从零开始构建微博爬虫:实现自动获取并保存微博内容
从零开始构建微博爬虫:实现自动获取并保存微博内容
前言
在信息爆炸的时代,社交媒体平台已经成为信息传播的重要渠道,其中微博作为中国最大的社交媒体平台之一,包含了大量有价值的信息和数据。对于研究人员、数据分析师或者只是想备份自己微博内容的用户来说,一个高效可靠的微博爬虫工具显得尤为重要。本文将详细介绍如何从零开始构建一个功能完善的微博爬虫,支持获取用户信息、爬取微博内容并下载图片。
项目概述
我们开发的微博爬虫具有以下特点:
- 功能全面:支持爬取用户基本信息、微博内容和图片
- 性能优化:实现了请求延迟、自动重试机制,避免被封IP
- 易于使用:提供简洁的命令行接口,支持多种参数配置
- 数据存储:支持CSV和JSON两种格式保存数据
- 容错机制:完善的错误处理,增强爬虫稳定性
- 自定义配置:通过配置文件灵活调整爬虫行为
技术选型
在构建微博爬虫时,我们使用了以下核心技术:
- Python:选择Python作为开发语言,其丰富的库和简洁的语法使爬虫开发变得简单高效
- Requests:处理HTTP请求,获取网页内容
- Pandas:数据处理和导出CSV格式
- tqdm:提供进度条功能,改善用户体验
- lxml:虽然本项目主要使用API接口,但保留XML解析能力以备扩展
- 正则表达式:用于清理HTML标签,提取纯文本内容
系统设计
架构设计
微博爬虫采用模块化设计,主要包含以下组件:
- 配置模块:负责管理爬虫的各种参数设置
- 爬虫核心:实现爬取逻辑,包括用户信息获取、微博内容爬取等
- 数据处理:清洗和结构化爬取到的数据
- 存储模块:将数据导出为不同格式
- 命令行接口:提供友好的用户交互界面
数据流程
整个爬虫的数据流程如下:
- 用户通过命令行指定爬取参数
- 爬虫初始化并请求用户信息
- 根据用户ID获取微博内容列表
- 解析响应数据,提取微博文本、图片URL等信息
- 根据需要下载微博图片
- 将处理后的数据保存到本地文件
实现细节
微博API分析
微博移动版API是我们爬虫的数据来源。与其使用复杂的HTML解析,直接调用API获取JSON格式的数据更为高效。我们主要使用了以下API:
- 用户信息API:
https://m.weibo.cn/api/container/getIndex?type=uid&value={user_id} - 用户微博列表API:
https://m.weibo.cn/api/container/getIndex?type=uid&value={user_id}&containerid={container_id}&page={page}
这些API返回的JSON数据包含了我们需要的所有信息,大大简化了爬取过程。
关键代码实现
1. 初始化爬虫
def __init__(self, cookie=None):"""初始化微博爬虫:param cookie: 用户cookie字符串"""self.headers = DEFAULT_HEADERS.copy()if cookie:self.headers['Cookie'] = cookieself.session = requests.Session()self.session.headers.update(self.headers)
使用requests.Session维持会话状态,提高爬取效率,同时支持传入cookie增强爬取能力。
2. 获取用户信息
def get_user_info(self, user_id):"""获取用户基本信息:param user_id: 用户ID:return: 用户信息字典"""url = API_URLS['user_info'].format(user_id)try:response = self.session.get(url)if response.status_code == 200:data = response.json()if data['ok'] == 1:user_info = data['data']['userInfo']info = {'id': user_info['id'],'screen_name': user_info['screen_name'],'followers_count': user_info['followers_count'],'follow_count': user_info['follow_count'],'statuses_count': user_info['statuses_count'],'description': user_info['description'],'profile_url': user_info['profile_url']}return inforeturn Noneexcept Exception as e:print(f"获取用户信息出错: {e}")return None
通过API获取用户的基本信息,包括昵称、粉丝数、关注数等。
3. 获取微博内容
def get_user_weibos(self, user_id, pages=10):"""获取用户的微博列表:param user_id: 用户ID:param pages: 要爬取的页数:return: 微博列表"""weibos = []container_id = f"{CONTAINER_ID_PREFIX}{user_id}"for page in tqdm(range(1, pages + 1), desc="爬取微博页数"):url = API_URLS['user_weibo'].format(user_id, container_id, page)# ... 请求和处理逻辑 ...
使用分页请求获取多页微博内容,并添加进度条提升用户体验。
4. 图片下载优化
def _get_large_image_url(self, url):"""将微博图片URL转换为大图URL"""# 常见的微博图片尺寸标识size_patterns = ['/orj360/', '/orj480/', '/orj960/', '/orj1080/', # 自适应尺寸'/thumb150/', '/thumb180/', '/thumb300/', '/thumb600/', '/thumb720/', # 缩略图'/mw690/', '/mw1024/', '/mw2048/' # 中等尺寸]# 替换为large大图result_url = urlfor pattern in size_patterns:if pattern in url:result_url = url.replace(pattern, '/large/')breakreturn result_url
微博图片URL通常包含尺寸信息,我们通过替换这些标识,获取原始大图。
容错和优化
在实际爬取过程中,我们实现了多种优化机制:
- 请求延迟:在每次请求之间添加延迟,避免请求过快被限制
- 自动重试:下载失败时自动重试,提高成功率
- 异常处理:捕获并处理各种异常情况,确保爬虫稳定运行
- 图片格式识别:自动识别图片格式,正确保存文件
- 进度显示:使用tqdm提供进度条,直观显示爬取进度
使用指南
安装与配置
- 克隆项目并安装依赖:
git clone https://github.com/yourusername/weibo-spider.git
cd weibo-spider
pip install -r requirements.txt
- 基本使用方法:
python main.py -u 用户ID
- 高级选项:
# 使用cookie增强爬取能力
python main.py -u 用户ID -c "你的cookie字符串"# 自定义爬取页数
python main.py -u 用户ID -p 20# 下载微博图片
python main.py -u 用户ID --download_images# 指定输出格式
python main.py -u 用户ID --format json
目标网页:
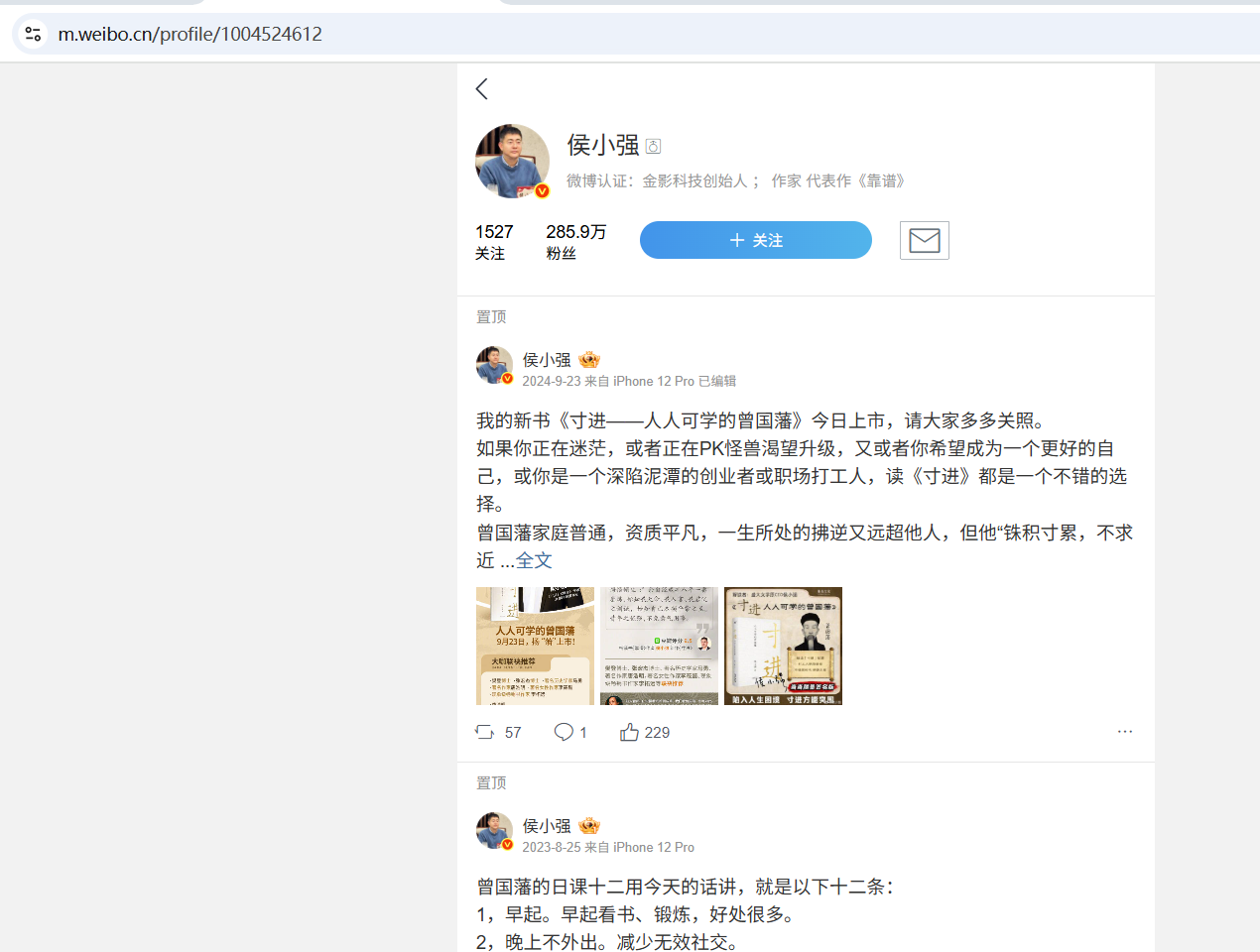
爬取结果数据:

技术挑战与解决方案
1. 反爬虫机制应对
微博有一定的反爬虫机制,主要体现在请求频率限制和内容访问权限上。我们通过以下方式解决:
- 添加合理的请求延迟,避免频繁请求
- 支持传入cookie增强权限
- 实现错误重试机制,提高稳定性
2. 图片防盗链问题
微博图片设有防盗链机制,直接访问可能返回403错误。解决方案:
- 解析并转换图片URL,获取原始链接
- 在请求头中添加正确的Referer和User-Agent
- 实现多次重试,应对临时失败
3. 数据清洗
微博内容包含大量HTML标签和特殊格式,需要进行清洗:
- 使用正则表达式去除HTML标签
- 规范化时间格式
- 结构化处理图片链接
未来改进方向
- 增加代理支持:支持代理池轮换,进一步避免IP限制
- 扩展爬取内容:支持爬取评论、转发等更多内容
- 增加GUI界面:开发图形界面,提升用户体验
- 数据分析功能:集成基础的统计分析功能
- 多线程优化:实现多线程下载,提高爬取效率
结语
本文详细介绍了一个功能完善的微博爬虫的设计与实现过程。通过这个项目,我们不仅实现了微博内容的自动获取和保存,也学习了爬虫开发中的各种技术要点和最佳实践。希望这个项目能对有类似需求的读者提供帮助和启发。
微博爬虫是一个既简单又有挑战性的项目,它涉及到网络请求、数据解析、异常处理等多个方面。通过不断的优化和改进,我们可以构建出越来越强大的爬虫工具,为数据分析和研究提供可靠的数据来源。
源码获取链接:源码
声明:本项目仅供学习和研究使用,请勿用于商业目的或违反微博用户隐私和服务条款的行为。使用本工具时请遵守相关法律法规,尊重他人隐私权。
相关文章:
从零开始构建微博爬虫:实现自动获取并保存微博内容
从零开始构建微博爬虫:实现自动获取并保存微博内容 前言 在信息爆炸的时代,社交媒体平台已经成为信息传播的重要渠道,其中微博作为中国最大的社交媒体平台之一,包含了大量有价值的信息和数据。对于研究人员、数据分析师或者只是…...

