深度学习框架PyTorch——从入门到精通(3.3)YouTube系列——自动求导基础
这部分是 PyTorch介绍——YouTube系列的内容,每一节都对应一个youtube视频。(可能跟之前的有一定的重复)
- 我们需要Autograd做什么?
- 一个简单示例
- 训练中的自动求导
- 开启和关闭自动求导
- 自动求导与原地操作
- 自动求导分析器
- 高级主题:自动求导的更多细节与高级API
- 高级 API
本节YouTube视频地址:点击这里
PyTorch的自动求导(Autograd)特性是使PyTorch在构建机器学习项目时具备灵活性和高效性的部分原因。它能够在复杂的计算过程中快速且轻松地计算多个偏导数(也称为梯度)。这一操作对于基于反向传播的神经网络学习来说至关重要。
自动求导(Autograd)的强大之处在于,它能在运行时动态地跟踪你的计算过程。这意味着,如果你的模型中存在决策分支,或者存在直到运行时才能确定长度的循环,计算过程仍会被正确跟踪,并且你将获得正确的梯度来推动学习。再加上你的模型是用Python构建的这一事实,这使得它相比那些依赖对结构更固定的模型进行静态分析来计算梯度的框架,具有大得多的灵活性。
我们需要Autograd做什么?
机器学习模型是一个具有输入和输出的函数。在本次讨论中,我们将输入视为一个i维向量 x ⃗ \vec{x} x,其元素为 x i x_{i} xi。然后,我们可以将模型 M M M表示为输入的向量值函数: y ⃗ = M ⃗ ( x ⃗ ) \vec{y}=\vec{M}(\vec{x}) y=M(x)。(我们将 M M M的输出值视为向量,因为一般来说,一个模型可能有任意数量的输出。)
由于我们主要在训练的背景下讨论自动求导,我们关注的输出将是模型的损失。损失函数 L ( y ⃗ ) = L ( M ⃗ ( x ⃗ ) ) L(\vec{y}) = L(\vec{M}(\vec{x})) L(y)=L(M(x))是模型输出的单值标量函数。这个函数表示模型对于特定输入的预测与理想输出之间的差距。注意:在这之后,在上下文明确的情况下,我们通常会省略向量符号,例如用 y y y代替 y ⃗ \vec{y} y 。
在训练模型时,我们希望最小化损失。在理想的完美模型情况下,这意味着调整其学习权重,即该函数的可调整参数,使得对于所有输入损失都为零。在现实世界中,这意味着一个反复调整学习权重的迭代过程,直到我们看到对于各种输入都能得到一个可接受的损失值。
我们如何决定调整权重的幅度和方向呢?我们希望最小化损失,这意味着使其关于输入的一阶导数等于0: ∂ L ∂ x = 0 \frac{\partial L}{\partial x}=0 ∂x∂L=0。
然而,要记住损失并非直接由输入推导而来,而是模型输出的函数(而模型输出又是输入的直接函数), ∂ L ∂ x = ∂ L ( y ⃗ ) ∂ x \frac{\partial L}{\partial x}=\frac{\partial L(\vec{y})}{\partial x} ∂x∂L=∂x∂L(y)。根据微积分的链式法则,我们有 ∂ L ( y ⃗ ) ∂ x = ∂ L ∂ y ∂ y ∂ x = ∂ L ∂ y ∂ M ( x ) ∂ x \frac{\partial L(\vec{y})}{\partial x}=\frac{\partial L}{\partial y}\frac{\partial y}{\partial x}=\frac{\partial L}{\partial y}\frac{\partial M(x)}{\partial x} ∂x∂L(y)=∂y∂L∂x∂y=∂y∂L∂x∂M(x)。
∂ M ( x ) ∂ x \frac{\partial M(x)}{\partial x} ∂x∂M(x) 让情况变得复杂。如果我们再次使用链式法则展开表达式,模型输出关于其输入的偏导数将涉及模型中每个相乘的学习权重、每个激活函数以及每个其他数学变换的许多局部偏导数。每个这样的偏导数的完整表达式是通过计算图中以我们试图测量其梯度的变量为终点的每条可能路径的局部梯度乘积之和。
特别地,我们关注学习权重的梯度,因为它们能告诉我们,为了让损失函数更接近零,每个权重应该朝什么方向调整。
由于这类局部导数的数量(每个局部导数对应模型计算图中的一条不同路径)会随着神经网络深度呈指数级增长,计算这些导数的复杂度也会随之增加。这就是自动求导(Autograd)发挥作用的地方:它会跟踪每一次计算的历史。在PyTorch模型中,每个计算得到的张量都记录着其输入张量的历史以及用于创建它的函数。再加上作用于张量的PyTorch函数都有内置的导数计算实现,这极大地加快了学习所需的局部导数的计算速度。
一个简单示例
前面讲了很多理论知识,不过在实际中使用自动求导(Autograd)是什么样的呢?
让我们从一个简单的例子开始。首先,我们要进行一些导入操作,以便绘制结果图形:
# %matplotlib inlineimport torchimport matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import math
接下来,我们将创建一个输入张量,其元素是在区间 [ 0 , 2 π ] [0, 2\pi] [0,2π]上均匀分布的值,并指定requires_grad=True 。(与大多数创建张量的函数一样,torch.linspace() 接受可选的requires_grad 选项。)设置这个标记意味着在后续的每一次计算中,自动求导(autograd)会在该计算的输出张量中累积计算过程的历史记录。
a = torch.linspace(0., 2. * math.pi, steps=25, requires_grad=True)
print(a)
输出:
tensor([0.0000, 0.2618, 0.5236, 0.7854, 1.0472, 1.3090, 1.5708, 1.8326, 2.0944,2.3562, 2.6180, 2.8798, 3.1416, 3.4034, 3.6652, 3.9270, 4.1888, 4.4506,4.7124, 4.9742, 5.2360, 5.4978, 5.7596, 6.0214, 6.2832],requires_grad=True)
接下来,我们将进行一次计算,并根据输入绘制其输出:
b = torch.sin(a)
plt.plot(a.detach(), b.detach())
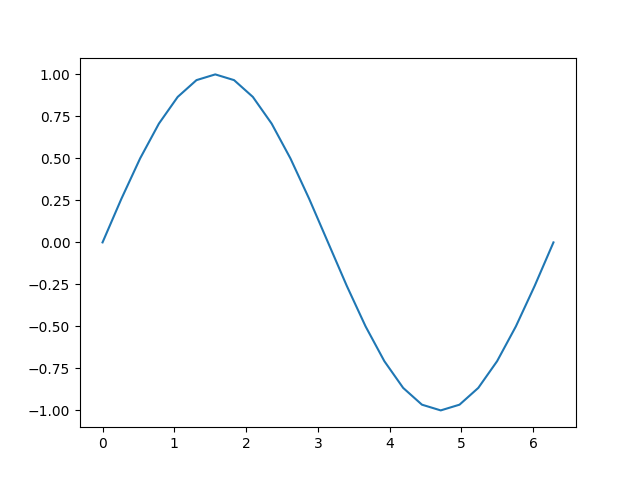
让我们更仔细地看看张量b。当我们打印它时,会看到一个表明它正在跟踪其计算历史的标识:
print(b)
# 输出
tensor([ 0.0000e+00, 2.5882e-01, 5.0000e-01, 7.0711e-01, 8.6603e-01,9.6593e-01, 1.0000e+00, 9.6593e-01, 8.6603e-01, 7.0711e-01,5.0000e-01, 2.5882e-01, -8.7423e-08, -2.5882e-01, -5.0000e-01,-7.0711e-01, -8.6603e-01, -9.6593e-01, -1.0000e+00, -9.6593e-01,-8.6603e-01, -7.0711e-01, -5.0000e-01, -2.5882e-01, 1.7485e-07],grad_fn=<SinBackward0>)
这个grad_fn 给我们一个提示,当我们执行反向传播步骤并计算梯度时,我们需要针对这个张量的所有输入计算 sin ( x ) \sin(x) sin(x) 的导数。
让我们进行更多的计算:
c = 2 * b
print(c)d = c + 1
print(d)
# 输出
tensor([ 0.0000e+00, 5.1764e-01, 1.0000e+00, 1.4142e+00, 1.7321e+00,1.9319e+00, 2.0000e+00, 1.9319e+00, 1.7321e+00, 1.4142e+00,1.0000e+00, 5.1764e-01, -1.7485e-07, -5.1764e-01, -1.0000e+00,-1.4142e+00, -1.7321e+00, -1.9319e+00, -2.0000e+00, -1.9319e+00,-1.7321e+00, -1.4142e+00, -1.0000e+00, -5.1764e-01, 3.4969e-07],grad_fn=<MulBackward0>)
tensor([ 1.0000e+00, 1.5176e+00, 2.0000e+00, 2.4142e+00, 2.7321e+00,2.9319e+00, 3.0000e+00, 2.9319e+00, 2.7321e+00, 2.4142e+00,2.0000e+00, 1.5176e+00, 1.0000e+00, 4.8236e-01, -3.5763e-07,-4.1421e-01, -7.3205e-01, -9.3185e-01, -1.0000e+00, -9.3185e-01,-7.3205e-01, -4.1421e-01, 4.7684e-07, 4.8236e-01, 1.0000e+00],grad_fn=<AddBackward0>)
