Spark两种运行模式与部署
1. Spark 的运行模式
部署Spark集群就两种方式,单机模式与集群模式
单机模式就是为了方便开发者调试框架的运行环境。但是生产环境中,一般都是集群部署。
现在Spark目前支持的部署模式:
(1)Local模式:在本地部署单个Spark服务
(2)Standalone模式:Spark自带的任务调度模式
(3)Yarn模式:Spark使用Hadoop的YARN组件进行资源与任务调度。
(4)Mesos模式:Spark使用Mesos平台进行资源与任务的调度。
如果资源是当前节点提供的就是单机模式,
如果资源是当前多个节点提供的就是集群模式/分布式模式,
如果资源是Yarn管理的就是Yarn部署环境(这个用的多)
如果资源是由Spark自己管理的就是Spark部署环境
2.Spark 的安装
下载地址:
1)官网地址:http://spark.apache.org/
2)文档查看地址:Redirecting…
3)下载地址:https://spark.apache.org/downloads.html
https://archive.apache.org/dist/spark/
2.1 Local 模式
1) 上传本地Spark的安装包并解压
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/这时候我们就把我们的环境安装好了
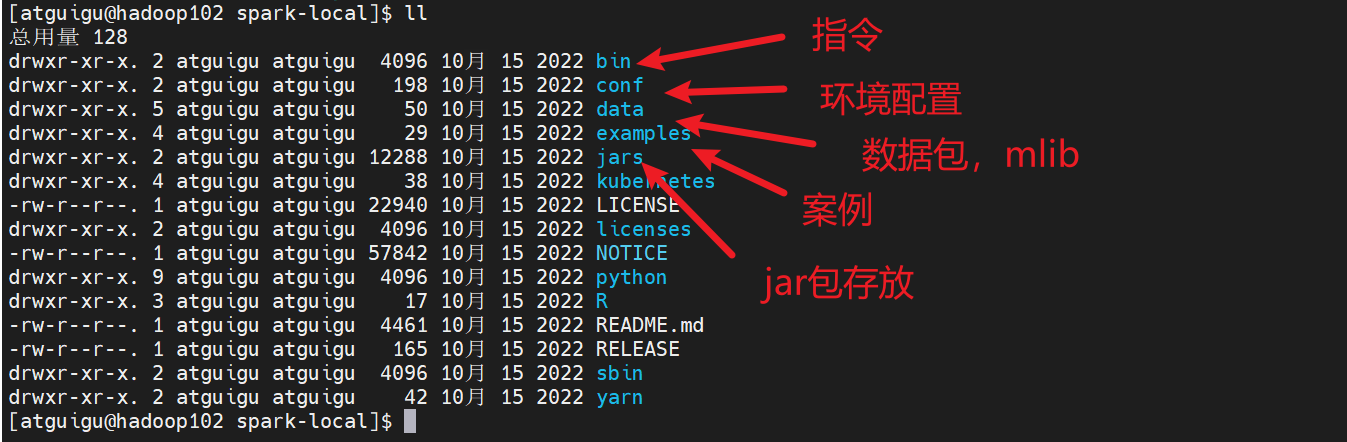
这时候我们要去运行一个案例试一下,看看能不能跑起来
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10解释
--class 表示要执行的主类
--master local[2]
1)local:没有指定线程数,则就是单线程执行
2)local [K]:指定使用K个core来运行计算,比如local[2]就是运行两个2个Core来执行。
3) local[*]: 帮你按照当前最多核心数去运行。
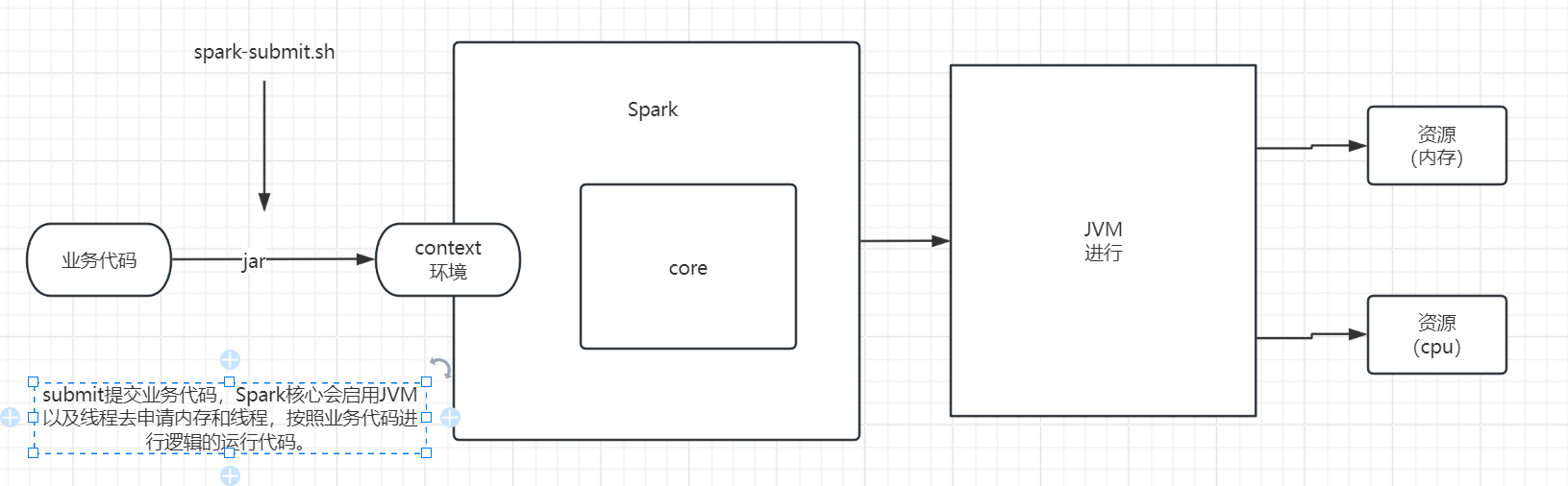 以上过程可以简化为,运行业务代码,启动进程,申请资源,执行计算,终止进程,资源释放。
以上过程可以简化为,运行业务代码,启动进程,申请资源,执行计算,终止进程,资源释放。
我们如何看到这个运行的过程呢?
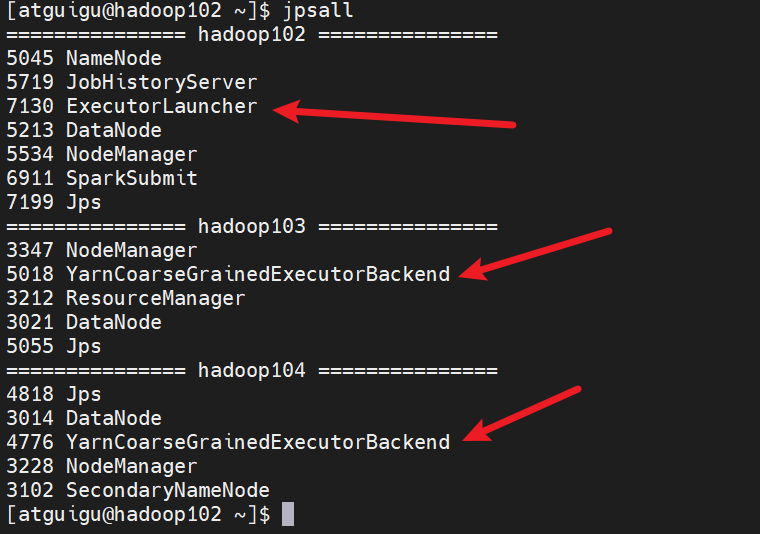
我们可以在Spark运行的时候,另一个行命令行窗口输入jps查看正在运行的进程。
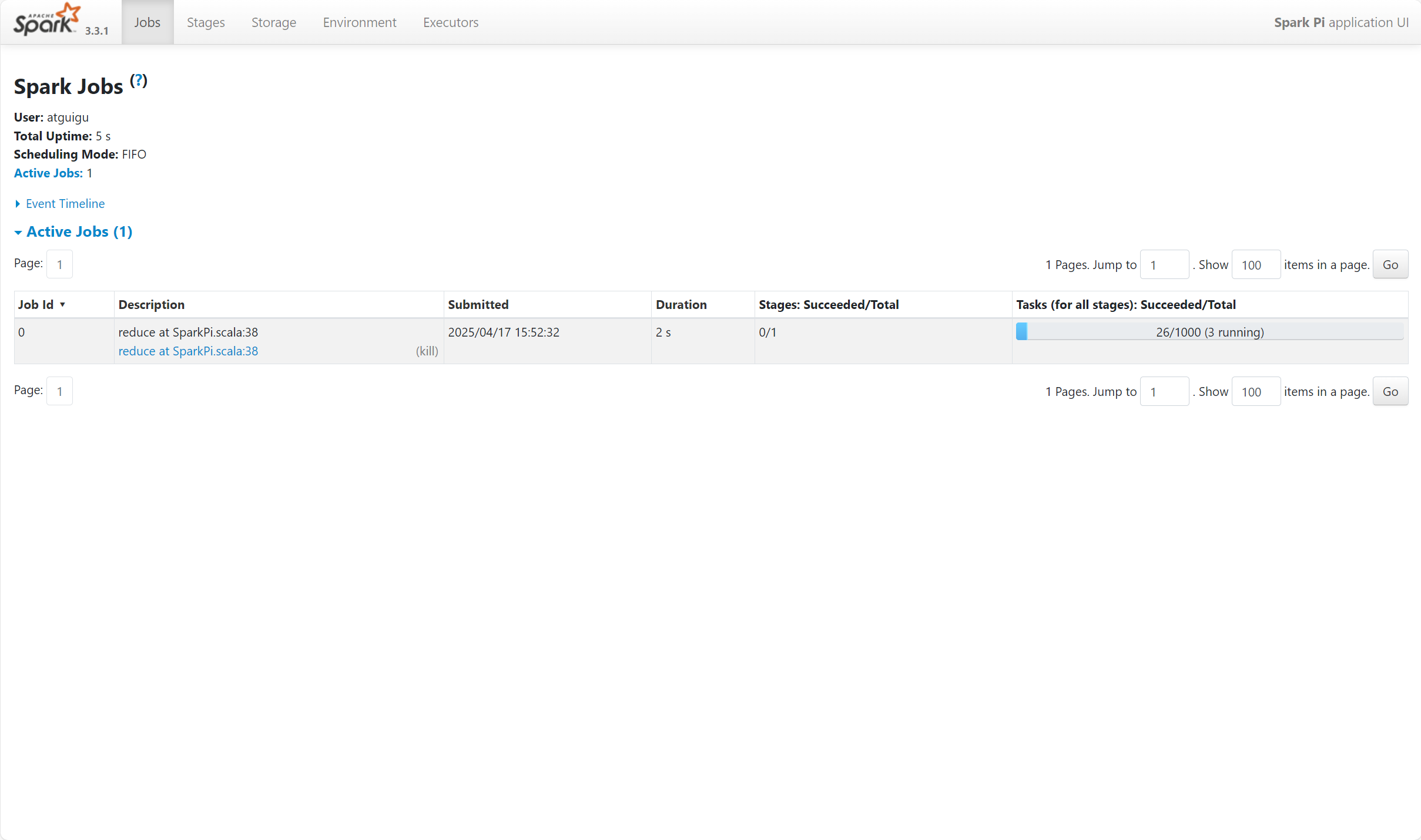
如果我们还想看一些比较详细的信息,可以在【主机名:4040】中查看正在运行的任务,想用这个查看提交的任务,必须保证有spark正在运行。
2.2 Yarn模式
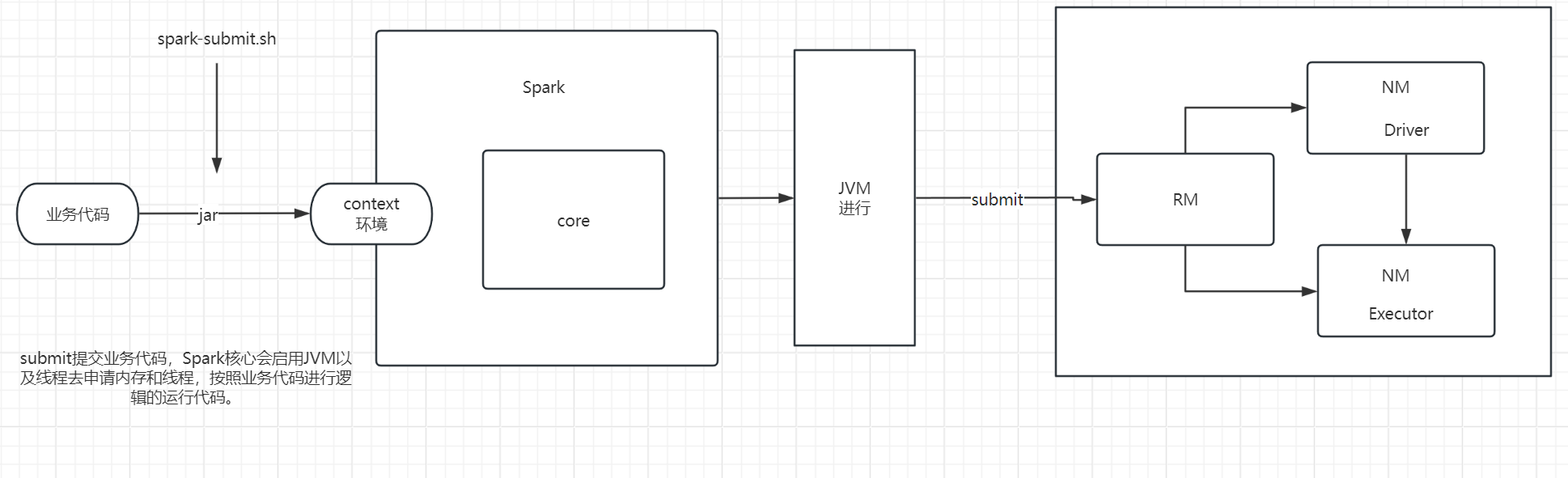
yarn模式就是由本地启动一个进程去提交一个任务给Yarn,然后Yarn分配给资源去运行
部署Yarn模式的步骤
1. 解压Spark
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/2. 进入到/opt/module, 修改目录名 spark-3.3.1-bin-hadoop3 为spark-yarn
3. 修改hadoop配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml,添加如下内容