Git -> Git 所有提交阶段的回滚操作
已经修改但没有暂存的回滚 修改状态单个文件所有文件说明已修改未暂存git checkout -- 文件路径git checkout -- .丢弃工作区修改 已经暂存但没有提交的回滚 修改状态单个文件所有文件说明已暂存未提交git reset HEAD 文件路径 -> git checkout -- 文件路径git reset HEA…...

三餐四季、灯火阑珊
2025年4月22日,15~28℃,挺好的 待办: 教学技能大赛教案(2025年4月24日,校赛,小组合作,其他成员给力,暂不影响校赛进度,搁置) 教学技能大赛PPT(202…...

【Java面试笔记:基础】8.对比Vector、ArrayList、LinkedList有何区别?
在Java中,Vector、ArrayList和LinkedList均实现了List接口,但它们在线程安全、数据结构、性能特性及应用场景上存在显著差异。 1. Vector、ArrayList 和 LinkedList 的区别 Vector: 线程安全:Vector 是线程安全的动态数组&#…...

麒麟V10安装MySQL8.4
1、下载安装包 wget https://cdn.mysql.com//Downloads/MySQL-8.4/mysql-8.4.5-1.el7.x86_64.rpm-bundle.tar2、解压 mkdir -p /opt/mysql tar -xvf mysql-8.4.5-1.el7.x86_64.rpm-bundle.tar -C /opt/mysql3、安装MySQL 3.1、卸载mariadb rpm -qa | grep mariadb rpm -e m…...
基于javaweb的SSM+Maven教材管理系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...
:C 语言数组详解)
C语言教程(十二):C 语言数组详解
一、引言数组的基本概念 数组是一组具有相同数据类型的元素的集合,这些元素在内存中连续存储。通过一个统一的数组名和下标来访问数组中的每个元素。使用数组可以方便地处理大量相同类型的数据,避免为每个数据单独定义变量。 二、一维数组 2.1 数组的…...

osxcross 搭建 macOS 交叉编译环境
1. osxcross 搭建 macOS 交叉编译环境 1. osxcross 搭建 macOS 交叉编译环境 1.1. 安装依赖1.2. 安装 osxcross 及 macOS SDK 1.2.1. 可能错误 1.3. 编译 cmake 类工程1.4. 编译 configure 类工程1.5. 单文件编译及其他环境编译1.6. 打包成 docker 镜像1.7. 使用 docker 编译 …...

Zookeeper 概述
Zookeeper 概述 Zookeeper 概述与使用指南什么是Zookeeper?Zookeeper的主要作用使用Zookeeper的框架典型使用场景1. 配置管理2. 分布式锁3. 服务注册与发现 Zookeeper的缺陷与其他协调服务的比较实际案例:Kafka使用Zookeeper最佳实践 Zookeeper 概述与使…...

