豆瓣图书数据采集与可视化分析
文章目录
- 一、适用题目
- 二、豆瓣图书数据采集
- 1. 图书分类采集
- 2. 爬取不同分类的图书数据
- 3. 各个分类数据整合
- 三、豆瓣图书数据清洗
- 四、数据分析
- 五、数据可视化
- 1. 数据可视化大屏展示
- 源码获取看下方名片
一、适用题目
- 基于Python的豆瓣图书数据采集与分析
- 基于Python的豆瓣图书数据采集与可视化分析
- 基于Python的豆瓣图书数据分析与展示
- 基于Python的豆瓣图书数据分析与可视化实现
- 基于Python的豆瓣图书数据可视化分析
- 基于Selenium和Pandas的豆瓣图书数据采集与分析
- 基于Selenium和Pandas的豆瓣图书数据采集与可视化分析
- 基于Selenium和Pandas的豆瓣图书数据分析与展示
- 基于Selenium和Pandas的豆瓣图书数据分析与可视化实现
- 基于Selenium和Pandas的豆瓣图书数据可视化分析
- 基于Pandas和FineBI的豆瓣图书数据采集与分析
- 基于Pandas和FineBI的豆瓣图书数据采集与可视化分析
- 基于Pandas和FineBI的豆瓣图书数据分析与展示
- 基于Pandas和FineBI的豆瓣图书数据分析与可视化实现
- 基于Pandas和FineBI的豆瓣图书数据可视化分析
二、豆瓣图书数据采集
1. 图书分类采集
首先,设定要访问的网址,即豆瓣读书的标签页面地址,这个页面包含了各类图书的分类标签信息。
然后,设置请求头,其中包含用户代理信息,模拟使用特定版本的浏览器(这里是 Windows 系统下的 Chrome 117.0.0.0)发送请求,以避免被网站识别为异常请求而拒绝访问。
接下来,使用网络请求工具向目标网址发送一个 GET 请求,并设置请求超时时间为 10 秒。请求成功后,获取服务器返回的响应内容,该内容为包含网页信息的文本数据。
获取到网页文本后,利用网页解析工具,以 lxml 解析器对文本进行解析,将其转换为便于处理的结构化数据。
在解析后的网页结构中,通过选择器选中所有包含图书分类标签的链接元素,这些元素位于特定的 CSS 类名(‘.tagCola’)下。
