Python基础语法3
目录
1、函数
1.1、语法格式
1.2、函数返回值
1.3、变量作用域
1.4、执行过程
1.5、链式调用
1.6、嵌套调用
1.7、函数递归
1.8、参数默认值
1.9、关键字参数
2、列表
2.1、创建列表
2.2、下标访问
2.3、切片操作
2.4、遍历列表元素
2.5、新增元素
2.6、查找元素
2.7、删除元素
2.8、连接列表
3、元组
4、字典
4.1、创建字典
4.2、查找key
4.3、新增和修改元素
4.4、删除元素
4.5、遍历字典元素
4.6、合法的key类型
1、函数
编程中的函数和数学中的函数有一定的相似之处。编程中的函数,是一段可以被重复使用的代码片段。例如:
# 1. 求 1 - 100 的和
sum = 0
for i in range(1, 101):sum += i
print(sum)
# 2. 求 300 - 400 的和
sum = 0
for i in range(300, 401):sum += i
print(sum)
# 3. 求 1 - 1000 的和
sum = 0
for i in range(1, 1001):sum += i
print(sum)可以发现,这几组代码基本是相似的,只有一点点差异,可以把重复代码提取出来,做成一个函数
1.1、语法格式
定义函数:
def 函数名(形参列表):函数体return 返回值调用函数:
函数名(实参列表)函数定义并不会执行函数体内容, 必须要调用才会执行。调用几次就会执行几次。函数必须先定义,再使用。Python要求函数定义必须写在前面,函数调用写在后面。例如:
# 定义函数
def calcSum(beg, end):sum = 0for i in range(beg, end + 1):sum += iprint(sum)
# 调用函数
calcSum(1, 100)
calcSum(300, 400)
calcSum(1, 1000)一个函数可以有一个形参, 也可以有多个形参, 也可以没有形参。一个函数的形参有几个, 那么传递实参的时候也得传几个。保证个数要匹配。
和 C++ / Java 不同,Python 是动态类型的编程语言,函数的形参不必指定参数类型。换句话说, 一个函数可以支持多种不同类型的参数。例如:
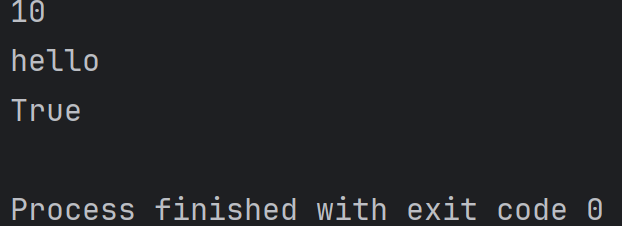
def test(a):print(a)
test(10)
test('hello')
test(True)结果为:
1.2、函数返回值
函数的参数可以视为是函数的 "输入", 则函数的返回值, 就可以视为是函数的 "输出" 。
例如:我们可以将之前的加法函数写为
def calcSum(beg, end):sum = 0for i in range(beg, end + 1):sum += ireturn sum
result = calcSum(1, 100)
print(result)这个代码与之前的代码的区别就在于,前者直接在函数内部进行了打印,后者则使用return语句把结果返回给函数调用者,再由调用者负责打印。
我们一般倾向于第二种写法,因为实际开发中我们的一个通常的编程原则是 "逻辑和用户交互分离"。 而第一种写法的函数中,既包含了计算逻辑,又包含了和用户交互(打印到控制台上),这种写法是不太好的,如果后续我们需要的是把计算结果保存到文件中,或者通过网络发送,或者展示到图形化界面里,那么第一种写法的函数,就难以胜任了。而第二种写法则专注于做计算逻辑,不负责和用户交互,那么就很容易把这个逻辑与其他代码搭配,来实现不同的效果。简单来说就是:一个函数只做一件事。
一个函数是可以一次返回多个返回值的,使用,来分割多个返回值。例如:
def getPoint():x = 10y = 20return x, y
a, b = getPoint()
print(a,b)如果只想关注其中的部分返回值,可以使用 _ 来忽略不想要的返回值。例如:
def getPoint():x = 10y = 20return x, y
_, b = getPoint()
print(b)注:Python中的一个函数可以返回多个返回值,这一点和C++与JAVA不同。
1.3、变量作用域
观察以下代码:
def getPoint():x = 10y = 20return x, y
x, y = getPoint()
print(x,y)在这个代码中, 函数内部存在 x, y, 函数外部也有 x, y。但是这两组 x, y 不是相同的变量, 而只是恰好有一样的名字。
在函数 getPoint() 内部定义的 x, y 只是在函数内部生效。一旦出了函数的范围, 这两个变量就不再生效了。例如:像下面这样写就会报错
def getPoint():x = 10y = 20return x, y
getPoint()
print(x, y)在不同的作用域中, 允许存在同名的变量,例如:
x = 20
def test():x = 10print(f'函数内部 x = {x}')
test()
print(f'函数外部 x = {x}')虽然名字相同,实际上是不同的变量。结果为:

