各种排序思路及实现
目录
- 1.排序
- 概念
- 常见的排序算法
- 2.常见排序算法实现
- (1)插入排序
- 直接插入排序
- 希尔排序(缩小增量排序)
- (2)选择排序
- 直接选择排序
- 堆排序
- (3)交换排序
- 冒泡排序
- 快速排序(hoare版)
- 快速排序优化
- 快速排序(非递归实现)
- (4)归并排序
- 非递归版本的归并排序
- 归并排序的好处
1.排序
概念
排序就是让一串记录按照某个规定,递增或递减的排列起来的操作
稳定性:稳定性就是在排序前后,两个相同元素的下标前后关系保持不变,如 arr[ i ] ==arr [ j ] , i < j ,排序完成之后这两元素的下标还是前面的小于后面的 , 就称为稳定排序,否则就是不稳定排序
如果出现大范围排序,跳跃交换元素,一般就是不稳定排序
内部排序:数据元素全部放在内存中的排序
外部排序:数据元素太多不能放在内存中,根据排序过程的要求不断的在内外存之间移动数据的排序
内存和外存(硬盘)的区别
1.内存的访问速度比硬盘(外存)快
2.内存的存储空间比硬盘(外存)小
3.内存上的数据断电后就消失了
硬盘的数据断电后还在,能持久的存储数据
常见的排序算法
2.常见排序算法实现
(1)插入排序
直接插入排序
类似于往顺序表中间位置插入元素
该排序是稳定排序
排序方式:
给定一个数组,把这个数组分为两个区间
1.有序区间(已排序区间)
2.无序区间(待排序区间)
初始情况下,该数组是未经排序的,此时认为有序区间是空区间,无序区间是整个数组
每次选择无序区间的一个元素,就把这个元素插入到有序区间的合适位置上(如果前一个比待插入元素大,就交换两元素位置,没有则停止),有序区间扩大一位,无序区间缩小一位,直到无序区间大小为0
时间复杂度:O(N2)
空间复杂度:O(1)
实现:
//实现插入排序private static void insertSort(int[] arr){//每次取出循环的第一个元素插入有序区间//整个循环N-1次//bound就是边界,分出有序和无序区间//有序区间[0,bound)//无序区间[bound,arr.length)for (int bound=1;bound<arr.length;bound++){int val=arr[bound];int cur=bound-1;for (;cur>=0;cur--){if(arr[cur]>val){//如果前面元素比后面大,把前面元素搬运到后面arr[cur+1]=arr[cur];}else break;//找到了要插入的位置,此时cur减了1}arr[cur+1]=val;//完成插入}}
测试一下:
public static void main(String[] args) {int[] arr={9,5,2,7};insertSort(arr);System.out.println(Arrays.toString(arr));}

希尔排序(缩小增量排序)
时间复杂度:O(log n)
最坏情况下:O(N2) => 平均复杂度:O (N1.5)
空间复杂度:O(1)
稳定性:不稳定排序
排序原理:分组进行插入排序
1.先把整个数组分成若干组,在针对每一组分别进行插入排序
引入了gap(间隙)的概念
假设gap为3,每隔三个就是一个组的元素(下图相同下标颜色即为一个组)

希尔排序不是值进行一次,而是要进行若干次的
插排完成后,依次把 gap 设置更小,直到变成 1 为止
希尔排序的好处:
普通的插入排序:
1.如果要排序的数组很短,整体效率就高
2.如果排序的数组基本有序了,整体效率也很高
希尔排序就结合了普通插入排序的两个优势, Gap值大时组长度小,Gap值小时数组相对有序,因此效率更高
实现:
//分组进行插入排序//根据gap值把整个数组分成多个组,针对每个组进行插入排序//此处把gap设为 size/2, size/4 ,size/8....1public static void shellSort(int[] arr){int gap=arr.length/2;while (gap>=1){insertShellSort(arr,gap);//分组插排gap/=2;//逐渐把gap值缩小}}public static void insertShellSort(int[] arr,int gap){for (int bound=gap;bound<arr.length;bound++){//针对每个组第1,2,3.。个元素排序int val=arr[bound];int cur=bound-gap;for (;cur>=0;cur-=gap){//分别对组排序if(arr[cur]>val){arr[cur+gap]=arr[cur];//后移元素(为插入元素挪位置)}else break;//找到了}arr[cur+gap]=val;}}
测试:
public static void main(String[] args) {int[] arr={9,5,2,7};//insertSort(arr);shellSort(arr);System.out.println(Arrays.toString(arr));}

