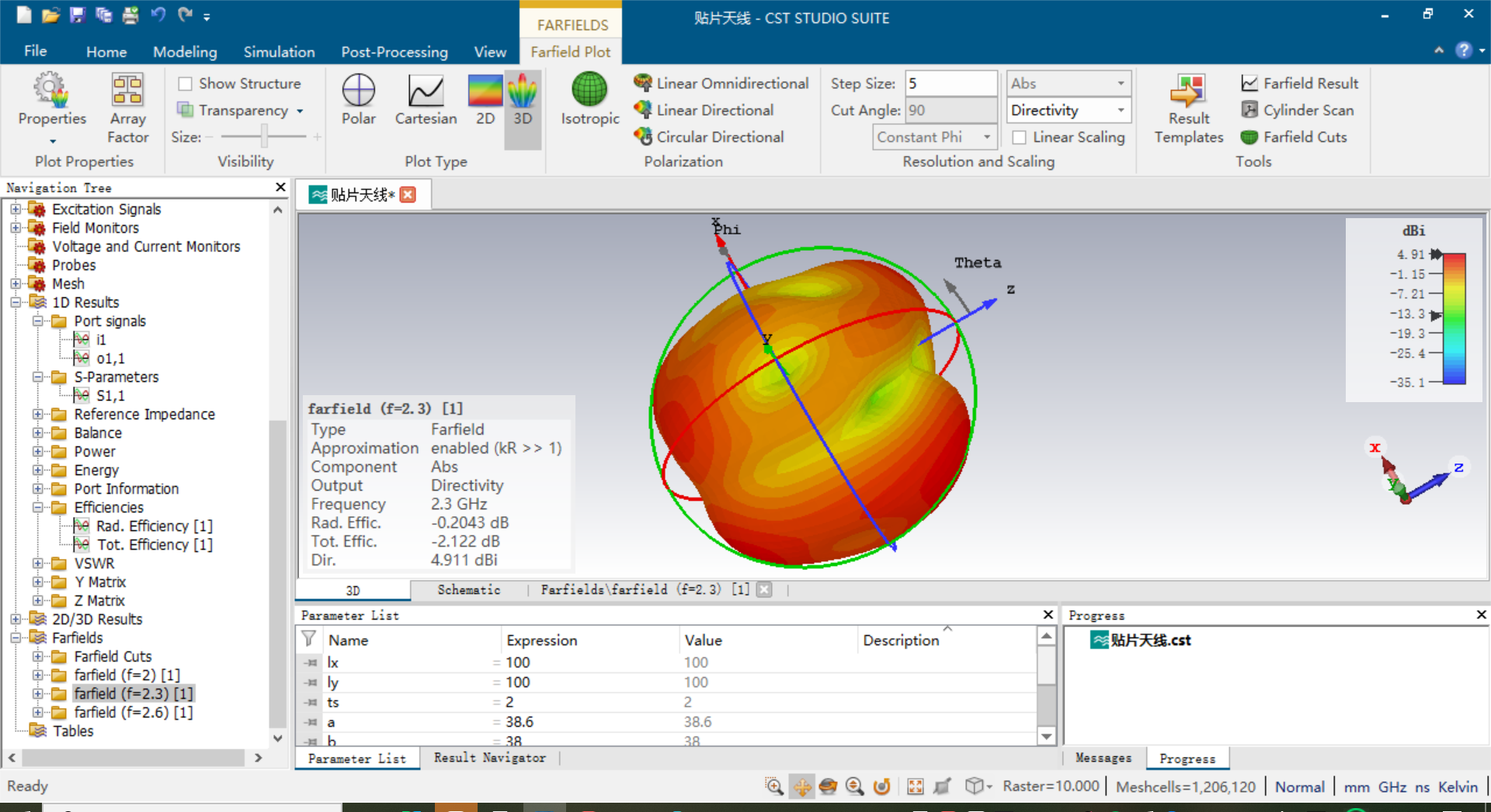
利用CST Microwave Studio设计贴片天线
利用CST Microwave Studio设计贴片天线的步骤如下,分为几个关键阶段: --- ### **1. 初始设置** - **新建项目**:打开CST,创建新项目(File > New),选择“Antenna (Planar)”或“Microwave &…...