注意:在函数内部的变量,也称为 "局部变量" 。不在任何函数内部的变量,也称为 "全局变量"。
全局变量是在整个程序中都有效的,局部变量只是在函数内部有效。
如果函数内部尝试访问的变量在局部不存在,就会尝试去全局作用域中查找。例如:
x = 20
def test():print(f'x = {x}')
test()如果是想在函数内部,修改全局变量的值,需要使用 global 关键字声明。例如:
x = 20
def test():global xx = 10print(f'函数内部 x = {x}')
test()
print(f'函数外部 x = {x}')如果此处没有 global ,则函数内部的 x = 10 就会被视为是创建一个局部变量 x,这样就和全局变量 x 不相关了。
if / while / for 等语句块不会影响到变量作用域。换而言之,在 if / while / for 中定义的变量,在语句外面也可以正常使用。例如:
for i in range(1, 10):print(f'函数内部 i = {i}')
print(f'函数外部 i = {i}')1.4、执行过程
调用函数才会执行函数体代码。不调用则不会执行。函数体执行结束(或者遇到 return 语句)。则回到函数调用位置,继续往下执行。例如:
def test():print("执行函数内部代码")print("执行函数内部代码")print("执行函数内部代码")
print("1111")
test()
print("2222")
test()
print("3333")上面的代码的执行过程还可以使用 PyCharm 自带的调试器来观察:
1、点击行号右侧的空白, 可以在代码中插入断点。
2、右键,Debug,可以按照调试模式执行代码,每次执行到断点,程序都会暂停下来。
3、使用 Step Into (F7) 功能可以逐行执行代码。
1.5、链式调用
把一个函数的返回值,作为另一个函数的参数,这种操作称为链式调用。链式调用中,先执行里面的函数,再执行外面的函数。例如:
# 判定是否是奇数
def isOdd(num):if num % 2 == 0:return Falseelse:return True
print(isOdd(10))1.6、嵌套调用
函数内部还可以调用其他的函数,这个动作称为 "嵌套调用"。一个函数里面可以嵌套调用任意多个函数。例如:
def test():print("执行函数内部代码")print("执行函数内部代码")print("执行函数内部代码")test 函数内部调用了 print 函数,这里就属于嵌套调用。
函数嵌套的过程是非常灵活的,例如:
def a():print("函数 a")
def b():print("函数 b")a()
def c():print("函数 c")b()
def d():print("函数 d")c()
d()如果把代码稍微调整,打印结果则可能发生很大变化,例如:
def a():print("函数 a")
def b():a()print("函数 b")
def c():b()print("函数 c")
def d():c()print("函数 d")
d()函数之间的调用关系,在 Python 中会使用一个特定的数据结构来表示,称为函数调用栈。每次函数调用,都会在调用栈里新增一个元素,称为栈帧。可以通过 PyCharm 调试器看到函数调用栈和栈帧。在调试状态下,PyCharm 左下角一般就会显示出函数调用栈。例如:
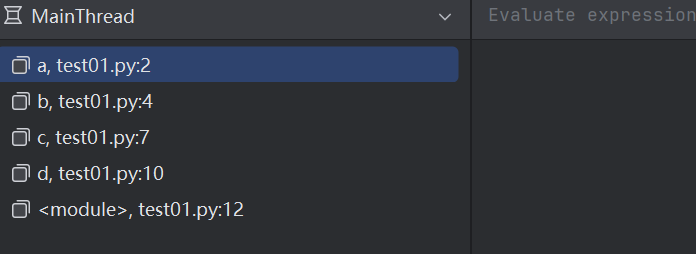
每个函数的局部变量,都包含在自己的栈帧中。调用函数则生成对应的栈帧,函数结束,则对应的栈帧消灭,里面的局部变量也就没了。例如:
def a():num1 = 10print("函数 a")
def b():num2 = 20a()print("函数 b")
def c():num3 = 30b()print("函数 c")
def d():num4 = 40c()print("函数 d")
d()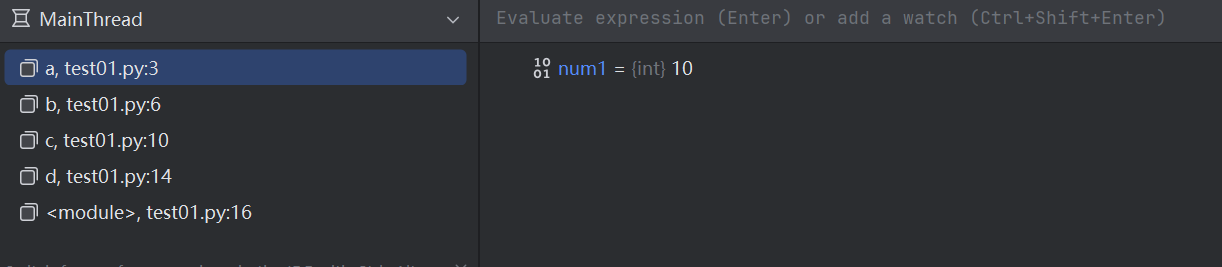
选择不同的栈帧,就可以看到各自栈帧中的局部变量。
1.7、函数递归
递归是嵌套调用中的一种特殊情况,即一个函数嵌套调用自己。例如:递归计算 5!
def factor(n):if n == 1:return 1return n * factor(n - 1)
result = factor(5)
print(result)上述代码中,就属于典型的递归操作。在 factor 函数内部,又调用了 factor 自身。
注意:递归代码务必要保证存在递归结束条件,比如 if n == 1 就是结束条件,当 n 为 1 的时候, 递归就结束了。每次递归的时候,要保证函数的实参是逐渐逼近结束条件的。
如果上述条件不能满足,就会出现 "无限递归" 。这是一种典型的代码错误。例如:
def factor(n):return n * factor(n - 1)
result = factor(5)
print(result)结果为:

如前面所描述, 函数调用时会在函数调用栈中记录每一层函数调用的信息,但是函数调用栈的空间不是无限大的,如果调用层数太多, 就会超出栈的最大范围, 导致出现问题。
递归的优点:递归类似于 "数学归纳法" ,明确初始条件和递推公式,就可以解决一系列的问题,递归代码往往代码量非常少。
递归的缺点:递归代码往往难以理解,很容易超出掌控范围。递归代码容易出现栈溢出的情况。递归代码往往可以转换成等价的循环代码。并且通常来说循环版本的代码执行效率要略高于递归版 本。
1.8、参数默认值
Python 中的函数, 可以给形参指定默认值,带有默认值的参数, 可以在调用的时候不传参。例如:
def add(x, y, debug=False):if debug:print(f'调试信息: x={x}, y={y}')return x + y
print(add(10, 20))
print(add(10, 20, True))此处 debug=False 即为参数默认值。当我们不指定第三个参数的时候,默认debug 的取值即为 False。
带有默认值的参数需要放到没有默认值的参数的后面。如果不这样做就会报错,例如:
def add(x, debug=False, y):if debug:print(f'调试信息: x={x}, y={y}')return x + y
print(add(10, 20))结果为:

如果有多个带有默认参数的形参,也是要放在后面的。
1.9、关键字参数
在调用函数的时候,需要给函数指定实参。一般默认情况下是按照形参的顺序,来依次传递实参的
但是我们也可以通过关键字参数, 来调整这里的传参顺序, 显式指定当前实参传递给哪个形参。
例如:
def test(x, y):print(f'x = {x}')print(f'y = {y}')
test(x=10, y=20)
test(y=100, x=200)形如上述 test(x=10, y=20) 这样的操作,即为关键字参数。
使用关键字参数能非常明显的告诉读代码的人参数要传递给谁。另外这种写法可以无视形参和实参的顺序。
2、列表
编程中, 经常需要使用变量, 来保存或表示数据。如果代码中需要表示的数据个数比较少, 我们直接创建多个变量即可。但是有的时候, 代码中需要表示的数据特别多, 甚至也不知道要表示多少个数据。这个时候, 就需要用到列表。
元组和列表相比, 是非常相似的, 只是列表中放哪些元素可以修改调整, 元组中放的元素是创建元组的时候就设定好的, 不能修改调整。
2.1、创建列表
创建列表主要有两种方式。alist = [ ] 和alist = list() ,其中[ ] 表示一个空的列表。例如:
alist = [ ] #使用列表字面值来创建列表
blist = list() #使用list()函数来创建列表
print(type(alist))
print(type(blist))注:列表的类型为list。
如果需要往里面设置初始值,可以直接写在 [ ] 当中。可以直接使用 print 来打印 list 中的元素内容
alist = [1, 2, 3, 4]
print(alist)列表中存放的元素允许是不同的类型,这一点和 C++ Java 差别较大。例如:
alist = [1, 'hello', True]
print(alist)注:列表内还可以放列表类型的元素。
注:因为 list 本身是 Python 中的内建函数, 不宜再使用 list 作为变量名, 因此命名为alist。
2.2、下标访问
可以通过下标访问操作符 [ ] 来获取到列表中的任意元素。我们把 [ ] 中填写的数字, 称为下标或者索引。例如:
alist = [1, 2, 3, 4]
print(alist[2])注意:下标是从 0 开始计数的, 因此下标为 2 , 则对应着 3 这个元素。
通过下标不光能读取元素内容, 还能修改元素的值,如果下标超出列表的有效范围, 会抛出异常。
alist = [1, 2, 3, 4]
print(alist[100])结果为:
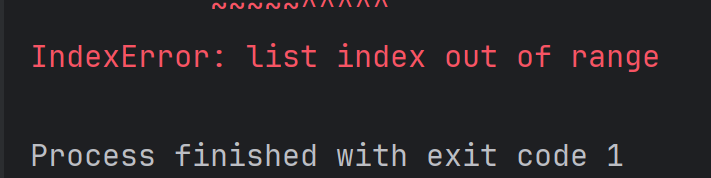
因为下标是从 0 开始的, 因此下标的有效范围是 [0, 列表长度 - 1]。使用 len函数可以获取列表的元素个数。例如:
alist = [1, 2, 3, 4]
print(len(alist))下标可以取负数,表示 "倒数第几个元素"。
alist = [1, 2, 3, 4]
print(alist[3])
print(alist[-1])alist[-1] 相当于alist[len(alist) - 1]。
2.3、切片操作
通过下标操作是一次取出里面第一个元素。通过切片, 则是一次取出一组连续的元素, 相当于得到一个子列表。列表的切片操作是一个比较高效的操作,进行切片时,只是取出原有列表的一部分,并不涉及到数据的拷贝。
1、使用 [ : ] 的方式进行切片操作。例如:
alist = [1, 2, 3, 4]
print(alist[1:3])结果为:
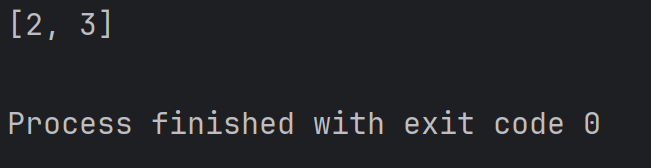
其中,alist[1:3] 中的 1:3 表示的是 [1, 3) 这样的由下标构成的前闭后开区间。也就是从下标为 1 的元素开始(2), 到下标为 3 的元素结束(4), 但是不包含下标为 3 的元素。
2、切片操作中可以省略前后边界。例如:
alist = [1, 2, 3, 4]
print(alist[1:])
print(alist[:-1])
print(alist[:]) 结果为:
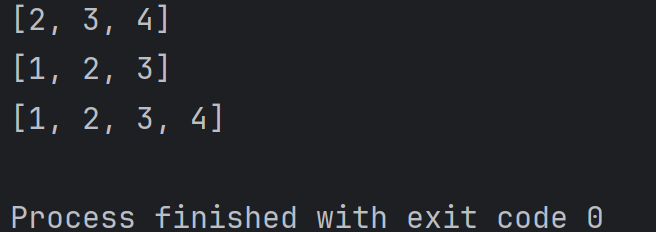
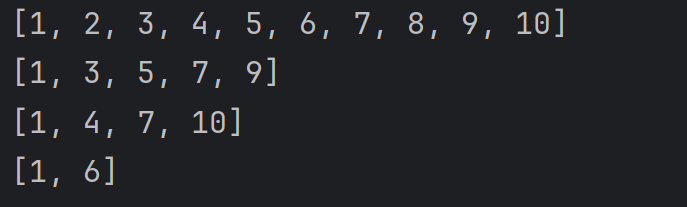
3、切片操作还可以指定 "步长" , 也就是 "每访问一个元素后, 下标自增几步"。例如:
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(alist[::1])
print(alist[::2])
print(alist[::3])
print(alist[::5])结果为:
4、切片操作指定的步长还可以是负数, 此时是从后往前进行取元素。表示 "每访问一个元素之后, 下标自减几步"。例如:
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(alist[::-1])
print(alist[::-2])
print(alist[::-3])
print(alist[::-5])结果为:

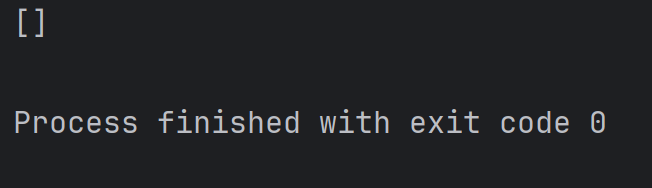
注:如果切片中填写的数字越界了, 不会出现异常,只会尽可能的把满足条件的元素给获取到。例如:
alist = [1, 2, 3, 4]
print(alist[100:200])结果为:
2.4、遍历列表元素
"遍历" 指的是把元素一个一个的取出来。
1、最简单的办法就是使用 for 循环,例如:
alist = [1, 2, 3, 4]
for elem in alist:print(elem)也可以使用 for 按照范围生成下标, 按下标访问,例如:
alist = [1, 2, 3, 4]
for i in range(0, len(alist)):print(alist[i])2、还可以使用 while 循环,手动控制下标的变化,例如:
alist = [1, 2, 3, 4]
i = 0
while i < len(alist):print(alist[i])i += 12.5、新增元素
使用 append 方法, 向列表末尾插入一个元素(尾插)。例如:
alist = [1, 2, 3, 4]
alist.append('hello')
print(alist)使用 insert 方法, 向任意位置插入一个元素,insert 第一个参数表示要插入元素的下标。例如:
alist = [1, 2, 3, 4]
alist.insert(1, 'hello')
print(alist)另外,如果插入的下标越界的话,不会出现异常,而是把要插入的元素进行尾插,例如:
alist = [1, 2, 3, 4]
alist.insert(100, 'hello')
print(alist)注:方法其实就是函数,只不过函数是独立存在的,而方法往往要依附于某个 "对象"。像上述代码 alist.append , append 就是依附于 alist,而不是作为一个独立的函数,相当于是 "针对 alist 这个列表, 进行尾插操作"。type,print,input等都是独立的函数,不用搭配其他的东西就能使用。
2.6、查找元素
使用 in 操作符, 判定元素是否在列表中存在,返回值是布尔类型,例如:
alist = [1, 2, 3, 4]
print(2 in alist)
print(10 in alist)
print(2 not in alist) #逻辑取反,结果为False使用 index 方法, 查找列表中的元素,返回值是一个整数,这个整数也就是查找到的元素的下标,如果元素不存在, 则会抛出异常,例如:
alist = [1, 2, 3, 4]
print(alist.index(2))
print(alist.index(10)) #会发生异常2.7、删除元素
使用 pop 方法删除最末尾元素,例如:
alist = [1, 2, 3, 4]
alist.pop()
print(alist)pop 也能按照下标来删除元素,例如:
alist = [1, 2, 3, 4]
alist.pop(2)
print(alist)使用 remove 方法, 按照元素值删除元素。例如:
alist = [1, 2, 3, 4]
alist.remove(2)
print(alist)2.8、连接列表
使用 + 能够把两个列表拼接在一起。此处的 + 结果会生成一个新的列表,而不会影响到旧列表的内容。例如:
alist = [1, 2, 3, 4]
blist = [5, 6, 7]
print(alist + blist)使用 extend 方法, 相当于把一个列表拼接到另一个列表的后面。a.extend(b) , 是把 b 中的内容拼接到 a 的末尾,不会修改 b, 但是会修改 a。例如:
alist = [1, 2, 3, 4]
blist = [5, 6, 7]
alist.extend(blist)
print(alist)
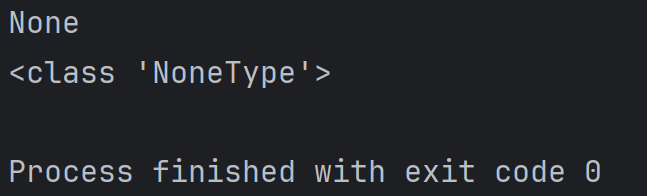
print(blist)注意:None在Python中是一个特殊的变量值,表示啥都没有。拿一个变量接收没有返回值的方法的返回值,这个变量的结果就为None,类型为Nonetype。例如:
alist = [1, 2, 3, 4]
blist = [5, 6, 7]
a=alist.extend(blist)
print(a)
print(type(a))结果为:
3、元组
元组的功能和列表相比, 基本是一致的,元组使用 ( ) 来表示。元组的类型为tuple,例如:
atuple = ( )
atuple = tuple()元组不能修改里面的元素, 列表则可以修改里面的元素。
因此,像读操作,比如访问下标,切片,遍历,in,index,+ 等,元组也是一样支持的。但是,像写操作,比如修改元素,新增元素,删除元素,extend 等,元组则不能支持。
另外, 元组在 Python 中很多时候是默认的集合类型。例如, 当一个函数返回多个值的时候。
def getPoint():return 10, 20
result = getPoint()
print(type(result))结果为:
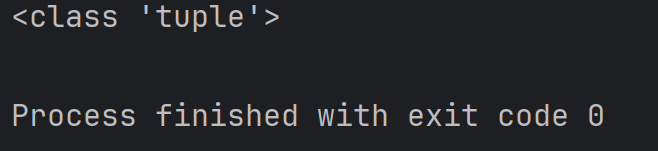
此处的 result 的类型,其实就是元组。
问题来了, 既然已经有了列表, 为啥还需要有元组?
元组相比于列表来说, 优势有两方面:
1、比如有一个列表, 现在需要调用一个函数进行一些处理,但是你有不是特别确认这个函数是否会修改你列表的数据,那么这时候传一个元组就安全很多。
2、我们马上要说的字典, 是一个键值对结构,要求字典的键必须是 "可hash对象" (字典本质上也 是一个hash表),而一个可hash对象的前提就是不可变,因此元组可以作为字典的键, 但是列表不行。
4、字典
字典是一种存储键值对的结构。把键(key)和值(value) 进行一个一对一的映射,这就是键值对,然后就可以根据键,快速找到值。
4.1、创建字典
创建一个空的字典,使用 { } 表示字典,字典的类型为dict,例如:
a = { }
b = dict()
print(type(a))
print(type(b))也可以在创建的同时指定初始值,键值对之间使用,分割,键和值之间使用 : 分割。冒号后面推荐加一个空格。例如:
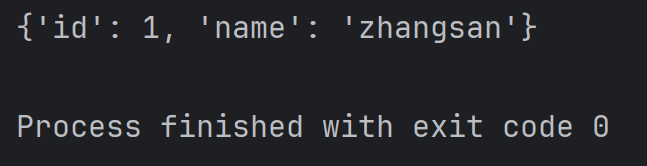
student = { 'id': 1, 'name': 'zhangsan' }
print(student)结果为:
注意:字典的key是不能重复的。
为了代码更规范美观, 在创建字典的时候往往会把多个键值对, 分成多行来书写。例如:
student = {'id': 1,'name': 'zhangsan'
}最后一个键值对,后面可以写,也可以不写,例如:
student = {'id': 1,'name': 'zhangsan',
}4.2、查找key
使用 in 可以判定 key 是否在字典中存在,返回布尔值,但是不能使用in判断value是否在字典中。例如:
student = {'id': 1,'name': 'zhangsan'
}
print('id' in student)
print('score' in student)使用 [ ] 通过类似于取下标的方式,获取到元素的值,只不过此处的 "下标" 是 key。(可能是整数, 也可能是字符串等其他类型)。
student = {'id': 1,'name': 'zhangsan',
}
print(student['id'])
print(student['name'])如果 key 在字典中不存在,则会抛出异常。例如:
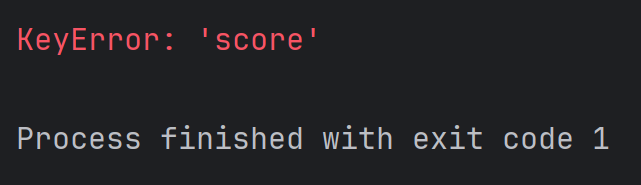
student = {'id': 1,'name': 'zhangsan',
}
print(student['score'])结果为:
4.3、新增和修改元素
使用 [ ] 可以根据 key 来新增/修改 value。
如果 key 不存在, 对取下标操作赋值, 即为新增键值对,例如:
student = {'id': 1,'name': 'zhangsan',
}
student['score'] = 90
print(student)如果 key 已经存在, 对取下标操作赋值, 即为修改键值对的值。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
student['score'] = 90
print(student)4.4、删除元素
使用 pop 方法根据 key 删除对应的键值对。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
student.pop('score')
print(student)4.5、遍历字典元素
直接使用 for 循环能够获取到字典中的所有的 key, 进一步的就可以取出每个值了。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
for key in student:print(key, student[key])注:在C++和JAVA中,哈希表里面的键值对的存储是无序的,Python中做了特殊处理,能够保证遍历出来的顺序,就是和插入的顺序一致的。Python中的字典不是一个单纯的哈希表。
使用 keys 方法可以获取到字典中的所有的 key,例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
print(student.keys())结果为:
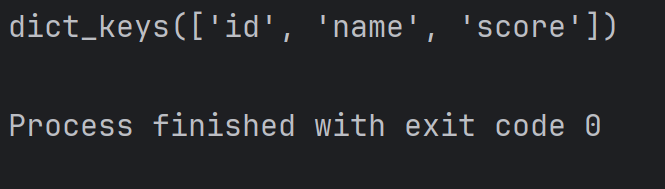
注:此处 dict_keys 是一个特殊的类型,专门用来表示字典的所有 key,这是一个自定义类型,返回的结果看起来像列表,又不完全是,但使用的时候也可以把他当作一个列表来使用。
使用 values 方法可以获取到字典中的所有 value,例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
print(student.values())结果为:
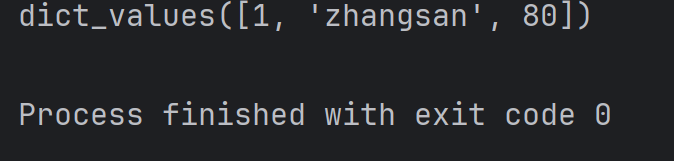
注:此处 dict_values 也是一个特殊的类型, 和 dict_keys 类似。
使用 items 方法可以获取到字典中所有的键值对。例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
print(student.items())结果为:

注:此处 dict_items 也是一个特殊的类型,首先是一个列表一样的结构,里面每个元素又是一个元组,元组里面包含了键和值。
我们还可以这样遍历字典元素,例如:
student = {'id': 1,'name': 'zhangsan','score': 80
}
for key,value in student.items():print(key,value)4.6、合法的key类型
不是所有的类型都可以作为字典的 key。字典本质上是一个 哈希表,哈希表的 key 要求是 "可哈希的",也就是可以计算出一个哈希值。
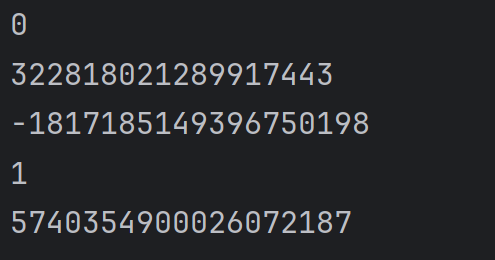
可以使用 hash 函数计算某个对象的哈希值。但凡能够计算出哈希值的类型,都可以作为字典的 key。例如:
print(hash(0))
print(hash(3.14))
print(hash('hello'))
print(hash(True))
print(hash(()))结果为:
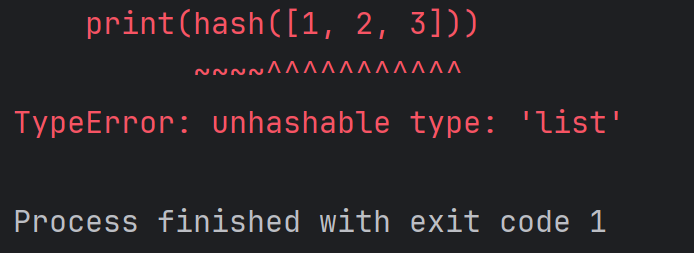
注意:列表无法计算哈希值,字典也无法计算哈希值,例如:
print(hash([1, 2, 3]))结果为:
再比如:
print(hash({ 'id': 1 }))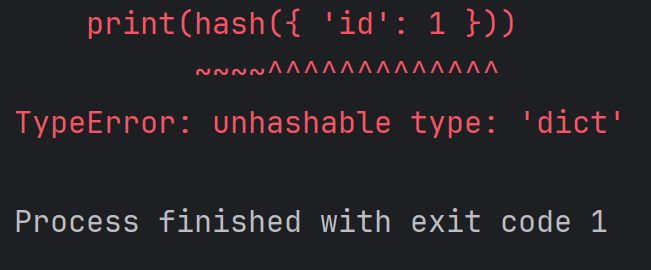
注:不可变的对象,一般就是可哈希的;可变的对象一般就是不可哈希的。
相关文章:
Python基础语法3
目录 1、函数 1.1、语法格式 1.2、函数返回值 1.3、变量作用域 1.4、执行过程 1.5、链式调用 1.6、嵌套调用 1.7、函数递归 1.8、参数默认值 1.9、关键字参数 2、列表 2.1、创建列表 2.2、下标访问 2.3、切片操作 2.4、遍历列表元素 2.5、新增元素 2.6、查找元…...