虽然希尔排序效率比普通插入排序高,但还是比不上后面的一些排序算法
(2)选择排序
直接选择排序
时间复杂度:O(N2)
空间复杂度:O(1)
稳定性:不稳定排序
原理:
把整个数组划分成两个部分,前面是有序区间,后面是无序区间
初始情况下,有序区间是空区间
从无序区间中找到最小值(打擂台,以待排序区间的第一个元素位置作为“擂台”,拿后续每个元素都和擂台的元素比较,如果比擂台元素小就交换),把这个值放到无序区间的第一个位置
再把无序区间的第一个元素划分到有序区间,重复上述过程直到无序区间长度为0
实现:
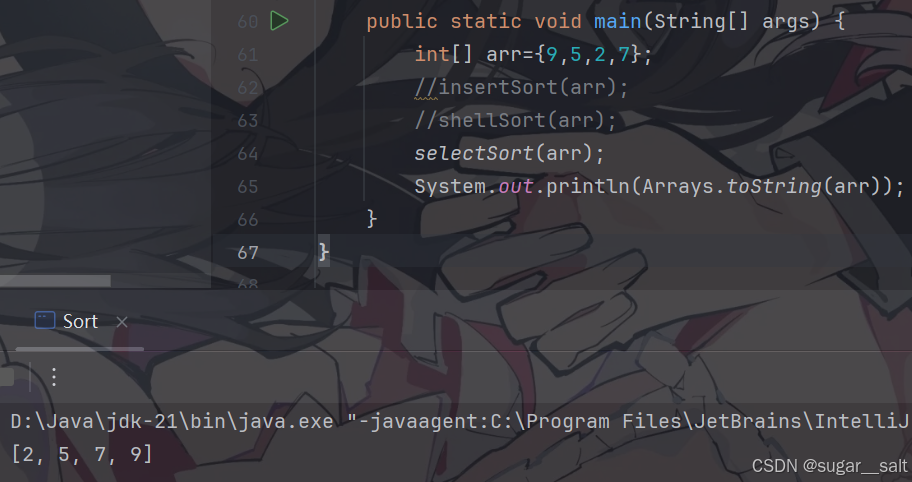
//直接选择排序public static void selectSort(int[] arr){//bound为边界,界定有序和无序区间for(int bound=0;bound<arr.length-1;bound++){for (int cur=bound+1;cur<arr.length;cur++){//cur表示要打擂台的元素位置if(arr[cur]<arr[bound]){//打擂台成功int t=arr[cur];arr[cur]=arr[bound];arr[bound]=t;}}}}
测试运行:
堆排序
时间复杂度:O(NlogN)
空间复杂度:O(1)
稳定性:不稳定排序
堆排序比直接选择排序效率更高,甚至比前面所有排序算法的时间复杂度都低
前面选择排序是已排序在前面,待排序在后面,而堆排序想法,是已排序在后面,待排序在前面
如果要升序排序,就要建立大堆,根据堆顶元素最大的性质,把最大元素放到最后再向下调整,循环往复,直到待排序区间为0
设父节点下标为 i ,左子树下标2i +1,右子树下标2i+2
因为堆的父子下标关系有一个前提,根节点下标是0,所以前半部分不能是已排序区间
堆排序基本思路:
1.针对整个数组建立大堆,初始情况下整个去加都是待排序区间
2.把堆顶(最大元素)和最后一个元素位置交换,无序区间右区间减少一位
3.进行一次向下调整,重回大堆状态
4.重复上述过程,直到无序区间为0
实现:
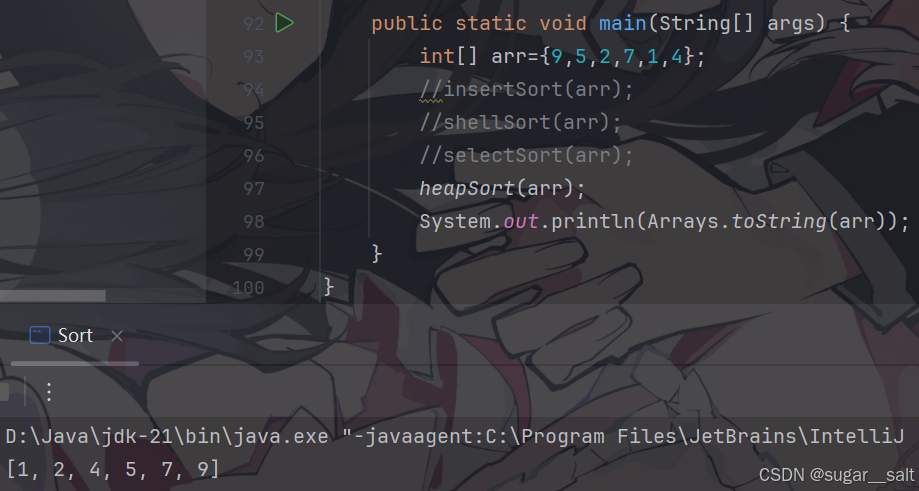
public static void heapSort(int[] arr){createHeap(arr);for (int bound=arr.length-1;bound>=0;bound--){int t=arr[0];arr[0]=arr[bound];arr[bound]=t;shiftDown(arr,bound,0);}}public static void shiftDown(int[] arr,int length,int index){int parent=index;int child=2*parent+1;while (child<length){if(child+1<length && arr[child+1]>arr[child]){child++;}if(arr[child]>arr[parent]){int t=arr[child];arr[child]=arr[parent];arr[parent]=t;}else break;//调整完成parent=child;child=2*parent+1;}}public static void createHeap(int[] arr){for (int i=(arr.length-1-1)/2;i>=0;i--){shiftDown(arr,arr.length,i);}}
测试:
(3)交换排序
冒泡排序
时间复杂度:O(N2)
空间复杂度:O(1)
稳定性:稳定
原理:
比较交换相邻元素
一趟下来就能把最大值放到最后(或从后往前遍历,把最小值放到最前)
实现:
//从后往前遍历实现public static void bubbleSort(int[] arr){for (int i=0;i<arr.length-1;i++){for (int j=arr.length-1;j>i;j--){if(arr[j]<arr[j-1]){int t=arr[j];arr[j]=arr[j-1];arr[j-1]=t;}}}}
快速排序(hoare版)
时间复杂度:最坏情况 [ 待排序序列是反序的 ] 下是O(N2),平均时间复杂度是O(NlogN)
空间复杂度:最坏情况下是O(N),平均是O(logN) ---->因为递归会额外消耗空间
稳定性:不稳定排序
理解分治思想:即把一个大问题拆分成许多个小问题,然后慢慢解决小问题,从而将大问题解决
分治最理想的情况:分出来的左右区间长度差不多
快速排序思想(这里选择最右侧为基准值):
给定一个待排序数组,从数组中选择一个 “ 基准值 ”
拿着数组中的每个元素和基准值比较,把该数组分成三个部分
左侧:比基准值小的元素
中间:基准值
右侧:比基准值大的元素
然后对左右侧递归,重复上述过程(取基准值,分区间),直到区间只有三个或两个元素,排序完成
.
基准值分数组步骤:
1.选定数组最右侧元素为基准值,记录最左侧下标 i 和最右侧下标 j
2.先从左侧找比基准值大的元素(没找到则 i++),再从右侧下标找比基准值小的元素(没找到则 j - - )
第二步会出现两种情况
<1> 左右两侧都找到了元素,就交换两下标位置的元素,然后继续重复第二步
<2> 两下标位置重合,证明找完了(此时因为先从左侧找比基准值大的元素,所以该下标位置元素的值一定比基准值大),把基准值和该下标元素交换
快速排序的基准值也可以选最左侧元素作为基准值,此时要调整思路:
要先从右往左找比基准值小的元素,再从左往右找比基准值大的元素
选取区间最右侧元素作为基准值,代码实现:
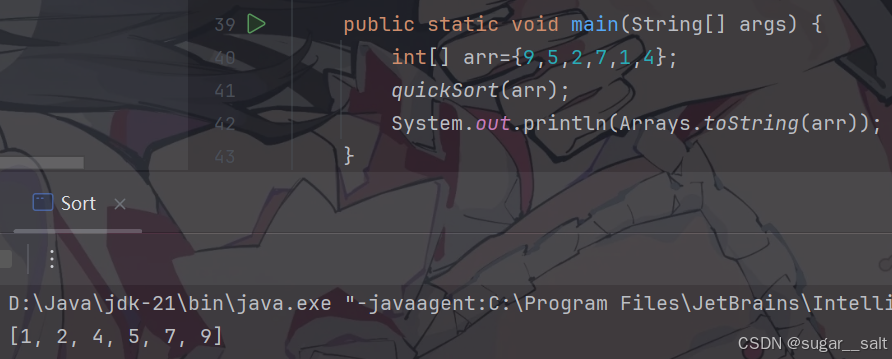
//快速查找,设置基准值为最右侧元素private static void quickSort(int[] arr){quickSort(arr,0,arr.length-1);}//规定区间为[left,right]private static void quickSort(int[] arr,int left,int right){//实现递归if(left>=right) return;int index=partition(arr, left, right);//对区间进行调整,返回调整后基准值下标实现递归quickSort(arr,left,index-1);//对左区间递归调整quickSort(arr,index+1,right);//对右区间递归调整}private static int partition(int[] arr,int left,int right){int l=left;int r=right;while (l<r){while (l<r && arr[right]>arr[l]){//先从左往右找比基准值大的元素l++;}while (l<r && arr[r]>arr[right]){r--;}//两边都找到了,进行交换(就算下标重合交换也没事)swap(arr,l,r);}//最后交换基准值和重合位置元素swap(arr,l,right);return l;//返回基准值下标位置}private static void swap(int[] arr,int left,int right){//交换两元素int t=arr[left];arr[left]=arr[right];arr[right]=t;}
测试:
快速排序优化
1.为了避免反序效率低的极端情况,使用“三数取中” 的策略,即取出数组最左侧,最右侧,中间位置元素,比较三个数的大小,取中间值,再把这个中间值移到 最左侧 / 最右侧,方便后续交换操作
