BERT - Bert模型框架复现
本节将实现一个基于Transformer架构的BERT模型。
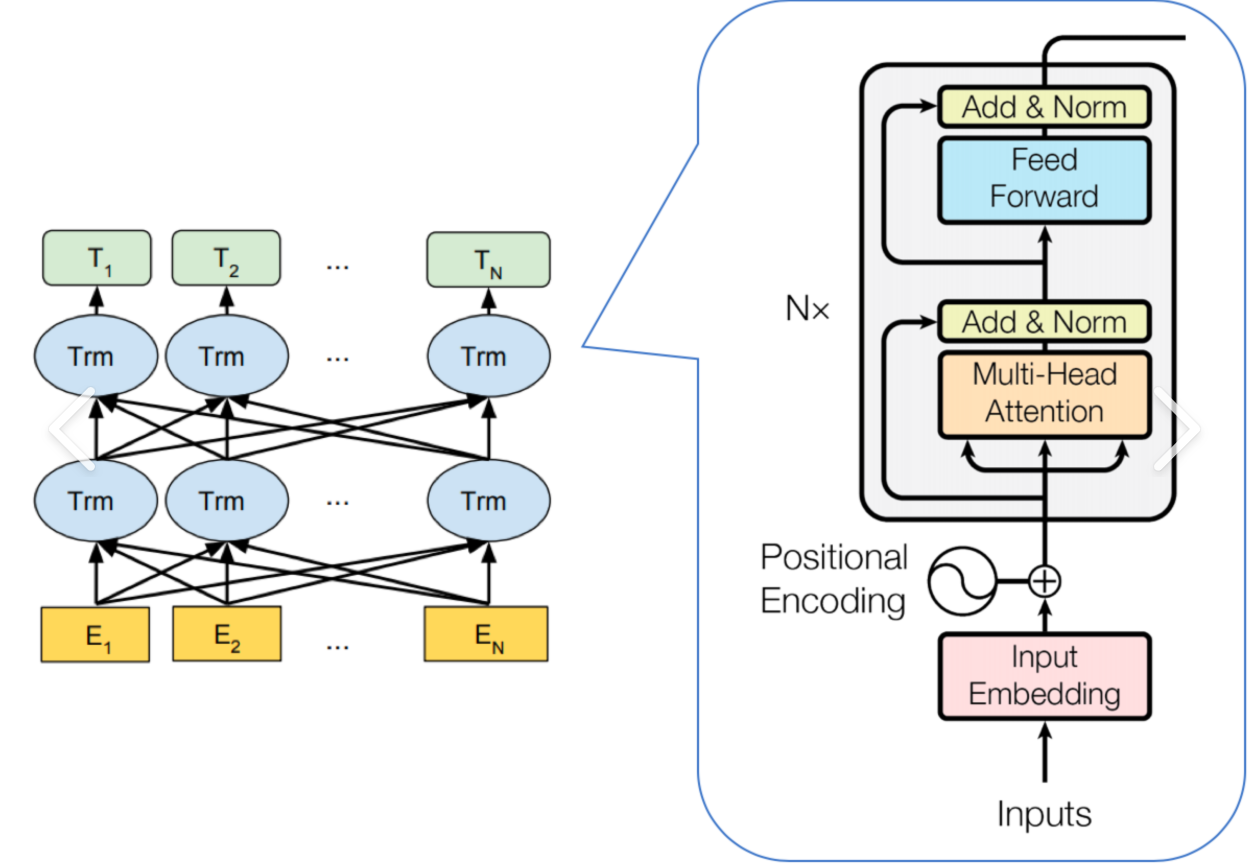
1. MultiHeadAttention 类
这个类实现了多头自注意力机制(Multi-Head Self-Attention),是Transformer架构的核心部分。
在前几篇文章中均有讲解,直接上代码
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads, dropout):super().__init__()self.num_heads = num_headsself.d_k = d_model // num_headsself.q_proj = nn.Linear(d_model, d_model)self.k_proj = nn.Linear(d_model, d_model)self.v_proj = nn.Linear(d_model, d_model)self.o_proj = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, mask=None):batch_size, seq_len, d_model = x.shapeQ = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)K = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)V = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)atten_scores = (Q @ K.transpose(-2, -1)) / math.sqrt(self.d_k)if mask is not None:mask = mask.unsqueeze(1).unsqueeze(1)atten_scores = atten_scores.masked_fill(mask == 0, -1e9)atten_scores = torch.softmax(atten_scores, dim=-1)out = atten_scores @ Vout = out.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)return self.dropout(self.o_proj(out))2. FeedForward 类
这个类实现了Transformer中的前馈网络(Feed-Forward Network, FFN)。
在前几篇文章中均有讲解,直接上代码
class FeedForward(nn.Module):def __init__(self, d_model, dff, dropout):super().__init__()self.W1 = nn.Linear(d_model, dff)self.act = nn.GELU()self.W2 = nn.Linear(dff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.W2(self.dropout(self.act(self.W1(x))))3. TransformerEncoderBlock 类
这个类实现了Transformer架构中的一个编码器块(Encoder Block)。
在前几篇文章中有Decoder的讲解(与Encoder原理基本相似),直接上代码
class TransformerEncoderBlock(nn.Module):def __init__(self, d_model, num_heads, dropout, dff):super().__init__()self.mha_block = MultiHeadAttention(d_model, num_heads, dropout)self.ffn_block = FeedForward(d_model, dff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)def forward(self, x, mask=None):res1 = self.norm1(x + self.dropout1(self.mha_block(x, mask)))res2 = self.norm2(res1 + self.dropout2(self.ffn_block(res1)))return res24. BertModel 类
这个类实现了BERT模型的整体架构。
class BertModel(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, num_heads, dropout, dff):super().__init__()self.tok_emb = nn.Embedding(vocab_size, d_model)self.seg_emb = nn.Embedding(3, d_model)self.pos_emb = nn.Embedding(seq_len, d_model)self.layers = nn.ModuleList([TransformerEncoderBlock(d_model, num_heads, dropout, dff)for _ in range(N_blocks)])self.norm = nn.LayerNorm(d_model)self.drop = nn.Dropout(dropout)def forward(self, x, seg_ids, mask):pos = torch.arange(x.shape[1])tok_emb = self.tok_emb(x)seg_emb = self.seg_emb(seg_ids)pos_emb = self.pos_emb(pos)x = tok_emb + seg_emb + pos_embfor layer in self.layers:x = layer(x, mask)x = self.norm(x)return x-
词嵌入、段嵌入和位置嵌入:
-
tok_emb:将输入的词索引映射到词嵌入空间。 -
seg_emb:用于区分不同的句子(例如在BERT中,用于区分句子A和句子B)。 -
pos_emb:将位置信息编码到嵌入空间,使模型能够捕捉到序列中的位置信息。
-
-
Transformer编码器层:通过
nn.ModuleList堆叠了N_blocks个TransformerEncoderBlock,每个块都负责对输入序列进行进一步的特征提取。 -
层归一化和Dropout:在所有编码器层处理完毕后,对输出进行层归一化和Dropout处理,进一步稳定模型的输出。
Bert完整代码(标红部分为本节所提到部分)
import re
import math
import torch
import random
import torch.nn as nnfrom transformers import BertTokenizer
