数据类型相关问题导致的索引失效 | OceanBase SQL 优化实践
背景
针对在OceanBase 论坛中遇到的一些典型SQL调优问题,进行记录与总结,分享给大家。本文介绍的事3个场景:数据类型不匹配、字符集相关属性不匹配,和过滤/联接条件上包含系统函数。
场景一:数据类型不匹配
类型不匹配包括两方面:
- 数据类型不匹配:比如 int vs varchar 等。
- 数据精度(包含 precision、scale 等数据类型的附属属性)不匹配:比如 char(100) vs char(1)、decimal(5, 2) vs decimal(3, 1) 等。
接下来看一个数据类型不匹配的简单例子:
create table t1(c1 varchar(10) primary key);insert into t1 values('1'), ('01.0'), ('+1.0');select * from t1 where c1 = 1;
+------+
| c1 |
+------+
| +1.0 |
| 01.0 |
| 1 |
+------+-- sql 1
obclient> explain select * from t1 where c1 = 1;
+---------------------------------------------------------------------------------------------------+
| Query Plan |
+---------------------------------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t1 |1 |4 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1]), filter([cast(t1.c1, DECIMAL(-1, -1)) = cast(1, DECIMAL(1, 0))]), rowset=16 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c1]), range(MIN ; MAX)always true |
+---------------------------------------------------------------------------------------------------+
11 rows in set (0.04 sec)
在上面的例子中,sql 1 的计划显示进行了全表扫描,没有使用索引:
- 查询计划中的 range_key 为 t1.c1,由于 c1 是字符串类型,而 1 是整数类型,因此进行了隐性类型转换(Implicit cast)。
- 转执行程中,系统会隐式地把 varchar 类型的 '+1.0' 被转换为 int 类型的 1,无法利用建在 varchar 上的索引进行 int 类型的定位。
- 这个隐式类型转换方向是由 SQL 标准制定的,标准 SQL 定义的转换方向大致是:字符串类型 -> 数字类型 -> 时间类型。
作为对比,下面 sql 2 的计划中,通过显式指定类型转换,从而可以达到利用索引进行TABLE GET的目的。(注意:这样改写 SQL 之后,和上面的 SQL 是不等价的,需要关注是否是业务可以接受的!)
-- sql 2
obclient> explain select * from t1 where c1 = cast(1 as char);
+----------------------------------------------------+
| Query Plan |
+----------------------------------------------------+
| ========================================= |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------- |
| |0 |TABLE GET|t1 |1 |3 | |
| ========================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1]), filter(nil), rowset=16 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.c1]), range[1 ; 1], |
| range_cond([t1.c1 = cast(1, CHAR(1048576))]) |
+----------------------------------------------------+为了方便大家理解,我们再反着来一遍,创建一个整数类型的列 c1,并尝试使用字符 '+1.0' 来查询。
create table t1(c1 int primary key);obclient> explain select * from t1 where c1 = '+1.0';
+--------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------+
| ========================================= |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------- |
| |0 |TABLE GET|t1 |1 |5 | |
| ========================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1]), filter(nil), rowset=16 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.c1]), range[1 ; 1], |
| range_cond([cast(t1.c1, DECIMAL(11, 0)) = cast('+1.0', DECIMAL(1, -1))]) |
+--------------------------------------------------------------------------------+
12 rows in set (0.04 sec)在上面这个例子中,尽管我们使用了字符 '+1.0' 来查询整数类型的列 c1,查询计划仍然使用了索引扫描。这是因为索引建在整型列上,隐式类型转换会将字符 '+1.0' 转换为整数 1,转换之后正好可以利用到建在整数类型上的索引。
场景二:字符集相关属性不匹配
charset 或者 collation 不同,都会导致无法利用索引。
请大家直接参考上一篇博客《collation 导致的索引失效》,内容十分详实,所以这里不再赘述了。
场景三:过滤/联接条件上包含系统函数
创建如下的表和索引,索引建在 date 类型列上。
CREATE TABLE employees (employee_id INT PRIMARY KEY,hire_date DATE
);CREATE INDEX idx_hire_date ON employees(hire_date);执行 SQL 时,如果在过滤条件中的 hire_dater 列的外层加一个 year 函数,就无法走上索引了。这个很好理解,索引建在 date 类型列上,但是过了条件两边,一个是 year,一个是 int,都不是 date 类型,走不上索引也是理所应当。
explain SELECT * FROM employees WHERE YEAR(hire_date) = 2023;
+---------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+---------------------------------------------------------------------------------------------------------------------+
| ==================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ---------------------------------------------------- |
| |0 |TABLE FULL SCAN|employees|1 |4 | |
| ==================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([employees.employee_id], [employees.hire_date]), filter([year(employees.hire_date) = 2023]), rowset=16 |
| access([employees.employee_id], [employees.hire_date]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([employees.employee_id]), range(MIN ; MAX)always true |
+---------------------------------------------------------------------------------------------------------------------+
11 rows in set (0.005 sec)这个时候,有一些用户会尝试用 hint 强制让 SQL 走索引,不过类型不匹配,索引无能为力,最终依然走不上索引。
explain basic SELECT /* index(employees idx_hire_date) */ * FROM employees WHERE year(hire_date) = 2023;
+---------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+---------------------------------------------------------------------------------------------------------------------+
| ============================== |
| |ID|OPERATOR |NAME | |
| ------------------------------ |
| |0 |TABLE FULL SCAN|employees| |
| ============================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([employees.employee_id], [employees.hire_date]), filter([year(employees.hire_date) = 2023]), rowset=16 |
| access([employees.employee_id], [employees.hire_date]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([employees.employee_id]), range(MIN ; MAX)always true |
+---------------------------------------------------------------------------------------------------------------------+
11 rows in set (0.05 sec)这种场景,最简单的等价 SQL 改写方法,就是让过滤条件中出现索引列的 date 类型,例如:
explain SELECT * FROM employees WHERE hire_date BETWEEN '2023-01-01' AND '2023-12-31';
+-----------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------+
| ==================================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------------------------- |
| |0 |TABLE RANGE SCAN|employees(idx_hire_date)|1 |4 | |
| ==================================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([employees.employee_id], [employees.hire_date]), filter(nil), rowset=16 |
| access([employees.employee_id], [employees.hire_date]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([employees.hire_date], [employees.employee_id]), range(2023-01-01,MIN ; 2023-12-31,MAX), |
| range_cond([cast(employees.hire_date, DATETIME(-1, -1)) >= INTERNAL_FUNCTION('2023-01-01', 114, 17)], [cast(employees.hire_date, DATETIME(-1, -1)) |
| <= INTERNAL_FUNCTION('2023-12-31', 112, 17)]) |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------+
13 rows in set (0.003 sec)
最后再多说一句,如果在过滤/联接条件的列上,加了计算结果类型和索引列类型一样的系统函数,也会导致走不上索引。例如:
create table t1(c1 int, index idx(c1));-- 走上索引了
obclient [test]> explain select * from t1 where c1 = 1;
+-----------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------+
| =================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------- |
| |0 |TABLE RANGE SCAN|t1(idx)|1 |4 | |
| =================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1]), filter(nil), rowset=16 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.c1], [t1.__pk_increment]), range(1,MIN ; 1,MAX), |
| range_cond([t1.c1 = 1]) |
+-----------------------------------------------------------------------+
12 rows in set (0.013 sec)-- 过滤条件在列上加了个 add 函数,就走不上索引
explain select * from t1 where c1 + 1 = 1;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t1 |1 |4 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1]), filter([t1.c1 + 1 = 1]), rowset=16 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
+------------------------------------------------------------------------------------+
11 rows in set (0.002 sec)原因是优化器在抽 query range 的时候,range_key 上不能有函数。不然每一行在函数作用下的结果可能都是不连续的,就构不成 range 了。
总结
- 当 SQL 走不上索引时,需要注意索引条件上是否存在隐式 cast,并考虑能否通过显式指定 cast 或其他 SQL 改写的方式解决该问题。
- 尽量保证索引条件上 column 属性和索引列完全一致,包括数据类型、字符集属性(charset 和 collation)、精度(precision 和 scale)等。
- 尽量不要在过滤条件和联接条件里,对希望能走索引的列上加系统函数。可以考虑通过改写 SQL 解决该问题。
补充
针对性能调优的各种场景,在OceanBas社区中建立了一个《OceanBase 性能调优》博客专题,欢迎大家积极留言评论,提出您的问题和需求。
相关文章:

