抖音视频下载工具
抖音视频下载工具
功能介绍
这是一个基于Python开发的抖音视频下载工具,可以方便地下载抖音平台上的视频内容。
主要特点
- 支持无水印视频下载
- 自动提取视频标题作为文件名
- 显示下载进度条
- 支持自动重试机制
- 支持调试模式
使用要求
- Python 3.10+
- Chrome浏览器
- 必要的Python包:
- selenium
- requests
- tqdm
- webdriver_manager(可选)
安装依赖
# 核心依赖
requests>=2.31.0
beautifulsoup4==4.12.2
lxml==4.9.3
urllib3>=2.1.0 # URL处理和安全连接
selenium>=4.18.1
pip install selenium requests tqdm webdriver_manager
使用方法
- 直接运行脚本:
python 抖音视频下载工具.py
- 作为模块导入:
from 抖音视频下载工具 import DouyinDownloaderdownloader = DouyinDownloader()
url = "你的抖音视频链接"
main(url)
参数说明
download_dir: 下载目录,默认为"downloads"max_retries: 最大重试次数,默认为3debug: 是否开启调试模式,默认为False
注意事项
- 确保系统已安装Chrome浏览器
- 需要稳定的网络连接
- 部分视频可能因为权限设置无法下载
- 建议不要频繁下载,以免被限制
常见问题
- 如果出现ChromeDriver相关错误,请确保Chrome浏览器版本与ChromeDriver版本匹配
- 如果下载失败,可以尝试增加重试次数或开启调试模式查看详细错误信息
代码实现
import tracebackimport requests
import re
import json
import os
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from urllib.parse import unquote
import logging
import argparse
from concurrent.futures import ThreadPoolExecutor
from tqdm import tqdmclass DouyinDownloader:def __init__(self, download_dir="downloads", max_retries=3, debug=False):"""初始化抖音下载器Args:download_dir (str): 下载目录max_retries (int): 最大重试次数debug (bool): 是否开启调试模式"""self.download_dir = download_dirself.max_retries = max_retriesself.debug = debugself.setup_logging()self.setup_chrome()if not os.path.exists(download_dir):os.makedirs(download_dir)def setup_logging(self):"""设置日志"""if self.debug:logging.basicConfig(level=logging.DEBUG,format='%(asctime)s - %(levelname)s - %(message)s',handlers=[logging.FileHandler('douyin_downloader.log'),logging.StreamHandler()])else:logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s',handlers=[logging.StreamHandler()])self.logger = logging.getLogger(__name__)def setup_chrome(self):"""设置Chrome浏览器"""chrome_options = Options()chrome_options.add_argument('--headless') # 开启无头模式chrome_options.add_argument('--disable-gpu')chrome_options.add_argument('--no-sandbox')chrome_options.add_argument('--disable-dev-shm-usage')chrome_options.add_argument('--disable-blink-features=AutomationControlled')chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])chrome_options.add_experimental_option('useAutomationExtension', False)self.driver = webdriver.Chrome(options=chrome_options)self.driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'})def __del__(self):"""析构函数,确保关闭浏览器"""if hasattr(self, 'driver'):self.driver.quit()def _save_debug_file(self, content, filename, message=""):"""保存调试文件Args:content: 要保存的内容filename: 文件名message: 提示信息"""if self.debug:try:with open(filename, 'w', encoding='utf-8') as f:f.write(content)if message:print(message)except Exception as e:print(f"保存调试文件 {filename} 失败: {str(e)}")def download_webpage(self, url):"""使用Selenium下载抖音视频页面"""try:print("正在打开网页...")self.driver.get(url)# 等待页面加载print("等待页面加载...")time.sleep(1)# 获取当前URLcurrent_url = self.driver.current_urlprint(f"最终URL: {current_url}")# 提取视频IDvideo_id = self._extract_video_id(current_url)if not video_id:print("无法提取视频ID")return None# 等待页面完全加载print("等待页面完全加载...")time.sleep(1)# 尝试提取页面数据print("尝试提取页面数据...")try:methods = [self._try_get_video_data_from_render_data,self._try_get_video_data_from_hydration,self._try_get_video_data_from_player,self._try_get_video_data_from_element]for method in methods:try:data = method()if data:return dataexcept Exception as e:if self.debug:print(f"方法 {method.__name__} 失败: {str(e)}")continueprint("所有提取方法都失败了")if self.debug:self._save_debug_file(self.driver.page_source,'page_source.html',"页面源代码已保存到page_source.html(用于调试)")return Noneexcept Exception as e:print(f"提取页面数据失败: {str(e)}")if self.debug:self._save_debug_file(self.driver.page_source,'page_source.html',"页面源代码已保存到page_source.html(用于调试)")print("详细错误信息:")print(traceback.format_exc())return Noneexcept Exception as e:print(f"下载网页时出错: {str(e)}")if self.debug:try:self._save_debug_file(self.driver.page_source,'page_source.html',"页面源代码已保存到page_source.html(用于调试)")except:print("保存页面源代码失败")print("详细错误信息:")print(traceback.format_exc())return Nonedef _try_get_video_data_from_render_data(self):"""尝试从RENDER_DATA获取视频数据"""script = """var renderData = null;try {// 方法1:直接从SSR_HYDRATED_DATA获取if (window.SSR_HYDRATED_DATA) {return JSON.stringify(window.SSR_HYDRATED_DATA);}// 方法2:从__NEXT_DATA__获取var nextDataElement = document.getElementById('__NEXT_DATA__');if (nextDataElement) {return nextDataElement.textContent;}// 方法3:从script标签中查找var scripts = document.getElementsByTagName('script');for (var i = 0; i < scripts.length; i++) {var content = scripts[i].textContent || '';if (content.includes('"video"') && content.includes('"play_addr"')) {return content;}}} catch (e) {console.log('获取数据时出错:', e);}return null;"""data = self.driver.execute_script(script)if data:print("找到页面数据")try:if self.debug:self._save_debug_file(data, 'raw_page_data.txt', "已保存原始数据到raw_page_data.txt")try:json_data = json.loads(data)if self.debug:self._save_debug_file(json.dumps(json_data, ensure_ascii=False, indent=2),'parsed_data.json',"已保存解析后的数据到parsed_data.json")return json.dumps(json_data)except:json_pattern = r'({[^{]*?"video"[^}]*?})'matches = re.finditer(json_pattern, data)for match in matches:try:json_str = match.group(1)json.loads(json_str) # 验证是否为有效JSONreturn json_strexcept:continueexcept Exception as e:if self.debug:print(f"处理页面数据时出错: {str(e)}")print("详细错误信息:")print(traceback.format_exc())return Nonedef _try_get_video_data_from_hydration(self):"""尝试从__HYDRA_DATA__获取视频数据"""script = """if (window.__HYDRA_DATA__) {return JSON.stringify(window.__HYDRA_DATA__);}return null;"""data = self.driver.execute_script(script)if data:print("从HYDRA_DATA中找到数据")return datareturn Nonedef _try_get_video_data_from_player(self):"""尝试从播放器获取视频数据"""script = """try {// 查找视频元素var videoElement = document.querySelector('video');if (videoElement && videoElement.src) {var videoData = {video_data: {nwm_video_url: videoElement.src}};// 尝试获取视频标题var title = document.title || '';if (!title) {var titleElement = document.querySelector('title, .video-title, .title, .desc, [data-e2e="video-desc"]');if (titleElement) {title = titleElement.textContent.trim();}}if (title) {videoData.desc = title;}return JSON.stringify(videoData);}// 如果没有找到视频元素,尝试从source标签获取var sourceElement = document.querySelector('source[src*="http"]');if (sourceElement && sourceElement.src) {var sourceData = {video_data: {nwm_video_url: sourceElement.src},desc: document.title || ''};return JSON.stringify(sourceData);}} catch (e) {console.log('获取视频数据时出错:', e);}return null;"""data = self.driver.execute_script(script)if data:print("从播放器中找到数据")return datareturn Nonedef _try_get_video_data_from_element(self):"""尝试从视频元素直接获取数据"""try:video_element = WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.TAG_NAME, "video")))video_url = video_element.get_attribute('src')if video_url:print("从视频元素中找到数据")return json.dumps({'video_data': {'nwm_video_url': video_url},'desc': self._get_video_title()})except:passreturn Nonedef _get_video_title(self):"""获取视频标题"""try:# 首先尝试从title标签获取title = self.driver.titleif title:return title# 如果title为空,尝试其他选择器selectors = ['title', # title标签'.video-title', # 视频标题类'.desc', # 描述类'[data-e2e="video-desc"]', # 抖音特定属性'.title', # 通用标题类]for selector in selectors:try:element = self.driver.find_element(By.CSS_SELECTOR, selector)if element and element.text.strip():return element.text.strip()except:continue# 如果还是没找到,尝试从页面源码中直接提取titlematch = re.search(r'<title[^>]*>(.*?)</title>', self.driver.page_source)if match:return match.group(1)except Exception as e:if self.debug:print(f"获取视频标题时出错: {str(e)}")return '未命名视频'def extract_video_info(self, json_str):"""从JSON响应中提取视频信息"""try:print("开始解析视频信息...")if not json_str:print("输入的JSON字符串为空")return Noneprint(f"JSON字符串长度: {len(json_str)}")print("JSON字符串前100个字符:", json_str[:100])try:data = json.loads(json_str)except json.JSONDecodeError as e:print(f"JSON解析错误: {str(e)}")print("尝试修复JSON数据...")# 尝试提取JSON部分json_pattern = r'({[^{]*?"video"[^}]*?