Vue 3中如何封装API请求:提升开发效率的最佳实践
在现代前端开发中,API请求是不可避免的一部分,尤其是与后端交互时。随着Vue 3的广泛应用,如何高效地封装API请求,既能提升代码的可维护性,又能确保代码的高复用性,成为了很多开发者关注的话题。 在本文中&…...
)
GitHub 趋势日报 (2025年04月17日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1Anduin2017/HowToCook程序员在家做饭方法指南。Programmer’s guide about how to cook at home (Simplified Chinese onl…⭐ 224…...

第5章-1 优化服务器设置
上一篇:《第4章-5 linux 网络管理》,接着服务器设置 本章我们将解释如何为MySQL服务器创建合适的配置文件。这是一个迂回的旅程,有许多兴趣点和可以俯瞰风景的短途旅程。这些短途旅程是必要的。确定合适配置的最短路径并不是从研究配置选项并…...

【AI】Windows环境安装SPAR3D单图三维重建心得
效果一览 左图为原始单个图像,右图为通过SPAR3D重建后的三维建模,可以看出效果还是不错的。 本地环境配置 系统:Windows 11 专业版CPU:i5-13400F内存:32GBGPU:RTX3060 12GBcuda:11.8conda&…...

桌面应用UI开发方案
一、基于 Web 技术的跨平台方案 Electron Python/Go 特点: 技术栈:前端使用 HTML/CSS/JS,后端通过 Node.js 集成 Python/Go 模块或服务。 跨平台:支持 Windows、macOS、Linux 桌面端,适合开发桌面应用。 生态成熟&…...
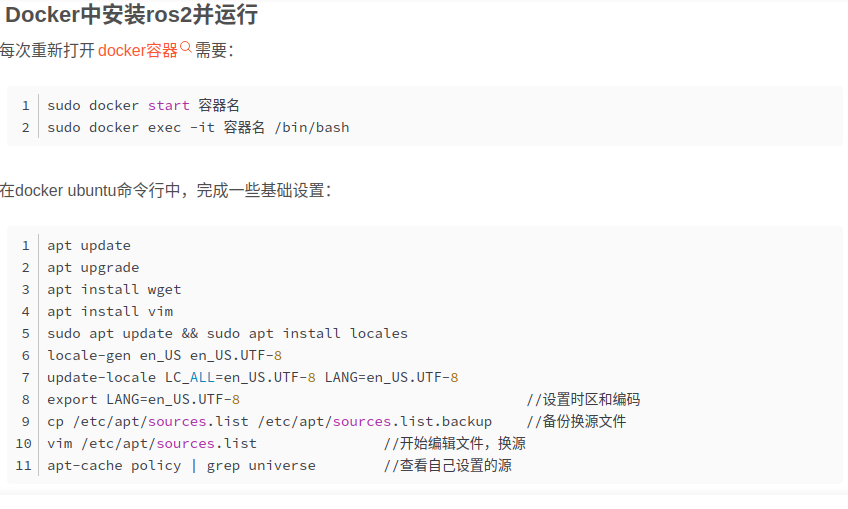
使用docker在manjaro linux系统上运行windows和ubuntu
因为最近项目必须要使用指定版本的solidworks和maxwell(都只能在win系统上使用), 且目前的ubuntu容器是没有桌面的,导致我运行不了一些带图形的ros2功能。无奈之下,决定使用docker-compose写一下配置文件,彻底解决问题…...