数据类型相关问题导致的索引失效 | OceanBase SQL 优化实践
背景 针对在OceanBase 论坛中遇到的一些典型SQL调优问题,进行记录与总结,分享给大家。本文介绍的事3个场景:数据类型不匹配、字符集相关属性不匹配,和过滤/联接条件上包含系统函数。 场景一:数据类型不匹配 类型不匹…...
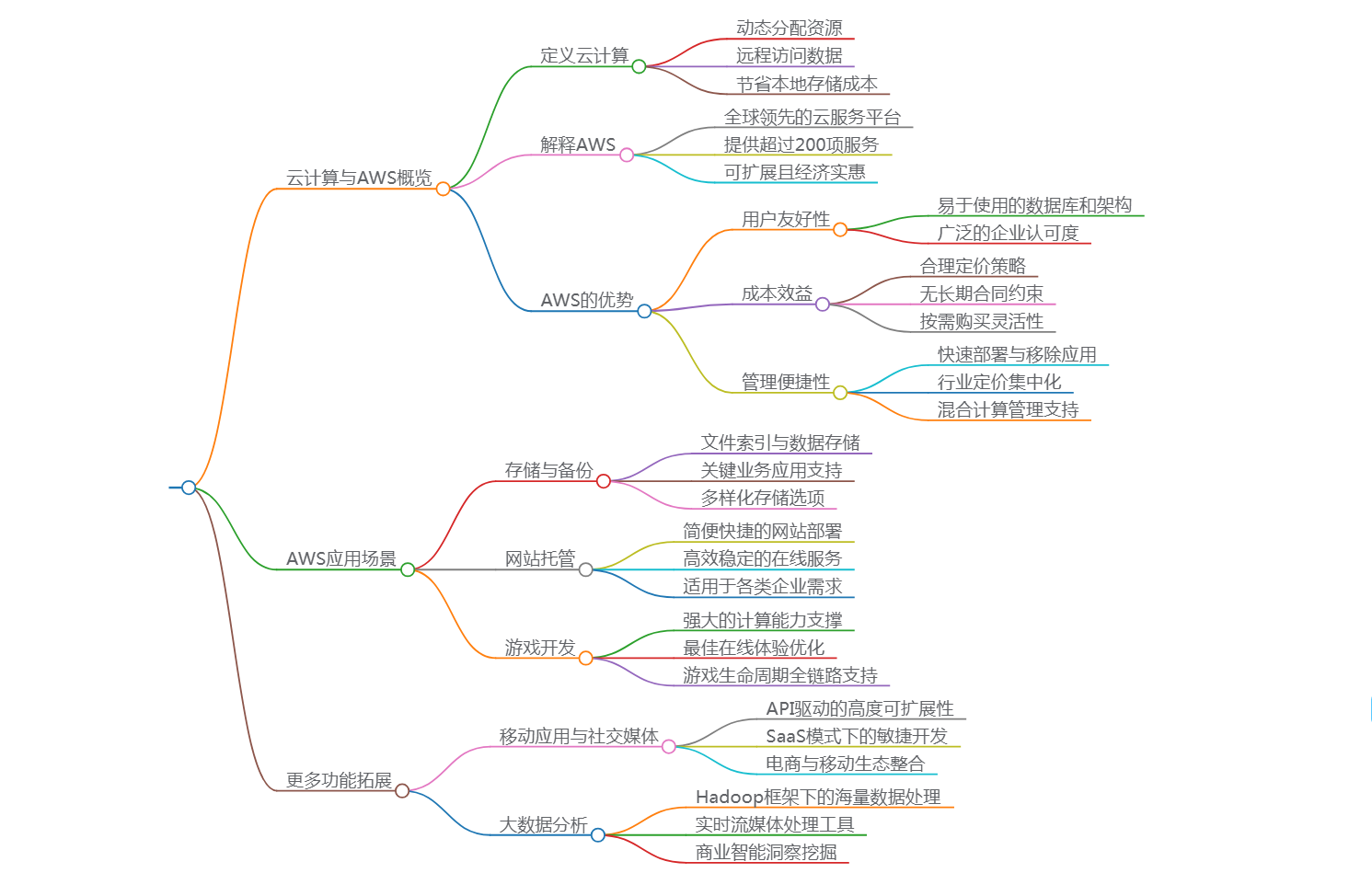
云计算(Cloud Computing)概述——从AWS开始
李升伟 编译 无需正式介绍亚马逊网络服务(Amazon Web Services,简称AWS)。作为行业领先的云服务提供商,AWS为全球开发者提供了超过170项随时可用的服务。 例如,Adobe能够独立于IT团队开发和更新软件。通过AWS的服务&…...
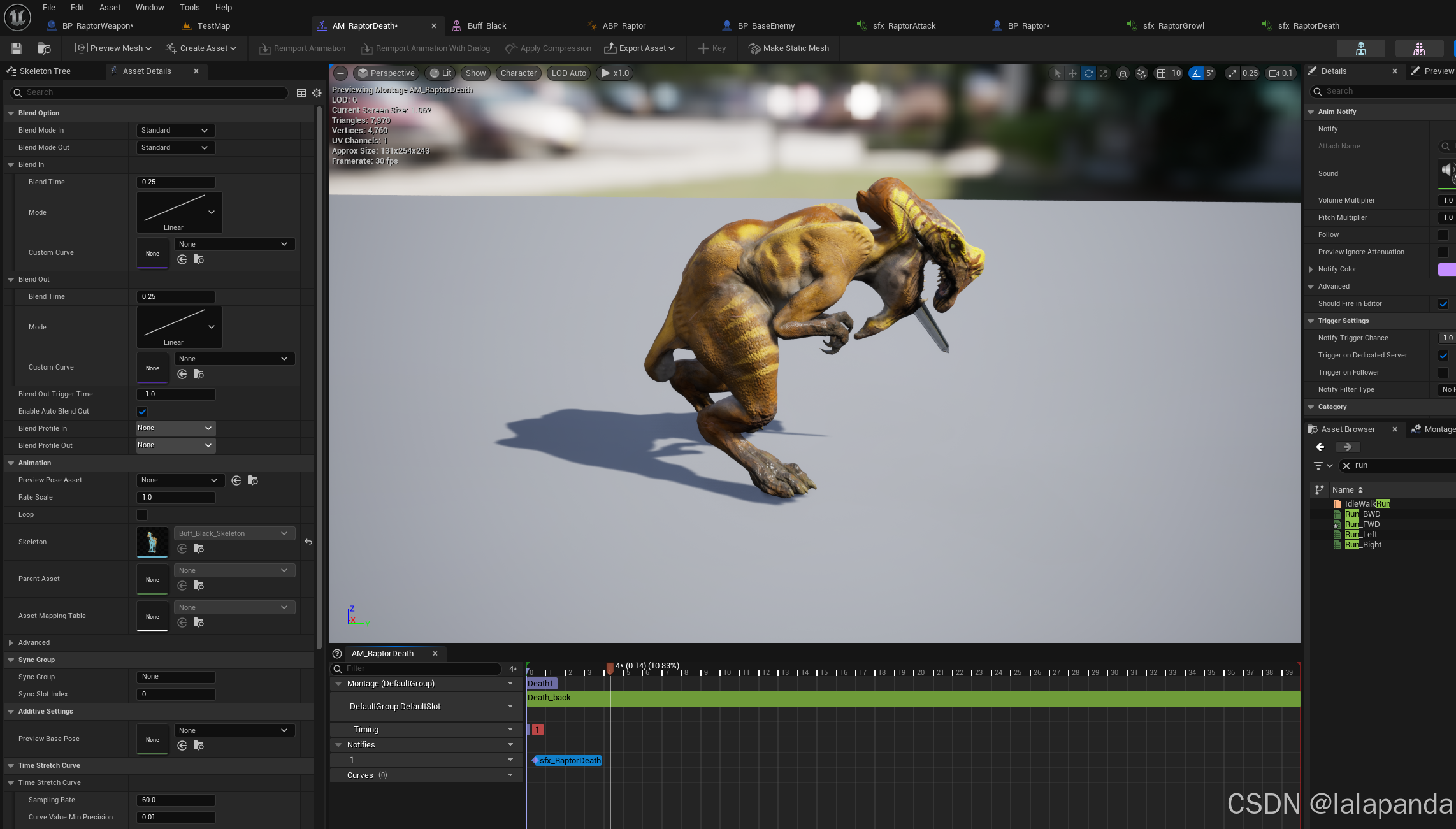
UE学习记录part18
225 animation blueprint templates: generic animation blueprints 在Animation Blueprint中选择template生成动画蓝图模板 在function中选择blurprintthreadsafeupdateanimation,用于做数据的更新 先创建变量,再将变量再blueprintinitializeanimation…...

