LoRA个关键超参数:`LoRA_rank`(通常简称为 `rank` 或 `r`)和 `LoRA_alpha`(通常简称为 `alpha`)
LoRA (Low-Rank Adaptation) 中的两个关键超参数:LoRA_rank(通常简称为 rank 或 r)和 LoRA_alpha(通常简称为 alpha)。
LoRA 的核心思想是,在对大型预训练模型(如 LLM 或 Stable Diffusion)进行微调时,我们不需要更新模型的所有权重。相反,我们可以冻结原始权重 W 0 W_0 W0,并为模型的某些层(通常是 Transformer 的 Attention 层中的 W q , W k , W v , W o W_q, W_k, W_v, W_o Wq,Wk,Wv,Wo 矩阵)注入一对可训练的、低秩的“适配器”矩阵 A A A 和 B B B。
模型层的前向传播被修改为:
原始: h = W 0 x h = W_0 x h=W0x
LoRA 修改后: h = W 0 x + Δ W x = W 0 x + B A x h = W_0 x + \Delta W x = W_0 x + B A x h=W0x+ΔWx=W0x+BAx
这里:
- W 0 W_0 W0 是原始的、冻结的权重矩阵。
- x x x 是输入。
- h h h 是输出。
- Δ W = B A \Delta W = B A ΔW=BA 是学习到的权重 变化量(权重更新),由两个较小的矩阵 B B B 和 A A A 的乘积来表示。
- 如果 W 0 W_0 W0 的维度是 d × k d \times k d×k,那么 A A A 的维度是 r × k r \times k r×k, B B B 的维度是 d × r d \times r d×r。这里的 r r r 就是
LoRA_rank。
1. LoRA_rank (r)
- 定义:
rank参数 r r r 定义了 LoRA 适配器矩阵 A A A 和 B B B 的内部维度(秩)。它直接决定了 Δ W = B A \Delta W = BA ΔW=BA 这个近似更新矩阵的秩。 - 作用:
- 模型容量/表达能力:
rank控制了 LoRA 适配器能够学习和表达的信息量。更高的rank意味着矩阵 A A A 和 B B B 更大, Δ W \Delta W ΔW 可以捕捉更复杂的模式和权重变化。理论上,更高的rank可以让模型更好地适应新的数据或任务,可能达到更高的微调性能。 - 参数数量:LoRA 引入的可训练参数数量与
rank成正比。对于一个 d × k d \times k d×k 的权重矩阵 W 0 W_0 W0,LoRA 引入的参数数量是 r × k + d × r = r × ( d + k ) r \times k + d \times r = r \times (d+k) r×k+d×r=r×(d+k)。相比于训练整个 d × k d \times k d×k 的矩阵,当 r ≪ min ( d , k ) r \ll \min(d, k) r≪min(d,k) 时,这个数量要小得多。因此,rank直接影响了 LoRA 微调的效率(内存占用和计算量)。 - 权衡:选择
rank是在 模型性能 和 效率/参数量 之间做权衡。- 较低的
rank(如 4, 8, 16):参数少,训练快,内存占用小,但可能无法完全捕捉所需的权重调整,导致性能略有损失。 - 较高的
rank(如 32, 64, 128, 256):参数更多,可能获得更好的性能,但训练更慢,占用内存更多,并且如果rank过高而微调数据量不足,可能有过拟合的风险。
- 较低的
- 模型容量/表达能力:
- 类比:你可以把
rank想象成给模型微调分配的“表达能力预算”或“复杂度预算”。预算越高,模型调整得可能越精细,但也更昂贵。 - 选择:
rank的选择通常取决于具体的任务、数据集大小和基础模型。实践中常常从较小的值(如 8 或 16)开始尝试,根据验证集上的性能表现来调整。
2. LoRA_alpha ( α \alpha α)
- 定义:
alpha是一个缩放因子(scaling factor),用于调整 LoRA 适配器输出的幅度。 - 作用:
- 调整适应强度:
alpha控制了 LoRA 适配器( Δ W = B A \Delta W = BA ΔW=BA)对原始模型输出 ( W 0 x W_0 x W0x) 的影响程度。修改后的前向传播通常实现为:
h = W 0 x + s ⋅ ( B A x ) h = W_0 x + s \cdot (B A x) h=W0x+s⋅(BAx)
这里的 s s s 是最终的缩放系数。在原始 LoRA 论文和许多实现中,这个缩放系数 s s s 通常设置为 α r \frac{\alpha}{r} rα。
h = W 0 x + α r ( B A x ) h = W_0 x + \frac{\alpha}{r} (B A x) h=W0x+rα(BAx)
这意味着,LoRA 部分的贡献被 α \alpha α 放大,同时被rank( r r r) 缩小。 - 归一化和稳定性:使用 α r \frac{\alpha}{r} rα 作为缩放因子的一个重要原因是,它有助于在改变
rank( r r r) 时,保持 LoRA 更新的初始幅度相对稳定。如果没有除以 r r r,那么增加rank会同时增加参与计算的参数数量和潜在的输出幅度,可能导致训练不稳定。通过除以 r r r,可以部分抵消这种影响。设置 α \alpha α 使得 α / r \alpha/r α/r 这个比例大致保持在一个合适的范围内(例如, α = r \alpha = r α=r 时,比例为 1; α = 2 r \alpha = 2r α=2r 时,比例为 2)。 - 控制学习范围:可以认为
