测试基础笔记第十天
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、查询语句
- 1.基本查询
- 2.条件查询
- 3.模糊查询
- 4.范围查询
- 5.判断空
- 二、其他复杂查询
- 1.排序
- 2.聚合函数
- 3.分组
- 4.分页查询
一、查询语句
1.基本查询
– 需求1: 准备商品数据, 查询所有数据, 查询部分字段, 起字段别名, 去重
– 查询所有数据: select * from 表名;
select * from goods;
– 查询部分字段: select 字段名1, 字段名2 from goods;
select goodsName, price from goods;
– 起字段别名: select 字段名 as ‘别名’ from goods;
select goodsName as ‘商品名称’, price as ‘价格’ from goods;
– 注意: 别名的引号可以省略
select goodsName as 商品名称, price as 价格 from goods;
– 注意: as 关键字也可以省略[掌握]
select goodsName 商品名称, price 价格 from goods;
– 起别名的作用: 1> 美化数据结果的显示效果 2> 可以起到隐藏真正字段名的
作⽤用
– 另: 除了可以给字段起别名以外, 还可以给数据表起别名(连接查询时使用)
– 去重: select distinct(字段名) from goods;
– 效果: 将目标字段内重复出现的数据只保留留一份显示
– 小需求: 显示所有的公司名称
select distinct(company) from goods;
2.条件查询
- 比较运算符&逻辑运算符
– 需求2: 查询价格等于30并且出自并夕夕的所有商品信息
select * from goods;
– 查询价格等于30 : 比较运算符(特殊: (大于等于)>=/(小于等于)<=/(不等于)!=/<>)
select * from goods where price=30;
– 并且出自并夕夕的所有商品信息 : 逻辑运算符(and(与)/or(或)/not(非))
– 注意: 作为查询条件使⽤用的字符串必须带引号!
select * from goods where price=30 and company=‘并夕夕’;
– 补充需求: 查询价格等于30但不出自并夕夕的所有商品信息
select * from goods where not company=‘并夕夕’ and price=30;
– 注意: not 与 and 和 or (左右两边连接条件)不同之处在于, not 只对自己右侧的条件有作用(右边连接条件)
select * from goods where price=30 and not company=‘并夕夕’;
3.模糊查询
– 需求3: 查询全部一次性口罩的商品信息
– 模糊查询: like 和符号 %(任意多个符)/(任意一个字符)
– 注意: 作为查询条件使用的字符串必须带引号!
– 注意: 如果需要控制字符数量, 需要使用, 并且有几个字符就使用几个_
– %关键词% : 关键词在中间
select * from goods where remark like ‘%⼀一次性%’;
– %关键词 : 关键词在末尾
select * from goods where remark like ‘%⼀一次性’;
– 关键词% : 关键词在开头
select * from goods where remark like ‘⼀一次性%’;
4.范围查询
– 需求4: 查询所有价格在30-100的商品信息
– 范围查询: 1> 非连续范围: in 2> 连续范围: between … and …
select * from goods where price between 30 and 100;
– 注意: between … and … 的范围必须是从小到大
select * from goods where price between 100 and 30;
5.判断空
– 需求5: 查询没有描述信息的商品信息
– 注意: 在 MySQL 中, 只有显示为 NULL 的才为空! 其余空白可能是空格/制
表符(tab)/换行符(回车键)等空白符号
– 判断空: 1> 为空: is null 2> 不为空(双重否定表肯定): is not null
select * from goods where remark is null;
– 补充需求: 查询有描述信息的所有商品
select * from goods where remark is not null;
二、其他复杂查询
1.排序
– 需求6: 查询所有商品信息, 按照价格从大到小排序, 价格相同时, 按照数量少到多排序
– select * from 表名 order by 列1 asc|desc,列2 asc|desc,…
– 说明: order by 排序, asc : 升序, desc : 降序
– 注意: 排序过程中, 支持连续设置多条排序规则, 但离 order by 关键字越近, 排序数据的范围越大!
select * from goods order by price desc;