最后,让我们计算一个单元素输出。当你在一个张量上不带参数调用.backward() 时,它要求调用的这个张量只包含一个元素,这和计算损失函数时的情况一样。
out = d.sum()
print(out)
# 输出
tensor(25., grad_fn=<SumBackward0>)
存储在我们张量中的每个grad_fn 都允许你通过其next_functions 属性一路追溯计算过程,直至其输入。下面我们可以看到,深入查看张量d 的这个属性,会向我们展示所有先前张量的梯度函数。请注意,a.grad_fn 显示为None ,这表明它是该函数的一个输入,自身没有计算历史记录。
print('d:')
print(d.grad_fn)
print(d.grad_fn.next_functions)
print(d.grad_fn.next_functions[0][0].next_functions)
print(d.grad_fn.next_functions[0][0].next_functions[0][0].next_functions)
print(d.grad_fn.next_functions[0][0].next_functions[0][0].next_functions[0][0].next_functions)
print('\nc:')
print(c.grad_fn)
print('\nb:')
print(b.grad_fn)
print('\na:')
print(a.grad_fn)
# 输出
d:
<AddBackward0 object at 0x7fb08c130e20>
((<MulBackward0 object at 0x7fb08c132230>, 0), (None, 0))
((<SinBackward0 object at 0x7fb08c132230>, 0), (None, 0))
((<AccumulateGrad object at 0x7fb08c130e20>, 0),)
()c:
<MulBackward0 object at 0x7fb08c132230>b:
<SinBackward0 object at 0x7fb08c132230>a:
None
有了这一整套机制后,我们要如何得到导数呢?你可以在输出张量上调用backward() 方法,然后检查输入张量的grad 属性来查看梯度:
out.backward()
print(a.grad)
plt.plot(a.detach(), a.grad.detach())
# 输出
tensor([ 2.0000e+00, 1.9319e+00, 1.7321e+00, 1.4142e+00, 1.0000e+00,5.1764e-01, -8.7423e-08, -5.1764e-01, -1.0000e+00, -1.4142e+00,-1.7321e+00, -1.9319e+00, -2.0000e+00, -1.9319e+00, -1.7321e+00,-1.4142e+00, -1.0000e+00, -5.1764e-01, 2.3850e-08, 5.1764e-01,1.0000e+00, 1.4142e+00, 1.7321e+00, 1.9319e+00, 2.0000e+00])[<matplotlib.lines.Line2D object at 0x7fb03055a050>]
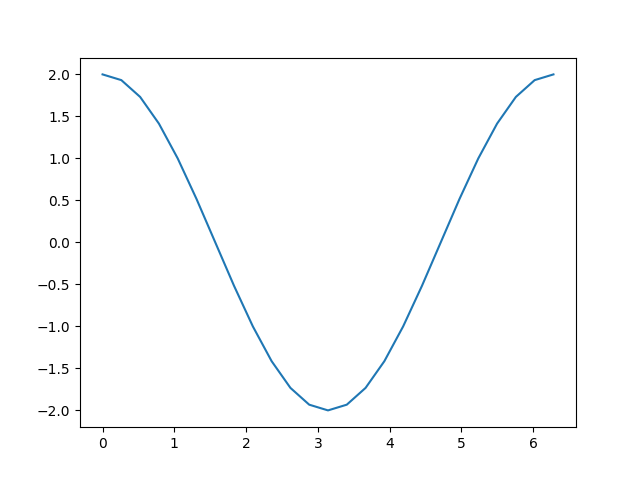
回想一下我们为得到当前结果所采取的计算步骤:
a = torch.linspace(0., 2. * math.pi, steps=25, requires_grad=True)
b = torch.sin(a)
c = 2 * b
d = c + 1
out = d.sum()
就像我们计算d 时那样,加上一个常数并不会改变导数。这样就剩下 c = 2 ∗ b = 2 ∗ sin ( a ) c = 2 * b = 2 * \sin(a) c=2∗b=2∗sin(a) ,其导数应该是 2 ∗ cos ( a ) 2 * \cos(a) 2∗cos(a) 。从上面的图中可以看到,结果正是如此。
需要注意的是,只有计算图中的叶节点会计算梯度。例如,如果你尝试print(c.grad) ,得到的结果会是None 。在这个简单例子中,只有输入是叶节点,所以只有它的梯度会被计算。
训练中的自动求导
我们已经简要了解了自动求导(Autograd)的工作原理,但它在实际用于其既定目的时是什么样的呢?让我们定义一个小型模型,并研究它在单个训练批次后是如何变化的。首先,定义一些常量、我们的模型以及一些输入和输出的替代值:
BATCH_SIZE = 16
DIM_IN = 1000
HIDDEN_SIZE = 100
DIM_OUT = 10class TinyModel(torch.nn.Module):def __init__(self):super(TinyModel, self).__init__()self.layer1 = torch.nn.Linear(DIM_IN, HIDDEN_SIZE)self.relu = torch.nn.ReLU()self.layer2 = torch.nn.Linear(HIDDEN_SIZE, DIM_OUT)def forward(self, x):x = self.layer1(x)x = self.relu(x)x = self.layer2(x)return xsome_input = torch.randn(BATCH_SIZE, DIM_IN, requires_grad=False)
ideal_output = torch.randn(BATCH_SIZE, DIM_OUT, requires_grad=False)model = TinyModel()
你可能会注意到,我们从未为模型的各层指定requires_grad = True。在torch.nn.Module的子类中,默认认为我们希望跟踪各层权重的梯度以用于学习。
如果查看模型的各层,我们可以检查权重的值,并确认此时尚未计算梯度:
print(model.layer2.weight[0][0:10]) # just a small slice
print(model.layer2.weight.grad)
# 输出
tensor([ 0.0920, 0.0916, 0.0121, 0.0083, -0.0055, 0.0367, 0.0221, -0.0276,-0.0086, 0.0157], grad_fn=<SliceBackward0>)
None
让我们看看在完成一个训练批次后情况会有怎样的变化。对于损失函数,我们将采用预测值与理想输出之间欧几里得距离的平方。并且,我们会使用一个基础的随机梯度下降优化器。
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)prediction = model(some_input)loss = (ideal_output - prediction).pow(2).sum()
print(loss)
# 输出
tensor(211.2634, grad_fn=<SumBackward0>)
现在,让我们调用loss.backward() 方法,看看会发生什么:
loss.backward()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])
# 输出
tensor([ 0.0920, 0.0916, 0.0121, 0.0083, -0.0055, 0.0367, 0.0221, -0.0276,-0.0086, 0.0157], grad_fn=<SliceBackward0>)
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,0.1732, -5.3835])
我们可以看到,针对每个学习权重的梯度都已经计算出来了,但权重本身并未改变,这是因为我们还没有运行优化器。优化器的作用就是根据计算得到的梯度来更新模型的权重。
optimizer.step()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])
# 输出
tensor([ 0.0791, 0.0886, 0.0098, 0.0064, -0.0106, 0.0293, 0.0186, -0.0300,-0.0088, 0.0211], grad_fn=<SliceBackward0>)
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,0.1732, -5.3835])
你应该会看到第二层(layer2)的权重已经发生了变化。
关于这个过程有一点很重要:在调用optimizer.step()之后,你需要调用optimizer.zero_grad(),否则每次你调用loss.backward()时,学习权重上的梯度就会累积起来。