vim yarn-site.xml<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4. 分发配置文件
xsync /opt/module/hadoop/etc/hadoop/yarn-site.xml5. 修改/opt/module/spark-yarn/conf/spark-env.sh,添加了YARN_CONF_DIR配置,保证就是能找到yarn位置
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop (需要改成自己对应的配置地址)
6. 启动HDFS集群和YARN集群
sbin/start-dfs.sh
sbin/start-yarn.sh7. 然后执行一下上面的那个案例
看看与local模式有什么不同
能看到和上图中的driver对应起来了
ExecutorLauncher--》driver
YarnCoarseGrainedExecutorBackend--》executor
2.3 配置历史服务配置
1)修改spark-default.conf.template名称
mv spark-defaults.conf.template spark-defaults.conf2)修改spark-default.conf文件,配置日志存储路径
vim spark-defaults.confspark.eventLog.enabled true
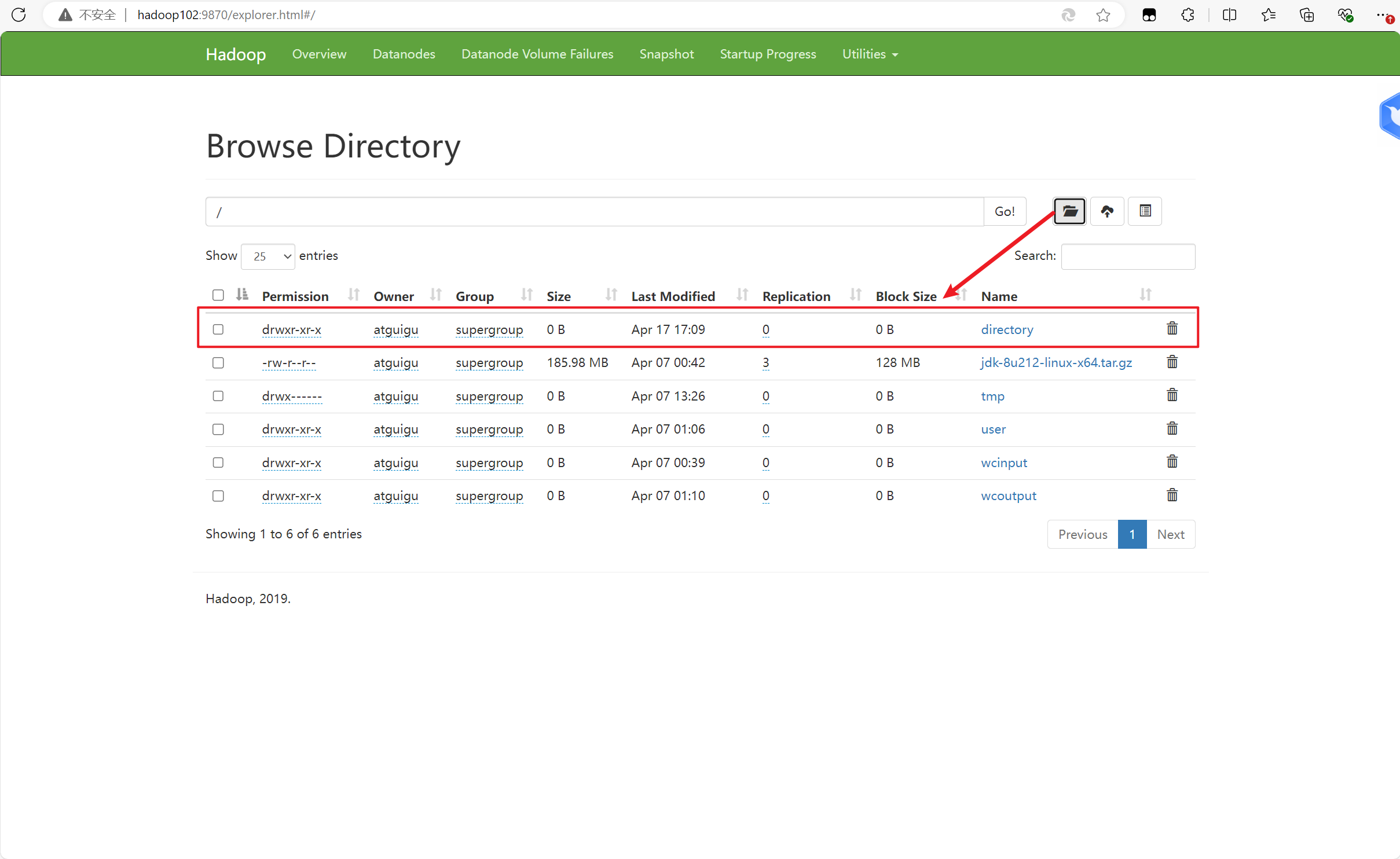
spark.eventLog.dir hdfs://hadoop102:8020/directory
然后去hadoop102:9870里创建一个新的文件directory
3)修改spark-env.sh文件,添加如下配置:
vim spark-env.shexport SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"
# 参数1含义:WEBUI访问的端口号为18080
# 参数2含义:指定历史服务器日志存储路径(读)
# 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
配置查看历史日志
为了能从Yarn上关联到Spark历史服务器,需要配置spark历史服务器关联路径。
1)修改配置文件/opt/module/spark-yarn/conf/spark-defaults.conf
添加如下内容:
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080
2)重启Spark历史服务
sbin/stop-history-server.sh
sbin/start-history-server.sh 3)提交任务到Yarn执行
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10
4)Web页面查看日志:http://hadoop103:8088/cluster
然后点击页面的history就能跳转到http:hadoop102:18080/
相关文章:
Spark两种运行模式与部署
1. Spark 的运行模式 部署Spark集群就两种方式,单机模式与集群模式 单机模式就是为了方便开发者调试框架的运行环境。但是生产环境中,一般都是集群部署。 现在Spark目前支持的部署模式: (1)Local模式:在本地…...

