【C++深入系列】:模版详解(上)
🔥 本文专栏:c++
🌸作者主页:努力努力再努力wz



💪 今日博客励志语录:
你不需要很厉害才能开始,但你需要开始才能很厉害。
★★★ 本文前置知识:
类和对象(上)
类和对象(中)
类和对象(下)
引入
那假设有这么一个场景,那么你现在要编写一个简单的程序,那么该程序实现的内容就是交换两个数,那么此时你会如何实现呢?
那么我们可以定义一个交换的_swap函数,那么这个函数就是用来实现交换两个数,但是这两个数的数据类型可以是内置类型也可以是自定义类型,那么意味着我们得利用函数的重载,编写多个同名但是参数列表不同的 _swap函数来处理多种不同数据类型的两个数的交换
void swap(int& a,int& b)
{int temp=a;a=b;b=temp;
}
void swap(double& a,double&b)
{double temp=a;a=b;b=temp;
}
.....
那么上面的这种实现方式肯定是没问题的,但是不难会发现这里定义了的多个 _swap函数,那么它们的函数逻辑都是一样的,唯一的区别就是处理的数据类型是不同的,那么这样其实会导致代码重复以及逻辑冗余,并且假设我们 _swap函数的代码逻辑写错了,我们还得修改之前编写的所有的 _swap函数,所以还存在不好维护的问题
为了解决这个问题,如果我们可以尝试把这些重载函数的代码逻辑给提取出来,忽略其涉及到的数据的数据类型,而我们需要调用处理特定数据类型的函数的话,那么只需要套用这个代码逻辑,将其中的数据类型给替换为我们想要的目标数据类型,而这种解决方式正是c++的模版解决该问题的核心思想,那么下文我将会从模版的使用以及其相关细节等多个维度带你全面认识模版,那么相信你看完之后,一定会对模版爱不释手
什么是模版以及模版如何使用
那么从模版这个名字,就形象的告诉了它的作用,那么对于函数来说,如果该函数要对不同的数据类型应用同一套函数逻辑的话,那么我们就可以采取模版,那么将该函数的代码逻辑给提取出来,忽略其涉及到的数据的数据类型,那么所谓的忽略其涉及到的数据的数据类型,不是说模版不提供数据类型,而是说它将该函数中涉及到的数据的数据类型都用一个变量来表示,那么这个变量可以代表着任意一个数据类型比如像int,double这样的内置类型,也可以是你自己定义的自定义类型,那么说这么多,我们先来看看模版长什么样子,那么我以上文的 _swap函数为例,来看看如何定义一个 _swap函数模版:
template<typename T>
void _swap(T& a,T&b)
{T temp=a;a=b;b=a;
}
那么其中模版的定义需要用到template关键字,那么template就是模版的英文,而后面跟上的尖括号里面的内容就是数据类型,那么它用一个变量T来表示,那么这个T就代表着任意的数据类型,那么它的专业的术语叫做模版参数,其中我们可以用typename或者class来声明一个模版参数,template下面就是模版函数的定义,那么此时模版函数不关心具体处理的是什么类型的数据,并且将涉及到的数据类型都用模版参数来替代
那么知道了模版如何定义之后,我们再来看看模版是如何使用,那么还是以 _swap函数为例,那么我写了一份简单的调用 _swap函数的c++代码:
#include<iostream>
using namespace std;
template<typename T>
void _swap(T& a, T& b)
{T temp = a;a = b;b = temp;
}
int main()
{int a = 10;int b = 20;cout << "befor: a=" << a << " b=" << b << endl;_swap(a, b);cout << "after: a=" << a << " b=" << b << endl;return 0;
}