alpha像一个专门针对 LoRA部分的“学习率”乘数。它决定了学习到的 Δ W \Delta W ΔW 在多大程度上改变模型的行为。
- 调整适应强度:
- 类比:你可以把
alpha想象成 LoRA 适应层输出的“音量旋钮”或“强度调节器”。 - 选择:
- 一个常见的做法是将
alpha设置为rank的某个倍数,最常见的是alpha = rank(即 α / r = 1 \alpha/r = 1 α/r=1)。这样可以简化超参数调整,只需要调整rank。 - 有时也会设置
alpha为rank的两倍 (alpha = 2 * rank) 或其他固定值(如 32)。 - 一些实现可能不遵循 α / r \alpha/r α/r 的缩放,而是直接使用 α \alpha α 作为缩放因子 s = α s = \alpha s=α。这时
alpha的作用更直接,需要根据实验效果调整。检查你使用的具体库或代码是如何实现缩放的非常重要。 - 通常,如果
alpha设置得太高,可能会导致训练不稳定或过拟合;如果太低,LoRA 的效果可能不明显。
- 一个常见的做法是将
rank(r) 决定了 LoRA 适配器的 容量 和 参数数量。它控制了模型能学习多复杂的调整。alpha( α \alpha α) 决定了 LoRA 适配器 影响的强度 或 缩放比例。它控制了学习到的调整在多大程度上应用于原始模型。- 两者通常一起调整。常见的策略是先选择一个
rank,然后将alpha设置为等于rank或rank的两倍,并根据实验结果进一步微调。alpha / rank这个比值通常被认为是一个更稳定的衡量 LoRA 影响力的指标。
缩放因子 s s s 是越大越好还是越小越好
关于缩放因子 s s s(通常是 α r \frac{\alpha}{r} rα),并不是简单的“越大越好”或“越小越好”。它是一个需要根据具体任务、模型和数据进行调整的超参数,其最佳值取决于你想要达到的效果和需要平衡的因素。
我们来分析一下 s s s 的大小意味着什么:
回顾 LoRA 的公式: h = W 0 x + s ⋅ ( B A x ) h = W_0 x + s \cdot (B A x) h=W0x+s⋅(BAx)
-
s s s 较大时 (例如, s > 1 s > 1 s>1,对应 α > r \alpha > r α>r):
- 效果:LoRA 适配器学习到的变化 Δ W = B A \Delta W = BA ΔW=BA 对模型最终输出的影响更大。模型会更倾向于根据微调数据进行调整,其行为会更多地偏离原始预训练模型。
- 优点:如果微调任务与预训练任务差异较大,或者需要模型进行显著的行为改变,较大的 s s s 可能有助于模型更快、更充分地适应新任务,可能达到更高的任务性能。
- 缺点:
- 训练不稳定:过大的 s s s 可能导致训练过程不稳定,梯度可能会爆炸或消失。
- 过拟合:模型可能过度拟合微调数据,丢失了预训练模型学到的泛化能力(灾难性遗忘)。
- 破坏预训练知识:LoRA 的目的是在保留预训练知识的基础上进行微调,过大的 s s s 可能过度改变模型行为,破坏了基础模型的良好特性。
-
s s s 较小时 (例如, s < 1 s < 1 s<1,对应 α < r \alpha < r α<r):
- 效果:LoRA 适配器学习到的变化 Δ W = B A \Delta W = BA ΔW=BA 对模型最终输出的影响较小。模型的行为会更接近原始的预训练模型。
- 优点:
- 训练更稳定:通常训练过程更平滑。
- 更好地保留预训练知识:有助于防止灾难性遗忘,保持模型的泛化能力。
- 更精细的调整:适合只需要对模型进行微小调整的任务。
- 缺点:如果微调任务需要较大的模型调整,较小的 s s s 可能导致 LoRA 的适应能力不足(underfitting),模型无法充分学习新任务的特性,性能提升有限。
-
s = 1 s = 1 s=1 时 (通常对应 α = r \alpha = r α=r):
- 这通常被认为是一个基准或合理的起点。它提供了一个直接的平衡,即 LoRA 学习到的更新 B A x BAx BAx 在幅度上与原始权重 W 0 x W_0 x W0x 的贡献具有一定的可比性(具体取决于 B A x BAx BAx 的实际数值大小)。许多研究和实践都从 s = 1 s=1 s=1 开始尝试。
总结:
- 没有绝对的最优值:最佳的 s s s 值取决于任务需求。需要通过实验来找到最适合场景的值。
- 权衡:需要在 适应新任务的程度 和 保留预训练知识/训练稳定性 之间进行权衡。
- 起点:通常从 s = 1 s=1 s=1 (即 α = r \alpha = r α=r) 开始是一个不错的选择。
- 调整策略:如果在 s = 1 s=1 s=1 时模型适应不足,可以尝试增大 s s s(比如设置 α = 2 r \alpha = 2r α=2r 使得 s = 2 s=2 s=2);如果模型训练不稳定或有过拟合迹象,可以尝试减小 s s s(比如设置 α = 0.5 r \alpha = 0.5r α=0.5r 使得 s = 0.5 s=0.5 s=0.5)。
相关文章:
和 `LoRA_alpha`(通常简称为 `alpha`))
LoRA个关键超参数:`LoRA_rank`(通常简称为 `rank` 或 `r`)和 `LoRA_alpha`(通常简称为 `alpha`)
LoRA (Low-Rank Adaptation) 中的两个关键超参数:LoRA_rank(通常简称为 rank 或 r)和 LoRA_alpha(通常简称为 alpha)。 LoRA 的核心思想是,在对大型预训练模型(如 LLM 或 Stable Diffusion&…...

