强化学习框架:OpenRLHF源码解读,模型处理
本文主要介绍 强化学习框架:OpenRLHF源码解读,模型处理
models框架设计
了解一下 OpenRLHF的模型框架设计范式:
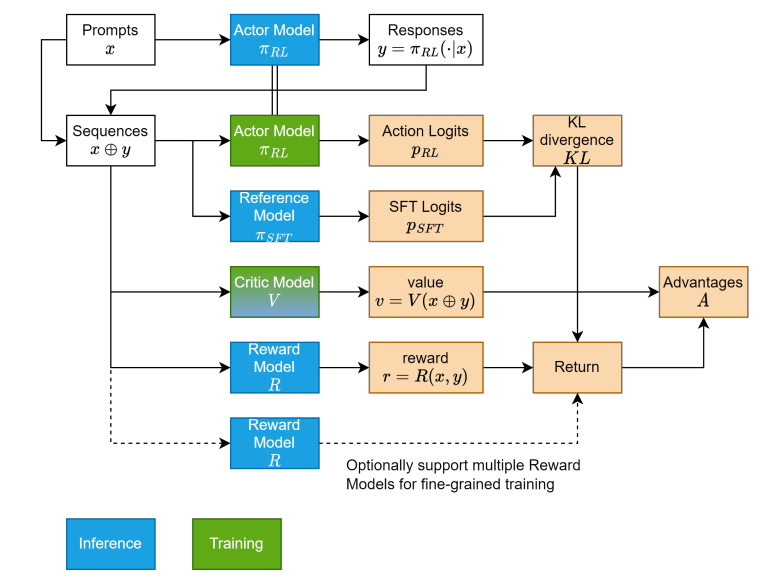
From:https://arxiv.org/pdf/2405.11143
可以知道一个大概的流程:输入Pormpt通过Actor model输出回复 Response,而后将两部分进行拼接再去由其他模型进行处理
1、actor.py
https://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/models/actor.py
这部分主要为加载所需要的模型
class Actor(nn.Module):def __init__(...):if isinstance(pretrain_or_model, str):...self.model = model_class.from_pretrained(pretrain_or_model,trust_remote_code=True,attn_implementation=attn_implementation,quantization_config=nf4_config,torch_dtype=torch.bfloat16 if bf16 else "auto",device_map=device_map,)if lora_rank > 0:self.model.enable_input_require_grads()lora_config = LoraConfig(task_type=TaskType.CAUSAL_LM,r=lora_rank,lora_alpha=lora_alpha,target_modules=target_modules,lora_dropout=lora_dropout,bias="none",)self.model = get_peft_model(self.model, lora_config)...else:self.model = pretrain_or_model@torch.no_grad()def generate(self, input_ids: torch.Tensor, **kwargs):...sequences = self.model.generate(**generate_args)eos_token_id = generate_args["eos_token_id"]pad_token_id = generate_args["pad_token_id"]return self.process_sequences(sequences, input_ids.size(1), eos_token_id, pad_token_id)def forward(...):...output["logits"] = output["logits"].to(torch.float32) # 得到每一个token概率...log_probs = log_probs_from_logits(output["logits"][:, :-1, :], sequences[:, 1:], temperature=self.temperature)...action_log_probs = log_probs[:, -num_actions:]这个actor比较简单,首先从huggingface加载需要的模型,并且对模型进行部分设置如:量化/lora微调。或者直接加载自己预训练好的模型。
1、generate:模块则是根据输入的内容(比如说被 tokenizer处理好的文本)input_ids通过模型输出新的内容(根据 **kwargs获取生成文本参数设置比如说:top_k等)
2、forward:根据输入的 token 序列(sequences),计算模型在生成最后若干个 token(即 “动作”)时的对数概率(log probs),之所以要这么处理是因为,在强化学习模型中(PPO、DPO等)一般而言模型的输出是一个序列,但优化目标不是“能不能生成这个序列”,而是:这个序列中,哪些 token 是“好”的?模型对这些 token 的概率应该更高!比如说在 DPO中:
L ( θ ) = E [ m i n ( r ( θ ) ∗ A , c l i p ( r ( θ ) , 1 − ε , 1 + ε ) ∗ A ) ] L(θ) = E[ min(r(θ) * A, clip(r(θ), 1-ε, 1+ε) * A) ] L(θ)=E[min(r(θ)∗A,clip(r(θ),1−ε,1+ε)∗A)]
里面的
r ( θ ) = π θ ( a ∣ s ) / π o l d ( a ∣ s ) r(\theta)=\pi_{\theta}(a|s)/\pi_{old}(a|s) r(θ)=πθ(a∣s)/πold(a∣s)
就是概率比值,上面代码中:
log_probs_from_logits(output["logits"][:, :-1, :], sequences[:, 1:], temperature=self.temperature)
计算的就是: l o g ( π θ ( a ∣ s ) ) log(\pi_{\theta}(a|s)) log(πθ(a∣s)),在具体代码中:
def log_probs_from_logits(logits: torch.Tensor, labels: torch.Tensor, temperature: float = 1.0) -> torch.Tensor:if temperature != 1.0:logits.div_(temperature)if logits.dtype in [torch.float32, torch.float64]:batch_dim = logits.shape[:-1]last_dim = logits.shape[-1]try:from flash_attn.ops.triton.cross_entropy import cross_entropy_lossoutput = cross_entropy_loss(logits.reshape(-1, last_dim), labels.reshape(-1))log_probs_labels = -output[0].view(*batch_dim)except ImportError:logits_labels = torch.gather(logits, dim=-1, index=labels.unsqueeze(-1)).squeeze(-1)logsumexp_values = _logsumexp_by_chunk(logits.reshape(-1, last_dim))logsumexp_values = logsumexp_values.view(*batch_dim)log_probs_labels = logits_labels - logsumexp_values # log_softmax(x_i) = x_i - logsumexp(x)else:log_probs_labels = []for row_logits, row_labels in zip(logits, labels): # loop to reduce peak mem consumptionrow_log_probs = F.log_softmax(row_logits, dim=-1)row_log_probs_labels = row_log_probs.gather(dim=-1, index=row_labels.unsqueeze(-1)).squeeze(-1)log_probs_labels.append(row_log_probs_labels)log_probs_labels = torch.stack(log_probs_labels)return log_probs_labels
补充-1:
在使用AutoModelForCausalLM.from_pretrained使用得到model之后,其支持输入参数为:
outputs = model(input_ids=None, # 输入的token(batch_size, seq_length)attention_mask=None, # 指示哪些 token 是有效的(非 padding),形状同 input_idsposition_ids=None, # 位置编码past_key_values=None,inputs_embeds=None,use_cache=None, # 是否使用k-v cachelabels=None, # 输入标签就直接计算lossoutput_attentions=None,output_hidden_states=None,return_dict=None,
)
补充-2:
在LLM训练过程中遇到过短的语句为了节约显存(如果都将内容补充到相同长度,那么就会有较多的padding造成浪费),因此可以将几个短的拼接起来,但是为了区分那些是一个句子那些不是的,在 OpenRLHF中通过参数:self.packing_samples。如果没有packing那么直接根据attention_mask将位置编码在处理一下
if not self.packing_samples:position_ids = attention_mask.long().cumsum(-1) - 1position_ids.masked_fill_(attention_mask == 0, 1)
else:# convert attention_mask to position_idsif ring_attn_group is not None:labels = sequencessequences, attention_mask, position_ids = convert_ring_attn_params(sequences, attention_mask, packed_seq_lens, ring_attn_group)else:position_ids = reset_position_ids(attention_mask)# explicitly ignore attention_mask for packing_samplesattention_mask = None
其中
reset_position_ids做的就是重新做位置编码重新处理
2、model.py
https://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/models/model.py
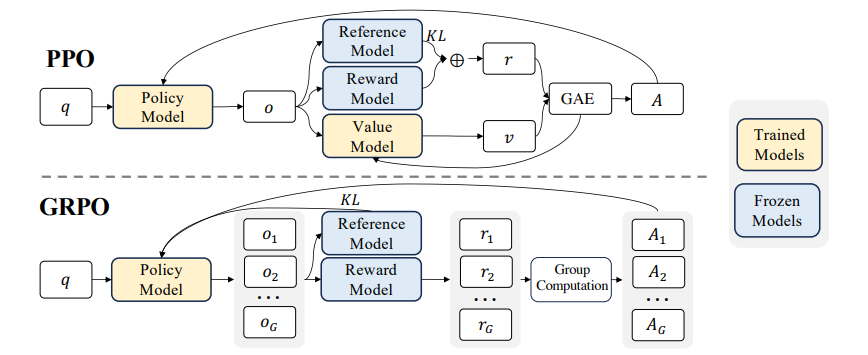
主要功能返回所需要的模型,主要返回2个模型:1、CriticModel;2、RewardModel 回顾一下这几类模型的作用:无论是在GRPO还是DPO中都会输出token然后需要去对token进行评分,起评分作用的就是 reward model 对应上面图中 reward model,除此之外都会计算 优势函数( Q ( s , a ) − V ( s ) Q(s,a)-V(s) Q(s,a)−V(s))来评估策略的好坏优势函数里面计算就是通过 critic model来对某一个策略进行评估对应上面图像中的:value model