智能座舱测试内容与步骤
智能座舱的测试步骤通常包括以下环节: 1.测试环境搭建与准备 • 硬件需求分析:准备测试车辆、服务器与工作站、网络设备以及传感器和执行器模拟器等硬件设备。 • 软件需求分析:选择测试管理软件、自动化测试工具、模拟软件和开发调试工具等。…...
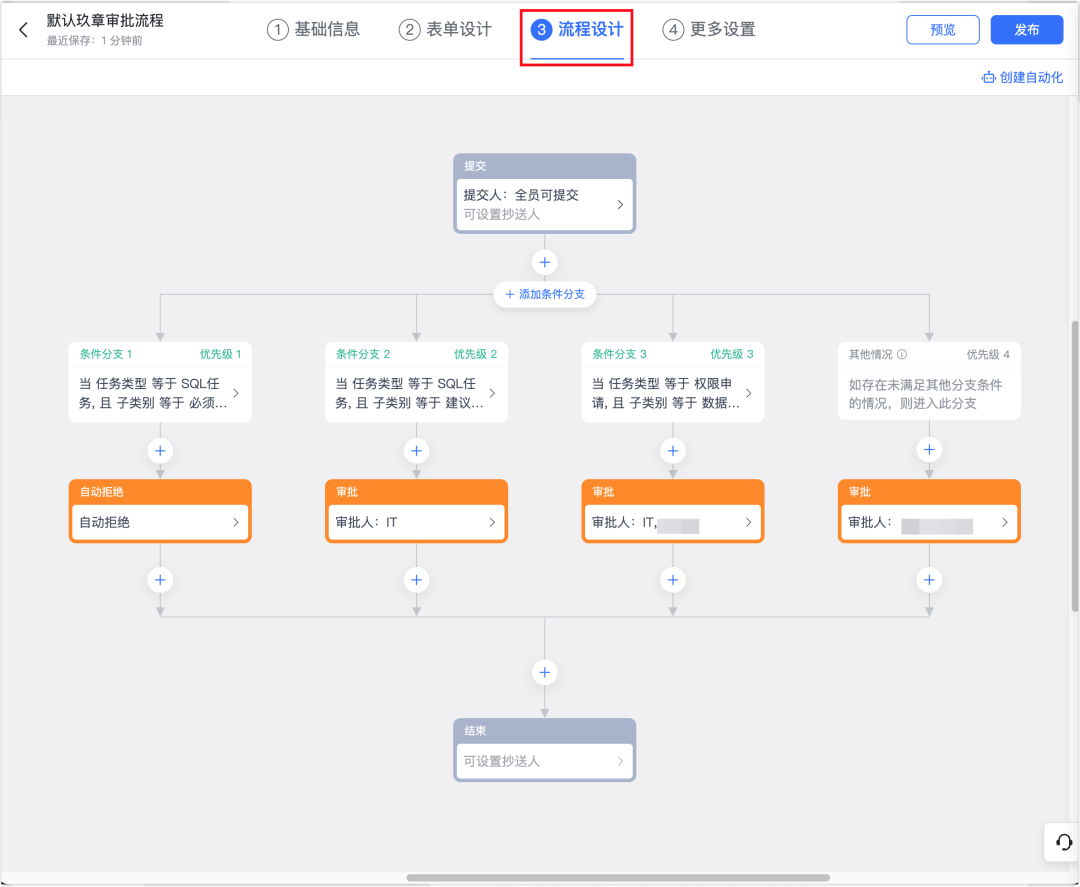
NineData 与飞书深度集成,企业级数据管理审批流程全面自动化
NineData 正式推出与飞书审批系统的深度集成功能,企业用户在 NineData 平台发起的审批工单,将自动推送至审批人的飞书中,审批人可以直接在飞书进行审批并通过/拒绝。该功能实现跨系统协作,带来巨大的审批效率提升,为各…...
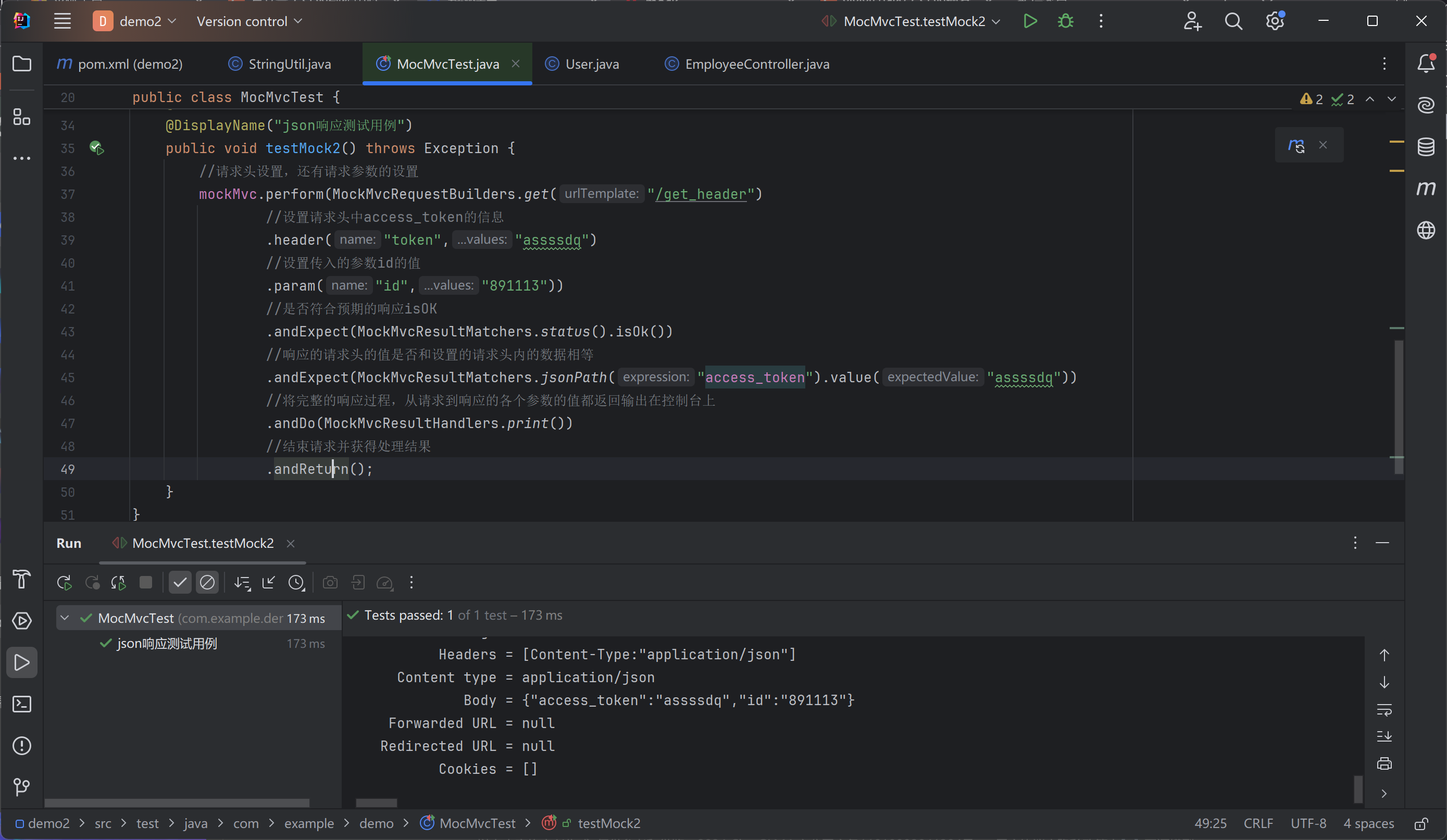
mockMvc构建web单元测试学习笔记
web应用本来需要依靠tomcat这个环境运行 现在用mockMvc是为了模拟这个web环境,简化测试 什么是mock(模拟) 模拟对象---mock object是以可控方式模拟真实对象行为的假对象,通过模拟输入数据,验证程序达到预期结果 为什么使用mock对象 因为…...

