一周学会Pandas2 Python数据处理与分析-Pandas2数据导出
锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

任何原始格式的数据载入DataFrame后,都可以使用类似 DataFrame.to_csv()的方法输出到相应格式的文件或者目标系统里。
支持导出的格式比较多,常用的有csv,excel,sql,html等。

导出CSV文件
导出csv文件我们使用to_csv()方法,pandas2提供了丰富的参数来实现强大的导出功能,我们看下to_csv()方法的参数:
def to_csv(self,path_or_buf: FilePath | WriteBuffer[bytes] | WriteBuffer[str] | None = None,sep: str = ",",na_rep: str = "",float_format: str | Callable | None = None,columns: Sequence[Hashable] | None = None,header: bool_t | list[str] = True,index: bool_t = True,index_label: IndexLabel | None = None,mode: str = "w",encoding: str | None = None,compression: CompressionOptions = "infer",quoting: int | None = None,quotechar: str = '"',lineterminator: str | None = None,chunksize: int | None = None,date_format: str | None = None,doublequote: bool_t = True,escapechar: str | None = None,decimal: str = ".",errors: OpenFileErrors = "strict",storage_options: StorageOptions | None = None,)to_csv() 是 pandas 中用于将 DataFrame 导出为 CSV 文件的重要方法。以下是该方法的参数详解:
基本参数
-
path_or_buf (str, path object, file-like object, 默认为 None)
-
文件路径或文件对象
-
如果为 None,则返回 CSV 字符串
-
-
sep (str, 默认为 ',')
-
指定分隔符
-
例如:
sep='\t'表示制表符分隔
-
-
na_rep (str, 默认为 '')
-
缺失值表示方式
-
例如:
na_rep='NA'会将缺失值显示为 NA
-
-
float_format (str, 默认为 None)
-
浮点数格式字符串
-
例如:
float_format='%.2f'保留两位小数
-
-
columns (sequence, 可选)
-
指定要写入的列
-
例如:
columns=['col1', 'col3']
-
-
header (bool or list of str, 默认为 True)
-
是否写入列名
-
如果传入列表,则用作列名
-
-
index (bool, 默认为 True)
-
是否写入行索引
-
-
index_label (str or sequence, 默认为 None)
-
索引列的列名
-
如果传入列表且有多级索引,则为每级指定名称
-
编码与日期格式
-
encoding (str, 默认为 None)
-
编码方式
-
例如:
encoding='utf-8'或encoding='gbk'
-
-
date_format (str, 默认为 None)
-
日期格式字符串
-
例如:
date_format='%Y-%m-%d'
-
性能相关参数
-
mode (str, 默认为 'w')
-
Python 写入模式
-
'w' 表示写入,'a' 表示追加
-
-
compression (str or dict, 默认为 'infer')
-
压缩方式
-
可选: 'infer', 'gzip', 'bz2', 'zip', 'xz', None
-
-
quoting (int or csv.QUOTE_*, 默认为 csv.QUOTE_MINIMAL)
-
引用约定
-
选项:
-
csv.QUOTE_ALL (引用所有字段)
-
csv.QUOTE_MINIMAL (仅引用包含特殊字符的字段)
-
csv.QUOTE_NONNUMERIC (引用所有非数字字段)
-
csv.QUOTE_NONE (不引用)
-
-
-
quotechar (str, 默认为 '"')
-
用于引用的字符
-
-
line_terminator (str, 默认为 '\n')
-
行结束符
-
其他参数
-
chunksize (int, 默认为 None)
-
按指定行数分批写入
-
-
doublequote (bool, 默认为 True)
-
引用字段中的引号是否双写
-
-
escapechar (str, 默认为 None)
-
用于转义的字符
-
-
decimal (str, 默认为 '.')
-
小数点的字符表示
-
例如:
decimal=','用于欧洲格式
-
我们先看最简单的一个示例,用字典构造一个DataFrame对象,然后直接导出csv文件:
import pandas as pdd = {'学号': [1, 2, 3],'姓名': ['张三', '李四', '王五'],'语文': [99, 88, 77],'数学': [44, 55, 55],'英语': [88, 55, 66]}df = pd.DataFrame(d)print(df)df.to_csv('out/student.csv')我们运行看下导出的csv文件:
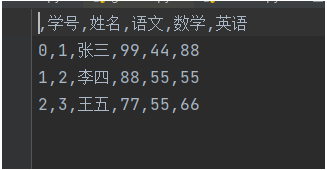
默认是有含行索引的,如果不需要的话,我们加下index=False参数:
df.to_csv('out/student2.csv', index=False) # 不需要行索引运行导出的csv文件:

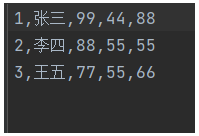
如果不需要表头,可以设置header=False
df.to_csv('out/student3.csv', index=False, header=False) # 不需要行索引,不要表头运行导出的csv文件:
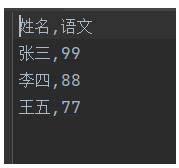
导出指定列数据,可以使用columns参数指定:
df.to_csv('out/student4.csv', index=False, columns=['姓名', '语文']) # 不需要行索引,不要表头运行导出的csv文件:
导出Excel文件
将DataFrame导出为Excel格式也很方便,使用DataFrame.to_excel方法即可。要想把DataFrame对象导出,首先要指定一个文件名,这个文件名必须以.xlsx或.xls为扩展名,生成的文件标签名也可以用sheet_name 指定。
to_excel()方法参数如下:
def to_excel(self,excel_writer: FilePath | WriteExcelBuffer | ExcelWriter,sheet_name: str = "Sheet1",na_rep: str = "",float_format: str | None = None,columns: Sequence[Hashable] | None = None,header: Sequence[Hashable] | bool_t = True,index: bool_t = True,index_label: IndexLabel | None = None,startrow: int = 0,startcol: int = 0,engine: Literal["openpyxl", "xlsxwriter"] | None = None,merge_cells: bool_t = True,inf_rep: str = "inf",freeze_panes: tuple[int, int] | None = None,storage_options: StorageOptions | None = None,engine_kwargs: dict[str, Any] | None = None,) 有个sheet_name标签名称参数,默认值是"Sheet1",其他参数使用和csv基本一致。
下面看一个示例:
import pandas as pd
d = {'学号': [1, 2, 3],'姓名': ['张三', '李四', '王五'],'语文': [99, 88, 77],'数学': [44, 55, 55],'英语': [88, 55, 66]}
df = pd.DataFrame(d)
df.to_excel('out/student.xlsx', sheet_name="我的标签页", index=False)导出的excel文件:

导出sql
将DataFrame中的数据保存到数据库的对应表中,pandas2提供了to_sql()方法,我们看下to_sql()方法的参数:
def to_sql(self,name: str,con,schema: str | None = None,if_exists: Literal["fail", "replace", "append"] = "fail",index: bool_t = True,index_label: IndexLabel | None = None,chunksize: int | None = None,dtype: DtypeArg | None = None,method: Literal["multi"] | Callable | None = None,)to_sql() 是 pandas 中用于将 DataFrame 写入 SQL 数据库的方法,支持多种关系型数据库。以下是该方法的详细参数说明:
基本参数
-
name (str)
-
目标数据库表名
-
如果表已存在,行为取决于
if_exists参数
-
-
con (sqlalchemy.engine.Engine or sqlite3.Connection)
-
数据库连接对象
-
通常使用 SQLAlchemy 引擎创建
-
-
schema (str, 可选)
-
数据库 schema 名称
-
默认为 None,使用数据库默认 schema
-
-
if_exists (str, 默认为 'fail')
-
表已存在时的处理方式:
-
'fail': 抛出 ValueError (默认)
-
'replace': 删除原表后重建
-
'append': 向现有表追加数据
-
-
写入控制参数
-
index (bool, 默认为 True)
-
是否将 DataFrame 的索引作为单独列写入
-
-
index_label (str or sequence, 可选)
-
索引列的列名
-
如果有多级索引,可传入序列
-
-
chunksize (int, 可选)
-
分批写入的行数
-
大数据集时使用可减少内存消耗
-
-
dtype (dict, 可选)
-
指定列的数据类型
-
格式:
{'column_name': sqlalchemy.types.Type} -
例如:
{'price': sqlalchemy.types.Float}
-
类型推断与性能
-
method (str or callable, 可选)
-
控制 SQL 插入方式:
-
None: 标准 SQL INSERT 语句
-
'multi': 单语句多行插入
-
callable: 自定义插入函数
-
-
大数据量时 'multi' 可提高性能
-
-
keys (sequence, 可选)
-
当 method='multi' 时,指定要插入的列
-
其他参数
-
fail_on_extra_columns (bool, 默认为 False)
-
如果为 True,当 DataFrame 包含表中不存在的列时会失败
-
-
alter_schema (bool, 默认为 False)
-
如果为 True,尝试修改表结构以匹配 DataFrame
-
下面是一个导出sql示例:
import pandas as pd
from sqlalchemy import create_engine
d = {'学号': [1, 2, 3],'姓名': ['张三', '李四', '王五'],'语文': [99, 88, 77],'数学': [44, 55, 55],'英语': [88, 55, 66]}
df = pd.DataFrame(d)
# 创建数据库引擎
# 注意:替换下面的用户名、密码、主机名和数据库名
engine = create_engine('mysql+pymysql://root:123456@localhost:3308/db_xuanke')
df.to_sql('t_student', engine, index_label='id')
运行后,自动建表,以及自动插入数据:

相关文章:
一周学会Pandas2 Python数据处理与分析-Pandas2数据导出
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili 任何原始格式的数据载入DataFrame后,都可以使用类似 DataFrame.to_csv()的方法输出到相应格式的文件或者…...
深入解析栈式虚拟机与反向波兰表示法
1.1 什么是虚拟机? 虚拟机(Virtual Machine, VM)是一种软件实现的计算机系统,提供与物理计算机相类似的环境,但在软件层面运行。虚拟机的存在简化了跨平台兼容性、资源管理以及安全隔离等问题。 1.2 栈式虚拟机的架构…...

python中的数据模型-pydantic浅讲
数据模型-pydantic 1. 基本用法 通过继承 BaseModel,你可以定义一个数据模型类。类的属性使用类型注解来声明字段的类型 from pydantic import BaseModelclass User(BaseModel):name: strage: intis_active: bool True # 默认值字段类型:每个字段…...

15.【.NET 8 实战--孢子记账--从单体到微服务--转向微服务】--单体转微服务--如何拆分单体
单体应用(Monolithic Application)是指将所有功能模块集中在一个代码库中构建的应用程序。它通常是一个完整的、不可分割的整体,所有模块共享相同的运行环境和数据库。这种架构开发初期较为简单,部署也较为方便,但随着…...

华为数字芯片机考2025合集4已校正
单选 1. 题目内容 影响芯片成本的主要因素是 Die Size 和封装,但电源、时钟等因素,特别是功耗对解决方案的成本影响较大,因此低成本设计需要兼顾低功耗设计:() 1. 解题步骤 1.1 分析题目 Die Size&…...

Java面试黄金宝典47
1. 如何设计一个秒杀系统 定义 秒杀系统是一种应对短时间内大量用户并发请求的系统,其核心目标是在高并发场景下保证系统的稳定性、数据的一致性,避免超卖等问题,同时快速响应用户请求。 秒杀系统设计需从多个层面考虑,以应对高并发场景: 前端优化: 页面静态化:将商品详…...
学习MySQL的第八天
海到无边天作岸 山登绝顶我为峰 一、数据库的创建、修改与删除 1.1 引言 在经过前面七天对于MySQL基本知识的学习之后,现在我们从基本的语句命令开始进入综合性的语句的编写来实现特定的需求,从这里开始需要我们有一个宏观的思想&…...

AI识别与雾炮联动:工地尘雾治理新途径
利用视觉分析的AI识别用于设备联动雾炮方案 背景 在建筑工地场景中,人工操作、机械作业以及环境因素常常导致局部出现大量尘雾。传统监管方式存在诸多弊端,如效率低、资源分散、监控功能单一、人力效率低等,难以完美适配现代工程需求。例如…...
GD32F303-IAP的过程和实验
使用的芯片为GD32F303VC 什么是IAP呢?有个博主写的很清楚;就是远程升级; 【单片机开发】单片机的烧录方式详解(ICP、IAP、ISP)_isp烧录-CSDN博客 我们需要写一个boot 和APP 通过 boot对APP的程序进行更新…...

众趣科技助力商家“以真示人”,让消费场景更真实透明
在当今的消费环境中,消费者权益保护问题日益凸显。无论是网购商品与实物不符、预定酒店民宿与图文描述差异大,还是游览景区遭遇“照骗”,这些问题不仅让消费者在消费和决策过程中倍感困扰,也让商家面临信任危机。 消费者在享受便…...

spark core编程之行动算子、累加器、广播变量
一、RDD 行动算子 reduce:聚集 RDD 所有元素,先聚合分区内数据,再聚合分区间数据。 collect:在驱动程序中以数组形式返回数据集所有元素。 foreach:分布式遍历 RDD 元素并调用指定函数。 count:返回 RDD…...

