MIP-Splatting:全流程配置与自制数据集测试【ubuntu20.04】【2025最新版】
一、引言
在计算机视觉和神经渲染领域,3D场景重建与渲染一直是热门研究方向。近期,3D高斯散射(3D Gaussian Splatting)因其高效的渲染速度和优秀的视觉质量而受到广泛关注。然而,当处理大型复杂场景时,这种方法面临着内存消耗过大和训练效率低下的问题。2024年,来自德国图宾根大学自主视觉团队(Autonomous Vision Group)开发的MIP-Splatting【CVPR 2024 Best Student Paper】提出了创新性解决方案,通过引入多尺度表示和兴趣点策略,显著提高了系统的性能和效率。
本文记录了我对MIP-Splatting技术的完整复现过程,从理论基础到环境配置,再到训练测试,全面展示这项技术的优势和实现细节。无论你是计算机视觉研究者,还是对三维重建感兴趣的开发者,这篇博客都将帮助你理解并应用这一前沿技术。

该项目由德国图宾根大学的自主视觉团队(Autonomous Vision Group)开发,该团队在计算机视觉、神经渲染和3D重建领域享有盛誉。主要团队成员包括来自图宾根大学和马克斯·普朗克智能系统研究所的研究人员
该项目已在GitHub上完全开源,包括源代码、预训练模型和示例数据。
代码库:https://github.com/autonomousvision/mip-splatting
二、技术原理解析
2.1 3DGS简介
3DGS是一种新型神经渲染技术,它使用3D空间中的高斯点云来表示场景。每个高斯点包含位置、旋转、缩放和颜色信息,可以通过差分光栅化进行高效渲染。与传统的神经辐射场(NeRF)相比,这种方法实现了数量级更快的渲染速度,同时保持了高质量的视觉效果。
2.2 MIP-Splatting核心创新
MIP-Splatting在3D高斯散射的基础上,引入了两个关键创新:
- 多分辨率表示(Multi-resolution Representation):类似于传统图形学中的MIP映射(Mipmapping),MIP-Splatting构建了多层级的高斯点表示。当观察者距离场景较远时,系统会使用低分辨率表示,减少渲染计算量;当观察者靠近时,则采用高分辨率表示,保证细节质量。这种多尺度策略极大地提高了渲染效率。
- 兴趣点策略(Interest Points):MIP-Splatting引入了兴趣点检测机制,自动识别场景中视觉上重要的区域,并在这些区域分配更多的高斯点,而在不重要的区域使用更少的点。这种自适应分配优化了内存使用和计算资源。
- 自适应优化(Adaptive Optimization):动态调整高斯点的分布和密度;智能分配计算资源,将更多资源用于视觉上重要的区域
2.3 技术优势
MIP-Splatting相比传统3DGS具有以下显著优势:
- 内存效率:在相同质量下,内存使用减少50-80%
- 训练速度:训练时间缩短40-60%
- 渲染质量:特别在远距离场景中,质量显著提升
- 可扩展性:能够处理更大规模的复杂场景
2.4 优缺点分析
(1)优点
- 显著降低内存需求,使大场景渲染更加实用
- 保持了实时渲染能力,同时提高了视觉质量
- 多分辨率表示使其更适合不同距离的渲染
- 完全开源,易于研究和扩展
(2)缺点
- 兴趣点检测可能需要额外的计算资源
- 多分辨率表示增加了实现的复杂性
- 对硬件要求仍然较高(需要现代GPU)
- 在极其复杂的场景中可能仍有优化空间
2.5 推荐测试数据集
MIP-Splatting作者推荐的测试数据集包括:
- NeRF 合成数据集:从 Google Drive 下载。
Google Drive 该地址貌似已经挂了,可以点击以下链接从百度飞桨进行下载
https://aistudio.baidu.com/datasetdetail/136816下载并解压缩nerf_synthetic.zip - Mip-NeRF 360 数据集:从 Mip-NeRF 360 下载,可能需额外请求某些场景。
- 自定义数据集:项目提供了处理自定义数据的工具
三、主要工作流程
3.1 初始化:从输入图像集合中重建初始点云(通常使用COLMAP)
3.2 兴趣点检测:分析场景,识别视觉上重要的区域
3.3 多分辨率构建:创建不同分辨率级别的高斯点表示
3.4 优化阶段:
-
位置优化:调整高斯点的空间位置
-
外观优化:优化颜色和不透明度
-
形状优化:调整高斯点的形状和方向
-
密度优化:根据场景复杂度动态调整高斯点密度
3.5 渲染:基于视点位置和方向,实时渲染场景
四、环境配置与安装
2.1 硬件要求
在开始前,确保你的系统满足以下硬件要求:
- CUDA兼容的GPU(建议至少8GB VRAM,理想为16GB+)
- 至少16GB系统RAM
- 充足的存储空间(建议SSD)
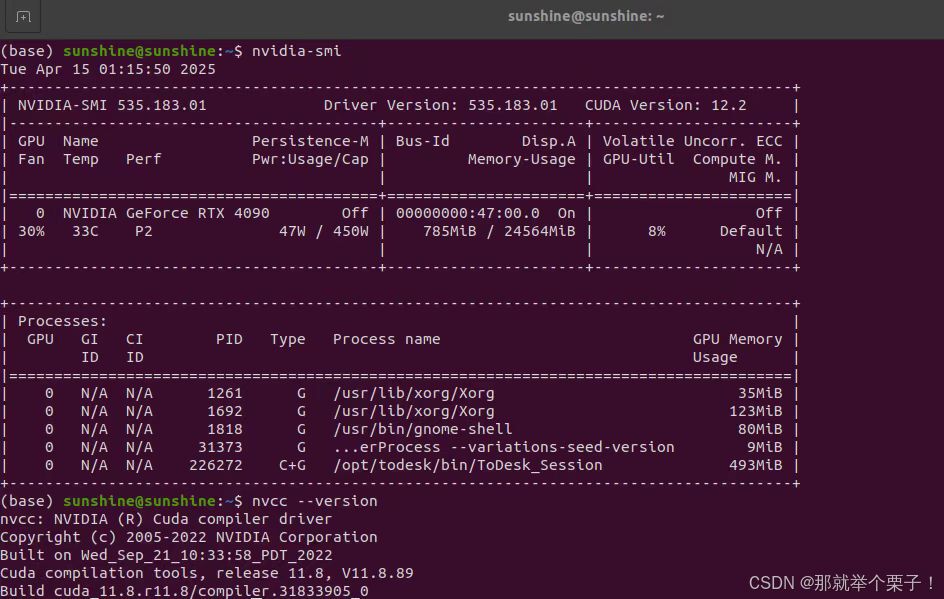
我的测试环境是:
- 系统: Ubuntu 20.04 LTS
- RAM: 64GB
- GPU: NVIDIA GeForce RTX 4090(24GB VRAM)
2.1 环境配置
1、克隆仓库
从 GitHub 克隆项目
git clone https://github.com/autonomousvision/mip-splatting.git
cd mip-splatting
2、创建虚拟环境
使用Conda创建独立的虚拟环境是一个良好实践,它可以避免依赖冲突并方便环境管理:
# 创建名为mip-splatting的conda环境
conda create -y -n mip-splatting python=3.8
conda activate mip-splatting
3、安装依赖库
安装过程需要特别注意PyTorch与CUDA版本的匹配:
# 安装PyTorch(确保与你的CUDA版本兼容)
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 -f https://download.pytorch.org/whl/torch_stable.html