def _get_reward_model(base_pretrained_model, base_llm_model, value_head_prefix="score", packing_samples=False):class RewardModel(base_pretrained_model):def __init__(...):...# 加载模型setattr(self, self.base_model_prefix, base_llm_model(config))self.value_head_prefix = value_head_prefixsetattr(self, value_head_prefix, nn.Linear(config.hidden_size, 1, bias=False) # 输出评分...def forward(self, input_ids: torch.LongTensor = None, attention_mask: Optional[torch.Tensor] = None, return_output=False, ring_attn_group=None,pad_sequence=False, packed_seq_lens=None,):...# 1、处理packingoutputs = getattr(self, self.base_model_prefix)(input_ids, attention_mask=attention_mask, position_ids=position_ids)last_hidden_states = outputs["last_hidden_state"]values = getattr(self, self.value_head_prefix)(last_hidden_states).squeeze(-1)...# 1、处理packingelse:# 输出最后一个有效token的评分代替整个句子评分eos_indices = attention_mask.size(1) - 1 - attention_mask.long().fliplr().argmax(dim=1, keepdim=True)reward = values.gather(dim=1, index=eos_indices).squeeze(1)if not self.training and self.normalize_reward:reward = (reward - self.mean) / self.stdreturn (reward, outputs) if return_output else rewardreturn RewardModeldef _get_critic_model(base_pretrained_model, base_llm_model, value_head_prefix="score", packing_samples=False):class CriticModel(base_pretrained_model):def __init__(...):...def forward(...):...# 1、处理packingoutputs = getattr(self, self.base_model_prefix)(input_ids, attention_mask=attention_mask, position_ids=position_ids)last_hidden_states = outputs["last_hidden_state"]values = getattr(self, self.value_head_prefix)(last_hidden_states).squeeze(-1)...if num_actions is None:assert return_outputreturn outputsif not self.packing_samples:action_values = values[:, -num_actions:]else:assert isinstance(num_actions, list) and len(num_actions) == len(packed_seq_lens)action_values = []offset = 0for num_action, seq_len in zip(num_actions, packed_seq_lens):start, end = max(0, offset + seq_len - num_action - 1), offset + seq_len - 1action_values.append(values[:, start:end])offset += seq_lenaction_values = torch.cat(action_values, dim=1)if return_output:return (action_values, outputs)else:return action_valuesreturn CriticModel
1、reward model: 传入一个 base_pretrained_model(比如 PreTrainedModel)、一个 base_llm_model(比如 AutoModel)以及一些控制参数。函数内部返回一个定制化的奖励模型类 RewardModel,它可以在给定输入句子时,输出一个数值(reward 分数),反映输出文本的质量。在forward计算中,直接将输入model使用的几个参数(见上面的补充有具体解释)计算最后取最后一个状态的值,并且将这个值取计算评分。也就是说 reward model:首先计算下一个预测的token而后对这些token进行打分
2、critic model:具体输入参数和 reward model相同。参考之前介绍,上面代码中直接返回action_values = values[:, -num_actions:]( num_actions存在条件下)这样就会得到不同的Q(s, a1), Q(s, a2), …
总结上面两组模型,在 LLM 的强化学习场景下,Reward Model 和 Critic Model 都从 last_hidden_state 得到 token-level 表达,再用 Linear 层输出每个 token 的 score。
