stack和queue的学习
stack的介绍
stack的文档介绍
- stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。
- stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。
- stack的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下操作:
- empty:判空操作
- back:获取尾部元素操作
- push_back:尾部插入元素操作
- pop_back:尾部删除元素操作
- 标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的底层容器,默认情况下使用deque
stack的使用
| 函数说明 | 接口说明 |
|---|---|
| stack() | 构造空的栈 |
| empty() | 检测stack是否为空 |
| size() | 返回stack中元素的个数 |
| top() | 返回栈顶元素的引用 |
| push() | 将元素val压入stack中 |
| pop() | 将stack中顶部的元素弹出 |
| swap() | 交换2个栈中的元素 |
来看一个不常用的函数。

- 解释:交换2个容器适配器中的内容
- 示例:
#include <iostream> // std::cout
#include <stack> // std::stack
using namespace std;
int main()
{stack<int> foo, bar;foo.push(10); foo.push(20); foo.push(30);bar.push(111); bar.push(222);foo.swap(bar);cout << "size of foo: " << foo.size() << '\n'; //size of foo: 2cout << "size of bar: " << bar.size() << '\n'; //size of bar: 3return 0;
}
这里主要展示一些常用的操作函数,至于使用方法跟其它的STL一样,所以就不在演示了。
queue的介绍
queue的文档介绍
- 队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端提取元素。
- 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
- 底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:
- empty:检测队列是否为空
- size:返回队列中有效元素的个数
- front:返回队头元素的引用
- back:返回队尾元素的引用
- push_back:在队列尾部入队列
- pop_front:在队列头部出队列
- 标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标准容器deque。
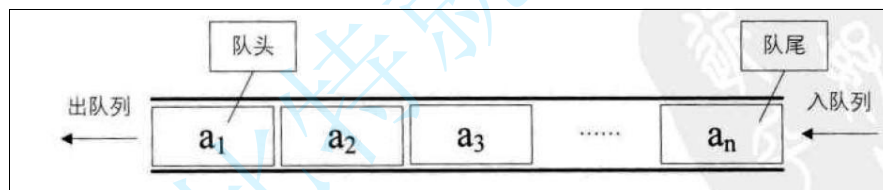
queue的使用
| 函数声明 | 接口说明 |
|---|---|
| queue() | 构造空的队列 |
| empty() | 检测队列是否为空,是返回true,否则返回false |
| size() | 返回队列中有效元素的个数 |
| front() | 返回队头元素的引用 |
| back() | 返回队尾元素的引用 |
| push() | 把队尾元素val入队列 |
| pop() | 将队头元素出队列 |
容器适配器
容器适配器(Container Adapter)是一种设计模式,它允许将一种容器类(如 std::vector、std::list、std::deque 等)的接口适配到另一种容器类上。在C++标准模板库(STL)中,有三种容器适配器:stack、queue 和 priority_queue。
这些适配器提供了特定的接口,使得它们可以被当作特定的数据结构来使用,而底层实际使用的是其他容器。以下是每种容器适配器的简要说明:
- stack(栈):它提供了后进先出(LIFO)的数据结构接口。
stack适配器通常使用std::deque或std::vector作为底层容器。 - queue(队列):它提供了先进先出(FIFO)的数据结构接口。