STM32之SG90舵机控制(附视频讲解)
目录 前言: 一、硬件准备与接线 1.1 硬件清单 1.2 接线 二、 SG90舵机简介 1.1 外观 1.2 基本参数 1.3 引脚说明 1.4 控制原理 1.5 特点 1.6 常见问题 三、 单片机简介 四、 程序设计 4.1 定时器配置 4.2 角度控制函数 4.3 主函数调用 五、 总结 …...
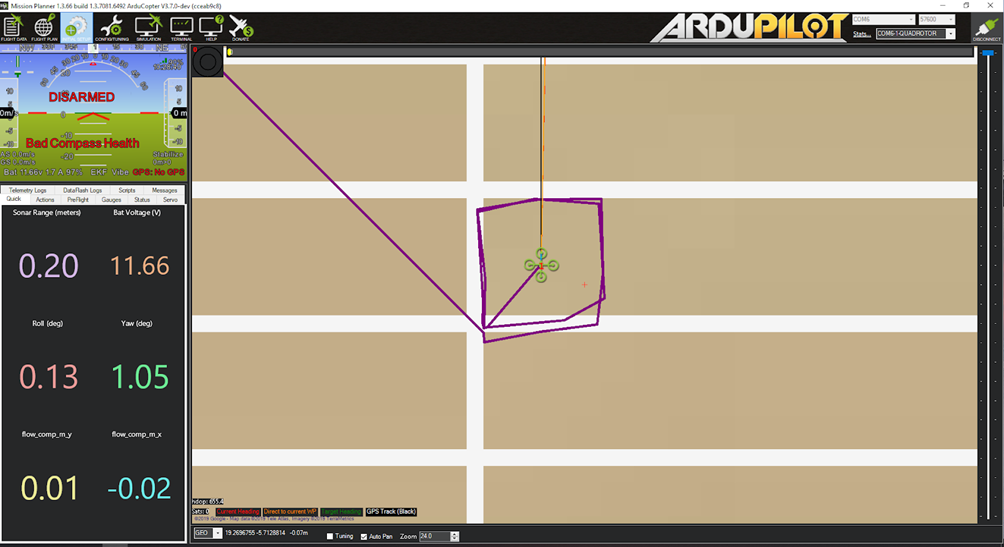
(1)英特尔 RealSense T265(三)
文章目录 前言 4.4 地面测试 4.5 飞行测试 4.6 室内外实验 4.7 数据闪存记录 4.8 启动时自动运行 4.9 使用 OpticalFlow 进行 EKF3 光源转换 前言 Realsense T265 通过 librealsense 支持 Windows 和 Linux 系统。不同系统的安装过程差异很大,因此请参阅 gi…...

Spring入门概念 以及入门案例
Spring入门案例 Springspring是什么spring的狭义与广义spring的两个核心模块IoCAOP Spring framework特点spring入门案例不用new方法,如何使用返回创建的对象 容器:IoC控制反转依赖注入 Spring spring是什么 spring是一款主流的Java EE轻量级开源框架 …...

xwiki的中文国际化
https://www.xwiki.org/xwiki/bin/view/Documentation/DevGuide/Tutorials/InternationalizingApplications/ 首先启用中文支持(参考此网页) 到Wiki的管理界面,进入Localization,在Supported Languages和Default Language里填zh&…...

多模态大语言模型arxiv论文略读(七)
MLLM-DataEngine: An Iterative Refinement Approach for MLLM ➡️ 论文标题:MLLM-DataEngine: An Iterative Refinement Approach for MLLM ➡️ 论文作者:Zhiyuan Zhao, Linke Ouyang, Bin Wang, Siyuan Huang, Pan Zhang, Xiaoyi Dong, Jiaqi Wang,…...
】——生产者消费者同步互斥模型)
【操作系统(Linux)】——生产者消费者同步互斥模型
✅ 一、程序功能概述 我们将做的:实现一个经典的「生产者-消费者问题」多线程同步模型的案例,主要用到 循环缓冲区 POSIX 信号量 sem_t pthread 多线程库,非常适合理解并发控制、线程通信和缓冲区管理。 案例目标:通过多个生产…...

SQL ③-基本语法
SQL基本语法 表操作 创建表 CREATE TABLE table_name (column1 datatype constraint,column2 datatype constraint,column3 datatype constraint,... );删除表 DROP [TEMPORARY] TABLE [IF EXISTS] table_name [, table_name...];TEMPORARY:表示临时表ÿ…...