对于每个选中的链接元素,提取其文本内容作为图书分类标签的名称,同时提取其链接地址,并将相对链接地址拼接上豆瓣读书的基础网址,得到完整的绝对链接地址。
将提取到的每个图书分类标签的名称和对应的链接地址,以字典的形式存储,字典的键分别为 ‘name’ 和 ‘href’,值分别为标签名称和链接地址。然后将每个字典添加到一个列表中,形成包含所有图书分类标签信息的列表。
最后,使用数据处理工具,将这个包含图书分类标签信息的列表转换为一个数据表格形式的数据结构。并将这个数据表格保存为一个 CSV 文件,文件名为 “图书分类标签.csv”,存储在 “原始数据层” 文件夹下,保存时不包含索引列,并使用特定的编码格式(utf-8-sig)以确保中文字符的正确保存和读取。
采集后的部分数据如下图所示:
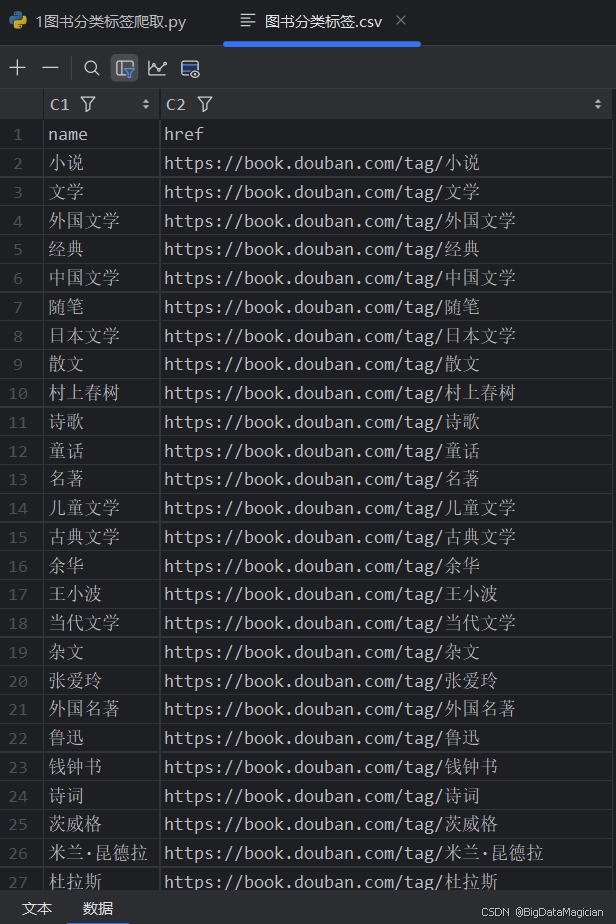
2. 爬取不同分类的图书数据
整个数据采集过程如下:
准备工作
- 读取分类标签:从之前保存的 CSV 文件中读取豆瓣读书的图书分类标签及对应的链接。
- 初始化浏览器:启动 Edge 浏览器,并打开一个示例图书分类页面,等待 60 秒,可能用于手动处理登录或其他验证。
处理每个图书分类
- 检查文件是否存在:对于每个图书分类,检查对应的 CSV 文件是否已经存在。如果存在,则跳过该分类,避免重复采集。
- 遍历分类页面:
- 构建页面 URL:根据分类链接和当前页码,构建要访问的页面 URL。
- 访问页面:使用浏览器访问该 URL,并随机等待 1 - 3 秒,模拟人类浏览行为。
- 检查页面是否有图书条目:如果页面上没有图书条目,则认为该分类的所有页面都已处理完毕,结束该分类的采集。
- 等待图书条目加载:等待页面上的所有图书条目元素加载完成,最多等待 10 - 20 秒。
- 提取图书信息:
- 遍历图书条目:对于页面上的每个图书条目,提取其相关信息,包括图书链接、封面图片链接、书名、出版信息、评分、评价数量、简介和购买信息。
- 存储图书信息:将提取的图书信息存储在一个字典中,并添加到数据列表中。