})'match = re.search(json_pattern, json_str)if match:json_str = match.group(1)data = json.loads(json_str)if self.debug:# 保存完整的JSON数据用于调试with open('debug_response.json', 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=2)print("已保存完整响应到debug_response.json")video_data = {'desc': '未命名视频','create_time': str(int(time.time())),'video_urls': []}# 处理不同的数据格式if isinstance(data, dict):# 直接获取的视频URL格式if 'video_data' in data and 'nwm_video_url' in data['video_data']:video_data['desc'] = data.get('desc', '未命名视频')video_data['video_urls'].append(data['video_data']['nwm_video_url'])return video_data# 遍历所有可能包含视频信息的字段video_url = self._find_video_url(data)if video_url:video_data['video_urls'].append(video_url)desc = self._find_video_desc(data)if desc:video_data['desc'] = descif video_data['video_urls']:return video_dataprint("无法从响应中提取视频信息")print("数据结构:", json.dumps(data, indent=2, ensure_ascii=False)[:500])return Noneexcept Exception as e:print(f"解析视频信息时出错: {str(e)}")import tracebackprint("详细错误信息:")print(traceback.format_exc())return Nonedef _find_video_url(self, data):"""递归查找视频URL"""if isinstance(data, dict):# 检查常见的视频URL字段url_fields = ['playApi', 'playAddr', 'downloadAddr', 'video_url', 'nwm_video_url']for field in url_fields:if field in data:url = data[field]if isinstance(url, str) and url.startswith('http'):return urlelif isinstance(url, dict) and 'url_list' in url:urls = url['url_list']if urls and isinstance(urls, list):return urls[0]# 递归搜索for value in data.values():result = self._find_video_url(value)if result:return resultelif isinstance(data, list):for item in data:result = self._find_video_url(item)if result:return resultreturn Nonedef _find_video_desc(self, data):"""递归查找视频描述"""if isinstance(data, dict):if 'desc' in data and isinstance(data['desc'], str):return data['desc']# 递归搜索for value in data.values():result = self._find_video_desc(value)if result:return resultelif isinstance(data, list):for item in data:result = self._find_video_desc(item)if result:return resultreturn Nonedef _clean_title(self, title):"""清理视频标题Args:title (str): 原始标题Returns:str: 清理后的标题"""# 移除HTML标签title = re.sub(r'<[^>]+>', '', title)# 移除抖音常见的标签(#xxx)title = re.sub(r'#[^ ]+', '', title)# 移除" - 抖音"后缀title = re.sub(r' *- *抖音.*$', '', title)# 移除特殊字符和空格title = re.sub(r'[\\/*?:"<>|]', '', title)title = re.sub(r'\s+', '', title)# 如果标题为空,使用默认标题if not title:title = '未命名视频'return titledef download_video(self, video_url, title, retry_count=0):"""下载视频文件Args:video_url (str): 视频URLtitle (str): 视频标题retry_count (int): 当前重试次数Returns:bool: 下载是否成功"""try:# 清理标题title = self._clean_title(title)print(f"处理后的文件名: {title}")filepath = os.path.join(self.download_dir, f"{title}.mp4")# 如果文件已存在,添加数字后缀base_filepath = filepathcounter = 1while os.path.exists(filepath):filename, ext = os.path.splitext(base_filepath)filepath = f"{filename}_{counter}{ext}"counter += 1headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Referer': 'https://www.douyin.com/'}response = requests.get(video_url, headers=headers, stream=True)response.raise_for_status()# 获取文件大小total_size = int(response.headers.get('content-length', 0))with open(filepath, 'wb') as f, tqdm(desc=os.path.basename(filepath),total=total_size,unit='iB',unit_scale=True,unit_divisor=1024,) as pbar:for data in response.iter_content(chunk_size=1024):size = f.write(data)pbar.update(size)self.logger.info(f"视频已保存到: {filepath}")return Trueexcept Exception as e:self.logger.error(f"下载视频时出错: {str(e)}")if retry_count < self.max_retries:self.logger.info(f"正在进行第{retry_count + 1}次重试...")time.sleep(1) # 等待2秒后重试return self.download_video(video_url, title, retry_count + 1)return Falsedef _extract_video_id(self, url):"""从URL中提取视频ID"""patterns = [r'/video/(\d+)',r'item_ids=(\d+)',r'aweme_id=(\d+)']for pattern in patterns:match = re.search(pattern, url)if match:video_id = match.group(1)print(f"提取到视频ID: {video_id}")return video_idreturn Nonedef main(url):try:# 创建下载器实例downloader = DouyinDownloader(download_dir="downloads",max_retries=3,debug=False # 默认关闭调试模式)print(f"正在处理链接: {url}")json_str = downloader.download_webpage(url)if json_str:video_info = downloader.extract_video_info(json_str)if video_info and video_info['video_urls']:print(f"视频标题: {video_info['desc']}")video_url = video_info['video_urls'][0]success = downloader.download_video(video_url, video_info['desc'])if success:print("下载成功!")else:print("下载失败!")else:print("无法获取视频下载地址")else:print("下载网页失败")except Exception as e:print(f"程序执行出错: {str(e)}")finally:if 'downloader' in locals():del downloaderif __name__ == "__main__":# 使用固定的测试链接url = 'https://v.douyin.com/Fw35vv97K4s/'main(url)
相关文章:

