大数据面试问答-Spark
1. Spark
1.1 Spark定位
"Apache Spark是一个基于内存的分布式计算框架,旨在解决Hadoop MapReduce在迭代计算和实时处理上的性能瓶颈。
1.2 核心架构
Spark架构中有三个关键角色:
Driver:解析代码生成DAG,协调任务调度(TaskScheduler)。
Executor:在Worker节点执行具体Task,通过BlockManager管理数据缓存。
Cluster Manager:支持Standalone/YARN/Kubernetes资源调度。
1.3 基础概念
1.3.1 RDD
RDD本质上是一个逻辑抽象,而非物理存储的实际数据。
RDD 不直接存储数据本身,而是通过四个核心元数据描述如何生成数据:
1.数据来源(数据块指针)
若从HDFS读取:记录文件路径、分块偏移量(如hdfs://data.log, [0-128MB])。
若从父RDD转换而来:记录依赖关系(如父RDD ID + map函数)。
2.依赖关系(Dependencies)
记录父RDD与当前RDD的依赖类型(宽/窄依赖),用于容错恢复和Stage划分。
示例:RDD2 = RDD1.filter(...).map(...) 的依赖链为 Narrow -> Narrow。
3.计算函数(Compute Function)
定义从父RDD或外部数据生成当前RDD分区的逻辑(如map(func)中的func)。
惰性执行:函数不会立即执行,直到遇到Action操作触发计算。
4.分区策略(Partitioner)
决定数据在计算过程中的分布方式:
HashPartitioner:按Key哈希值分配(用于groupByKey)。
RangePartitioner:按Key范围分配(用于排序操作)。
1.3.1.1 RDD中的分区
分区的本质
分区(Partition) 是 RDD 的最小计算单元,表示数据在逻辑上的分块。
虽然 RDD 不存储实际数据,但它通过分区描述数据的分布方式(类似“目录”记录“文件”的位置)。
分区的来源
初始 RDD:从外部数据源(如 HDFS、本地文件)加载时,分区规则由数据源决定。
例如:HDFS 文件按 128MB 分块,每个块对应一个 RDD 分区。
转换后的 RDD:由父 RDD 的分区规则和转换算子类型决定。
窄依赖(如 map):子 RDD 分区与父 RDD 一一对应。
宽依赖(如 groupByKey):子 RDD 分区由 Shuffle 重新分配。
| 维度 | 分区的核心作用 |
|---|---|
| 并行计算 | 每个分区由一个 Task 处理,分区数决定并行度(如 100 个分区 → 100 个 Task) |
| 数据本地性 | 调度器优先将 Task 分配到数据所在节点(避免跨节点传输) |
| 容错 | 分区是容错的最小单元,丢失时只需重新计算该分区 |
1.3.2 宽窄依赖
窄依赖(Narrow Dependency)
父RDD的每个分区最多被一个子RDD分区依赖。(一对一)
无需跨节点数据传输(数据局部性优化)。
容错成本低:若子分区数据丢失,只需重新计算对应的父分区。
示例操作:map、filter、union。
宽依赖(Wide Dependency / Shuffle Dependency)
父RDD的每个分区可能被多个子RDD分区依赖。(多对多)
必须跨节点传输数据(Shuffle过程)。
容错成本高:若子分区数据丢失,需重新计算所有相关父分区。
示例操作:groupByKey、reduceByKey、join(非相同分区情况)。
| 维度 | 窄依赖 | 宽依赖 |
|---|---|---|
| Stage划分 | 允许合并到同一Stage(流水线执行) | 强制划分Stage边界(需等待Shuffle完成) |
| 数据移动 | 无Shuffle,本地计算优先 | 需跨节点Shuffle,网络IO开销大 |
| Stage划分 | 可合并操作(如map+filter合并执行) | 需手动调优(如调整分区数或Partitioner) |
1.3.3 算子
算子的定义
在 Spark 中,算子(Operator) 是指对 RDD 或 DataFrame 进行操作的函数。所有数据处理逻辑均通过算子组合实现,类似于烹饪中的“步骤”(如切菜、翻炒、调味)。
算子分为两类:
转换算子(Transformations):定义数据处理逻辑,生成新的 RDD(惰性执行,不立即计算)。比如map、filter
# 转换算子链(无实际计算)
rdd = sc.textFile("data.txt") \.filter(lambda line: "error" in line) \ # 过滤错误日志.map(lambda line: line.split(",")[0]) # 提取第一列
宽窄依赖与算子对照表,只涉及转换算子,行动算子不涉及宽窄依赖
| 依赖类型 | 转换算子 | 含义及示例 | 触发Shuffle? |
|---|---|---|---|
| 窄依赖 | map(func) | 对每个元素应用函数,一对一转换。例:rdd.map(x => x*2) | 否 |
| 窄依赖 | filter(func) | 过滤满足条件的元素。例:rdd.filter(x => x > 10) | 否 |
| 窄依赖 | flatMap(func) | 一对多转换(输出为多个元素)。例:rdd.flatMap(x => x.split(" ")) | 否 |
| 窄依赖 | mapPartitions(func) | 对每个分区迭代处理(更高效)。例:rdd.mapPartitions(it => it.map(_*2)) | 否 |
| 窄依赖 | union(otherRDD) | 合并两个RDD,保留各自分区。例:rdd1.union(rdd2) | 否 |
| 窄依赖 | glom() | 将每个分区的元素合并为一个数组。例:rdd.glom() → 得到分区数组的RDD | 否 |
| 窄依赖 | mapValues(func) | 仅对键值对的Value进行转换(保留原Key的分区)。例:pairRdd.mapValues(_+1) | 否 |