提高课:数据结构之树状数组
1,楼兰图腾 #include<iostream> #include<cstring> #include<cstdio> #include<algorithm>using namespace std;typedef long long LL;const int N 200010;int n; int a[N]; int tr[N]; int Greater[N], lower[N];int lowbit(int x) {ret…...
基于javaweb的SpringBoot新闻视频发布推荐评论系统(源码+部署文档)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

使用Go语言实现自动清理应用系统日志
在服务器上部署业务应用系统,每天都会产生大量的日志,随着时间的推移,日志越积累越多,占用了大量的磁盘空间,除了可以手动清理日志外,还可以通过程序实现自动清理日志。 之所以选择Go语言,是因…...

机器学习之PCA主成分分析详解
文章目录 引言一、PCA的概念二、PCA的基本数学原理2.1 内积与投影2.2 基2.3 基变换2.4 关键问题及优化目标2.5 方差2.6 协方差2.7 协方差矩阵2.8 协方差矩阵对角化 三、PCA执行步骤总结四、PCA计算实例五、PCA参数解释六、代码实现七、PCA的优缺点八、总结 引言 在机器学习领域…...

回溯——固定套路 | 面试算法12道
目录 输出二叉树所有路径 路径总和问题 组合总和问题 分割回文串 子集问题 排列问题 字母大小写全排列 单词搜索 复原IP地址 电话号码问题 括号生成问题 给我一种感觉是回溯需要画图思考是否需要剪枝。 元素个数n相当于树的宽度(横向)&#x…...

【11】Strongswan processor 详解1
processor_t结构体,声明了一些公用方法: get_total_threads获取总的线程数量; get_idle_threads获取空闲线程数量; get_working_threads按指定的优先级获取处理该优先级的job的线程数量; get_job_load 或取指定优先级j…...
Maven和MyBatis学习总结
目录 Maven 1.Maven的概念: 2.在具体的使用中意义: 3.与传统项目引入jar包做对比: 传统方式: 在maven项目当中: 4.在创建maven项目后,想要自定义一些maven配置 5.maven项目的结构 6.maven指令的生…...
)
普通通话CSFB方式(2g/3g)
一、CSFB的触发条件 当模块(或手机)驻留在 4G LTE网络 时,若发生以下事件,会触发CSFB流程: 主叫场景:用户主动拨打电话。被叫场景:接收到来电(MT Call)。紧急呼叫&…...

揭开人工智能与机器学习的神秘面纱:开发者的视角
李升伟 编译 人工智能(AI)和机器学习(ML)早已不再是空洞的流行语——它们正在彻底改变我们构建软件、做出决策以及与技术互动的方式。无论是自动化重复性任务,还是驱动自动驾驶汽车,AI/ML都是现代创新的核…...
AndroidTV 当贝播放器-v1.5.2-官方简洁无广告版
AndroidTV 当贝播放器 链接:https://pan.xunlei.com/s/VONXRf0g3cT0ECVt6GEsoODFA1?pwds4qv# AndroidTV 当贝播放器-v1.5.2-官方简洁无广告版...

BERT - MLM 和 NSP
本节代码将实现BERT模型的两个主要预训练任务:掩码语言模型(Masked Language Model, MLM) 和 下一句预测(Next Sentence Prediction, NSP)。 1. create_nsp_dataset 函数 这个函数用于生成NSP任务的数据集。 def cr…...