from torch.utils.data import Dataset, DataLoader# nn.TransformerEncoderLayerclass MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads, dropout):super().__init__()self.num_heads = num_headsself.d_k = d_model // num_headsself.q_proj = nn.Linear(d_model, d_model)self.k_proj = nn.Linear(d_model, d_model)self.v_proj = nn.Linear(d_model, d_model)self.o_proj = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, mask=None):batch_size, seq_len, d_model = x.shapeQ = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)K = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)V = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)atten_scores = (Q @ K.transpose(-2, -1)) / math.sqrt(self.d_k)if mask is not None:mask = mask.unsqueeze(1).unsqueeze(1)atten_scores = atten_scores.masked_fill(mask == 0, -1e9)atten_scores = torch.softmax(atten_scores, dim=-1)out = atten_scores @ Vout = out.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)return self.dropout(self.o_proj(out))class FeedForward(nn.Module):def __init__(self, d_model, dff, dropout):super().__init__()self.W1 = nn.Linear(d_model, dff)self.act = nn.GELU()self.W2 = nn.Linear(dff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.W2(self.dropout(self.act(self.W1(x))))class TransformerEncoderBlock(nn.Module):def __init__(self, d_model, num_heads, dropout, dff):super().__init__()self.mha_block = MultiHeadAttention(d_model, num_heads, dropout)self.ffn_block = FeedForward(d_model, dff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)def forward(self, x, mask=None):res1 = self.norm1(x + self.dropout1(self.mha_block(x, mask)))res2 = self.norm2(res1 + self.dropout2(self.ffn_block(res1)))return res2class BertModel(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, num_heads, dropout, dff):super().__init__()self.tok_emb = nn.Embedding(vocab_size, d_model)self.seg_emb = nn.Embedding(3, d_model)self.pos_emb = nn.Embedding(seq_len, d_model)self.layers = nn.ModuleList([TransformerEncoderBlock(d_model, num_heads, dropout, dff)for _ in range(N_blocks)])self.norm = nn.LayerNorm(d_model)self.drop = nn.Dropout(dropout)def forward(self, x, seg_ids, mask):pos = torch.arange(x.shape[1])tok_emb = self.tok_emb(x)seg_emb = self.seg_emb(seg_ids)pos_emb = self.pos_emb(pos)x = tok_emb + seg_emb + pos_embfor layer in self.layers:x = layer(x, mask)x = self.norm(x)return xclass BERT(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, num_heads, dropout, dff):super().__init__()self.bert = BertModel(vocab_size, d_model, seq_len, N_blocks, num_heads, dropout, dff)self.mlm_head = nn.Linear(d_model, vocab_size)self.nsp_head = nn.Linear(d_model, 2)def forward(self, mlm_tok_ids, seg_ids, mask):bert_out = self.bert(mlm_tok_ids, seg_ids, mask)cls_token = bert_out[:, 0, :]mlm_logits = self.mlm_head(bert_out)nsp_logits = self.nsp_head(cls_token)return mlm_logits, nsp_logitsdef read_data(file):with open(file, "r", encoding="utf-8") as f:data = f.read().strip().replace("\n", "")corpus = re.split(r'[。,“”:;!、]', data)corpus = [sentence for sentence in corpus if sentence.strip()]return corpusdef create_nsp_dataset(corpus):nsp_dataset = []for i in range(len(corpus)-1):next_sentence = corpus[i+1]rand_id = random.randint(0, len(corpus) - 1)while abs(rand_id - i) <= 1:rand_id = random.randint(0, len(corpus) - 1)negt_sentence = corpus[rand_id]nsp_dataset.append((corpus[i], next_sentence, 1)) # 正样本nsp_dataset.append((corpus[i], negt_sentence, 0)) # 负样本return nsp_datasetclass BERTDataset(Dataset):def __init__(self, nsp_dataset, tokenizer: BertTokenizer, max_length):self.nsp_dataset = nsp_datasetself.tokenizer = tokenizerself.max_length = max_lengthself.cls_id = tokenizer.cls_token_idself.sep_id = tokenizer.sep_token_idself.pad_id = tokenizer.pad_token_idself.mask_id = tokenizer.mask_token_iddef __len__(self):return len(self.nsp_dataset)def __getitem__(self, idx):sent1, sent2, nsp_label = self.nsp_dataset[idx]sent1_ids = self.tokenizer.encode(sent1, add_special_tokens=False)sent2_ids = self.tokenizer.encode(sent2, add_special_tokens=False)tok_ids = [self.cls_id] + sent1_ids + [self.sep_id] + sent2_ids + [self.sep_id]seg_ids = [0]*(len(sent1_ids)+2) + [1]*(len(sent2_ids) + 1)mlm_tok_ids, mlm_labels = self.build_mlm_dataset(tok_ids)mlm_tok_ids = self.pad_to_seq_len(mlm_tok_ids, 0)seg_ids = self.pad_to_seq_len(seg_ids, 2)mlm_labels = self.pad_to_seq_len(mlm_labels, -100)mask = (mlm_tok_ids != 0)return {"mlm_tok_ids": mlm_tok_ids,"seg_ids": seg_ids,"mask": mask,"mlm_labels": mlm_labels,"nsp_labels": torch.tensor(nsp_label)}def pad_to_seq_len(self, seq, pad_value):seq = seq[:self.max_length]pad_num = self.max_length - len(seq)return torch.tensor(seq + pad_num * [pad_value])def build_mlm_dataset(self, tok_ids):mlm_tok_ids = tok_ids.copy()mlm_labels = [-100] * len(tok_ids)for i in range(len(tok_ids)):if tok_ids[i] not in [self.cls_id, self.sep_id, self.pad_id]:if random.random() < 0.15:mlm_labels[i] = tok_ids[i]if random.random() < 0.8:mlm_tok_ids[i] = self.mask_idelif random.random() < 0.9:mlm_tok_ids[i] = random.randint(106, self.tokenizer.vocab_size - 1)return mlm_tok_ids, mlm_labelsif __name__ == "__main__":data_file = "4.10-BERT/背影.txt"model_path = "/Users/azen/Desktop/llm/models/bert-base-chinese"tokenizer = BertTokenizer.from_pretrained(model_path)corpus = read_data(data_file)max_length = 25 # len(max(corpus, key=len))print("Max length of dataset: {}".format(max_length))nsp_dataset = create_nsp_dataset(corpus)trainset = BERTDataset(nsp_dataset, tokenizer, max_length)batch_size = 16trainloader = DataLoader(trainset, batch_size, shuffle=True)vocab_size = tokenizer.vocab_sized_model = 768N_blocks = 2num_heads = 12dropout = 0.1dff = 4*d_modelmodel = BERT(vocab_size, d_model, max_length, N_blocks, num_heads, dropout, dff)lr = 1e-3optim = torch.optim.Adam(model.parameters(), lr=lr)loss_fn = nn.CrossEntropyLoss()epochs = 20for epoch in range(epochs):for batch in trainloader:batch_mlm_tok_ids = batch["mlm_tok_ids"]batch_seg_ids = batch["seg_ids"]batch_mask = batch["mask"]batch_mlm_labels = batch["mlm_labels"]batch_nsp_labels = batch["nsp_labels"]mlm_logits, nsp_logits = model(batch_mlm_tok_ids, batch_seg_ids, batch_mask)loss_mlm = loss_fn(mlm_logits.view(-1, vocab_size), batch_mlm_labels.view(-1))loss_nsp = loss_fn(nsp_logits, batch_nsp_labels)loss = loss_mlm + loss_nsploss.backward()optim.step()optim.zero_grad()print("Epoch: {}, MLM Loss: {}, NSP Loss: {}".format(epoch, loss_mlm, loss_nsp))passpass相关文章:
BERT - Bert模型框架复现
本节将实现一个基于Transformer架构的BERT模型。 1. MultiHeadAttention 类 这个类实现了多头自注意力机制(Multi-Head Self-Attention),是Transformer架构的核心部分。 在前几篇文章中均有讲解,直接上代码 class MultiHeadAtt…...
(Go语言版))
【LeetCode 热题100】二叉树遍历入门:从中序遍历到层序与右视图(力扣94 / 102/199)(Go语言版)
🌳 二叉树遍历入门:从中序遍历到层序与右视图 本文涵盖 LeetCode 上的三道基础但极具代表性的二叉树遍历题: 二叉树的中序遍历 二叉树的层序遍历 二叉树的右视图 通过这些题目,我们将从 DFS 到 BFS,深入理解如何处理…...
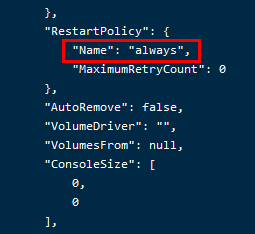
docker创建容器添加启动--restart选项
一、通过 Docker 命令直接修改已启动的容器(推荐-已验证) 操作步骤: 1.执行更新命令: docker update --restartalways <容器名或ID>此命令会将容器的重启策略调整为 always(无论容器以何种状态退出࿰…...