2.当递归到一定程度,每个区间比较小的时候,继续递归依然会消耗很多空间
此时在区间比较小的时候用插入排序速度更快
3.如果是特别大的数组,当地贵到一定深度时,此时区间长度还是比较大,可以使用堆排序对区间进行调整,而非继续递归
快速排序(非递归实现)
思路和上面快速排序一样,只是递归改为用栈模拟实现
static class Range{//保存左右区间int left;int right;public Range(int left, int right) {this.left = left;this.right = right;}}private static void quickSortByStack(int[] arr){Stack<Range> stack=new Stack<>();stack.push(new Range(0,arr.length-1));while (!stack.isEmpty()){Range range=stack.pop();if(range.left>=range.right){continue;}int index=partition(arr,range.left,range.right);stack.push(new Range(range.left,index-1));//向左区间调整stack.push(new Range(index+1,range.right));//向右区间调整}}private static int partition(int[] arr,int left,int right){//就是之前的partitiong方法int l=left;int r=right;while (l<r){while (l<r && arr[right]>arr[l]){//先从左往右找比基准值大的元素l++;}while (l<r && arr[r]>arr[right]){r--;}//两边都找到了,进行交换(就算下标重合交换也没事)swap(arr,l,r);}//最后交换基准值和重合位置元素swap(arr,l,right);return l;//返回基准值下标位置}
(4)归并排序
时间复杂度:O(NlogN)------>和logN相关
空间复杂度:O(N)
递归的空间复杂度:O(logN) ------->分区间是均匀的
由于合并数组要创建临时数组,所以整体复杂度为O(N)
稳定性:稳定排序
它也体现了分治思想
思路:
先把一个无序的数组拆分,如:
假设数组长度为N,先把这些数组对半拆,一直拆到每个区间长度为1,即只有一个元素
再两两合并数组,此时就是有序的数组了,一直合并直到整个区间长度为N
模拟实现:
private static void mergeSort(int[] arr){mergeSort(arr,0,arr.length-1);//递归分区间}private static void mergeSort(int[] arr,int left,int right){//递归取得区间if(left>=right) return;int mid=(left+right)/2;//取得要分开的下标mergeSort(arr,left,mid);//左半区间递归mergeSort(arr,mid+1,right);//右半区间递归//递归完了,对两个区间进行调整merge(arr,left,mid,right);//合并区间}private static void merge(int[] arr,int left,int mid,int right){int[] newArr=new int[right-left+1];int resultSize=0;//记录位置int cur1=left;int cur2=mid+1;while (cur1<=mid && cur2<=right){//模拟顺序表合并if(arr[cur1]<=arr[cur2]){//稳定性取决于这个,两者相等取左边newArr[resultSize++]=arr[cur1];cur1++;}else{newArr[resultSize++]=arr[cur2];cur2++;}}while (cur1<=mid)newArr[resultSize++]=arr[cur1++];while (cur2<=right)newArr[resultSize++]=arr[cur2++];for(int i=0;i<resultSize;i++){//把临时数组的元素放到原数组中arr[left+i]=newArr[i];}}
归并排序与快速排序比较
1.快速排序:平均效率高,但是可能会出现极端情况,使得效率变低(发挥不稳定,忽高忽低)
2.归并排序:平均效率高,而且不存在极端最坏情况(发挥很稳定)
两者相较,归并排序更优
非递归版本的归并排序
时间复杂度和空间复杂度与前面的一致
思路:
数组从小区间开始合并,然后区间长度逐渐增大
实现:
//非递归版本归并排序private static void mergeSortByLoop(int[] arr){for(int size=1;size<arr.length;size*=2){//数组区间长度for(int i=0;i<arr.length;i+=size*2){//对每个小区间合并//左区间[i,i+size] 右区间[i+size+1,i+size*2-1]int left=i;int mid=i+size;if(mid>arr.length-1){//避免超出范围mid=arr.length-1;}int right=i+size*2-1;if(right>arr.length-1){//避免超出范围right=arr.length-1;}merge(arr,left,mid,right);}}}private static void merge(int[] arr,int left,int mid,int right){//和上面的的方法是一样的int[] newArr=new int[right-left+1];int resultSize=0;//记录位置int cur1=left;int cur2=mid+1;while (cur1<=mid && cur2<=right){//模拟顺序表合并if(arr[cur1]<=arr[cur2]){newArr[resultSize++]=arr[cur1];cur1++;}else{newArr[resultSize++]=arr[cur2];cur2++;}}while (cur1<=mid)newArr[resultSize++]=arr[cur1++];while (cur2<=right)newArr[resultSize++]=arr[cur2++];for(int i=0;i<resultSize;i++){//把临时数组的元素放到原数组中arr[left+i]=newArr[i];}}
归并排序的好处
1.归并排序是可以针对链表进行排序的
堆排序/快速排序 (依赖下标)虽然效率都很高,但是只能针对数组,不能针对链表
归并排序是链表的高效排序的做法
2.归并排序,对于海量数据(数据太多,内存无法同时保存下),也是能够处理的
其他排序都要求所有数据必须同时在内存中才可以进行
例如有1000G的数据要排序,归并排序会先把1000GB拆分成1000个1GB,分别对1GB排序,再把这些数据合并
上述排序算法中,实用的排序
堆排序,快速排序,归并排序
相关文章:
各种排序思路及实现
目录 1.排序概念常见的排序算法 2.常见排序算法实现(1)插入排序直接插入排序希尔排序(缩小增量排序) (2)选择排序直接选择排序堆排序 (3)交换排序冒泡排序快速排序(hoare…...

