使用Python爬虫的2大原因和6大常用库
爬虫其实就是请求http、解析网页、存储数据的过程,并非高深的技术,但凡是编程语言都能做,连Excel VBA都可以实现爬虫,但Python爬虫的使用频率最高、场景最广。

这可不仅仅是因为Python有众多爬虫和数据处理库,还有一个更直接的原因是Python足够简单。
Python作为解释型语言,不需要编译就可以运行,而且采用动态类型,灵活赋值,同样的功能实现,代码量比Java、C++少很多。
而且Python既可以面向对象也可以面向过程编程,这样就简化了爬虫脚本编写的难度,即使新手也可以快速入门。

比如一个简单网页请求和解析任务,Python只需要7行代码,Java则需要20行。
python实现:
requests.get用于请求http服务,soup.find_all用于解析html
import requests
from bs4 import BeautifulSoupurl = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')links = [a['href'] for a in soup.find_all('a', href=True)]
print(links)
Java实现:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;public class JavaCrawler {public static void main(String[] args) {String url = "https://example.com";try {Document doc = Jsoup.connect(url).get();Elements links = doc.select("a[href]");for (Element link : links) {System.out.println(link.attr("href"));}} catch (IOException e) {e.printStackTrace();}}
}
当然python的第三方库生态也为Python爬虫提供了诸多便利,比如requests、bs4、scrapy,这些库将爬虫技术进行了高级封装,提供了便捷的api接口,原来需要几十行代码解决的问题,现在只需要一行就可以搞定。
这里介绍6个最常用的爬虫库。
requests
不用多说,requests 是 Python 中一个非常流行的第三方库,用于发送各种 HTTP 请求。它简化了 HTTP 请求的发送过程,使得从网页获取数据变得非常简单和直观。
requests 库提供了丰富的功能和灵活性,支持多种请求类型(如 GET、POST、PUT、DELETE 等),可以发送带有参数、头信息、文件等的请求,并且能够处理复杂的响应内容(如 JSON、XML 等)。

urllib3
urllib3 是 Python内置网页请求库,类似于requests库,主要用于发送HTTP请求和处理HTTP响应。它建立在Python标准库的urllib模块之上,但提供了更高级别、更健壮的API。
urllib3可以用于处理简单身份验证、cookie 和代理等复杂任务。
BeautifulSoup
BeautifulSoup是最常用的Python网页解析库之一,可将 HTML 和 XML 文档解析为树形结构,能更方便地识别和提取数据。
此外,你还可以设置 BeautifulSoup 扫描整个解析页面,识别所有重复的数据(例如,查找文档中的所有链接),只需几行代码就能自动检测特殊字符等编码。
lxml
lxml也是网页解析库,主要用于处理XML和HTML文档。它提供了丰富的API,可以轻松地读取、解析、创建和修改XML和HTML文档。

Scrapy
Scrapy是一个流行的高级爬虫框架,可快速高效地抓取网站并从其页面中提取结构化数据。
由于 Scrapy 主要用于构建复杂的爬虫项目,并且它通常与项目文件结构一起使用。
Scrapy 不仅仅是一个库,还可以用于各种任务,包括监控、自动测试和数据挖掘。
Selenium
Selenium 是一款基于浏览器地自动化程序库,可以抓取网页数据。它能在 JavaScript 渲染的网页上高效运行,这在其他 Python 库中并不多见。
在开始使用 Python 处理 Selenium 之前,需要先使用 Selenium Web 驱动程序创建功能测试用例。
Selenium 库能很好地与任何浏览器(如 Firefox、Chrome、IE 等)配合进行测试,比如表单提交、自动登录、数据添加/删除和警报处理等。
其实除了Python这样编程语言实现爬虫之外,还有其他无代码爬虫工具可以使用。
八爪鱼爬虫
八爪鱼是一款简单方便的桌面端爬虫软件,主打可视化操作,即使是没有任何编程基础的用户也能轻松上手。
八爪鱼支持多种数据类型采集,包括文本、图片、表格等,并提供强大的自定义功能,能够满足不同用户需求。此外,八爪鱼爬虫支持将采集到的数据导出为多种格式,方便后续分析处理。
使用和下载:https://affiliate.bazhuayu.com/zwjzht