【Pandas】pandas DataFrame bool
Pandas2.2 DataFrame Conversion 方法描述DataFrame.astype(dtype[, copy, errors])用于将 DataFrame 中的数据转换为指定的数据类型DataFrame.convert_dtypes([infer_objects, …])用于将 DataFrame 中的数据类型转换为更合适的类型DataFrame.infer_objects([copy])用于尝试…...
试卷及答案)
2025年3月全国青少年软件编程等级考试(Python五级)试卷及答案
2025.03电子学会 全国青少年软件编程等级考试(Python五级)试卷 一、单选题 1.以下哪个选项不是Python中的推导式?( ) A.列表推导式 B.字典推导式 C.集合推导式 D.元组推导式 2.以下Python代码的返回结果是?( ) [x**2 for…...

esp32cam -> 服务器 | 手机 -> 服务器 直接服务器传输图片
服务器先下载python : 一、Python环境搭建(CentOS/Ubuntu通用) 一条一条执行 安装基础依赖 # CentOS sudo yum install gcc openssl-devel bzip2-devel libffi-devel zlib-devel # Ubuntu sudo apt update && sudo apt install b…...

豆浆机语音提示芯片方案:基于可远程在线更换语音的WT2003H-16S芯片
随着智能家居概念的普及,消费者对家电产品的智能化、便捷性提出了更高要求。豆浆机作为厨房常用电器,其操作便捷性和用户体验直接影响市场竞争力。传统豆浆机多依赖指示灯或简单蜂鸣器提示用户操作状态,信息传递单一且无法满足个性化需求。 在…...

解密工业控制柜:认识关键硬件(PLC)
前言 作为一名视觉开发工程师,我们不仅要做到做好自己的工作,我们更需要在工业现场学习更多知识,最近网上流传很多,“教会徒弟,饿死师傅”;在自动化行业中,在项目下来很忙的时候,我们…...

【嵌入式系统设计师】知识点:第11 章 嵌入式系统设计案例分析
提示:“软考通关秘籍” 专栏围绕软考展开,全面涵盖了如嵌入式系统设计师、数据库系统工程师、信息系统管理工程师等多个软考方向的知识点。从计算机体系结构、存储系统等基础知识,到程序语言概述、算法、数据库技术(包括关系数据库、非关系型数据库、SQL 语言、数据仓库等)…...

记录一次SSH和SFTP服务分离后文件上传权限问题
开门见山 因服务器安全需求,需要将ssh和sftp服务分离,并创建一个用户组sftpuser::sftp,根目录权限均正常。用户sftpuser仅能通过sftp访问服务器,不能通过ssh访问服务器。但是,ssh应用用户appuser::sftp通过sftp建立链…...
【深度解析】SkyWalking 10.2.0版本安全优化与性能提升实战指南
前言 Apache SkyWalking 作为云原生可观测性领域的佼佼者,在微服务架构监控中扮演着至关重要的角色。然而,官方版本在安全性、镜像体积和功能扩展方面仍有优化空间。本文将分享一套完整的 SkyWalking 10.2.0 版本优化方案,从安全漏洞修复到镜…...
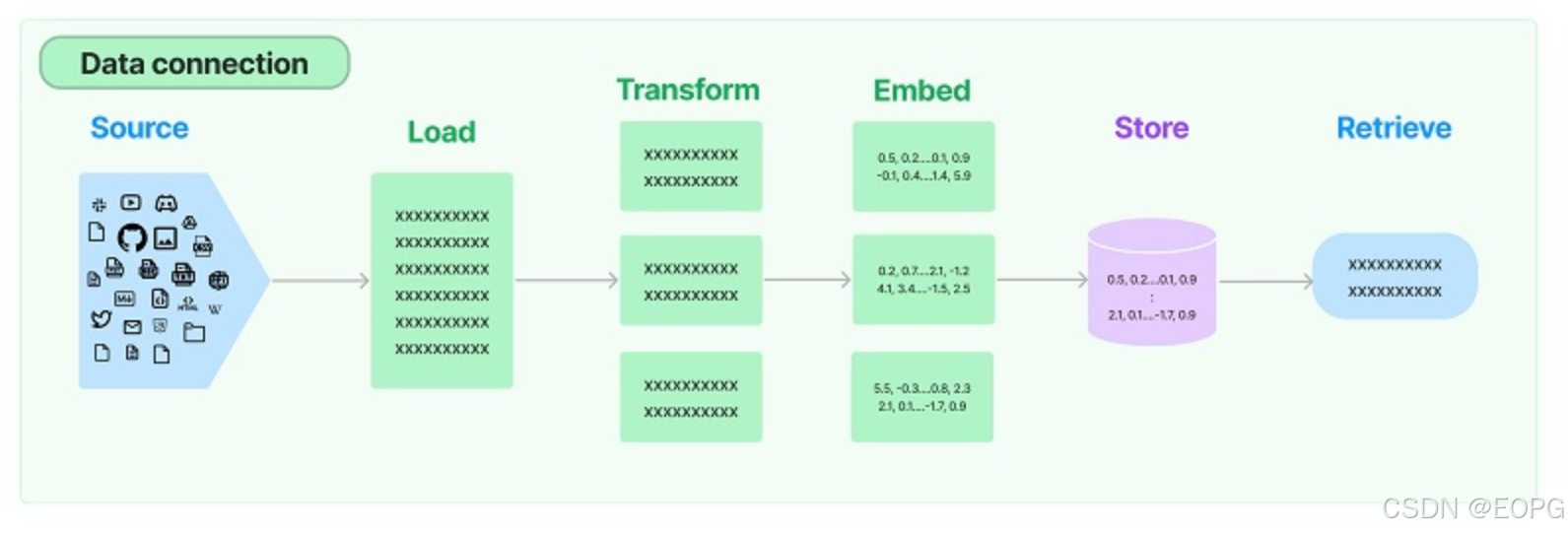
面向大模型的开发框架LangChain
这篇文章会带给你 如何使用 LangChain:一套在大模型能力上封装的工具框架如何用几行代码实现一个复杂的 AI 应用面向大模型的流程开发的过程抽象 文章目录 这篇文章会带给你写在前面LangChain 的核心组件文档(以 Python 版为例)模型 I/O 封装…...