那么我们发现调用模版函数就和我们调用普通函数一样,在代码中直接调用即可,而这就是模版的强大之处,当我们调用模版函数时,那么编译器会根据你函数调用处识别到参数的数据类型,然后找到匹配的函数模版,由于模版定义的时候,你已经给出了该函数的完整定义,只不过不涉及到的具体的数据类型,那么这里编译器就会将T给赋予具体的含义,替换为int类型或者double类型等等,也就意味着编译器此识别到模版函数调用处涉及到的参数的数据类型,然后根据模版实例化出一份具体的函数代码实现
所以之所以我们能够像调用普通函数那样调用模版函数,是因为有一个人为我们默默承担了一切,那么这个人就是编译器,那么本来应该由我们自己去编写处理int类型的数据的 _swap函数的代码以及处理double类型的数据的 _swap函数的代码,那么这个工作都交给了编译器来完成,也就是编译器在编译阶段会根据你调用该模版函数传的具体的参数的数据类型,然后它自己根据模版生成一份该函数的代码
所以总而言之,模版就是一个蓝图,那么编译器就像一个建筑师,那么它手上持有了这份蓝图,那么编译器会根据模版函数调用处传递的参数的类型,来根据蓝图建造出不同的房子,那么这就是模版,那么模版的出现就体现了一个泛型编程的思想,所谓的泛型编程就是编写独立于数据类型的代码
模版的相关细节补充
1.template关键字
那么我们知道了模版函数如何定义以及如何调用之后,那么有的小伙伴可能对于template关键字的使用不是特别熟悉,假设有这么一个场景,那么有个小伙伴想要定义两个模版函数,比如一个是上文所说的用于交换两个数的 _swap函数,另一个则是用于比较两个数大小的 _max函数,那么此时它采取的是这种方式定义模版函数的:
template<typename T>
void _swap(T& a, T& b)
{T temp = a;a = b;b = temp;
}
T _max(T&a,T&b)
{return a>=b? a: b;
}
那么你觉得上面小伙伴这种定义的方式对吗?那么接下来我通过代码来验证一下:
#include<iostream>
using namespace std;
template<typename T>
void _swap(T& a, T& b)
{T temp = a;a = b;b = temp;
}
T _max(T& a, T& b)
{return a >= b?a : b;
}
int main()
{int a = 10;int b = 20;cout << "max :" << _max(a, b) << endl;return 0;
}

那么根据运行结果我们知道这么定义是错的,那么我猜这么定义的小伙伴心里面想的就是我在template关键字下面定义两个模版函数,那么这两个模版函数都会采取用上面template关键字后面的同一个模版参数,那么如果有的小伙伴是怎么想的话,那么我想说,你还是把编译器想的太天真了
根据编译器报的错误,那么我们可以发现template作用或者说修饰的范围只能是它下面接挨着的函数或者我们后文说道的类(类也可以定义为模版),那么此时编译器就把你后面定义的 _max当做一个普通的全局函数的定义来处理了,而这里我们没有所谓的T的内置类型,并且我们在代码中也没有定义所谓的T的类,编译器也无法将其视作自定义类型来处理,所以这里会报一个无法识别T的类型的错误,那么在编译器阶段就不会通过,所以我们还是老老实实的在定义每一个模版函数或者模版类前面加一个template关键字
正确版本:
#include<iostream>
using namespace std;
template<typename T>
void _swap(T& a, T& b)
{T temp = a;a = b;b = temp;
}
template<typename T>
T _max(T& a, T& b)
{return a >= b?a : b;
}
int main()
{int a = 10;int b = 20;cout << "max :" << max(a, b) << endl;cout << "a: " << a << " b:" << b << endl;return 0;
}

2.模版函数的调用机制
那么有的现在有的小伙伴可能会好奇,对于上文提到的 _swap函数,那么如果这里我定义了一个 _swap的普通函数的话,并且也定义了 _swap 的模版函数,那么我能否调用成功该 _swap函数,那么这里我首先写了一个代码来实验一下,那么这里代码的逻辑也很简单,那么就是定义了一个 _swap的模版函数以及一个处理int类型数据交换的普通函数 :
#include<iostream>
using namespace std;
template<typename T>
void _swap(T& a, T& b)
{T temp = a;a = b;b = temp;
}
void _swap(double& a, double& b)
{double temp = a;a = b;b = temp;
}
int main()
{int a = 10;int b = 20;cout << "befor: " << "a=" << a << " b=" << b << endl;_swap(a, b);cout <<"after: " << "a: " << a << " b:" << b << endl;return 0;
}

那么结果没有任何问题
那么我们再来简单的改变一下代码的逻辑,让其处理double类型的数据的交换:
#include<iostream>
using namespace std;
template<typename T>
void _swap(T& a, T& b)
{T temp = a;a = b;b = temp;
}
void _swap(double& a, double& b)
{double temp = a;a = b;b = temp;
}
int main()
{double a = 10.7;double b = 20.5;cout << "befor: " << "a=" << a << " b=" << b << endl;_swap(a, b);cout <<"after: " << "a: " << a << " b:" << b << endl;return 0;
}