select * from goods order by price desc, count asc;
– 注意: 默认排序为升序, asc 可以省略
select * from goods order by price desc, count;
2.聚合函数
– 需求7: 查询以下信息: 商品信息总条数; 最高商品价格; 最低商品价格;
商品平均价格; 一次性口罩的总数量
– 聚合函数: 系统提供的一些可以直接用来获取统计数据的函数
– 商品信息总条数: count(字段): 查询总记录数
select count() from goods;
– 注意: 统计数据总数, 建议使用, 如果使用某一特定字段, 可能会造成数据总数错误!
select count(remark) from goods;
– 最高商品价格: max(字段): 查询最大值
select max(price) from goods;
– 最低商品价格: min(字段): 查询最小值
select min(price) from goods;
– 商品平均价格: avg(字段): 求平均值
select avg(price) from goods;
– 一次性口罩的总数量: sum(): 求和
– 注意: 此处的 count 是数据表中字段名!
select sum(count) from goods where remark like ‘%一次性%’;
– 扩展: 在需求允许的情况下, 可以一次性在一条 SQL语句中, 使用所有的聚合函数
select count(*), max(price), min(price), avg(price) from goods;
3.分组
– 需求8: 查询每家公司的商品信息数量
– 分组: select 字段1,字段2,聚合… from 表名 group by 字段1,字段
2…
– 说明: group by : 分组
– 注意:
– 1> 一般情况, 使用哪个字段进行分组, 那么只有该字段可以在 * 的位置处使用, 其他字段没有实际意义(只要一组数据中的一条)
– 2> 分组操作多和聚合函数配合使用
select count() from goods group by company;
select * from goods;
select company, count() from goods group by company;
– 说明: 其他字段没有实际意义(只要一组数据中的一条)
select price, count(*) from goods group by company;
– 扩充: 分组后条件过滤
– 说明: group by 后增加过滤条件时, 需要使用 having 关键字
– 注意:
– 1. group by 和 having 一般情况下需要配合使用
– 2. group by 后边不推荐使用 where 进行条件过滤
– 3. having 关键字后侧可以使用的内容与 where 完全⼀一致(比较运算符/逻辑运算符/模糊查询/判断空)
– 3. having 关键字后侧允许使用聚合函数
– where 和 having 的区别:
– where 是对 from 后⾯面指定的表进行数据筛选,属于对原始数据的筛选
– having 是对 group by 的结果进行筛选
– having 后⾯面的条件中可以用聚合函数,where 后面不可以
4.分页查询
– 需求9: 查询当前表当中第5-10行的所有数据
– 分页查询: select * from 表名 limit start,count
– 说明: limit 分页; start : 起始行号; count : 数据行数
– 注意: 计算机的计数从 0 开始, 因此 start 默认的第一条数据应该为 0,
后续数据依次减1
– 过渡需求: 获取前 5 条数据
select * from goods limit 0, 5;
– 注意: 如果默认从第一条数据开始获取, 则 0 可以省略!
select * from goods limit 5;
– 需求:
select * from goods limit 4, 6;
– 扩展 1: 根据公式计算显示某页的数据
– 已知:每页显示m条数据,求:显示第n页的数据
– select * from 表名 limit (n-1)*m, m
– 示例: 每页显示 4 条数据, 求展示第 2 页的数据内容
select * from goods limit 0, 4; – 第1页(有数据)
select * from goods limit 4, 4; – 第2页(有数据)
select * from goods limit 8, 4; – 第3页(有数据)
select * from goods limit 12, 4; – 第4页(⼀一共 12 条数据, 每页显示
4 条, 没有第 4 页数据)
– 扩展 2: 分页的其他应⽤用
– 需求: 要求查询商品价格最贵的数据信息
select * from goods order by price desc limit 1;
– 进阶需求: 要求查询商品价格最贵的前三条数据信息
select * from goods order by price desc limit 3;
相关文章:

测试基础笔记第十天
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、查询语句1.基本查询2.条件查询3.模糊查询4.范围查询5.判断空 二、其他复杂查询1.排序2.聚合函数3.分组4.分页查询 一、查询语句 1.基本查询 – 需求1: 准备商…...

Geek强大的电脑卸载软件工具,免费下载
一款强大的卸载电脑软件工具,无需安装 免费下载...

Linux:41线程控制lesson29
1.线程的优点: • 创建⼀个新线程的代价要⽐创建⼀个新进程⼩得多 创建好线程只要调度就好了 • 与进程之间的切换相⽐,线程之间的切换需要操作系统做的⼯作要少很多 为什么? ◦ 最主要的区别是线程的切换虚拟内存空间依然是相同的&#x…...

基于Flask与Ngrok实现Pycharm本地项目公网访问:从零部署
目录 概要 1. 环境与前置条件 2. 安装与配置 Flask 2.1 创建虚拟环境 2.2 安装 Flask 3. 安装与配置 Ngrok 3.1 下载 Ngrok 3.2 注册并获取 Authtoken 4. 在 PyCharm 中创建 Flask 项目 5. 运行本地 Flask 服务 6. 启动 Ngrok 隧道并获取公网地址 7. 完整示例代码汇…...

Ai晚报20250423
Kortix 发布全球首个开源通用型 AI Agent——Suna,能像人类一样学习、推理和适应,通过自然对话帮助用户完成多种现实任务,支持浏览器自动化、文件管理等 20 个用户场景。腾讯混元大模型 AI 阅读助手“企鹅读伴”正式上线,为中小学…...

密码学货币混币器详解及python实现
目录 一、前言二、混币器概述2.1 混币器的工作原理2.2 关键特性三、数据生成与预处理四、系统架构与流程五、核心数学公式六、异步任务调度与 GPU 加速七、PyQt6 GUI 设计八、完整代码实现九、自查测试与总结十、展望摘要 本博客聚焦 “密码学货币混币器实现”,以 Python + P…...
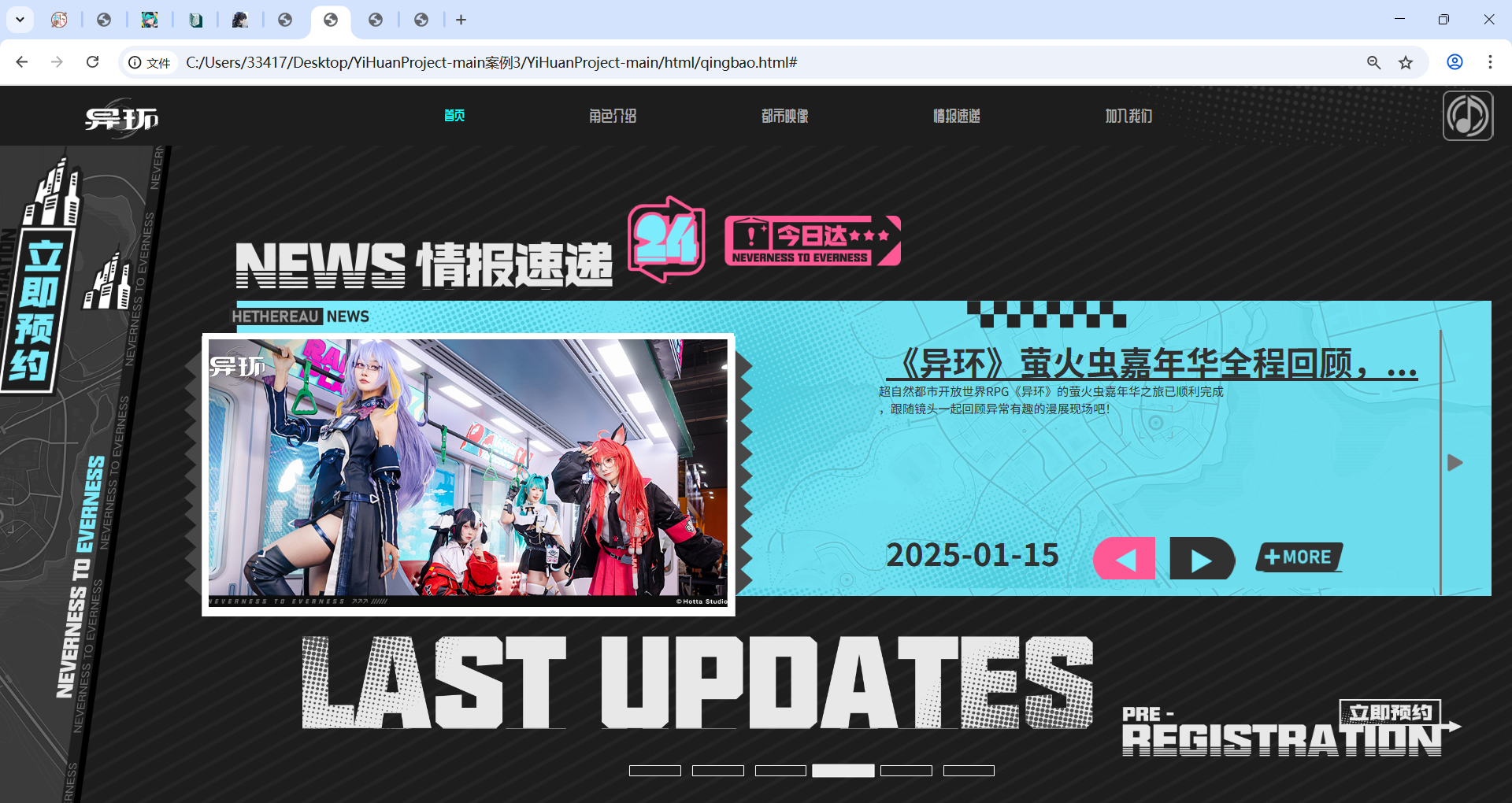
HTMLCSS实现网页轮播图
网页中轮播图区域的实现与解析 在现代网页设计中,轮播图是一种常见且实用的元素,能够在有限的空间内展示多个内容,吸引用户的注意力。下面将对上述代码中轮播图区域的实现方式进行详细介绍。 一、HTML 结构 <div class"carousel-c…...