- 保存数据:
- 创建 CSV 文件:如果对应的 CSV 文件不存在,则创建该文件并写入表头。
- 追加数据:将当前页面提取的图书信息以 DataFrame 的形式追加到 CSV 文件中。
- 等待一段时间:随机等待 1 - 3 秒,避免对网站造成过大压力。
结束采集
处理完所有图书分类后,关闭浏览器,结束数据采集过程。
爬取后的数据如下图所示:
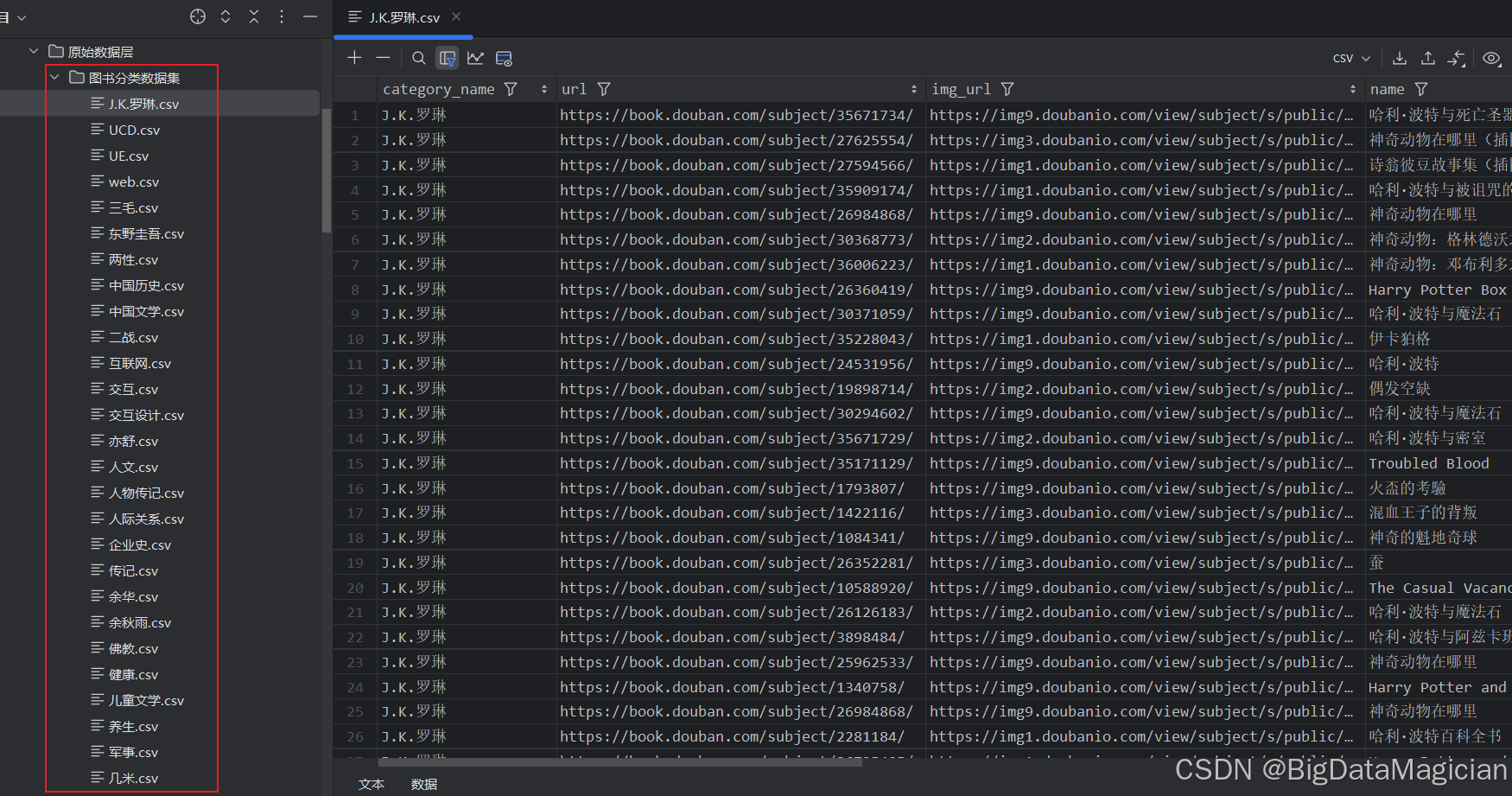
3. 各个分类数据整合
此过程旨在将指定目录下的多个 CSV 文件合并为一个 CSV 文件。具体步骤如下:
准备工作
- 明确源目录和目标文件路径。源目录是存放待合并 CSV 文件的位置,目标文件是合并后数据要保存的地方。
- 若目标文件所在的输出目录不存在,将其创建出来。
获取 CSV 文件
- 对源目录进行查找,找出其中所有的 CSV 文件。
- 统计找到的 CSV 文件数量并记录。
读取 CSV 文件
- 逐个读取这些 CSV 文件。
- 若文件读取成功,记录读取成功信息;若读取过程中出现错误,记录错误信息。
合并数据
- 将所有成功读取的 CSV 文件对应的数据进行合并。
- 记录合并完成信息。
保存合并后的数据
- 把合并好的数据保存到之前指定的目标文件中。
- 若保存成功,记录保存成功信息;若保存过程中出现错误,记录错误信息。
整合后的部分数据如下图所示:
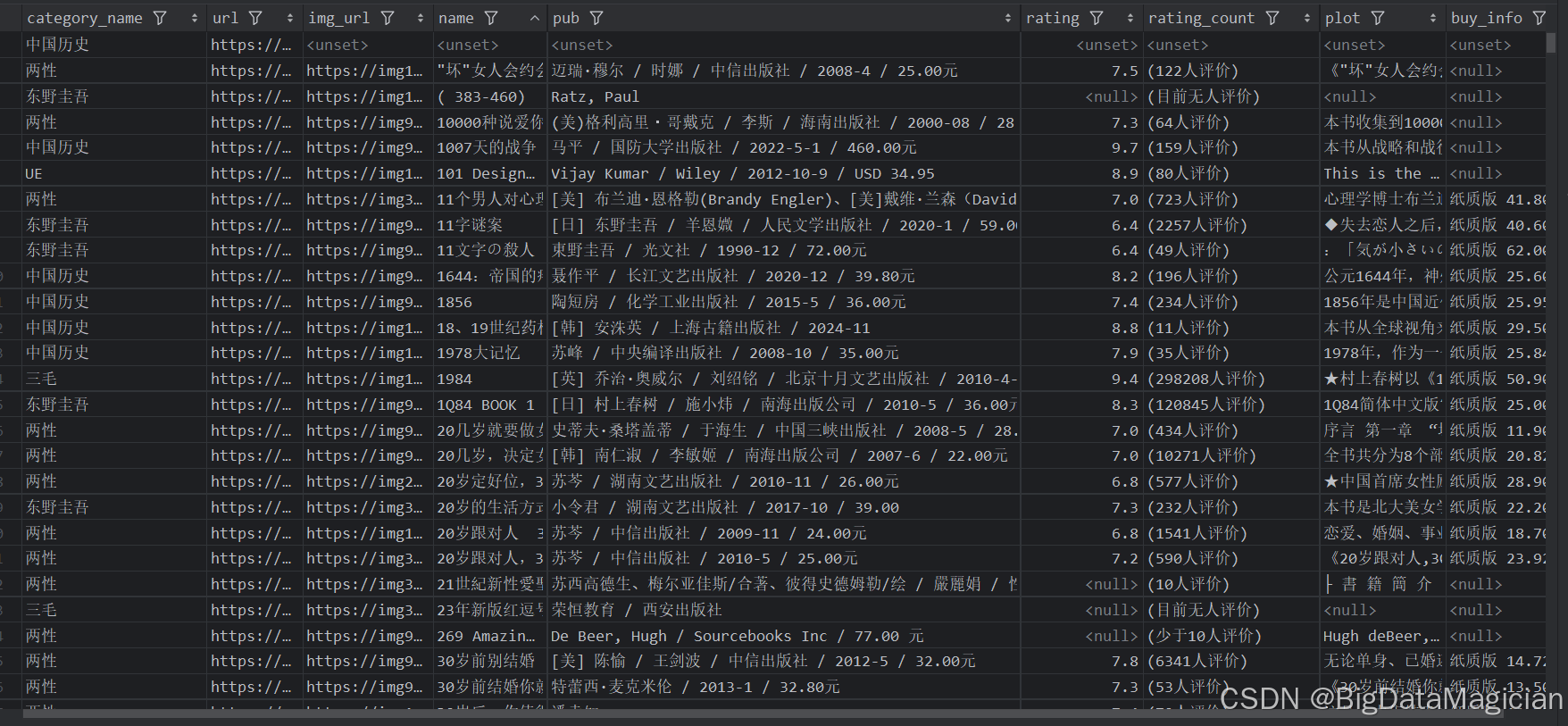
三、豆瓣图书数据清洗
- 数据读取与查看:从本地CSV文件读取豆瓣图书数据,查看数据的前几行、列名及基本信息,对数据有初步了解。
- 拆分“pub”列:对数据中的“pub”列进行拆分,根据不同的分隔符和格式,将其拆分为“author”(作者)、“translator”(译者)、“publisher”(出版社)、“publish_date”(出版日期)和“price”(价格)这几列。拆分完成后,删除原“pub”列,再将处理后的数据保存到新的CSV文件中。