pip install pytrec_eval失败的解决方案
1、问题描述 在使用华为云 notebook 的时候,想要: !pip install transformer结果失败,阅读报错后,疑似是 pytrec_eval 库的下载问题。 于是,单独尝试: !pip install pytrec_eval发现确实是这个库安装失…...

Easysearch VS Opensearch 数据写入与存储性能对比
本文记录 Easysearch 和 Opensearch 数据写入和数据存储方面的性能对比。 准备 压测工具:INFINI Loadgen 对比版本: Easysearch 1.11.1(lucene 8.11.4)Opensearch 2.19.1(lucene 9.12.1) 节点 JVM 配置…...
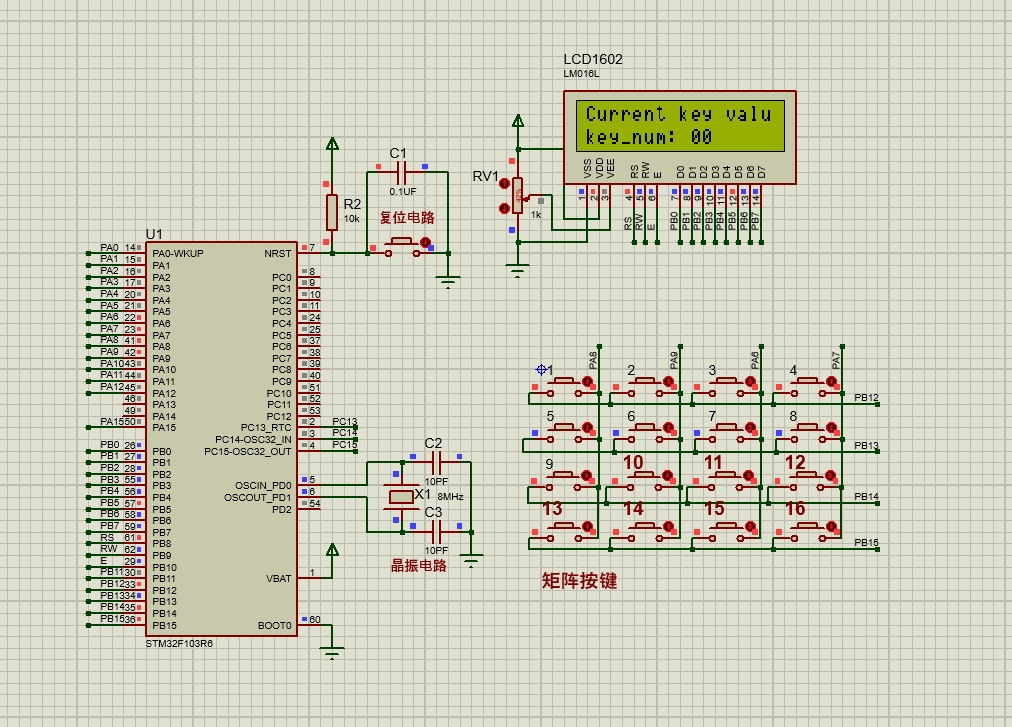
【Proteus仿真】【32单片机-A009】矩阵按键系统设计
目录 一、主要功能 二、使用步骤 三、硬件资源 四、软件设计 五、实验现象 联系作者 一、主要功能 1、按键值与LCD显示 2、矩阵按键 二、使用步骤 系统运行后,LCD1602显示当前的按键值; 当按下不同按键后显示屏更新对应的按键值。 三、硬件资…...