queue适配器通常使用std::deque作为底层容器。 - priority_queue(优先队列):它提供了一个优先级队列的接口,其中元素按照优先级顺序排列,最高优先级的元素最先被移除。
priority_queue适配器通常使用std::vector作为底层容器,并使用堆(heap)数据结构来维护元素的顺序。
容器适配器的优点包括:
- 封装性:它们隐藏了底层容器的具体实现细节,使得用户可以专注于使用特定的数据结构口。
- 灵活性:通过改变底层容器,可以轻松地改变容器适配器的行为。
- 一致性:它们遵循STL的一致性原则,使得代码更加模块化和可重用
stack和queue的模拟实现
stack的模拟实现
先来看看栈的基本结构
template<class T>class stack{private:vector<int> _con;}_
这个结构的成员_con的类型是vector<int>,后续对stack进行操作,实际上就是对vector进行操作。在进行操作之前,我们要先想清楚用vector的头部还是尾部来做栈的顶部,答案是用vector的尾部来做栈的顶。因为当在头部进行插入或者删除数据时,其它元素也会跟着移动,这会降低程序的性能。所以用尾部是最合适的。
入栈:就是对vector尾插
void push(const T& x)
{_con.push_back(x);
}
出栈:就是对vector尾删
void pop()
{_con.pop_back();
}
取栈顶:就是对vector取尾部元素
T& top()
{return _con.back();
}
判空和元素个数:跟vector的操作一样
void empty()
{_con.empty();
}size_t size()
{return _con.size();
}
那么在上面既然讲到了容器适配器,就说明还能使用其它的容器来对stack进行操作。比如说用list进行操作的话,难道还需要重新写一个list<int>的版本吗?那肯定是不需要的,只需要传入第二个参数就行了,如下所示:
template<class T,class Container = vector<T>>class stack{private:Container _con;}
第二个参数Container的底层容器就是默认用vector实现的,如果不传入第二个参数就默认为vector。如果想用list容器来实现stack,形式如下:
stack<int, list<int>>
queue的模拟实现
这里就直接展示代码了,跟stack的原理一样。不过queue的实现使用list比较合适,因为queue需要头删,使用list进行头删代价比较小,而且vector没有头删,只有指定删除位置上的元素,代价比较大,而list有头删,所以使用list是最合适的。
template<class T,class Container = list<T>>
class queue
{
public:queue(){}void push(const T& x)
{_con.push_back(x);
}void pop()
{_con.pop_front();
}const T& front()
{return _con.front();
}const T& back()
{return _con.back();
}bool empty()
{return _con.empty();
}size_t size()
{return _con.size();
}private:Container _con;};
deque的简单介绍(了解)
deque的原理
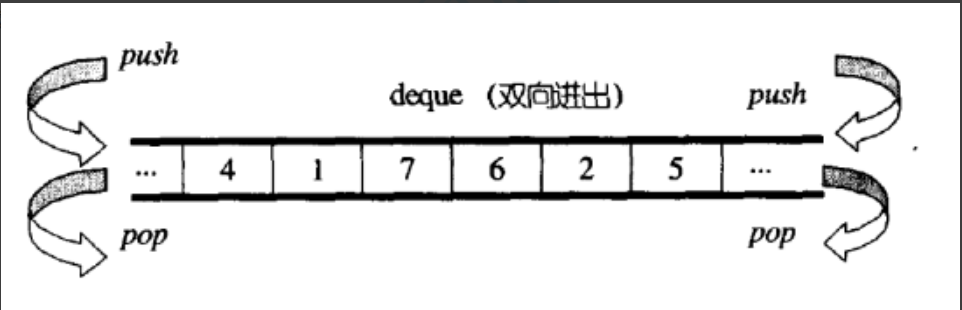
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。相当于是把list和vector的优点结合在一起。
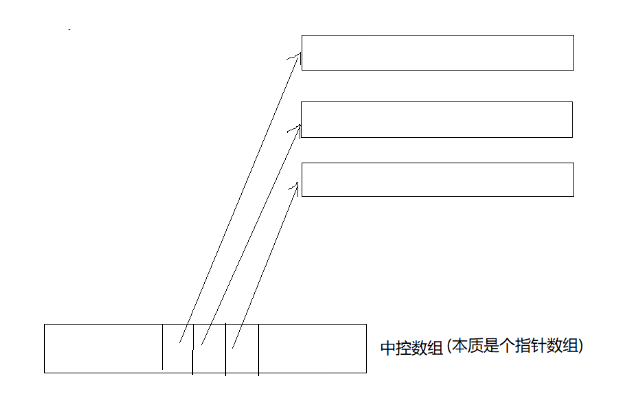
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:
如果想头插或者尾插元素,插入的顺序就如下图所示:
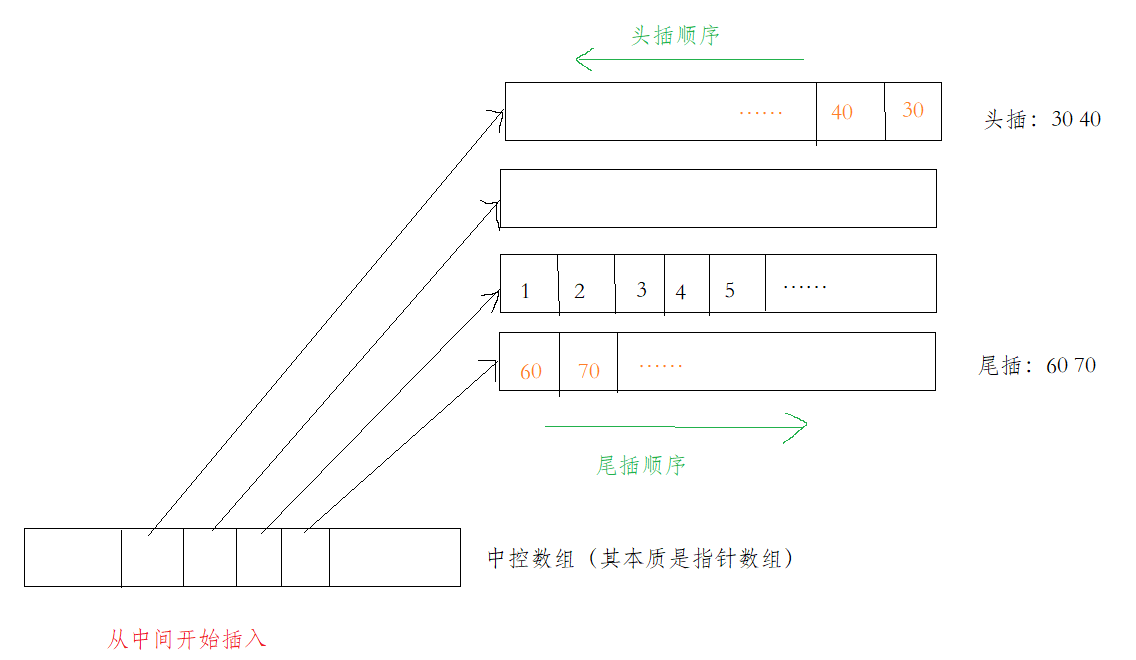
可以看到,我们进行头部插入,不会影响其他数据,这是它相对于vector的优势。而由于其内存是部分连续的,可以通过中控数组的指针偏移量与小数组的指针偏移量来锁定元素。所以其也可以支持下标随机访问。
