gpt2 本地调用调用及其调用配置说明
gpt2 本地调用调用及其调用配置说明
环境依赖安装,模型下载
在大模型应用开发中,需要学会本地调用模型,
要在本地环境调用gpt2 模型需要将模型下载到本地,这里记录本地调用流程:
在huggingface 模型库中查找到需要使用的模型;这里以调用 uer/gpt2-chinese-cluecorpussmall 模型为例。使用transformers 对应模型进行模型下载;
下载模型:
需要先安装 PyTorch 或者 TensorFlow 同时确保能够访问到 https://huggingface.co 网站 否则下载不成功;
pip install torch torchvision torchaudio
pip install tensorflow
#将模板下载到本地
from transformers import AutoModelForCausalLM, AutoTokenizer
#将饭型利分问器卜我到小地,并指定保任路径
model_name ="uer/gpt2-chinese-cluecorpussmall"
cache_dir ="model/uer/gpt2-chinese-cluecorpussmall"
#下载模型
AutoModelForCausalLM.from_pretrained(model_name, cache_dir=cache_dir)
#下载分词库工具
AutoTokenizer.from_pretrained(model_name,cache_dir=cache_dir)
print(f"模型分词器已下载到:{cache_dir}")
模型下载完成后目录结构:

目录文件说明:
调用模型是使用分带有config.json 的目录结对路径
config.json:
{// 激活函数类型,这里使用 GELU 的改进版(gelu_new),常用于 GPT 模型"activation_function": "gelu_new",// 模型架构类型,这里是 GPT2 的带语言模型头的版本(用于文本生成)"architectures": ["GPT2LMHeadModel"],// Attention 层的 dropout 概率(防止过拟合)"attn_pdrop": 0.1,// Embedding 层的 dropout 概率"embd_pdrop": 0.1,// 是否启用梯度检查点(节省显存但降低速度),false 表示不启用"gradient_checkpointing": false,// 参数初始化范围(正态分布的标准差)"initializer_range": 0.02,// Layer Normalization 的 epsilon(防止除以零的小常数)"layer_norm_epsilon": 1e-05,// 模型类型标识(这里是 GPT2)"model_type": "gpt2",// 上下文最大长度(token 数量)"n_ctx": 1024,// Embedding 的维度大小"n_embd": 768,// Attention 头的数量"n_head": 12,// Feed-Forward 层中间维度(null 表示使用默认值 4*n_embd)"n_inner": null,// Transformer 的层数"n_layer": 12,// 模型支持的最大位置编码长度"n_positions": 1024,// 是否输出过去的隐藏状态(兼容性参数)"output_past": true,// 残差连接的 dropout 概率"resid_pdrop": 0.1,// 任务特定参数(这里是文本生成的默认配置)"task_specific_params": {"text-generation": {// 是否使用采样(而非贪婪解码)"do_sample": true,// 生成的最大长度"max_length": 320}},// 使用的 tokenizer 类型(虽然模型是 GPT2,但这里用了 BertTokenizer)"tokenizer_class": "BertTokenizer",// 词表大小(中文 BERT 词表通常为 21128)"vocab_size": 21128
}
special_tokens_map.json:
{// 未知字符标记(遇到不在词表中的字符时使用)"unk_token": "[UNK]",// 分隔符标记(用于分隔两个句子的特殊标记,如句子A和句子B)"sep_token": "[SEP]",// 填充标记(用于将不同长度的序列补齐到相同长度)"pad_token": "[PAD]",// 分类标记(常用于文本分类任务,放在文本开头)"cls_token": "[CLS]",// 掩码标记(用于掩码语言模型MLM任务,如BERT的完形填空)"mask_token": "[MASK]"
}
unk_token
用途:当遇到词表中不存在的字符或单词时使用