golang 采用use-go/onvif获取RTSP流
采用https://github.com/use-go/onvif得到完整的RTSP流的地址 全局变量UseGoMain 函数GetDeviceInformation 函数GetRTSPUri 函数 全局变量 这些变量用来设定 ONVIF 设备的连接信息,包含设备地址、用户名和密码 var deviceXaddr "*92.1*8.11*.12*:80" …...

虚幻基础:碰撞帧运算
能帮到你的话,就给个赞吧 😘 文章目录 碰撞碰撞盒线段检测 帧运算:每个程序流就是一帧的计算结果速度过快时(10000),导致每帧移动过大(83),从而导致碰撞盒错过而没有碰撞速度快的碰撞要用线段检测 碰撞 碰撞盒 线段检…...
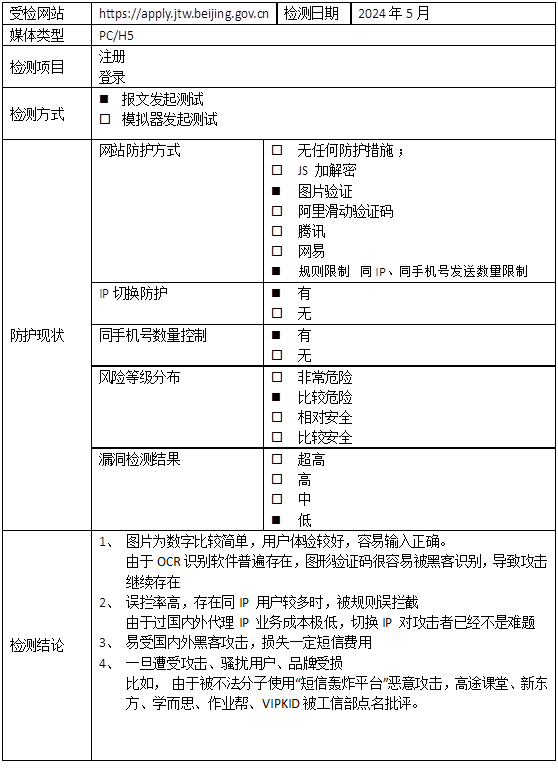
【北京市小客车调控网站-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