C++11智能指针深度解析:在Visual Studio中高效管理内存
文章目录 **C++11智能指针深度解析:在Visual Studio中高效管理内存****一、C++11智能指针的核心价值****二、三大智能指针详解与Visual Studio实战****1. `std::unique_ptr`:独占所有权****2. `std::shared_ptr`:共享所有权****3. `std::weak_ptr`:打破循环引用****三、高级…...
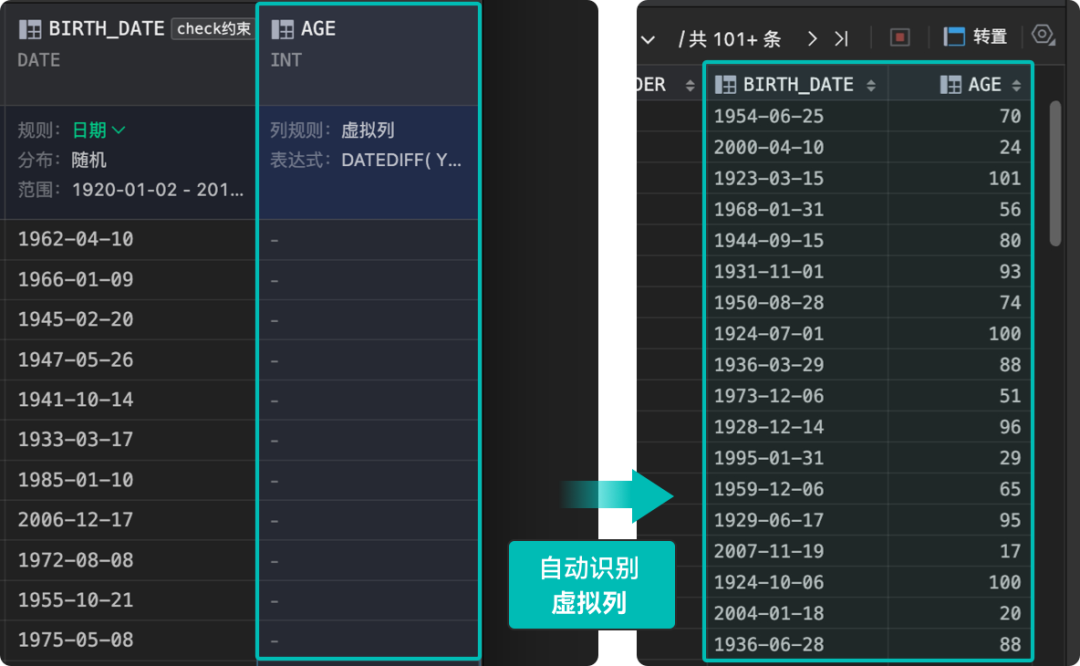
达梦官方管理工具SQLark:自动识别外键约束、check约束与虚拟列,助力高效生成测试数据
在数据库管理和应用开发过程中,高质量的测试数据对于系统调试和POC测试至关重要。达梦官方推出的新一代管理工具 SQLark百灵连接,其数据生成功能,可以为应用开发者、DBA 以及测试人员带来极大便利,能够轻松应对各类复杂的测试场景…...