react 父子组件通信 子 直接到父, 父 forwardref子
React核心概念:单向数据流(Unidirectional Data Flow) React 中数据的流动像瀑布一样,只能从上层组件(父组件)流向下层组件(子组件)。 子组件无法直接反向修改父组件的数据&#x…...

qt画一朵花
希望大家的生活都更加美好,画一朵花送给大家 效果图 void FloatingArrowPubshButton::paintEvent(QPaintEvent *event) {QPainter painter(this);painter.setRenderHints(QPainter::Antialiasing);QPen pen;pen.setColor("green");pen.setWidth(5);QBrush…...
服务器上安装maven
1.安装 下载安装包 https://maven.apache.org/download.cgi 解压安装包 cd /opt/software tar -xzvf apache-maven-3.9.9-bin.tar.gz 安装目录(/opt/maven/) mv /opt/software/apache-maven-3.9.9 /opt/ 3.权限设置 把/opt/software/apache-maven-3.9.9 文件夹重命名为ma…...
UOS+N 卡 + CUDA 环境下 X86 架构 DeepSeek 基于 vLLM 部署与 Dify 平台搭建指南
一、文档说明 本文档是一份关于 DeepSeek 在X86架构下通vLLM工具部署的操作指南,主要面向需要在UOSN卡CUDA环境中部署DeepSeek的技术人员,旨在指导文档使用者完成从 Python 环境升级、vLLM 库安装、模型部署到 Dify 平台搭建的全流程操作。 二、安装Pyt…...