刀片服务器的散热构造方式
刀片服务器的散热构造是其高密度、高性能设计的核心挑战之一。其散热系统需在有限空间内高效处理多个刀片模块产生的集中热量,同时兼顾能耗、噪音和可靠性。以下从模块化架构、核心散热技术、典型方案对比、厂商差异及未来趋势等方面展开分析: 一、模块化散热架构 刀片服务器…...

算法01-最小生成树prim算法
最小生成树prim算法 题源:代码随想录卡哥的题 链接:https://kamacoder.com/problempage.php?pid1053 时间:2025-04-18 难度:4⭐ 题目: 1. 题目描述: 在世界的某个区域,有一些分散的神秘岛屿&…...

【每日八股】复习计算机网络 Day1:TCP 的头部结构 + TCP 确保可靠传输 + TCP 的三次握手
文章目录 复习计算机网络 Day1TCP 的头部结构TCP 如何保证可靠传输?1. 数据完整性保障2. 顺序与去重控制3. 流量与拥塞控制4. 连接控制5. 其他辅助机制TCP 可靠传输的保障手段总结 TCP 的三次握手?TCP 为什么要三次握手?TCP 三次握手出现报文…...
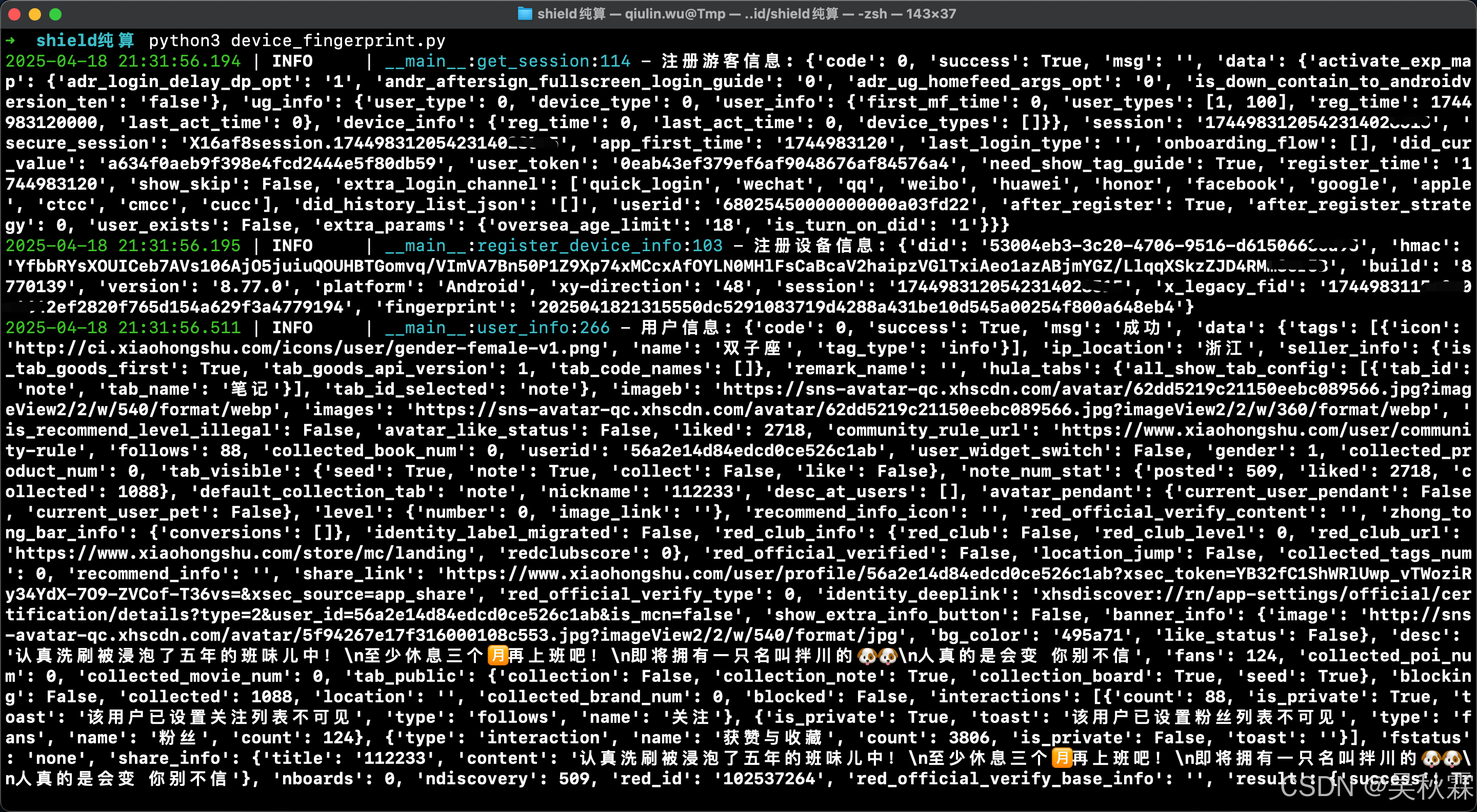
device_fingerprint、device_id、hmac生成
文章目录 1. 写在前面2. 设备信息3. 数美指纹 【🏠作者主页】:吴秋霖 【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守并致力于Python…...

高防IP如何针对DDoS攻击特点起防护作用
高防IP通过多层防护机制和动态资源调度能力,针对性化解DDoS攻击的核心特征(如大流量、协议滥用、连接耗尽等)。以下是其具体防护策略与技术实现: 一、DDoS攻击的核心特点与高防IP的针对性策略 攻击特…...

python抓取HTML页面数据+可视化数据分析(投资者数量趋势)
本文所展示的代码是一个完整的数据采集、处理与可视化工具,主要用于从指定网站下载Excel文件,解析其中的数据,并生成投资者数量的趋势图表。以下是代码的主要功能模块及其作用: 1.网页数据获取 使用fetch_html_page函数从目标网…...