Visio绘图工具全面科普:解锁专业图表绘制新境界[特殊字符]
Visio绘图工具全面科普:解锁专业图表绘制新境界🌟 在信息爆炸的时代,清晰、直观地呈现复杂信息变得至关重要。无论是绘制流程图📊、组织结构图👥,还是规划网络拓扑🖧,一款强大的绘图…...

RPCRT4!OSF_CCONNECTION::OSF_CCONNECTION函数分析之创建一个RPCRT4!OSF_CCALL--RPC源代码分析
RPCRT4!OSF_CCONNECTION::OSF_CCONNECTION函数分析之创建一个RPCRT4!OSF_CCALL 第一部分: 1: kd> p RPCRT4!OSF_CCONNECTION::OSF_CCONNECTION0x167: 001b:77bf6957 393dec35c877 cmp dword ptr [RPCRT4!gfRPCVerifierEnabled (77c835ec)],edi 1: kd> …...
、数据湖与数据运河)
快速认识:数据库、数仓(数据仓库)、数据湖与数据运河
数据技术核心概念对比表 概念核心定义核心功能数据特征典型技术/工具核心应用场景数据库结构化数据的「电子档案柜」,按固定 schema 存储和管理数据,支持高效读写和事务处理。实时事务处理(增删改查),确保数据一致性&…...
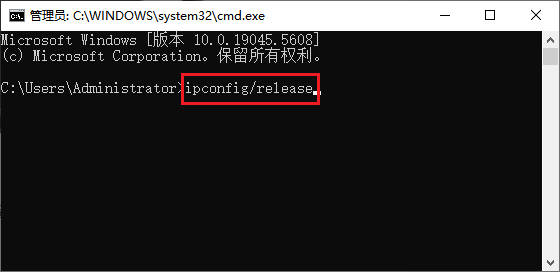
不关“猫”如何改变外网IP?3种免重启切换IP方案
每次更换外网IP都要重启路由器?太麻烦了!那么,不关猫怎么改变外网IP?无论是为了网络调试、爬虫需求,还是解决IP限制问题,频繁重启设备既耗时又影响效率。其实,更换外网IP并不一定要依赖“重启大…...
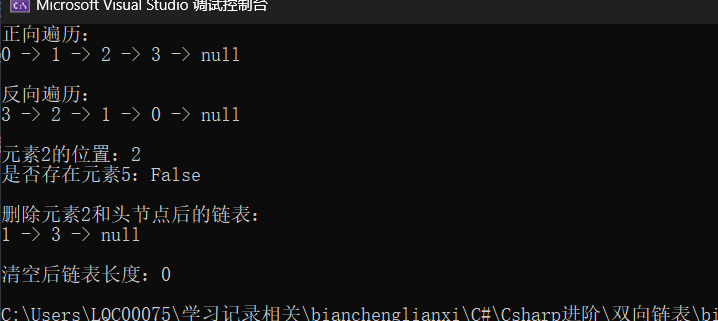
C#进阶学习(五)单向链表和双向链表,循环链表(中)双向链表
目录 一、双向链表的声明 1. 节点类声明 2. 链表类框架声明 3、实现其中的每一个函数 增删操作(核心方法组) 删除操作(核心方法组) 查询操作(辅助方法) 维护方法(内部逻辑) …...

case客户续保预测中用到的特征工程、回归分析和决策树分析的总结
文章目录 [toc]1. 回归分析概述1.1 基本概念1.2 与分类的区别 2. 常见回归算法2.1 线性回归2.2 决策树回归2.3 逻辑回归(Logistic Regression)2.3 其他算法补充:通俗版:决策树 vs 随机森林🌳 决策树:像玩「…...