亮数据爬虫
亮数据则是专门用于复杂网页数据采集的工具,可以搞定反爬、动态页面,比如它的Web Scraper IDE、亮数据浏览器、SERP API等,能够自动化地从网站上抓取所需数据,无需分析目标平台的接口,直接使用亮数据提供的方案即可安全稳定地获取数据。
而且亮数据有个很强大的功能:Scraper APIs,你可以理解成一种爬虫接口,它帮你绕开了IP限制、验证码、加密等问题,无需编写任何的反爬机制处理、动态网页处理代码,后续也无需任何维护,就可以“一键”获取Tiktok、Amazon、Linkedin、Github、Instagram等全球各大主流网站数据。
web直接使用:https://get.brightdata.com/webscra
Web Scraper
Web Scraper是一款轻便易用的浏览器扩展插件,用户无需安装额外的软件,即可在Chrome浏览器中进行爬虫。插件支持多种数据类型采集,并可将采集到的数据导出为多种格式。
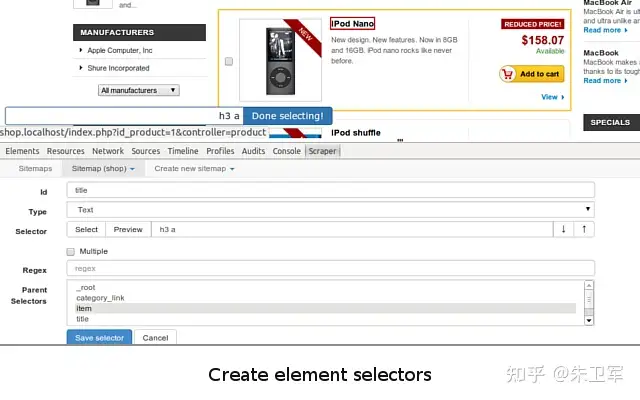
无论是Python库还是爬虫软件,都能实现数据采集任务,可以选择适合自己的。当然记得在使用这些工具时,一定要遵守相关网站的爬虫政策和法律法规。
相关文章:
使用Python爬虫的2大原因和6大常用库
爬虫其实就是请求http、解析网页、存储数据的过程,并非高深的技术,但凡是编程语言都能做,连Excel VBA都可以实现爬虫,但Python爬虫的使用频率最高、场景最广。 这可不仅仅是因为Python有众多爬虫和数据处理库,还有一个…...

Java 架构设计:从单体架构到微服务的转型之路
Java 架构设计:从单体架构到微服务的转型之路 在现代软件开发中,架构设计的选择对系统的可扩展性、可维护性和性能有着深远的影响。随着业务需求的日益复杂和用户规模的不断增长,传统的单体架构逐渐暴露出其局限性,而微服务架构作…...