deque的优缺点
优点:
- 两端快速插入和删除:
std::deque允许在队列的前端和后端进行快速的插入和删除操作,这比std::vector和std::list更有优势。 - 内存分配:
std::deque使用多个固定大小的块来存储元素,这可以减少内存分配和复制操作,特别是在频繁插入和删除时。 - 随机访问:与
std::list不同,std::deque提供了随机访问迭代器,这意味着可以快速访问任何元素,就像std::vector一样。 - 灵活性:
std::deque结合了std::vector的随机访问特性和std::list的快速两端操作特性。
缺点: - 内存使用:由于
std::deque使用多个块来存储元素,它可能会比std::vector使用更多的内存,因为每个块之间需要额外的空间来存储块的指针。 - 连续性:与
std::vector不同,std::deque中的元素不是存储在连续的内存块中的,这可能会影响某些算法的性能。 - 迭代器失效:在
std::deque中,除了在两端进行操作外,其他插入和删除操作可能会导致迭代器失效。
另外,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构
deque与vector和list的区别
| deque | vector | list | ||
|---|---|---|---|---|
| 内存分配 | 非连续内存分配,使用多个块 | 连续内存分配,适合随机访问 | 节点链表,每个节点包含数据和指向前后指针的节点 | |
| 插入和删除性能 | 在两端插入和删除元素时非常高效 | 在中间插入和删除元素时,可能需要移动大量的元素 | 在任意位置插入和删除元素时都非常高效 | |
| 随机访问 | 支持随机访问 | 支持随机访问 | 不支持随机访问,只能顺序访问 | |
| 内存局部性 | 由于使用多个块,内存局部性不如vector | 由于元素存储在连续内存中,具有很好的内存局部性 | 不支持随机访问,只能顺序访问 | |
| 迭代器失效 | 在中间插入或删除元素时,可能会使所有迭代器失效 | 在中间插入或删除元素时,可能会使部分迭代器失效 | 在任何位置插入或删除元素,都不会使迭代器失效 |
为什么选择deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
- stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
- 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。结合了deque的优点,而完美的避开了其缺陷。
deque的使用
deque的文档介绍
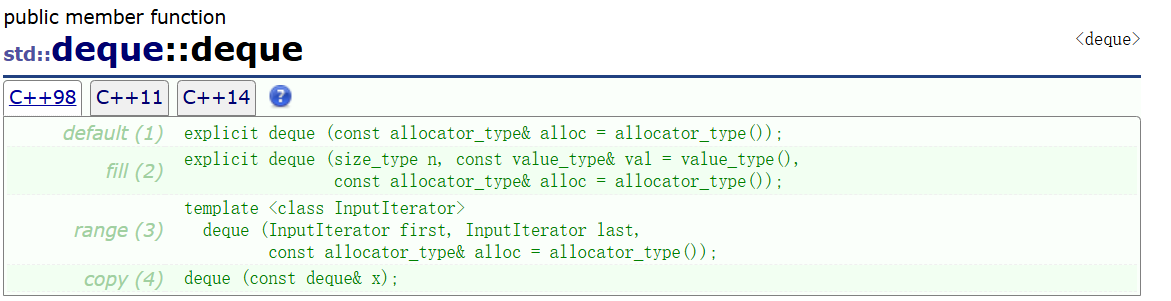
- 示例:
#include <iostream>
#include <deque> int main ()
{ unsigned int i; // constructors used in the same order as described above: deque<int> first; // 空的队列 deque<int> second (4,100); // 初始化为4个100的second队列 deque<int> third (second.begin(),second.end()); // 迭代器区间 deque<int> fourth (third); // 复制third // the iterator constructor can be used to copy arrays: int myints[] = {16,2,77,29}; deque<int> fifth (myints, myints + sizeof(myints) / sizeof(int) ); cout << "The contents of fifth are:"; for (deque<int>::iterator it = fifth.begin(); it!=fifth.end(); ++it) cout << ' ' << *it; //The contents of fifth are: 16 2 77 29cout << '\n'; return 0;
}
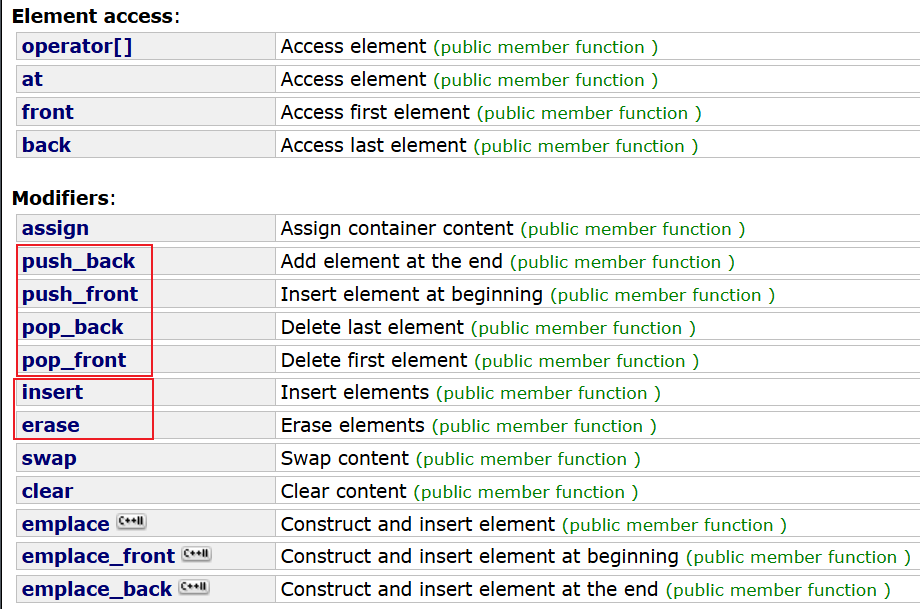
下面直接展示deque的函数,就不介绍使用方法