示例:“你好[UNK]世界”(中间的词未被词表收录)
注意:所有NLP模型都需要处理OOV(Out-Of-Vocabulary)问题
sep_token
典型场景:
句子对任务(如文本相似度判断)
问答系统(问题和上下文的分隔)
BERT风格格式:[CLS]句子A[SEP]句子B[SEP]
pad_token
功能:
保证batch内样本长度一致
通常配合attention_mask使用(1表示真实token,0表示padding)
训练技巧:计算loss时应忽略padding部分
cls_token
特殊用途:
分类任务中代表整个序列的语义
通常接分类器层[CLS] -> Dense -> Softmax
可视化:可通过注意力权重观察模型如何聚合信息
mask_token
预训练用途:
BERT的MLM任务:“机器[MASK]很厉害” -> “机器学习很厉害”
通常15%的token会被随机mask
微调注意:下游任务中可能不需要此tok
tokenizer_config.json:
使用transformers 进行模型调用:
# 本地离线调用gpa2 模型
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline# 设置具体包含config 本地模型路径
model_name = r"D:\study\ai_lean\PythonProject\gpt2-lean\model\uer\gpt2-chinese-cluecorpussmall\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3"# 加载模型 和分词器tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)# 使用加载的模型和分词器生成文本的 pipelinegenerator = pipeline("text-generation", # pipeline 的类型model=model, # 模型tokenizer=tokenizer, # 分词器device=0, # 设备max_length=100, # 最大长度do_sample=True, # 是否使用采样top_k=10, # 采样的topknum_return_sequences=1, # 返回的文本数量eos_token_id=tokenizer.eos_token_id, # 结束符
)# 生成文本
output = generator("你好,我是一名程序员", num_return_sequences=1, max_length=100)
print(output)
输出结果:
[{‘generated_text’: ‘你好,我是一名程序员 。 我 的 职 业 发 展 是 做 程 序 员 , 但 我 没 有 一 技 之 长 。 所 有 的 事 情 , 我 都 想 着 尽 可 能 的 做 好 。 在 这 里 我 想 说 : 一 个 人 的 一 生 是 有 规 律 的 , 每 个 人 都 是 在 不 断 完 善 , 不 断 探 索 。 我 在 这 个 问 题 上 , 有 自 我 的 判 断’}]
这是调用uer/gpt2-chinese-cluecorpussmall 模型续写的结果,
相关文章:
gpt2 本地调用调用及其调用配置说明
gpt2 本地调用调用及其调用配置说明 环境依赖安装,模型下载 在大模型应用开发中,需要学会本地调用模型, 要在本地环境调用gpt2 模型需要将模型下载到本地,这里记录本地调用流程: 在huggingface 模型库中查找到需要使…...
【Abstract Thought】【Design Patterns】python实现所有个设计模式【下】
前言 彼岸花开一千年,花开花落不相见。 若问花开叶落故,彼岸缘起缘又灭——《我欲封天》 \;\\\;\\\; 目录 前言简单的设计模式复杂的设计模式13责任链14迭代器15备忘录16状态机17模板方法18访问者19观察者20命令Shell21策略22调解23解释器 简单的设计模…...
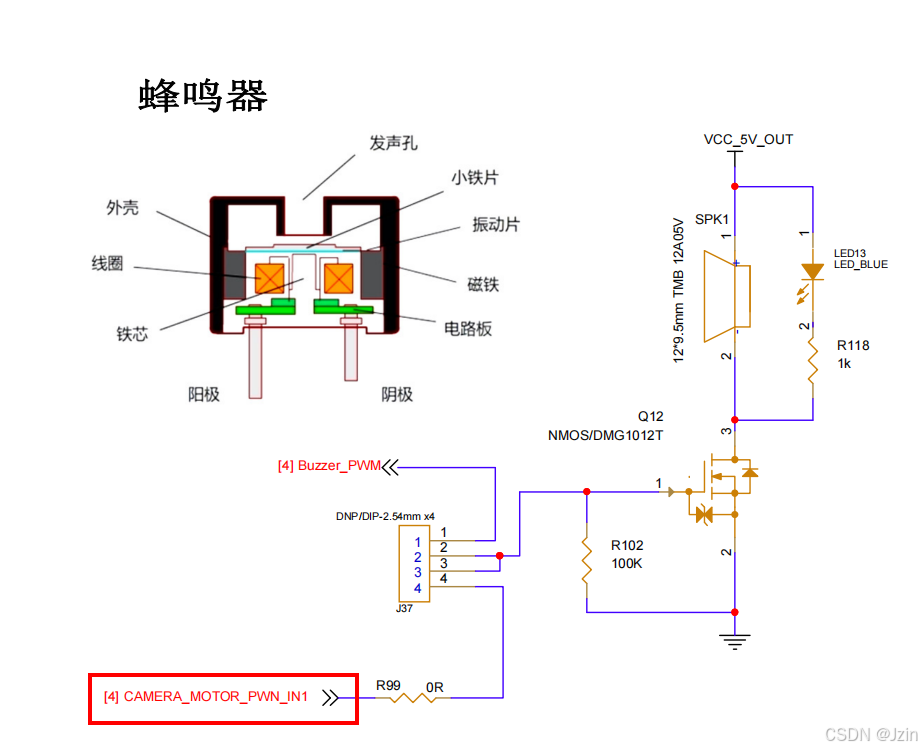
【物联网】PWM控制蜂鸣器
文章目录 一、PWM介绍1.PWM的频率2.PWM的周期 二、PWM工作原理分析三、I.MX6ull PWM介绍1.时钟信号2.工作原理3.FIFO 四、PWM重点寄存器介绍1.PWM Control Register (PWMx_PWMCR)2.PWM Counter Register (PWMx_PWMCNR)3.PWM Period Register (PWMx_PWMPR)4.PWM Sample Register…...
Python----机器学习(基于PyTorch的乳腺癌逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。 一、数据集介绍 在本例中&…...