conda install cudatoolkit-dev=11.3 -c conda-forge# 安装基本依赖
pip install -r requirements.txt# 安装扩展库
pip install submodules/diff-gaussian-rasterization
pip install submodules/simple-knn/在安装过程中,如果遇到PyTorch与CUDA版本不匹配的问题。解决方法是确认自己的CUDA版本(nvcc --version),然后安装相应版本的PyTorch。
4 验证安装
安装完成后,建议验证环境是否正确配置:
python -c "import torch; print('CUDA available:', torch.cuda.is_available()); print('CUDA version:', torch.version.cuda); print('GPU count:', torch.cuda.device_count()); print('GPU name:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'None')"
如果一切正常,你应该能看到GPU信息和CUDA可用状态。
还可以通过conda list 查看虚拟环境中所安装的库
环境配置完毕!!
五、数据集准备
5.1 准备NeRF合成数据集
为了初步测试系统功能,我首先使用了项目推荐的的数据集:
- NeRF 合成数据集:从 Google Drive 下载。
Google Drive 该地址貌似已经挂了,可以点击以下链接从百度飞桨进行下载
https://aistudio.baidu.com/datasetdetail/136816下载并解压缩nerf_synthetic.zip
tar -xvf nerf_synthetic.tar # 解压文件
然后再项目目录下新建一个data文件夹,将nerf_synthetic放在里面
mkdir -p data
mv nerf_synthetic data/
目录结构如下图所示:
mip-splatting/
├── data/
│ ├── nerf_synthetic/
│ │ ├── bonsai/
│ │ ├── chair/
│ │ └── …
│ ├── mipnerf360/ (可选)
└── …
5.2 NeRF合成数据集转化
因为 mip-splatting 项目使用的是不同于 NeRF/Blender 的多尺度训练数据格式,你必须先转为它支持的目录结构和 JSON 格式,否则训练和渲染会出错
5.2.1 原始 NeRF 数据集结构(如 nerf_synthetic/lego)
lego/
├── images/ ← 原始图像
├── transforms_train.json
├── transforms_val.json
├── transforms_test.json
这种结构适用于 NeRF + instant-ngp + mip-NeRF 系列项目,但 mip-splatting 不能直接读取
mip-splatting 不直接支持这种格式的原因是
它需要读取:
-
多分辨率图像(如 images_2, images_4)
-
metadata.json 中描述图像 → 相机参数 → 分辨率
-
统一的路径结构,如 d0/, d1/, d2/…
-
所以必须做格式转换
5.2.2 数据集转换
python convert_blender_data.py --blender_dir nerf_synthetic/ --out_dir multi-scale
- –blender_dir :nerf_synthetic/
指向原始 NeRF 数据所在的主目录(例如 nerf_synthetic/lego) - –out_dir:multi-scale
指定输出路径,用于保存转换后的 mip-splatting 格式数据
这行代码可将NeRF 合成数据集(Blender 格式)转换为 mip-splatting 所需的多尺度训练格式。
将 nerf_synthetic/{scene} 下的数据(如 transforms_train.json, images/ 等),转换为 multi-scale/{scene} 下的多尺度结构,包括 d0/, d1/, metadata.json 等。
如下图所示:
六、训练与评估
现在,可以使用官方数据集测试项目是否正常运行。
6.1 运行 NeRF 合成数据集(单尺度+多尺度训练):
# single-scale training and multi-scale testing on NeRF-synthetic dataset
python scripts/run_nerf_synthetic_stmt.py
# multi-scale training and multi-scale testing on NeRF-synthetic dataset
python scripts/run_nerf_synthetic_mtmt.py
训练结束后会分别生成单多尺度训练文件夹,如下图所示
七、在线查看
训练后,可以将 3D 平滑滤波器与高斯参数融合在一起
python create_fused_ply.py -m {model_dir}/{scene} --output_ply fused/{scene}_fused.ply"
## 在这里我们使用了如下代码
python create_fused_ply.py -m multi-scale/chair --output_ply fused/chair_fused.ply
会在fused目录下生成chair_fused.ply文件
然后可以使用的在线3D查看器来可视化经过训练的模型