相关文章:
stack和queue的学习
stack的介绍 stack的文档介绍 stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,…...

微服务Nacos组件的介绍、安装、使用
微服务Nacos组件的介绍、安装、使用 在微服务架构日渐普及的今天,服务注册与配置管理成了系统架构中的关键环节。阿里巴巴开源的 Nacos(Naming and Configuration Service)正是解决这一问题的利器。本文将为你全面介绍 Nacos 的概念、安装方…...

SpringBoot_为何需要SpringBoot?
Spring Boot 出现前的开发困境 配置繁琐 大量的 XML 配置文件 Spring 是一个非常优秀的轻量级框架,但其配置却是重量级的需要编写大量的 XML 配置文件或注解配置,使项目配置复杂且难以维护配置文件中容易出现错误,且排查问题困难开发过程中…...
格式工厂 v5.18最新免安装绿色便携版
前言 用它来转视频的时候,还能顺便给那些有点小瑕疵的视频修修补补,保证转出来的视频质量杠杠的。更厉害的是,它不只是转换那么简单,还能帮你把PDF合并成一本小册子,视频也能合并成大片,还能随心所欲地裁剪…...

使用logrotate实现日志轮转
logrotate 是一个强大的 Linux 工具,用于自动化管理日志文件的轮转、压缩、删除和归档。它能有效防止日志文件无限增长,节省磁盘空间,同时保持日志的可追溯性。以下是详细讲解 logrotate 的用法,涵盖安装、配置、测试、自动化、常…...
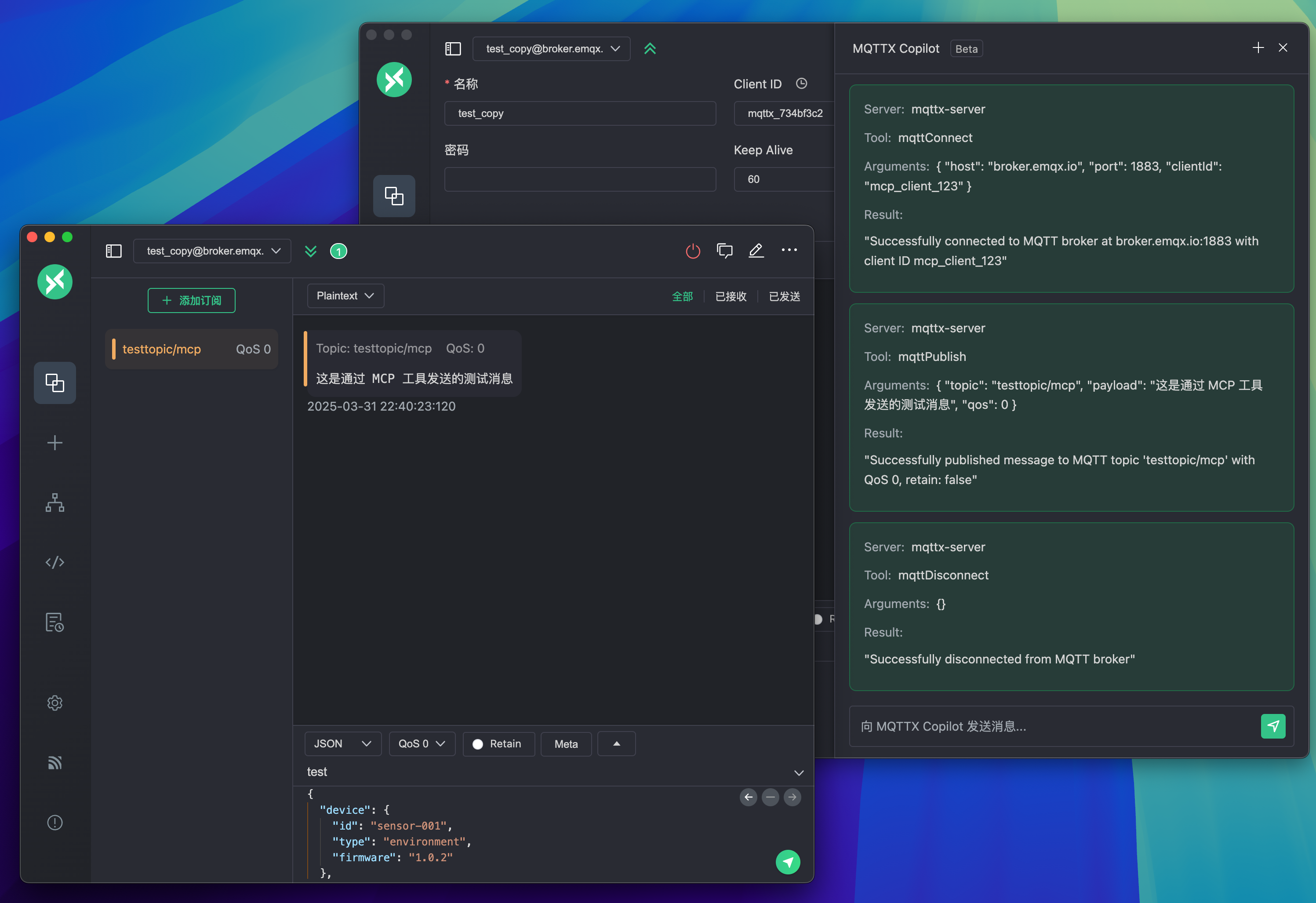
MQTTX + MCP:MQTT 客户端秒变物联网 Agent
引言:MQTTX 与 MCP 的融合 作为最受欢迎的 MQTT 客户端工具,MQTTX 在 1.12.0 beta 版本中集成了模型上下文协议(MCP)到 Copilot AI 功能中,显著提升了服务能力。这一融合让 MQTTX 转变为 MCP Host(也就是发…...