| 宽依赖 | groupByKey() | 按键分组,相同Key的值合并为迭代器。例:pairRdd.groupByKey() | 是 |
| 宽依赖 | reduceByKey(func) | 按键聚合(本地预聚合减少Shuffle量)。例:pairRdd.reduceByKey(+) | 是 |
| 宽依赖 | join(otherRDD) | 按键关联两个RDD(相同Key的值连接)。例:rdd1.join(rdd2) | 是 |
| 宽依赖 | distinct() | 去重(内部用reduceByKey实现)。例:rdd.distinct() | 是 |
| 宽依赖 | repartition(num) | 显式调整分区数(触发全量Shuffle)。例:rdd.repartition(100) | 是 |
| 宽依赖 | sortByKey() | 按键排序(需全局Shuffle)。例:pairRdd.sortByKey() | 是 |
| 宽依赖 | cogroup(otherRDD) | 对多个RDD按Key联合分组(类似SQL全外连接)。例:rdd1.cogroup(rdd2) | 是 |
| 宽依赖 | intersection(otherRDD) | 求两个RDD的交集。例:rdd1.intersection(rdd2) | 是 |
| 宽依赖 | subtractByKey(otherRDD) | 按Key差集(移除与另一RDD匹配的Key)。例:rdd1.subtractByKey(rdd2) | 是 |
行动算子(Actions):触发实际计算并返回结果或持久化数据(立即执行)。比如collect、count
# 触发计算,返回结果
result = rdd.count() # 统计过滤后的行数
print(result)
| Action 算子 | 功能描述 |
|---|---|
| collect() | 将所有数据拉取到 Driver 内存 |
| count() | 统计 RDD 元素总数 |
| take(n) | 返回前 n 个元素 |
| saveAsTextFile(path) | 将结果写入 HDFS/Local 文件系统 |
| foreach(func) | 对每个元素应用函数(无返回值) |
| reduce(func) | 全局聚合所有元素(需可交换、可结合的聚合函数) |
| first() | 返回第一个元素 |
| countByKey() | 统计每个 Key 的出现次数 |
Action 触发计算的全流程
1.3.3.1 reduceByKey 与 groupByKey
| 算子 | 功能描述 | 输出示例(输入:[(“a”,1), (“a”,2), (“b”,3)]) |
|---|---|---|
| groupByKey | 将相同 Key 的所有 Value 合并为一个 迭代器(Iterable) | [(“a”, [1, 2]), (“b”, [3])] |
| reduceByKey | 对相同 Key 的 Value 按指定函数进行 聚合(如求和、求最大值),直接输出最终结果 | [(“a”, 3), (“b”, 3)](假设聚合函数为 lambda x,y: x + y) |
groupByKey 的执行流程
Shuffle Write:将数据按 Key 分发到不同分区,所有 Value 直接传输。
Shuffle Read:每个节点拉取对应分区的数据,合并为迭代器。
输出:生成 (Key, Iterable[Value]) 形式的键值对。
reduceByKey 的执行流程
本地预聚合(Map-side Combine):
在 Map 任务所在节点,先对相同 Key 的 Value 进行局部聚合(如求和)。
Shuffle Write:仅传输 预聚合后的结果。
Shuffle Read:对预聚合结果进行全局聚合(如二次求和)。
输出:生成 (Key, AggregatedValue) 形式的键值对。
| 算子 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| reduceByKey | Shuffle 数据量小,内存占用低 | 仅支持聚合操作 | 求和、计数、极值计算 |
| groupByKey | 保留所有 Value 的完整信息 | Shuffle 开销大,易引发 OOM | 需全量 Value 的非聚合操作 |
groupByKey 的 SQL 对应形式
Spark RDD 代码:
rdd.groupByKey().mapValues(list) # 输出 (Key, [Value1, Value2, ...])
Spark SQL 代码:
SELECT key, COLLECT_LIST(value) AS values
FROM table
GROUP BY key;
reduceByKey 的 SQL 对应形式
Spark RDD 代码:
rdd.reduceByKey(lambda a, b: a + b) # 输出 (Key, Sum_Value)
Spark SQL 代码:
SELECT key, SUM(value) AS total
FROM table
GROUP BY key;
1.3.4 DAGScheduler
定义:Spark 内部调度器,将逻辑 DAG 划分为物理执行的 Stage。
核心功能:
Stage 划分:以宽依赖(Shuffle)为边界切分 DAG。
任务调度:生成 TaskSet 提交给 TaskScheduler。
容错处理:重新提交失败的 Stage。
1.3.4.1 DAG(有向无环图)
定义:表示 RDD 转换操作的依赖关系图,无循环依赖。
作用:
优化执行顺序(如合并窄依赖操作)。
支持容错(通过血统重新计算丢失分区)。
DAG 的节点是 RDD,边是 RDD 之间的 依赖关系(窄依赖或宽依赖)。
DAG 的构建逻辑:
每个转换操作生成新的 RDD,并记录其父 RDD。
Action 触发时,Spark 根据 RDD 的血统(Lineage)构建 DAG。
rdd1 = sc.textFile("data.txt") # 初始 RDD
rdd2 = rdd1.map(lambda x: x.upper()) # 窄依赖