print(model.layer2.weight.grad[0][0:10])for i in range(0, 5):prediction = model(some_input)loss = (ideal_output - prediction).pow(2).sum()loss.backward()print(model.layer2.weight.grad[0][0:10])optimizer.zero_grad(set_to_none=False)print(model.layer2.weight.grad[0][0:10])
# 输出
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,0.1732, -5.3835])
tensor([ 19.2095, -15.9459, 8.3306, 11.5096, 9.5471, 0.5391, -0.3370,8.6386, -2.5141, -30.1419])
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
在运行完上述代码块后,你应该会发现,在多次运行loss.backward() 之后,大多数梯度的量级会大得多。如果在运行下一个训练批次之前没有将梯度清零,就会导致梯度以这种方式激增,从而产生错误且不可预测的学习结果。
开启和关闭自动求导
在某些情况下,你需要对自动求导(Autograd)是否启用进行精细控制。根据不同的情况,有多种方法可以做到这一点。
最简单的方法是直接更改张量上的requires_grad 标志:
a = torch.ones(2, 3, requires_grad=True)
print(a)b1 = 2 * a
print(b1)a.requires_grad = False
b2 = 2 * a
print(b2)
# 输出
tensor([[1., 1., 1.],[1., 1., 1.]], requires_grad=True)
tensor([[2., 2., 2.],[2., 2., 2.]], grad_fn=<MulBackward0>)
tensor([[2., 2., 2.],[2., 2., 2.]])
在上面的代码单元中,我们看到b1 有一个grad_fn(即一个被追踪的计算历史记录),这正是我们所预期的,因为它是从一个开启了自动求导功能的张量a 推导而来的。当我们通过a.requires_grad = False 显式地关闭自动求导时,计算历史记录就不再被追踪了,正如我们在计算b2 时所看到的那样。
如果你只是需要暂时关闭自动求导功能,一个更好的方法是使用torch.no_grad():
a = torch.ones(2, 3, requires_grad=True) * 2
b = torch.ones(2, 3, requires_grad=True) * 3c1 = a + b
print(c1)with torch.no_grad():c2 = a + bprint(c2)c3 = a * b
print(c3)
# 输出
tensor([[5., 5., 5.],[5., 5., 5.]], grad_fn=<AddBackward0>)
tensor([[5., 5., 5.],[5., 5., 5.]])
tensor([[6., 6., 6.],[6., 6., 6.]], grad_fn=<MulBackward0>)
torch.no_grad() 也可以用作函数或方法的装饰器:
def add_tensors1(x, y):return x + y@torch.no_grad()
def add_tensors2(x, y):return x + ya = torch.ones(2, 3, requires_grad=True) * 2
b = torch.ones(2, 3, requires_grad=True) * 3c1 = add_tensors1(a, b)
print(c1)c2 = add_tensors2(a, b)
print(c2)
# tensor([[5., 5., 5.],[5., 5., 5.]], grad_fn=<AddBackward0>)
tensor([[5., 5., 5.],[5., 5., 5.]])
有一个对应的上下文管理器torch.enable_grad(),用于在自动求导未开启时将其开启。它也可以用作装饰器。
最后,你可能有一个需要进行梯度跟踪的张量,但你想要一个不需要梯度跟踪的副本。为此,我们可以使用张量对象的detach()方法,它会创建一个与计算历史分离的张量副本。
x = torch.rand(5, requires_grad=True)
y = x.detach()print(x)
print(y)
# 输出
tensor([0.0670, 0.3890, 0.7264, 0.3559, 0.6584], requires_grad=True)
tensor([0.0670, 0.3890, 0.7264, 0.3559, 0.6584])
我们在上面想要绘制某些张量的图像时就进行了这样的操作。这是因为matplotlib期望输入为NumPy数组,而对于requires_grad=True的PyTorch张量,并未启用从PyTorch张量到NumPy数组的隐式转换。创建一个分离的副本能让我们继续进行操作。
自动求导与原地操作
到目前为止,在本笔记本的每个示例中,我们都使用变量来保存计算的中间值。自动求导需要这些中间值来进行梯度计算。因此,在使用自动求导时,你必须谨慎使用原地操作。因为这样做可能会破坏在backward()调用中计算导数所需的信息。如下所示,如果尝试对需要自动求导的叶子变量进行原地操作,PyTorch甚至会阻止你这么做。
注意
下面的代码单元会抛出一个运行时错误。这是预期的情况。
a = torch.linspace(0., 2. * math.pi, steps=25, requires_grad=True)
torch.sin_(a)
自动求导分析器
自动求导会详细追踪你计算的每一步。这样的计算历史记录,再结合时间信息,就可以成为一个实用的分析器——而自动求导已经内置了这个功能。以下是一个简单的使用示例:
device = torch.device('cpu')
run_on_gpu = False
if torch.cuda.is_available():device = torch.device('cuda')run_on_gpu = Truex = torch.randn(2, 3, requires_grad=True)
y = torch.rand(2, 3, requires_grad=True)
z = torch.ones(2, 3, requires_grad=True)with torch.autograd.profiler.profile(use_cuda=run_on_gpu) as prf:for _ in range(1000):z = (z / x) * yprint(prf.key_averages().table(sort_by='self_cpu_time_total'))# 输出
/var/lib/workspace/beginner_source/introyt/autogradyt_tutorial.py:485: FutureWarning:The attribute `use_cuda` will be deprecated soon, please use ``use_device = 'cuda'`` instead.------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------cudaEventRecord 53.91% 7.718ms 53.91% 7.718ms 1.929us 0.000us 0.00% 0.000us 0.000us 4000aten::mul 23.35% 3.344ms 23.35% 3.344ms 3.344us 6.782ms 50.51% 6.782ms 6.782us 1000aten::div 22.65% 3.242ms 22.65% 3.242ms 3.242us 6.646ms 49.49% 6.646ms 6.646us 1000cudaDeviceSynchronize 0.09% 12.581us 0.09% 12.581us 12.581us 0.000us 0.00% 0.000us 0.000us 1
------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 14.317ms
Self CUDA time total: 13.428ms
分析器还能够为各个代码子模块添加标签,依据输入张量的形状拆分数据,并将数据导出为Chrome追踪工具文件。有关该API的完整详细信息,请查阅文档。
高级主题:自动求导的更多细节与高级API
若有一个具有 n n n维输入和 m m m维输出的函数, y ⃗ = f ( x ⃗ ) \vec{y} = f(\vec{x}) y=f(x) ,其完整梯度是一个矩阵,矩阵中的元素是每个输出相对于每个输入的导数,此矩阵被称为雅可比矩阵:
J = ( ∂ y 1 ∂ x 1 ⋯ ∂ y n ∂ x 1 ⋮ ⋱ ⋮ ∂ y 1 ∂ x m ⋯ ∂ y m ∂ x n ) J = \begin{pmatrix} \frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_n}{\partial x_1} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_1}{\partial x_m} & \cdots & \frac{\partial y_m}{\partial x_n} \end{pmatrix} J= ∂x1∂y1⋮∂xm∂y1⋯⋱⋯∂x1∂yn⋮∂xn∂ym
若存在第二个函数, l = g ( y ⃗ ) l = g(\vec{y}) l=g(y) ,它接收 m m m维输入(即与上述输出维度相同)并返回标量输出,那么它相对于 y ⃗ \vec{y} y 的梯度可表示为列向量, v = ( ∂ l ∂ y 1 ⋯ ∂ l ∂ y m ) T v = \begin{pmatrix} \frac{\partial l}{\partial y_1} & \cdots & \frac{\partial l}{\partial y_m} \end{pmatrix}^T v=(∂y1∂l⋯∂ym∂l)T ,这其实就是一个单列的雅可比矩阵。
更具体来讲,可将第一个函数视为你的PyTorch模型(可能存在多个输入和多个输出),将第二个函数视为损失函数(以模型的输出作为输入,损失值作为标量输出)。
如果我们将第一个函数的雅可比矩阵与第二个函数的梯度相乘,并应用链式法则,可得:
J T ⋅ v = ( ∂ y 1 ∂ x 1 ⋯ ∂ y m ∂ x 1 ⋮ ⋱ ⋮ ∂ y 1 ∂ x n ⋯ ∂ y m ∂ x n ) ( ∂ l ∂ y 1 ⋮ ∂ l ∂ y m ) = ( ∂ l ∂ x 1 ⋮ ∂ l ∂ x n ) J^T \cdot v = \begin{pmatrix} \frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_m}{\partial x_1} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_1}{\partial x_n} & \cdots & \frac{\partial y_m}{\partial x_n} \end{pmatrix} \begin{pmatrix} \frac{\partial l}{\partial y_1} \\ \vdots \\ \frac{\partial l}{\partial y_m} \end{pmatrix}= \begin{pmatrix} \frac{\partial l}{\partial x_1} \\ \vdots \\ \frac{\partial l}{\partial x_n} \end{pmatrix} JT⋅v= ∂x1∂y1⋮∂xn∂y1⋯⋱⋯∂x1∂ym⋮∂xn∂ym ∂y1∂l⋮∂ym∂l = ∂x1∂l⋮∂xn∂l
注意:也可使用等效操作 v T ⋅ J v^T \cdot J vT⋅J ,会得到一个行向量。
所得的列向量是第二个函数相对于第一个函数输入的梯度——在模型与损失函数的情境下,就是损失相对于模型输入的梯度。
torch.autograd 是用于计算这些乘积的引擎。这就是我们在反向传播过程中累积学习权重梯度的方式。
基于这个原因,backward() 调用也可以接受一个可选的向量输入。这个向量表示张量上的一组梯度,它们会与在其之前的由自动求导所追踪的张量的雅可比矩阵相乘。让我们用一个小向量来尝试一个具体的例子:
x = torch.randn(3, requires_grad=True)y = x * 2
while y.data.norm() < 1000:y = y * 2print(y)
# 结果
tensor([ 299.4868, 425.4009, -1082.9885], grad_fn=<MulBackward0>)
如果我们现在尝试调用y.backward(),会得到一个运行时错误,提示信息为只能对标量输出隐式计算梯度。对于多维输出,自动求导要求我们为这三个输出提供梯度,以便它能将这些梯度与雅可比矩阵相乘。
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float) # stand-in for gradients
y.backward(v)print(x.grad)
# 输出
tensor([1.0240e+02, 1.0240e+03, 1.0240e-01])
(请注意,输出梯度都与 2 的幂次相关——这正是我们对重复加倍操作所预期的结果。)
高级 API
自动求导(Autograd)有一个 API,可让你直接访问重要的微分矩阵和向量运算。具体而言,它允许你针对特定输入计算特定函数的雅可比矩阵和海森矩阵。(海森矩阵与雅可比矩阵类似,但它表示的是所有的二阶偏导数。)它还提供了用这些矩阵进行向量乘积运算的方法。
让我们来计算一个简单函数的雅可比矩阵,该函数针对两个单元素输入进行求值:
def exp_adder(x, y):return 2 * x.exp() + 3 * yinputs = (torch.rand(1), torch.rand(1)) # arguments for the function
print(inputs)
torch.autograd.functional.jacobian(exp_adder, inputs)
# 输出
(tensor([0.7212]), tensor([0.2079]))(tensor([[4.1137]]), tensor([[3.]]))
如果你仔细观察,第一个输出应该等于(2ex)(因为(ex) 的导数是(e^x) ),并且第二个值应该是(3)。
当然,你也可以对更高阶的张量进行这样的操作:
inputs = (torch.rand(3), torch.rand(3)) # arguments for the function
print(inputs)
torch.autograd.functional.jacobian(exp_adder, inputs)
# 输出
(tensor([0.2080, 0.2604, 0.4415]), tensor([0.5220, 0.9867, 0.4288]))(tensor([[2.4623, 0.0000, 0.0000],[0.0000, 2.5950, 0.0000],[0.0000, 0.0000, 3.1102]]), tensor([[3., 0., 0.],[0., 3., 0.],[0., 0., 3.]]))
torch.autograd.functional.hessian()方法的工作原理完全相同(前提是你的函数是二阶可微的),但它会返回一个包含所有二阶导数的矩阵。
如果你提供一个向量,还有一个函数可以直接计算向量与雅可比矩阵的乘积:
def do_some_doubling(x):y = x * 2while y.data.norm() < 1000:y = y * 2return yinputs = torch.randn(3)
my_gradients = torch.tensor([0.1, 1.0, 0.0001])
torch.autograd.functional.vjp(do_some_doubling, inputs, v=my_gradients)
# 输出
(tensor([-665.7186, -866.7054, -58.4194]), tensor([1.0240e+02, 1.0240e+03, 1.0240e-01]))
torch.autograd.functional.jvp() 方法执行的矩阵乘法操作与 vjp() 相同,只是操作数的顺序相反。vhp() 和 hvp() 方法对于向量与海森矩阵的乘积也做了类似的事情(只是操作数顺序有所不同)。
如需了解更多信息,请查阅包括关于函数式 API 文档中的性能说明 。
相关文章:
深度学习框架PyTorch——从入门到精通(3.3)YouTube系列——自动求导基础
这部分是 PyTorch介绍——YouTube系列的内容,每一节都对应一个youtube视频。(可能跟之前的有一定的重复) 我们需要Autograd做什么?一个简单示例训练中的自动求导开启和关闭自动求导自动求导与原地操作 自动求导分析器高级主题&…...
【基础算法】二分算法详解
🎯 前言:二分不是找某个数,而是找一个满足条件的位置/值 所以最关键的是:找到单调性,写好 check() 函数,剩下交给模板! 什么是二分算法 二分算法是一种在有序区间中查找答案的方法,时间复杂度:O(log n)。核心思想是: 每次把搜索区间分成两半,只保留可能存在答案的…...
mysql——基础知识
关键字大小写不敏感 查看表结构中的 desc describe 描述 降序中的 desc descend 1. 数据库的操作 1. 创建数据库 create database 数据库名;为防止创建的数据库重复 CREATE DATABASE IF NOT EXISTS 数据库名;手动设置数据库采用的字符集 character set 字符集名;chars…...

