SmolDocling:一种超紧凑的视觉语言模型,用于端到端多模态文档转换
paper地址:SmolDocling: An ultra-compact vision-language model for
end-to-end multi-modal document conversion
Huggingface地址:SmolDocling-256M-preview
代码对应的权重文件:SmolDocling-256M-preview权重文件
一、摘要
以下是文章摘要的总结:
SmolDocling 是一个超紧凑型的视觉-语言模型,用于端到端的文档转换。它通过生成一种名为 DocTags 的新标记格式,捕捉文档中所有元素的内容、结构和位置。SmolDocling 在多种文档类型(如商务文档、学术论文、技术报告等)上表现出稳健的性能,能够准确重现代码、表格、公式、图表等复杂元素。与更大规模的模型相比,它在性能上具有竞争力,同时显著降低了计算需求。此外,该研究还贡献了多个公开数据集,用于支持图表、表格、公式和代码识别等任务。
(1)以下是 SmolDocling 模型支持的所有要素:
- 代码列表:识别和解析代码片段,包括缩进和行号等细节。
- 表格:识别表格结构,包括单元格合并、表头信息等。
- 公式:识别和解析数学公式,支持 LaTeX 格式。
- 图表:识别图表并将其转换为表格形式。
- 列表:识别有序列表和无序列表,支持嵌套列表。
- 页眉和页脚:识别页面的页眉和页脚内容。
- 图片:识别图片并提供分类信息。
- 段落文本:识别普通文本内容,包括换行和格式。
- 标题:识别文档中的标题和章节标题。
- 脚注:识别脚注内容。
- 文档索引:识别文档索引部分。
- 化学分子结构:识别化学分子图像并转换为 SMILES 格式(扩展功能)。
这些要素涵盖了文档中常见的各种内容类型,使得 SmolDocling 能够全面、准确地处理和转换复杂的文档。
(2) DocTags 输出格式
DocTags 是 SmolDocling 的核心输出格式,用于统一表示文档的内容、结构和布局。以下是 DocTags 支持的主要标签和格式:
文档块类型
<text>:普通文本内容。<title>:标题或章节标题。<section_header>:章节标题。<list_item>:列表项。<ordered_list>:有序列表。<unordered_list>:无序列表。<code>:代码片段,支持缩进和行号。<formula>:数学公式,支持 LaTeX 格式。<picture>:图片,支持分类信息。<caption>:标题或说明文字(通常嵌套在图片或表格中)。<footnote>:脚注。<page_header>:页眉。<page_footer>:页脚。<document_index>:文档索引。<otsl>:表格结构,使用 OTSL 标签表示。
位置标签
<loc_x1><loc_y1><loc_x2><loc_y2>:表示元素在页面中的位置(边界框),左上角坐标和右下角坐标。
表格结构(OTSL 标签)
<fcel>:包含内容的单元格。<ecel>:空单元格。<ched>:列标题单元格。<rhed>:行标题单元格。<srow>:表格部分的行。
代码分类
<_programming-language_>:编程语言分类标签(如 Python、Java 等)。
图片分类
<image_class>:图片分类标签(如 pie_chart、bar_chart、natural_image 等)。
2. 其他格式
SmolDocling 的输出可以通过 DocTags 转换为其他常见格式,具体取决于下游任务的需求:
LaTeX
- 用于数学公式(
<formula>标签)的输出。 - 示例:
<formula>E = mc^2</formula>可以转换为 LaTeX 格式。
HTML
- 用于表格(
<otsl>标签)和其他结构化内容的输出。 - 示例:
<otsl>标签可以转换为 HTML 表格。
Markdown
- 用于文本、列表、标题等的输出。
- 示例:
<text>,<list_item>,<title>等标签可以转换为 Markdown 格式。
SMILES
- 用于化学分子结构的输出(扩展功能)。
- 示例:分子图像可以转换为 SMILES 格式。
SmolDocling 的主要输出格式是 DocTags,它是一种高效的标记语言,能够统一表示文档的内容、结构和布局。此外,DocTags 可以轻松转换为其他常见格式(如 LaTeX、HTML、Markdown 等),以满足不同的应用需求。这种灵活性使得 SmolDocling 能够适应多种文档处理任务。
二、背景介绍
1、文档转换的背景与挑战
- 技术挑战:将复杂的数字文档(如 PDF)转换为结构化的、可机器处理的格式是一项长期的技术难题。
- 主要问题:
- 文档布局和样式的多样性。
- PDF 格式本身不透明,优化用于打印而非语义解析。