5分钟学会接口自动化测试框架
今天,我们来聊聊接口自动化测试。 接口自动化测试是什么?如何开始?接口自动化测试框架如何搭建? 自动化测试 自动化测试,这几年行业内的热词,也是测试人员进阶的必备技能,更是软件测试未来发…...
基于FreeRTOS和LVGL的多功能低功耗智能手表(APP篇)
目录 一、简介 二、软件框架 2.1 MDK工程架构 2.2 CubeMX框架 2.3 板载驱动BSP 1、LCD驱动 2、各个I2C传感器驱动 3、硬件看门狗驱动 4、按键驱动 5、KT6328蓝牙驱动 2.4 管理函数 2.4.1 StrCalculate.c 计算器管理函数 2.4.2 硬件访问机制-HWDataAccess 2.4.3 …...
)
visual studio 常用的快捷键(已经熟悉的就不记录了)
以下是 Visual Studio 中最常用的快捷键分类整理,涵盖代码编辑、调试、导航等核心场景: 一、生成与编译 生成解决方案 Ctrl Shift B 一键编译整个解决方案,检查编译错误(最核心的生成操作)编译当前文件 Ctrl F…...

学习记录-接口自动化python数据类型
1.字符串 str "字符串" str_1 字符串1 2.列表[ ] list [1,2,3,4,5,6] list_1 ["boy","girl"] 3.字典{ } key:value 键值对 dict {"name":"小林","age":20} 4.元组( ) tuple …...

大语言模型深度思考与交互增强
总则:深度智能交互的全面升级 在主流大语言模型(LLM)与用户的每一次交互中,模型需于回应或调用工具前,展开深度、自然且无过滤的思考进程。当模型判断思考有助于提升回复质量时,必须即时进行全方位的思考与…...

<C#> 详细介绍.NET 依赖注入
在 .NET 开发中,依赖注入(Dependency Injection,简称 DI)是一种设计模式,它可以增强代码的可测试性、可维护性和可扩展性。以下是对 .NET 依赖注入的详细介绍: 1. 什么是依赖注入 在软件开发里࿰…...

布局决定终局:基于开源AI大模型、AI智能名片与S2B2C商城小程序的战略反推思维
摘要:在商业竞争日益激烈的当下,布局与终局预判成为企业成功的关键要素。本文探讨了布局与终局预判的智慧性,强调其虽无法做到百分之百准确,但能显著提升思考能力。终局思维作为重要战略工具,并非一步到位的战略部署&a…...

构建面向大模型训练与部署的一体化架构:从文档解析到智能调度
作者:汪玉珠|算法架构师 标签:大模型训练、数据集构建、GRPO、自监督聚类、指令调度系统、Qwen、LLaMA3 🧭 背景与挑战 随着 Qwen、LLaMA3 等开源大模型不断进化,行业逐渐从“能跑通”迈向“如何高效训练与部署”的阶…...