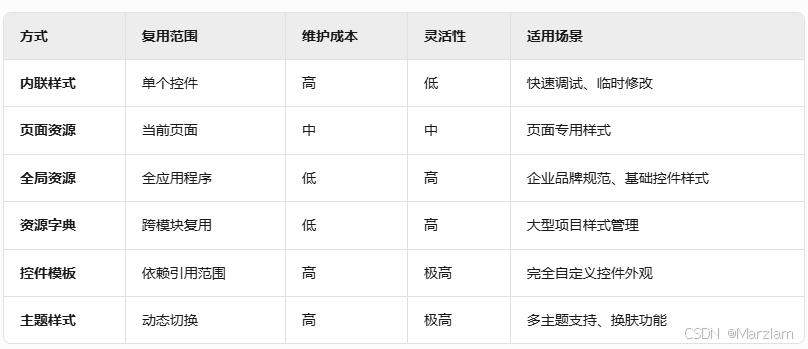
一文读懂WPF系列之常用控件以及样式
WPF控件 控件分类概览常用控件常用控件代码示例和效果 样式与模板应用样式定义方式行内样式页面/窗口级资源样式(Local Resource)应用程序全局资源独立资源字典(ResourceDictionary)控件模板(ControlTemplate&…...

嵌入式硬件篇---单片机周期
文章目录 前言 前言 在单片机中,时序控制是其执行指令和协调外设的核心基础。以下是单片机中常见的各种周期及其详细说明,以层次结构展开: 时钟周期(Clock Cycle) 定义: 时钟周期是单片机的最小时间单位&a…...
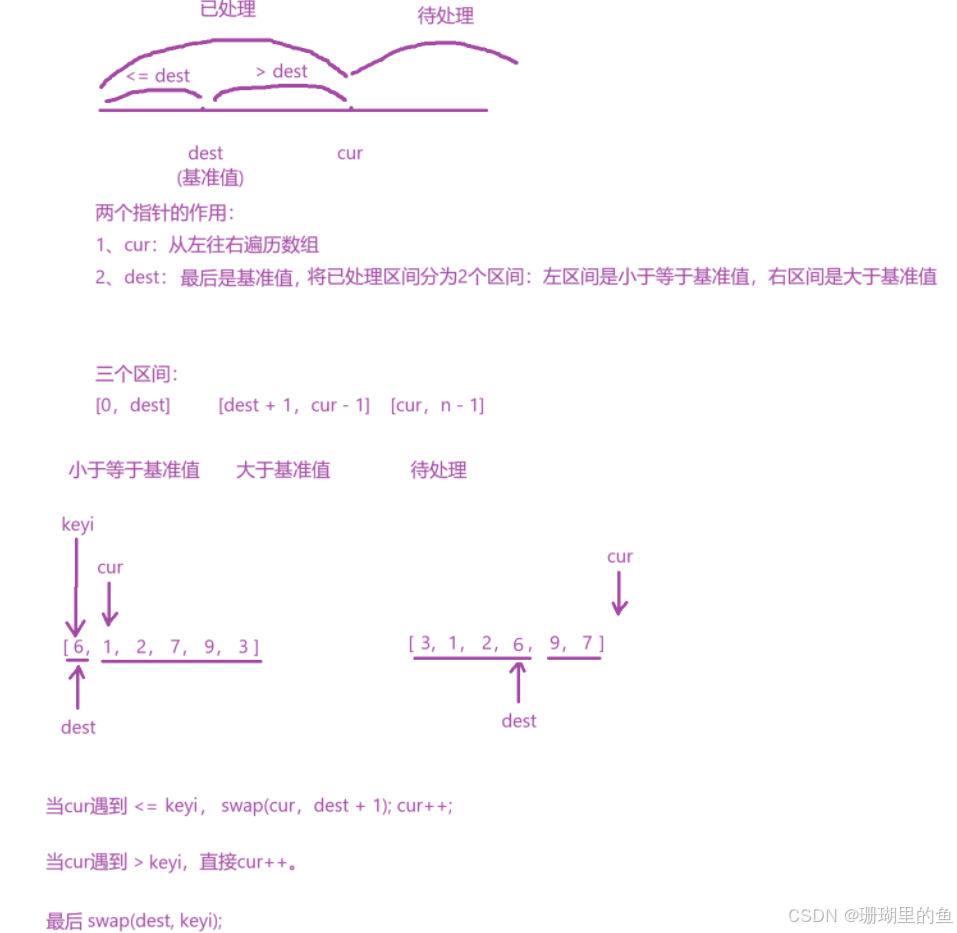
【双指针】专题:LeetCode 283题解——移动零
移动零 一、题目链接二、题目三、题目解析四、算法原理两个指针的作用以及三个区间总结 五、与快速排序的联系六、编写代码七、时间复杂度、空间复杂度 一、题目链接 移动零 二、题目 三、题目解析 “保持非零元素的相对顺序”,比如,示例1中非零元素1…...

2025蓝桥杯JavaB组
说明 博主自己水平有限,而且答案也不一定对,下面代码和思路仅作分享。我只把我考场上做了的写出来了,有什么问题欢迎评论区交流。 A:逃离高塔 思路: 由于有了去年的经验,所以一上来我就是找规律…...

SQL学习--基础语法学习
SQL和excle对比 学习目标 单表查询 项目背景 SQL 练习环境 SQL Online Compiler - Next gen SQL Editor 商品信息表:https://study-zhibo.oss-cn-shanghai.aliyuncs.com/test/%E5%95%86%E5%93%81%E4%BF%A1%E6%81%AF%E8%A1%A8.csv 订单明细表:https://…...
MATLAB2022b安装
1 从百度网盘下载MATLAB2022b,下载完成后解压到某个文件夹; 链接: MATLAB2022b 提取码: 6666 2 打开解压后的文件夹,进入setup文件夹,双击打开“setup.exe”文件; 3 在弹出窗口中选择“高级选项”-->“我有文件安…...