rdd3 = rdd2.filter(lambda x: "ERROR" in x) # 窄依赖
rdd4 = rdd3.groupByKey() # 宽依赖
rdd4.collect() # 触发 DAG 构建
对应的 DAG:
1.3.4.2 Stage
定义:DAG 的物理执行单元,分为 ShuffleMapStage(Shuffle 数据准备)和 ResultStage(最终计算)。
划分规则:
窄依赖操作合并为同一 Stage。
宽依赖触发 Stage 分割。
划分 Stage 的核心作用
优化执行效率:
窄依赖操作合并为流水线(Pipeline):同一 Stage 内的连续窄依赖操作(如 map→filter)合并为单个 Task 执行,避免中间数据落盘。
宽依赖强制划分 Stage:确保 Shuffle 前所有数据准备完成,明确任务执行边界。
容错管理:
Stage 是容错的最小单元,失败时只需重算该 Stage 及其后续 Stage。
Stage 划分规则:
以宽依赖为边界,将 DAG 切分为多个 Stage。
窄依赖操作合并到同一 Stage。
map 和 filter 是窄依赖,合并为 Stage 1。
groupByKey 是宽依赖,触发 Stage 2。
Shuffle 发生的环节
在 Spark 中,Shuffle 是连接不同 Stage 的桥梁,通常发生在以下操作中:
宽依赖操作:如 groupByKey、reduceByKey等需要跨分区重新分配数据的操作。
当触发 Shuffle 时,Spark 会将当前 Stage 的 Task 划分为 Shuffle Write(数据写出)和 Shuffle Read(数据读取)两个阶段,分属不同 Stage 的上下游 Task 3。
1.3.5 Driver 程序
Driver 是用户编写的应用主逻辑:
用户必须自行编写 Driver 程序(如 Python/Scala/Java 代码),在其中定义数据处理流程(创建 RDD/DataFrame,调用转换和行动操作)。
# 用户编写的 Driver 程序(必须存在)
from pyspark import SparkContext
sc = SparkContext("local", "WordCount")
rdd = sc.textFile("hdfs://input.txt")
result = rdd.flatMap(lambda line: line.split(" ")) \.countByValue() # Action 操作
print(result)
1.4 Spark计算流程
Spark与MapReduce对比
| 对比维度 | Spark | MapReduce | 优劣分析 |
|---|---|---|---|
| 执行模型 | 基于内存的DAG模型,多阶段流水线执行 | 严格的Map-Shuffle-Reduce两阶段模型 | Spark减少中间数据落盘,MR依赖磁盘保证稳定性 |
| 容错机制 | 基于RDD血缘关系(Lineage)重建丢失分区 | 通过Task重试和HDFS副本机制 | Spark重建成本低,MR依赖数据冗余保障可靠性 |
| 延迟性能 | 亚秒级到秒级(内存计算) | 分钟级(多轮磁盘IO) | Spark适合交互式查询/实时处理,MR仅适合离线批处理 |
| 适用场景 | 迭代计算(ML)、实时流处理、交互式分析 | 超大规模离线批处理(TB/PB级) | Spark覆盖场景更广,MR在单一超大Job场景仍有优势 |
2. SparkSQL
Spark SQL 是 Apache Spark 的模块之一,核心功能是 处理结构化数据,其设计目标是:统一 SQL 与代码:允许开发者混合使用 SQL 和 DataFrame API(Python/Scala/Java),打破 SQL 与编程语言的界限。
高性能查询:通过 Catalyst 优化器生成逻辑/物理执行计划,结合 Tungsten 引擎的二进制内存管理,提升执行效率。
多数据源支持:可对接 Hive、JSON、Parquet、JDBC 等数据源,甚至自定义数据源。
Spark Sql转换成程序执行的过程
3. Spark Streaming
3.1 核心定位
Spark Streaming 是 Spark 生态中用于实时流数据处理的模块,采用 微批处理(Micro-Batch) 模式,将流数据切分为小批次(如1秒~数分钟),以类似批处理的方式实现近实时(Near-Real-Time)计算。其核心优势是与 Spark 生态的无缝集成,复用批处理代码和资源调度能力。
3.2 离散化流DStream与结构化流Structured Streaming
数据抽象:DStream
离散化流(Discretized Stream, DStream):是 Spark Streaming 的基础抽象,表示一个连续的数据流,内部由一系列 RDD 组成,每个 RDD 对应一个时间窗口内的数据。
处理流程:
输入源:从 Kafka、Flume、Kinesis、TCP Socket 等读取数据。
批处理窗口:按用户定义的批次间隔(如5秒)将数据划分为微批次。
转换操作:对每个批次的 RDD 应用 map、reduce、join 等操作。
输出结果:将处理后的数据写入 HDFS、数据库或实时看板。
执行模型
Driver 节点:负责调度任务,生成 DStream 的 DAG 执行计划。
Worker 节点:执行具体的任务(Task),处理每个微批的 RDD。
容错机制:基于 RDD 的血缘(Lineage)机制,自动恢复丢失的分区数据。
Structured Streaming(结构化流)
核心抽象:将流数据视为无界的 DataFrame/Dataset,支持与静态数据相同的 SQL 操作。
处理模式:
微批处理(默认):类似传统 Spark Streaming。
连续处理(实验性):实现毫秒级延迟(Spark 2.3+)。
关键特性:
端到端 Exactly-Once 语义:通过与 Kafka 等源的协同,保证数据不丢不重。
事件时间与水位线:支持基于事件时间的窗口聚合,处理乱序数据。
状态管理:内置状态存储(StateStore),支持 mapGroupsWithState 等复杂状态操作。
相关文章:

大数据面试问答-Spark
1. Spark 1.1 Spark定位 "Apache Spark是一个基于内存的分布式计算框架,旨在解决Hadoop MapReduce在迭代计算和实时处理上的性能瓶颈。 1.2 核心架构 Spark架构中有三个关键角色: Driver:解析代码生成DAG,协调任务调度&a…...
线程池七个参数的含义
Java中的线程池里七个参数的以及其各自的含义 面试题:说一下线程池七个参数的含义? 所谓的线程池的 7 大参数是指,在使用 ThreadPoolExecutor 创建线程池时所设置的 7 个参数,如以下源码所示: public ThreadPoolExe…...
Windows suwellofd 阅读器-v5.0.25.0320
Windows suwellofd 阅读器 链接:https://pan.xunlei.com/s/VOO7tUkTHHTTjSe39CeVkUHbA1?pwd3ibx# OFD(Open Fixed-layout Document) , 数科OFD阅读器支持国标版式、可信阅读、是电子发票、电子证照,电子病历等电子文件理想阅读工具。 多格…...

三大等待和三大切换
三大等待 1、三大等待:等待的方式有三种:强制等待,隐性等待,显性等待。 1、强制等待:time.sleep(2),秒 优点:使用简单缺点:等待时间把握不准,容易造成时间浪费或者等待时…...
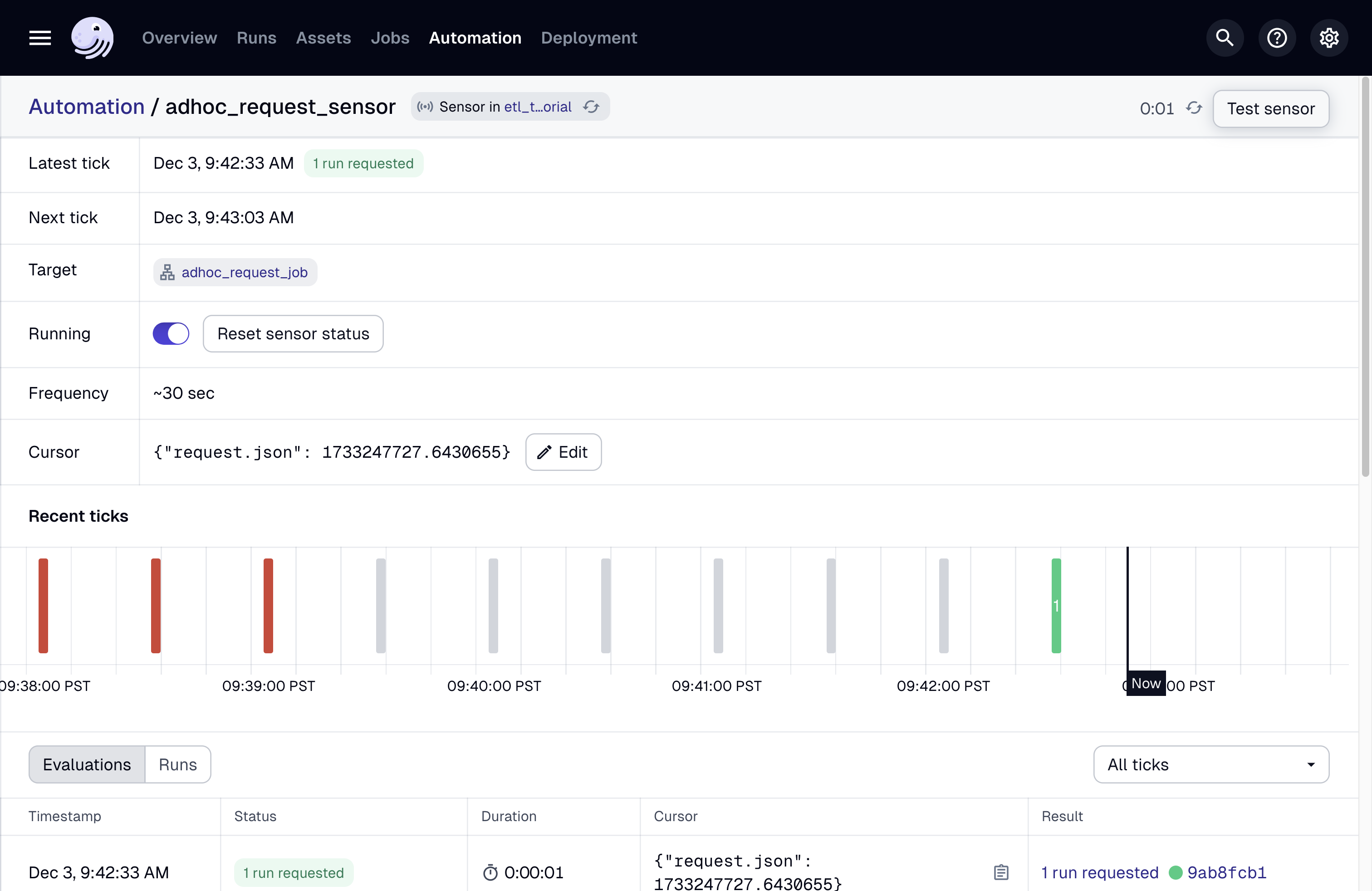
告别定时任务!用Dagster监听器实现秒级数据响应自动化
在数据管道开发中,我们经常面临需要根据外部事件触发计算任务的场景。传统基于时间的调度方式存在资源浪费和时效性不足的问题。本文将通过Dagster的**传感器(Sensor)**功能,演示如何构建事件驱动的数据处理流程。 场景模拟&…...