发现结果也没有问题,那么我们对于第一个代码,那么我们应该知道,这里我们调用的真正的 _swap函数其实是编译器利用模版生成的 _swap函数因为没有处理int类型的普通函数,而对于第二种情况,我们可能会存有一个疑问,那么就是这里理论上编译器可以调用模版实例化生成的函数,也可以调用我们定义的普通函数,那么这里编译器的最终的行为是什么呢?那么这里我在代码中打了断点,通过调试来看看编译器此时的选择:

那么根据调试的结果,我们可以发现,当我们运行到 _swap函数调用处的时候,那么此时编译器调用的是我们自己定义的 _swap函数,那么这里我们就可以认识到编译器调用模版函数的机制了,那么当我们调用一个函数的时候,那么编译器此时会收集候选函数,而这里的候选函数就包括我们自己定义匹配的普通函数以及模版函数,那么这时候编译器调用的优先级肯定是优先调用参数列表最为匹配的普通函数,如果没有普通函数,但是有模版函数的话,那么此时编译器才会根据模版实例化函数,然后调用实例化后的函数
3.在调用处显示实例化
那么在上文的 _max函数的例子中,那么该函数只能处理一种数据类型,也就是 _swap函数只能处理两个相同数据类型的数的交换,但是不能处理两个数数据类型不同的情况,比如一个int类型的数与double类型的数的交换:
#include<iostream>
using namespace std;
template<typename T>
T _max(T& a, T& b)
{return a>=b ?a :b;
}
int main()
{int a=10;double b=20.8;cout<<"max: "<<_max(a,b)<<endl;return 0;
}

那么之所以会出现这种情况,就是因为我们定义的模版参数只有一个,那么这里编译器识别到模版函数的调用处,那么其识别到了两种不同的类型,但是按照模版函数的定义,该模版函数只能处理一种数据类型,所以它无法根据模版来实例化出函数,所以为了解决这个问题,那么第一种做法可以是定义两个模版参数,那么这样编译器就可以根据模版生成函数了
#include<iostream>
using namespace std;
template<typename T1,typename T2>
T2 _max(T1& a, T2& b)
{return a >= b ? a : b;
}
int main()
{int a = 10;double b= 20.8;cout << "max: " << _max(a, b) << endl;return 0;
}

那么第二种方式就是可以利用类型转换,那么为了匹配模版参数,那么这里我们可以将int类型转换为double类型,但是这里由于是传值而不是传引用,那么类型转换中间会生成临时变量,而临时变量具有常性,所以这里我们得用const引用来接收:
#include<iostream>
using namespace std;
template<typename T>
T _max(const T& a, const T& b)
{return a >= b ? a : b;
}
int main()
{int a = 10;double b= 20.8;cout << "max: " << _max((double)a, b) << endl;return 0;
}
那么还有一种方式则是在调用处显示实例化,那么所谓显示实例化,就是在调用处给编译器指定你要将该位置的调用的模版函数的模版参数给实例化成什么类型,那么编译器此时就不会关心你传递的参数的类型,而是先生成一份函数,然后再去识别类型,调用相应的匹配的函数
#include<iostream>
using namespace std;
template<typename T>
T _max(const T& a, const T& b)
{return a >= b ? a : b;
}
int main()
{int a = 10;double b= 20.8;cout << "max: " << _max<double>(a, b) << endl;return 0;
}
4.类模版
那么刚才讲的例子都是函数模版,那么我们类也可以支持所谓的泛型编程的思想,也就是不关心特定的数据类型,那么比如拿我们的栈来作为例子,那么我们知道我们可以将栈定义为一个类,然后采取动态数组的方式来实现,那么此时这个数组里面的元素可以是存储的是int类型,也可以存储的是double类型,那么如果没有模版的话,那么我们采取的方式就是定义两个类,那么一个类名叫stackInt对应的是存储int类型的数据的栈,还得定义一个类名为stackDouble的类对应存储double类型的数据的栈,那么这里面临的问题和上文的函数面临的问题一样,那么就是会导致代码重复并且不好维护
所以这里我们可以将栈定义成一个模版类,那么这里不关心该类中涉及到各种成员变量的数据类型以及成员函数中定义的变量的数据类型:
template<typename T>
class stack
{private:T* ptr;T top;T max_size;public:stack(int _deafult):ptr(new T[_deafult]),top(-1),max_size(_deafult){}void push(T x){if(top+1==max_size){ptr=new T[2*max_size];max_size=2*max_size;}ptr[++top]=x;}void pop(){if(top==-1){return;}top--;}bool empty(){return top==-1;}
};
那么注意我们实例化一个模版类的对象的时候,就一定要注意,对于我们自定义的类来,那么它的类型就是类名,而对于模板类来说,那么类型不在等于类名,而是类名加模版参数才是类型,那么一定要注意这点
类名<type> a;
那么编译器会根据调用的类模版以及模版参数实例化出一份类:
#include<iostream>
using namespace std;
template<typename T>
class stack
{
private:T* ptr;T top;T max_size;
public:stack(int _deafult=4):ptr(new T[_deafult]), top(-1), max_size(_deafult){}void push(T x){if (top + 1 == max_size){ptr = new T[2 * max_size];max_size = 2 * max_size;}ptr[++top] = x;}void pop(){if (top == -1){return;}top--;}bool empty(){return top == -1;}void print(){for (int i = 0;i <= top;i++){cout << "stack[i]: " << ptr[i] << " ";}cout << endl;}
};
int main()
{stack<int> a;a.push(1);a.push(2);a.push(4);a.push(5);a.pop();a.print();return 0;
}