抖音视频下载工具
抖音视频下载工具 功能介绍 这是一个基于Python开发的抖音视频下载工具,可以方便地下载抖音平台上的视频内容。 主要特点 支持无水印视频下载自动提取视频标题作为文件名显示下载进度条支持自动重试机制支持调试模式 使用要求 Python 3.10Chrome浏览器必要的P…...
断言与反射——以golang为例
断言 x.(T) 检查x的动态类型是否是T,其中x必须是接口值。 简单使用 func main() {var x interface{}x 100value1, ok : x.(int)if ok {fmt.Println(value1)}value2, ok : x.(string)if ok {//未打印fmt.Println(value2)} }需要注意如果不接受第二个参数就是OK,这…...
】商务部信用对接、法律咨询与视频面试功能开发全攻略)
【家政平台开发(27)】商务部信用对接、法律咨询与视频面试功能开发全攻略
本【家政平台开发】专栏聚焦家政平台从 0 到 1 的全流程打造。从前期需求分析,剖析家政行业现状、挖掘用户需求与梳理功能要点,到系统设计阶段的架构选型、数据库构建,再到开发阶段各模块逐一实现。涵盖移动与 PC 端设计、接口开发及性能优化,测试阶段多维度保障平台质量,…...
【数据结构】排序算法(下篇·开端)·深剖数据难点
前引:前面我们通过层层学习,了解了Hoare大佬的排序精髓,今天我们学习的东西可能稍微有点难度,因此我们必须学会思想,我很受感慨,借此分享一下:【用1520分钟去调试】,如果我们遇到了任…...
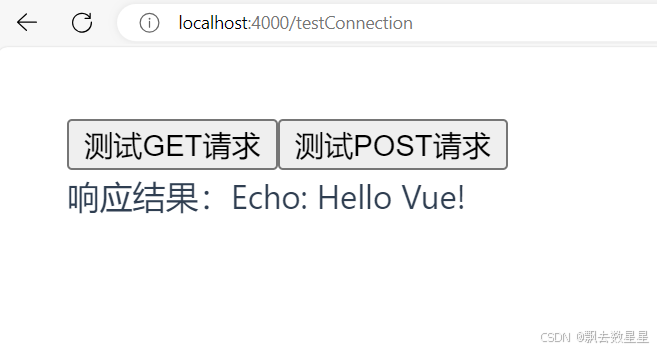
山东大学软件学院创新项目实训开发日志(9)之测试前后端连接
在正式开始前后端功能开发前,在队友的帮助下,成功完成了前后端测试连接: 首先在后端编写一个测试相应程序: 然后在前端创建vue 并且在index.js中添加一下元素: 然后进行测试,测试成功: 后续可…...