告别循环!用Stream优雅处理集合
什么是stream? 也叫Stream流,是jdk8新增的一套API(java.util.stream.*)可以用于操作集合或者数组的数据。 优势:Stream流大量的结合了Lambda语法的风格编程,提供了一种更加强大,更加简单的方式…...

Linux电源管理、功耗管理 和 发热管理 (CPUFreq、CPUIdle、RPM、thermal、睡眠 和 唤醒)
1 架构图 1.1 Linux内核电源管理的整体架构 《Linux设备驱动开发详解:基于最新的Linux4.0内核》图19.1 1.2 通用的低功耗软件栈 《SoC底层软件低功耗系统设计与实现》 1.3 低功耗系统的架构设计;图1-3 2 系统级睡眠和唤醒管理 Linux系统的待机、睡眠…...
OSCP - Proving Grounds -FunboxEasy
主要知识点 弱密码路径枚举文件上传 具体步骤 首先是nmap扫描一下,虽然只有22,80和3306端口,但是事情没那么简单 Nmap scan report for 192.168.125.111 Host is up (0.45s latency). Not shown: 65532 closed tcp ports (reset) PORT …...

探索 Go 与 Python:性能、适用场景与开发效率对比
1 性能对比:执行速度与资源占用 1.1 Go 的性能优势 Go 语言被设计为具有高效的执行速度和低资源占用。它编译后生成的是机器码,能够直接在硬件上运行,避免了 Python 解释执行的开销。 以下是一个用 Go 实现的简单循环计算代码: …...
与析构函数(Destructor))
c++:构造函数(Constructor)与析构函数(Destructor)
目录 为什么我们需要构造函数? 什么是构造函数? 🧬 本质:构造函数是“创建对象的一部分” 为什么 需要析构函数? 什么是析构函数? 析构函数的核心作用 ❗注意点 为什么我们需要构造函数?…...

三周年创作纪念日
文章目录 回顾与收获三年收获的五个维度未来的展望致谢与呼唤 亲爱的社区朋友们,大家好! 今天是 2025 年 4 月 14 日,距离我在 2022 年 4 月 14 日发布第一篇技术博客《SonarQube 部署》整整 1,095 天。在这条创作之路上,我既感慨…...
Vue 3 国际化实战:支持 Element Plus 组件和语言持久化
目录 Vue 3 国际化实战:支持 Element Plus 组件和语言持久化实现效果:效果一、中英文切换效果二、本地持久化存储效果三、element Plus国际化 vue3项目国际化实现步骤第一步、安装i18n第二步、配置i18n的en和zh第三步:使用 vue-i18n 库来实现…...

1.阿里云快速部署Dify智能应用
一、宝塔面板 宝塔面板是一款功能强大且易于使用的服务器管理软件,支持Linux和Windows系统,通过web端可视化操作,优化了建站流程,提供安全管理、计划任务、文件管理以及软件管理等功能。 1.1 宝塔面板的特点与优势 易用性 宝塔面…...

Ubuntu与windows时间同步
由于ubuntu每次重启后时间老是不对,所以使用ntp服务,让ubuntu作为客户端,去同步windows时间。 一、windows服务端配置 1、启用ntp服务 # 启动W32Time服务(若未启动) net start w32time # 配置服务为NTP模式 w32tm /…...

在pycharm配置虚拟环境和jupyter,解决jupyter运行失败问题
记录自己pycharm环境配置和解决问题的流程。 解决pycharm无法运行jupyter代码,仅运行import板块显示运行失败,但是控制台不输出任何错误信息,令人困惑。 遇到的问题是:运行代码左下角显示运行失败但是有没有任何的输出错误信息。 …...

Vue 技术解析:从核心概念到实战应用
Vue.js 是一款流行的渐进式前端框架,以其简洁的 API、灵活的组件化结构和高效的响应式数据绑定而受到开发者的广泛欢迎。本文将深入解析 Vue 技术的核心概念、原理和应用场景,帮助开发者更好地理解和使用 Vue.js。 一、Vue 的设计哲学与核心概念 &…...

Series和 DataFrame是 Pandas 库中的两种核心数据结构
Series 和 DataFrame 是 Pandas 库中的两种核心数据结构,它们各有特点和用途。理解它们之间的区别有助于更高效地进行数据分析和处理。以下是 Series 和 DataFrame 的主要区别: 1. 维度 Series:是一维的数组,可以存储任何类型的…...