C# 混淆代码工具--ConfuserEx功能与使用指南
目录 1 前言1.1 可能带来的问题 2 ConfuserEx2.1 简介2.2 功能特点2.3 基本使用方法2.4 集成到MSBuild2.5 深入设置2.5.1 保护机制2.5.1.1 ConfuserEx Protection 2.5.2 精细的代码保护主要特性1. decl-type(string)2.full-name(string)3. is-public()4. match(string)5. match…...
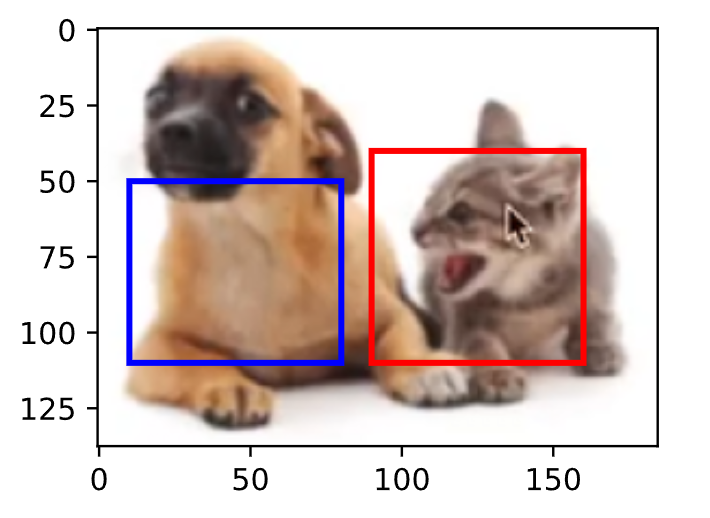
使用PyTorch实现目标检测边界框转换与可视化
一、引言 在目标检测任务中,边界框(Bounding Box)的坐标表示与转换是核心基础操作。本文将演示如何: 实现边界框的两种表示形式(角点坐标 vs 中心坐标)之间的转换 使用Matplotlib在图像上可视化边界框 验…...

nlp面试重点
深度学习基本原理:梯度下降公式,将损失函数越来越小,最终预测值和实际值误差比较小。 交叉熵:-p(x)logq(x),p(x)是one-hot形式。如果不使用softmax计算交叉熵,是不行的。损失函数可能会非常大,…...
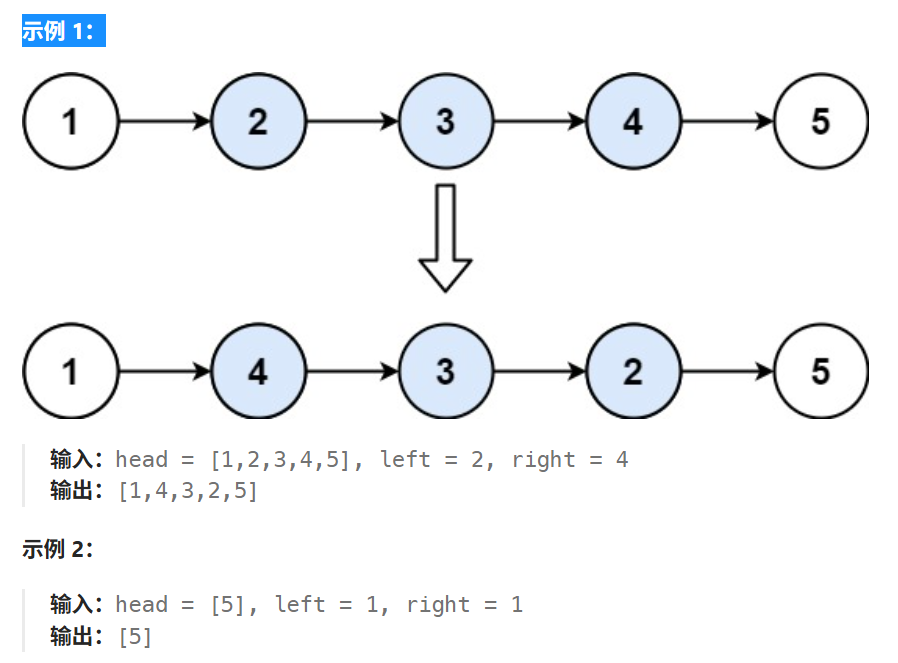
欢乐力扣:反转链表二
文章目录 1、题目描述2、思路 1、题目描述 反转链表二。 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 2、思路 参考官方题解,基本思路…...
(完结))
2025最新系统 Git 教程(七)(完结)
第4章 分布式Git 4.1 分布式 Git - 分布式工作流程 你现在拥有了一个远程 Git 版本库,能为所有开发者共享代码提供服务,在一个本地工作流程下,你也已经熟悉了基本 Git 命令。你现在可以学习如何利用 Git 提供的一些分布式工作流程了。 这一…...

