【速写】多LoRA并行衍生的一些思考
迁移学习上的一个老问题,怎么做多领域的迁移?以前的逻辑认为领域迁移属于是对参数做方向性的调整,如果两个领域方向相左,实际上不管怎么加权相加都是不合理的。
目前一些做法想着去观察LoRA权重矩阵中的稠密块与稀疏块,选择稠密的部分予以保留,稀疏的部分予以舍弃,然后有选择地进行合并,这是一种很模糊的做法,实际上也缺乏理论保证,而且,低秩与稀疏通常并不等价。
假定是做秩一分解:
h 1 = W 0 x + ( B 1 A 1 ) x = W 0 x + ( ∑ i = 1 r 1 d 1 i v i v i ⊤ ) x = W 0 x + ∑ i = 1 r 1 ( d 1 i v i ⊤ x ) v i = W 0 x + ∑ i = 1 r 1 k 1 i v i h 2 = W 0 x + ( B 2 A 2 ) x = W 0 x + ( ∑ i = 1 r 2 d 2 i u i u i ⊤ ) x = W 0 x + ∑ i = 1 r 2 ( d 2 i v i ⊤ x ) v i = W 0 x + ∑ i = 1 r 2 k 2 i v i h_1 = W_0 x + (B_1A_1) x = W_0 x + \left(\sum_{i=1}^{r_1} d_{1i} v_iv_i^\top\right) x = W_0 x + \sum_{i=1}^{r_1} (d_{1i} v_i^\top x) v_i = W_0 x + \sum_{i=1}^{r_1} k_{1i} v_i \\ h_2 = W_0 x + (B_2A_2) x = W_0 x + \left(\sum_{i=1}^{r_2} d_{2i} u_iu_i^\top\right) x = W_0 x + \sum_{i=1}^{r_2} (d_{2i} v_i^\top x) v_i = W_0 x + \sum_{i=1}^{r_2} k_{2i} v_i h1=W0x+(B1A1)x=W0x+(i=1∑r1d1ivivi⊤)x=W0x+i=1∑r1(d1ivi⊤x)vi=W0x+i=1∑r1k1ivih2=W0x+(B2A2)x=W0x+(i=1∑r2d2iuiui⊤)x=W0x+i=1∑r2(d2ivi⊤x)vi=W0x+i=1∑r2k2ivi
调整的其实就是rank数量的单位向量的加权和。
这里面的 u i , v i u_i,v_i ui,vi都是单位向量, d 1 i d_{1i} d1i和 d 2 i d_{2i} d2i表示奇异值。
k 1 i k_{1i} k1i和 k 2 i k_{2i} k2i都是标量。
那么我们可以在每一层的输出时,选择需要保留的若干个单位向量的加权和作为这层的输出,保留的依据可以根据 k 1 i k_{1i} k1i和 k 2 i k_{2i} k2i的大小来确定(保大去小)。
比如在合并的时候从 r 1 + r 2 r_1+r_2 r1+r2个秩一矩阵中取 r 1 + r 2 2 \frac{r_1+r_2}{2} 2r1+r2个出来作为融合后的LoRA
这样的调整本身关于输入 x x x是动态的,复杂度很差。
另一件事就是白盒压缩、或者说模型压缩的时候,为什么不直接用SVD进行降维处理呢,重新训练一个小模型出来,可能连模型结构都不一样的模型出来替代原模型,难道还能比跟原模型结构相同的东西有更令人信服的性能吗?
题外话,以及做INT量化与用SVD进行降维处理,两种方法截然不同,对精度的影响有何区别呢?两者都对隐层权重的数值,从而影响每个隐层的输出,但是直觉上,INT量化产生的误差的方差在point-wise上是处处相等的(即均匀误差),但是SVD似乎并非如此,因为SVD给出的误差其实是若干个比较小的奇异值所对应的秩一矩阵的加权和,而秩一矩阵值的分布显然不可能是均匀分布,这取决于奇异向量的分布:
(1) 高度结构化
- 所有行成比例:矩阵的每一行是向量 v v v的标量倍数(系数为 u i u_i ui)。
第 i 行 = u i ⋅ [ v 1 , v 2 , … , v n ] \text{第} i \text{行} = u_i \cdot [v_1, v_2, \dots, v_n] 第i行=ui⋅[v1,v2,…,vn] - 所有列成比例:每一列是向量 u u u的标量倍数(系数为 v j v_j vj)。
第 j 列 = v j ⋅ [ u 1 , u 2 , … , u m ] T \text{第} j \text{列} = v_j \cdot [u_1, u_2, \dots, u_m]^T 第j列=vj⋅[u1,u2,…,um]T
(2) 数值分布依赖基向量
- 矩阵元素的值完全由 u u u和 v v v的分布决定:
- 若 u u u或 v v v服从高斯分布,则 M i j M_{ij} Mij是高斯变量的乘积(分布可能复杂,但通常呈现尖峰、重尾特性)。
- 若 u u u或 v v v是稀疏的,则 M M M也会稀疏。
(3) 特征值与奇异值
- 非零特征值:秩1矩阵仅有1个非零特征值(等于 u T v u^T v uTv或 v T u v^T u vTu)。
- 奇异值:唯一非零奇异值为 ∥ u ∥ ⋅ ∥ v ∥ \|u\| \cdot \|v\| ∥u∥⋅∥v∥,其余奇异值为0。
至少从误差的分布上来说,量化要更稳定可控一些。
总是觉得现在人做事太简单粗暴了,没有理论分析的支撑,全凭拍脑袋。
下面简单看一看DeepSeek对于多LoRA合并的论述:
多LoRA并行(Multiple LoRA Adapters Parallel)的底层逻辑涉及在模型运行时动态组合多个低秩适配器的权重,其核心是通过并行计算或权重叠加的方式将不同LoRA模块的影响同时作用于基座模型(Base Model)。
1. 基本概念回顾
- LoRA的本质:
在原始模型权重 W 0 ∈ R d × k W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k 旁注入低秩矩阵 A ∈ R d × r A \in \mathbb{R}^{d \times r} A∈Rd×r 和 B ∈ R r × k B \in \mathbb{R}^{r \times k} B∈Rr×k,其中 r ≪ min ( d , k ) r \ll \min(d,k) r≪min(d,k)。
前向传播时,输出为:
h = W 0 x + ( B A ) x h = W_0 x + (BA) x h=W0x+(BA)x - 多LoRA并行:
同时激活多个LoRA模块(如 B A ( 1 ) + B A ( 2 ) + … BA^{(1)} + BA^{(2)} + \dots BA(1)+BA(2)+…),输出变为:
h = W 0 x + ∑ i = 1 N ( B ( i ) A ( i ) ) x h = W_0 x + \sum_{i=1}^N (B^{(i)} A^{(i)}) x h=W0x+i=1∑N(B(i)A(i))x
2. 运行时计算的两种实现方式
方式1:权重直接叠加(静态合并)
步骤:
- 离线合并:在加载模型时,将所有激活的LoRA的增量权重 Δ W i = B ( i ) A ( i ) \Delta W_i = B^{(i)}A^{(i)} ΔWi=B(i)A(i) 相加:
Δ W merged = ∑ i = 1 N B ( i ) A ( i ) \Delta W_{\text{merged}} = \sum_{i=1}^N B^{(i)}A^{(i)} ΔWmerged=i=1∑NB(i)A(i) - 前向计算:仅需计算一次合并后的增量:
h = W 0 x + Δ W merged x h = W_0 x + \Delta W_{\text{merged}} x h=W0x+ΔWmergedx
底层逻辑:
- 优点:计算量与单LoRA相同,无额外开销。
- 缺点:静态合并后无法动态调整适配器组合。
- 适用场景:推理时需固定融合多个LoRA。
代码示例(PyTorch):
# 假设 lora_A 和 lora_B 是两个LoRA模块的增量权重
delta_W = lora_A @ lora_B + lora_C @ lora_D # 低秩矩阵乘法
h = base_model_W @ x + delta_W @ x
方式2:动态并行计算(运行时逐适配器计算)
步骤:
- 独立保留LoRA权重:保持每个LoRA的 A ( i ) A^{(i)} A(i) 和 B ( i ) B^{(i)} B(i) 矩阵独立存储。
- 前向传播时逐适配器计算:
h = W 0 x + ∑ i = 1 N ( B ( i ) ( A ( i ) x ) ) h = W_0 x + \sum_{i=1}^N (B^{(i)} (A^{(i)} x)) h=W0x+i=1∑N(B(i)(A(i)x))- 先计算所有 A ( i ) x A^{(i)} x A(i)x,再与对应的 B ( i ) B^{(i)} B(i) 相乘,最后累加结果。
底层逻辑:
- 优点:支持动态开关适配器(如根据输入选择不同的LoRA组合)。
- 缺点:计算量随LoRA数量线性增长(需 N N N 次低秩矩阵乘法和累加)。
- 适用场景:需要运行时灵活切换适配器的场景(如多任务推理)。
代码示例(PEFT库实现逻辑):
# 伪代码:动态多LoRA计算
h = base_layer(x)
for adapter in active_adapters:lora_A = adapters[adapter].A # 形状 (d, r)lora_B = adapters[adapter].B # 形状 (r, k)h += (lora_B @ (lora_A @ x)) * adapter.scaling # 缩放系数
3. 关键优化技术
为了减少多LoRA并行的计算开销,框架(如PEFT)通常会采用以下优化:
(1) 共享基座模型权重
- 所有LoRA复用同一份 W 0 W_0 W0,仅额外存储增量部分 Δ W i \Delta W_i ΔWi。
(2) 批处理低秩计算
- 将多个LoRA的 A ( i ) A^{(i)} A(i) 拼接为大矩阵 A stack ∈ R N ⋅ r × d A_{\text{stack}} \in \mathbb{R}^{N \cdot r \times d} Astack∈RN⋅r×d,通过一次矩阵乘法和分割结果加速计算:
[ A ( 1 ) x ; A ( 2 ) x ; … ] = A stack x [A^{(1)}x; A^{(2)}x; \dots] = A_{\text{stack}} x [A(1)x;A(2)x;…]=Astackx
再分别与对应的 B ( i ) B^{(i)} B(i) 相乘。
(3) 延迟缩放(Scaling)
- 将LoRA的缩放系数 α r \frac{\alpha}{r} rα 合并到 B ( i ) B^{(i)} B(i) 中,避免重复乘法:
B ′ ( i ) = B ( i ) ⋅ α r B'^{(i)} = B^{(i)} \cdot \frac{\alpha}{r} B′(i)=B(i)⋅rα
4. 数学形式对比
假设有两个LoRA( Δ W 1 = B 1 A 1 \Delta W_1 = B_1A_1 ΔW1=B1A1, Δ W 2 = B 2 A 2 \Delta W_2 = B_2A_2 ΔW2=B2A2):
| 方法 | 计算过程 | FLOPs |
|---|---|---|
| 静态合并 | h = W 0 x + ( B 1 A 1 + B 2 A 2 ) x h = W_0 x + (B_1A_1 + B_2A_2) x h=W0x+(B1A1+B2A2)x | O ( d k + d r + r k ) O(dk + dr + rk) O(dk+dr+rk) |
| 动态并行 | h = W 0 x + B 1 ( A 1 x ) + B 2 ( A 2 x ) h = W_0 x + B_1(A_1 x) + B_2(A_2 x) h=W0x+B1(A1x)+B2(A2x) | O ( d k + 2 ( d r + r k ) ) O(dk + 2(dr + rk)) O(dk+2(dr+rk)) |
| 批处理优化 | h = W 0 x + [ B 1 , B 2 ] ⋅ [ A 1 ; A 2 ] x h = W_0 x + [B_1, B_2] \cdot [A_1; A_2] x h=W0x+[B1,B2]⋅[A1;A2]x | O ( d k + d ( 2 r ) + ( 2 r ) k ) O(dk + d(2r) + (2r)k) O(dk+d(2r)+(2r)k) |
5. 实际框架中的实现
以PEFT(Hugging Face)为例:
- 注册多个适配器:
model.add_adapter("adapter1", lora_config_A) model.add_adapter("adapter2", lora_config_B) - 动态激活组合:
model.set_active_adapters(["adapter1", "adapter2"]) - 底层计算:
- PEFT自动选择动态并行计算(方式2),按需累加所有激活适配器的输出。
6. 总结:多LoRA并行的本质
- 静态合并:算术叠加权重,适合固定组合的轻量推理。
- 动态并行:独立计算后求和,适合灵活适配但计算成本较高。
- 优化方向:通过批处理和共享基座权重减少冗余计算。
如果需要进一步分析具体框架(如PEFT、AdaLoRA)的实现细节,可以提供更多上下文!
相关文章:

【速写】多LoRA并行衍生的一些思考
迁移学习上的一个老问题,怎么做多领域的迁移?以前的逻辑认为领域迁移属于是对参数做方向性的调整,如果两个领域方向相左,实际上不管怎么加权相加都是不合理的。 目前一些做法想着去观察LoRA权重矩阵中的稠密块与稀疏块࿰…...

探索智能仓颉!Cangjie Magic:码字之间,意境自生
仓颉输入法,对于许多老牌中文使用者来说,不仅仅是一种输入工具,更是一种情怀,一种文化符号。它以拆字为核心,将汉字结构还原成最原始的构件,再通过特定的编码规则进行输入。然而,随着拼音输入法…...

py默认框架和代码
py默认框架 平常工作日常需要频繁写python脚本,留下一个常用的模板 # template.py import logging import json import time import functools import os from typing import Any, Dict, Optional, Union from pathlib import Path from logging.handlers import …...

通过 Samba 服务实现 Ubuntu 和 Windows 之间互传文件
在 Ubuntu 上进行配置 1. 安装 Samba 服务 打开终端,输入以下命令来安装 Samba: sudo apt update sudo apt install samba2. 创建共享目录 可以使用以下命令创建一个新的共享目录,例如创建名为 shared_folder 的目录: sudo m…...

k8s-1.28.10 安装metrics-server
1.简介 Metrics Server是一个集群范围的资源使用情况的数据聚合器。作为一个应用部署在集群中。Metric server从每个节点上KubeletAPI收集指标,通过Kubernetes聚合器注册在Master APIServer中。为集群提供Node、Pods资源利用率指标。 2.下载yaml文件 wget https:/…...

基于外部中中断机制,实现以下功能: 1.按键1,按下和释放后,点亮LED 2.按键2,按下和释放后,熄灭LED 3.按键3,按下和释放后,使得LED闪烁
题目: 参照外部中断的原理和代码示例,再结合之前已经实现的按键切换LED状态的实验,用外部中断改进其实现。 请自行参考文档《中断》当中,有关按键切换LED状态的内容, 自行连接电路图,基于外部中断机制,实现以下功能&am…...

【我的创作纪念日】 --- 与CSDN走过的第365天
个人主页:夜晚中的人海 不积跬步,无以至千里;不积小流,无以成江海。-《荀子》 文章目录 🎉一、机缘🚀二、收获🎡三、 日常⭐四、成就🏠五、憧憬 🎉一、机缘 光阴似箭&am…...

学习笔记——《Java面向对象程序设计》-继承
参考教材: Java面向对象程序设计(第3版)微课视频版 清华大学出版社 1、定义子类 class 子类名 extends 父类名{...... }如: class Student extends People{...... } (1)如果一个类的声明中没有extends关…...

鸿蒙生态新利器:华为ArkUI-X混合开发框架深度解析
鸿蒙生态新利器:华为ArkUI-X混合开发框架深度解析 作者:王老汉 | 鸿蒙生态开发者 | 2025年4月 📢 前言:开发者们的新机遇 各位鸿蒙开发者朋友们,是否还在为多平台开发重复造轮子而苦恼?今天给大家介绍一位…...