如何更改OCP与metadb集群的连接方式 —— OceanBase运维管理
背景 许多用户都会借助OCP平台来进行OceanBase集群的运维与监控,且因为考虑单节点的OCP部署,在遇故障时可能会短时间出现无法管控 OceanBase集群,多数用户倾向于采用多节点方式来部署OCP,即 OCP的 metadb集群也是三节点的集群部署…...

HTTP实现心跳模块
HTTP实现心跳模块 使用轻量级的cHTTP库cpp-httplib重现实现HTTP心跳模块 头文件HttplibHeartbeat.h #ifndef HTTPLIB_HEARTBEAT_H #define HTTPLIB_HEARTBEAT_H#include <string> #include <thread> #include <atomic> #include <chrono> #include …...
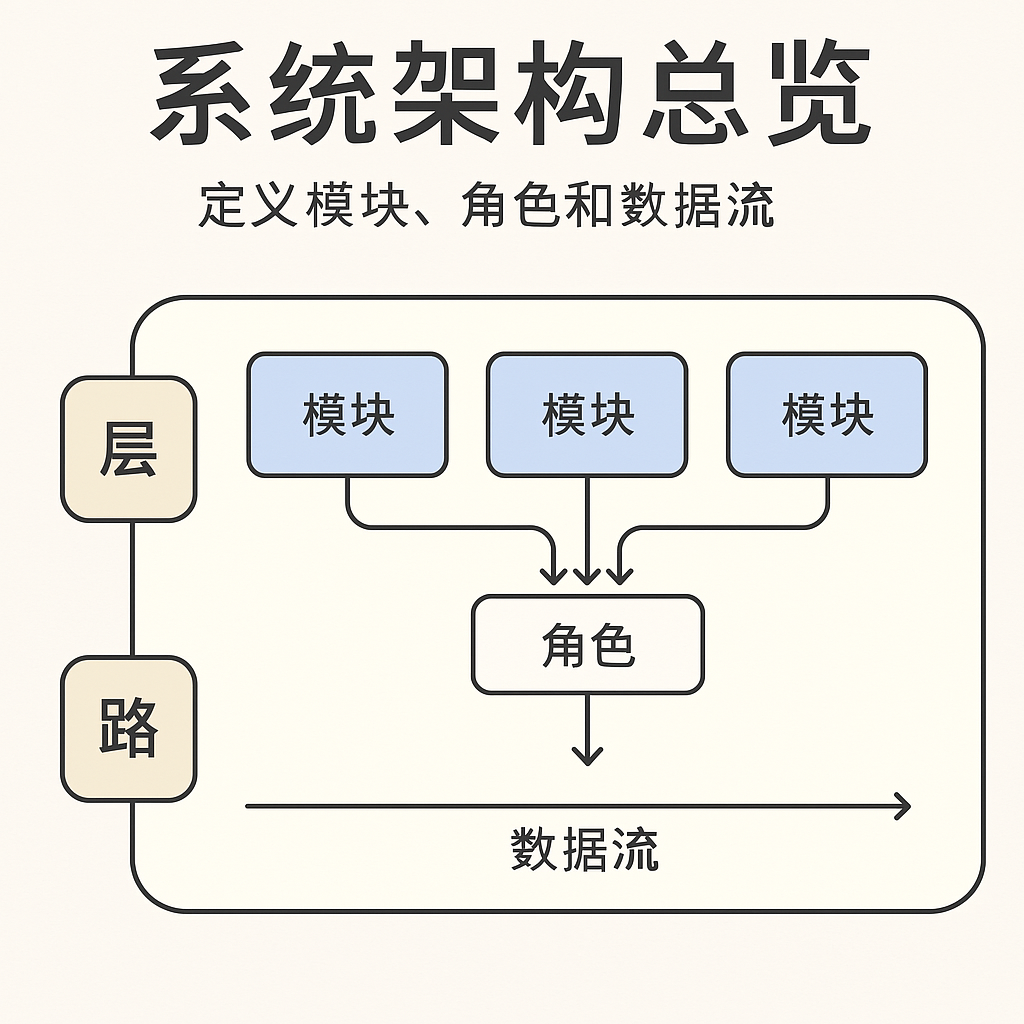
架构总览怎么写,才算工业级?
📈系统架构文档是整个项目最重要的起点,但很多人第一章就“写穿了”: 不是写得太细,就是没有重点。想要写出高质量、能协作、能传承的架构文档,这一篇会告诉你应该怎么做—— ✅ 架构总览的终极目标 明确边界、定义角色、画清数据流 别讲执行细节,别深入函数调用。 ✅ 架…...

Python10天突击--Day 3:函数式编程突破
以下是 Python 中实现方法耗时统计装饰器的完整方案,包含同步/异步支持、多级嵌套调用统计、可视化输出和性能分析等高级功能: 基础版:同步方法计时装饰器 import time from functools import wrapsdef timeit(func):"""基础…...
Datawhale 入驻 GitCode:以开源力量推动 AI 教育公平与创新
在 AI 技术深度重塑教育生态的今天,国内首个 AI 开源学习社区 —— Datawhale 正式加入 GitCode 开源平台!作为覆盖全球 3000 高校、培养超百万 AI 人才的创新社区,Datawhale 将通过开源协作模式,为人工智能教育公平注入新动能&a…...