Agent智能体ReAct机制深度解读:推理与行动的完美闭环
一、从Chain-of-Thought到ReAct的范式演进 1.1 传统决策机制的局限 #mermaid-svg-Jf3ygvgHcGciJvX8 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Jf3ygvgHcGciJvX8 .error-icon{fill:#552222;}#mermaid-svg-Jf3y…...

在 Node.js 中使用原生 `http` 模块,获取请求的各个部分:**请求行、请求头、请求体、请求路径、查询字符串** 等内容
在 Node.js 中使用原生 http 模块,可以通过 req 对象来获取请求的各个部分:请求行、请求头、请求体、请求路径、查询字符串 等内容。 ✅ 一、基础结构 const http require(http); const url require(url);const server http.createServer((req, res)…...

Redis(01)Redis连接报错Redis is running in protected mode……的解决方案
一、引言:从一个典型连接错误说起 在分布式系统开发中,Redis 作为高性能缓存中间件被广泛使用。 然而,当我们首次部署 Redis 并尝试从外部客户端连接时,常常会遇到以下错误: DENIED Redis is running in protected m…...
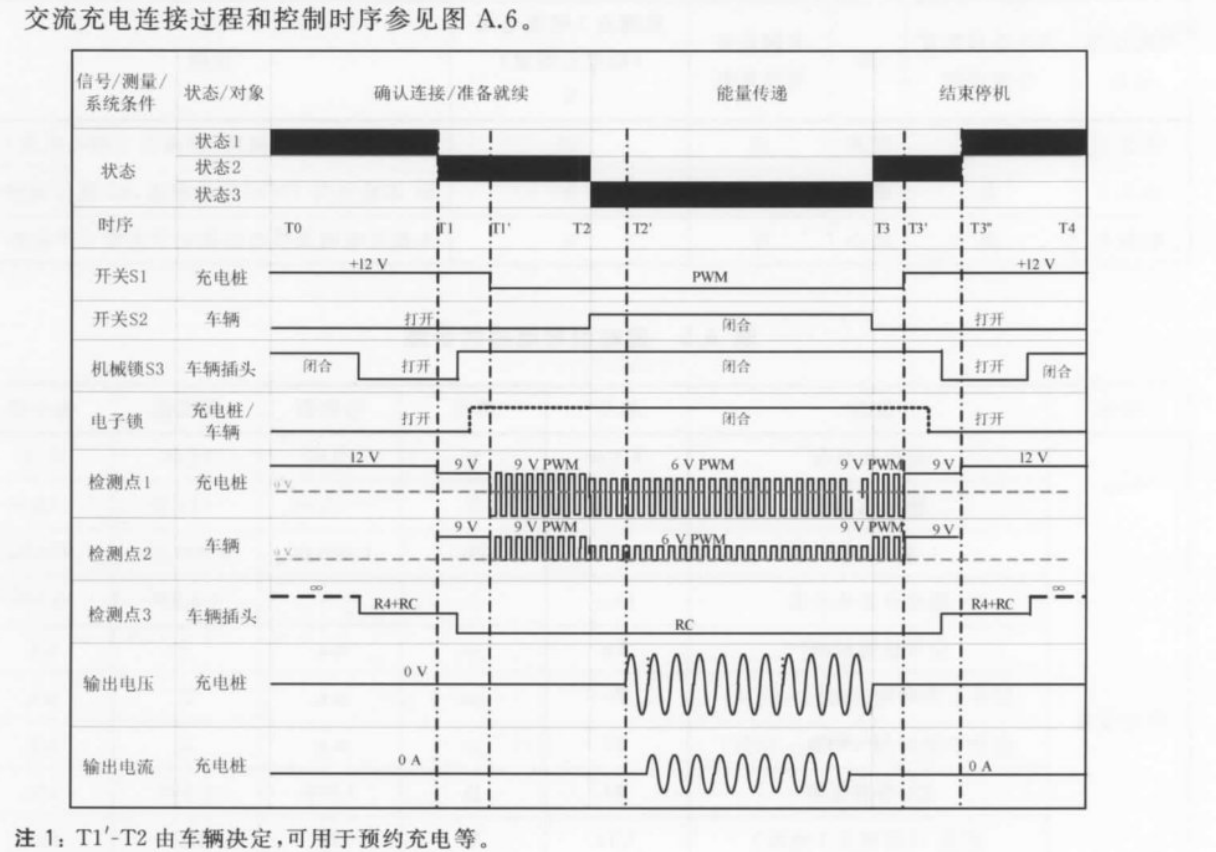
18487.1-2015-解读笔记之四-交流充电之流程分析
前面简单分析了国标交流充电桩插枪监测逻辑和PWM控制逻辑,下面简单分析一下交流充电流程 附录A 交流充电连接过程和控制时序如下: 由此可以将充电流程大概分为几个阶段: 1.充电连接阶段 充电连接阶段CC(电阻由无穷大到R4RC&…...