一文读懂WPF系列之MVVM
WPF MVVM 什么是MVVMWPF为何使用MVVM机制WPFMVVM 的实现手段 INotifyPropertyChanged数据绑定的源端通知原理 PropertyChanged事件双向绑定的完整条件常见疑惑问题 什么是MVVM 翻译全称就是 model-view-viewmodel 3部分内容 以wpf的概念角度来解释就是 数据库数据源模型…...
【Unity】打包TextMeshPro的字体
前言 在Unity中,TextMeshPro与常规 Text 组件相比提供了更高级的文本呈现功能,TextMesh Pro 可以处理各种语言,包括中文。我们可以轻松地在 Unity 项目中使用中文,而不必担心字体和布局问题。TextMeshPro需要的字体资源就需要我们…...
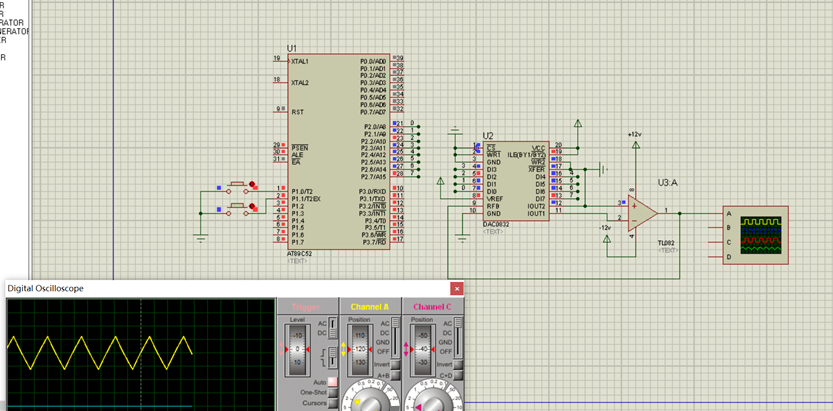
51单片机实验五:A/D和D/A转换