关于异步消息队列的详细解析,涵盖JMS模式对比、常用组件分析、Spring Boot集成示例及总结
以下是关于异步消息队列的详细解析,涵盖JMS模式对比、常用组件分析、Spring Boot集成示例及总结: 一、异步消息核心概念与JMS模式对比 1. 异步消息核心组件 组件作用生产者发送消息到消息代理(如RabbitMQ、Kafka)。消息代理中间…...

利用 Python 进行股票数据可视化分析
在金融市场中,股票数据的可视化分析对于投资者和分析师来说至关重要。通过可视化,我们可以更直观地观察股票价格的走势、交易量的变化以及不同股票之间的相关性等。 Python 作为一种功能强大的编程语言,拥有丰富的数据处理和可视化库…...

【Docker】离线安装Docker
背景 离线安装Docker的必要性,第一,在目前数据安全升级的情况下,很多外网已经基本不好访问了。第二,如果公司有对外部署的需求,那么难免会存在对方只有内网的情况,那么我们就要做到学会离线安装。 下载安…...

kubectl命令补全以及oc命令补全
kubectl命令补全 1.安装bash-completion 如果你用的是Bash(默认情况下是),先安装补全功能支持包 sudo apt update sudo apt install bash-completion -y2.为kubectl 启用补全功能 会话中临时: source <(kubectl completion bash)持久化配置&#x…...

《 C++ 点滴漫谈: 三十三 》当函数成为参数:解密 C++ 回调函数的全部姿势
一、前言 在现代软件开发中,“解耦” 与 “可扩展性” 已成为衡量一个系统架构优劣的重要标准。而在众多实现解耦机制的技术手段中,“回调函数” 无疑是一种高效且广泛使用的模式。你是否曾经在编写排序算法时,希望允许用户自定义排序规则&a…...
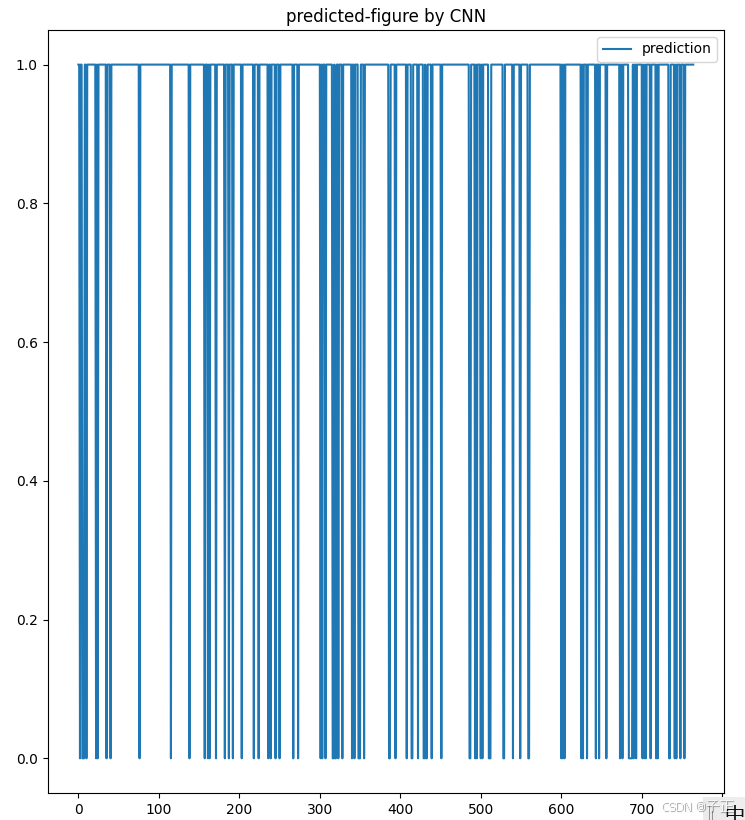
极简cnn-based手写数字识别程序
1.先看看识别效果: 这个程序识别的是0~9的一组手写数字,这是最终的识别效果,为1,代表识别成功,0为失败。 然后数据源是:ds deeplake.load(hub://activeloop/optical-handwritten-digits-train)里面是一组…...