如何收集用户白屏/长时间无响应/接口超时问题
想象一下这样的场景:一位用户在午休时间打开某电商应用,准备购买一件心仪已久的商品。然而,页面加载了数秒后依然是一片空白,或者点击“加入购物车”按钮后没有任何反馈,甚至在结算时接口超时导致订单失败。用户的耐心被迅速消耗殆尽,关闭应用,转而选择了竞争对手的产品…...

信号调制与解调技术基础解析
调制解调技术是通信系统中实现基带信号与高频载波信号相互转换的主要技术,通过调整信号特性使其适应不同信道环境,保障信息传输的效率和可靠性。 调制与解调的基本概念 调制(Modulation) 将低频基带信号(如语音或数…...

[PTA]2025 CCCC-GPLT天梯赛 胖达的山头
来源:L2-055 胖达的山头-Pintia题意:给定 n n n 个事件的起始和终止时刻(以hh:mm:ss给出),求最多并行事件数。关键词:差分(签到,模板题)题解:将所有时刻转换为秒,当某事件开始1,结束则-1。按时…...

基于Spring Cloud 2023.0.x + Micrometer Tracing的分布式链路追踪详细解析
前言 在微服务架构中,复杂的调用链路常让问题排查如大海捞针。Spring Cloud 2023.0.x整合Micrometer Tracing,深度支持OpenTelemetry标准,为开发者提供了轻量、高效的分布式链路追踪能力。本文将深入解析从TraceID透传到可视化分析的全流程实现,结合最新技术栈代码…...
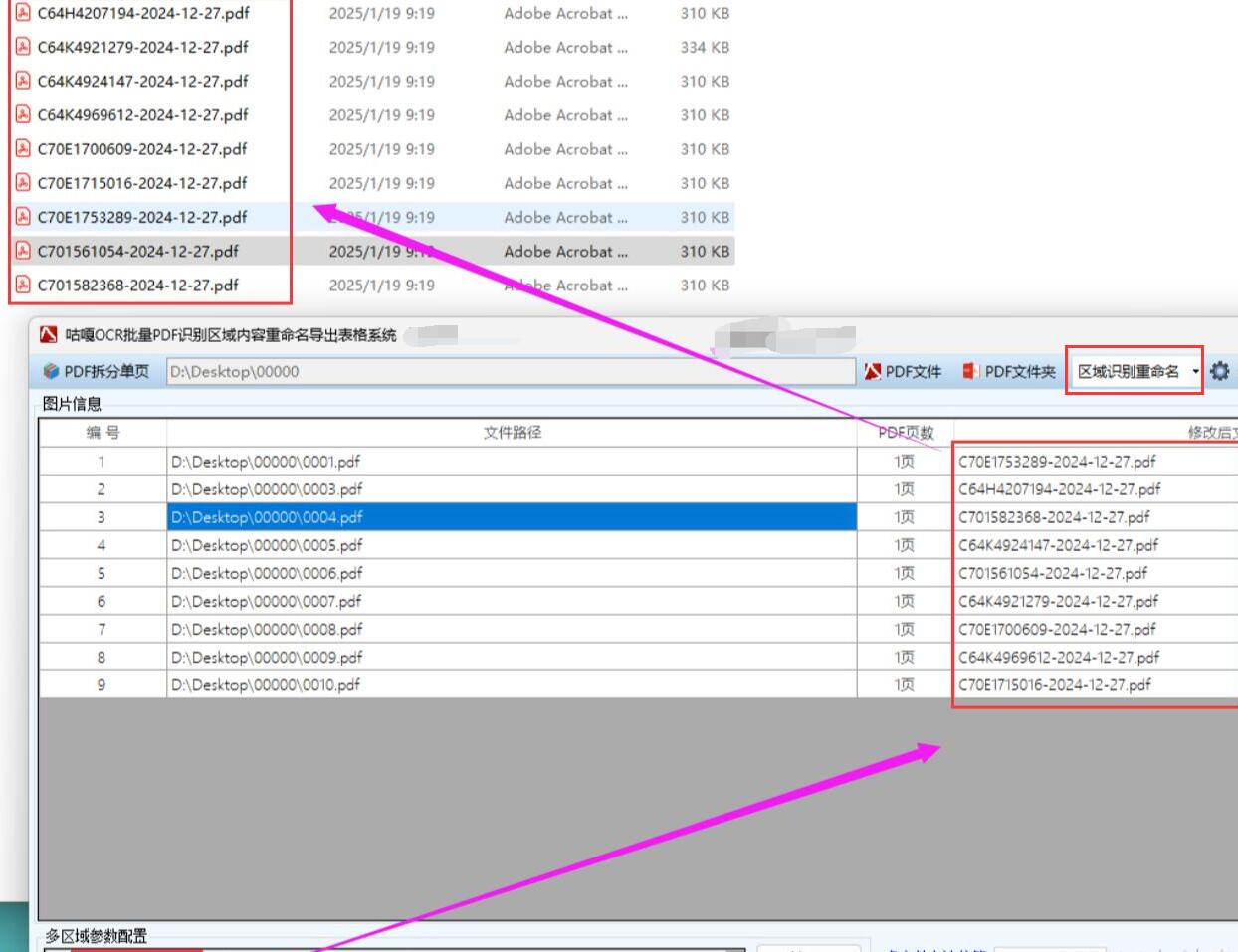
【扫描件批量改名】批量识别扫描件PDF指定区域内容,用识别的内容修改PDF文件名,基于C++和腾讯OCR的实现方案,超详细
批量识别扫描件PDF指定区域内容并重命名文件方案 应用场景 本方案适用于以下场景: 企业档案数字化管理:批量处理扫描的合同、发票等文件,按内容自动分类命名财务票据处理:自动识别票据上的关键信息(如发票号码、日期)用于归档医疗记录管理:从扫描的检查报告中提取患者I…...