ChatDBA:一个基于AI的智能数据库助手
今天给大家介绍一个基于 AI 大语言模型实现数据库故障诊断的智能助手:ChatDBA。 ChatDBA 是由上海爱可生信息技术股份有限公司开发,通过对话交互,提供数据库故障诊断、专业知识学习、SQL 生成和优化等功能,旨在提升 DBA 工作效率。…...
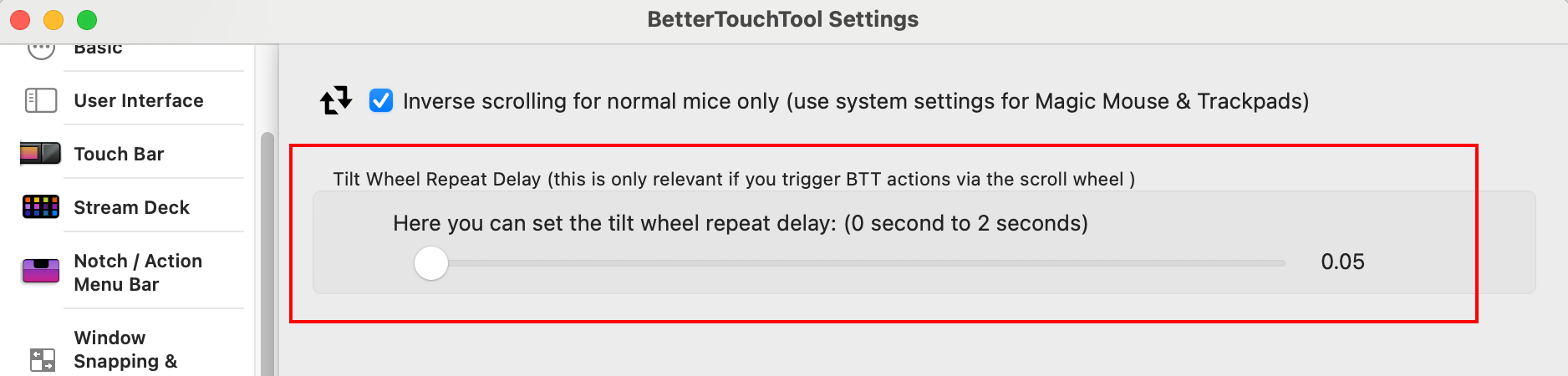
MacOS中的鼠标、触控板的设置研究
一、背景和写这篇文章的原因 想搞清楚和配置好鼠标,比如解决好为什么我的滚动那么难用?怎么设置滚轮的方向跟windows相同?调整双击速度,调整鼠标滚轮左右拨动的"冷却时间"。 二、各种设置之详细解释 1. MacOS设置 -&…...
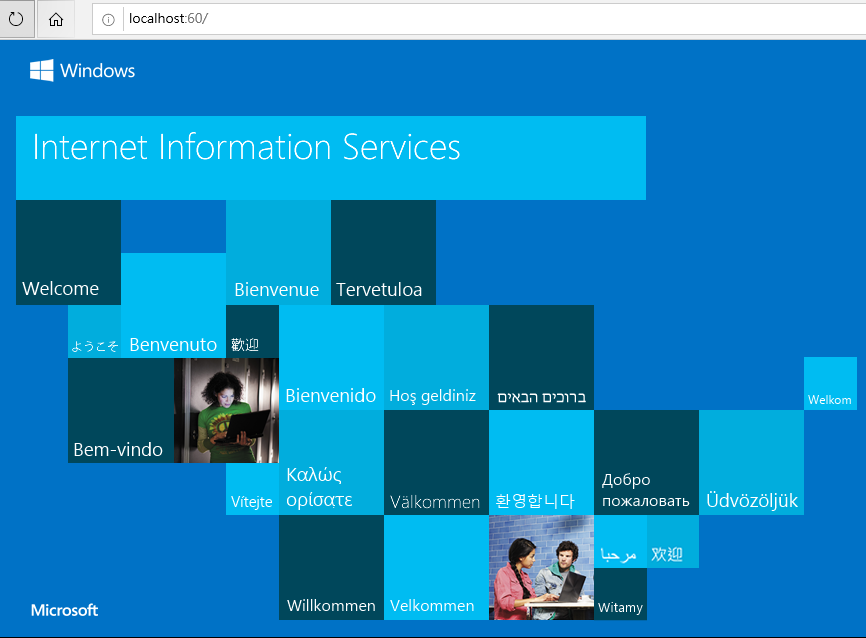
asp.net core 项目发布到 IIS 服务器
目录 一、VS2022 发布 二、设置IIS服务 三、配置IIS管理器 (一)打开IIS管理器 (二)添加站台 (三)配置应用程式集区 四、安装ASP.NET Core Hosting Bundle 五、设定IIS的日志位置 六、测试 一、VS2…...
)
如何解决线程安全问题(不涉及分布式情况)
线程安全问题本质 当多个线程并发操作共享资源(变量/对象)时,可能因非原子性操作或内存可见性问题导致数据不一致。 解决方案一:synchronized 关键字 实现方式: 实例方法同步锁 在实现Runnable接口的自定义线…...
:RedisTemplate的List类型操作)
Spring Boot(二十二):RedisTemplate的List类型操作
RedisTemplate和StringRedisTemplate的系列文章详见: Spring Boot(十七):集成和使用Redis Spring Boot(十八):RedisTemplate和StringRedisTemplate Spring Boot(十九)…...