一、实验环境与实验器材 环境:Keli,STC-ISP烧写软件,Proteus. 器材:TX-1C单片机(STC89C52RC)、电脑。 二、 实验内容及实验步骤 1.A/D转换 概念:模数转换是将连续的模拟信号转换为离散的数字信…...
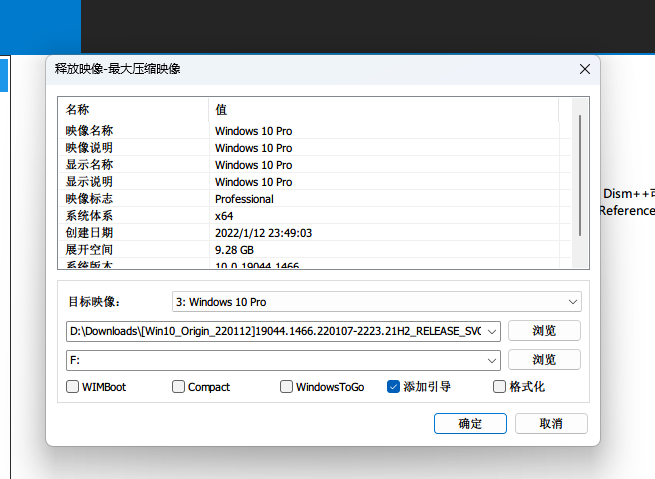
使用VHD虚拟磁盘安装双系统,避免磁盘分区
前言 很多时候,我们对现在的操作系统不满意,就想要自己安装一个双系统 但是安装双系统又涉及到硬盘分区,非常复杂,容易造成数据问题 虚拟机的话有经常用的不爽,这里其实有一个介于虚拟机和双系统之间的解决方法,就是使用虚拟硬盘文件安装系统. 相当于系统在机上…...
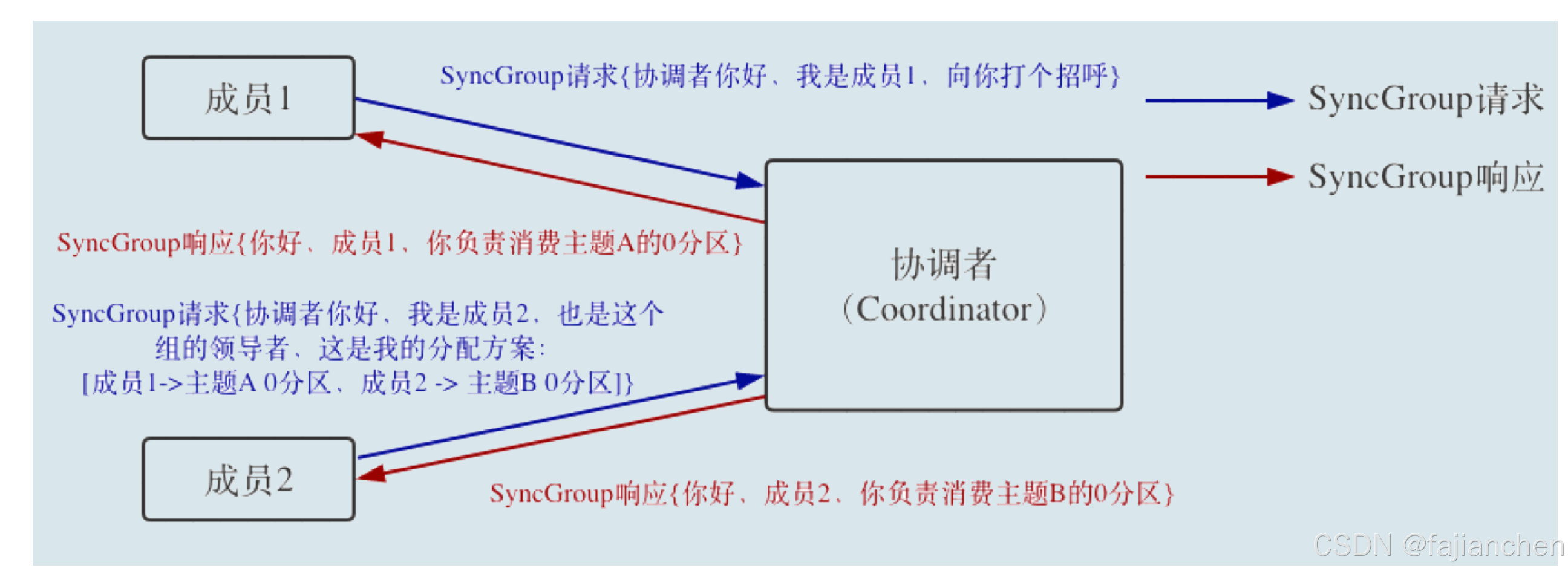
Kafka消费者端重平衡流程
重平衡的完整流程需要消费者 端和协调者组件共同参与才能完成。我们先从消费者的视角来审视一下重平衡的流程。在消费者端,重平衡分为两个步骤:分别是加入组和等待领导者消费者(Leader Consumer)分配方案。这两个步骤分别对应两类…...