LOH 怎么进行深度标准化?
The panel of normals is applied by replacing the germline read depth of the sample with the median read depth of samples with the same genotype in our panel. 1.解释: panel of normal 正常组织,用于识别技术噪音 germline read depth: 胚系测序深度。根…...

【Python Web开发】01-Socket网络编程01
文章目录 1.套接字(Socket)1.1 概念1.2 类型1.3 使用步骤 Python 的网络编程主要用于让不同的计算机或者程序之间进行数据交换和通信,就好像人与人之间打电话、发消息一样。 下面从几个关键方面通俗易懂地介绍一下: 1.套接字(Socket) 在 Python 网络编…...
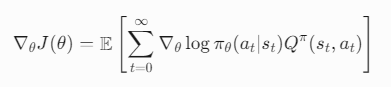
序列决策问题(Sequential Decision-Making Problem)
序列决策问题(Sequential Decision-Making Problem)是强化学习(Reinforcement Learning, RL)的核心研究内容,其核心思想是:智能体(Agent)需要在连续的时间步骤中,通过…...
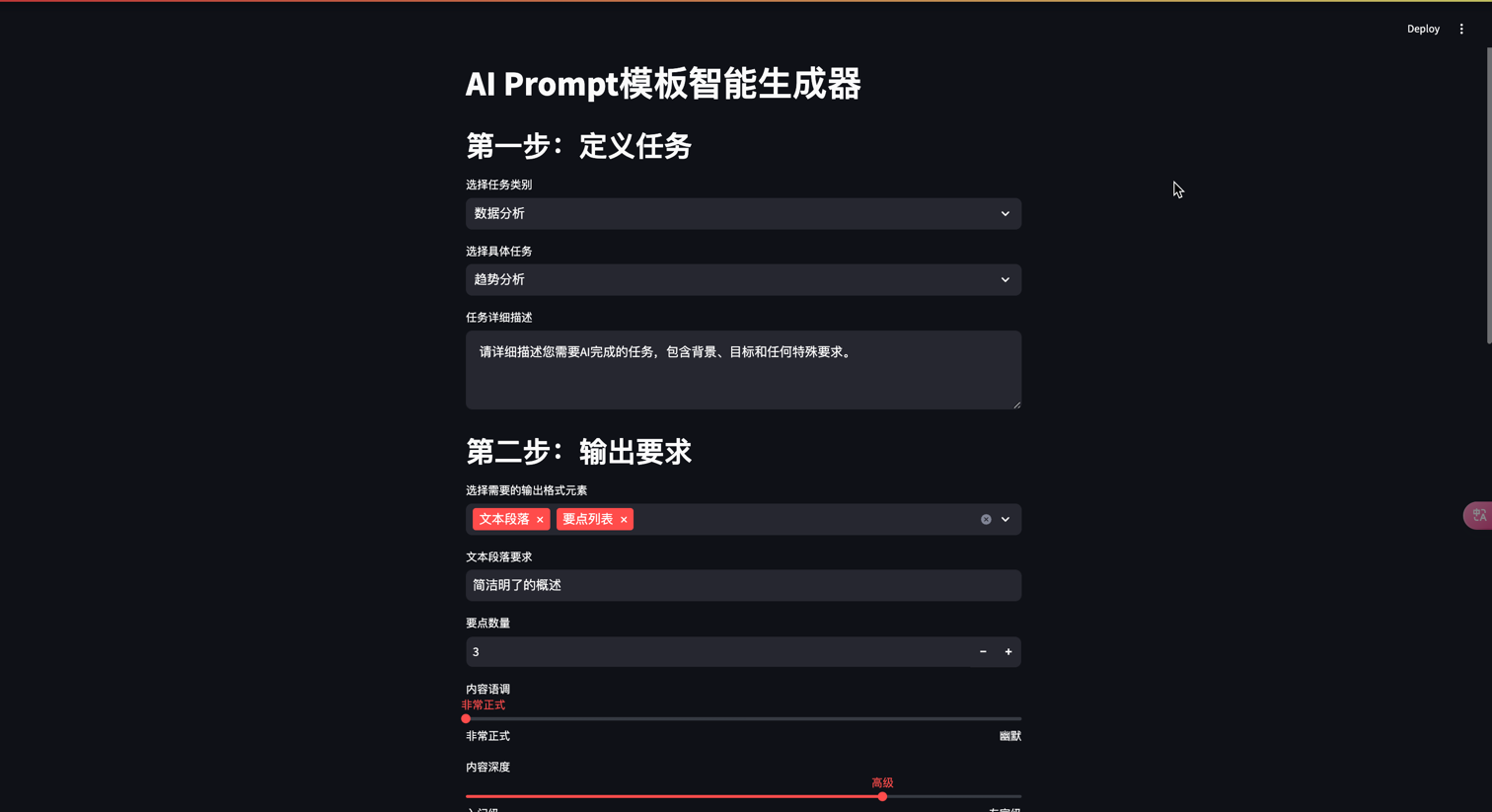
L2-1、打造稳定可控的 AI 输出 —— Prompt 模板与格式控制
一、为什么需要 Prompt 模板? 在与 AI 模型交互时,我们经常会遇到输出不稳定、格式混乱的问题。Prompt 模板帮助我们解决这些问题,通过结构化的输入指令来获得可预测且一致的输出结果。 模板的作用主要体现在: 固定输出格式&am…...