14-大模型微调和训练之-Hugging Face 模型微调训练(基于 BERT 的中文评价情感分析(二分类))
1. datasets 库核心方法 1.1. 列出数据集 使用 datasets 库,你可以轻松列出所有 Hugging Face 平台上的数据集: from datasets import list_datasets # 列出所有数据集 all_datasets list_datasets() print(all_datasets)1.2. 加载数据集 你可以通过…...

聊透多线程编程-线程基础-4.C# Thread 子线程执行完成后通知主线程执行特定动作
在多线程编程中,线程之间的同步和通信是一个常见的需求。例如,我们可能需要一个子线程完成某些任务后通知主线程,并由主线程执行特定的动作。本文将基于一个示例程序,详细讲解如何使用 AutoResetEvent 来实现这种场景。 示例代码…...
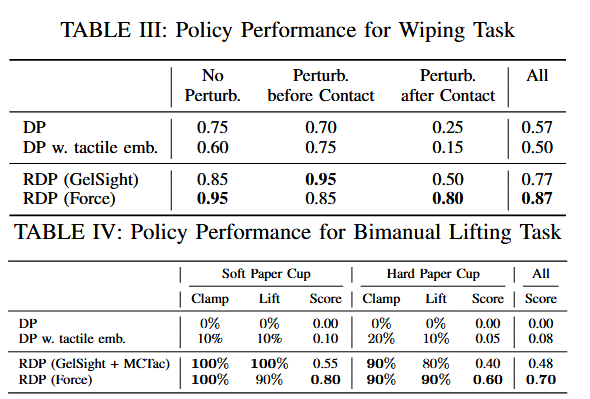
论文阅读笔记——Reactive Diffusion Policy
RDP 论文 通过 AR 提供实时触觉/力反馈;慢速扩散策略,用于预测低频潜在空间中的高层动作分块;快速非对称分词器实现闭环反馈控制。 ACT、 π 0 \pi_0 π0 采取了动作分块,在动作分块执行期间处于开环状态,无法及时响…...
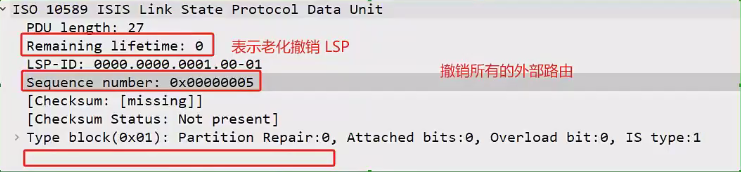
ISIS协议(动态路由协议)
ISIS基础 基本概念 IS-IS(Intermediate System to Intermediate System,中间系统到中间系统)是ISO (International Organization for Standardization,国际标准化组织)为它的CLNP(ConnectionL…...
Kafka实时数据采集与分发的企业级实践:从架构设计到性能调优)
大数据(7.1)Kafka实时数据采集与分发的企业级实践:从架构设计到性能调优
目录 一、实时数据洪流下的技术突围1.1 行业需求演进曲线1.2 传统方案的技术瓶颈 二、Kafka实时架构设计精要2.1 生产者核心参数矩阵2.1.1 分区策略选择指南 2.2 消费者组智能负载均衡 三、实时数据管道实战案例3.1 电商大促实时看板3.2 工业物联网预测性维护 四、生产环境性能…...

UniApp 实现兼容 H5 和小程序的拖拽排序组件
如何使用 UniApp 实现一个兼容 H5 和小程序的 九宫格拖拽排序组件,实现思路和关键步骤。 一、完整效果图示例 H5端 小程序端 git地址 二、实现目标 支持拖动菜单项改变顺序拖拽过程实时预览移动位置拖拽松开后自动吸附回网格兼容 H5 和小程序平台 三、功能…...

C,C++,C#
C、C 和 C# 是三种不同的编程语言,虽然它们名称相似,但在设计目标、语法特性、运行环境和应用场景上有显著区别。以下是它们的核心区别: 1. 设计目标和历史 语言诞生时间设计目标特点C1972(贝尔实验室)面向过程&#…...