- 日期列处理:对“publish_date”列进行处理,只保留年份信息。若日期不为空,截取前4位作为年份并转换为整数类型;若年份不是4位数字、无法转换为整数、大于2025或小于1900,则设为“None”。处理完成后,将该列重命名为“publish_year”。
- 价格列处理:从“buy_info”列中提取价格信息,若提取的价格大于2000,则设为2000;若提取失败则设为“None”。处理完成后,删除“buy_info”列。
- 出版社列处理:对“publisher”列进行处理,若列值中包含“年”或“-”,则设为“None”,否则保留原内容。
- 评价人数列处理:对“rating_count”列进行处理,将“少于10人评价”转换为10,“目前无人评价”转换为0,其他情况提取数字作为评价人数;若提取失败则设为“None”。
- 空值处理:检查数据各列的缺失值情况,对“name”(图书名称)、“author”(作者)、“publisher”(出版社)列的缺失值直接删除;对“rating”(评分)列的缺失值,按图书分类用均值填充;对“plot”(情节简介)列的缺失值用“未知”填充;对“translator”(译者)列的缺失值用“无译者”填充并去除前后空格;对“publish_year”(出版年份)列的缺失值,按图书分类用中位数填充;对“price”(价格)列的缺失值,按图书分类用均值填充。
- 重复值处理:检查数据中的重复值,若存在则删除重复数据。
- 异常值处理:检查数据的异常值,对“rating”(评分)列的异常值进行处理,将评分限制在0 - 10的范围内。
- 数据保存:将清洗后的数据保存到本地新的CSV文件中,同时将其保存到MySQL数据库的指定表中。
清洗后的部分数据如下图所示:
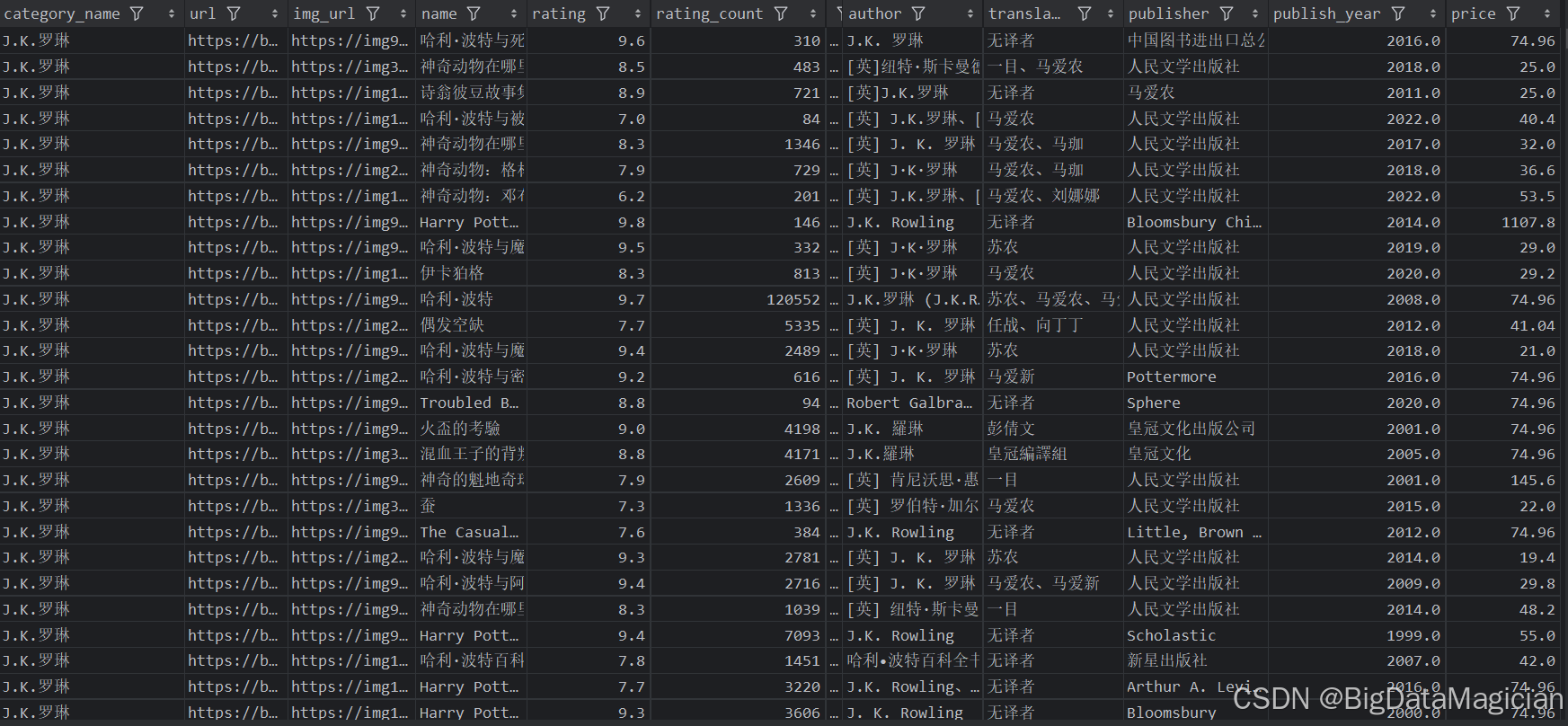
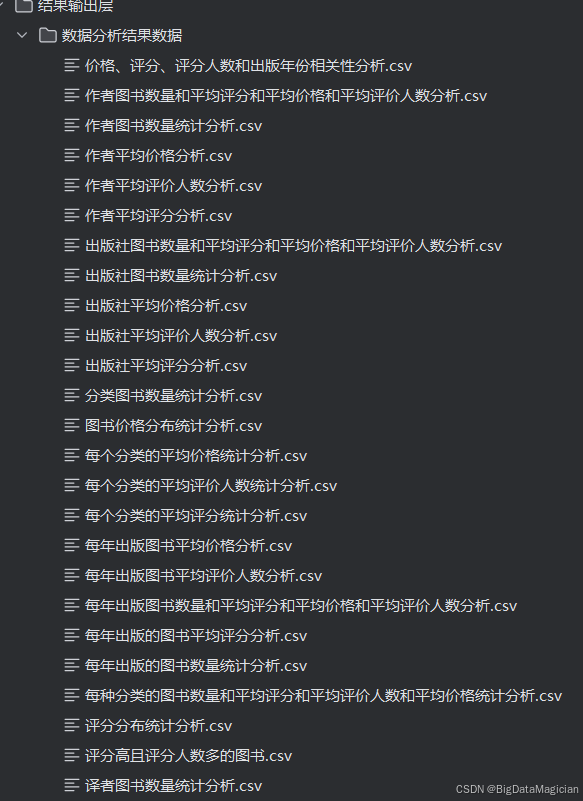
四、数据分析
分析后的结果数据文件如下图所示:
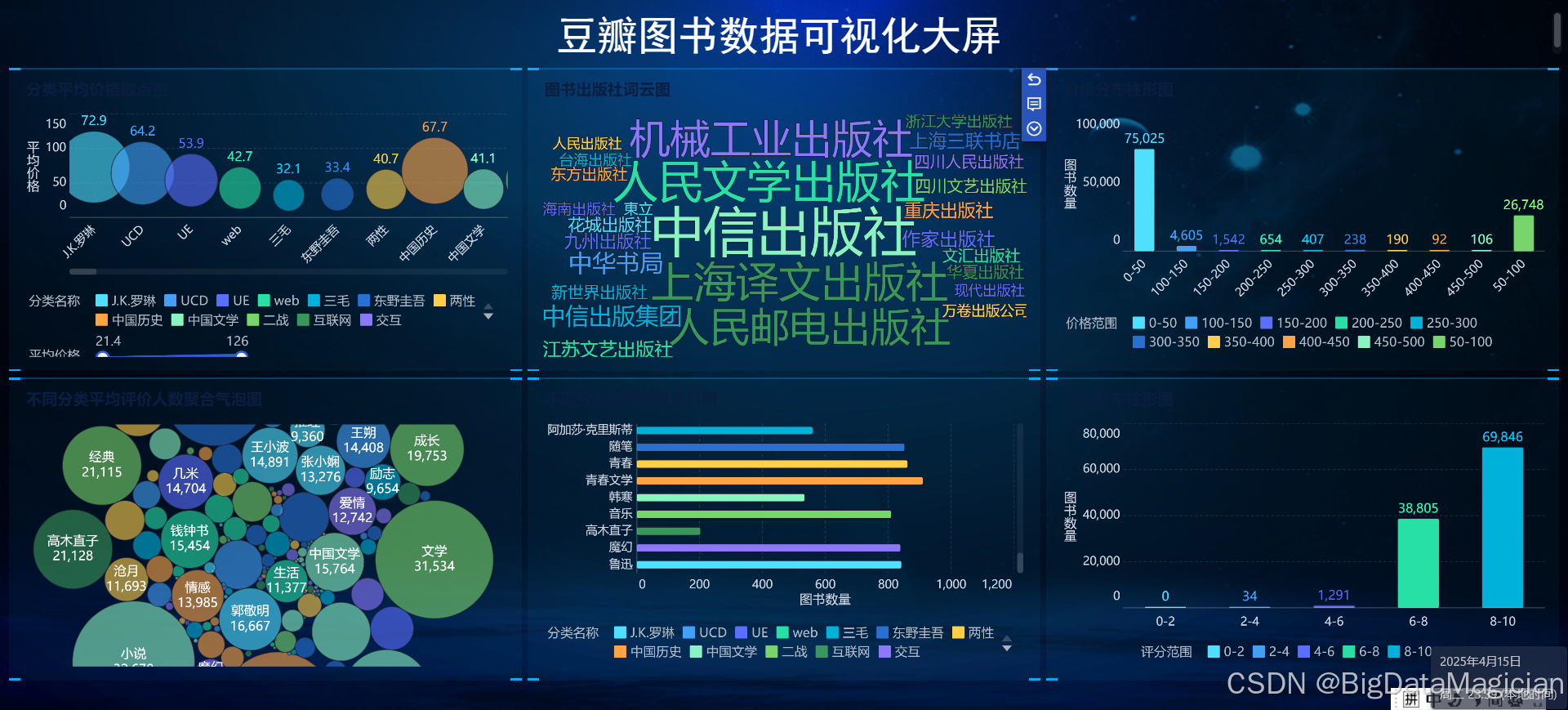
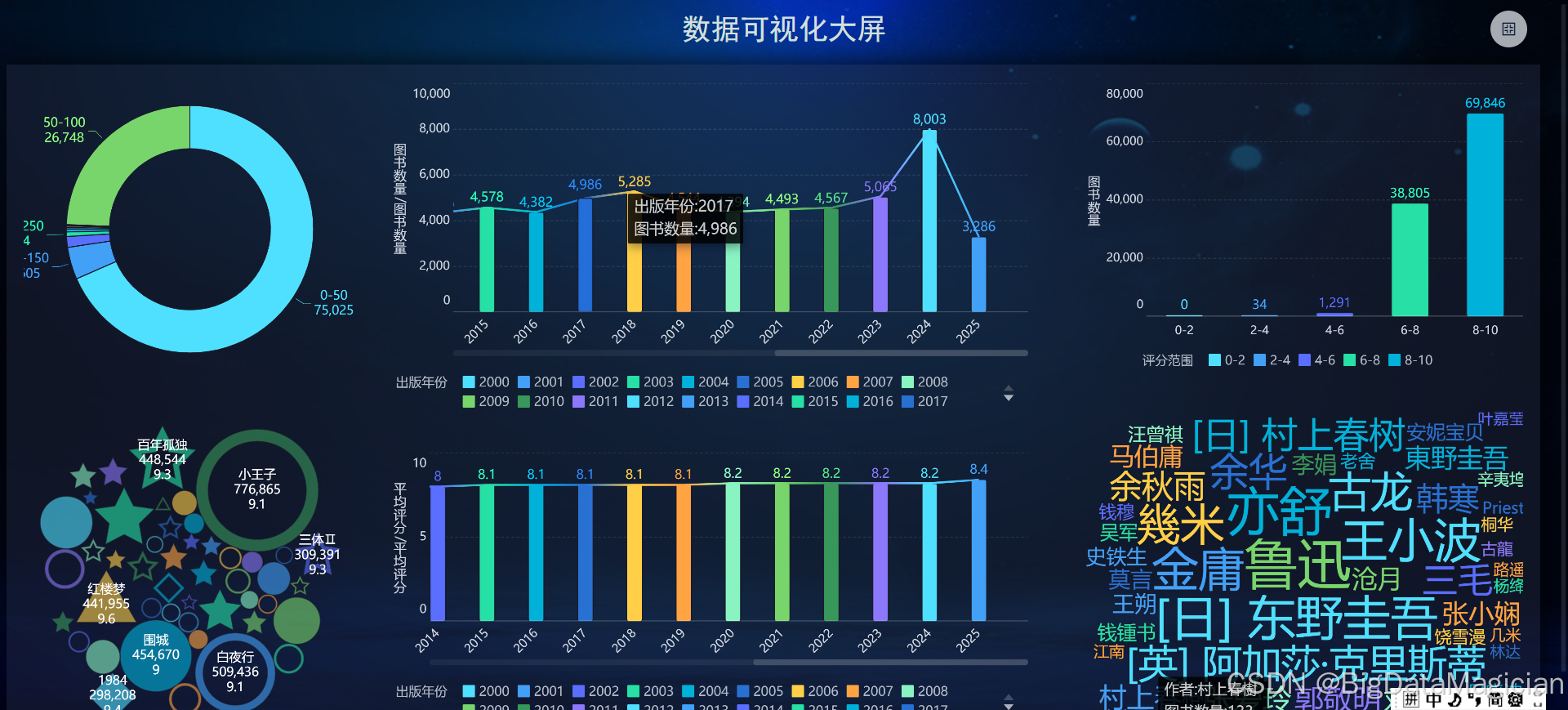
五、数据可视化
1. 数据可视化大屏展示