ClickHouse进行LEFT JOIN 关联查询时, 关联键的数据类型不一致,导致报错 的解决方案详解
一.场景 使用golang语言操作ClickHouse数据库进行LEFT JOIN关联查询查询计算: 关联键在不同数据表中的数据类型不一致, 这样SQL语句就会报错, 二.问题 通过上面场景描述, 下面贴出具体的sql语句相关: 表user_phone_bind: 字段UserId(用户id): 类型Int64字段Phone(手机号): 类型…...
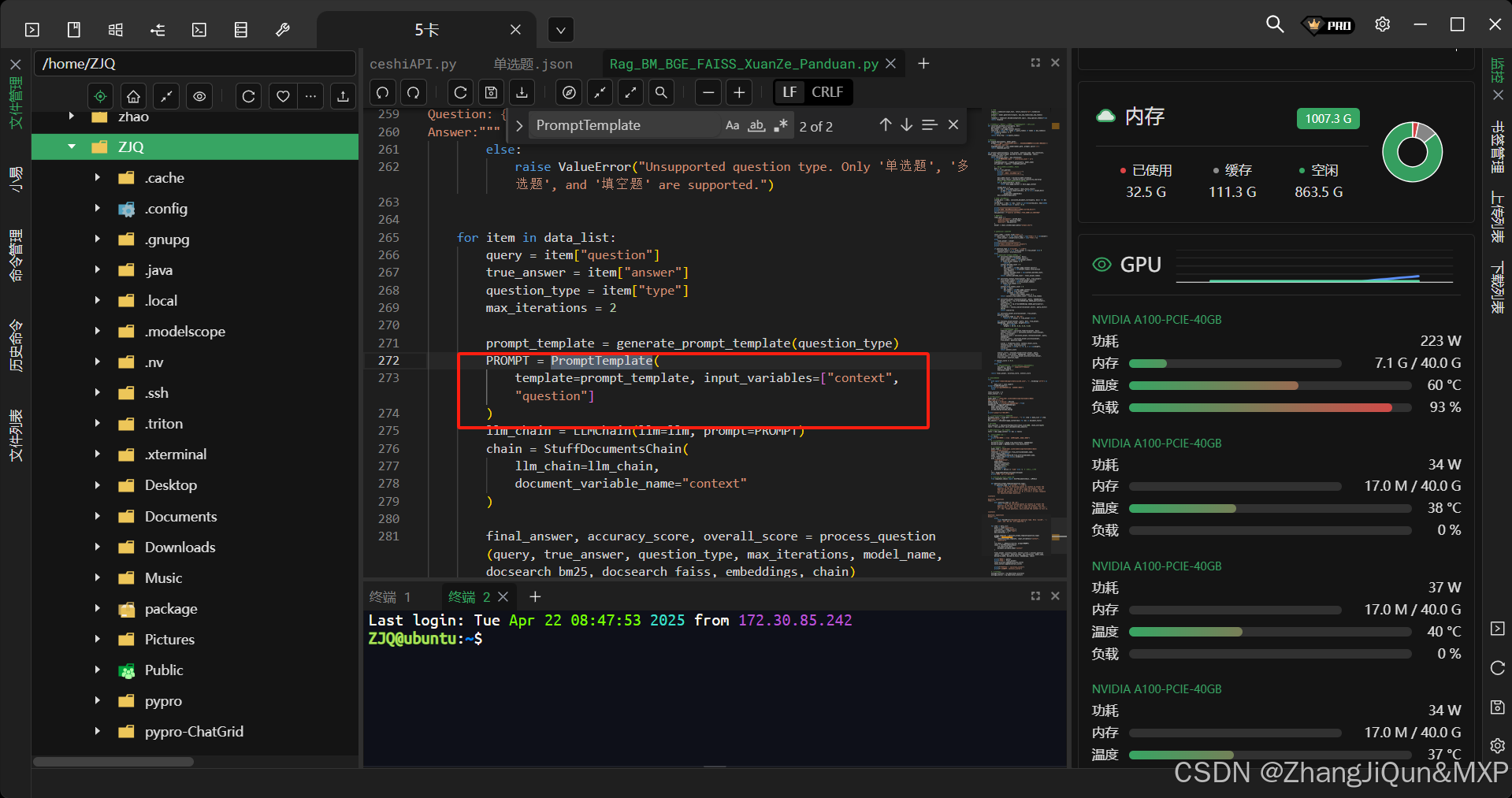
LLM中什么是模板定义、提示工程和文档处理链
LLM中什么是模板定义、提示工程和文档处理链 定义提示模板(prompt_template):prompt_template = """Use the following pieces of context to answer the question at the end. If you dont know the answer, just say that you dont know, dont try to make…...
密码学(二)流密码
2.1流密码的基本概念 流密码的基本思想是利用密钥 k 产生一个密钥流...,并使用如下规则对明文串 ... 加密:。密钥流由密钥流发生器产生: ,这里是加密器中的记忆元件(存储器)在时刻 i 的状态,…...
:垃圾回收器—CMS(图文+代码))
深度学习与总结JVM专辑(七):垃圾回收器—CMS(图文+代码)
CMS垃圾收集器深度解析教程 1. 前言:为什么需要CMS?2. CMS 工作原理:一场与时间的赛跑2.1. 初始标记(Initial Mark)2.2. 并发标记(Concurrent Mark)2.3. 重新标记(Remark)…...