html+js+clickhouse环境搭建
实验背景: 我目前有一台服务器A,和一台主机B,两台设备属于同一局域网,相互之间可以通讯。服务器A中部署着clickhouse,我在主机B中想直接通过javascript代码访问服务器中的clickhouse数据库并获取数据。 ClickHouse 服务…...

JWT算法详解
JWT(JSON Web Token)的整个算法流程主要基于其签名算法。以最常见的签名算法HS256(HMAC SHA256)为例,以下是详细的算法流程,涵盖编码、签名和验证过程: 编码 构造头部(Header&#x…...
OOA-CNN-LSTM-Attention、CNN-LSTM-Attention、OOA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比
OOA-CNN-LSTM-Attention、CNN-LSTM-Attention、OOA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比 目录 OOA-CNN-LSTM-Attention、CNN-LSTM-Attention、OOA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比预测效果基本介绍程序设计参考资料 预测效果 基本介绍 基于OOA-CN…...

Python Cookbook-6.6 在代理中托管特殊方法
任务 在新风格对象模型中,Python 操作其实是在类中查找特殊方法的(而不是在实例中那是经典对象模型的处理方式)。现在,需要将一些新风格的实例包装到代理类中,此代理可以选择将一些特殊方法委托给内部的被包装对象。 解决方案 你需要即时地…...
PCIE Spec ---Base Address Registers
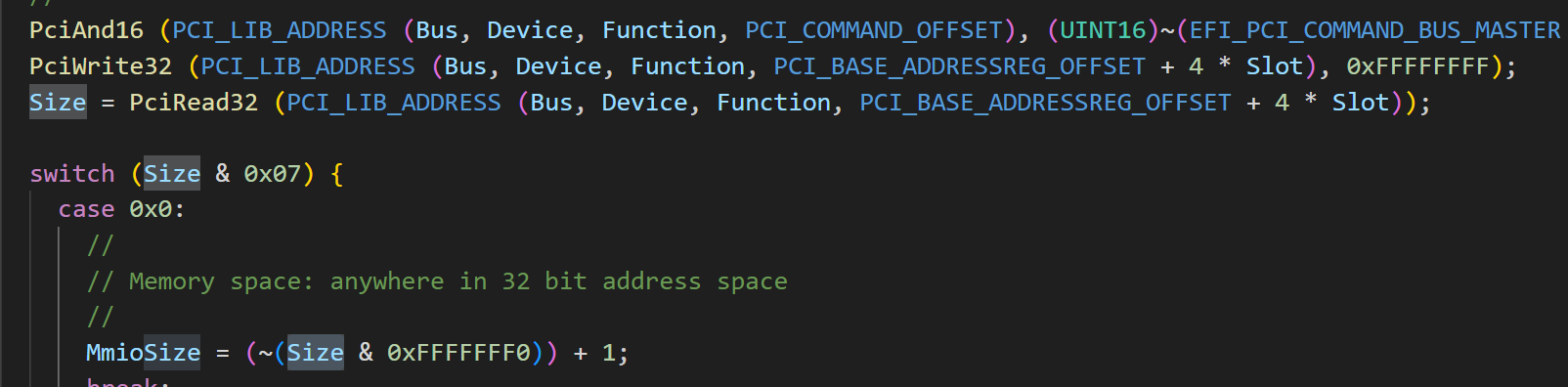
7.5.1.2.1 Base Address Registers (Offset 10h - 24h) 在 boot 到操作系统之前,系统软件需要生产一个内存映射的 address map ,用于告诉系统有多少内存资源,以及相应功能需要的内存空间,所以在设备的 PCI 内存空间中就有了这个 …...
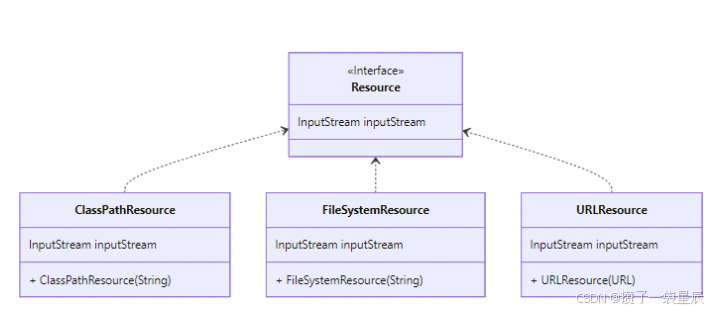
Spring如何通过XML注册Bean
在上一篇当中我们完成了对三种资源文件的读写 上篇内容:Spring是如何实现资源文件的加载 Test public void testClassPathResource() throws IOException { DefaultResourceLoader defaultResourceLoader new DefaultResourceLoader(); Resource resource …...