- 复杂的布局样式和视觉挑战元素(如表格、图表、表单)会影响文档的阅读顺序和理解。
2、现有方法的局限性
- 传统流水线方法:
- 依赖多个专门模型(如 OCR、布局分析、表格结构识别等)。
- 虽然结果质量高,但难以调优和泛化。
- 大型多模态模型(LVLMs):
- 能够端到端解决文档转换问题。
- 存在幻觉(hallucinations)、计算资源消耗大等问题。
- 缺乏高质量的公开数据集。
3、SmolDocling 的提出
- 目标:通过一个紧凑的模型实现端到端的文档转换,同时保持高效性和高质量输出。
- 核心创新:
- DocTags 格式:一种新的标记语言,用于统一表示文档的内容、结构和布局。
- 超紧凑模型:基于 Hugging Face 的 SmolVLM-256M,参数量仅为 256M。
- 数据集贡献:公开了多个高质量数据集,用于支持图表、表格、公式和代码识别等任务。
4、SmolDocling 的优势
- 性能:在多种文档类型(如商务文档、学术论文、技术报告等)上表现出稳健的性能。
- 效率:显著减少了计算需求,与更大规模的模型相比具有竞争力。
- 灵活性:支持多种文档元素(如代码、表格、公式、图表等)的识别和转换。
5、数据集的贡献
- DocLayNet-PT:140 万页的多模态文档预训练数据集,包含丰富的标注(如布局、表格、代码、图表等)。
- 任务特定数据集:针对表格、代码、公式、图表等任务生成了多个高质量数据集(如 PubTables-1M、SynthChartNet、SynthCodeNet 等)。
三、相关工作
主要分为两个方面:大型视觉-语言模型(LVLMs) 和 文档理解领域的研究现状。以下是详细总结:
1. 大型视觉-语言模型(LVLMs)
- 专有模型:
- GPT-4o、Gemini 和 Claude 3.5 等专有模型展示了在多种模态(包括视觉)上的卓越能力。
- 开源方法:
- BLIP-2:最早将视觉编码器与冻结的大型语言模型(如 OPT 或 FlanT5)结合,使用轻量级的 Q-former。
- MiniGPT-4:在 BLIP-2 的基础上,将冻结的视觉编码器与冻结的 LLM(如 Vicuna)结合,使用 Q-Former 网络和单个投影层。
- LLaVA:使用最小的适配层,结合视觉编码器和 LLM。
- LLaVA-OneVision 和 LLaVA-NeXTInterleave:支持多图像、更高分辨率和视频理解。
- InternLM-XComposer:专门设计用于处理高分辨率和文本-图像组合与理解。
- Qwen-VL:引入位置感知适配器,解决视觉编码器生成的长图像特征序列带来的效率问题。
- Qwen2.5-VL:使用窗口注意力和 2D 旋转位置嵌入,高效处理原生分辨率输入,并引入视觉-语言合并器进行动态特征压缩。
2. 文档理解领域的研究现状
- 文档理解任务:
- 包括文档分类、OCR、布局分析、表格识别、键值对提取、图表理解、公式识别等。
- 现有解决方案:
- 商业云服务:如 Amazon Textract、Google Cloud Document AI、Microsoft Azure AI Document Intelligence。
- 前沿模型:如 GPT-4o、Claude。
- 开源库:如 Docling、GROBID、Marker、MinerU 或 Unstructured。
- 流水线系统:
- 实现了源代码中的流水线,根据输入文档有条件地应用专门的单任务模型,并将预测结果组合成有意义的文档表示。
- 每个任务通常涉及人工设计的预处理和后处理逻辑(如设置布局检测的置信度阈值、匹配布局元素与文本单元格等)。
- 多任务模型:
- 旨在提供一个能够同时处理多种文档理解相关任务的单一模型,利用跨任务共享的上下文和表示。
- OCR 依赖方法:如 LayoutLM 和 UDOP,使用从外部 OCR 引擎提取的文本,以及图像和文本边界框位置作为输入。
- 无 OCR 方法:如 Donut、Dessurt、DocParser、Pix2Struct,基于变换器的模型,端到端训练以直接从图像输出文本。
- 大型视觉语言模型(LVLMs):如 LLaVA、LLaVA-OneVision、UReader、Kosmos-2 和 Qwen-VL,利用各种视觉编码器、投影适配器和 LLM。
- 评估数据集:如 DocVQA 和 mPLUG-DocOwl 1.5 数据集,主要关注问答和推理。
3. 与 SmolDocling 相关的最接近的工作
- Nougat:专注于学术文档的精确转换和结构识别。
- DocOwl 2:使用动态形状自适应裁剪模块处理高分辨率图像,并通过 ViT 视觉编码器和 LLaMa 基础的 LLM 进行处理。
- GOT:专注于将多种元素(如文本、公式、分子图、表格、图表、乐谱和几何形状)转换为结构化格式。
- Qwen2.5-VL:引入 Omni-Parsing 策略,将多种文档元素整合到一个统一的基于 HTML 的表示中。