八、自制数据集训练【使用自制图片数据集】
8.1 准备自己的图片
(1)拍摄场景的多视角图片:
- 拍摄 20-100 张照片,从不同角度覆盖整个场景
- 保持适当的重叠度(相邻图片有约 60-70% 的重叠)
- 避免运动模糊和光照变化
- 使用高质量相机,保持固定焦距
(2)创建数据目录结构:
# 创建目录来存放图片
mkdir -p data/3dgsdata/1/input
# 将您的图片复制到这个目录
cp /path/to/your/photos/*.jpg data/3dgsdata/1/input
8.2 使用 COLMAP 进行结构化数据处理
MIP-Splatting 需要使用 COLMAP 生成的相机参数和稀疏点云。以下是完整步骤:
(1) 安装 COLMAP
#安装依赖
sudo apt-get install git cmake ninja-build build-essential libboost-program-options-dev libboost-filesystem-dev libboost-graph-dev libboost-system-dev libeigen3-dev libflann-dev libfreeimage-dev libmetis-dev libgoogle-glog-dev libgtest-dev libsqlite3-dev libglew-dev qtbase5-dev libqt5opengl5-dev libcgal-dev libceres-dev# 下载colmap
git clone https://github.com/colmap/colmap.git
#进入文件夹
cd colmap
git checkout 3.7
#创建并进入build文件夹
mkdir build
cd build#构建安装
cmake .. -GNinja #CMake预处理,生成Ninja构建系统所需的文件
ninja #默认使用系统最大可用cpu核心数进行编译,如果系统cpu有32个核,等效与ninja -j32
sudo ninja install
(2)运行 COLMAP 处理
MIP-Splatting 提供了一个脚本来自动运行 COLMAP 并准备数据格式:
# 返回到 mip-splatting 目录
cd /path/to/mip-splatting# 运行 COLMAP 数据处理脚本,为相机参数创建必要的文件
python convert.py -s data/3dgsdata/1 --resize# 参数说明:
# --s: 指定包含图片的数据目录
# --resize: 使用标志时,创建图像的缩小版本(50%、25%、12.5%)这个脚本会:
- 运行 COLMAP 的特征提取和匹配
- 执行增量式重建
- 转换 COLMAP 输出为 MIP-Splatting 所需的格式
- 生成训练/测试分割
生成的文件夹目录如图所示
/path/to/your/images//input # Your original images/images # Original size images processed by COLMAP/images_2 # 50% scaled images/images_4 # 25% scaled images/images_8 # 12.5% scaled images/sparse # Camera parameters
8.3 训练模型
1、单尺度训练(STMT)
python train.py -s data/3dgsdata/1 -m output/1 --eval --kernel_size 0.1
## 参数意义
-s data/3dgsdata/1 设置输入数据路径。该目录应包含 images/ 和转换后的 transforms_train.json
-m output/1 设置模型输出路径。训练中会将 checkpoint 和日志保存到该路径下
--eval 每隔一段迭代自动执行一次测试(调用 render()),生成结果图像和指标,如果不添加此参数,后续无法计算指标
--kernel_size 0.1 控制初始高斯点的半径,影响点的体积。值越大表示点云分布越粗,越小越精细。推荐值 0.03~0.12、多尺度训练
python train.py -s data/3dgsdata/1 -m output/1 --eval --load_allres --sample_more_highres --kernel_size 0.1
## 参数意义
-s data/3dgsdata/1 设置输入数据路径。该目录应包含 images/ 和转换后的 transforms_train.json
-m output/1 设置模型输出路径。训练中会将 checkpoint 和日志保存到该路径下
--eval 每隔一段迭代自动执行一次测试(调用 render()),生成结果图像和指标,如果不添加此参数,后续无法计算指标
##额外多的参数
--load_allres 加载多分辨率图像(如 images_2, images_4,这些来自 convert.py --resize)
--sample_more_highres 在训练采样中优先选择更高分辨率的图像,以增强高精细区域的学习效果--kernel_size 0.1 控制初始高斯点的半径,影响点的体积。值越大表示点云分布越粗,越小越精细。推荐值 0.03~0.13、训练效果对比
为了更大发挥模型性能,此处采用了多尺度训练方式,如下图所示:


Training progress: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30000/30000 [14:50<00:00, 33.69it/s, Loss=0.0067375]
[ITER 30000] Evaluating test: L1 0.005026974682030933 PSNR 33.37032018389021 [14/04 19:31:06]
[ITER 30000] Evaluating train: L1 0.003797494899481535 PSNR 37.59125595092774 [14/04 19:31:06]
[ITER 30000] Saving Gaussians [14/04 19:31:06]
Training complete. [14/04 19:31:07]
real 15m2.915s
user 15m6.362s
sys 0m17.852s
8.4 模型渲染
# 渲染新视角,生成模型输出图像
python render.py -m output/1 --skip_train
## 参数介绍
python render.py 执行渲染脚本。该脚本读取测试数据 + 已训练模型,输出渲染结果图像
-m output/1 指定模型路径
--skip_train 表示跳过训练集图像的渲染,仅对测试集进行渲染(节省时间和显存)
no --skip_train 对训练集和测试及都会进行渲染
## 代码作用
使用路径 output/1 下保存的模型,执行测试图像的渲染过程,生成预测图像(test_preds)和对应的 GT(ground truth)对齐图像,用于后续评估(如 SSIM、PSNR、LPIPS)会在 output/1/ 中生成如下内容:
output/1/
├── config.yml ← 模型配置文件
├── checkpoint_30000.pth ← 最终模型权重
└── test/└── ours_30000/├── test_preds_1/ ← 渲染预测图像└── gt_1/ ← 对齐 ground truth 图像(真实图)
输出图像格式说明
每个测试视角图像(如 00001.png, 00002.png)会保存两份:
output/1/test/ours_30000/
├── test_preds_1/ ← 模型预测图像
├── gt_1/ ← 对齐的 Ground Truth 图像
这些将被 metrics.py 用于计算 SSIM / PSNR / LPIPS 等指标
运行代码如下图所示:

8.5 评估模型
# 指标评估
python metrics.py -m output/1
## 参数介绍
-m output/1 指定模型路径
## 可选参数
-r 或 --resolution 默认-1 设置用于评估的分辨率等级:1 表示使用 images;2 表示 images_2;依此类推。-1 为自动匹配 默认优先选 test_preds_1/(即分辨率等级为 1 的图像),会自动查找 ours_30000/ 目录下的 test_preds_* 子文件夹,所以评估的是原始图像分辨率下的结果,对应模型训练时 d0
## 代码作用
使用 output/1 中的测试结果图像(test_preds 与 gt),计算图像质量评估指标:SSIM、PSNR、LPIPS。
这是最终量化模型好坏的关键步骤,常用于论文报告与模型对比。
metrics.py 的工作流程
执行这条命令后会依次完成以下步骤:
(1)加载预测图与 GT 图:
-
从 output/1/test/ours_30000/test_preds_1/ 中读取预测图像
-
从 output/1/test/ours_30000/gt_1/ 中读取对应的 GT 图像
-
每对图像都会被读取为 tensor 并送入指标计算器
(2)计算三种指标:
-
SSIM(结构相似度)
-
PSNR(峰值信噪比)
-
LPIPS(感知图像距离,加载 VGG 特征网络)
各个指标含义详解

输出结果(控制台 + 文件):
-
控制台输出:

Scene: output/1
Method: ours_30000
Metric evaluation progress: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:00<00:00, 11.17it/s]
SSIM : 0.9742036
PSNR : 33.3556633
LPIPS: 0.0743872 -
保存文件:
output/1/results.json:总体指标
output/1/per_view.json:每张图像的指标值
8.6 后处理
(1)创建包含 3D 平滑参数的融合 PLY 文件:

2)使用在线查看器以交互方式浏览您的场景:
- 将融合 PLY 上传到 [Mip-Splatting 在线查看器]
- 或者,如果已设置查看器,则在本地查看
相关文章:
MIP-Splatting:全流程配置与自制数据集测试【ubuntu20.04】【2025最新版】
一、引言 在计算机视觉和神经渲染领域,3D场景重建与渲染一直是热门研究方向。近期,3D高斯散射(3D Gaussian Splatting)因其高效的渲染速度和优秀的视觉质量而受到广泛关注。然而,当处理大型复杂场景时,这种…...
怎样完成本地模型知识库检索问答RAG
怎样完成本地模型知识库检索问答RAG 目录 怎样完成本地模型知识库检索问答RAG使用密集检索器和系数检索器混合方式完成知识库相似检索1. 导入必要的库2. 加载文档3. 文本分割4. 初始化嵌入模型5. 创建向量数据库6. 初始化大语言模型7. 构建问答链8. 提出问题并检索相关文档9. 合…...
XCTF-web(三)
xff_referer 拦截数据包添加:X-Forwarded-For: 123.123.123.123 添加:Referer: https://www.google.com baby_web 提示:想想初始页面是哪个 查看/index.php simple_js 尝试万能密码,没有成功,在源码中找到如下…...