redis close+连接参数设置+并发情况风险分析
1,如下代码 redis 为什么 client.close,不关闭会出现什么问题 public void confirm(String token, MenuHistoryVO menuHistoryVO) {if (StringUtil.isEmptyOrNull(token) || Objects.isNull(menuHistoryVO)) {return;}String key getKey(token);JedisC…...

[密码学实战]GMT 0048-2016智能密码钥匙密码检测规范技术解析与实战指南
GMT 0048-2016智能密码钥匙密码检测规范技术解析与实战指南 引言 随着信息安全需求的升级,智能密码钥匙(如USB Key、安全芯片等)作为密码运算和密钥管理的核心设备,广泛应用于金融、政务、物联网等领域。中国国家密码管理局发布…...

Android OkHttp 框架的使用与源码、原理解析
一、引言 在如今的移动应用开发领域,网络交互已经成为了绝大多数 Android 应用不可或缺的一部分。无论是获取最新的资讯内容、同步用户数据,还是与后端服务器进行实时通信,高效且稳定的网络请求都是保障应用良好用户体验的基石。而 OkHttp 框…...

Qt C++ 解析和处理 XML 文件示例
使用 Qt C 解析和处理 XML 文件 以下是使用 Qt C 实现 XML 文件处理的几种方法,包括解析、创建和修改 XML 文件。 1. 使用 QXmlStreamReader (推荐方式) #include <QFile> #include <QXmlStreamReader> #include <QDebug>void parseXmlWithStr…...

快手砍掉本地生活的门槛
一场本地商家的效率革命。 作者|景行 编辑|杨舟 “两斤鸡翅根七块九,两盒蓝莓九块钱,两公斤卫生纸十四块九一提。” 这是朝阳佳惠超市,在快手一则普通的短视频内容。 佳惠超市在辽宁省朝阳市有22家分店,打开佳惠超市的相关快手…...
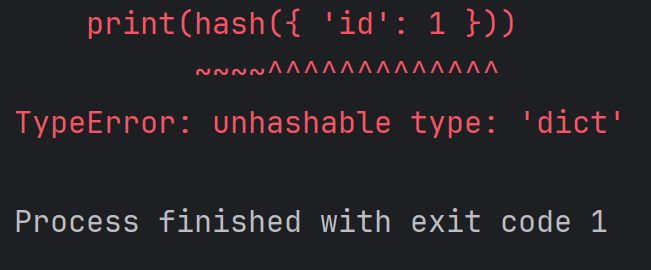
Python基础语法3
目录 1、函数 1.1、语法格式 1.2、函数返回值 1.3、变量作用域 1.4、执行过程 1.5、链式调用 1.6、嵌套调用 1.7、函数递归 1.8、参数默认值 1.9、关键字参数 2、列表 2.1、创建列表 2.2、下标访问 2.3、切片操作 2.4、遍历列表元素 2.5、新增元素 2.6、查找元…...

Vue 3中如何封装API请求:提升开发效率的最佳实践
在现代前端开发中,API请求是不可避免的一部分,尤其是与后端交互时。随着Vue 3的广泛应用,如何高效地封装API请求,既能提升代码的可维护性,又能确保代码的高复用性,成为了很多开发者关注的话题。 在本文中&…...
)
GitHub 趋势日报 (2025年04月17日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1Anduin2017/HowToCook程序员在家做饭方法指南。Programmer’s guide about how to cook at home (Simplified Chinese onl…⭐ 224…...