C++ std::function的含义、意义和用法,与std::bind的区别
在 C 中,std::function 是一个通用的多态函数包装器,它是 C 标准库 <functional> 头文件中的一部分。下面从含义、意义和用法三个方面详细介绍 std::function。 含义 std::function 是一个类模板,它可以存储、复制和调用任何可调用对…...
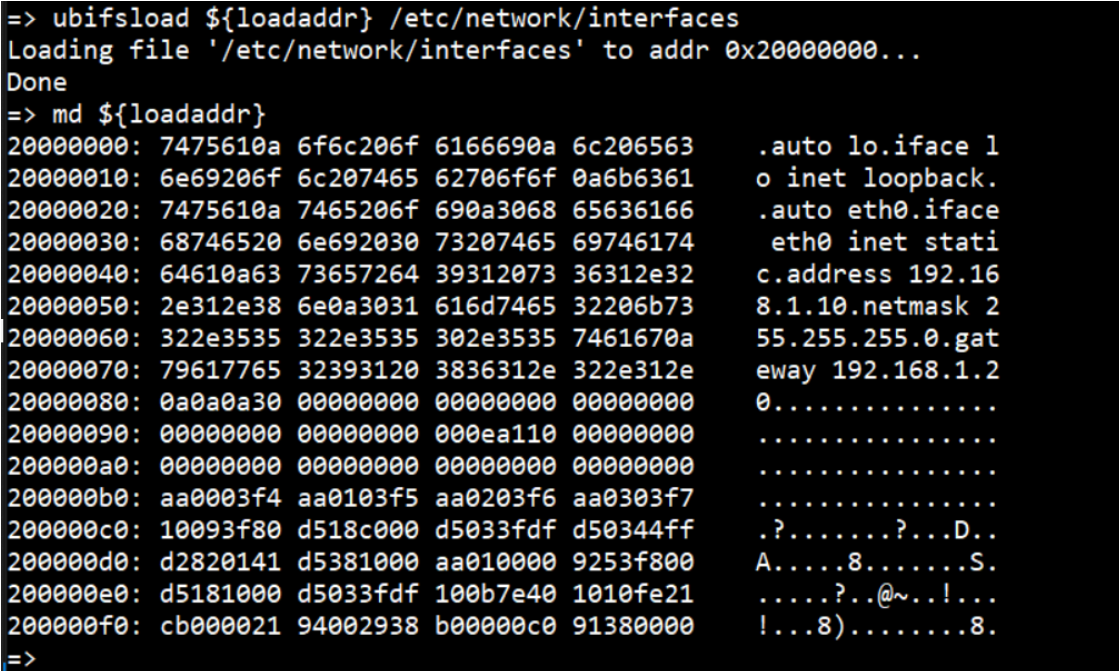
uboot下读取ubifs分区的方法
在uboot 的defconfig中增加以下内容: CONFIG_MTDIDS_DEFAULT"nand0nand0" CONFIG_MTDPARTS_DEFAULT"mtdpartsnand0:1M(boot1),1M(boot2),1M(hwinfo),6M(kernel1),6M(kernel2),56M(rootfs1),56M(rootfs2),-(ubi2)" CONFIG_CMD_UBIy 其中&#x…...

HAL详解
一、直通式HAL 这里使用一个案例来介绍直通式HAL,选择MTK的NFC HIDL 1.0为例,因为比较简单,代码量也比较小,其源码路径:vendor/hardware/interfaces/nfc/1.0/ 1、NFC HAL的定义 1)NFC HAL数据类型 通常定…...
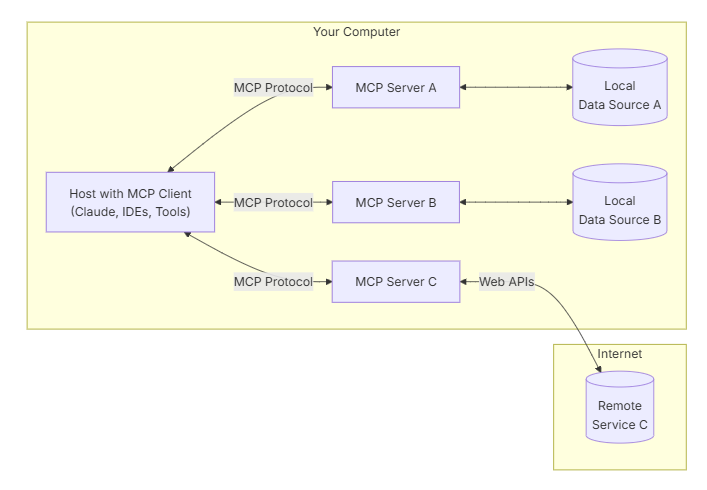
MCP(模型上下文协议)说明
背景 MCP(Model Context Protocol,模型上下文协议)旨在解决大型语言模型(LLM)与外部数据源及工具集成的问题。由Anthropic公司于2024年11月提出并开源,目标是实现AI模型与现有系统的无缝集成。 解决的问题…...

AI当前状态:有哪些新技术
一、到目前为址AI领域出现的新技术 到目前为止,AI领域涌现了许多令人兴奋的新技术。以下是一些关键的进展,涵盖了从基础模型到实际应用的多个方面: 1. 更强大的大型语言模型 (LLMs): 性能提升: 新一代LLM,例如OpenAI的GPT-4o和…...