MySQL终章(8)JDBC
目录 1.前言 2.正文 2.1JDBC概念 2.2三种编码方式 2.2.1第一种 2.2.2第二种(优化版) 2.2.3第三种(更优化版) 3.小结 1.前言 哈喽大家好吖,今天来给大家带来Java中的JDBC的讲解,之前学习的都是操作…...

点云数据处理开源C++方案
一、主流开源库对比 库名称特点适用场景开源协议活跃度PCL功能最全,算法丰富科研、工业级应用BSD★★★★★Open3D现代API,支持Python绑定快速开发、深度学习MIT★★★★☆CGAL计算几何算法强大网格处理、高级几何运算GPL/LGPL★★★☆☆PDAL专注于点云…...

Python 爬虫如何伪装 Referer?从随机生成到动态匹配
一、Referer 的作用与重要性 Referer 是 HTTP 请求头中的一个字段,用于标识请求的来源页面。它在网站的正常运行中扮演着重要角色,例如用于统计流量来源、防止恶意链接等。然而,对于爬虫来说,Referer 也可能成为被识别为爬虫的关…...

【MySQL】表的约束(主键、唯一键、外键等约束类型详解)、表的设计
目录 1.数据库约束 1.1 约束类型 1.2 null约束 — not null 1.3 unique — 唯一约束 1.4 default — 设置默认值 1.5 primary key — 主键约束 自增主键 自增主键的局限性:经典面试问题(进阶问题) 1.6 foreign key — 外键约束 1.7…...