Android系统通知机制深度解析:Framework至SystemUI全链路剖析
1. 前言 在Android 13的ROM定制化开发中,系统通知机制作为用户交互的核心组件,其实现涉及Framework层到SystemUI的复杂协作。本文将深入剖析从Notification发送到呈现的全链路流程,重点解析关键类的作用机制及系统服务间的交互逻辑ÿ…...

重学Redis:Redis常用数据类型+存储结构(源码篇)
一、SDS 1,SDS源码解读 sds (Simple Dynamic String),Simple的意思是简单,Dynamic即动态,意味着其具有动态增加空间的能力,扩容不需要使用者关心。String是字符串的意思。说白了就是用C语言自己封装了一个字符串类型&a…...

Elasticsearch的Java客户端库QueryBuilders查询方法大全
matchAllQuery 使用方法:创建一个查询,匹配所有文档。 示例:QueryBuilders.matchAllQuery() 注意事项:这种查询不加任何条件,会返回索引中的所有文档,可能会影响性能,特别是文档数量很多时。 ma…...
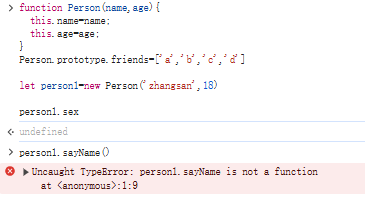
js原型和原型链
js原型: 1、原型诞生的目的是什么呢? js原型的产生是为了解决在js对象实例之间共享属性和方法,并把他们很好聚集在一起(原型对象上)。每个函数都会创建一个prototype属性,这个属性指向的就是原型对象。 …...

usb重定向qemu前端处理
1、qemu添加spicevmc前端时会创建vmc通道。 -chardev spicevmc,idusbredirchardev0,nameusbredir red::shared_ptr<RedCharDevice> spicevmc_device_connect(RedsState *reds, SpiceCharDeviceInstance *sin, uint8_t channel_type) {auto channel(red_vmc_channel_new(r…...
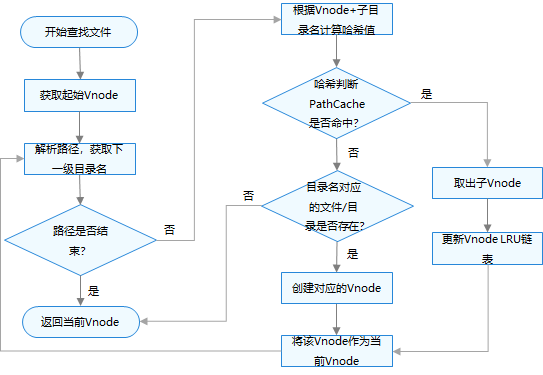
OpenHarmony - 小型系统内核(LiteOS-A)(五)
OpenHarmony - 小型系统内核(LiteOS-A)(五) 六、文件系统 虚拟文件系统 基本概念 VFS(Virtual File System)是文件系统的虚拟层,它不是一个实际的文件系统,而是一个异构文件系统之…...

PyTorch进阶学习笔记[长期更新]
第一章 PyTorch简介和安装 PyTorch是一个很强大的深度学习库,在学术中使用占比很大。 我这里是Mac系统的安装,相比起教程中的win/linux安装感觉还是简单不少(之前就已经安好啦),有需要指导的小伙伴可以评论。 第二章…...
proteus8.17 环境配置
Proteus介绍 Proteus 8.17 是一款功能强大的电子设计自动化(EDA)软件,广泛应用于电子电路设计、仿真和分析。以下是其主要特点和新功能: ### 主要功能 - **电路仿真**:支持数字和模拟电路的仿真,包括静态…...