力扣第446场周赛
有事没赶上, 赛后模拟了一下, 分享一下我的解题思路和做题感受 1.执行指令后的得分 题目链接如下:力扣 给你两个数组:instructions 和 values,数组的长度均为 n。 你需要根据以下规则模拟一个过程: 从下标 i 0 的第一个指令开…...

OpenCV中的透视变换方法详解
文章目录 引言1. 什么是透视变换2. 透视变换的数学原理3. OpenCV中的透视变换代码实现3.1 首先定义四个函数 3.1.1 cv_show() 函数 3.1.2 def resize() 函数 3.1.3 order_points() 函数 3.1.4 four_point_transform() 函数 3.2 读取图片并做预处理3.3 轮廓检测3.4 获取最大…...

并发设计模式实战系列(3):工作队列
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第三章工作队列(Work Queue),废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 生产者-消费者架构 …...
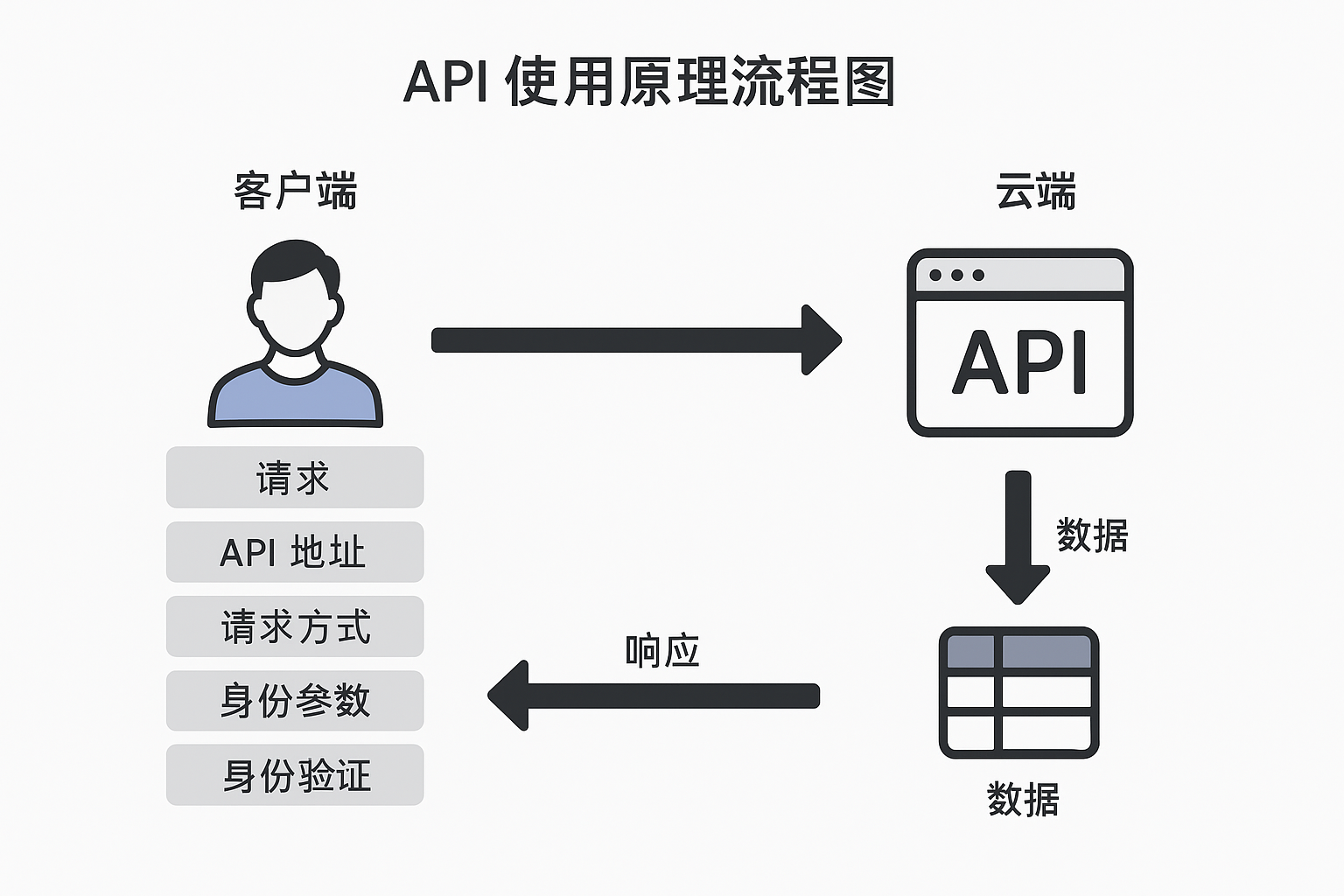
如何理解抽象且不易理解的华为云 API?
API的概念在华为云的使用中非常抽象,且不容易理解,用通俗的语言 形象的比喻来讲清楚——什么是华为云 API,怎么用,背后原理,以及主要元素有哪些,尽量让新手也能明白。 🧠 一句话先理解…...