基于STC89C52RC和8X8点阵屏、独立按键的小游戏《打砖块》
目录 系列文章目录前言一、效果展示二、原理分析三、各模块代码1、8X8点阵屏2、独立按键3、定时器04、定时器1 四、主函数总结 系列文章目录 前言 用的是普中A2开发板,外设有:8X8LED点阵屏、独立按键。 【单片机】STC89C52RC 【频率】12T11.0592MHz 效…...
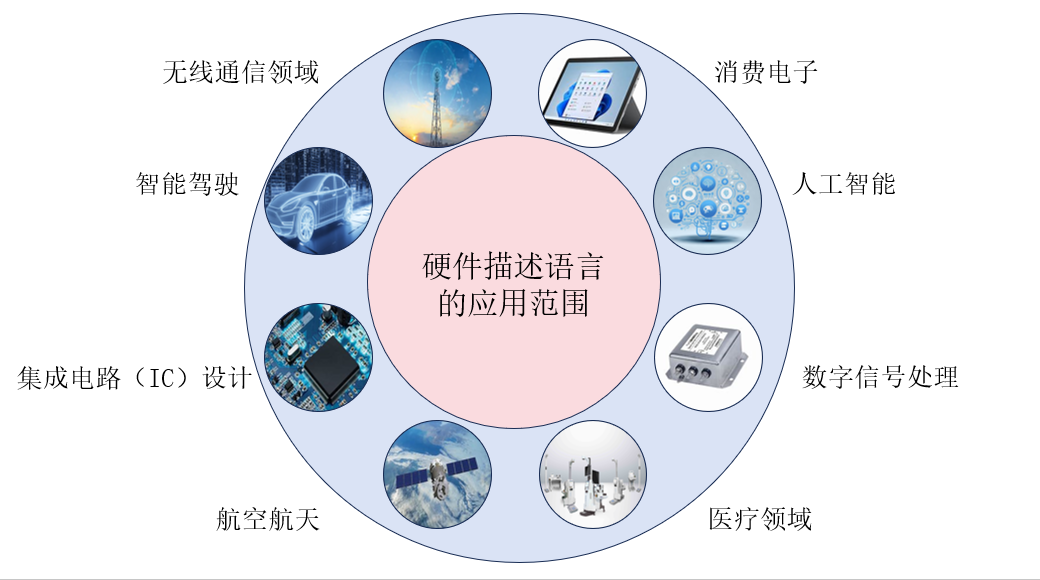
数字电子技术基础(五十)——硬件描述语言简介
目录 1 硬件描述语言简介 1.1 硬件描述语言简介 1.2 硬件编程语言的发展历史 1.3 两种硬件描述的比较 1.4 硬件描述语言的应用场景 1.5 基本程序结构 1.5.1 基本程序结构 1.5.2 基本语句和描述方法 1.5.3 仿真 1 硬件描述语言简介 1.1 硬件描述语言简介 硬件描述语…...
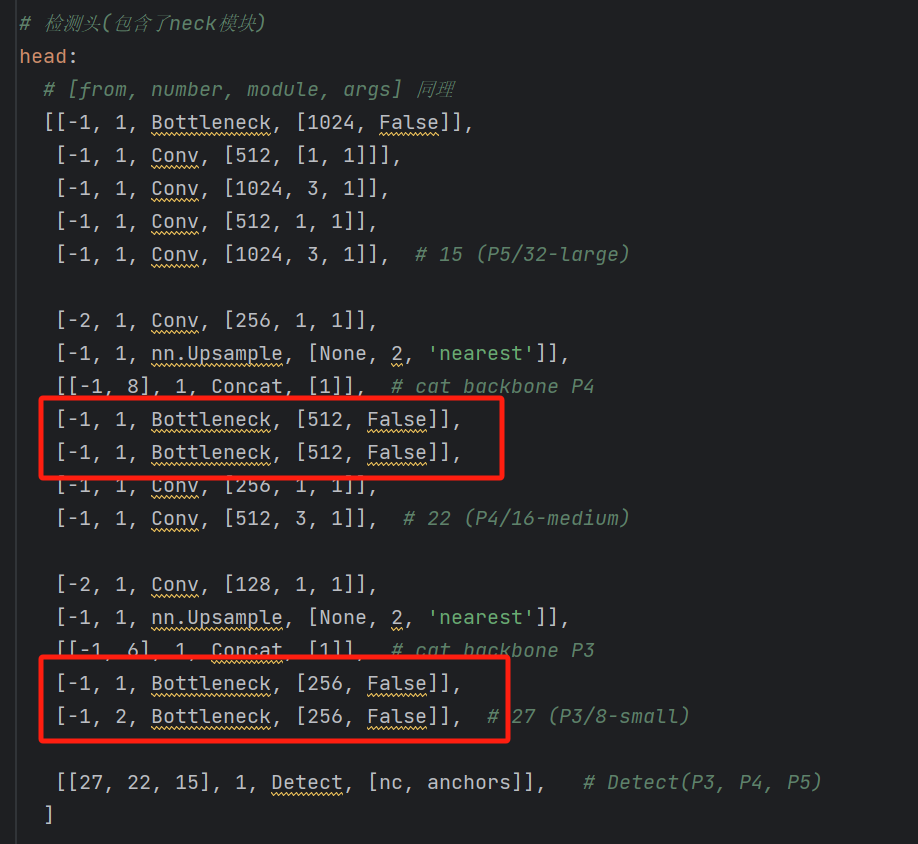
【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读
【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读 文章目录 【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读前言autopad函数Conv类__init__成员函数forward成员函数forward_fuse成员函数 Bottleneck类__init__成员…...
16.Chromium指纹浏览器开发教程之WebGPU指纹定制
WebGPU指纹概述 WebGPU是下一代的Web图形和计算API,旨在提供高性能的图形渲染和计算能力。它是WebGL的后继者,旨在利用现代GPU的强大功能,使得Web应用能够实现接近原生应用的图形和计算性能。而且它是一个低级别的API,可以直接与…...

示例:spring 纯xml配置
以下是一个完整的 纯 XML 配置开发示例,涵盖 DAO、Service、Controller 层,通过 Spring XML 配置实现依赖注入和事务管理,无需任何注解。 1. 项目结构 src/main/java ├── com.example.dao │ └── UserDao.java # DAO 接口…...
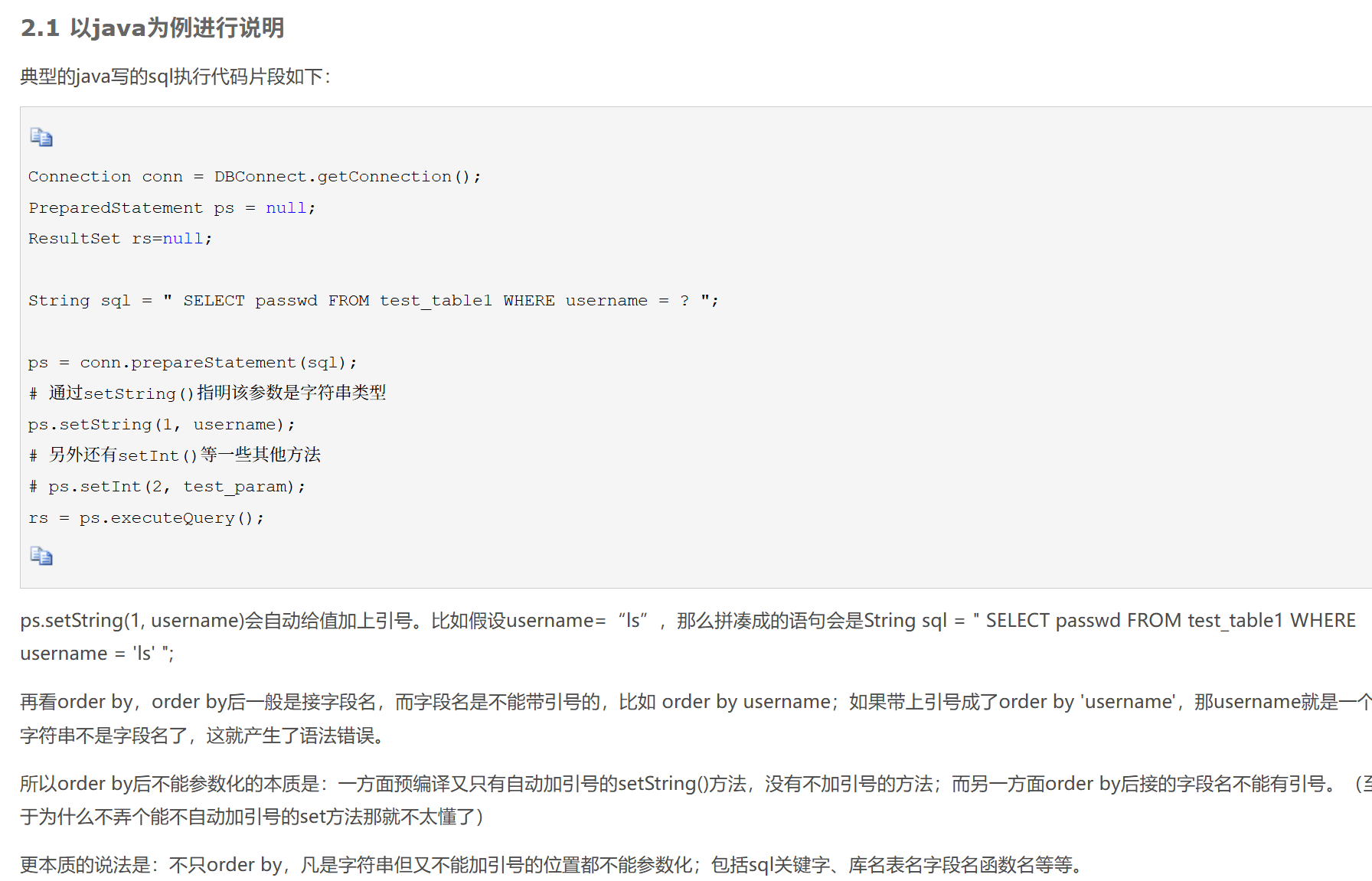
SQL预编译——预编译真的能完美防御SQL注入吗
SQL注入原理 sql注入是指攻击者拼接恶意SQL语句到接受外部参数的动态SQL查询中,程序本身 未对插入的SQL语句进行过滤,导致SQL语句直接被服务端执行。 拼接的SQL查询例如,通过在id变量后插入or 11这样的条件,来绕过身份验证&#…...