西湖大学团队开源SaProt等多款蛋白质语言模型,覆盖结构功能预测/跨模态信息搜索/氨基酸序列设计等
2025 年 3 月 22—23 日,上海交通大学「AI 蛋白质设计峰会」正式举行。 本次峰会汇聚了来自清华大学、北京大学、复旦大学、浙江大学、厦门大学等知名高校的 300 多位专家学者,以及 200 余位行业领军企业代表和技术研发人员,深入探讨了 AI 在…...

算法--递归实现【DFS】
题目:指数型枚举 从 1∼n这 n 个整数中随机选取任意多个,输出所有可能的选择方案。 输入格式 输入一个整数 n。 输出格式 每行输出一种方案。 同一行内的数必须升序排列,相邻两个数用恰好 11 个空格隔开。 对于没有选任何数的方案,…...
一个批量文件Dos2Unix程序(Microsoft Store,开源)
这个程序可以把整个目录的文本文件改成UNIX格式,源码是用C#写的。 目录 一、从Microsoft Store安装 二、从github获取源码 三、功能介绍 3.1 运行 3.2 浏览 3.3 转换 3.4 转换(无列表) 3.5 取消 3.6 帮助 四、源码解读 五、讨论和…...

无法读取库伦值文件节点解决方案
读取库伦值的目的是为了换算成电流,量化场景功耗用途 1.报错日志 /power_log/debuglogger$ adb shell dmesg | grep -Ei "avc..system_server"[ 79.942272] logd.auditd: type1400 audit(1744279324.832:7149): avc: denied { read } for comm"…...
Linux系统学习Day2——在Linux系统中开发OpenCV
一、OpenCV简介 OpenCV(Open Source Computer Vision Library)是一个开源的跨平台计算机视觉和机器学习库,广泛应用于图像处理、视频分析、物体检测等领域。它提供了丰富的算法和高效的工具集,支持C、Python等多种语言,…...
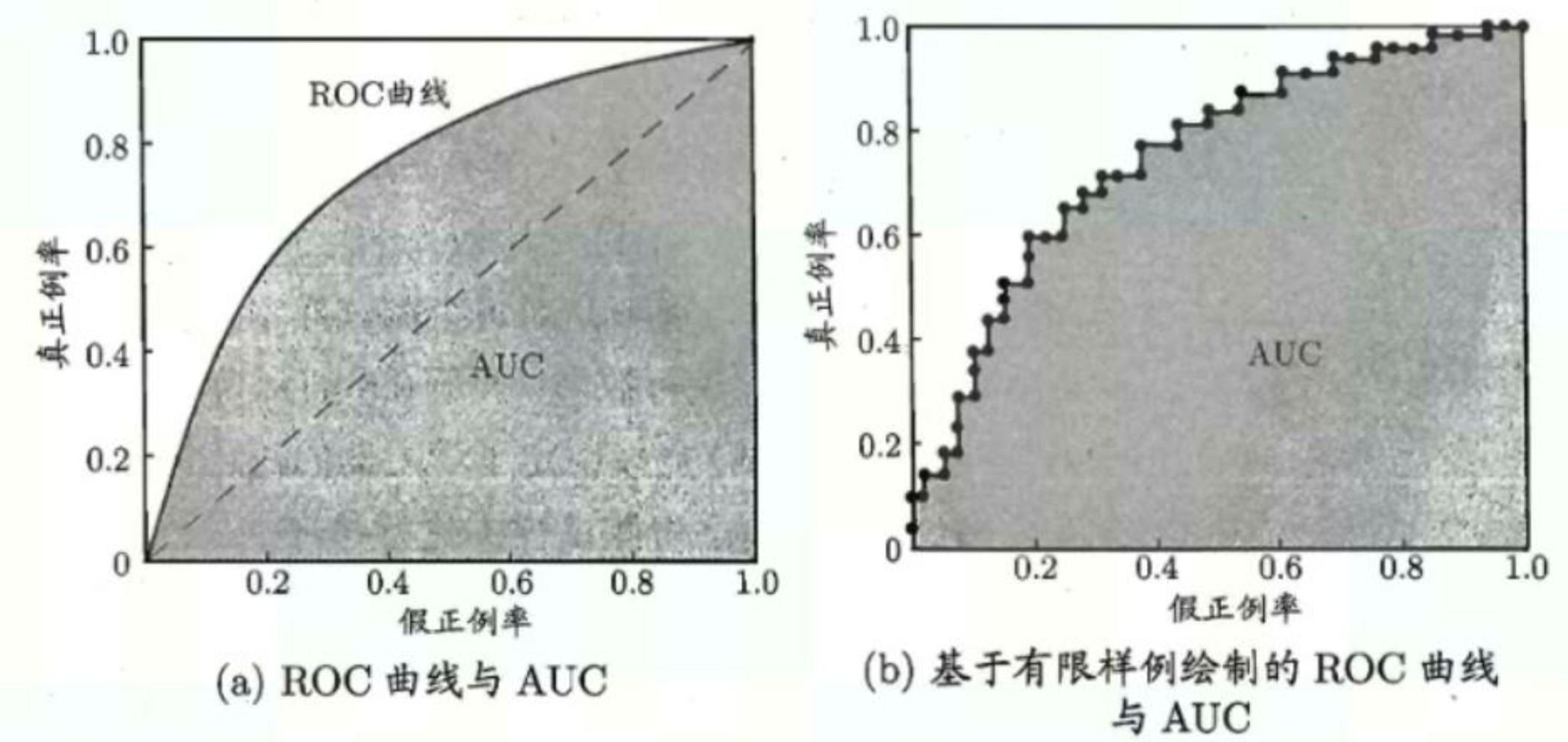
【图像分类】【深度学习】图像分类评价指标
【图像分类】【深度学习】图像分类评价指标 文章目录 【图像分类】【深度学习】图像分类评价指标前言二分类评价指标Accuracy(准确率/精度)Precision(精确率/查准率)Recall(召回率/查全率)F1-ScoreAUC-ROC曲线(Area Under the Curv-Receiver Operating Characteristic Curve)二…...