如何确定置信水平的最佳大小
在统计学中,置信水平的选择并不是一成不变的,而是根据具体的研究目的、样本量、数据类型以及行业标准等因素来确定的。然而,在大多数情况下,95%的置信水平是最常用的。 选择95%置信水平的原因 平衡可靠性与精确性: •…...

Java基础第21天-正则表达式
正则表达式是对字符串执行模式匹配的技术 如果想灵活的运用正则表达式,必须了解其中各种元字符的功能,元字符从功能上大致分为: 限定符选择匹配符分组组合和反向引用符特殊字符字符匹配符定位符 转义号\\:在我们使用正则表达式去检索某些特…...

Maven 项目中引入本地 JAR 包
在日常开发过程中,我们有时会遇到一些未上传到 Maven 中央仓库或公司私有仓库的 JAR 包,比如第三方提供的 SDK 或自己编译的库。这时候,我们就需要将这些 JAR 包手动引入到 Maven 项目中。本文将介绍两种常见方式:将 JAR 安装到本…...

CSGO 盲盒开箱系统技术实现深度解析
一、系统架构设计 (一)前后端分离架构 采用前后端分离模式,后端专注业务逻辑处理与数据管理,前端负责用户交互界面呈现。后端通过 RESTful API 与前端进行数据交互,这种架构能有效提高开发效率,便于团队分…...