系统架构师2025年论文《论基于UML的需求分析》
论基于构件的软件开发 摘要: 2011 年 3 月,我有幸参加了某市医院预约挂号系统项目的开发工作,并担任系统架构师一职,负责系统的架构设计及核心构件的开发工作。该项目是某市医院为提升患者就医体验、优化挂号流程而委托开发的,项目于 2011 年底验收,满足了医院及患者提…...
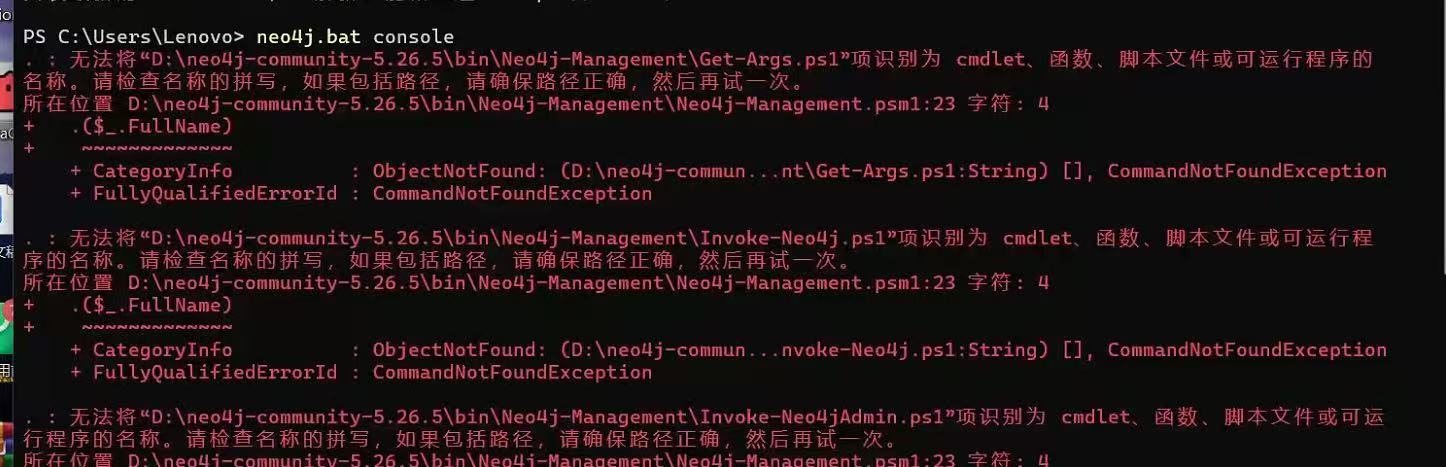
运行neo4j.bat console 报错无法识别为脚本,PowerShell 教程:查看语言模式并通过注册表修改受限模式
无法将“D:\neo4j-community-4.4.38-windows\bin\Neo4j-Management\Get-Args.ps1”项识别为cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次。 前提配置好环境变量之后依然报上面的错…...
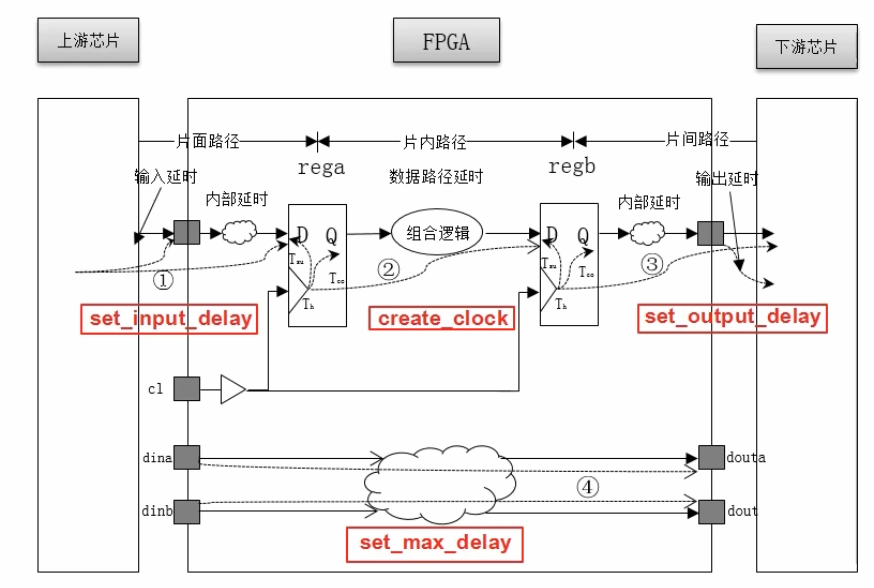
【EDA软件】【设计约束和分析操作方法】
1. 设计约束 设计约束主要分为物理约束和时序约束。 物理约束主要包括I/O接口约束(如引脚分配、电平标准设定等物理属性的约束)、布局约束、布线约束以及配置约束。 时序约束是FPGA内部的各种逻辑或走线的延时,反应系统的频率和速度的约束…...

【Lua】Lua 入门知识点总结
Lua 入门学习笔记 本教程旨在帮助有编程基础的学习者快速入门Lua编程语言。包括Lua中变量的声明与使用,包括全局变量和局部变量的区别,以及nil类型的概念、数值型、字符串和函数的基本操作,包括16进制表示、科学计数法、字符串连接、函数声明…...