理解 `#pragma pack`:C/C++内存对齐的钥匙
引言:为什么我的网络程序收发的数据总是错位? 在网络编程中,你是否遇到过这样的困惑:明明发送方和接收方的结构体定义完全一样,但解析出来的数据却乱七八糟?这很可能是因为内存对齐在作祟。今天我们就来深…...

开源键鼠共享软件的“爱恨情仇“:Deskflow、InputLeap与Barrier的演化史
开源键鼠共享软件的"爱恨情仇":Deskflow、InputLeap与Barrier的演化史 一、血脉渊源:从Synergy到三足鼎立 这三款软件的起源都与 Synergy 这款商业软件密切相关: 2001年:Synergy开创软件化KVM先河2017年&…...

【Python核心库实战指南】从数据处理到Web开发
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块对比 二、实战演示环境配置要求核心代码实现(5个案例)案例1:NumPy数组运算案例2:Pandas数据分析…...

运维:概念、模式与硬件基础
一、运维概述:从网管到智能运维的进化之路 1. 运维岗位的定义 IT运维管理是保障企业IT系统及网络可用性、安全性、稳定性,确保业务连续性的核心工作。通过专业技术手段,对计算机网络、应用系统、电信网络、软硬件环境及运维服务流程等进行综…...

基于Java的不固定长度字符集在指定宽度和自适应模型下图片绘制生成实战
目录 前言 一、需求介绍 1、指定宽度生成 2、指定列自适应生成 二、Java生成实现 1、公共方法 2、指定宽度生成 3、指定列自适应生成 三、总结 前言 在当今数字化与信息化飞速发展的时代,图像的生成与处理技术正日益成为众多领域关注的焦点。从创意设计到数…...

【版本控制】idea中使用git
大家好,我是jstart千语。接下来继续对git的内容进行讲解。也是在开发中最常使用,最重要的部分,在idea中操作git。目录在右侧哦。 如果需要git命令的详解: 【版本控制】git命令使用大全-CSDN博客 一、配置git 要先关闭项目…...
 在 VS2015 中正确关闭串口避免被占用)
QT:Qt5 串口模块 (QSerialPort) 在 VS2015 中正确关闭串口避免被占用
以下是使用 Qt5 串口模块 (QSerialPort) 在 VS2015 中正确关闭串口避免被占用的完整示例代码: #include <QSerialPort> #include <QDebug>// 创建全局或类成员变量(推荐使用智能指针) QSerialPort *serialPort nullptr; // 打开…...

Linux——入门常用基础指令
文章目录 Linux入门常用基础指令使用工具介绍基础指令clear指令pwd指令ls指令cd指令Linux系统下的文件路径及文件存储结构文件结构家目录绝对路径和相对路径tree工具 stat指令which指令alias指令touch指令mkdir指令cat指令rm指令man指令cp指令通配符 * Linux入门常用基础指令 …...
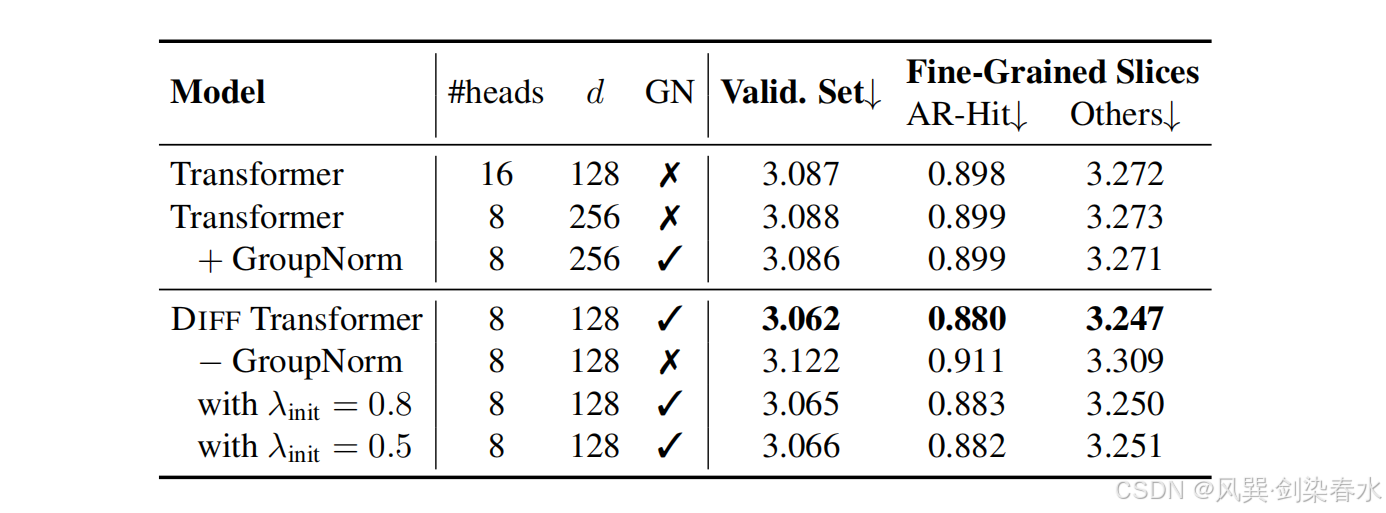
【技术追踪】Differential Transformer(ICLR-2025)
Differential Transformer:大语言模型新架构, 提出了 differential attention mechanism,Transformer 又多了一个小 trick~ 论文:Differential Transformer 代码:https://github.com/microsoft/unilm/tree/master/Diff…...