如何校验一个字符串是否是可以正确序列化的JSON字符串呢?
方法1:先给一个比较暴力的方法 try {JSONObject o new JSONObject(yourString); } catch (JSONException e) {LOGGER.error("No valid json"); } 方法2: Object json new cn.hutool.json.JSONTokener("[{\"name\":\"t…...
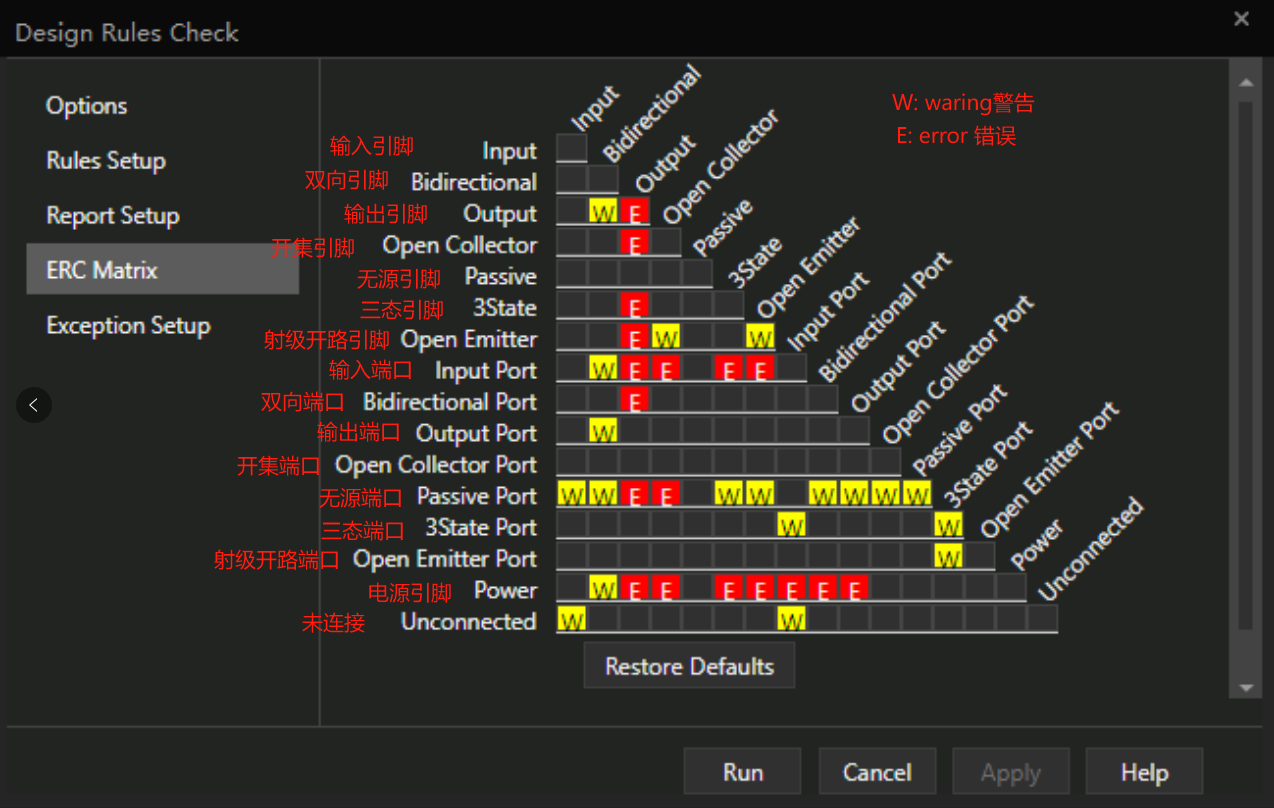
orcad csi 17.4 DRC规则设置及检查
rCAD绘制完原理图之后总是需要开启DRC检测,但是DRC一般都是英文版的,下面基于Cadence17.4 的orCAD16.6 对DRC的界面做简单的介绍 首先,鼠标点击原理图,然后再点击右上方的小勾图标 desine rules check option选项的界面 电气规…...

k8s教程3:Kubernetes应用的部署和管理
学习目标 理解Kubernetes中应用部署的基本概念和方法掌握Deployment、ReplicaSet、StatefulSet、DaemonSet、Job与CronJob等控制器的使用了解Helm作为Kubernetes的包管理工具的基本使用通过实际示例学习应用的部署、更新与管理 Kubernetes提供了一套强大而灵活的机制ÿ…...

微信小程序获得当前城市,获得当前天气
// // 获取用户当前所在城市 // wx.getLocation({// type: wgs84, // 默认为 wgs84 返回 gps 坐标,gcj02 返回可用于 wx.openLocation 的坐标 // success: function(res) {// console.log(获取位置成功, res); // // 使用腾讯地图API进行逆地址解析 // wx…...