Godot学习-关于3D模型选择问题
下面是OBJ、glTF/GLB、BLEND和FBX四种3D模型格式的比较表格,以便更直观地了解它们之间的差异: 特性/格式OBJglTF / GLBBLENDFBX文件类型文本文本/二进制二进制二进制几何数据支持支持支持支持材质支持基础高级(PBR等)完整支持高级…...
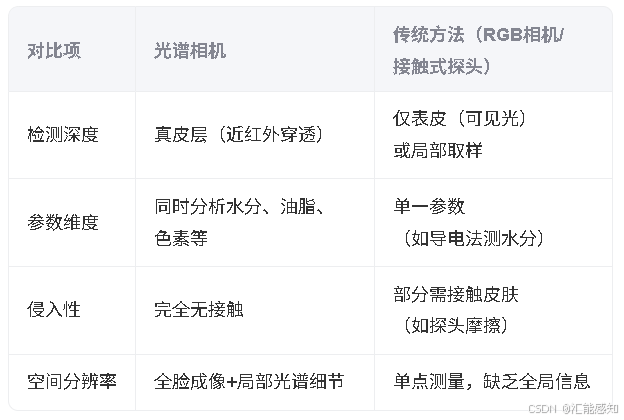
光谱相机在肤质检测中的应用
光谱相机在肤质检测中具有独特优势,能够通过多波段光谱分析皮肤深层成分及生理状态,实现非侵入式、高精度、多维度的皮肤健康评估。以下是其核心应用与技术细节: 一、工作原理 光谱反射与吸收特性: 血红蛋白&a…...
)
IDEA 插件推荐清单(2025)
IDEA 插件推荐清单 精选高效开发必备插件,提升 Java 开发体验与效率。 参考来源:十六款好用的 IDEA 插件,强烈推荐!!!不容错过 代码开发助手类 插件名称功能简介推荐指数CodeGeeX智能代码补全、代码生成、…...

机器学习第一篇 线性回归
数据集:公开的World Happiness Report | Kaggle中的happiness dataset2017. 目标:基于GDP值预测幸福指数。(单特征预测) 代码: 文件一:prepare_for_traning.py """用于科学计算的一个库…...
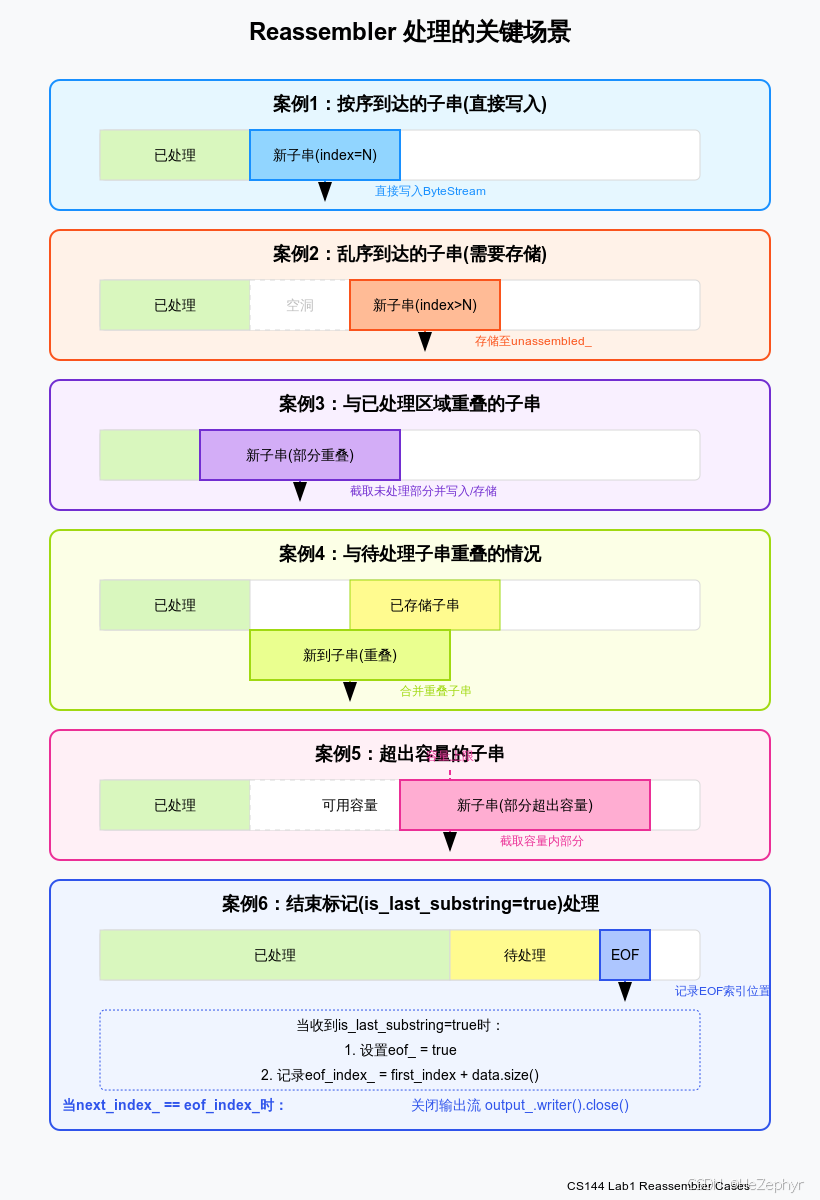
CS144 Lab1实战记录:实现TCP重组器
文章目录 1 实验背景与要求1.1 TCP的数据分片与重组问题1.2 实验具体任务 2 重组器的设计架构2.1 整体架构2.2 数据结构设计 3 重组器处理的关键场景分析3.1 按序到达的子串(直接写入)3.2 乱序到达的子串(需要存储)3.3 与已处理区…...
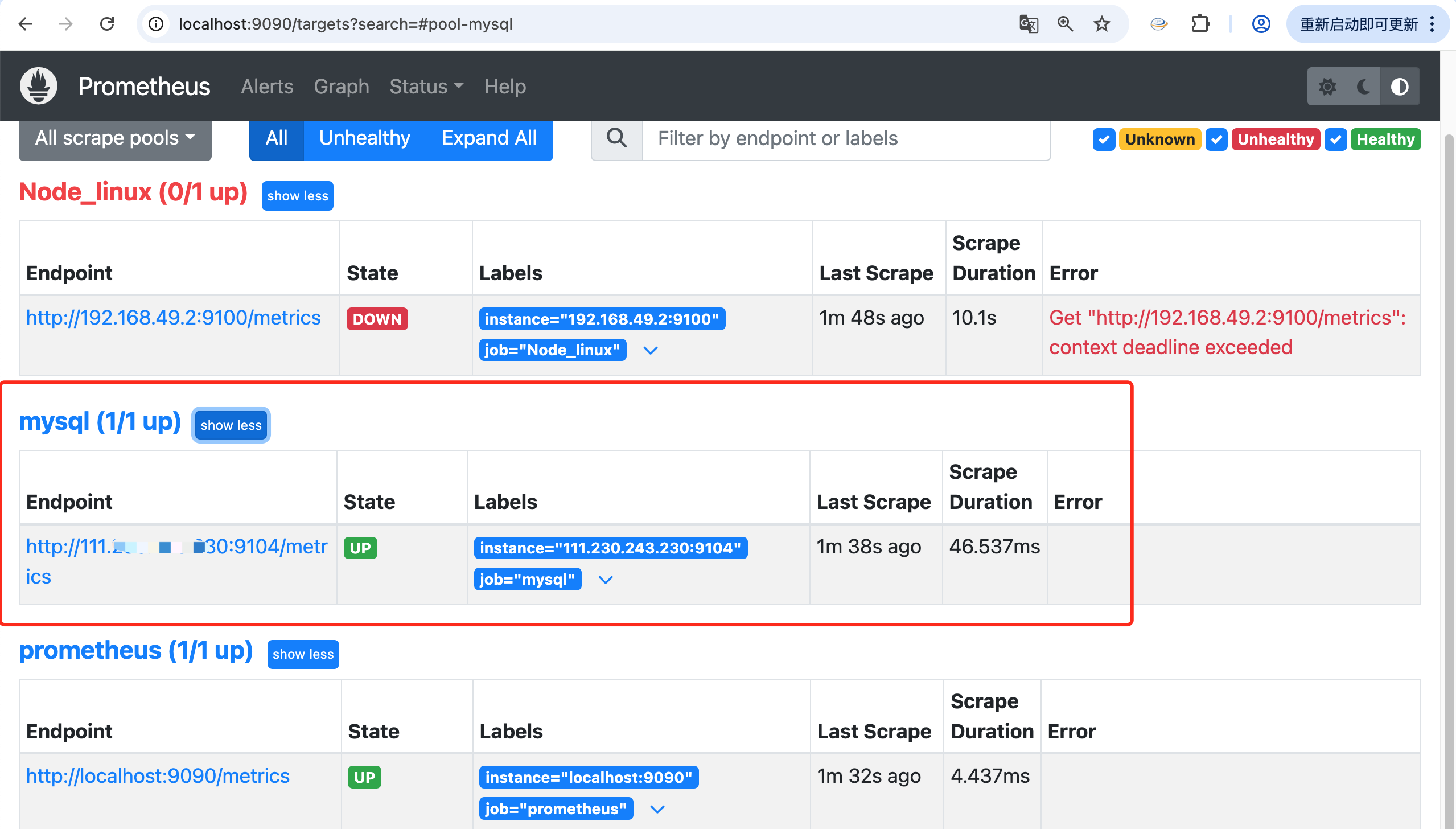
Linux安装mysql_exporter
mysqld_exporter 是一个用于监控 MySQL 数据库的 Prometheus exporter。可以从 MySQL 数据库的 metrics_schema 收集指标,相关指标主要包括: MySQL 服务器指标:例如 uptime、version 等数据库指标:例如 schema_name、table_rows 等表指标:例如 table_name、engine、…...