MySQL | 三大日志文件
Undo Log(回滚日志) 实现原理与分类 原理:Undo Log 记录的是数据修改前的旧值,通过这些旧值可以将数据恢复到修改之前的状态。它采用的是逻辑日志,即记录的是如何撤销操作,而不是物理数据的实际值。 分类…...
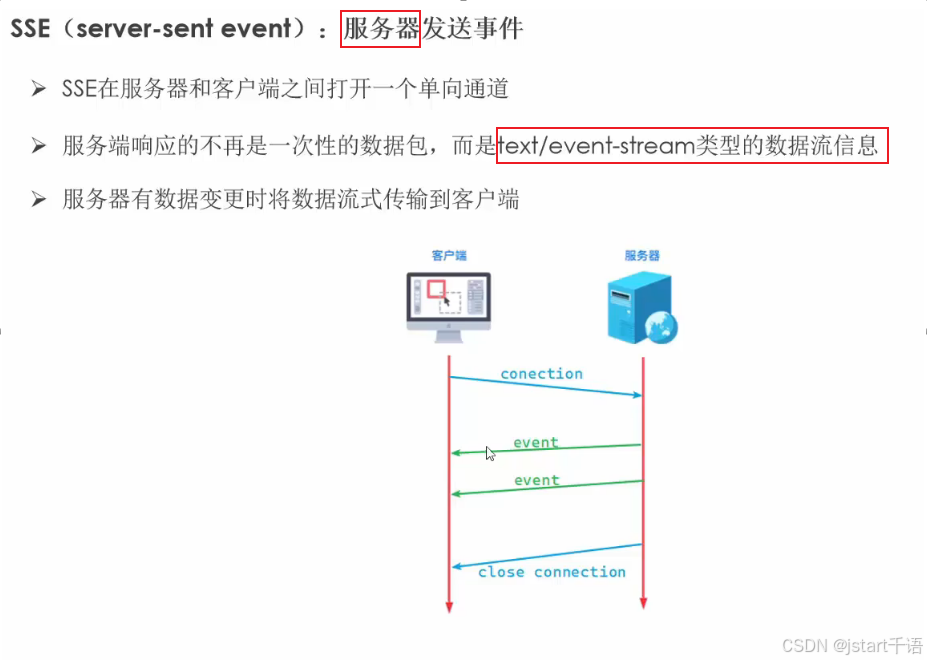
【网络协议】WebSocket讲解
目录 webSocket简介 连接原理解析: 客户端API 服务端API(java) 实战案例 (1)引入依赖 (2)编写服务端逻辑 (3)注册配置类 (4)前端连接 WebSocket 示例…...
啥是Spring,有什么用,既然收费,如何免费创建SpringBoot项目,依赖下载不下来的解决方法,解决99%问题!
一、啥是Spring,为啥选择它 我们平常说的Spring指的是Spring全家桶,我们为什么要选择Spring,看看官方的话: 意思就是:用这个东西,又快又好又安全,反正就是好处全占了,所以我们选择它…...

一天时间,我用AI(deepseek)做了一个配色网站
前言 最近在开发颜色搭配主题的相关H5和小程序,想到需要补充一个web网站,因此有了这篇文章。 一、确定需求 向AI要答案之前,一定要清楚自己想要做什么。如果你没有100%了解自己的需求,可以先让AI帮你理清逻辑和思路,…...

Day14:关于MySQL的索引——创、查、删
前言:先创建一个练习的数据库和数据 1.创建数据库并创建数据表的基本结构 -- 创建练习数据库 CREATE DATABASE index_practice; USE index_practice;-- 创建基础表(包含CREATE TABLE时创建索引) CREATE TABLE products (id INT PRIMARY KEY…...
)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(二)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(二) 7. 实现条件WGAN-GP # 训练条件WGAN-GP def train_conditional_wgan_gp():# 用于记录损失d_losses []g_losses []# 用于记录生成样本的多样性(通过类别分…...