Reward Model最后提取的是 EOS token 的 score,表示整句话的奖励。Critic Model会进一步提取最后 num_actions 个 token 的 value,这些 token 是 Actor 生成的动作,对应到 PPO 中的:𝐴(𝑠,𝑎)=𝑄(𝑠,𝑎)−𝑉(𝑠)。
理解上面内容,回顾最上面的框架设计,用下面例子进行解释。
Prompt:"The capital of France is"
Actor model:"Paris is beautiful"。那么合并得到:input_ids = ["The", "capital", "of", "France", "is", " Paris", "is", "beautiful"]
Reward model:对上面每个单词进行评分,假设:values = [0.1, 0.2, 0.3, 0.2, 0.4, 0.7, 0.5, 0.8] # 每个 token 的 score 而后输出句子中整体评分 0.8
Critic model:只对最后几个 token 的 action 计算 loss,于是:action_values = values[:, -3:] # 即取出最后 3 个生成 token 的 Q 值这些值也就对应了我们模型的生成
3、loss.py
https://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/models/loss.py
补充-1:
裁剪使用的是torch.clamp(https://pytorch.org/docs/stable/generated/torch.clamp.html)强制将范围外的数值处理为边界值,范围内数字保持不变
1、PolicyLoss:Policy Loss for PPO
r t = exp ( log π ( a t ∣ s t ) − log π old ( a t ∣ s t ) ) L clip ( t ) = min ( r t ⋅ A t , clip ( r t , 1 − ϵ , 1 + ϵ ) ⋅ A t ) L policy = − E t [ L clip ( t ) ] \begin{align*} r_t &= \exp(\log \pi(a_t \mid s_t) - \log \pi_{\text{old}}(a_t \mid s_t)) \\ \mathcal{L}_{\text{clip}}(t) &= \min\left(r_t \cdot A_t,\ \text{clip}(r_t,\ 1 - \epsilon,\ 1 + \epsilon) \cdot A_t\right) \\ \mathcal{L}_{\text{policy}} &= -\mathbb{E}_t \left[ \mathcal{L}_{\text{clip}}(t) \right] \end{align*} rtLclip(t)Lpolicy=exp(logπ(at∣st)−logπold(at∣st))=min(rt⋅At, clip(rt, 1−ϵ, 1+ϵ)⋅At)=−Et[Lclip(t)]
2、ValueLoss: Value Loss for PPO
L value = 1 2 ⋅ E t ∼ mask [ max ( ( V clip , t − R t ) 2 , ( V t − R t ) 2 ) ] 其中: V clip = V old + clip ( V − V old , − ϵ , ϵ ) \mathcal{L}_{\text{value}} = \frac{1}{2} \cdot \mathbb{E}_{t \sim \text{mask}} \left[ \max \left( (V_{\text{clip}, t} - R_t)^2, \, (V_t - R_t)^2 \right) \right]\\ \text{其中:}V_{\text{clip}} = V_{\text{old}} + \text{clip}(V - V_{\text{old}}, -\epsilon, \epsilon) Lvalue=21⋅Et∼mask[max((Vclip,t−Rt)2,(Vt−Rt)2)]其中:Vclip=Vold+clip(V−Vold,−ϵ,ϵ)
代码测试
修改了代码见链接:https://www.big-yellow-j.top/_jupyter/OpenRLHF_model.py
总结
本文主要介绍了在 OpenRLHF中模型框架设计,主要分为3类模型:1、actor model;2、critic model;3、reward model这三类模型中分别起到作用:1、直接更具prompt输出response;2、输出token的评分(action_values = values[:, -3:]);3、返回整句输出评分(找出最后一个有效 token 的索引,然后从 value 向量中提取该位置的值作为 reward。)
相关文章:
强化学习框架:OpenRLHF源码解读,模型处理
本文主要介绍 强化学习框架:OpenRLHF源码解读,模型处理 models框架设计 了解一下 OpenRLHF的模型框架设计范式: From:https://arxiv.org/pdf/2405.11143 可以知道一个大概的流程:输入Pormpt通过Actor model输出回复 Response&am…...
STL常用算法——C++
1.概述 2.常用遍历算法 1.简介 2.for_each 方式一:传入普通函数(printf1) #include<stdio.h> using namespace std; #include<string> #include<vector> #include<functional> #include<algorithm> #include…...