磁流变式汽车减振器创新设计与关键技术研究
摘要 本文针对智能悬架系统的发展需求,深入探讨磁流变减振器(MR Damper)的核心设计原理与工程实现路径。通过建立磁场-流场耦合模型,优化磁路结构与控制策略,提出具有快速响应特性的新型磁流变减振器设计方案…...

Python3.14都有什么重要新特性
目录 1、语法糖新宠:模式匹配再进化 1.1 结构化数据克星 1.2 类型守卫(Type Guard) 2、性能黑科技:尾递归与异步双杀 2.1 尾调用优化(TCO) 2.2 异步任务重构 3、注释系统重构:annotationlib深度解析 3.1 延迟评估机制 3.2 类型推导增…...

前端资源加载失败后重试加载(CSS,JS等引用资源)
前端资源加载失败后的重试 .前端引用资源时出现了资源加载失败(这里针对的是路径引用异常或者url解析错误时) 解决这个问题首先要明确一下几个步骤 1.什么情况或者什么时候重试 2.如何重试 3.重试过程中的边界处理 这里引入里三个测试脚本,分别加载里三个不同的脚…...
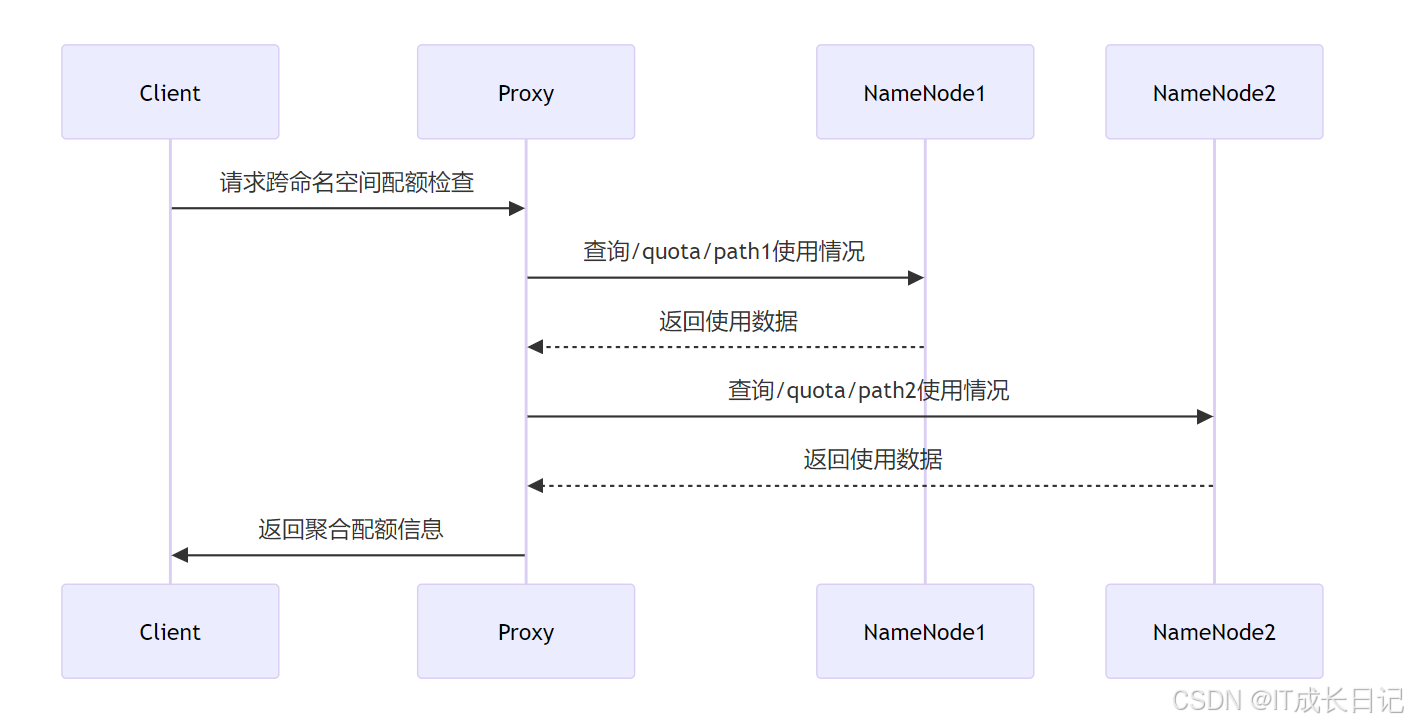
【HDFS入门】联邦机制(Federation)与扩展性:HDFS NameNode水平扩展深度解析
目录 引言 1 NameNode水平扩展原理 1.1 传统HDFS架构的局限性 1.2 联邦机制的基本原理 1.3 联邦架构的关键组件 2 多个Namespace的路由规则配置 2.1 客户端挂载表概念 2.2 挂载表配置示例 2.3 挂载表匹配规则 2.4 配置示例 3 BlockPool与Namespace的映射关系 3.1 B…...