结语
那么这就是本期关于模版所讲解的全部内容,那么这部分内容只是模版的一部分知识点,那么剩余知识点我打算在介绍完STL之后的模版下篇讲解,那么这部分知识就足够让我们顺利进入STL的学习,那么注意模版应用的场景一定还是类或者函数的逻辑相同,处理的数据类型不同的情况,如果函数的逻辑不同的话,那么还是得老老实实利用函数重载自己去手写几份代码
那么下一期我将讲解string,那么我会持续更新,希望你多多关注,如果本文有帮组到你的话,还请多多支持,你的支持就是我创作的最大的动力!

相关文章:
【C++深入系列】:模版详解(上)
🔥 本文专栏:c 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: 你不需要很厉害才能开始,但你需要开始才能很厉害。 ★★★ 本文前置知识: 类和对象(上) …...

leetcode刷题日记——同构字符串
[ 题目描述 ]: [ 思路 ]: 题目要求判断 s 和 t 是否为同构字符串,即 s 中每个字符与 t 中对应位置的字符形成一个映射关系,且只能是一对一映射ASCII(American Standard Code for Information Interchange)…...
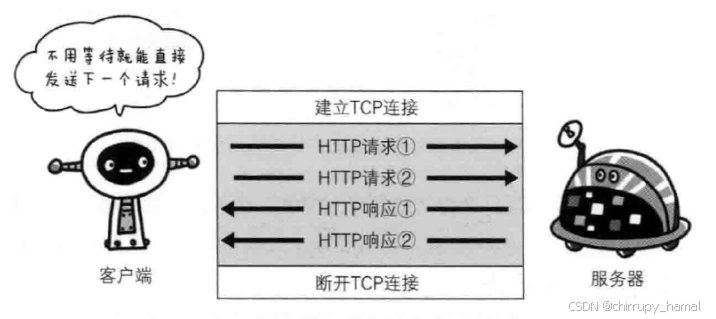
HTTP/1.1 队头堵塞问题
文章目录 一、队头堵塞1、非管线化2、管线化 二、如何解决? 一、队头堵塞 1、非管线化 如图,http 请求必须等到上一个请求响应后才能发送,后面的以此类推,由此可以看出,在一个 tcp 通道中,如果某个 http 请…...
【Quest开发】在虚拟世界设置具有遮挡关系的透视窗口
软件:Unity 2022.3.51f1c1、vscode、Meta XR All in One SDK V72 硬件:Meta Quest3 仅针对urp管线 参考了YY老师这篇,可以先看他的再看这个可能更好理解一些:Unity Meta Quest MR 开发(七):使…...