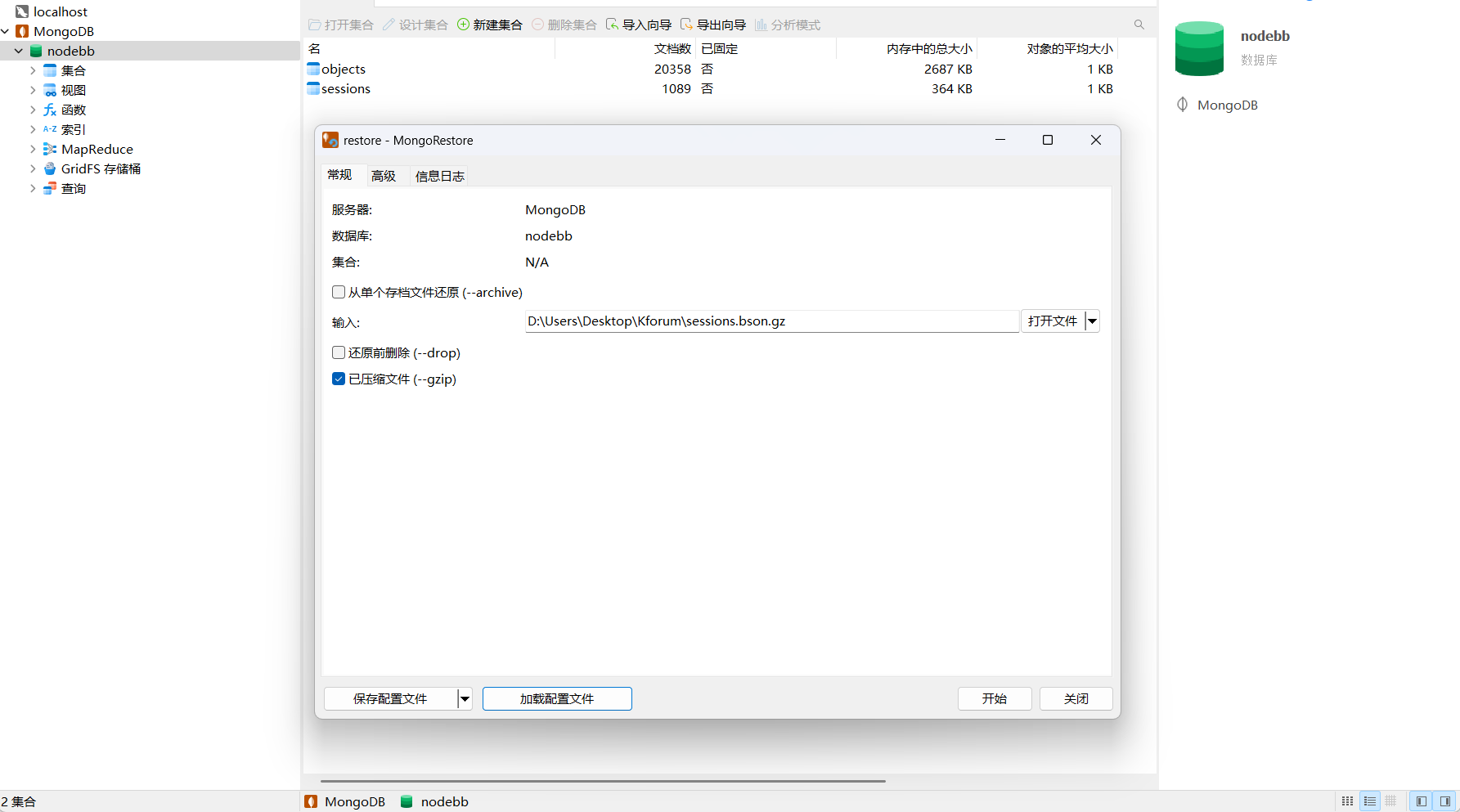
【Nodebb系列】Nodebb笔记写入方案
NodeBB写入方案 前言 最近在整理以前记录的碎片笔记,想把它们汇总到NodeBB中,方便管理和浏览。但是笔记内容有点多,并且用发帖的形式写到NodeBB中会丢失时间信息,因此整理了一套NodeBB写入方案,大致流程如下…...

计算机视觉——基于YOLOV8 的人体姿态估计训练与推理
概述 自 Ultralytics 发布 YOLOV5 之后,YOLO 的应用方向和使用方式变得更加多样化且简单易用。从图像分类、目标检测、图像分割、目标跟踪到关键点检测,YOLO 几乎涵盖了计算机视觉的各个领域,似乎已经成为计算机视觉领域的“万能工具”。 Y…...

鸿蒙小案例---心情日记
效果演示 代码实现 import { router, window } from kit.ArkUIEntry Component struct Index {async aboutToAppear(): Promise<void> {let w await window.getLastWindow(getContext())w.setWindowSystemBarProperties({statusBarColor: #00C6C3,statusBarContentColo…...

力扣第206场周赛
周赛链接:竞赛 - 力扣(LeetCode)全球极客挚爱的技术成长平台 1. 二进制矩阵中的特殊位置 给定一个 m x n 的二进制矩阵 mat,返回矩阵 mat 中特殊位置的数量。 如果位置 (i, j) 满足 mat[i][j] 1 并且行 i 与列 j 中…...

从 SYN Flood 到 XSS:常见网络攻击类型、区别及防御要点
常见的网络攻击类型 SYN Flood、DoS(Denial of Service) 和 DDoS(Distributed Denial of Service) 是常见的网络攻击类型,它们的目标都是使目标系统无法正常提供服务。以下是它们的详细说明: 1. SYN Flood…...