四、SmolDocling 模型
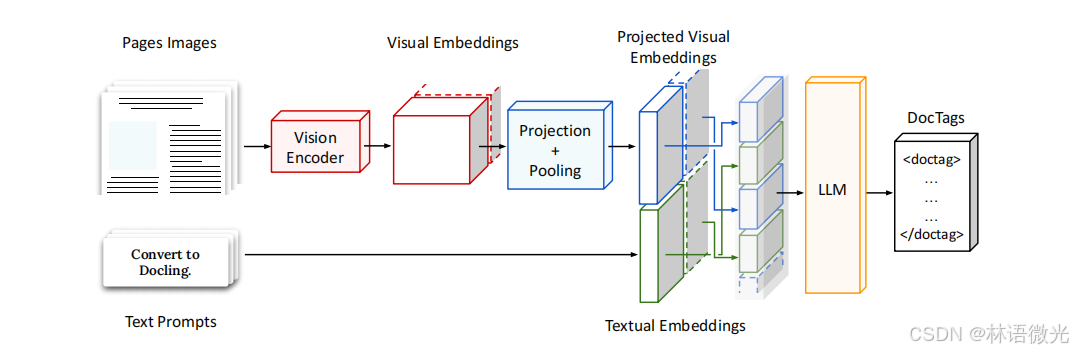
图1展示了SmolDocling的端到端流程:输入文档图像,经视觉编码器提取特征,与文本提示嵌入结合,通过LLM自回归生成DocTags序列输出。
1、SmolDocling 的模型架构
SmolDocling 的模型架构通过紧凑的视觉编码器和轻量级语言模型设计,结合激进的像素洗牌策略和视觉嵌入投影与池化技术,实现了高效的多模态融合,能够快速、准确地将文档图像转换为结构化的 DocTags 格式,显著减少了计算需求,同时在多种文档任务上表现出色。
2、DocTags格式
DocTags格式是一种结构化的标记语言,用于高效表示文档内容、结构和布局,通过明确标签(如文本、标题、列表项、代码、公式、图片等)和位置信息标签,支持表格结构和代码、图片分类,结合图2展示其如何描述文档元素的关键特征,包括元素类型、位置和内容,从而实现文档的高效转换和解析。
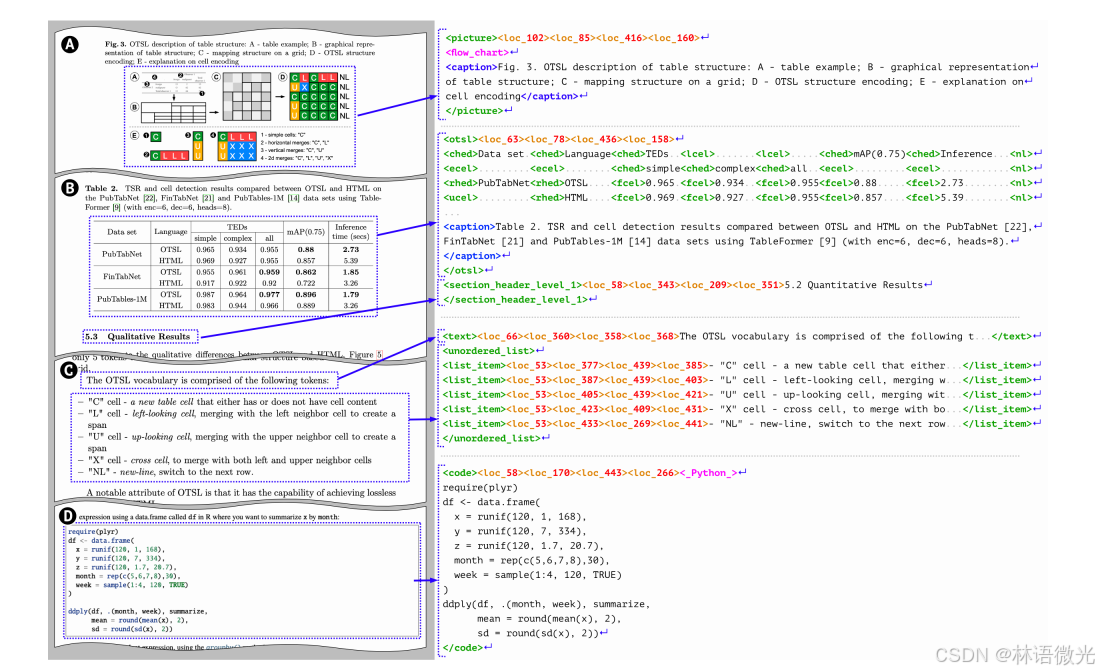
图2:DocTags格式描述了文档元素的关键特征:元素类型(文本、图片、表格、代码等)、页面位置和内容。嵌套标签传达额外信息:图片和表格可以嵌套标题,表格结构用OTSL标签表示,列表嵌套列表项,代码和图片带有分类。所有DocTags输出均来自SmolDocling预测,人为插入了换行符和点(…)以提高可读性。
3、模型训练
SmolDocling的模型训练采用课程学习方法,通过三个阶段逐步提升模型性能。
初始阶段将DocTags标记引入tokenizer,冻结视觉编码器,单独训练语言模型以适应新输出格式。
联合训练阶段解冻视觉编码器,同时训练视觉和语言部分,实现多模态融合。
最后使用所有数据集进行微调,确保模型在多种任务上的泛化能力。训练数据涵盖DocLayNet-PT预训练数据集和多个任务特定数据集,全面覆盖多种文档类型和任务。最终,SmolDocling在A100 GPU上实现单页转换时间0.35秒,内存占用仅0.489 GB,展现出高效、准确的文档转换能力。
五、数据
1、预训练数据集
- DocLayNet-PT:包含140万页的文档图像,从CommonCrawl、Wikipedia和商业文档中提取,涵盖方程式、表格、代码和彩色布局等内容。通过PDF解析和增强处理,提供布局元素、表格结构、语言、主题和图形分类的弱标注。
- Docmatix:包含130万文档,采用与DocLayNet-PT相同的弱标注策略,并增加了将多页文档转换为DocTags的指令。
2、任务特定数据集
- 布局数据集:
- DocLayNet v2:从DocLayNet-PT中采样76K页,经人工标注和质量审查,用于微调。
- WordScape:提取63K包含文本和表格的页面,作为可靠的真实标注源。
- SynthDocNet:合成250K页,使用Wikipedia内容生成,增强模型对不同布局、颜色和字体的适应性。
- 表格数据集:包括PubTables-1M、FinTabNet、WikiTableSet和从WordScape文档中提取的表格信息,转换为OTSL格式并与文本内容交织,形成紧凑序列。
- 图表数据集:包含250万张不同类型的图表(线图、饼图、柱状图等),使用三个可视化库生成,确保视觉多样性。
- 代码数据集:包含930万段渲染代码片段,涵盖56种编程语言,使用LaTeX和Pygments生成视觉多样化的代码渲染。
- 公式数据集:包含550万条独特公式,从arXiv源LaTeX代码中提取并规范化,使用LaTeX渲染,确保模型训练基于正确和标准化的代码。
3、文档指令调优数据集
- 使用DocLayNet-PT页面样本,通过随机采样布局元素生成指令,如“在特定边界框内执行OCR”、“识别页面元素类型”等,并结合Granite-3.1-2b-instruct LLM避免灾难性遗忘。
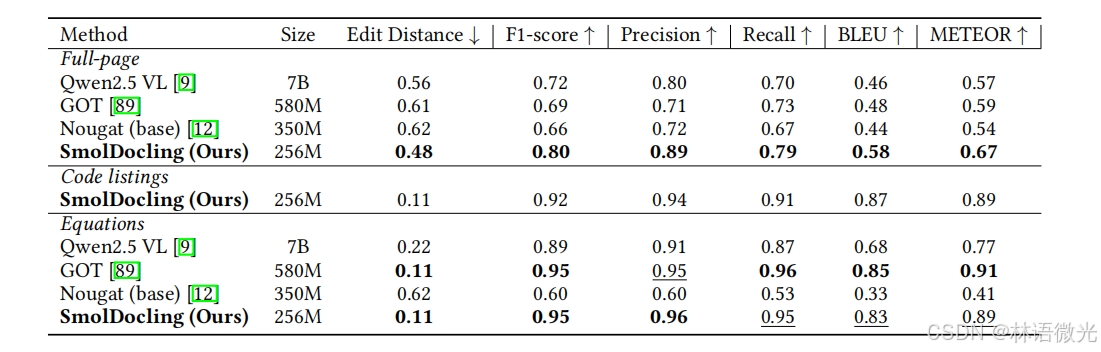
表2:结构化文档文本识别。我们在DocLayNet上评估OCR性能和文档格式,重点关注文本元素,排除表格。文本准确性通过多个指标(编辑距离、F1分数、精确度、召回率、BLEU和METEOR)进行衡量。
4、数据集贡献
- SmolDocling团队贡献了多个高质量数据集,包括DocLayNet-PT、Docmatix、SynthChartNet、SynthC
相关文章:
SmolDocling:一种超紧凑的视觉语言模型,用于端到端多模态文档转换
paper地址:SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion Huggingface地址:SmolDocling-256M-preview 代码对应的权重文件:SmolDocling-256M-preview权重文件 一、摘要 以下是文章摘要的总结: SmolDocling 是一…...