Qt界面卡住变慢的解决方法
本质原因: 当Qt界面出现卡顿或无响应时,通常是因为主线程(GUI线程)被耗时操作阻塞。 完全忘了。。。 Qt Creater解决方法 1. 定位耗时操作 目标:找到阻塞主线程的代码段。 方法: 使用QElapsedTimer测量代码执行时间…...
常用 Git 命令详解
Git 是一个强大的版本控制工具,广泛用于软件开发和团队协作中。掌握 Git 命令可以帮助开发者更高效地管理代码版本和项目进度。本文将介绍一些常用的 Git 命令,并提供示例以帮助你更好地理解和应用这些命令。 目录 常用命令 git clonegit stashgit pul…...

java导出word含表格并且带图片
背景 我们需要通过 Java 动态导出 Word 文档,基于预定义的 模板文件(如 .docx 格式)。模板中包含 表格,程序需要完成以下操作: 替换模板中的文本(如占位符 ${设备类型} 等)。 替换模板中的图…...

基于CNN卷积神经网络和GEI步态能量提取的视频人物步态识别算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1 GEI步态能量提取 4.2 CNN卷积神经网络原理 5.算法完整程序工程 1.算法运行效果图预览 (完整程序运行后无水印) 2.算法运行软件版本 matlab2024b/matlab2022a 3.部分核心程序 &…...

【Pandas】pandas DataFrame isin
Pandas2.2 DataFrame Indexing, iteration 方法描述DataFrame.head([n])用于返回 DataFrame 的前几行DataFrame.at快速访问和修改 DataFrame 中单个值的方法DataFrame.iat快速访问和修改 DataFrame 中单个值的方法DataFrame.loc用于基于标签(行标签和列标签&#…...

算法思想之链表
欢迎拜访:雾里看山-CSDN博客 本篇主题:算法思想之链表 发布时间:2025.4.18 隶属专栏:算法 目录 算法介绍常用技巧 例题两数相加题目链接题目描述算法思路代码实现 两两交换链表中的节点题目链接题目描述算法思路代码实现 重排链表…...

Oceanbase单机版上手示例
本月初Oceanbase单机版发布,作为一个以分布式起家的数据库,原来一个集群动辄小十台机器,多着十几台几十台甚至更多,Oceanbase单机版的发布确实大大降低了硬件部署的门槛。 1.下载安装介质 https://www.oceanbase.com/softwarece…...
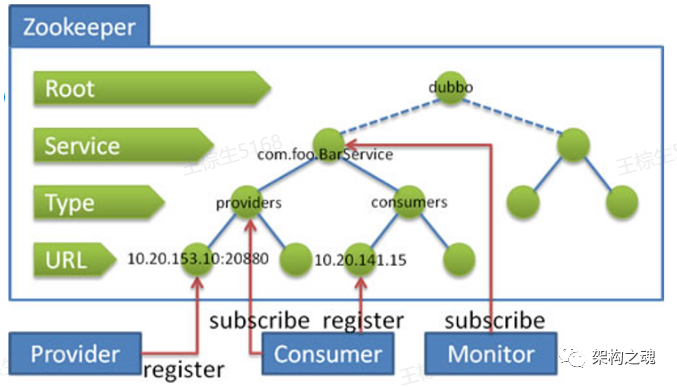
架构师面试(三十二):注册中心数据结构
问题 提到【注册中心】,我们对它的基本功能,肯定可以顺手拈来,比如:【服务注册】【服务发现】【健康检查】【变更通知】等。 透过这些基本功能,一个普适的注册中心的数据结构应该如何设计呢? 可以结合着…...
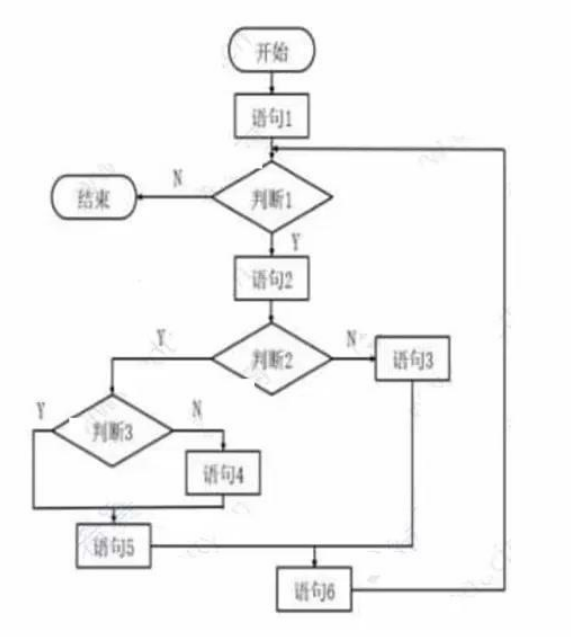
《软件设计师》复习笔记(11.5)——测试原则、阶段、测试用例设计、调试
目录 1. 测试基础概念 2. 测试方法分类 3. 测试阶段 真题示例: 题目1 题目2 题目3 4. 测试策略 5. 测试用例设计 真题示例: 6. 调试与度量 真题示例: 1. 测试基础概念 定义:系统测试是为发现错误而执行程序的过程&…...