【白雪讲堂】[特殊字符]内容战略地图|GEO优化框架下的内容全景布局
📍内容战略地图|GEO优化框架下的内容全景布局 1️⃣ 顶层目标:GEO优化战略 目标关键词: 被AI理解(AEO) 被AI优先推荐(GEO) 在关键场景中被AI复读引用 2️⃣ 三大引擎逻辑&#x…...
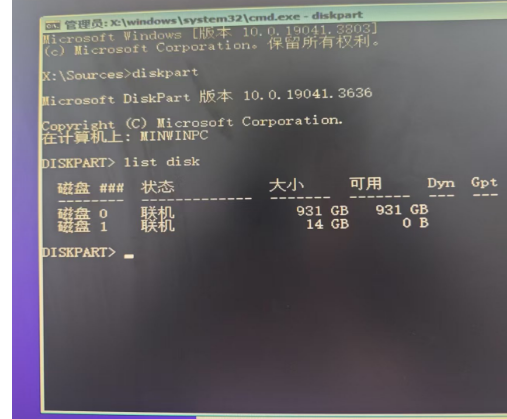
Windows7升级Windows10,无法在此驱动器上安装Windows
一、现象描述 台式机工作站,从Windows7升级Windows10,采用MediaCreationTool_22H2制作U盘启动盘,安装系统遇到问题如下: 二、原因分析 是由于硬盘格式不是GPT硬盘,而Windows系统只能安装到GPT硬盘上,所以…...