考研单词笔记 2025.04.09
act v表现,行动,做事,扮演,充当,担任,起作用n行为,行动,法案,法令 action n行为,行动 behave v表现,行事,守规矩,举止端…...
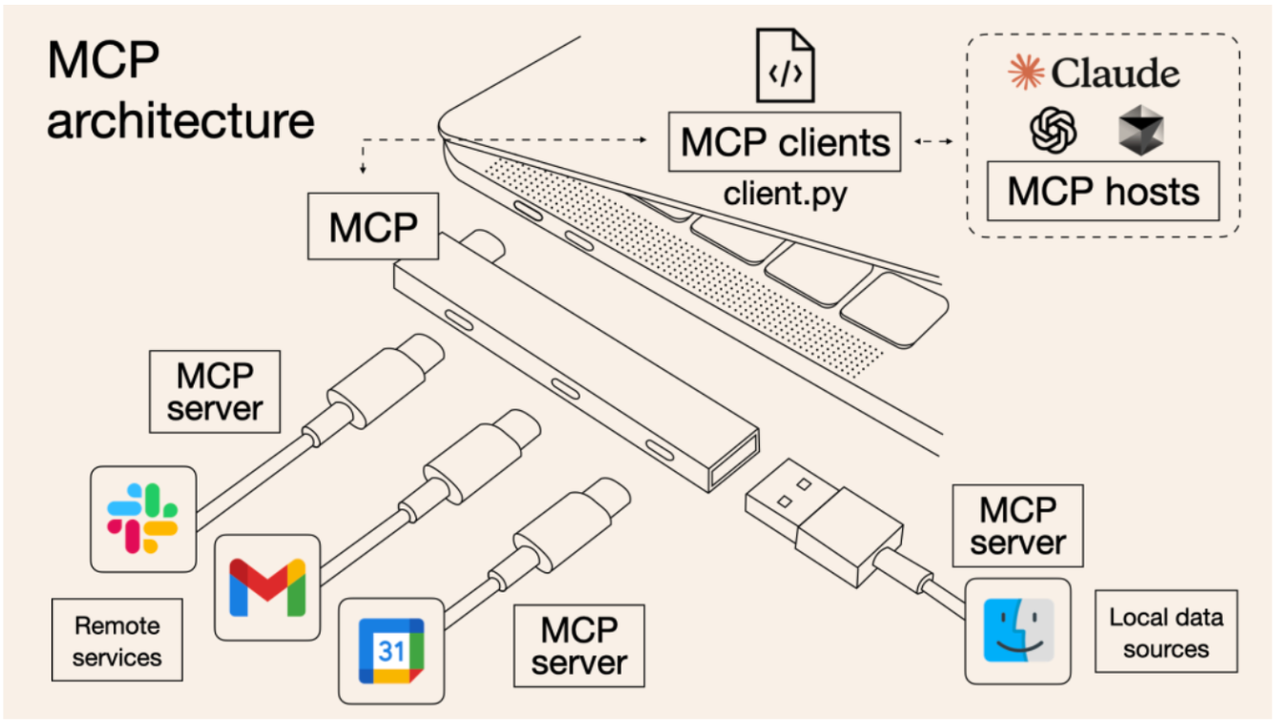
用一个实际例子快速理解MCP应用的工作步骤
已经有很多的文章介绍MCP server,MCP Client工作原理,这里不做太多介绍。但是很多介绍都只是侧重介绍概念,实际的工作原理理解起来对初学者还是不太友好。本文以一个智能旅游咨询系统为例,详细说明在利用 Model Context Protocol&…...