【VUE3】Eslint 与 Prettier 的配置
目录 0 前言 1 VSCode 中的 Eslint 与 prettier 插件 2 两种方案 3 eslint.config.js 4 eslint-plugin-prettier 插件 5 eslint-config-prettier 插件 6 安装插件命令 7 其他配置 8 参考资料 0 前言 黑马程序员视频地址:160-Vue3大事件项目-ESlint配合P…...

蓝桥杯C++组算法知识点整理 · 考前突击(上)【小白适用】
【背景说明】本文的作者是一名算法竞赛小白,在第一次参加蓝桥杯之前希望整理一下自己会了哪些算法,于是有了本文的诞生。分享在这里也希望与众多学子共勉。如果时间允许的话,这一系列会分为上中下三部分和大家见面,祝大家竞赛顺利…...

springboot调用python文件,python文件使用其他dat文件,适配windows和linux,以及docker环境的方案
介绍 后台是用springboot技术,其他同事做的算法是python,现在的需求是springboot调用python,python又需要调用其他的数据文件,比如dat文件,这个文件是app通过蓝牙获取智能戒指数据以后,保存到后台…...
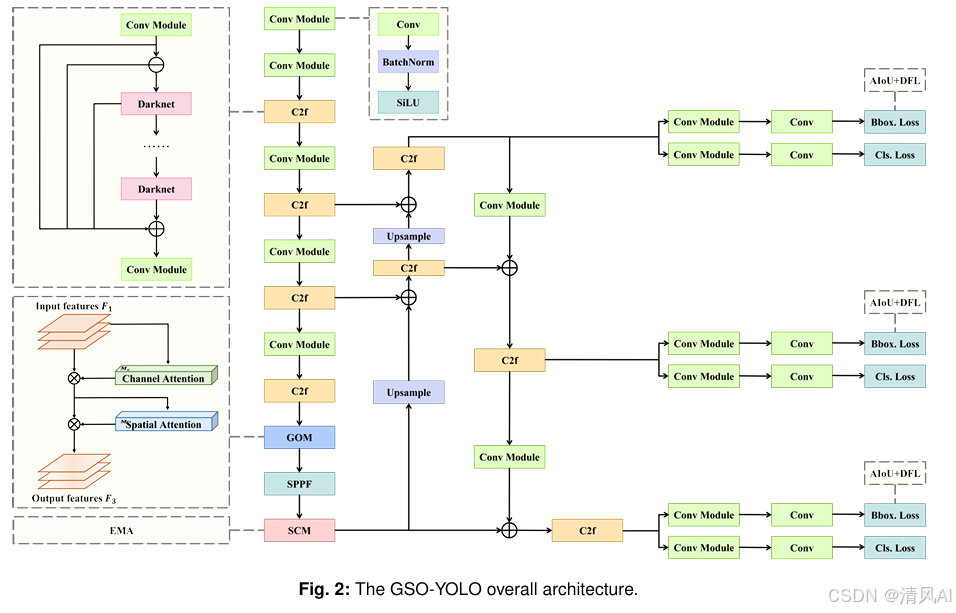
GSO-YOLO:基于全局稳定性优化的建筑工地目标检测算法解析
论文地址:https://arxiv.org/pdf/2407.00906 1. 论文概述 《GSO-YOLO: Global Stability Optimization YOLO for Construction Site Detection》提出了一种针对建筑工地复杂场景优化的目标检测模型。通过融合全局优化模块(GOM)、稳定捕捉模块(SCM)和创新的AIoU损失函…...