Microsoft SQL Server Management 一键删除数据库所有外键
DECLARE ESQL VARCHAR(1000); DECLARE FCursor CURSOR --定义游标 FOR (SELECT ALTER TABLE O.name DROP CONSTRAINT F.name; AS CommandSQL from SYS.FOREIGN_KEYS F JOIN SYS.ALL_OBJECTS O ON F.PARENT_OBJECT_ID O.OBJECT_ID WHERE O.TYPE U AND F.TYPE …...

【JAVAFX】自定义FXML 文件存放的位置以及使用
情况 1:FXML 文件与调用类在同一个包中(推荐) 假设类 MainApp 的包是 com.example,且 FXML 文件放在 resources/com/example 下: 项目根目录 ├── src │ └── sample │ └── Main.java ├── src/s…...

Oracle 如何停止正在运行的 Job
Oracle 如何停止正在运行的 Job 先了解是dbms_job 还是 dbms_scheduler,再确定操作命令。 一 使用 DBMS_JOB 包停止作业(适用于旧版 Job) 1.1 查看正在运行的 Job SELECT job, what, this_date, this_sec, failures, broken FROM user_j…...
结构体(2)-Python)
高级语言调用C接口(四)结构体(2)-Python
这个专栏好久没有更新了,主要是坑开的有点大,也不知道怎么填,涉及到的开发语言比较多,写起来比较累,需要看的人其实并不多,只能说,慢慢填吧,中间肯定还会插很多别的东西,…...
Java对接Dify API接口完整指南
Java对接Dify API接口完整指南 一、Dify API简介 Dify是一款AI应用开发平台,提供多种自然语言处理能力。通过调用Dify开放API,开发者可以快速集成智能对话、文本生成等功能到自己的Java应用中。 二、准备工作 获取API密钥 登录Dify平台控制台在「API密…...

极狐GitLab GEO 功能介绍
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 Geo (PREMIUM SELF) Geo 是广泛分布的开发团队的解决方案,可作为灾难恢复策略的一部分提供热备份。Geo 不是 开箱…...

Nginx-前言
nginx是什么? 轻量级,开源免费的web服务器软件,服务器安装nginx,服务器则成为web服务器 nginx的稳定版版本号: 偶数版本 nginx的相关目录: /etc/nginx/nginx.conf nginx的主配置文件 /etc/nginx/ngi…...

LFI to RCE
LFI不止可以来读取文件,还能用来RCE 在多道CTF题目中都有LFItoRCE的非预期解,下面总结一下LFI的利用姿势 1. /proc/self/environ 利用 条件:目标能读取 /proc/self/environ,并且网页中存在LFI点 利用方式: 修改请…...
云原生(Cloud Native)的详解、开发流程及同类软件对比
以下是云原生(Cloud Native)的详解、开发流程及同类软件对比: 一、云原生核心概念 定义: 云原生(Cloud Native)是基于云环境设计和运行应用程序的方法论,强调利用云平台的弹性、分布式和自动化…...
生成策略)
全局唯一标识符(UID)生成策略
目录 一、UUID 二、雪花算法 三、时间戳 随机数 四、利用数据库的自增字段 五、 基于 Redis 的原子操作 总结 在信息系统中,生成唯一ID是非常常见的需求,尤其是在分布式系统或高并发场景下。以下是几种常见的生成唯一ID的算法或方式: …...

学习笔记:减速机工作原理
学习笔记:减速机工作原理 一、减速机图片二、减速比概念三、减速机的速比与扭矩之间的关系四、题外内容--电机扭矩 一、减速机图片 二、减速比概念 即减速装置的传动比,是传动比的一种,是指减速机构中,驱动轴与被驱动轴瞬时输入速…...

《UE5_C++多人TPS完整教程》学习笔记36 ——《P37 拾取组件(Pickup Widget)》
本文为B站系列教学视频 《UE5_C多人TPS完整教程》 —— 《P37 拾取组件(Pickup Widget)》 的学习笔记,该系列教学视频为计算机工程师、程序员、游戏开发者、作家(Engineer, Programmer, Game Developer, Author) Steph…...

《空间复杂度(C语言)》
文章目录 前言一、什么是空间复杂度?通俗理解: 二、空间复杂度的数学定义三、常见空间复杂度举例(含C语言代码)🔹 O(1):常数空间🔹 O(n):线性空间🔹 O(n^2):平…...