C#学习第16天:聊聊反射
什么是反射? 定义:反射是一种机制,允许程序在运行时获取关于自身的信息,并且可以动态调用方法、访问属性或创建实例。用途:常用于框架设计、工具开发、序列化、代码分析和测试等场景 反射的核心概念 1. 获取类型信息…...

论文阅读:2024 arxiv AI Safety in Generative AI Large Language Models: A Survey
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 AI Safety in Generative AI Large Language Models: A Survey https://arxiv.org/pdf/2407.18369 https://www.doubao.com/chat/3262156521106434 速览 研究动机&#x…...
AI推荐系统的详细解析 +推荐系统中滤泡效应(Filter Bubble)的详细解析+ 基于Java构建电商推荐系统的分步实现方案,结合机器学习与工程实践
以下是AI推荐系统的详细解析: 一、核心概念 定义 推荐系统是通过分析用户行为、物品特征或用户画像,向用户推荐个性化内容的技术,广泛应用于电商、视频、社交等领域。 目标 提升用户留存与转化率增强用户体验实现精准营销 二、技术原理 1…...

CSS 美化页面(五)
一、position属性 属性值描述应用场景static默认定位方式,元素遵循文档流正常排列,top/right/bottom/left 属性无效。普通文档流布局,默认布局,无需特殊定位。relative相对定位,相对于元素原本位置进行偏…...

java 设计模式之模板方法模式
简介 模板方法模式:定义一个算法的基本流程,将一些步骤延迟到子类中实现。模板方法模式可以提高代码的复用性, 模板方法中包含的角色: 抽象类:负责给出一个算法的基本流程,它由一个模板方法和若干个基本…...