overlay 模块加载失败问题分析
问题背景 CentOS 7系统上,内核版本是3.10.0-693.21.1.el7.x86_64,加载overlay模块的时候失败了。错误提示说找不到支持的overlay文件系统,让我确认内核足够新并且已经加载了overlay支持。但是检查发现/lib/modules/3.10.0-693.el7.x86_64/ke…...
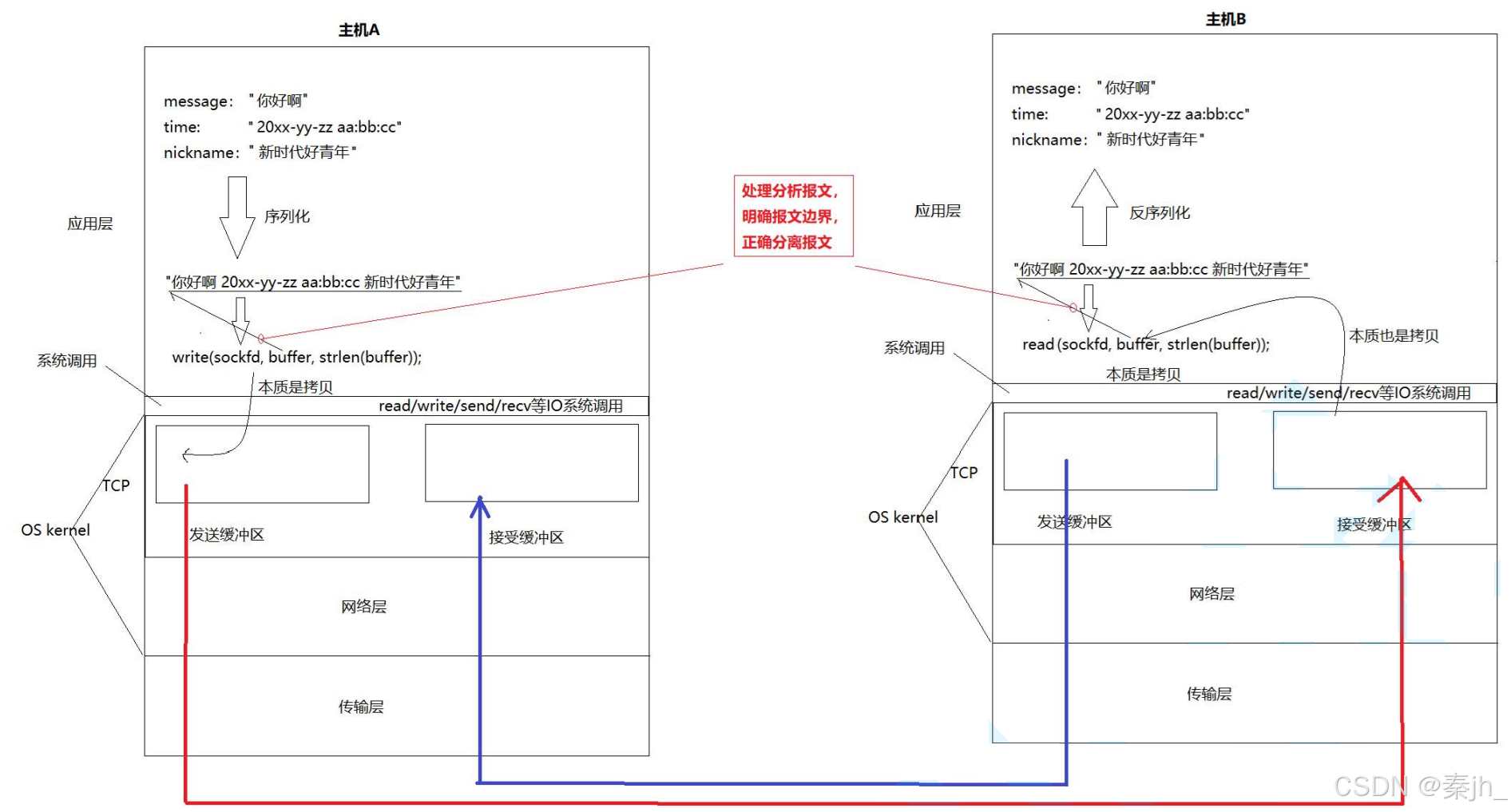
【Linux网络】应用层自定义协议与序列化
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343 🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12891150.html 目录 应用层 再谈 "协议" 网络版计算器 序列化 和 反序列化 重新理解…...
Vue接口平台学习十——接口用例页面2
效果图及简单说明 左边选择用例,右侧就显示该用例的详细信息。 使用el-collapse折叠组件,将请求到的用例详情数据展示到页面中。 所有数据内容,绑定到caseData中 // 页面绑定的用例编辑数据 const caseData reactive({title: "",…...
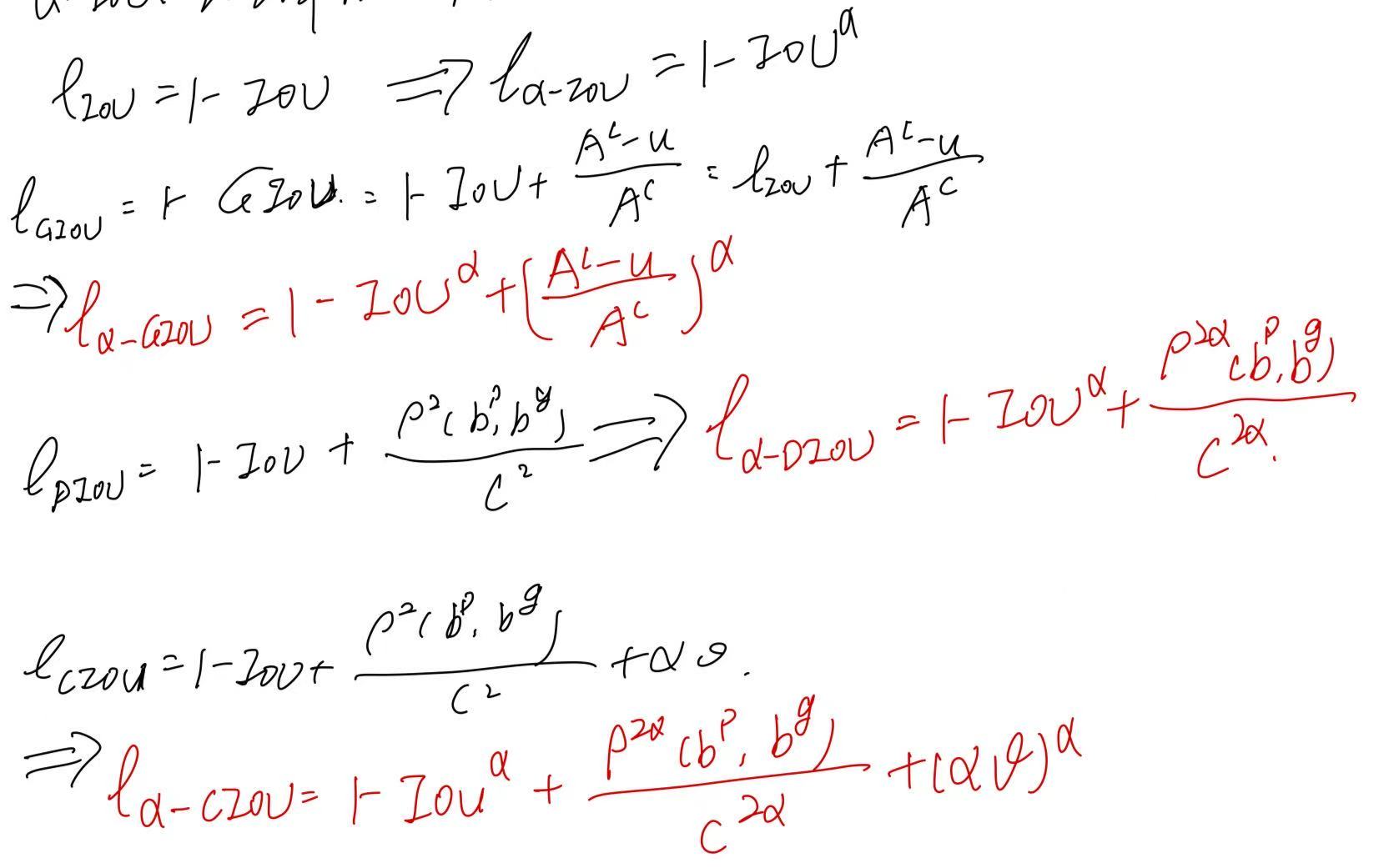
目标检测中的损失函数(二) | BIoU RIoU α-IoU
BIoU来自发表在2018年CVPR上的文章:《Improving Object Localization With Fitness NMS and Bounded IoU Loss》 论文针对现有目标检测方法只关注“足够好”的定位,而非“最优”的框,提出了一种考虑定位质量的NMS策略和BIoU loss。 这里不赘…...
 - 什么是MCP)
SpringAI系列 - MCP篇(一) - 什么是MCP
目录 一、引言二、MCP核心架构三、MCP传输层(stdio / sse)四、MCP能力协商机制(Capability Negotiation)五、MCP Client相关能力(Roots / Sampling)六、MCP Server相关能力(Prompts / Resources / Tools)一、引言 之前我们在接入大模型时,不同的大模型通常都有自己的…...
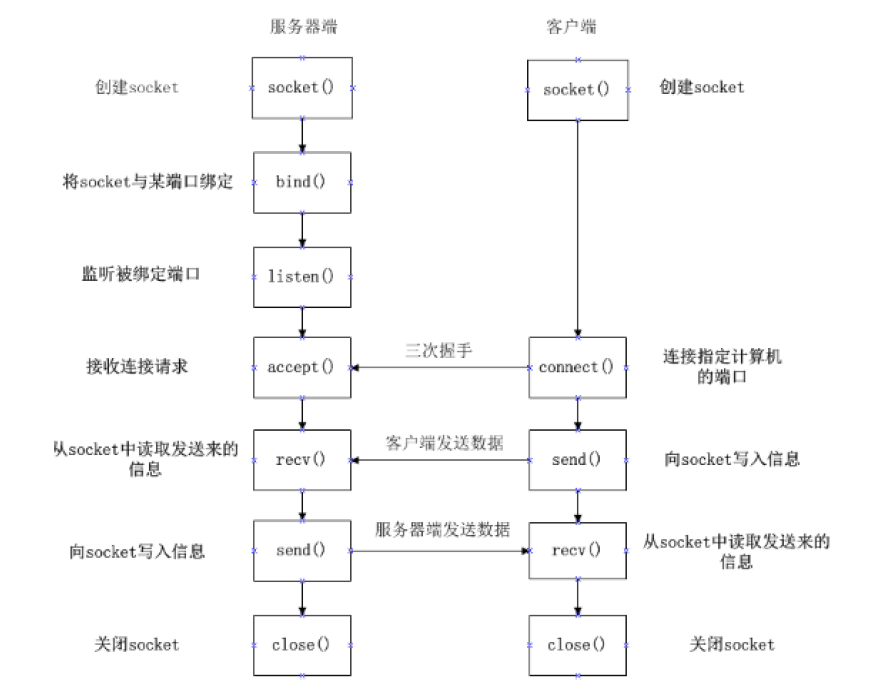
Linux 入门十一:Linux 网络编程
一、概述 1. 网络编程基础 网络编程是通过网络应用编程接口(API)编写程序,实现不同主机上进程间的信息交互。它解决的核心问题是:如何让不同主机上的程序进行通信。 2. 网络模型:从 OSI 到 TCP/IP OSI 七层模型&…...