第5章-1 优化服务器设置
上一篇:《第4章-5 linux 网络管理》,接着服务器设置 本章我们将解释如何为MySQL服务器创建合适的配置文件。这是一个迂回的旅程,有许多兴趣点和可以俯瞰风景的短途旅程。这些短途旅程是必要的。确定合适配置的最短路径并不是从研究配置选项并…...

【AI】Windows环境安装SPAR3D单图三维重建心得
效果一览 左图为原始单个图像,右图为通过SPAR3D重建后的三维建模,可以看出效果还是不错的。 本地环境配置 系统:Windows 11 专业版CPU:i5-13400F内存:32GBGPU:RTX3060 12GBcuda:11.8conda&…...

桌面应用UI开发方案
一、基于 Web 技术的跨平台方案 Electron Python/Go 特点: 技术栈:前端使用 HTML/CSS/JS,后端通过 Node.js 集成 Python/Go 模块或服务。 跨平台:支持 Windows、macOS、Linux 桌面端,适合开发桌面应用。 生态成熟&…...
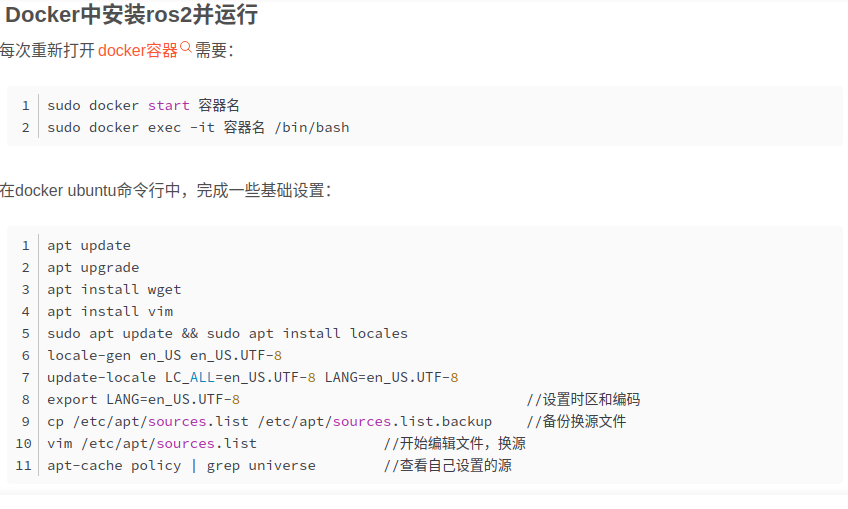
使用docker在manjaro linux系统上运行windows和ubuntu
因为最近项目必须要使用指定版本的solidworks和maxwell(都只能在win系统上使用), 且目前的ubuntu容器是没有桌面的,导致我运行不了一些带图形的ros2功能。无奈之下,决定使用docker-compose写一下配置文件,彻底解决问题…...

Agent智能体ReAct机制深度解读:推理与行动的完美闭环
一、从Chain-of-Thought到ReAct的范式演进 1.1 传统决策机制的局限 #mermaid-svg-Jf3ygvgHcGciJvX8 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Jf3ygvgHcGciJvX8 .error-icon{fill:#552222;}#mermaid-svg-Jf3y…...

在 Node.js 中使用原生 `http` 模块,获取请求的各个部分:**请求行、请求头、请求体、请求路径、查询字符串** 等内容
在 Node.js 中使用原生 http 模块,可以通过 req 对象来获取请求的各个部分:请求行、请求头、请求体、请求路径、查询字符串 等内容。 ✅ 一、基础结构 const http require(http); const url require(url);const server http.createServer((req, res)…...