基于大模型的腹股沟疝诊疗全流程风险预测与方案制定研究报告
目录 一、引言 1.1 研究背景与意义 1.2 国内外研究现状 1.3 研究目的与创新点 二、大模型技术概述 2.1 大模型基本原理 2.2 常用大模型类型及特点 2.3 大模型在医疗领域的应用潜力 三、腹股沟疝诊疗流程分析 3.1 腹股沟疝的发病机制与分类 3.2 传统术前评估方法与局…...
无约束最优化问题的求解算法--梯度下降法(Gradient Descent)
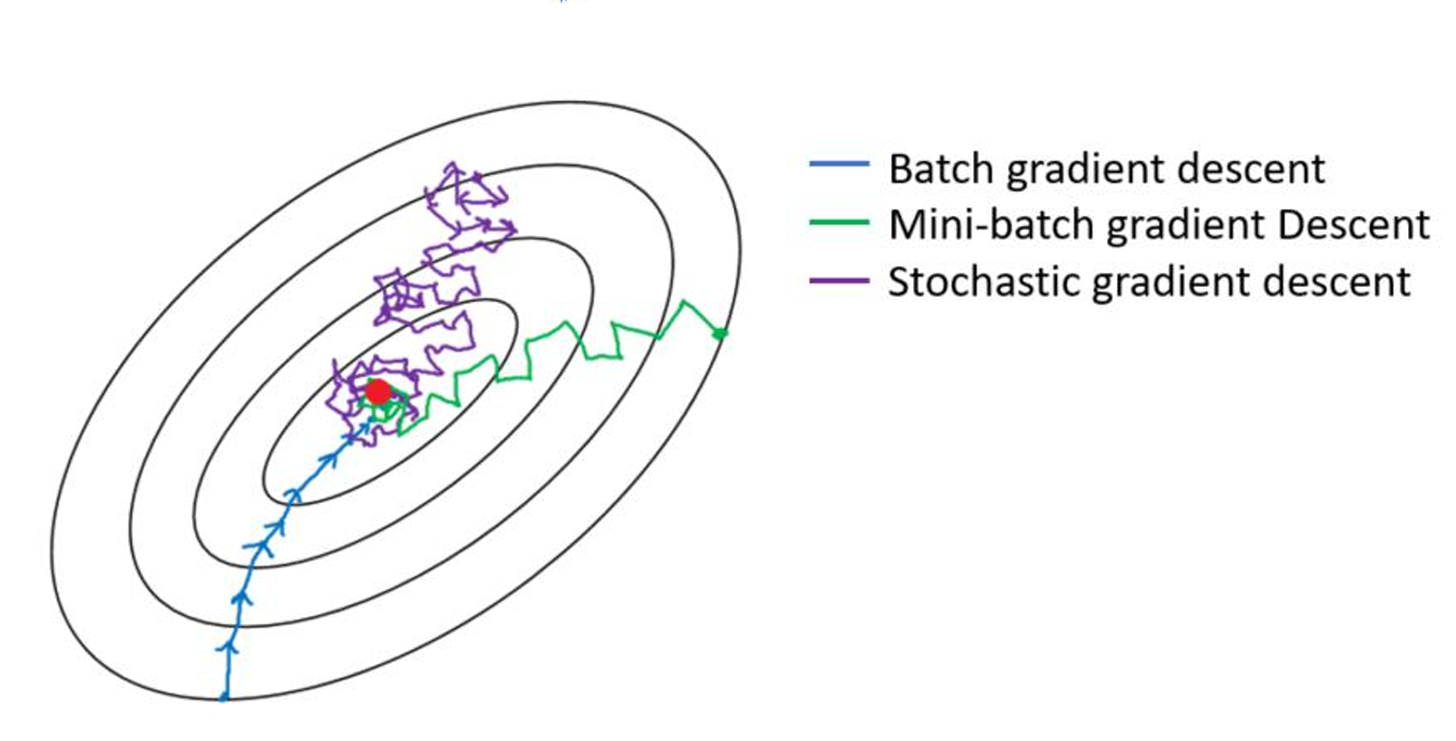
文章目录 梯度下降法梯度下降法原理(通俗版)梯度下降法公式学习率的设置**如何选择学习率?** 全局最优解梯度下降法流程损失函数的导函数三种梯度下降法**梯度下降法核心步骤回顾****优缺点详解****1. 全量梯度下降 (Batch Gradient Descent,…...
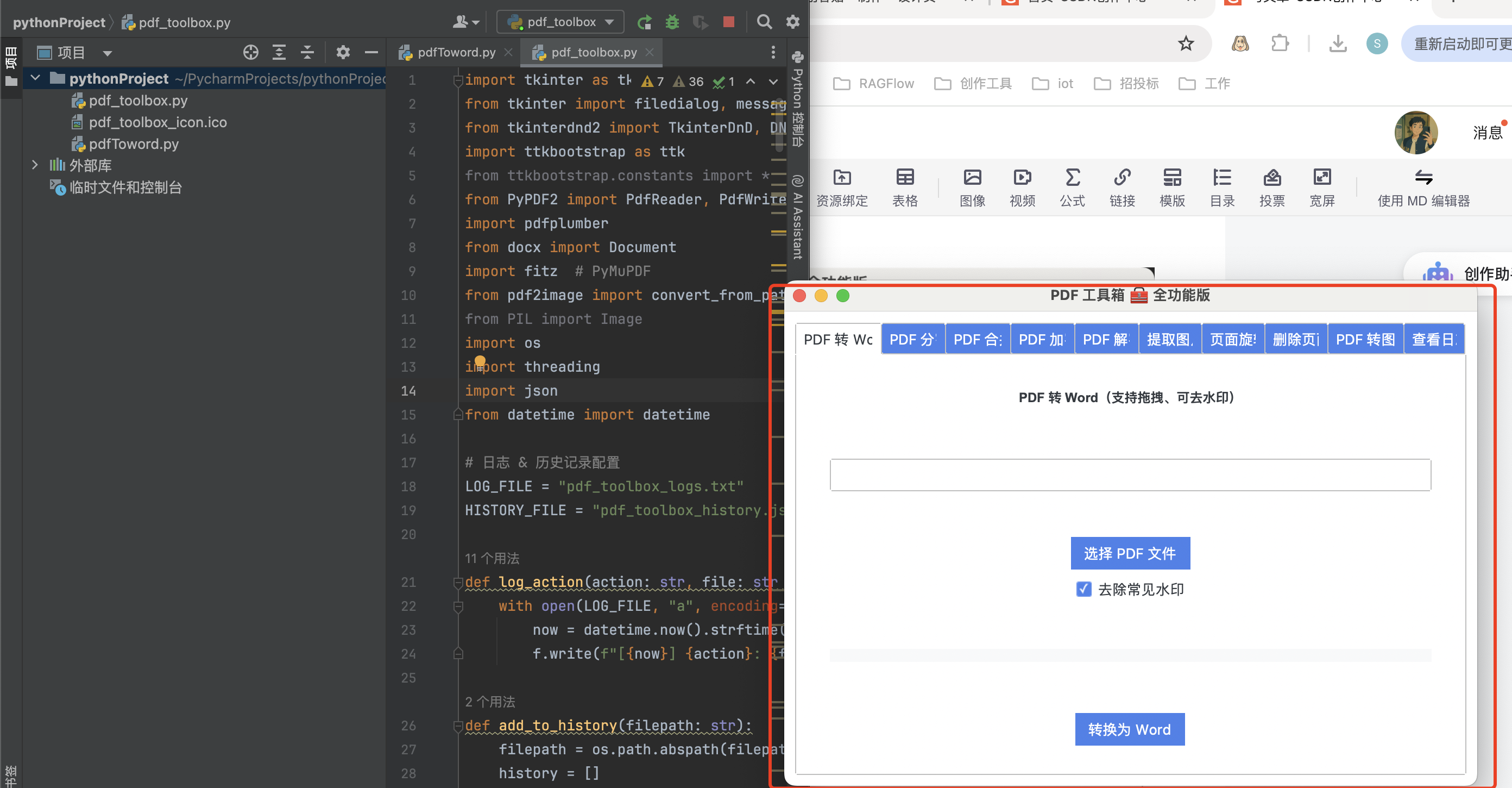
Python全功能PDF工具箱GUI:支持转换、加密、旋转、图片提取、日志记录等多功能操作
使用Python打造一款集成 PDF转换、编辑、加密、解密、图片提取、日志追踪 等多个功能于一体的桌面工具应用(Tkinter ttkbootstrap PyPDF2 等库)。 ✨项目背景与开发动机 在日常办公或学习中,我们经常会遇到各种关于PDF文件的操作需求&#…...