Element Plus表格组件深度解析:构建高性能企业级数据视图
一、架构设计与核心能力 Element Plus的表格组件(el-table)基于Vue 3的响应式系统构建,通过声明式配置实现复杂数据渲染。其核心设计理念体现在三个层级: 数据驱动:通过data属性绑定数据源,支持动态更新与…...
Idea创建项目的搭建
1、普通java项目 如果没有project SDK去new,默认在C:\Program Files\Java\jdk1.8.0_261 输入项目名称和项目路径 点击完成,即创建好一个普通的Java项目。 2、普通JavaWEB项目 目录中没有WEB-INF文件可以直接从tomcat中粘贴过来 D:\apache-tomcat-8.5.…...

drupal7可以从测试环境一键部署到生产环境吗
Drupal 7 本身并没有“内建的一键部署功能”,所以“从测试环境一键部署到生产环境”不能完全自动化完成,尤其是涉及数据库、配置和文件系统时。但你可以通过一些工具和方法实现接近“一键部署”的效果 ✅ 🚧 为什么不能直接一键部署ÿ…...

Springboot 集成 RBAC 模型实战指南
RBAC 模型核心原理 详情可参考之前的笔记:https://blog.csdn.net/qq_35201802/article/details/146036789?spm1011.2415.3001.5331 RBAC 定义与优势 RBAC(Role-Based Access Control,基于角色的访问控制)** 是一种通过角色关联…...
系列专题 (四) KWDB核心概念解析:多模、时序与分布式)
KWDB 创作者计划 KWDB(KaiwuDB)系列专题 (四) KWDB核心概念解析:多模、时序与分布式
KWDB核心概念解析:多模、时序与分布式 1. 引言 KWDB(KaiwuDB)作为一款面向AIoT(人工智能物联网)的分布式多模数据库,以其独特的多模融合设计、高效时序处理能力和灵活的分布式架构,满足了物联网场景下复杂数据管理的需求。要深入掌握KWDB,理解其三大核心概念——多模…...

GpuGeek:以弹性算力与全栈服务赋能产业智能升级
在人工智能技术快速融入各领域的趋势下,企业对高效、低成本的AI基础设施需求日益迫切。GpuGeek作为一站式AI基础设施平台,凭借其弹性算力调度、全流程开发支持、全球化资源覆盖以及国产化技术适配四大核心优势,为产业智能化升级提供了坚实的技…...

C语言main的参数;argc与argv
目录 前言 什么是命令行参数 argc与argv argc (Argument Count) argv (Argument Vector) 示例 前言 在C语言中,main函数的标准形式通常有两种: int main(void)int main(int argc, char *argv[]) 其中,argc 和 argv 是用于处理命令行参数…...