Python 中使用单例模式
有这么一种场景,Web服务中有一个全局资源池,在需要使用的地方就自然而言引用该全局资源池即可,此时可以将该资源池以单例模式实现。随后,需要为某一特殊业务场景专门准备一个全局资源池,于是额外复制一份代码新建了一个…...

系统思考—提升解决动态性复杂问题能力
感谢合作伙伴的信任推荐! 客户今年的人才发展重点之一,是提升管理者应对动态性、复杂性问题的能力。 在深入交流后,系统思考作为关键能力模块,最终被纳入轮训项目——这不仅是一次培训合作,更是一场共同认知的跃迁&am…...
)
Java基础 - 反射(2)
文章目录 示例5. 通过反射获得类的private、 protected、 默认访问修饰符的属性值。6. 通过反射获得类的private方法。7. 通过反射实现一个工具BeanUtils, 可以将一个对象属性相同的值赋值给另一个对象 接上篇: 示例 5. 通过反射获得类的private、 pro…...

Python proteinflow 库介绍
ProteinFlow是一个开源的Python库,旨在简化蛋白质结构数据在深度学习应用中的预处理过程。以下是其详细介绍: 功能 数据处理:支持处理单链和多链蛋白质结构,包括二级结构特征、扭转角等特征化选项。 数据获取:能够从Protein Data Bank (PDB)和Structural Antibody Databa…...

P1162 洛谷 填涂颜色
题目描述 思考 看数据量 30 而且是个二维的,很像走迷宫 直接深搜! 而且这个就是搜连通块 代码 一开始的15分代码,想的很简单,对dfs进行分类,如果是在边界上,就直接递归,不让其赋值,…...
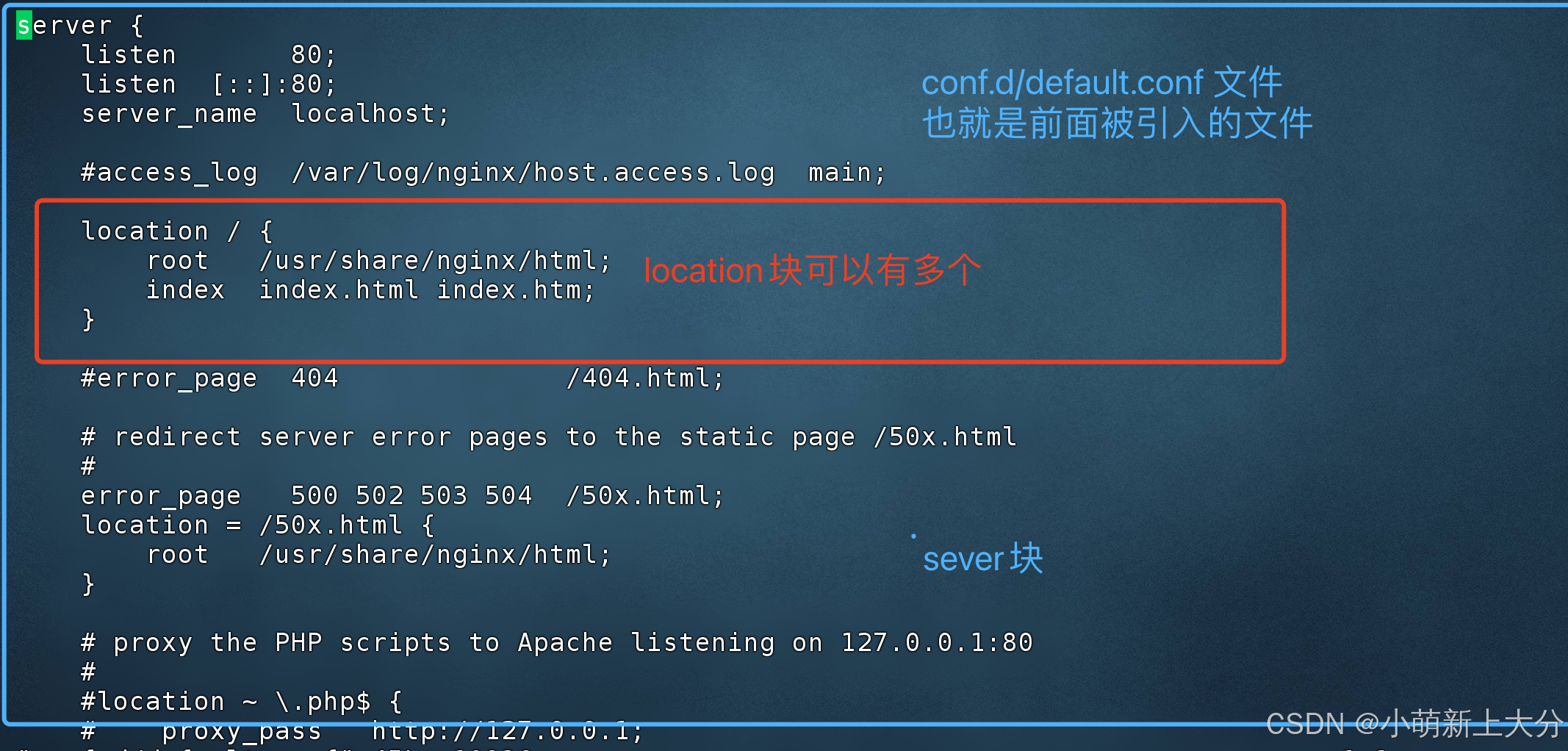
docker安装nginx,基础命令,目录结构,配置文件结构
Nginx简介 Nginx是一款轻量级的Web服务器(动静分离)/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。其特点是占有内存少,并发能力强. 🔗官网 docker安装Nginx 🐳 一、前提条件 • 已安装 Docker(dock…...