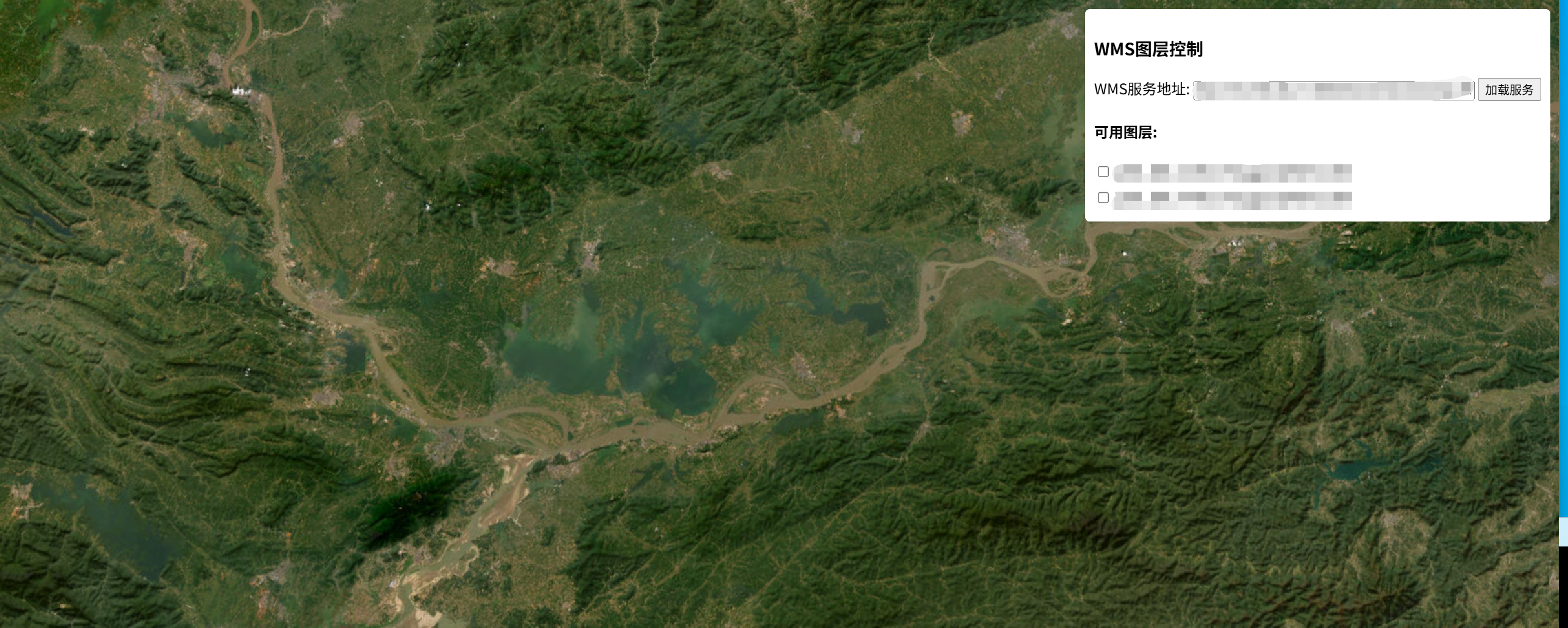
JS通过GetCapabilities获取wms服务元数据信息并在SuperMap iClient3D for WebGL进行叠加显示
获取wms服务元数据信息并在三维webgl客户端进行叠加显示 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><tit…...
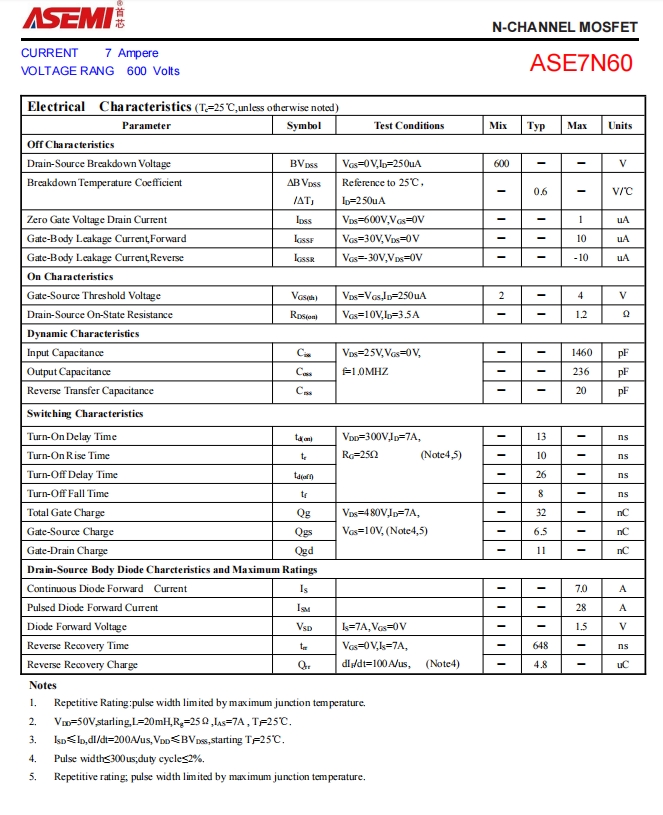
7N60-ASEMI无人机专用功率器件7N60
编辑:LL 7N60-ASEMI无人机专用功率器件7N60 型号:7N60 品牌:ASEMI 封装:TO-220F 最大漏源电流:7A 漏源击穿电压:600V 批号:最新 RDS(ON)Max:1.20Ω …...
)
Redis日常学习(一)
我的Redis学习笔记:从命令行到性能调优 Redis Redis(Remote Dictionary Server)本质上是一个基于内存的键值存储系统. 安装配置Redis的过程非常简单: # Ubuntu/Debian安装Redis sudo apt-get update sudo apt-get install red…...