BeautifulSoup 库的使用——python爬虫
文章目录 写在前面python 爬虫BeautifulSoup库是什么BeautifulSoup的安装解析器对比BeautifulSoup的使用BeautifulSoup 库中的4种类获取标签获取指定标签获取标签的的子标签获取标签的的父标签(上行遍历)获取标签的兄弟标签(平行遍历)获取注释根据条件查找标签根据CSS选择器查找…...
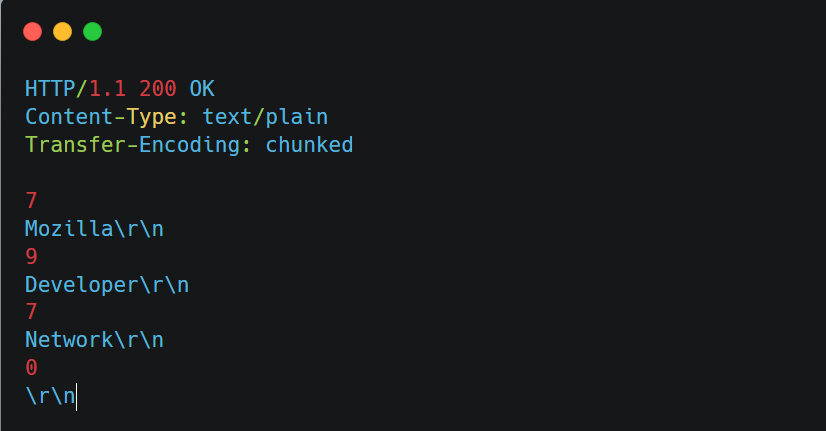
HTTP的Header
一、HTTP Header 是什么? HTTP Header 是 HTTP 协议中的头部信息部分,位于请求或响应的起始行之后,用来在客户端(浏览器等)与服务器之间传递元信息(meta-data)(简单理解为传递信息的…...

linux虚拟机网络问题处理
yum install -y yum-utils \ > device-mapper-persistent-data \ > lvm2 --skip-broken 已加载插件:fastestmirror, langpacks Loading mirror speeds from cached hostfile Could not retrieve mirrorlist http://mirrorlist.centos.org/?release7&arch…...

unet算法发展历程简介
UNet是一种基于深度学习的图像分割架构,自2015年提出以来经历了多次改进和扩展,逐渐成为医学图像分割和其他精细分割任务的标杆。以下是UNet算法的主要发展历程和关键变体: 1. 原始UNet(2015) 论文: U-Net: Convoluti…...
)
基于华为云 ModelArts 的在线服务应用开发(Requests 模块)
基于华为云 ModelArts 的在线服务应用开发(Requests 模块) 一、本节目标 了解并掌握 Requests 模块的特点与用法学会通过 PythonRequests 访问华为云 ModelArts 在线推理服务熟悉 JSON 模块在 Python 中的数据序列化与反序列化掌握 Python 文件 I/O 的基…...