源码获取看下方名片
相关文章:
豆瓣图书数据采集与可视化分析
文章目录 一、适用题目二、豆瓣图书数据采集1. 图书分类采集2. 爬取不同分类的图书数据3. 各个分类数据整合 三、豆瓣图书数据清洗四、数据分析五、数据可视化1. 数据可视化大屏展示 源码获取看下方名片 一、适用题目 基于Python的豆瓣图书数据采集与分析基于Python的豆瓣图书…...
常见的爬虫算法
1.base64加密 base64是什么 Base64编码,是由64个字符组成编码集:26个大写字母AZ,26个小写字母az,10个数字0~9,符号“”与符号“/”。Base64编码的基本思路是将原始数据的三个字节拆分转化为四个字节,然后…...

Numpy常用库方法总结
numpy的底层是ndarray,也就是矩阵结构 对于ndarray结构来说,里面所有的元素必须是同一类型的 如果不是的话,会自动的向下进行转换 list [1,2,3,4,5] array np.array(list) array输出:array([1, 2, 3, 4, 5]) 1.1 ndarray基本…...
YOLOV8 OBB 海思3516训练流程
YOLOV8 OBB 海思3516训练流程 目录 1、 下载带GPU版本的torch(可选) 1 2、 安装 ultralytics 2 3、 下载pycharm 社区版 2 4、安装pycharm 3 5、新建pycharm 工程 3 6、 添加conda 环境 4 7、 训练代码 5 9、配置Ymal 文件 6 10、修改网络结构 9 11、运行train.py 开始训练模…...
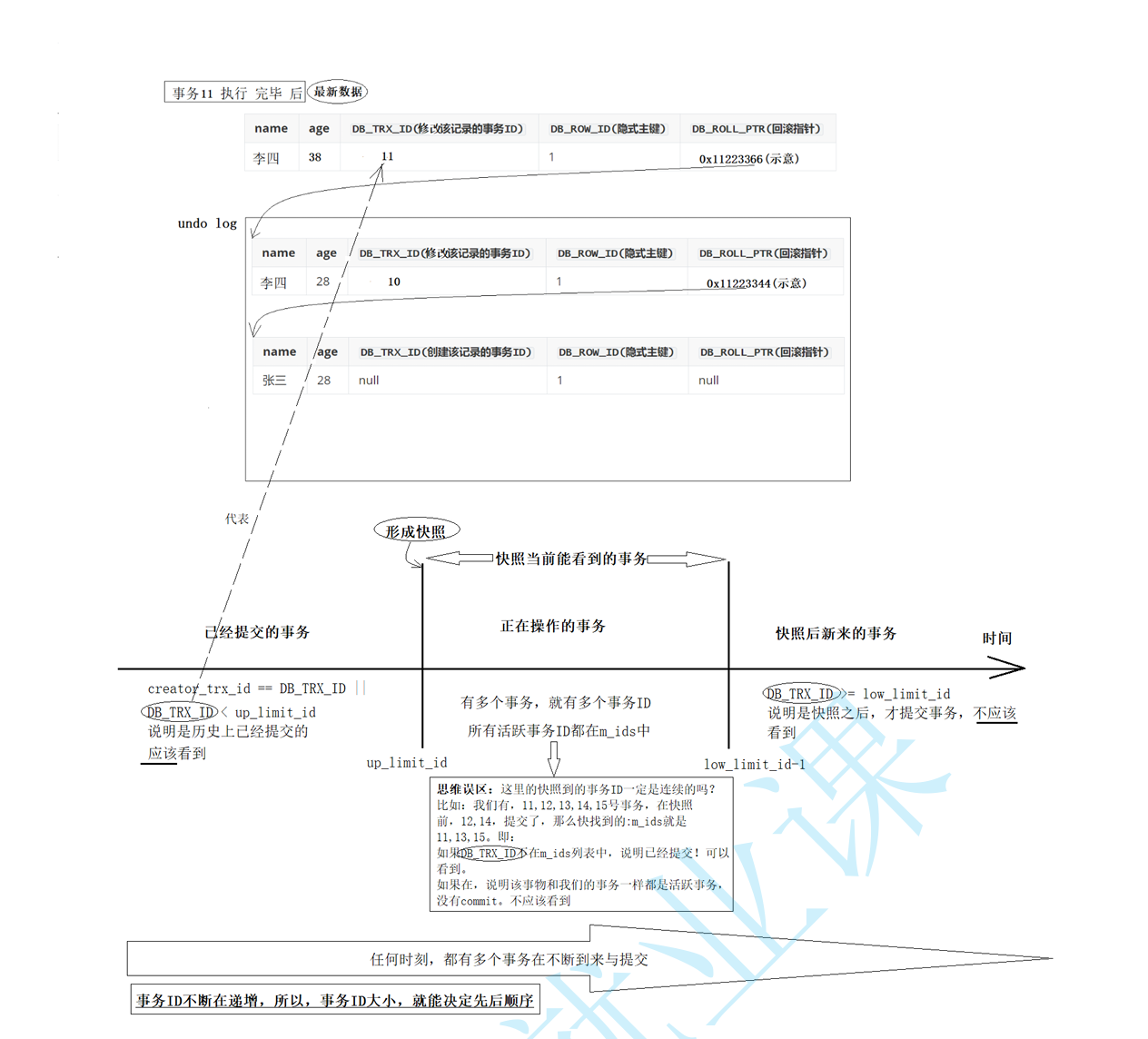
[MySQL] 事务管理(二) 事务的隔离性底层
事务的隔离性底层 1.数据库并发的场景2.读-写2.1MVCC三个变量2.1.1 3个记录隐藏列字段2.1.2 undo日志 模拟MVCCselect 的读取2.1.3 Read View(读视图) 3.RR与RC的区别 1.数据库并发的场景 读-读:不存在问题,也不需要并发控制读-写…...