UofTCTF-2025-web-复现
感兴趣朋友可以去我博客里看,画风更好看 UofTCTF-2025-web-复现 文章目录 scavenger-huntprismatic-blogscode-dbprepared-1prepared-2timeless scavenger-hunt 国外的一些ctf简单题就喜欢把flag藏在注释里,开源代码找到第一部分的flag 抓个包返回数据…...

Ruby 正则表达式
Ruby 正则表达式 引言 正则表达式(Regular Expression,简称Regex)是一种强大的文本处理工具,在编程和数据处理中有着广泛的应用。Ruby 作为一种动态、灵活的编程语言,同样内置了强大的正则表达式功能。本文将详细介绍…...

[密码学基础]GB与GM国密标准深度解析:定位、差异与协同发展
[密码学基础]GB与GM国密标准深度解析:定位、差异与协同发展 导语 在国产密码技术自主可控的浪潮下,GB(国家标准)与GM(密码行业标准)共同构建了我国商用密码的技术规范体系。二者在制定主体、法律效力、技术…...

代理设计模式:从底层原理到源代码 详解
代理设计模式(Proxy Pattern)是一种结构型设计模式,它通过创建一个代理对象来控制对目标对象的访问。代理对象充当客户端和目标对象之间的中介,允许在不修改目标对象的情况下添加额外的功能(如权限控制、日志记录、延迟…...