Spring - 13 ( 11000 字 Spring 入门级教程 )
一: Spring AOP 备注:之前学习 Spring 学到 AOP 就去梳理之前学习的知识点了,后面因为各种原因导致 Spring AOP 的博客一直搁置。。。。。。下面开始正式的讲解。 学习完 Spring 的统一功能后,我们就进入了 Spring AOP 的学习。…...
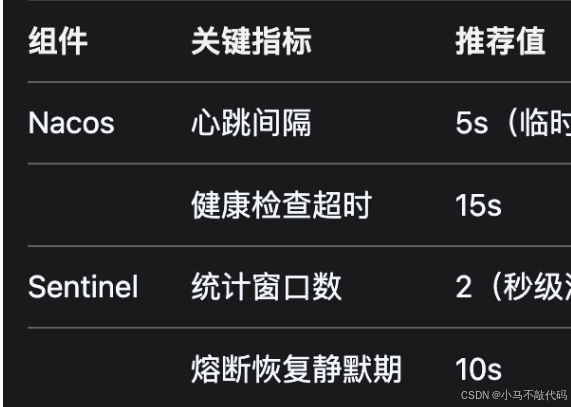
Spring Cloud Alibaba微服务治理实战:Nacos+Sentinel深度解析
一、引言 在微服务架构中,服务发现、配置管理、流量控制是保障系统稳定性的核心问题。Spring Cloud Netflix 生态曾主导微服务解决方案,但其部分组件(如 Eureka、Hystrix)已进入维护模式。 Spring Cloud Alibaba 凭借 高性能、轻…...

设计模式之迭代器模式:遍历的艺术与实现
引言 迭代器模式(Iterator Pattern)是一种行为型设计模式,它提供了一种顺序访问聚合对象中各个元素的方法,而又不暴露其底层实现。迭代器模式将遍历逻辑与聚合对象解耦,使得我们可以用统一的方式处理不同的集合结构。…...

红宝书第三十六讲:持续集成(CI)配置入门指南
红宝书第三十六讲:持续集成(CI)配置入门指南 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、什么是持续集成? 持续集成(CI)就像咖啡厅的…...

Java—HTML:3D形变
今天我要介绍的是在Java HTML中CSS的相关知识点内容之一:3D形变(3D变换)。该内容包含透视(属性:perspective),3D变换,3D变换函数以及案例演示, 接下来我将逐一介绍&…...

什么是音频预加重与去加重,预加重与去加重的原理是什么,在什么条件下会使用预加重与去加重?
音频预加重与去加重是音频处理中的两个重要概念,以下是对其原理及应用条件的详细介绍: 1、音频预加重与去加重的定义 预加重:在音频信号的发送端,对音频信号的高频部分进行提升,增加高频信号的幅度,使其在…...

免费下载 | 2025清华五道口:“十五五”金融规划研究白皮书
《2025清华五道口:“十五五”金融规划研究白皮书》的核心内容主要包括以下几个方面: 一、五年金融规划的重要功能与作用 凝聚共识:五年金融规划是国家金融发展的前瞻性谋划和战略性安排,通过广泛听取社会各界意见,凝…...

微信小程序实战案例 - 餐馆点餐系统 阶段 4 - 订单列表 状态
✅ 阶段 4 – 订单列表 & 状态 目标 展示用户「我的订单」列表支持状态筛选(全部 / 待处理 / 已完成)支持分页加载和实时刷新使用原生组件编写 ✅ 1. 页面结构:文件结构 pages/orders/├─ index.json├─ index.wxml├─ index.js└─…...

如何为C++实习做准备?
博主介绍:程序喵大人 35- 资深C/C/Rust/Android/iOS客户端开发10年大厂工作经验嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手《C20高级编程》《C23高级编程》等多本书籍著译者更多原创精品文章,首发gzh,见文末👇…...

【docker】--部署--安装docker教程
文章目录 环境方法一:脚本安装方法二:手动安装**步骤 1:卸载旧版本(如有)****步骤 2:更新系统并安装依赖****步骤 3:添加 Docker 官方 GPG 密钥****步骤 4:设置 Docker 仓库****步骤…...