Pytorch图像数据转为Tensor张量
PyTorch的所有模型(nn.Module)都只接受Tensor格式的输入,所以我们在使用图像数据集时,必须将图像转换为Tensor格式。PyTorch提供了torchvision.transforms模块来处理图像数据集。torchvision.transforms模块提供了一些常用的图像预…...

Java 加密与解密:从算法到应用的全面解析
Java 加密与解密:从算法到应用的全面解析 一、加密与解密技术概述 在当今数字化时代,数据安全至关重要。Java 加密与解密技术作为保障数据安全的关键手段,被广泛应用于各个领域。 加密是将明文数据通过特定算法转换为密文,使得…...

Java基础系列-HashMap源码解析2-AVL树
文章目录 AVL树左旋右旋左旋右旋的4种情况LL 型RR 型LR 型RL 型 实际插入时怎么判断是那种类型?插入时注意事项删除节点 AVL树 为避免BST树退化成链表的极端情况, AVL 树应运而生。 平衡因子取值(-1,0,1)…...

蓝桥杯 19. 最大比例
最大比例 原题目链接 题目描述 X 星球的某个大奖赛设了 M 级奖励。每个级别的奖金是一个正整数。 并且,相邻两个级别间的比例是一个固定值,也就是说:所有级别的奖金构成一个等比数列。 例如: 奖金数列为 16, 24, 36, 54&…...

前端加密介绍与实战
前端数据加密 文章目录 前端数据加密前端数据加密介绍为什么需要前端数据加密?前端数据加密的常见方式前端数据加密的实现场景:加密用户密码并发送到后端步骤 1:安装加密库步骤 2:实现加密逻辑步骤 3:后端解密 实战总结…...

Zookeeper是什么?基于zookeeper实现分布式锁
zookeeper听的很多,但实际在应用开发中用的不错,主要是作为中间件配合使用的,例如:Kafka。 了解zk首先需要知道它的数据结构,可以想象为树、文件夹目录。每个节点有基本的信息,例如:创建时间、…...

Kafka 主题设计与数据接入机制
一、前言:万物皆流,Kafka 是入口 在构建实时数仓时,Kafka 既是 数据流动的起点,也是后续流处理系统(如 Flink)赖以为生的数据源。 但“消息进来了” ≠ “你就能处理好了”——不合理的 Topic 设计、接入方…...