15.第二阶段x64游戏实战-分析怪物血量(遍历周围)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:14.第二阶段x64游戏实战-分析人物的名字 如果想实现自动打怪,那肯定…...
HarmonyOS 基础语法概述 UI范式
ArkUI框架 - UI范式 ArkTS的基本组成 装饰器: 用于装饰类、结构、方法以及变量,并赋予其特殊的含义。如上述示例中Entry、Component和State都是装饰器,Component表示自定义组件,Entry表示该自定义组件为入口组件,Stat…...
专题讨论2:树与查找
在讨论前先回顾一下定义: BST树的定义 二叉搜索树是一种特殊的二叉树,对于树中的任意一个节点: 若它存在左子树,那么左子树中所有节点的值都小于该节点的值。 若它存在右子树,那么右子树中所有节点的值都大于该节点…...
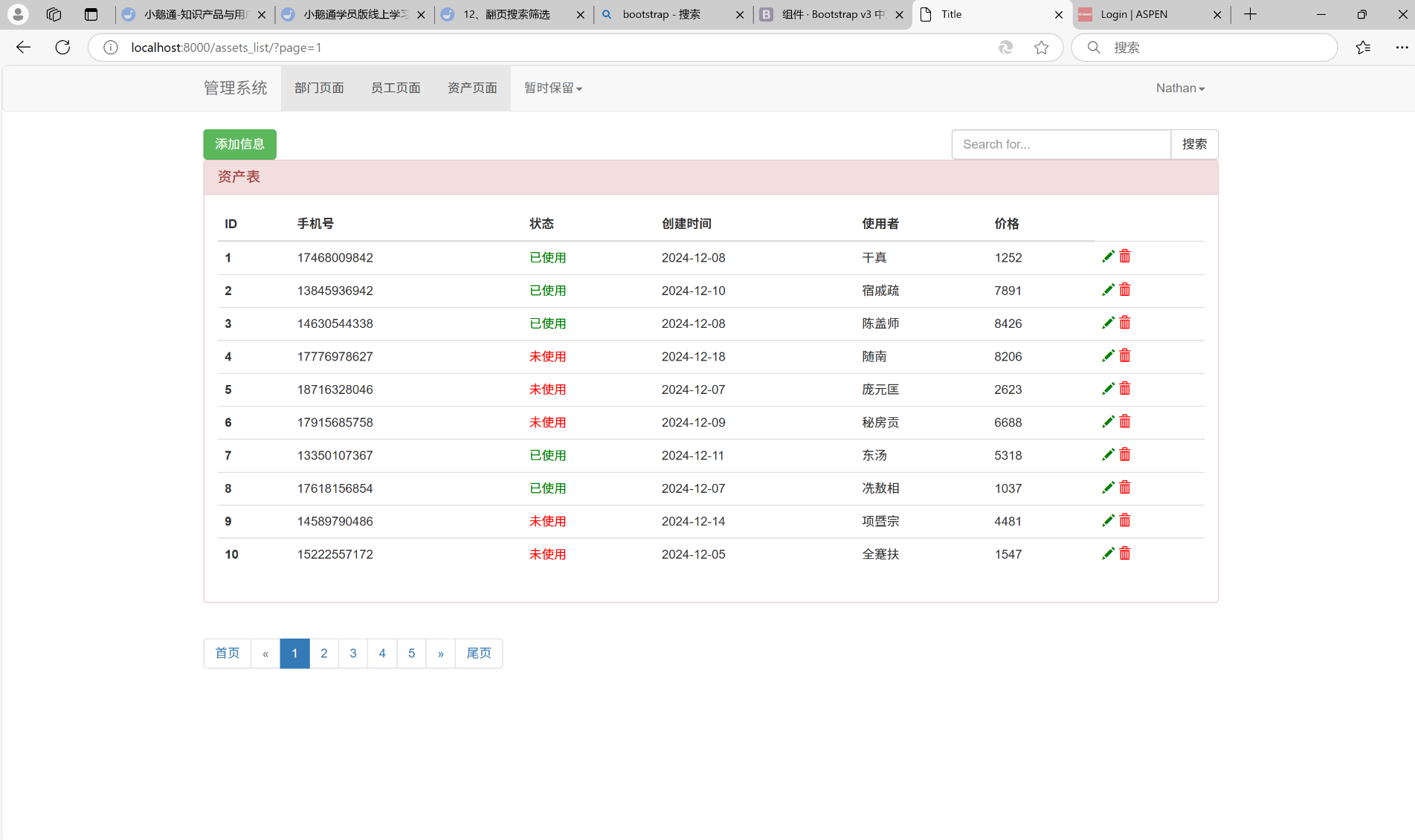
django之数据的翻页和搜索功能
数据的翻页和搜素功能 目录 1.实现搜素功能 2.实现翻页功能 一、实现搜素功能 我们到bootstrap官网, 点击组件, 然后找到输入框组, 并点击作为额外元素的按钮。 我们需要使用上面红色框里面的组件, 就是搜素组件, 代码部分就是下面红色框框出来的部分。 把这里的代码复制…...