20、.NET SDK概述
.NET SDK(Software Development Kit) 是微软提供的一套开发工具包,用于构建、运行和管理基于 .NET 平台的应用程序。它包含了一组丰富的工具、库和运行时环境,支持开发者在多种操作系统(如 Windows、Linux 和 macOS&am…...

Go:包和 go 工具
引言 通过对关联特性分类,组成便于理解和修改的单元,使包与程序其他包保持独立,助力大型程序的设计与维护 。模块化让包可在不同项目共享、复用、发布及全球范围使用。 每个包定义不同命名空间作为标识符,关联具体包,…...
18-21源码剖析——Mybatis整体架构设计、核心组件调用关系、源码环境搭建
学习视频资料来源:https://www.bilibili.com/video/BV1R14y1W7yS 文章目录 1. 架构设计2. 核心组件及调用关系3. 源码环境搭建3.1 测试类3.2 实体类3.3 核心配置文件3.4 映射配置文件3.5 遇到的问题 1. 架构设计 Mybatis整体架构分为4层: 接口层&#…...
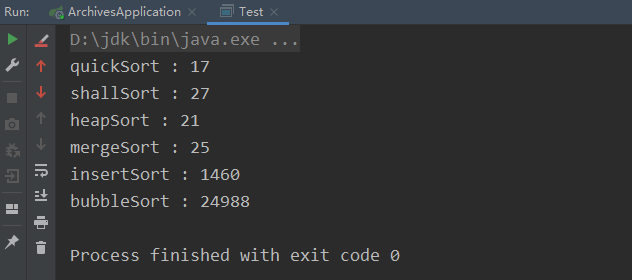
冒泡排序、插入排序、快速排序、堆排序、希尔排序、归并排序
目录 冒泡排序插入排序快速排序(未优化版本)快速排序(优化版本)堆排序希尔排序归并排序各排序时间消耗对比 冒泡排序 冒泡排序核心逻辑就是对数组从第一个位置开始进行遍历,如果发现该元素比下一个元素大,则交换位置,如果不大,就…...