Redis(01)Redis连接报错Redis is running in protected mode……的解决方案
一、引言:从一个典型连接错误说起 在分布式系统开发中,Redis 作为高性能缓存中间件被广泛使用。 然而,当我们首次部署 Redis 并尝试从外部客户端连接时,常常会遇到以下错误: DENIED Redis is running in protected m…...
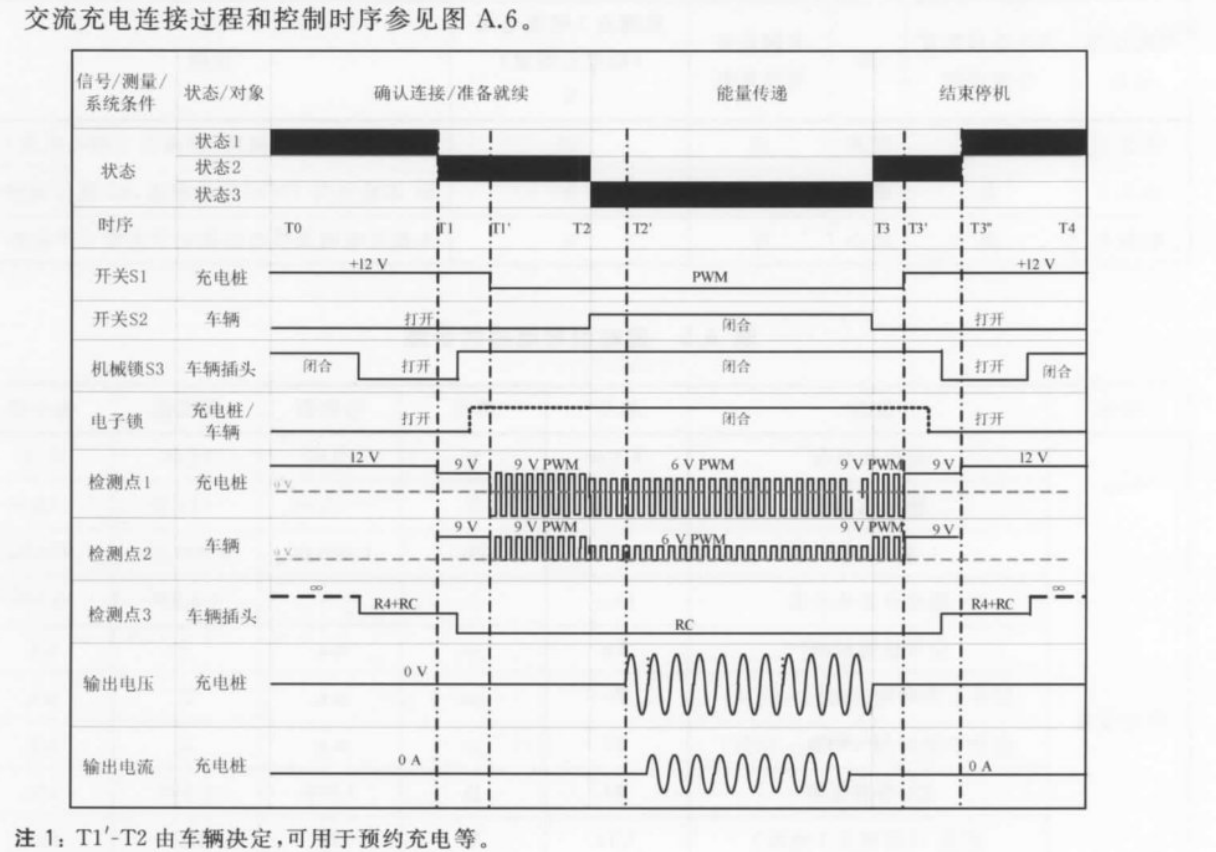
18487.1-2015-解读笔记之四-交流充电之流程分析
前面简单分析了国标交流充电桩插枪监测逻辑和PWM控制逻辑,下面简单分析一下交流充电流程 附录A 交流充电连接过程和控制时序如下: 由此可以将充电流程大概分为几个阶段: 1.充电连接阶段 充电连接阶段CC(电阻由无穷大到R4RC&…...

海外服务器安装Ubuntu 22.04图形界面并配置VNC远程访问指南
在云计算和远程工作日益普及的今天,如何高效地管理和使用海外服务器成为了一个热门话题。本文将详细介绍如何在海外的Ubuntu 22.04服务器上安装图形界面,并配置VNC服务来实现远程访问。无论您是开发者、系统管理员,还是只是想要更便捷地管理您的海外服务器,这篇指南都能为您…...
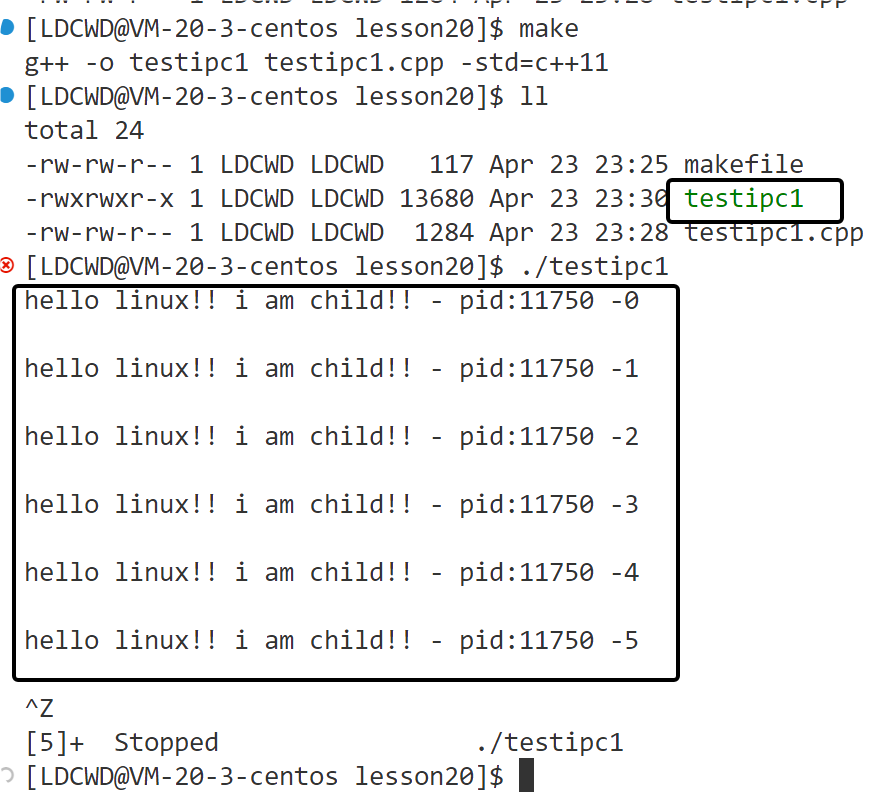
Linux 管道理解
一、什么是管道 1.1 unix中最古老的进程间通信 1.2 一个进程链接到另一个进程的数据流称为“管道”: 图解: 二、管道通信的原理 2.1当我们创建一个进程然后打开一个文件的时候 会经过以下步骤: ①首先要描述这个进程,为这个…...