盈达科技GEO供应商:用AICC智能认知攻防系统重构AI时代的“内容主权”
《盈达科技GEO供应商:用AICC智能认知攻防系统重构AI时代的“内容主权”》 ——从全网认知统一到多模态智能投喂,破解生成式AI的内容暗战 前言 当用户向ChatGPT提问“XX品牌空调质量如何”时,AI的回答可能直接决定企业30%的潜在客户流向。 生…...
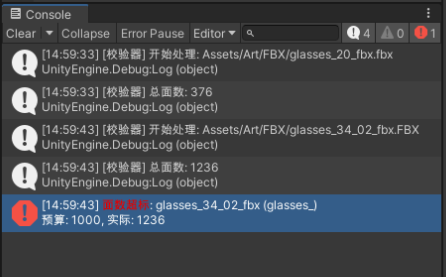
unity脚本-FBX自动化模型面数校验
根据目前模型资源平均面数预算进行脚本制作,自动化校验模型面数是否符合规范。 *注:文件格式为.cs。需要放置在unity资源文件夹Assets>Editor下。 测试效果(拖一个fbx文件进unity时自动检测): 以下为完整代码 us…...

C++用于保留浮点数的两位小数,使用宏定义方法(可兼容低版本Visual Studio)
文章目录 一、 描述二、 样例二、 结果输出 一、 描述 这个宏定义(可放入.h头文件里)使用基本的数学运算,几乎兼容所有版本的VS,以下可对正数做四舍五入: #define ROUND_TO_TWO(x) ( (floor((x) * 100 0.5) / 100) …...

day30 学习笔记
文章目录 前言一、凸包特征检测1.穷举法2.QuickHull法 二、图像轮廓特征查找1.外接矩形2.最小外接矩形3.最小外接圆 前言 通过今天的学习,我掌握了OpenCV中有关凸包特征检测,图像轮廓特征查找的相关原理和操作 一、凸包特征检测 通俗的讲,凸…...

[密码学基础]密码学发展简史:从古典艺术到量子安全的演进
密码学发展简史:从古典艺术到量子安全的演进 密码学作为信息安全的基石,其发展贯穿人类文明史,从最初的文字游戏到量子时代的数学博弈,每一次变革都深刻影响着政治、军事、科技乃至日常生活。本文将以技术演进为主线,…...
(51单片机)LCD显示温度(DS18B20教程)(LCD1602教程)(延时函数教程)(单总线教程)
演示视频: LCD显示温度 源代码 如上图将9个文放在Keli5 中即可,然后烧录在单片机中就行了 烧录软件用的是STC-ISP,不知道怎么安装的可以去看江科大的视频: 【51单片机入门教程-2020版 程序全程纯手打 从零开始入门】https://www.…...
服务器运维:服务器流量的二八法则是什么意思?
文章目录 用户行为角度时间分布角度应用场景角度 服务器流量的二八法则,又称 80/20 法则,源自意大利经济学家帕累托提出的帕累托法则,该法则指出在很多情况下,80% 的结果是由 20% 的因素所决定的。在服务器流量领域,二…...

高并发秒杀使用RabbitMQ的优化思路
高并发秒杀使用RabbitMQ的优化思路 一、判断是否重复抢购(防止一人多次秒杀)的逻辑1. 整体逻辑代码2. 原始判断重复抢购的方式:3. 后来优化为什么用 Redis 判断? 二、高并发下优化过的秒杀逻辑1.秒杀核心逻辑(请求入口)…...

B + 树与 B 树的深度剖析
在数据库领域,B 树和 B 树是两种极为关键的数据结构,它们对于数据的存储、查询以及索引的构建等方面都有着深远的影响。深刻理解这两种树的原理、特性以及它们之间的差异,对于数据库的性能优化、数据组织和管理等工作具有不可替代的重要作用…...