Docker Compose 中配置 Host 网络模式
在 Docker Compose 中配置 Host 网络模式时,需通过 network_mode 参数直接指定容器使用宿主机的网络栈。以下是具体配置方法及注意事项: 1. 基础配置示例 在 docker-compose.yml 文件中,为需要启用 Host 模式的服务添加 network_mode: "…...

HTML、CSS 和 JavaScript 常见用法及使用规范
一、HTML 深度剖析 1. 文档类型声明 HTML 文档开头的 <!DOCTYPE html> 声明告知浏览器当前文档使用的是 HTML5 标准。它是文档的重要元信息,能确保浏览器以标准模式渲染页面,避免怪异模式下的兼容性问题。 2. 元数据标签 <meta> 标签&am…...

Elasticsearch 索引数据量激增的应对与优化:从原理到部署实践
Elasticsearch(ES)作为一款强大的分布式搜索和分析引擎,广泛应用于日志分析、全文搜索和实时数据处理等场景。然而,随着数据量激增,索引可能面临性能瓶颈,如写入变慢、查询延迟高或存储成本上升。如何有效应…...

CD27.【C++ Dev】类和对象 (18)友元和内部类
目录 1.友元 友元函数 几个特点 友元类 格式 代码示例 2.内部类(了解即可) 计算有内部类的类的大小 分析 注意:内部类不能直接定义 内部类是外部类的友元类 3.练习 承接CD21.【C Dev】类和对象(12) 流插入运算符的重载文章 1.友元 友元函数 在CD21.【C Dev】类和…...
QT安装详细步骤
下载 清华源 : 清华源 1. 2. 3. 4....

Unity游戏多语言工具包
由于一开始的代码没有考虑多语言场景,导致代码中提示框和UI显示直接用了中文,最近开始提取代码的中文,提取起来太麻烦,所以拓展了之前的多语言包,降低了操作复杂度。最后把工具代码提取出来到单独项目里面,…...
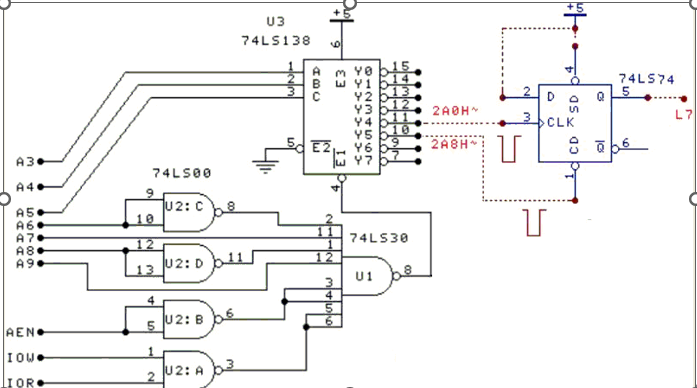
实验三 I/O地址译码
一、实验目的 掌握I/O地址译码电路的工作原理。 二、实验电路 实验电路如图1所示,其中74LS74为D触发器,可直接使用实验台上数字电路实验区的D触发器,74LS138为地址译码器, Y0:280H~287H&…...
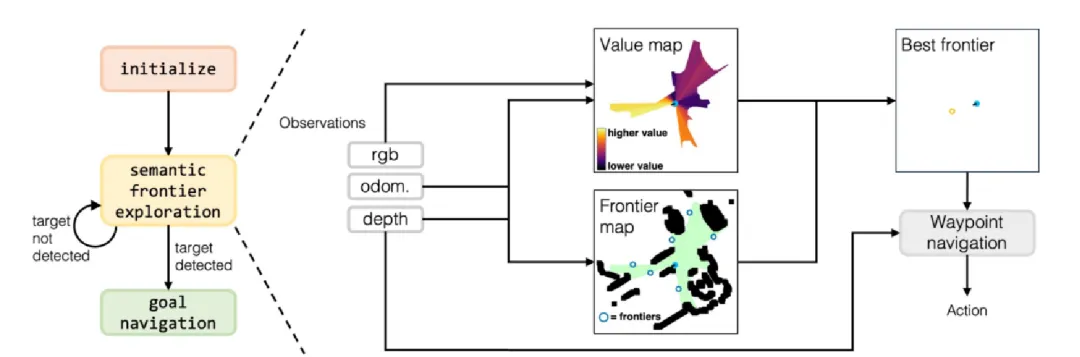
视觉语言导航(VLN):连接语言、视觉与行动的桥梁
文章目录 1. 引言:什么是VLN及其重要性?2. VLN问题定义3. 核心挑战4. 基石:关键数据集与模拟器5. 评估指标6. 主要方法与技术演进6.1 前CLIP时代:奠定基础6.2 后CLIP时代:视觉与语言的统一 7. 最新进展与前沿趋势 (202…...

计算机网络中科大 - 第7章 网络安全(详细解析)-以及案例
目录 🛡️ 第8章:网络安全(Network Security)优化整合笔记📌 本章学习目标 一、网络安全概念二、加密技术(Encryption)1. 对称加密(Symmetric Key)2. 公钥加密࿰…...
)
2026《数据结构》考研复习笔记一(C++基础知识)
C基础知识复习 一、数据类型二、修饰符和运算符三、Lambda函数和表达式四、数学函数五、字符串六、结构体 一、数据类型 1.1基本类型 基本类型 描述 字节(位数) 范围 char 字符类型,存储ASCLL字符 1(8位) -128…...
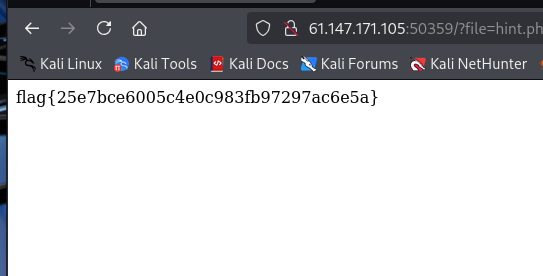
XCTF-web(四)
unserialize3 需要反序列化一下:O:4:“xctf”:2:{s:4:“flag”;s:3:“111”;} php_rce 题目提示rce漏洞,测试一下:?s/Index/\think\app/invokefunction&functioncall_user_func_array&vars[0]phpinfo&vars[1][]1 flag࿱…...
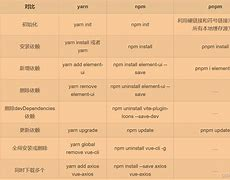
在Vue项目中查询所有版本号为 1.1.9 的依赖包名 的具体方法,支持 npm/yarn/pnpm 等主流工具
以下是 在Vue项目中查询所有版本号为 1.1.9 的依赖包名 的具体方法,支持 npm/yarn/pnpm 等主流工具: 一、使用 npm 1. 直接过滤依赖树 npm ls --depth0 | grep "1.1.9"说明: npm ls --depth0:仅显示直接依赖…...
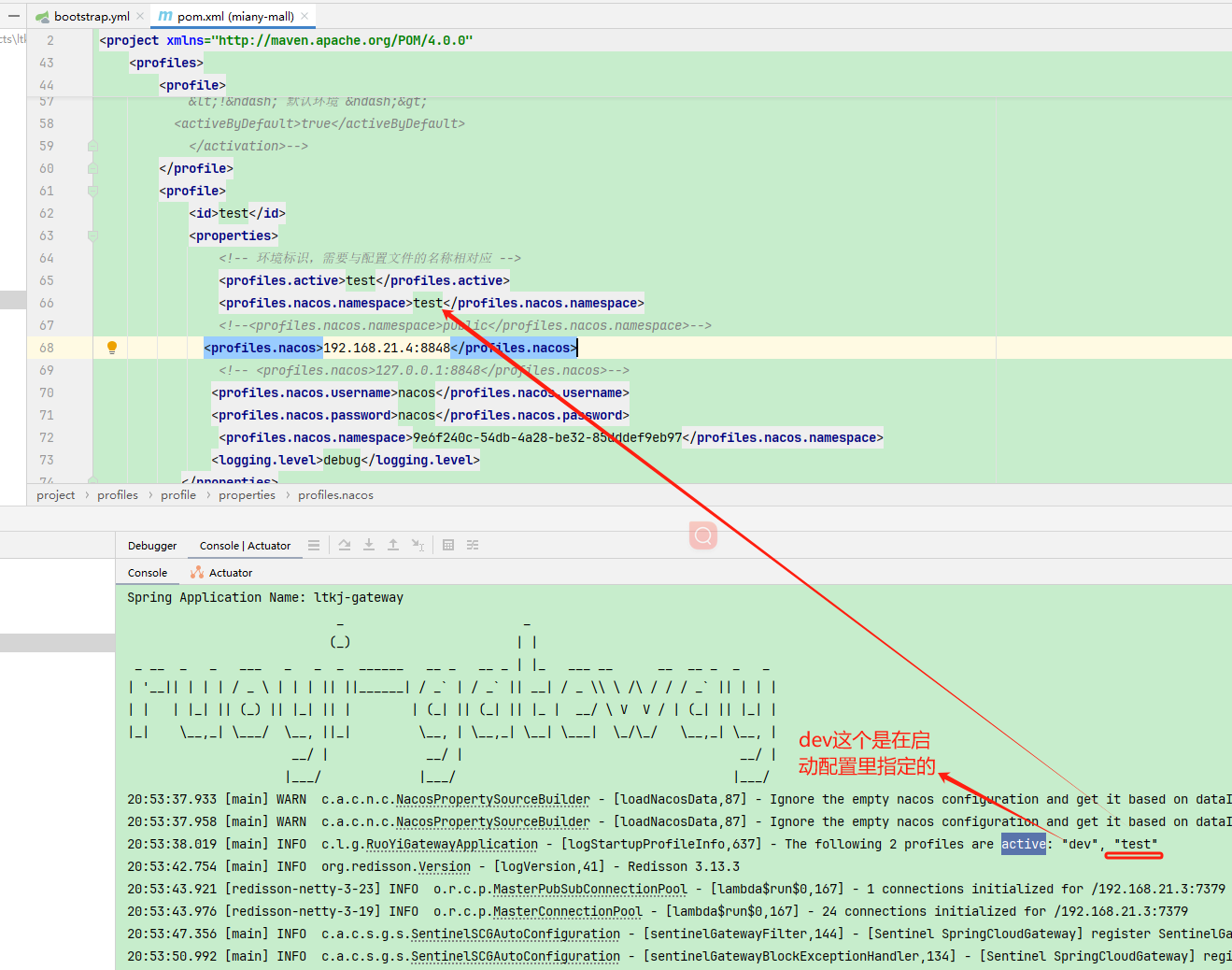
若依微服务版启动小程序后端
目录标题 本地启动,dev对应 nacos里的 xxx-xxx-dev配置文件 本地启动,dev对应 nacos里的 xxx-xxx-dev配置文件...