使用Python+xml+shutil修改目标检测图片和对应xml标注文件
使用Pythonxmlshutil修改目标检测图片文件名和对应xml标注文件: import os import glob import xml.etree.ElementTree as et import shutildef change_labels(source_dir):name_id 18001file_list glob.glob(os.path.join(source_dir, "*.xml"))print…...

How AI could empower any business - Andrew Ng
How AI could empower any business - Andrew Ng References 人工智能如何为任何业务提供支持 empower /ɪmˈpaʊə(r)/ vt. 授权;给 (某人) ...的权力;使控制局势;增加 (某人的) 自主权When I think about the rise of AI, I’m reminded …...

地理人工智能中位置编码的综述:方法与应用
以下是对论文 《A Review of Location Encoding for GeoAI: Methods and Applications》 的大纲和摘要整理: A Review of Location Encoding for GeoAI: Methods and Applications 摘要(Summary) 本文系统综述了地理人工智能(G…...
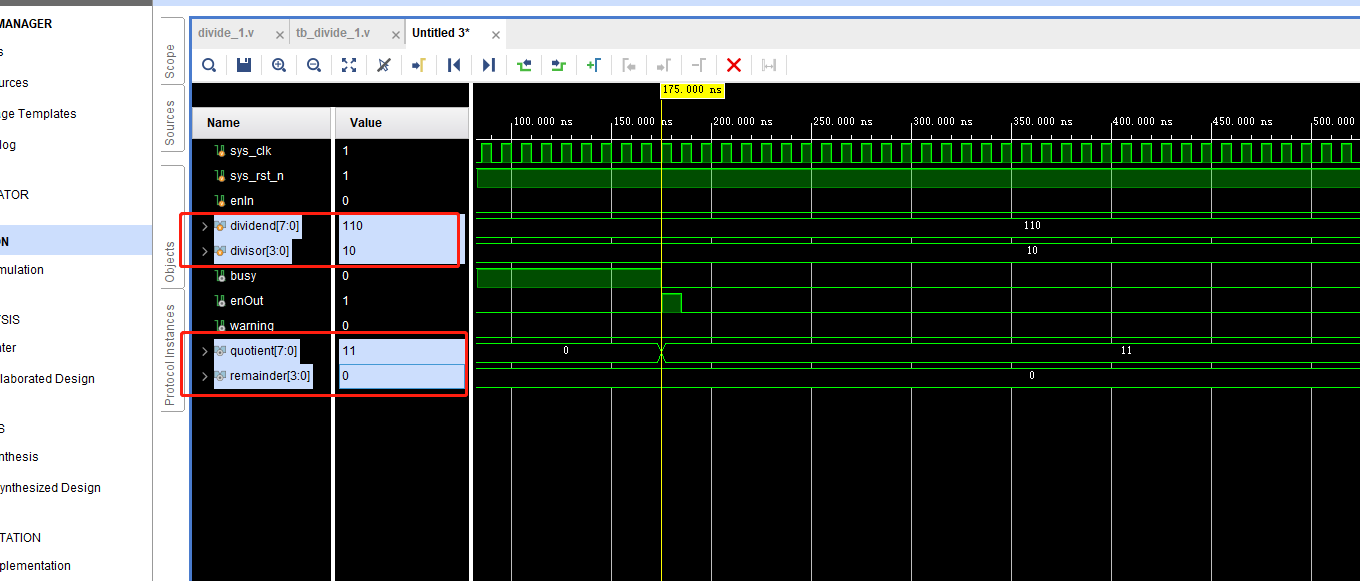
Verilog的整数除法
1、可变系数除法实现----利用除法的本质 timescale 1ns / 1ps // // Company: // Engineer: // // Create Date: 2025/04/15 13:45:39 // Design Name: // Module Name: divide_1 // Project Name: // Target Devices: // Tool Versions: // Description: // // Depe…...

C++ | STL之list详解:双向链表的灵活操作与高效实践
引言 std::list 是C STL中基于双向链表实现的顺序容器,擅长高效插入和删除操作,尤其适用于频繁修改中间元素的场景。与std::vector不同,std::list的内存非连续,但提供了稳定的迭代器和灵活的元素管理。本文将全面解析std::list的…...
React 把一系列 state 更新加入队列
把一系列 state 更新加入队列 设置组件 state 会把一次重新渲染加入队列。但有时你可能会希望在下次渲染加入队列之前对 state 的值执行多次操作。为此,了解 React 如何批量更新 state 会很有帮助。 开发环境:Reacttsantd 学习内容 什么是“批处理”以…...
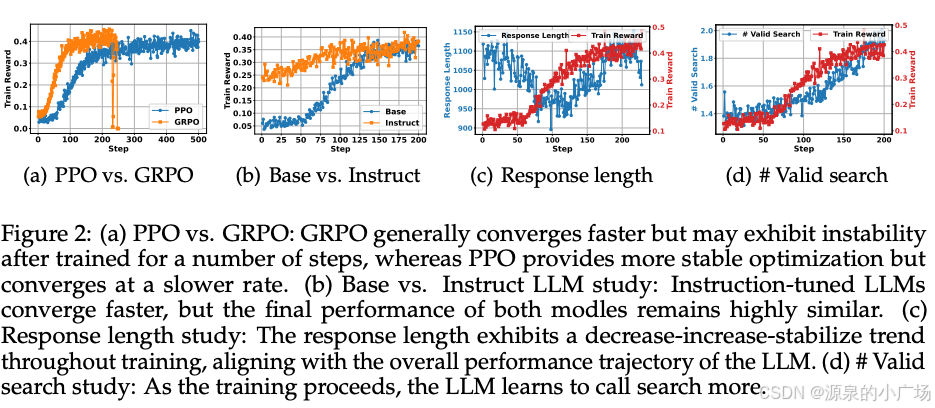
【大模型理论篇】Search-R1: 通过强化学习训练LLM推理与利⽤搜索引擎
最近基于强化学习框架来实现大模型在推理和检索能力增强的项目很多,也是Deep Research技术持续演进的缩影。之前我们讨论过《R1-Searcher:通过强化学习激励llm的搜索能⼒》,今天我们分析下Search-R1【1】。 1. 研究背景与问题 ⼤模型(LLM&a…...