理解CSS3 的 max/min-content及fit-content等width值
本文首发在我的个人博客: 理解CSS3 的 max/min-content及fit-content等width值https://www.brandhuang.com/article/1744253362074 width/height 的属性值 fit-content 这是一个 CSS3 属性,用来设置元素的宽度和高度,值为 fit-content&#…...
关键路径任务延误,如何快速调整
快速识别延误原因、优化资源配置、实施任务并行、调整任务优先级是关键路径任务延误后快速调整的有效方式。其中,快速识别延误原因尤为重要,需要项目管理者及时发现影响关键路径任务延误的核心问题,通过系统性的分析,确保延误的具…...

Elasticsearch 全面解析
Elasticsearch 全面解析 前言一、简介核心特性应用场景 二、核心原理与架构设计1. 倒排索引(Inverted Index)2. 分片与副本机制(Sharding & Replication)3. 节点角色与集群管理 三、核心特点1. 灵活的查询语言(Que…...
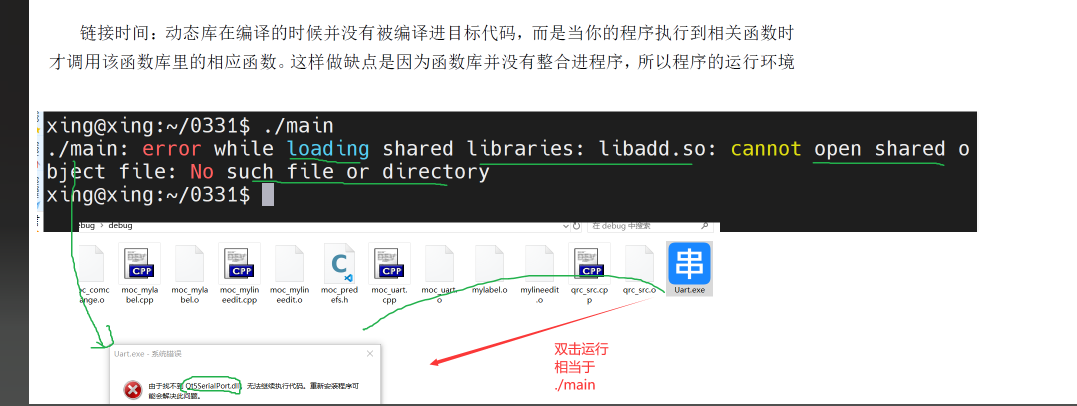
linux入门四:Linux 编译器
一、C 语言编译器 GCC:开启编程之旅 1.1 GCC 安装:一站式工具链 GCC(GNU Compiler Collection)是 Linux 下最常用的 C/C 编译器,支持多种编程语言。安装命令(适用于 Debian/Ubuntu 系统)&…...