10分钟二叉树的非递归排序完成
import java.util.Stack;public class test_04_23 {//二叉树的三种遍历static class TreeNode{int data;TreeNode left;TreeNode right;public TreeNode(int data){this.data data;}}//先序遍历public static void test1(TreeNode root){Stack<TreeNode> stack new Sta…...

[特殊字符]fsutil命令用法详解
🔧fsutil命令用法详解 以下是 fsutil 命令的常见用法及功能详解: 1. 基础语法 fsutil [子命令] [参数]2. 核心功能与用法 (1)管理硬链接 fsutil hardlink create <新硬链接路径> <原文件路径>作用:为文…...
详细介绍)
GPIO(通用输入输出端口)详细介绍
一、基本概念 GPIO(General - Purpose Input/Output)即通用输入输出端口,是微控制器(如 STM32 系列)中非常重要的一个外设。它是一种软件可编程的引脚,用户能够通过编程来控制这些引脚的输入或输出状态。在…...
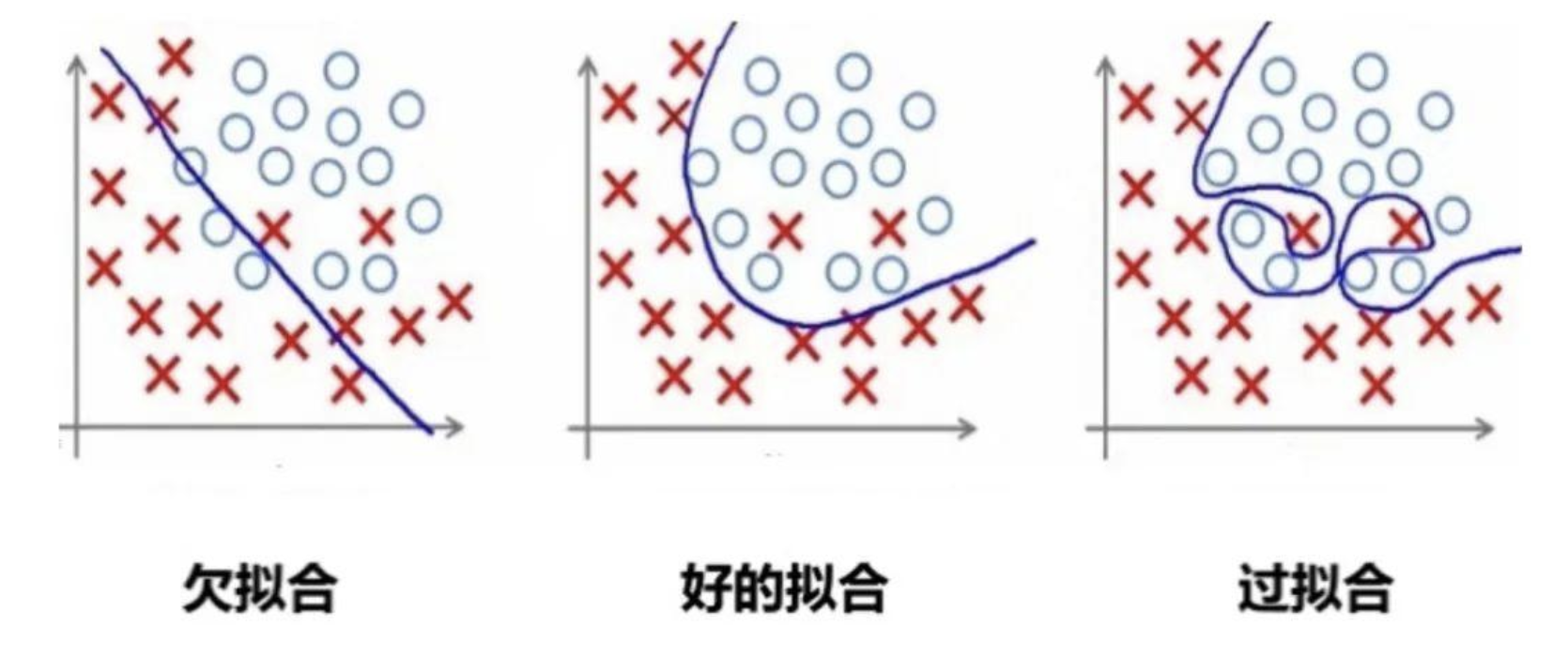
深度学习-全连接神经网络(过拟合,欠拟合。批量标准化)
七、过拟合与欠拟合 在训练深层神经网络时,由于模型参数较多,在数据量不足时很容易过拟合。而正则化技术主要就是用于防止过拟合,提升模型的泛化能力(对新数据表现良好)和鲁棒性(对异常数据表现良好)。 1. 概念认知 …...