一组可能的机器学习问题列表
线性回归与多项式拟合的关系最小二乘法在机器学习中的应用梯度下降是如何实现的贝叶斯分类器的应用场景高斯分布与判定在哪里用到模型的评估有哪些参数误差中的偏差和方差定义训练集分组的快捷方式如何度量模型性能查准率查全率的定义roc,aux的含义正则化是什么意思k均值用来解…...
)
context上下文(一)
创建一个基础的context 使用BackGround函数,BackGround函数原型如下: func Background() Context {return backgroundCtx{} } 作用:Background 函数用于创建一个空的 context.Context 对象。 context.Background() 函数用于获取一个空的 cont…...
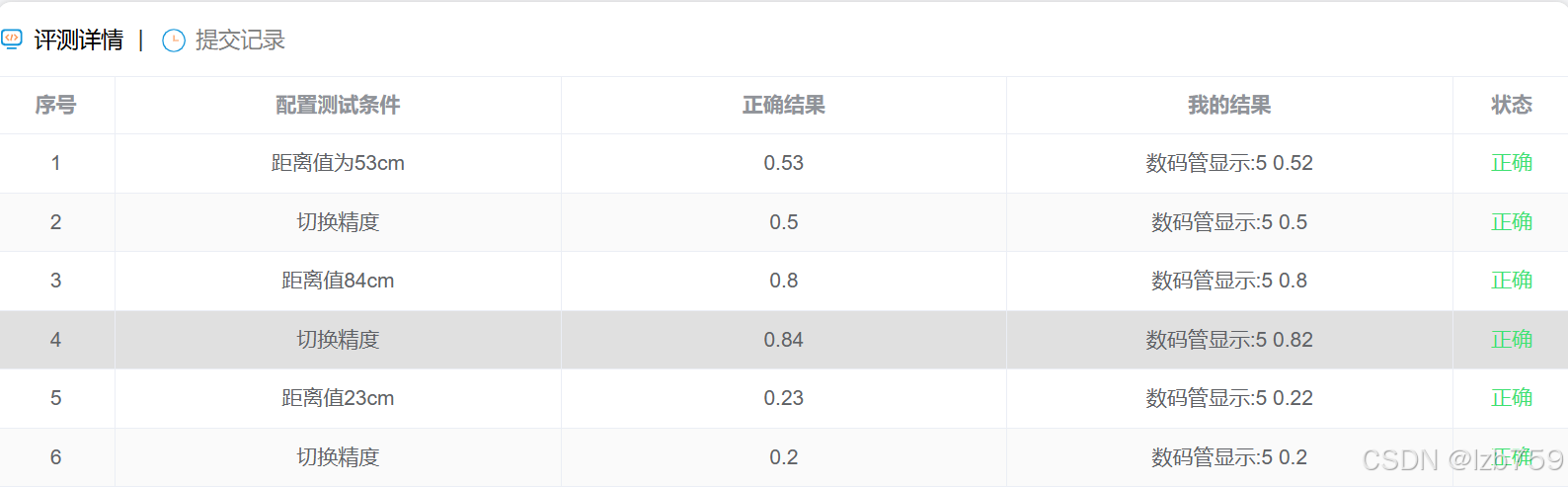
蓝桥杯单片机刷题——按键控制距离显示精度
设计要求 驱动超声波传感器,启动距离测量功能,并将其结果显示到数码管上,距离数据单位为m。 按键“S4”定义为“切换”按键,通过此按键切换距离的显示精度(一位或两位小数)。切换顺序如图所示。 数码管显示格式如下图…...
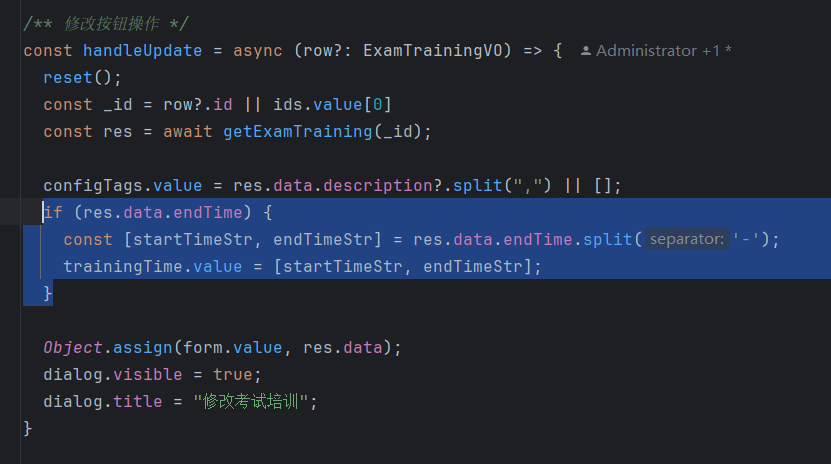
el-time-picker标签的使用
需求: 实现培训日期,用户可以选择某一天的日期,这个比较简单 <el-form-item label"培训日期" prop"startTime"><el-date-picker clearablev-model"form.startTime"type"date"placeholder…...
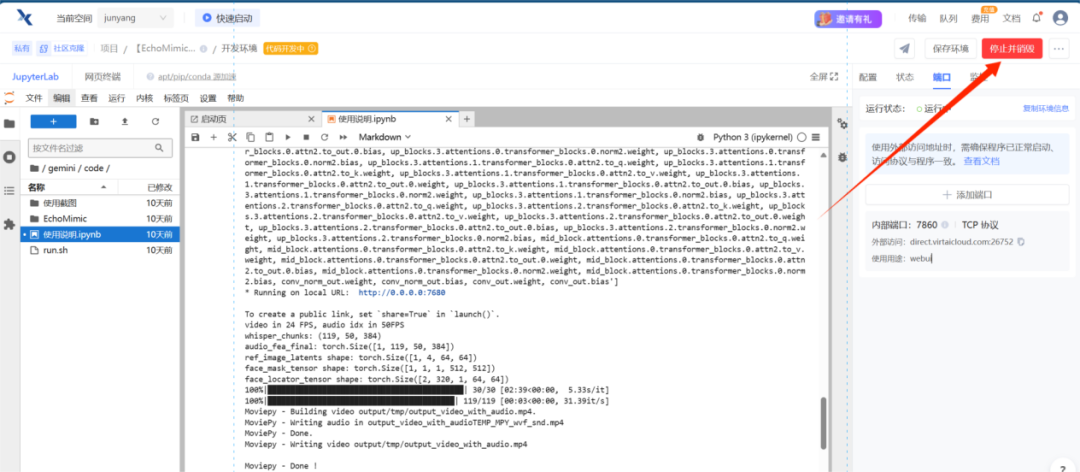
云平台一键部署【OmniGen】多功能图像生成模型(2025更新版)
OmniGen 是智源推出的一款全新的扩散模型架构,专注于统一图像生成。它简化了图像生成的复杂流程,通过一个框架处理多种任务,例如文本生成图像、图像编辑和基于视觉条件的生成等。此外,OmniGen 通过统一学习结构实现了知识迁移&…...