Python生成exe
其中的 -w 参数是 PyInstaller 用于窗口模式(Windowed mode),它会关闭命令行窗口的输出,这通常用于 图形界面程序(GUI),比如使用 PyQt6, Tkinter, PySide6 等。 所以: 如果你在没有…...
MySql 自我总结
目录 1. 数据库约束 1.1约束类型 2. 表的设计 2.1 一对一 2.2 一对多 2.3 多对多 3. 新增 4. 查询 4.1 聚合查询 4.2 GROUP BY 4.3 HAVING 4.4 联合查询 4.5 内连接 4.5.1 内连接的核心概念 4.5.2 内连接的语法 4.5.3 ON 与 WHERE 的区别 4.6 自连接 4.6.1 定…...
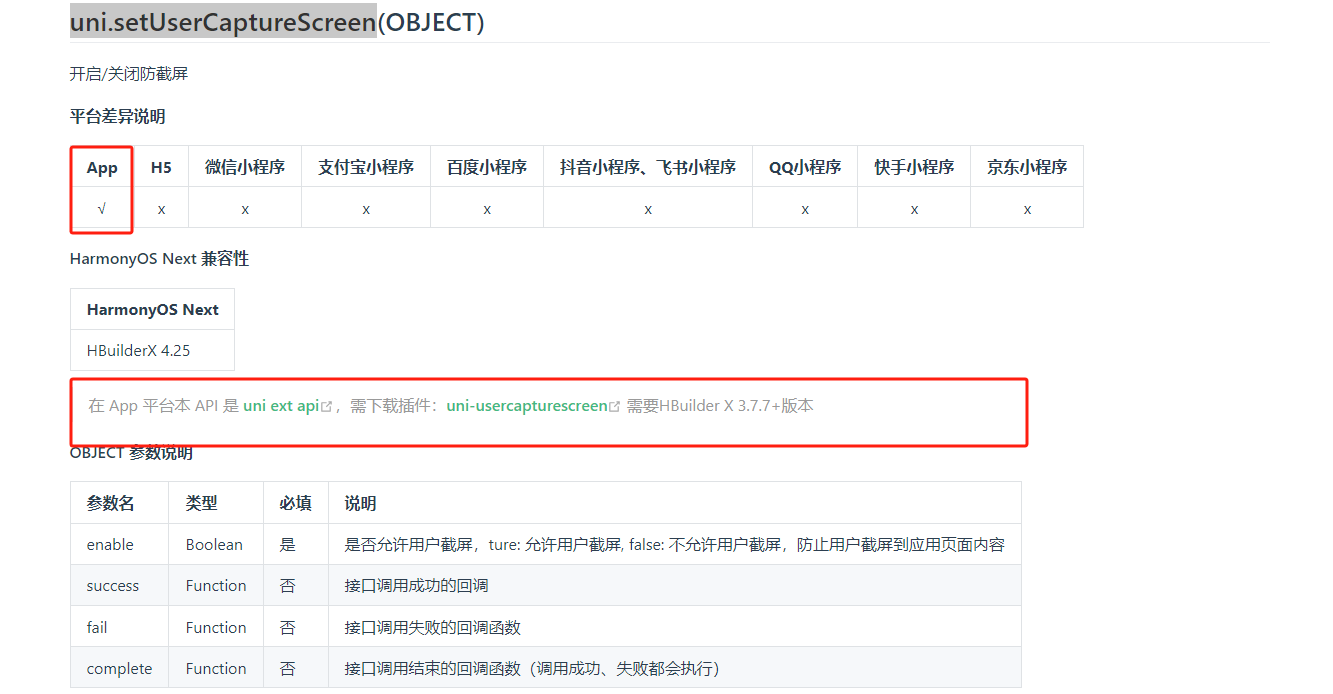
uni-app app 安卓和ios防截屏
首先可参考文档 uni.setUserCaptureScreen 这里需要在项目中引入这个插件 uni-usercapturescreen - DCloud 插件市场 否则会报错,在需要防止截屏录屏的页面中,加入 uni.setUserCaptureScreen({enable: false,success() {console.log(全局截屏录屏功能已禁用);},fail(err)…...
)
Android Input——查找并添加目标窗口(七)
在 Android 输入系统中,InputDispatcher 的核心职责之一是将输入事件正确地传递到目标窗口。上一篇文章我们介绍到 InputDispatcher 事件分发调用到 findFocusedWindowTargetsLocked() 函数查找焦点窗口,并将焦点窗口添加到目标窗口,这里我们继续往下看。 一、获取焦点窗口…...

ruby内置全局变量
以下是 Ruby 中常见的 内置全局变量 及其用途的详细说明。这些变量以 $ 开头,由 Ruby 解释器自动管理,用于访问系统状态、异常、输入输出等核心信息。 一、异常处理相关 全局变量说明示例$!当前作用域最后抛出的异常对象(等同于 rescue >…...