闲来无事,用HTML+CSS+JS打造一个84键机械键盘模拟器
今天闲来无聊,突发奇想要用前端技术模拟一个机械键盘。说干就干,花了点时间搞出来了这么一个有模有样的84键机械键盘模拟器。来看看效果吧! 升级版的模拟器 屏幕录制 2025-04-18 155308 是不是挺像那么回事的?哈哈! 它…...

23种设计模式全面解析
设计模式是解决软件设计中常见问题的经典方案。根据《设计模式:可复用面向对象软件的基础》(GoF),23种设计模式分为以下三类: 一、创建型模式(5种) 目标:解耦对象的创建过程&#x…...

Java学习手册:常见并发问题及解决方案
在Java并发编程中,开发者常常会遇到各种并发问题,这些问题可能导致程序行为不可预测、性能下降甚至程序崩溃。以下是一些常见的并发问题及其解决方案: 1.竞态条件(Race Condition) 竞态条件是指多个线程同时访问共享…...
【免费下载】中国各省市地图PPT,可编辑改颜色
很多同学做PPT时,涉及到中国地图或省份展示,自己绘制和调色难度大,下面为大家准备了中国地图的可编辑模板,可以根据PPT整体色或想突出的省份,直接调整颜色。 需要这份数据,请在文末查看下载方法。 一、数…...

Linux 系统编程 day4 进程管道
进程间通信(IPC) Linux环境下,进程地址空间相互独立,任何一个进程的全局变量在另一个进程中都看不到,所以进程和进程之间不能互相访问,要交换数据必须通过内核,在内核中开辟一块缓冲区…...