Google政策大更新:影响金融,新闻,社交等所有类别App
Google Play 4月10日 迎来了2025年第一次大版本更新,新政主要涉及金融(个人贷款),新闻两个行业。但澄清内容部分却使得所有行业都需进行一定的更新。下面,我们依次从金融(个人贷款),…...
)
什么时候触发full GC(发生场景)
文章目录 1. 老年代空间不足2. 分配担保失败3. 显式调用`System.gc()`4. 元空间/永久代空间不足5. CMS/G1的并发失败6. 空间分配担保机制7. 堆内存碎片化8. 其他场景总结回答在Java中,Full GC(全局垃圾回收)会回收整个堆内存(包括年轻代、老年代)以及元空间(或永久代)。…...
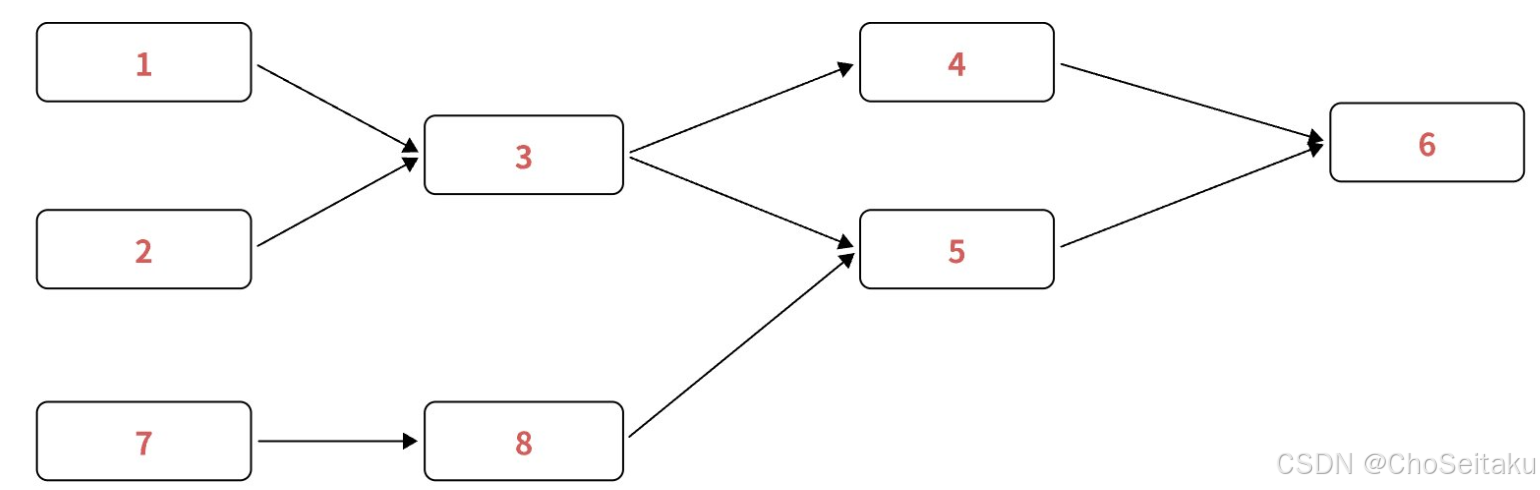
NO.93十六届蓝桥杯备战|图论基础-拓扑排序|有向无环图|AOV网|摄像头|最大食物链计数|杂物(C++)
有向⽆环图 若⼀个有向图中不存在回路,则称为有向⽆环图(directed acycline graph),简称 DAG 图 AOV⽹ 举⼀个现实中的例⼦:课程的学习是有优先次序的,如果规划不当会严重影响学习效果。课程间的先后次序可以⽤有向图表⽰ 在…...
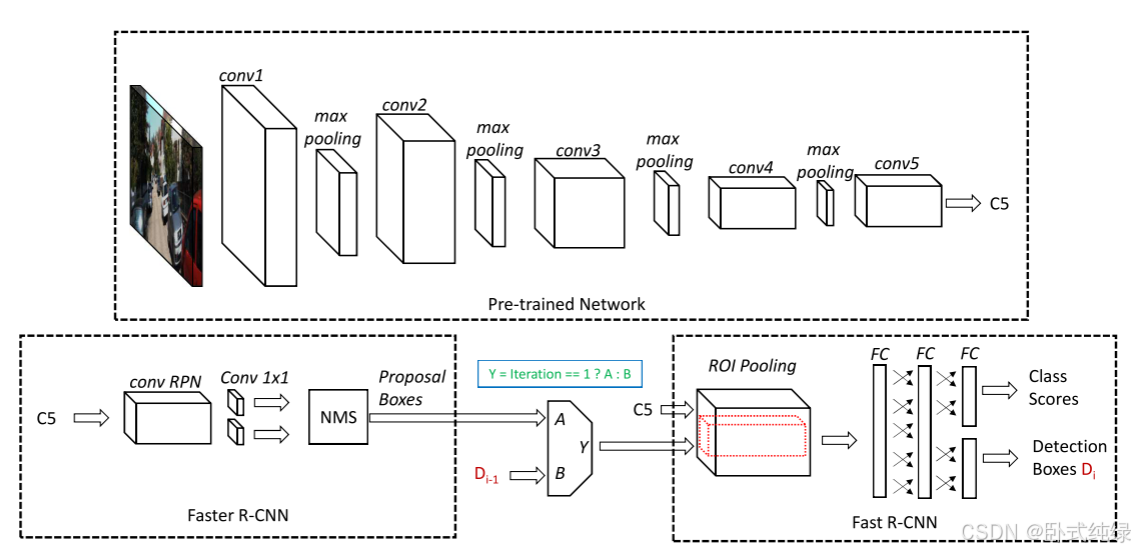
每日文献(十三)——Part one
今天看的是《RefineNet: Iterative Refinement for Accurate Object Localization》。 目录 零、摘要 0.1 原文 0.2 译文 一、介绍 二、RefineNet A. Fast R-CNN B. Faster R-CNN C. RefineNet 训练 D. RefineNet 测试 零、摘要 0.1 原文 We investigate a new str…...