Django之modelform使用
Django新增修改数据功能优化 目录 1.新增数据功能优化 2.修改数据功能优化 在我们做数据优化处理之前, 我们先回顾下传统的写法, 是如何实现增加修改的。 我们需要在templates里面新建前端的页面, 需要有新增还要删除, 比如说员工数据的新增, 那需要有很多个输入框, 那html…...

云轴科技ZStack入选中国人工智能产业发展联盟《大模型应用交付供应商名录》
2025年4月8日至9日,中国人工智能产业发展联盟(以下简称AIIA)第十四次全体会议暨人工智能赋能新型工业化深度行(南京站)在南京召开。工业和信息化部科技司副司长杜广达,中国信息通信研究院院长、中国人工智能…...

写论文时降AIGC和降重的一些注意事项
‘ 写一些研究成果,英文不是很好,用有道翻译过来句子很简单,句型很单一。那么你会考虑用ai吗? 如果语句太正式,高级,会被误判成aigc ,慎重选择ai润色。 有的话就算没有用ai生成,但…...
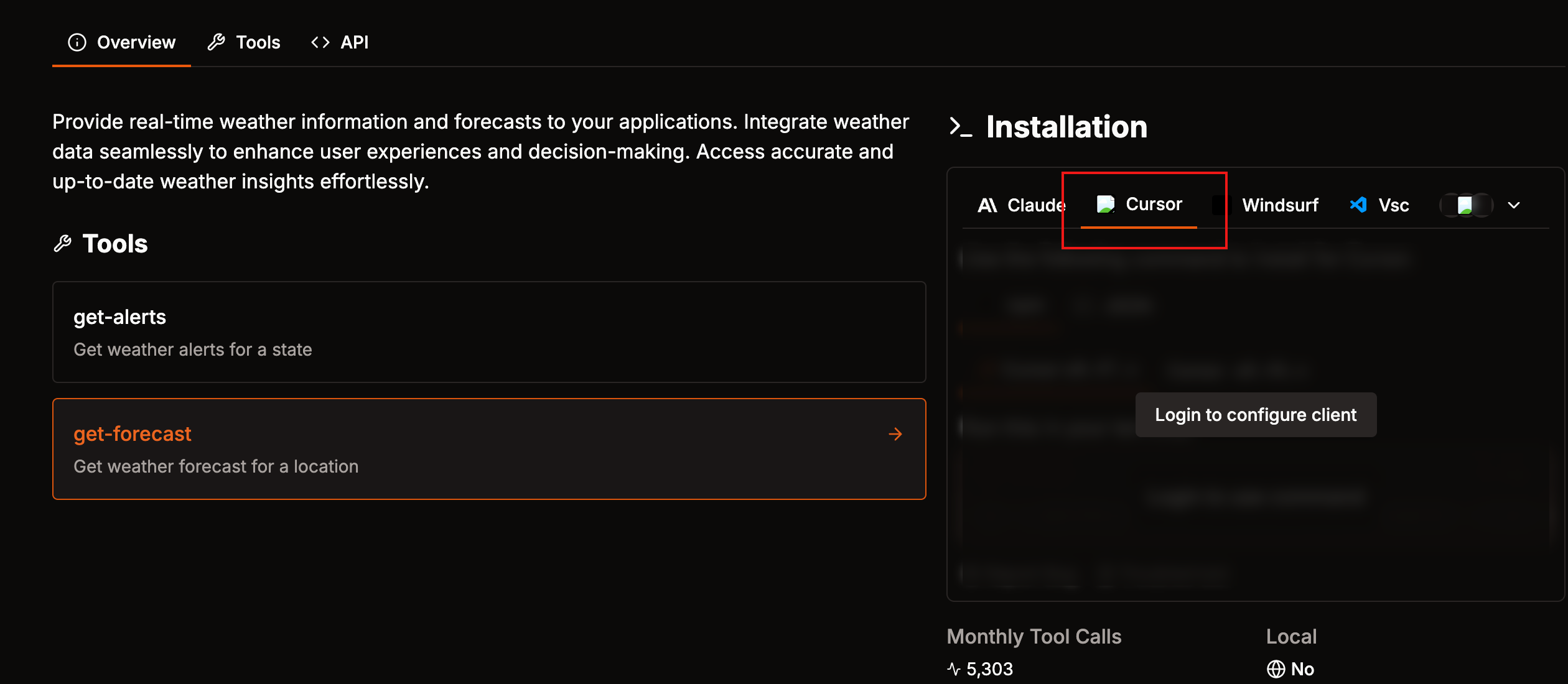
AI 编程工具—如何在 Cursor 中集成使用 MCP工具
AI 编程工具—如何在 Cursor 中集成使用 MCP工具 这里我们给出了常用的MCP 聚合工具,也就是我们可以在这些网站找MCP服务 这是一个MCP Server共享平台,用户可以在上面发布和下载MCP Server配置。在这里可以选择你需要的MCP 服务。 如果你不知道你的mcp 对应的server 名称也不…...
(蓝桥杯常考点)—动态规划(C/C++))
基础算法篇(5)(蓝桥杯常考点)—动态规划(C/C++)
文章目录 动态规划前言线性dp路径类dp经典线性dp背包问题分类01背包问题完全背包问题多重背包分组背包问题混合背包问题多维费用的背包问题区间dp 动态规划 前言 在竞赛中,如果遇到动态规划的题目,只要不是经典题型,那么大概率就是以压轴题的…...

MLLMS_KNOW尝鲜版
背景(个人流水账,可毫不犹豫跳过) 最近项目中有涉及到小物体检测的内容,昨天晚上讨论的时候有提出是否可以将关注区域放大的idea,不过后来没有就着这个东西深入,结果好巧不巧地,今天关注到这篇…...
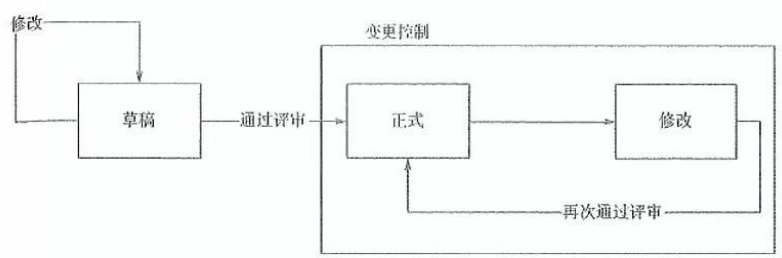
《软件设计师》复习笔记(12.2)——成本管理、配置管理
目录 一、项目成本管理 1. 定义 2. 主要过程 3. 成本类型 4. 其他概念 真题示例: 二、软件配置管理 1. 定义 2. 主要活动 3. 配置项 4. 基线(Baseline) 5. 配置库类型 真题示例: 一、项目成本管理 1. 定义 在批准…...