springboot集成springcloud vault读值示例
接上三篇 Vault---机密信息管理工具安装及常用示例 Vault机密管理工具集群配置示例 vault签发根证书、中间证书、ca证书流程记录 项目里打算把所有密码都放到vault里管理,vault提供了springcloud vault用来在springboot里连接vault,启动加载vault里的值放…...

什么是虚拟线程?与普通线程的区别
引言:线程的演进与挑战 在传统的并发编程中,线程是一种非常重要的概念。我们使用线程来实现任务的并发执行,从而提高程序的执行效率。普通线程(如 Thread 类)是一种重量级的线程,每个线程都对应着操作系统…...
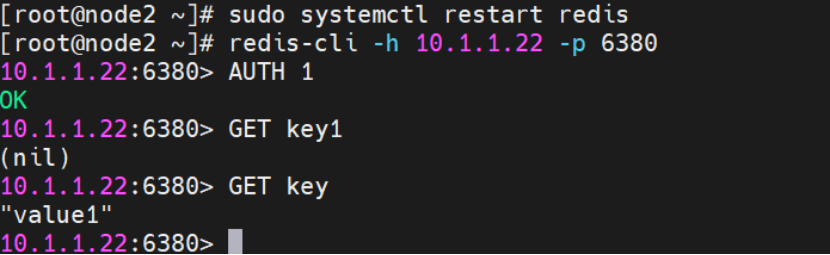
edis 主从复制
Redis 主从复制是一种数据同步机制,主节点(Master)将数据复制到一个或多个从节点(Slave),从 而实现数据备份、读写分离和高可用性。 1、解决我们的日常一个单机故障,而衍生出来 主从架构 2、…...

机器视觉+深度学习,让电子零部件表面缺陷检测效率大幅提升
在精密加工的3C电子行业中,一抹0.1毫米的油渍,一粒肉眼难辨的灰尘或将引发整机性能隐患。当制造业迈入微米级品质竞争时代,产品表面看似微不足道的脏污缺陷,正成为制约企业高质量发展的隐形枷锁。分布无规律的污渍斑点、形态各异的…...