C/C++ 知识点:解释型语言与编译型语言
文章目录 一、解释型语言与编译型语言1、概念2、主要区别3、示例对比 一、解释型语言与编译型语言 1、概念 解释型语言 代码逐行解释执行,无需提前编译。如:Python、JavaScript、Ruby。 编译型语言 代码先编译成机器码,再直接执行。如&…...
算法训练之动态规划(四)——简单多状态问题
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨ 个…...

uniapp离线打包提示未添加videoplayer模块
uniapp中使用到video标签,但是离线打包放到安卓工程中,运行到真机中时提示如下: 解决方案: 1、把media-release.aar、weex_videoplayer-release.aar放到工程的libs目录下; 文档:https://nativesupport.dcloud.net.cn/…...

5. 蓝桥公园
题目描述 小明喜欢观景,于是今天他来到了蓝桥公园。 已知公园有 N 个景点,景点和景点之间一共有 M 条道路。小明有 Q 个观景计划,每个计划包含一个起点 stst 和一个终点 eded,表示他想从 stst 去到 eded。但是小明的体力有限&am…...

机器人零位标定修正流程介绍
如果想看运动学标定可以看看 机器人运动学参数标定, 一次性把运动学参数和零位标定等一起标定求解. 1. 零位标定 零位标定是机器人运动学标定中的一个重要步骤,其目的是校正机器人关节的初始位置误差。以下是需要进行零位标定的主要原因: 制造误差 在机…...

大疆无人机系列知识
目录 知识 开发者文档 (上云) 无人机的应用 知识 大疆行业无人机接入音视频平台协议详解_大疆无人机 视频流-CSDN博客 开发者文档 (上云) 上云API 无人机的应用 【大疆无人机地图测绘技术学习:高精度、高效率的…...
深入 C++ 线程库:从创建到同步的探索之旅
目录 创建多线程 获取线程返回值 1.传指针 2.传引用 原子操作 互斥量 互斥量(Mutex)的基本概念 mutex类型介绍 锁的类型 互斥锁(Mutex) 自旋锁(Spin Lock) 读写锁(Read - Write Lo…...
【2025年认证杯数学中国数学建模网络挑战赛】A题 解题建模过程与模型代码(基于matlab)
目录 【2025年认证杯数学建模挑战赛】A题解题建模过程与模型代码(基于matlab)A题 小行星轨迹预测解题思路第一问模型与求解第二问模型与求解 【2025年认证杯数学建模挑战赛】A题 解题建模过程与模型代码(基于matlab) A题 小行星轨…...