沐渥氮气柜控制板温湿度氧含量氮气流量四显智控系统
氮气柜控制板通常用于实时监控和调节柜内环境参数,确保存储物品如电子元件、精密仪器、化学品等,处于低氧、干燥的稳定状态。以下是沐渥氮气柜控制板核心参数的详细介绍及控制逻辑: 一、控制板核心参数显示模块 1)温度显示&am…...

vue3 主题模式 结合 element-plus的主题
vue3 主题模式 结合 element-plus的主题 npm i element-plus --save-dev在 Vue 3 中,实现主题模式主要有以下几种方式 1.使用 CSS 变量(自定义属性) CSS 变量是一种在 CSS 中定义可重用值的方式。在主题模式中,可以将颜色、字体…...
)
Redis 有序集合(Sorted Set)
Redis 有序集合(Sorted Set) 以下从基础命令、内部编码和使用场景三个维度对 Redis 有序集合进行详细解析: 一、基础命令 命令时间复杂度命令含义zadd key score member [score member …] O ( k l o g ( n ) ) O(klog(n)) O(klog(n))&…...

[c语言日寄]免费文档生成器——Doxygen在c语言程序中的使用
【作者主页】siy2333 【专栏介绍】⌈c语言日寄⌋:这是一个专注于C语言刷题的专栏,精选题目,搭配详细题解、拓展算法。从基础语法到复杂算法,题目涉及的知识点全面覆盖,助力你系统提升。无论你是初学者,还是…...
QtCreator的设计器、预览功能能看到程序图标,编译运行后图标消失
重新更换虚拟机(Vmware Kylin),重新编译和配置了很多第三方库后,将代码跑到新的这个虚拟机环境中,但是出现程序图标不可见,占位也消失,后来继续检查ui文件,ui文件图标也异常&#x…...

QT文件和文件夹拷贝操作
1.拷贝文件夹 //(源文件目录路劲,目的文件目录,文件存在是否覆盖) bool copyDirectory(const QString& srcPath, const QString& dstPath, bool coverFileIfExist) { QDir srcDir(srcPath); QDir dstDir(dstPath); if (!dstDir.exi…...