【LeetCode】嚼烂热题100【持续更新】
2、字母异位词分组 方法一:排序哈希表 思路:对每个字符串排序,排序后的字符串作为键插入到哈希表中,值为List<String>形式存储单词原型,键为排序后的字符串。 Map<String, List<String>> m new Ha…...

赛灵思 XC7K325T-2FFG900I FPGA Xilinx Kintex‑7
XC7K325T-2FFG900I 是 Xilinx Kintex‑7 系列中一款工业级 (I) 高性能 FPGA,基于 28 nm HKMG HPL 工艺制程,核心电压标称 1.0 V,I/O 电压可在 0.97 V–1.03 V 之间灵活配置,并可在 –40 C 至 100 C 温度范围内稳定运行。该器件提供…...

【速写】多LoRA并行衍生的一些思考
迁移学习上的一个老问题,怎么做多领域的迁移?以前的逻辑认为领域迁移属于是对参数做方向性的调整,如果两个领域方向相左,实际上不管怎么加权相加都是不合理的。 目前一些做法想着去观察LoRA权重矩阵中的稠密块与稀疏块࿰…...

探索智能仓颉!Cangjie Magic:码字之间,意境自生
仓颉输入法,对于许多老牌中文使用者来说,不仅仅是一种输入工具,更是一种情怀,一种文化符号。它以拆字为核心,将汉字结构还原成最原始的构件,再通过特定的编码规则进行输入。然而,随着拼音输入法…...

py默认框架和代码
py默认框架 平常工作日常需要频繁写python脚本,留下一个常用的模板 # template.py import logging import json import time import functools import os from typing import Any, Dict, Optional, Union from pathlib import Path from logging.handlers import …...

通过 Samba 服务实现 Ubuntu 和 Windows 之间互传文件
在 Ubuntu 上进行配置 1. 安装 Samba 服务 打开终端,输入以下命令来安装 Samba: sudo apt update sudo apt install samba2. 创建共享目录 可以使用以下命令创建一个新的共享目录,例如创建名为 shared_folder 的目录: sudo m…...

k8s-1.28.10 安装metrics-server
1.简介 Metrics Server是一个集群范围的资源使用情况的数据聚合器。作为一个应用部署在集群中。Metric server从每个节点上KubeletAPI收集指标,通过Kubernetes聚合器注册在Master APIServer中。为集群提供Node、Pods资源利用率指标。 2.下载yaml文件 wget https:/…...

基于外部中中断机制,实现以下功能: 1.按键1,按下和释放后,点亮LED 2.按键2,按下和释放后,熄灭LED 3.按键3,按下和释放后,使得LED闪烁
题目: 参照外部中断的原理和代码示例,再结合之前已经实现的按键切换LED状态的实验,用外部中断改进其实现。 请自行参考文档《中断》当中,有关按键切换LED状态的内容, 自行连接电路图,基于外部中断机制,实现以下功能&am…...

【我的创作纪念日】 --- 与CSDN走过的第365天
个人主页:夜晚中的人海 不积跬步,无以至千里;不积小流,无以成江海。-《荀子》 文章目录 🎉一、机缘🚀二、收获🎡三、 日常⭐四、成就🏠五、憧憬 🎉一、机缘 光阴似箭&am…...

学习笔记——《Java面向对象程序设计》-继承
参考教材: Java面向对象程序设计(第3版)微课视频版 清华大学出版社 1、定义子类 class 子类名 extends 父类名{...... }如: class Student extends People{...... } (1)如果一个类的声明中没有extends关…...

鸿蒙生态新利器:华为ArkUI-X混合开发框架深度解析
鸿蒙生态新利器:华为ArkUI-X混合开发框架深度解析 作者:王老汉 | 鸿蒙生态开发者 | 2025年4月 📢 前言:开发者们的新机遇 各位鸿蒙开发者朋友们,是否还在为多平台开发重复造轮子而苦恼?今天给大家介绍一位…...