SQLI漏洞公开报告分析
文章目录 1. 闭合 )2. 邀请码|POST参数|时间盲注 | **PostgreSQL**3. POST|order by参数|布尔盲注|Oracle4. SOAP请求|MSSQL|布尔盲注5. MySQL 时间盲注漏洞6. GET|普通回显注入7. ImpressCMS 1.4.2 | CVE | POST | 布尔盲注8. Mysql | post | 布尔/时间盲注9. 登录口 | post |…...

SpringBoot项目部署之启动脚本
一、启动脚本方案 1. 基础启动方式 1.1 直接运行JAR java -jar your-app.jar --spring.profiles.activeprod优点:简单直接,适合快速测试缺点:终端关闭即终止进程 1.2 后台运行 nohup java -jar your-app.jar > app.log 2>&1 &…...
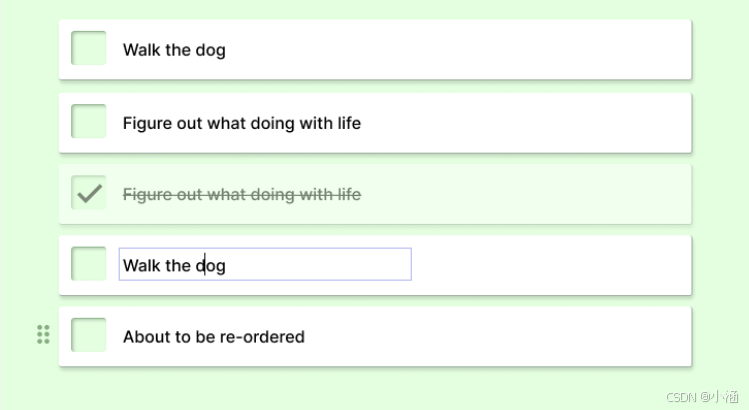
用Django和AJAX创建一个待办事项应用
用Django和AJAX创建一个待办事项应用 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 用Django和AJAX创建一个待办事项应用让我们创建一个简单的 Django 项目,其中包含不同类型的 A…...

JavaScript:游戏开发的利器
在近年来的科技迅速发展中,JavaScript 已逐渐成为游戏开发领域中最受欢迎的编程语言之一。它的跨平台特性、广泛的社区支持、丰富的库和框架使得开发者能够快速、有效地创建各种类型的游戏。本文将深入探讨 JavaScript 在游戏开发中的优势。 一、跨平台支持 JavaSc…...
C语言今天开始了学习
好多年没有弄了,还是捡起来弄下吧 用的vscode 建议大家参考这个配置 c语言vscode配置 c语言这个语言简单,但是今天听到了一个消息说python 不知道怎么debug。人才真多啊...