el-tree 实现树形菜单子级取消选中后父级选中效果不变
背景 在复杂的企业级管理系统中,树形菜单是一种常见的数据展示和交互组件。传统的树形菜单通常存在以下交互局限: 子节点取消选中时,父节点会自动取消选中无法满足复杂的权限分配和数据筛选场景实际应用场景: 组织架构权限管理多层级资源分配复杂的数据筛选与展示实现需求…...

Java虚拟机——JVM(Java Virtual Machine)解析一
1.JVM是什么? 1.1 JVM概念 Java Virtual Machine (JVM) 是JDK的核心组件之一,它使得 Java 程序能够在任何支持 JVM 的设备或操作系统上运行,而无需修改源代码 JDK是什么,JDK和JVM是什么关系?1.Java IDE(Integrated …...

开源的PMPI库实现及示例代码
开源的PMPI库实现及示例代码 PMPI (Profiling MPI) 是MPI标准中定义的接口,允许开发者通过拦截MPI调用进行性能测量和调试。以下是几个常用的开源PMPI库实现: 1. MPICH的PMPI接口 MPICH本身提供了PMPI接口,可以直接使用。 2. OpenMPI的PM…...
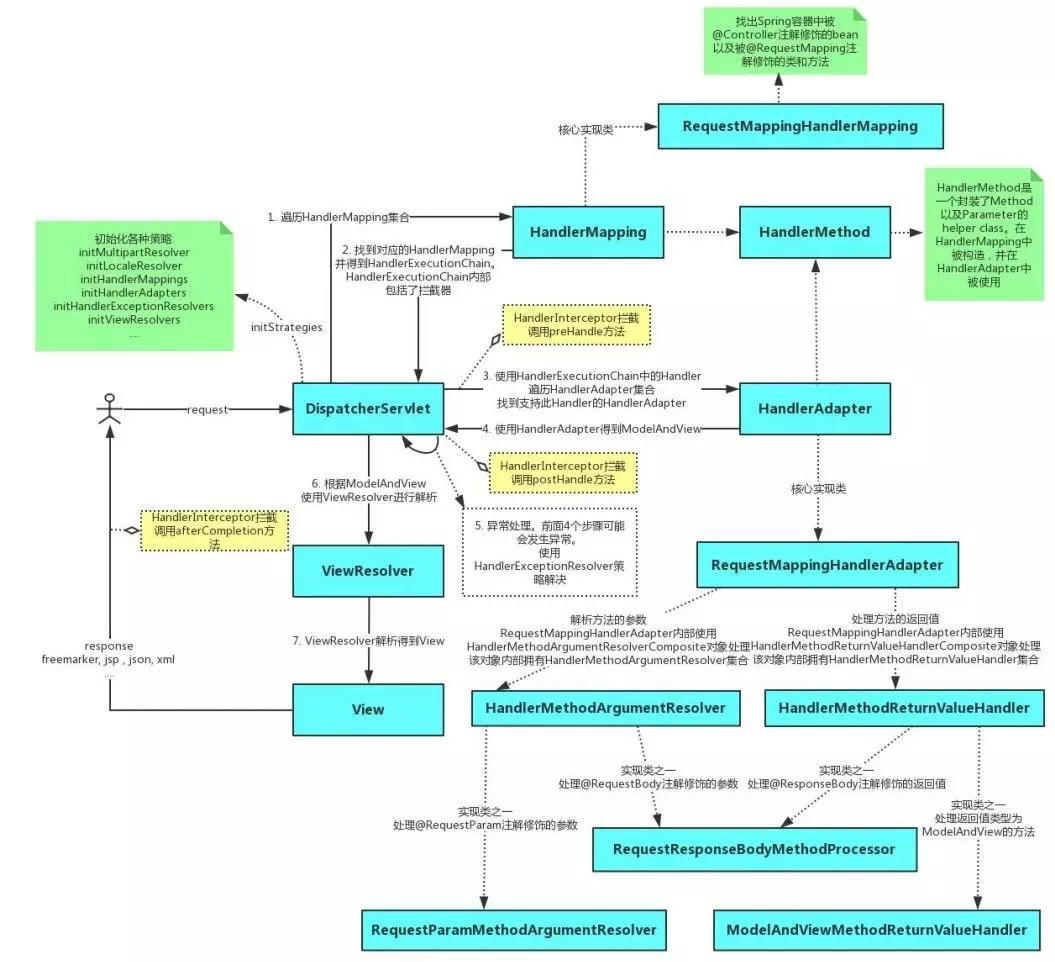
【源码】SpringMvc源码分析
文章目录 SpringMVC 基础回顾核心组件源码分析DispatcherServletHandlerMappingHandlerAdapterViewResolver 请求处理流程源码解析 在当今的 Java Web 开发领域,SpringMVC 无疑是最为广泛应用的 Web 框架之一。它以其强大的功能、灵活的配置以及高度的…...

tcp特点+TCP的状态转换图+time_wait详解
tcp特点TCP的状态转换图time wait详解 目录 一、tcp特点解释 1.1 面向连接 1.1.1 连接建立——三次握手 1.1.2 连接释放——四次挥手 1.2 可靠的 1.2.1 应答确认 1.2.2 超时重传 1.2.3 乱序重排 1.2.4 去重 1.2.5 滑动窗口进行流量控制 1.3 流失服务(字节…...
高支模自动化监测解决方案
1.行业现状 高大模板支撑系统在浇筑施工过程中,诸多重大安全风险点进行实时自动化安全监测的解决方案主要监测由于顶杆失稳、扣件失效、承压过大等引起的支撑轴力、模板沉降、相对位移、支撑体系倾斜等参数变化。系统采用无线自动组网、高频连续采样,实时…...