莒县第六实验小学:举行“阅读世界 丰盈自我”淘书会
4月16日,莒县第六实验小学校园内书香四溢、笑语盈盈,以“阅读世界 丰盈自我”为主题的第二十四届读书节之“淘书会”活动火热开启。全校师生齐聚一堂,以书会友、共享阅读之乐,为春日校园增添了一抹浓厚的文化气息。 活动在悠扬的诵…...

国产数据库与Oracle数据库事务差异分析
数据库中的ACID是事务的基本特性,而在Oracle等数据库迁移到国产数据库国产中,可能因为不同数据库事务处理机制的不同,在迁移后的业务逻辑处理上存在差异。本文简要介绍了事务的ACID属性、事务的隔离级别、回滚机制和超时机制,并总…...

C++学习记录:
今天我们来学习一门新的语言,也是C语言最著名的一个分支语言:C。 在C的学习中,我们主要学习的三大组成部分:语法、STL、数据结构。 C的介绍 C的历史可追溯至1979年,当时贝尔实验室的本贾尼斯特劳斯特卢普博士在面对复杂…...
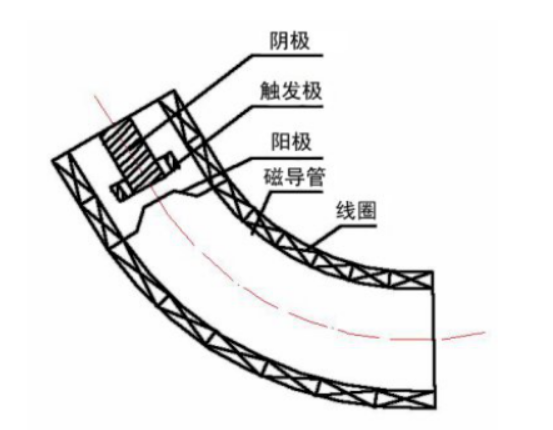
等离子体浸没离子注入(PIII)
一、PIII 是什么?基本原理和工艺 想象一下,你有一块金属或者硅片(就是做芯片的那种材料),你想给它的表面“升级”,让它变得更硬、更耐磨,或者有其他特殊功能。怎么做呢?PIII 就像是用…...

LeetCode-16.最接近的三数之和 C++实现
一 题目描述 给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums 中选出三个整数,使它们的和与 target 最接近。 返回这三个数的和。 假定每组输入只存在恰好一个解 示例 1: 输入:nums [-1,2,1,-4], target 1 输出&…...

【机器学习】每日一讲-朴素贝叶斯公式
文章目录 **一、朴素贝叶斯公式详解****1. 贝叶斯定理基础****2. 从贝叶斯定理到分类任务****3. 特征独立性假设****4. 条件概率的估计** **二、在AI领域的作用****1. 文本分类与自然语言处理(NLP)****2. 推荐系统****3. 医疗与生物信息学****4. 实时监控…...

C 语言中的 volatile 关键字
1、概念 volatile 是 C/C 语言中的一个类型修饰符,用于告知编译器:该变量的值可能会在程序控制流之外被意外修改(如硬件寄存器、多线程共享变量或信号处理函数等),因此编译器不应对其进行激进的优化(如缓存…...

Python自学第1天:变量,打印,类型转化
突然想学Python了。经过Deepseek的推荐,下载了一个Python3.12安装。安装过程请自行搜索。 乖乖从最基础的学起来,废话不说了,上链接,呃,打错了,上知识点。 变量的定义 # 定义一个整数类型的变量 age 10#…...