gem5-gpu教程05 内存建模
memory-modeling|Details on how memory is modeled in gem5-gpu gem5-gpu’s Memory Simulation gem5-gpu在很大程度上避开了GPGPU-Sim的单独功能模拟,而是使用了gem5的执行中执行模型。因此,当执行存储/加载时,内存会被更新/读取。没有单独的功能路径。(顺便说一句,这…...
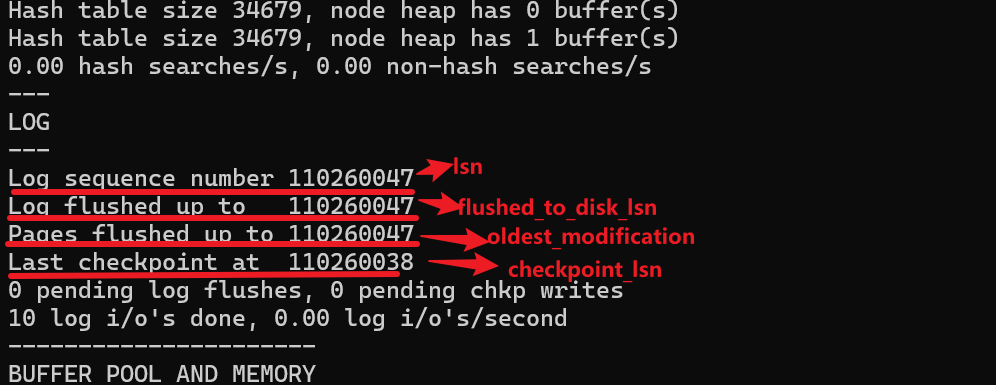
MySQL的日志--Redo Log【学习笔记】
MySQL的日志--Redo Log 知识来源: 《MySQL是怎样运行的》--- 小孩子4919 MySQL的事务四大特性之一就是持久性(Durability)。但是底层是如何实现的呢?这就需要我们的Redo Log(重做日志)闪亮登场了。它记录着…...
【AI应用】免费代码仓构建定制版本的ComfyUI应用镜像
免费代码仓构建定制版本的ComfyUI应用镜像 1 创建代码仓1.1 注册登陆1.2 创建代码仓1.5 安装中文语言包1.4 拉取ComfyUI官方代码2 配置参数和预装插件2.1 保留插件和模型的版本控制2.2 克隆插件到代码仓2.2.1 下载插件2.2.2 把插件设置本仓库的子模块管理3 定制Docker镜像3.1 创…...

MineWorld,微软研究院开源的实时交互式世界模型
MineWorld是什么 MineWorld是微软研究院开发并开源的一个基于《我的世界》(Minecraft)的实时互动世界模型。该模型采用了视觉-动作自回归Transformer架构,将游戏场景和玩家动作转化为离散的token ID,并通过下一个token的预测进行…...

被裁20240927 --- 视觉目标跟踪算法
永远都像初次见你那样使我心荡漾 参考文献目前主流的视觉目标跟踪算法一、传统跟踪算法1. 卡尔曼滤波(Kalman Filter)2. 相关滤波(Correlation Filter,如KCF、MOSSE)3. 均值漂移(MeanShift/CamShift&#x…...

Agentic AI——当AI学会主动思考与决策,世界将如何被重塑?
一、引言:2025,Agentic AI的元年 “如果ChatGPT是AI的‘聊天时代’,那么2025年将开启AI的‘行动时代’。”——Global X Insights[1] 随着Agentic AI(自主决策型人工智能)的崛起,AI系统正从被动应答的“工具…...

Ollama API 应用指南
1. 基础信息 默认地址: http://localhost:11434/api数据格式: application/json支持方法: POST(主要)、GET(部分接口) 2. 模型管理 API (1) 列出本地模型 端点: GET /api/tags功能: 获取已下载的模型列表。示例:curl http://lo…...
PNG透明免抠设计素材大全26000+
在当今的数字设计领域,寻找高质量且易于使用的素材是每个设计师的日常需求。今天,我们将为大家介绍一个超全面的PNG透明免抠设计素材大全,涵盖多种风格、主题和应用场景,无论是平面设计、网页设计还是多媒体制作,都能轻…...

4.多表查询
SQL 多表查询:数据整合与分析的强大工具 文章目录 SQL 多表查询:数据整合与分析的强大工具一、 多表查询概述1.1 为什么需要多表查询1.2 多表查询的基本原理 二、 多表查询关系2.1 一对一关系(One-to-One)示例: 2.2 一…...