游戏引擎学习第225天
只能说太难了 回顾当前的进度 我们正在进行一个完整游戏的开发,并在直播中同步推进。上周我们刚刚完成了过场动画系统的初步实现,把开场动画基本拼接完成,整体效果非常流畅。看到动画顺利呈现,令人十分满意,整个系统…...

git提取出指定提交所涉及的所有文件
当需要提取出某次提交所修改过的所有的文件时,可以使用如下命令,该命令来自文心一言 mkdir temp_dir git diff-tree --no-commit-id --name-only -r <commit-hash> | xargs -I {} cp --parents {} temp_dir/--no-commit-id:不显示提交…...

Linux 使用Nginx搭建简易网站模块
网站需求: 一、基于域名[www.openlab.com](http://www.openlab.com)可以访问网站内容为 welcome to openlab 二、给该公司创建三个子界面分别显示学生信息,教学资料和缴费网站,基于[www.openlab.com/student](http://www.openlab.com/stud…...
抖音ai无人直播间助手场控软件
获取API权限 若使用DeepSeek官方AI服务,登录其开发者平台申请API Key或Token。 若为第三方AI(如ChatGPT),需通过接口文档获取访问权限。 配置场控软件 打开DeepSeek场控软件,进入设置界面找到“AI助手”或“自动化”…...
)
深度解析Redis过期字段清理机制:从源码到集群化实践 (二)
本文紧跟 上一篇 深度解析Redis过期字段清理机制:从源码到集群化实践 (一) 可以从redis合集中查看 八、Redis内核机制深度解析 8.1 Lua脚本执行引擎原理 Lua脚本执行流程图技术方案 执行全流程解析: #mermaid-svg-X51Gno…...
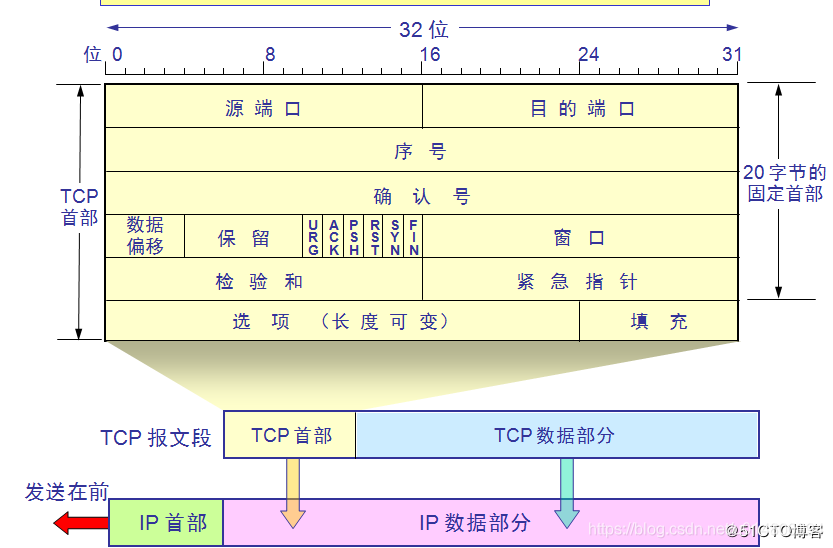
TCP标志位抓包
说明 TCP协议的Header信息,URG、ACK、PSH、RST、SYN、FIN这6个字段在14字节的位置,对应的是tcp[13],因为字节数是从[0]开始数的,14字节对应的就是tcp[13],因此在抓这几个标志位的数据包时就要明确范围在tcp[13] 示例1…...
)
如何实现动态请求地址(baseURL)
需求: 在项目中遇到了需要实时更换请求地址,后续使用修改后的请求地址(IP) 例如:原ip请求为http://192.168.1.1:80/xxx,现在需要你点击或其他操作将其修改为http://192.168.1.2:80/xxx,该如何操作 tips: 修改后需要跳转( 修改了IP之前的不可使用,需要访问修改后的地址来操作 …...