pytorch查询字典、列表维度
输出tensor变量维度 print(a.shape)输出字典维度 for key, value in output_dict.items():if isinstance(value, torch.Tensor):print(f"{key} shape:", value.shape)输出列表维度 def get_list_dimensions(lst):# 基线条件:如果lst不是列表࿰…...
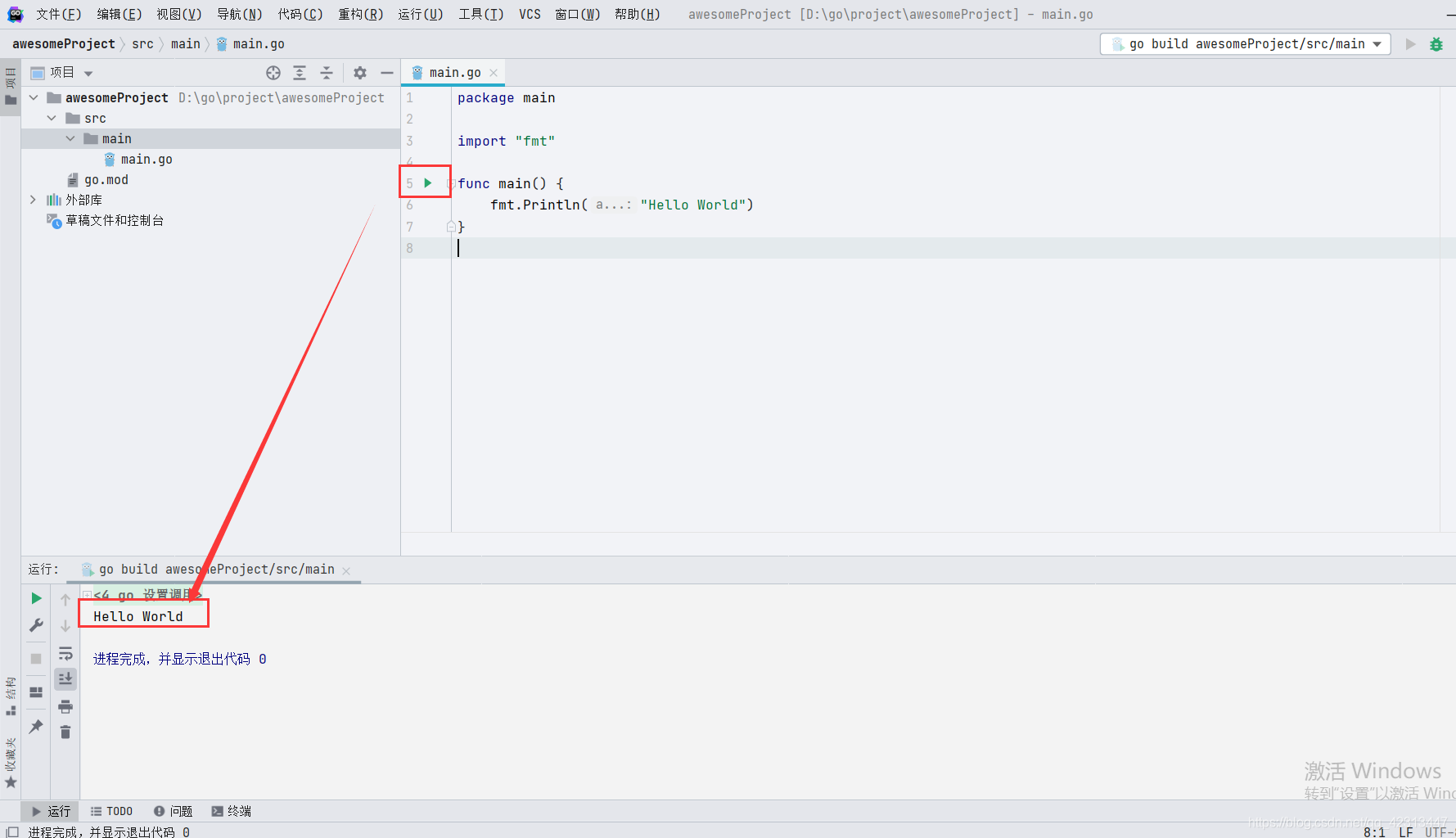
【Go】windows下的Go安装与配置,并运行第一个Go程序
【Go】windows下的Go安装与配置,并运行第一个Go程序 安装环境:windows10 64位 安装版本:go1.16 windows/amd64 一、安装配置步骤 1.到官方网址下载安装包 https://golang.google.cn/dl/ 默认情况下 .msi 文件会安装在 c:\Go 目录下。可自行配…...

Windows上使用Qt搭建ARM开发环境
在 Windows 上使用 Qt 和 g++-arm-linux-gnueabihf 进行 ARM Linux 交叉编译(例如针对树莓派或嵌入式设备),需要配置 交叉编译工具链 和 Qt for ARM Linux。以下是详细步骤: 1. 安装工具链 方法 1:使用 MSYS2(推荐) MSYS2 提供 mingw-w64 的 ARM Linux 交叉编译工具链…...