国产RK3568+FPGA以 “实时控制+高精度采集+灵活扩展” 为核心的解决方案
RK3568FPGA方案在工业领域应用的核心优势 一、实时性与低延迟控制 AMP架构与GPIO中断技术 通过非对称多处理架构(AMP)实现Linux与实时操作系统(RTOS/裸机)协同,主核负责调度,从核通过GPIO中断响应紧…...
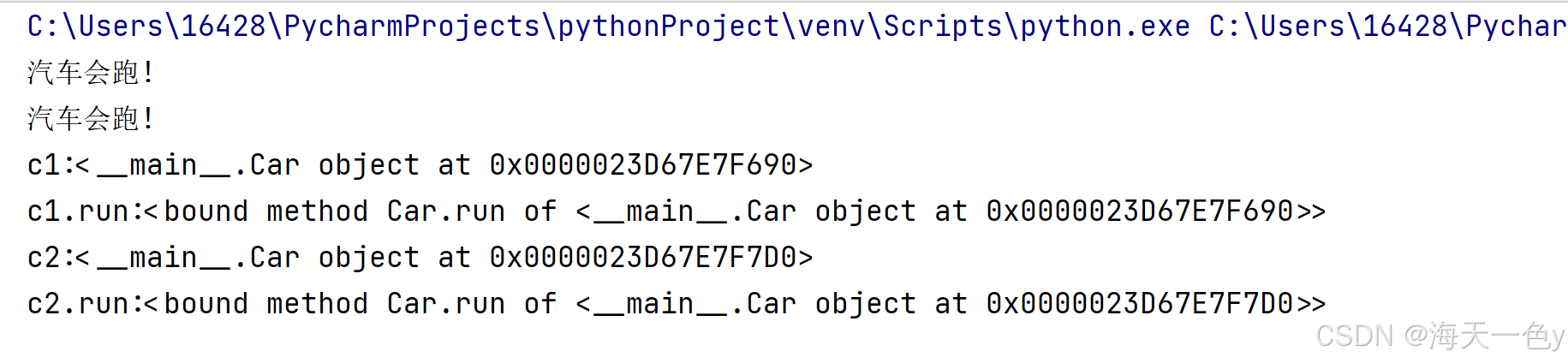
Pycharm(十五)面向对象程序设计基础
目录 一、面向对象基本概述 class 类名: 属性(类似于定义变量) 行为(类似于定义函数,只不过第一个形参要写self) 二、self关键字介绍 三、在类内部调用类中的函数 四、属性的定义和调用 五、魔法方法init方法 六、魔法方法str和del方法 七、案例-减肥 一、…...

华三(H3C)与华为(Huawei)设备配置IPsec VPN的详细说明,涵盖配置流程、参数设置及常见问题处理
以下是针对华三(H3C)与华为(Huawei)设备配置IPsec VPN的详细说明,涵盖配置流程、参数设置及常见问题处理: 一、华三(H3C)设备IPsec VPN配置详解 1. 配置流程 华三IPsec VPN配置主要…...

【消息队列RocketMQ】四、RocketMQ 存储机制与性能优化
一、RocketMQ 存储机制详解 1.1 存储文件结构 RocketMQ 的存储文件主要分布在store目录下,该目录是在broker.conf配置文件中通过storePathRootDir参数指定的,默认路径为${user.home}/store 。主要包含以下几种关键文件类型: 1.1.1 Comm…...

结合地理数据处理
CSV 文件不仅可以存储表格数据,还可以与地理空间数据结合,实现更强大的地理处理功能。例如,你可以将 CSV 文件中的坐标数据转换为点要素类,然后进行空间分析。 示例:将 CSV 文件中的坐标数据转换为点要素类 假设我们有…...

店匠科技摘得 36 氪“2025 AI Partner 创新大奖”
全场景 AI 方案驱动跨境电商数智化跃迁 4 月 18 日,36 氪 2025 AI Partner 大会于上海盛大开幕。大会紧扣“Super App 来了”主题,全力探寻 AI 时代的全新变量,探索 AI 领域下一个超级应用的无限可能性。在此次大会上,跨境电商独立站 SaaS 平台店匠科技(Shoplazza)凭借“店匠跨…...