Java基础关键_035_Lambda 表达式
目 录 一、引例:TreeSet 排序 1.实现 Comparable 接口 2.比较器 3.匿名内部类 4.Lambda 表达式 5.Lambda 表达式和匿名内部类的区别 二、函数式编程 三、Lambda 表达式的使用 1.无返回值函数式接口 (1)无返回值无参数 (…...
OPEX baota 2024.02.26
OPEX baota 2024.02.26 运维集成软件宝塔2024.02.26作废例子: 最重要的两个地方:上传文件 网站,重启应用服务器(tomcat) 其他很少用的...
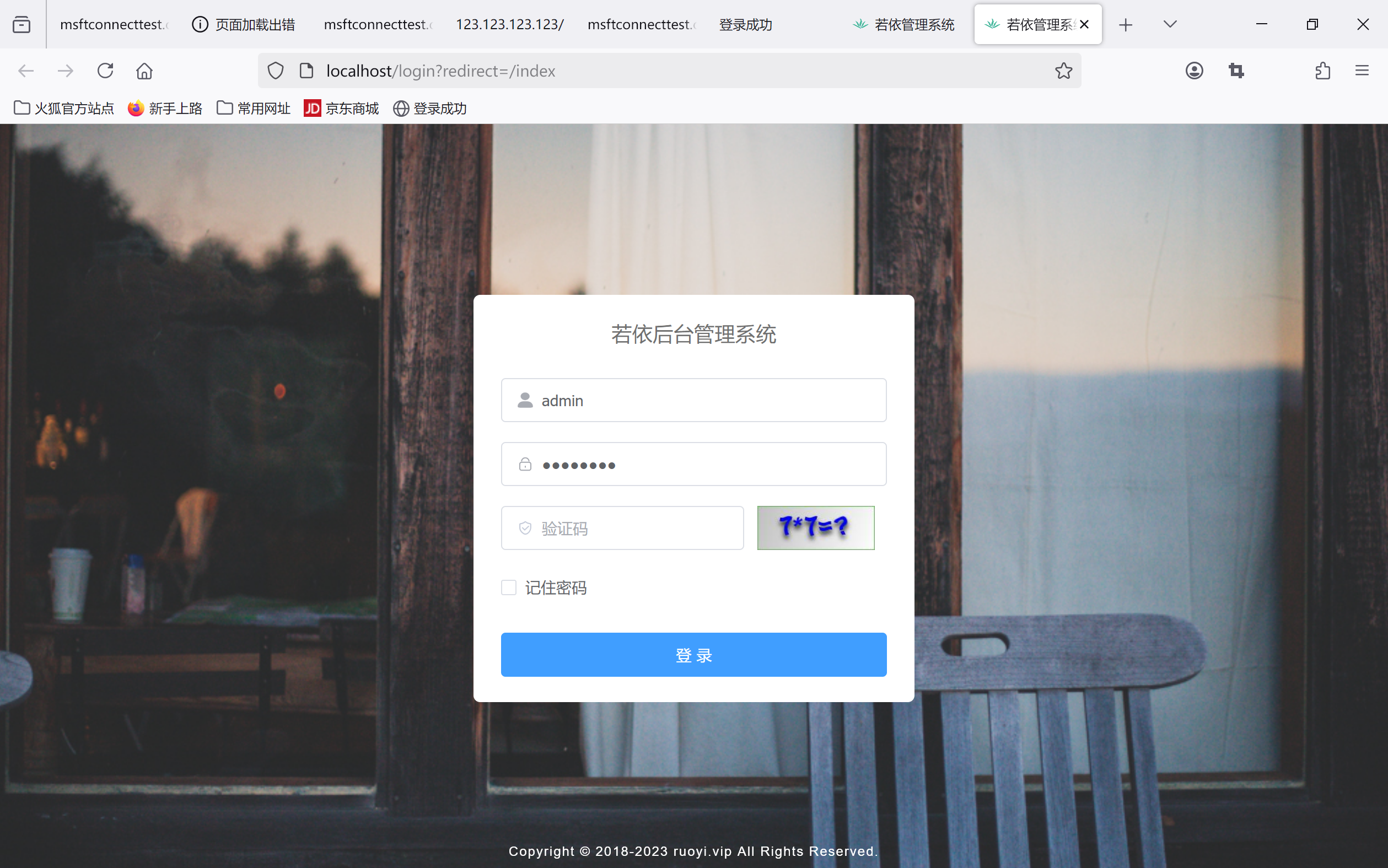
若依 前后端部署
后端:直接把代码从gitee上拉去到本地目录 (https://gitee.com/y_project/RuoYi-Vue ) 注意下redis连接时password改auth 后端启动成功 前端:运行前首先确保安装了node环境,随后执行: !!一定要用管理员权限…...
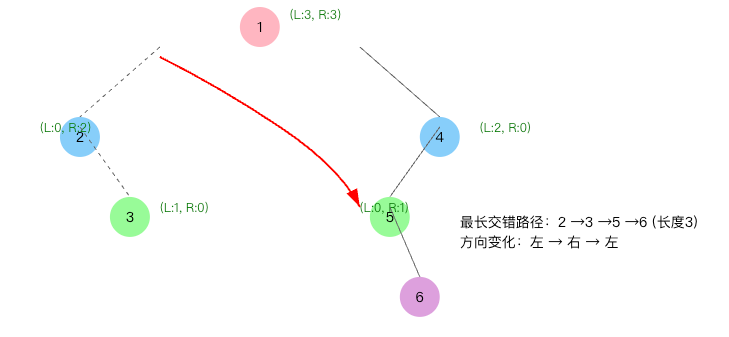
LeetCode算法题(Go语言实现)_37
题目 给你一棵以 root 为根的二叉树,二叉树中的交错路径定义如下: 选择二叉树中 任意 节点和一个方向(左或者右)。 如果前进方向为右,那么移动到当前节点的的右子节点,否则移动到它的左子节点。 改变前进方…...

网络3 子网掩码 划分ip地址
1.根据子网掩码判断主机数 IP地址网络位主机位 核心:将主机位划分为子网位和主机位 疑问:子网位有什么作用 子网掩码:网络位全为1,主机位全为0 主机数2^主机位 -2 2.根据主机和子网判断子网掩码 有一个B类网络145.38.0.0需要划…...
使用 react-three-fiber 快速重构 Three.js 场景⚛️
不明白的知识先放在一边,激发兴趣是第一步,所以不必纠结代码的细节,相信我你很快就会爱上这种感觉!!! 今天,我们将更进一步,将上一篇中vite npm传统 Three.js 原生代码完整 重构为 …...
RT-Thread 屏蔽在线软件包的方法
说明 可能大家对 RT-Thread 的 Kconfig 配置项,Scons 构建有些疑惑,其实 BSP 的 Kconfig 可以自由的配置,目录也可以自由的调整 RT-Thread BSP 默认都有在线软件包的配置项,如果你不需要在线软件包,也可以把这个配置项…...