C++_并发编程_thread_01_基本应用
👋 Hi, I’m liubo👀 I’m interested in harmony🌱 I’m currently learning harmony💞️ I’m looking to collaborate on …📫 How to reach me …📇 sssssdsdsdsdsdsdasd🎃 dsdsdsdsdsddfsg…...

网络原理 - 4(TCP - 1)
目录 TCP 协议 TCP 协议段格式 可靠传输 几个 TCP 协议中的机制 1. 确认应答 2. 超时重传 完! TCP 协议 TCP 全称为 “传输控制协议”(Transmission Control Protocol),要对数据的传输进行一个详细的控制。 TCP 协议段格…...
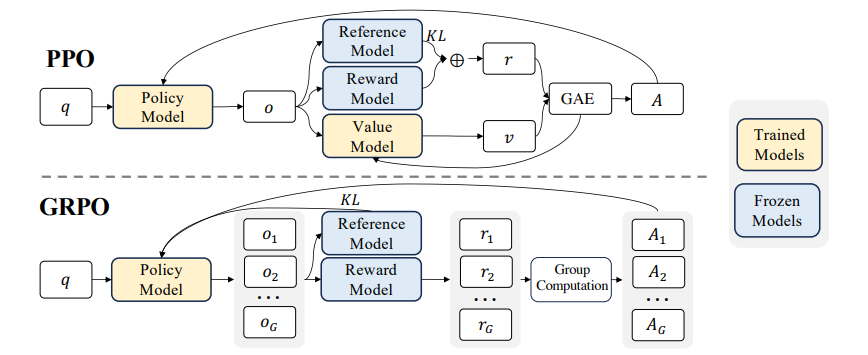
强化学习框架:OpenRLHF源码解读,模型处理
本文主要介绍 强化学习框架:OpenRLHF源码解读,模型处理 models框架设计 了解一下 OpenRLHF的模型框架设计范式: From:https://arxiv.org/pdf/2405.11143 可以知道一个大概的流程:输入Pormpt通过Actor model输出回复 Response&am…...
STL常用算法——C++
1.概述 2.常用遍历算法 1.简介 2.for_each 方式一:传入普通函数(printf1) #include<stdio.h> using namespace std; #include<string> #include<vector> #include<functional> #include<algorithm> #include…...

UofTCTF-2025-web-复现
感兴趣朋友可以去我博客里看,画风更好看 UofTCTF-2025-web-复现 文章目录 scavenger-huntprismatic-blogscode-dbprepared-1prepared-2timeless scavenger-hunt 国外的一些ctf简单题就喜欢把flag藏在注释里,开源代码找到第一部分的flag 抓个包返回数据…...

Ruby 正则表达式
Ruby 正则表达式 引言 正则表达式(Regular Expression,简称Regex)是一种强大的文本处理工具,在编程和数据处理中有着广泛的应用。Ruby 作为一种动态、灵活的编程语言,同样内置了强大的正则表达式功能。本文将详细介绍…...

[密码学基础]GB与GM国密标准深度解析:定位、差异与协同发展
[密码学基础]GB与GM国密标准深度解析:定位、差异与协同发展 导语 在国产密码技术自主可控的浪潮下,GB(国家标准)与GM(密码行业标准)共同构建了我国商用密码的技术规范体系。二者在制定主体、法律效力、技术…...

代理设计模式:从底层原理到源代码 详解
代理设计模式(Proxy Pattern)是一种结构型设计模式,它通过创建一个代理对象来控制对目标对象的访问。代理对象充当客户端和目标对象之间的中介,允许在不修改目标对象的情况下添加额外的功能(如权限控制、日志记录、延迟…...

15.第二阶段x64游戏实战-分析怪物血量(遍历周围)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:14.第二阶段x64游戏实战-分析人物的名字 如果想实现自动打怪,那肯定…...