【Reading Notes】(8.2)Favorite Articles from 2025 February
【February】 高阶智驾别被短期市占率迷住眼!(2025年02月01日) 2024年,高阶智驾发展迅猛,粗略计算中国市场(特斯拉之外)的城市NOA车型的年度搭载量超过了100万台。但相比于中国乘用车市场2000万…...
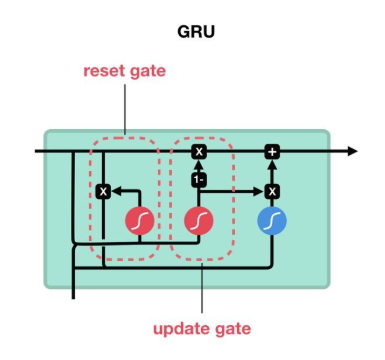
探索大语言模型(LLM):循环神经网络的深度解析与实战(RNN、LSTM 与 GRU)
一、循环神经网络(RNN) 1.1 基本原理 循环神经网络之所以得名,是因为它在处理序列数据时,隐藏层的节点之间存在循环连接。这意味着网络能够记住之前时间步的信息,并利用这些信息来处理当前的输入。 想象一下…...
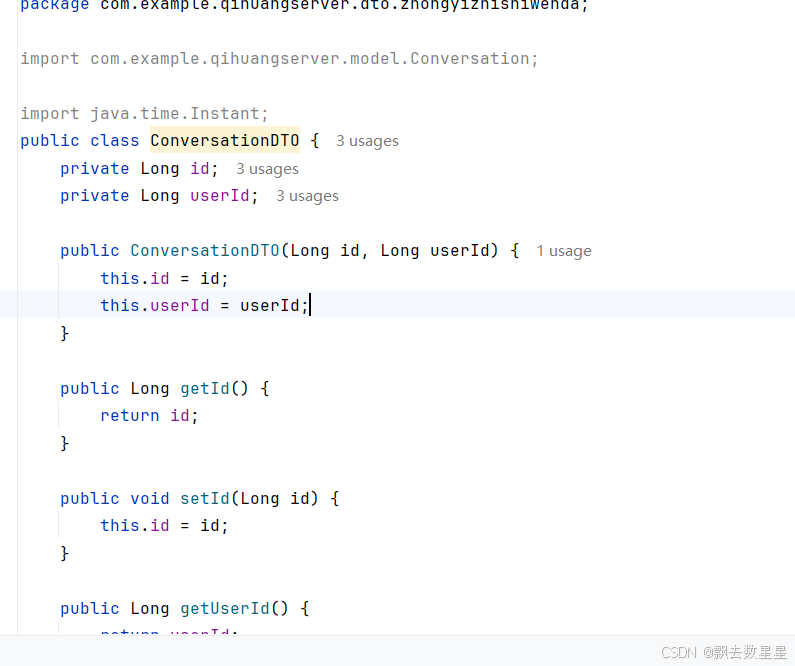
山东大学软件学院创新项目实训开发日志(15)之中医知识问答历史对话查看bug处理后端信息响应成功但前端未获取到
在开发中医知识问答历史对话查看功能的时候,出现了前后端信息获取异同的问题,在经过非常非常非常艰难的查询之后终于解决了这一问题,而这一问题的罪魁祸首就是后端没有setter和getter方法!!!!&a…...

poj1067 取石子游戏 威佐夫博弈
题目 有两堆石子,数量任意,可以不同。游戏开始由两个人轮流取石子。游戏规定,每次有两种不同的取法, 一是可以在任意的一堆中取走任意多的石子;二是可以在两堆中同时取走相同数量的石子。最后把石子全部取完者为胜者…...
优先级队列的实模拟实现
优先级队列底层默认用的是vector来存储数据,实现了类似我们数据结构中学习过的堆的队列,他的插入和删除都是优先级高先插入和删除。下面我们来模拟实现它们常见的接口来熟悉优先级队列。 仿函数 在介绍优先级队列之前,我们先熟悉一个概念&a…...