Rust重定义数据库内核:从内存安全到性能革命的破界之路
Rust语言正在颠覆传统数据库开发范式,其独特的所有权系统与零成本抽象能力,为攻克C/C时代遗留的内存泄漏、并发缺陷等顽疾提供全新解决方案。本文通过TiKV、Materialize等新一代数据库核心组件的实践案例,剖析Rust如何重塑存储引擎、查询优化…...
初治成人患者诊疗中的应用研究)
大模型在慢性髓细胞白血病(CML)初治成人患者诊疗中的应用研究
目录 一、引言 1.1 研究背景与意义 1.2 国内外研究现状 1.3 研究目的与内容 二、大模型技术与 CML 相关知识 2.1 大模型技术原理与特点 2.2 CML 的病理生理与诊疗现状 三、术前风险预测与手术方案制定 3.1 术前数据收集与预处理 3.2 大模型预测术前风险 3.3 根据预测…...
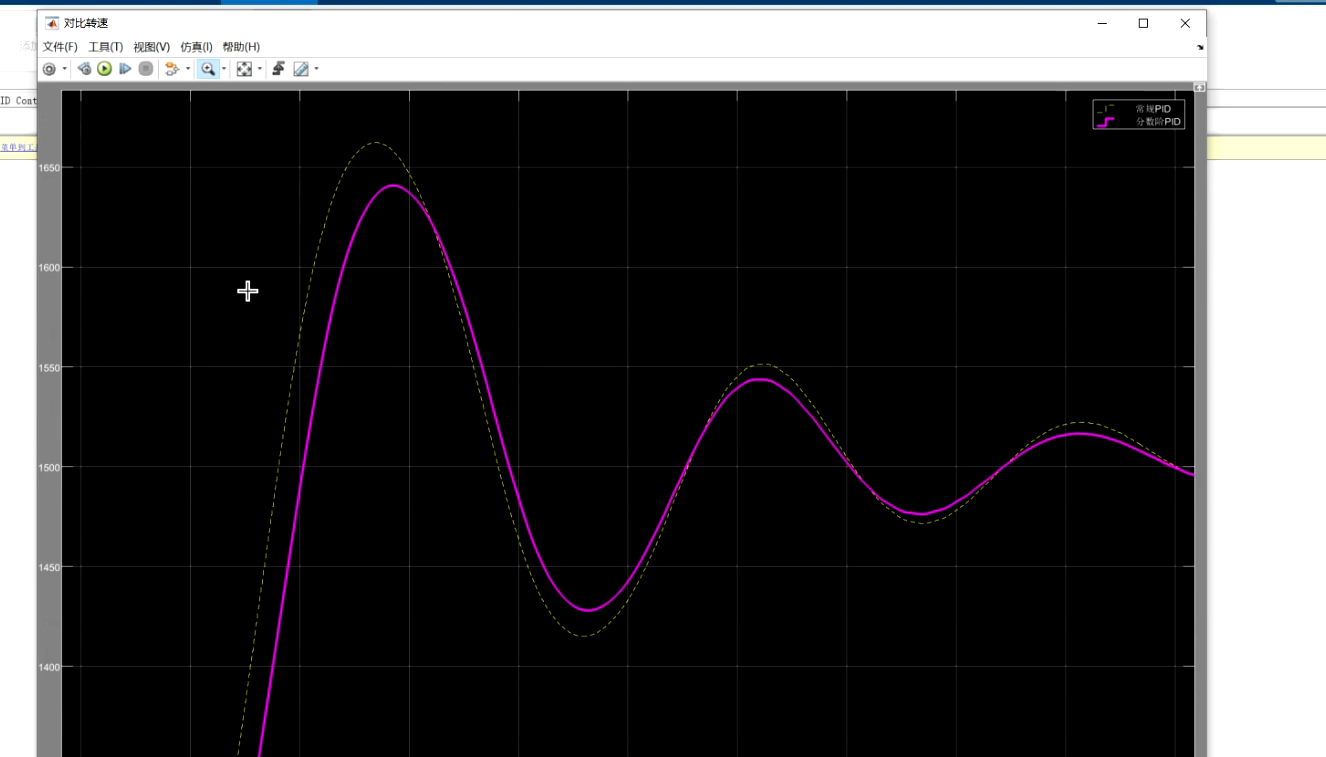
Matlab 分数阶PID控制永磁同步电机
1、内容简介 Matlab 203-分数阶PID控制永磁同步电机 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...
)
GO语言入门-反射5(结构体的Tag)
12.5 结构体的 Tag 在定义结构体类型时,可以在字段后面加上一个字符串,称为 Struct Tag。Tag 主要用来补充附加信息。 Tag 由多个 key - value 构成,并以空格来分隔,key 和 value 之间用英文的冒号分隔。其格式如下:…...

免费下载 | 2025电力数据资产管理体系白皮书
本文是一份关于2025年电力数据资产管理体系的白皮书,详细阐述了电力数据要素和数据资产管理的现状、挑战、发展进程以及电网数据资产管理体系的构建与实践。白皮书强调了数据作为生产要素的重要性,并提出了电网数据资产管理体系的创新模式,旨…...

4185 费马小定理求逆元
4185 费马小定理求逆元 ⭐️难度:简单 🌟考点:费马小定理 📖 📚 import java.util.Scanner; import java.util.Arrays;public class Main {static int[][] a;public static void main(String[] args) {Scanner sc …...

处理Excel表不等长时间序列用tsfresh提取时序特征
我原本的时间序列格式是excel表记录的,每一行是一条时间序列,时间序列不等长。 要把excel表数据读取出来之后转换成extract_features需要的格式。 1.读取excel表数据 import pandas as pd import numpy as np from tsfresh import extract_features mda…...