《AI赋能职场:大模型高效应用课》第8课 AI辅助职场沟通与协作
【本课目标】 掌握AI辅助邮件、沟通话术的优化技巧。学习利用AI快速生成高效的会议纪要。通过实操演练,提升职场沟通效率与协作能力。 【准备工具】 DeepSeek大模型(deepseek.com)百度文心一言(yiyan.baidu.com) 一…...
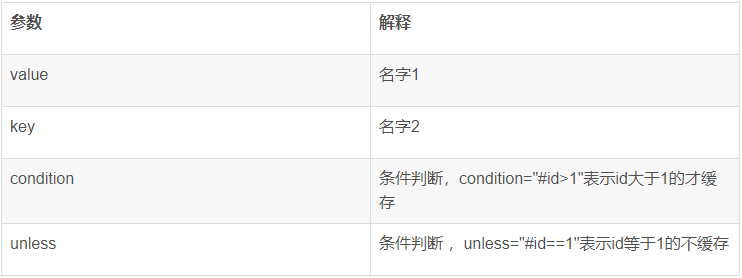
Spring 中的 @Cacheable 缓存注解
1 什么是缓存 第一个问题,首先要搞明白什么是缓存,缓存的意义是什么。 对于普通业务,如果要查询一个数据,一般直接select数据库进行查找。但是在高流量的情况下,直接查找数据库就会成为性能的瓶颈。因为数据库查找的…...
settimeout和setinterval区别
1. setTimeout:单次延迟执行 语法: const timeoutId setTimeout(callback, delay, arg1, arg2, ...); 核心功能:在指定的 delay(毫秒)后,执行一次 callback 函数。 参数: callback&#x…...
睫毛和眼睛的渲染是正常的,而在 Play 模式下出现模糊)
UE5编辑器静止状态下(非 Play 模式)睫毛和眼睛的渲染是正常的,而在 Play 模式下出现模糊
这通常指向以下几个 运行时(Runtime) 特有的原因: 抗锯齿 (Anti-Aliasing) 方法,特别是 Temporal Anti-Aliasing (TAA): 这是最可能的原因。 UE5 默认启用的 TAA 通过混合多帧信息来平滑边缘和减少闪烁,尤其是在运动中…...

怎样选择适合网站的服务器带宽?
合适的服务器带宽对于网站的需求起着至关重要的作用,服务器带宽会直接影响到网站的访问速度和用户体验,本文将介绍一下企业该怎样选择适合网站需求的服务器带宽! 不同类型的网站对于服务器带宽的需求也是不同的,小型博客网站的访问…...

Kaamel隐私与安全分析报告:Microsoft Recall功能评估与风险控制
本报告对Microsoft最新推出的Recall功能进行了全面隐私与安全分析。Recall是Windows 11 Copilot电脑的专属AI功能,允许用户以自然语言搜索曾在电脑上查看过的内容。该功能在初次发布时因严重隐私和安全问题而备受争议,后经微软全面重新设计。我们的分析表…...

linux 4.14内核jffs2文件系统不自动释放空间的bug
前段时间在做spi-nor flash项目的时候,使用jffs2文件系统,发现在4.14内核下存在无法释放空间的bug,后来进行了修复,修复后功能正常,现将修复patch公开,供后来者学习: diff --git a/fs/jffs2/ac…...

Thymeleaf简介
在Java中,模板引擎可以帮助生成文本输出。常见的模板引擎包括FreeMarker、Velocity和Thymeleaf等 Thymeleaf是一个适用于Web和独立环境的现代服务器端Java模板引擎。 Thymeleaf 和 JSP比较: Thymeleaf目前所作的工作和JSP有相似之处,Thyme…...

uniapp中uni-easyinput 使用@input 不改变绑定的值
只允许输入数字和字母 使用input 正则replace后赋值给A 遇到问题: 当输入任意连续的非法字符时, 输入框不变. 直到输入一个合法字符非法字符才成功被过滤. <uni-forms-item label"纳税人识别号" name"number"><uni-easyinput v-model"numb…...

前端零基础入门到上班:Day7——表单系统实战全解析
🧩前端零基础入门到上班:Day7——表单系统实战全解析 ✅ 目标:不仅掌握 HTML 表单标签,更深入理解其在实战中的作用、验证方式、美化技巧与 JS 联动,为后续接入 Vue、后端接口打下坚实基础。 🌟 一、HTML 表…...

【特殊场景应对1】视觉设计:信息密度与美学的博弈——让简历在HR视网膜上蹦迪的科学指南
写在最前 作为一个中古程序猿,我有很多自己想做的事情,比如埋头苦干手搓一个低代码数据库设计平台(目前只针对写java的朋友),比如很喜欢帮身边的朋友看看简历,讲讲面试技巧,毕竟工作这么多年,也做到过高管,有很多面人经历,意见还算有用,大家基本都能拿到想要的offe…...
o3和o4-mini的升级有哪些亮点?
ChatGPT是基于OpenAI GPT系列的高性能对话生成AI,经过多代迭代不断提升自然语言理解和生成能力。 在过去的一年中,OpenAI先后发布了GPT-4、GPT‑4.1及多种mini版本,为不同使用场景提供灵活选择。 随着用户需求向更高效、更精准的推理和视觉…...

影楼精修行业浅见-序言
影楼及商业摄影行业对高效、智能化的图像精修需求日益增长。传统修图流程耗时长、人工成本高,且修图师水平参差不齐影响最终成片质量。AI驱动的影像精修软件通过自动化、批量处理和智能算法,显著提升了修片效率和一致性,成为影楼数字化升级的…...