Elasticsearch 系列专题 - 第五篇:集群与性能优化
随着数据量和访问量的增长,单节点 Elasticsearch 已无法满足需求。本篇将介绍集群架构、性能优化方法以及常见故障排查,帮助你应对生产环境中的挑战。 1. 集群架构 1.1 节点角色(Master、Data、Ingest 等) Elasticsearch 集群由多个节点组成,每个节点可扮演不同角色: M…...
)
鸿蒙NEXT开发Preferences工具类(ArkTs)
import { AppUtil } from ./AppUtil; import dataPreferences from ohos.data.preferences; export const DEFAULT_PREFERENCE_NAME: string "SP_HARMONY_UTILS_PREFERENCES"; // Preferences实例的名称。/*** Preferences工具类* author CSDN-鸿蒙布道师* since 20…...
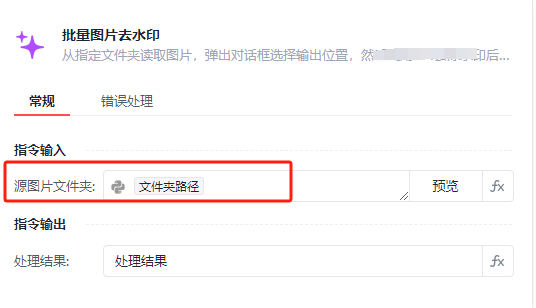
电商素材革命:影刀RPA魔法指令3.0驱动批量去水印,实现秒级素材净化
本文 去除水印实操视频展示电商图片水印处理的困境影刀 RPA 魔法指令 3.0 强势登场利用魔法指令3.0两步实现去除水印操作关于影刀RPA 去除水印实操视频展示 我们这里选择了4张小红书里面比较帅气的图片,但凡用过小红书的都知道,小红书右下角是会有小…...
:什么是vuex,请解释一下它在Vue中的作用)
前端面试题(七):什么是vuex,请解释一下它在Vue中的作用
Vuex 是一个专门为 Vue.js 应用程序开发的状态管理库。它可以集中管理应用的所有状态,并保证状态以一种可预测的方式发生变化。简单来说,Vuex 用来管理 Vue 应用中的数据(即状态),使得数据的传递和共享更加清晰和可靠&…...

笔记:头文件与静态库的使用及组织方式
笔记:头文件与静态库的使用及组织方式 1. 头文件的作用 接口声明:提供函数、类、变量等标识符的声明,供其他模块调用。编译依赖:编译器需要头文件来验证函数调用和类型匹配。避免重复定义:通过包含保护(如…...
)
ubuntu,react的学习(1)
在此目录下,开启命令行 /home/kt/react 如下操作 tkt4028:~/react$ npm create vitelatest task-manager -- --template react Need to install the following packages: create-vite6.3.1 Ok to proceed? (y) y> npx > cva task-manager --template react…...

【QT】QTreeWidgetItem的checkState/setCheckState函数和isSelected/setSelected函数
目录 1、函数原型1.1 checkState/setCheckState1.2 isSelected/setSelected2、功能用途3、示例QTreeWidget的checkState/setCheckState函数和isSelected/setSelected这两组函数有着不同的用途,下面具体说明: 1、函数原型 1.1 checkState/setCheckState Qt::CheckState QTr…...
 join() get() 使用经验)
CompletableFuture 和 List<CompletableFuture> allOf() join() get() 使用经验
CompletableFuture<Map<Menu, Map<IntentDetail, Double>>> xxx CompletableFuture.supplyAsync(() -> {Map<Menu, Map<IntentDetail, Double>> scores new ConcurrentHashMap<>();// 存储结果scores.computeIfAbsent(menu, k -> n…...

CExercise_09_结构体和枚举_2VS的Debug模式查看它的内存布局,采用结构体数组的方式存储信息,调用函数打印结构体数组.
题目: 下面结构体类型的变量的内存布局是怎样的?请使用VS的Debug模式查看它的内存布局 typedef struct stundent_s {int number;char name[25];char gender;int chinese;int math;int english; } Student;// 结构体对象的声明和初始化 Student s1 { 1, …...

SSRF漏洞技术解析与实战防御指南
一、SSRF漏洞简介 服务端请求伪造(Server-Side Request Forgery, SSRF) 是一种攻击者通过操控服务端发起非预期网络请求的安全漏洞。攻击者利用目标服务器的权限,构造恶意请求访问内网资源、本地系统文件或第三方服务,可能导致…...