深入理解Java反射
反射(Reflection)是Java语言的一个强大特性,它允许程序在运行时动态地获取类的信息并操作类或对象的属性、方法和构造器。就是在获取运行时的java字节码文件,通过各种方法去创建对象,反射是Java被视为动态语言的关键特性之一。 反射其实就是…...
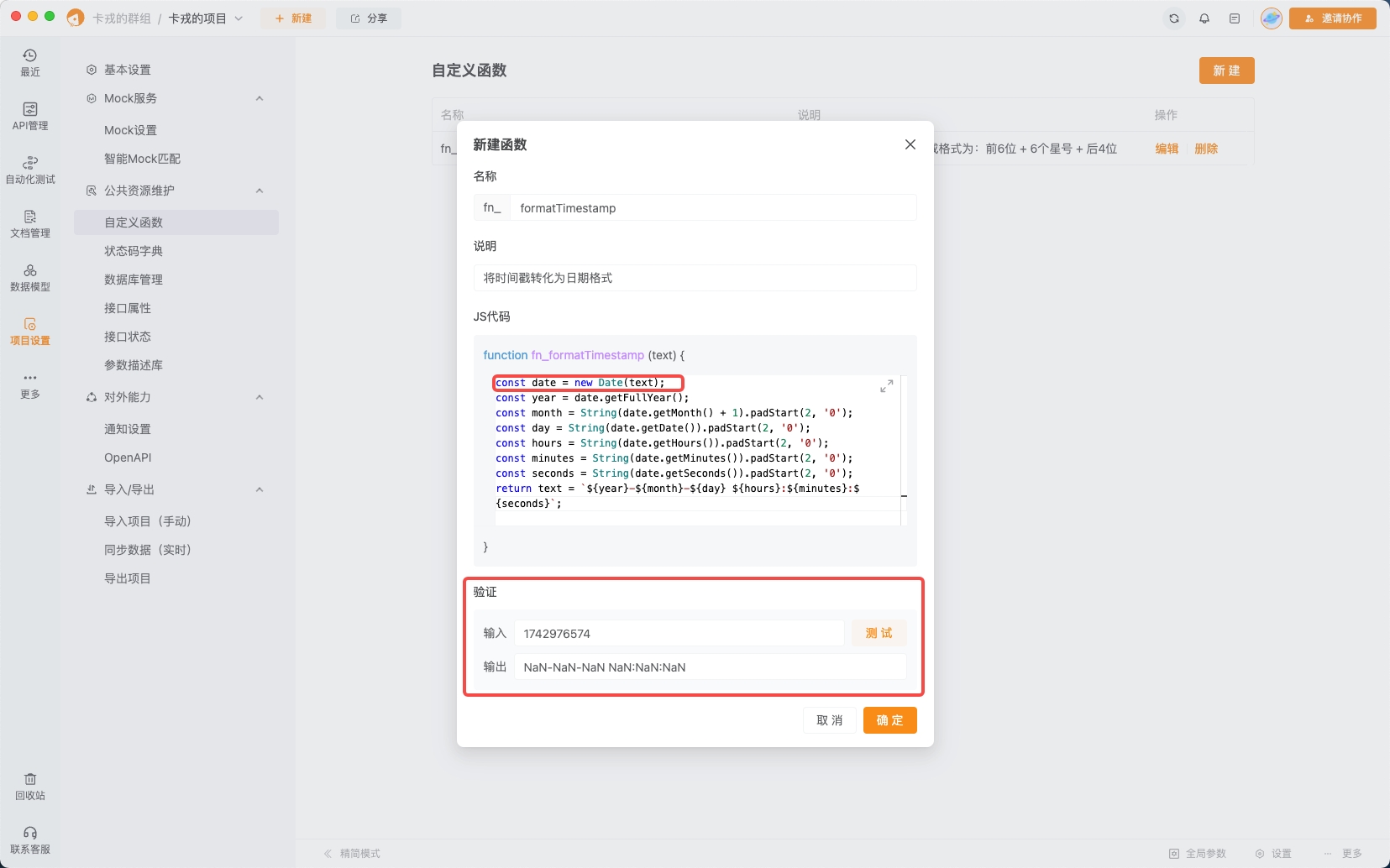
Apipost自定义函数深度实战:灵活处理参数值秘籍
在开发过程中,为了更好地处理传递给接口的参数值,解决在调试过程中的数据处理问题,我们经常需要用到函数处理数据。 过去,我们通过预执行脚本来处理数据,先添加脚本,然后将处理后的结果再赋值给请求参数。…...

对重大保险风险测试的算法理解
今天与同事聊到重大保险风险测试,借助下面链接的文章, 谈IFRS 17下的重大保险风险测试 - 知乎 谈一下对下图这个公式的理解。 尤其是当看到下面这段文字的解释时,感觉有些算法上的东西,需要再澄清一些。 首先,上面文…...