封装一个搜索区域 SearchForm.vue组件
父组件 <template><div><SearchForm:form-items"searchItems":initial-values"initialValues"search"handleSearch"reset"handleReset"><!-- 自定义插槽内容 --><template #custom-slot"{ form }&qu…...

《ADVANCING MATHEMATICAL REASONING IN LAN- GUAGE MODELS》全文阅读
《ADVANCING MATHEMATICAL REASONING IN LAN- GUAGE MODELS: THE IMPACT OF PROBLEM-SOLVING DATA, DATA SYNTHESIS METHODS, AND TRAINING STAGES》全文阅读 提升语言模型中的数学推理能力:问题求解数据、数据合成方法及训练阶段的影响 \begin{abstract} 数学推…...

Day56 | 99. 恢复二叉搜索树、103. 二叉树的锯齿形层序遍历、109. 有序链表转换二叉搜索树、113. 路径总和 II
99. 恢复二叉搜索树 题目链接:99. 恢复二叉搜索树 - 力扣(LeetCode) 题目难度:中等 代码: class Solution {public void recoverTree(TreeNode root) {List<TreeNode> listnew ArrayList<>();dfs(root,…...
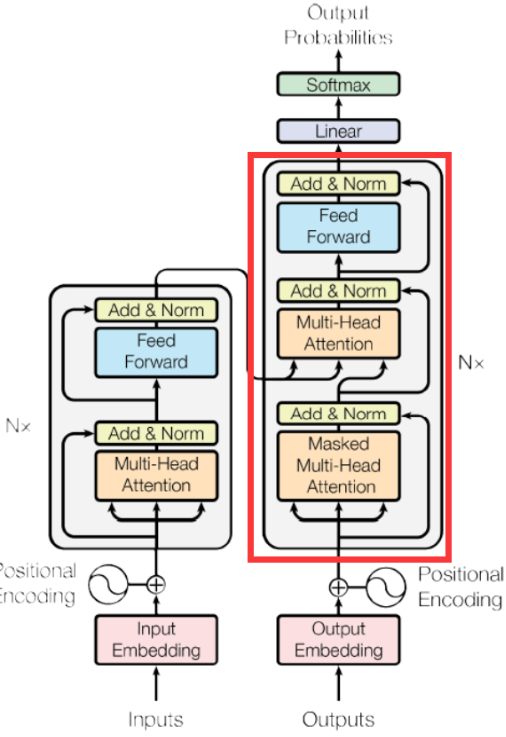
GPT - GPT(Generative Pre-trained Transformer)模型框架
本节代码主要为实现了一个简化版的 GPT(Generative Pre-trained Transformer)模型。GPT 是一种基于 Transformer 架构的语言生成模型,主要用于生成自然语言文本。 1. 模型结构 初始化部分 class GPT(nn.Module):def __init__(self, vocab…...

前端加密的几种方式
前端加密的几种方式 一、对称加密原理常用算法代码示例(AES)适用场景 二、非对称加密原理常用算法代码示例(RSA)适用场景 三、哈希函数原理常用算法代码示例(SHA-256)适用场景 四、Base64 编码原…...
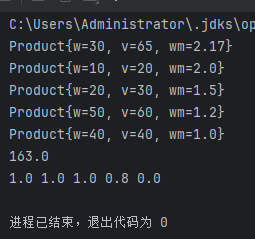
贪心算法:部分背包问题深度解析
简介: 该Java代码基于贪心算法实现了分数背包问题的求解,核心通过单位价值降序排序和分阶段装入策略实现最优解。首先对Product数组执行双重循环冒泡排序,按wm(价值/重量比)从高到低重新排列物品;随后分两阶段装入:循环…...

连接器电镀层的作用与性能
连接器电镀层的作用与性能: 镀金 金具有很高的化学稳定性,只溶于王水,不溶于其它酸,金镀层耐蚀性强,导电性好,易于焊接,耐高温,硬金具有一定的耐磨性。 对钢、铜、银及其合金基体而…...

神经网络如何表示数据
神经网络是如何工作的?这是一个让新手和专家都感到困惑的问题。麻省理工学院计算机科学和人工智能实验室(CSAIL)的一个团队表示,理解这些表示,以及它们如何为神经网络从数据中学习的方式提供信息,对于提高深…...
)
【双指针】和为 s 的两个数字(easy)
和为 s 的两个数字(easy) 题⽬描述:解法⼀(暴⼒解法,会超时):解法⼆(双指针 - 对撞指针):算法思路:C 算法代码Java 算法代码: 题⽬链接…...