中国高校光芯片技术进展:前沿突破与产业化路径分析——基于材料、集成与系统协同创新的视角
引言:光电子技术的范式变革 随着摩尔定律逼近物理极限,光芯片技术成为突破电子芯片性能瓶颈的核心路径。光芯片以光子为载体,在传输速率(>100 Gbps)、能耗效率(<1 pJ/bit)及抗电磁干扰等…...
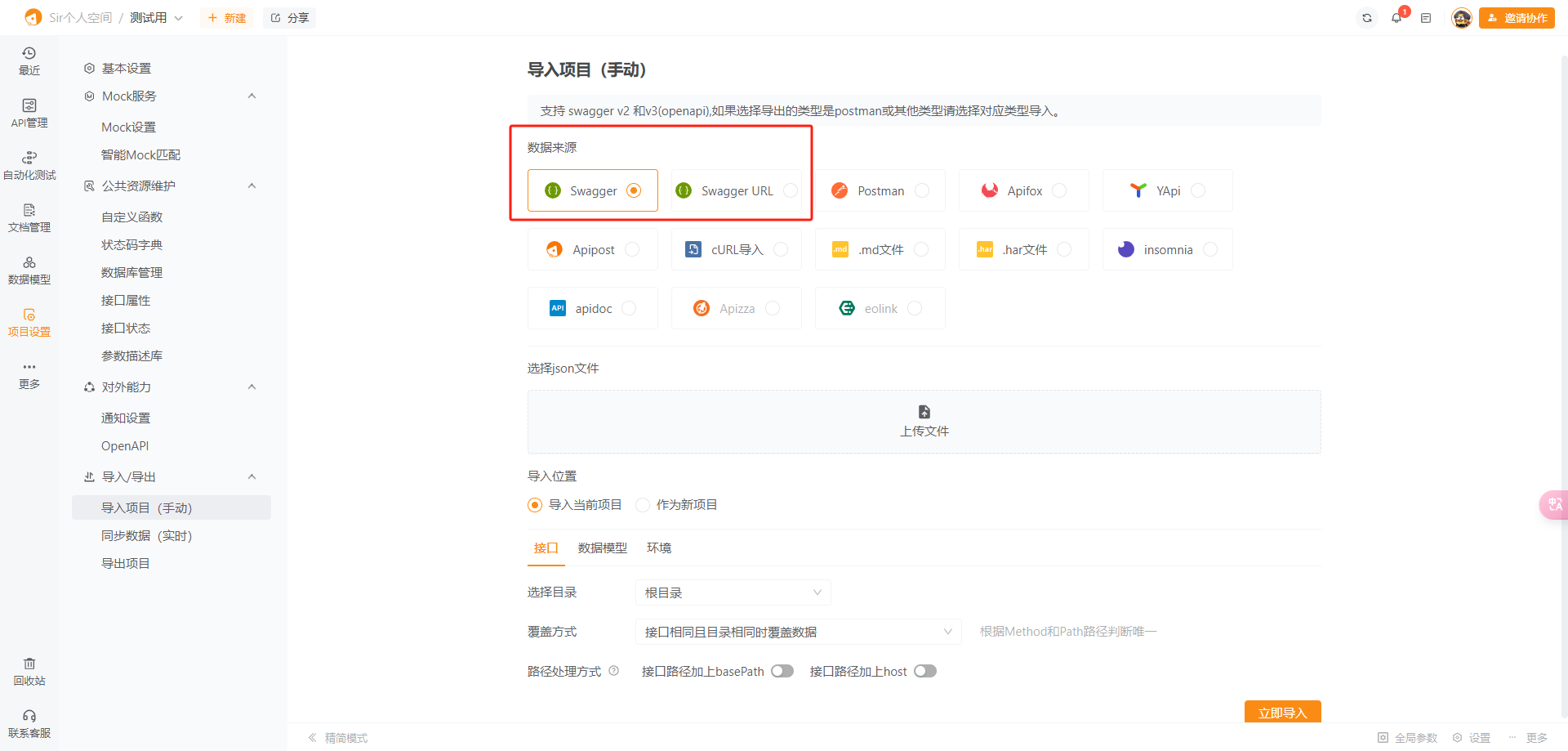
swagger 导入到apipost中
打开swagger json链接 保存到本地转为json格式文件 上传文件就行...

网安加·百家讲坛 | 刘志诚:AI安全风险与未来展望
作者简介:刘志诚,乐信集团信息安全中心总监、OWASP广东区域负责人、网安加社区特聘专家。专注于企业数字化过程中网络空间安全风险治理,对大数据、人工智能、区块链等新技术在金融风险治理领域的应用,以及新技术带来的技术风险治理…...

熵权法+TOPSIS+灰色关联度综合算法(Matlab实现)
熵权法TOPSIS灰色关联度综合算法(Matlab实现) 代码获取私信回复:熵权法TOPSIS灰色关联度综合算法(Matlab实现) 摘要: 熵权法TOPSIS灰色关联度综合算法(Matlab实现)代码实现了一种…...

React 中如何获取 DOM:用 useRef 操作非受控组件
📌 场景说明 在写 React 的时候,通常我们是通过“受控组件”来管理表单元素,比如用 useState 控制 <input> 的值。 但有些时候,控制的需求只是临时性的,或者完全不需要重新渲染组件,这时候直接访问…...

YAFFS2 的页缓存机制原理及配置优化方法详解
YAFFS2(Yet Another Flash File System 2)通过其独特的 页缓存机制 和 日志结构设计 优化了 NAND 闪存的读写性能与寿命。以下是其页缓存实现的核心机制及关键流程: 一、YAFFS2 页缓存架构 1. 缓存结构 YAFFS2 的页缓存基于 动态缓存池 设计…...

神经接口安全攻防:从技术漏洞到伦理挑战
随着脑机接口(BCI)技术的快速发展,神经接口设备已从实验室走向消费市场。然而,2025年曝光的某品牌脑机接口设备漏洞(CVE-2025-3278)引发了行业对神经数据安全的深度反思。本文围绕神经接口安全的核心矛盾&a…...