如何白嫖Grok3 API? 如何使用Grok3 API调用实例?怎么使用Grok3模型?
前段时间,Grok3(想要体验Grok3的童鞋可以参考本文:Grok 上线角色扮演功能,教你课后作业手到擒来,Grok3使用次数限制?如何使用Grok3? Grok3国内支付手段如何订阅升级Premium - AI is all your need!&#x…...

学习Python的优势体现在哪些方面?
文章目录 前言易于学习和使用应用领域广泛丰富的开源库和社区支持跨平台兼容性职业发展前景好 前言 学习 Python 具有多方面的优势,这使得它成为当今最受欢迎的编程语言之一,以下为你详细介绍。 易于学习和使用 语法简洁易懂:Python 的语法…...

icoding题解排序
数组合并 假设有 n 个长度为 k 的已排好序(升序)的数组,请设计数据结构和算法,将这 n 个数组合并到一个数组,且各元素按升序排列。即实现函数: void merge_arrays(const int* arr, int n, int k, int* out…...
)
LangChain-检索系统 (Retrieval)
检索系统 (Retrieval) 检索系统是LangChain的核心组件之一,它提供了从各种数据源获取相关信息的能力,是构建知识增强型应用的基础。本文档详细介绍LangChain检索系统的组件、工作原理和最佳实践。 概述 检索系统解决了大型语言模型知识有限和过时的问…...

Fast网络速度测试工具
目录 网站简介 功能特点 测试过程 为什么使用Fast 如果网络速度不达标 网站简介 Fast是一个由Netflix提供的网络速度测试工具,主要用来测试用户的互联网下载速度。它以其简洁的界面和快速的测试过程而受到用户的欢迎。 功能特点 下载速度测试:这是…...
ubuntu20.04在mid360部署direct_lidar_odometry(DLO)
editor:1034Robotics-yy time:2025.4.10 1.下载DLO,mid360需要的一些...: 1.1 在工作空间/src下 下载DLO: git clone https://github.com/vectr-ucla/direct_lidar_odometry 1.2 在工作空间/src下 下载livox_ros_driver2&…...
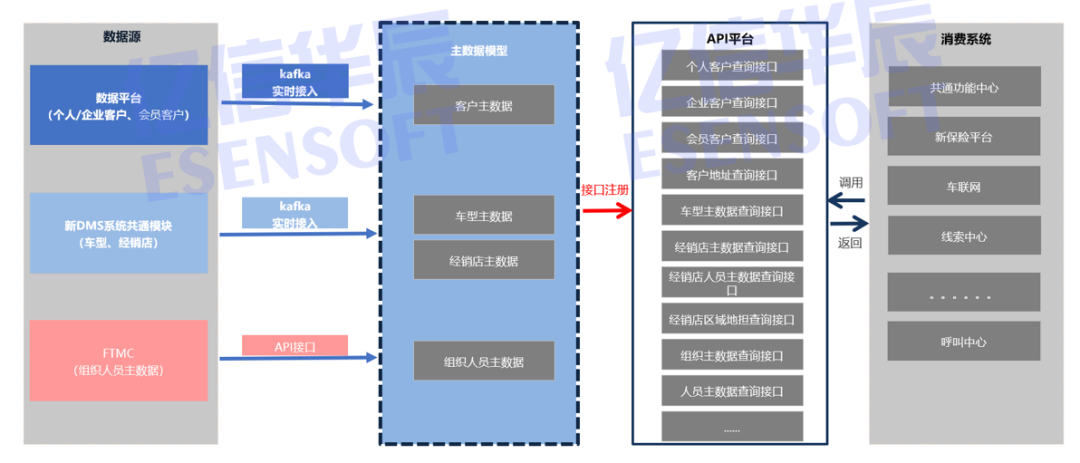
制造企业数据治理体系搭建与业务赋能实践
当下制造企业正面临着前所未有的机遇与挑战,从多环节业务协同的复杂性,到海量数据资源的沉睡与孤岛化;从个性化定制需求的爆发,到供应链效率优化的迫切性——如何通过数据治理将“数据包袱”转化为“数据资产”,已成为…...

java基础多态------面试八股文
是什么是多态 类引用指向子类对象,并调用子类重写的方法,实现不同的行为 例子 class Animal {void sound() {System.out.println("动物发出声音");} }class Dog extends Animal {Overridevoid sound() {System.out.println("狗叫&…...

【LunarVim】解决which-key 自定义键位注册不成功问题
问题描述 LunarVim将which-key设置放在一个keymaps.lua中,然后config.lua调用reload “user.keymaps”,键位没用注册成功,而直接写在config.lua中,就注册成功 这暴露了LunarVim 插件和配置加载顺序的一些细节坑,下面解…...
开源推荐#5:CloudFlare-ImgBed — 基于 CloudFlare Pages 的开源免费文件托管解决方案
大家好,我是 jonssonyan。 寻找一个稳定、快速、还最好是免费或成本极低的图床服务,一直是许多开发者、博主和内容创作者的痛点。公共图床可能说关就关,付费服务又增加成本。现在,一个名为 CloudFlare-ImgBed 的开源项目…...
算法训练之动态规划(三)
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨ 个…...