海外服务器安装Ubuntu 22.04图形界面并配置VNC远程访问指南
在云计算和远程工作日益普及的今天,如何高效地管理和使用海外服务器成为了一个热门话题。本文将详细介绍如何在海外的Ubuntu 22.04服务器上安装图形界面,并配置VNC服务来实现远程访问。无论您是开发者、系统管理员,还是只是想要更便捷地管理您的海外服务器,这篇指南都能为您…...
Linux 管道理解
一、什么是管道 1.1 unix中最古老的进程间通信 1.2 一个进程链接到另一个进程的数据流称为“管道”: 图解: 二、管道通信的原理 2.1当我们创建一个进程然后打开一个文件的时候 会经过以下步骤: ①首先要描述这个进程,为这个…...

国产RK3568+FPGA以 “实时控制+高精度采集+灵活扩展” 为核心的解决方案
RK3568FPGA方案在工业领域应用的核心优势 一、实时性与低延迟控制 AMP架构与GPIO中断技术 通过非对称多处理架构(AMP)实现Linux与实时操作系统(RTOS/裸机)协同,主核负责调度,从核通过GPIO中断响应紧…...
Pycharm(十五)面向对象程序设计基础
目录 一、面向对象基本概述 class 类名: 属性(类似于定义变量) 行为(类似于定义函数,只不过第一个形参要写self) 二、self关键字介绍 三、在类内部调用类中的函数 四、属性的定义和调用 五、魔法方法init方法 六、魔法方法str和del方法 七、案例-减肥 一、…...

华三(H3C)与华为(Huawei)设备配置IPsec VPN的详细说明,涵盖配置流程、参数设置及常见问题处理
以下是针对华三(H3C)与华为(Huawei)设备配置IPsec VPN的详细说明,涵盖配置流程、参数设置及常见问题处理: 一、华三(H3C)设备IPsec VPN配置详解 1. 配置流程 华三IPsec VPN配置主要…...

【消息队列RocketMQ】四、RocketMQ 存储机制与性能优化
一、RocketMQ 存储机制详解 1.1 存储文件结构 RocketMQ 的存储文件主要分布在store目录下,该目录是在broker.conf配置文件中通过storePathRootDir参数指定的,默认路径为${user.home}/store 。主要包含以下几种关键文件类型: 1.1.1 Comm…...

结合地理数据处理
CSV 文件不仅可以存储表格数据,还可以与地理空间数据结合,实现更强大的地理处理功能。例如,你可以将 CSV 文件中的坐标数据转换为点要素类,然后进行空间分析。 示例:将 CSV 文件中的坐标数据转换为点要素类 假设我们有…...

店匠科技摘得 36 氪“2025 AI Partner 创新大奖”
全场景 AI 方案驱动跨境电商数智化跃迁 4 月 18 日,36 氪 2025 AI Partner 大会于上海盛大开幕。大会紧扣“Super App 来了”主题,全力探寻 AI 时代的全新变量,探索 AI 领域下一个超级应用的无限可能性。在此次大会上,跨境电商独立站 SaaS 平台店匠科技(Shoplazza)凭借“店匠跨…...
Joint communication and state sensing under logarithmic loss
摘要——我们研究一种基本的联合通信与感知设置,其中发射机希望向接收机传输一条消息,并同时通过广义反馈估计其信道状态。我们假设感知目标是获得状态的软估计(即概率分布),而非通常假设的点估计;并且我们…...

测试基础笔记第十天
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、查询语句1.基本查询2.条件查询3.模糊查询4.范围查询5.判断空 二、其他复杂查询1.排序2.聚合函数3.分组4.分页查询 一、查询语句 1.基本查询 – 需求1: 准备商…...

Geek强大的电脑卸载软件工具,免费下载
一款强大的卸载电脑软件工具,无需安装 免费下载...

Linux:41线程控制lesson29
1.线程的优点: • 创建⼀个新线程的代价要⽐创建⼀个新进程⼩得多 创建好线程只要调度就好了 • 与进程之间的切换相⽐,线程之间的切换需要操作系统做的⼯作要少很多 为什么? ◦ 最主要的区别是线程的切换虚拟内存空间依然是相同的&#x…...

基于Flask与Ngrok实现Pycharm本地项目公网访问:从零部署
目录 概要 1. 环境与前置条件 2. 安装与配置 Flask 2.1 创建虚拟环境 2.2 安装 Flask 3. 安装与配置 Ngrok 3.1 下载 Ngrok 3.2 注册并获取 Authtoken 4. 在 PyCharm 中创建 Flask 项目 5. 运行本地 Flask 服务 6. 启动 Ngrok 隧道并获取公网地址 7. 完整示例代码汇…...

Ai晚报20250423
Kortix 发布全球首个开源通用型 AI Agent——Suna,能像人类一样学习、推理和适应,通过自然对话帮助用户完成多种现实任务,支持浏览器自动化、文件管理等 20 个用户场景。腾讯混元大模型 AI 阅读助手“企鹅读伴”正式上线,为中小学…...

密码学货币混币器详解及python实现
目录 一、前言二、混币器概述2.1 混币器的工作原理2.2 关键特性三、数据生成与预处理四、系统架构与流程五、核心数学公式六、异步任务调度与 GPU 加速七、PyQt6 GUI 设计八、完整代码实现九、自查测试与总结十、展望摘要 本博客聚焦 “密码学货币混币器实现”,以 Python + P…...
HTMLCSS实现网页轮播图
网页中轮播图区域的实现与解析 在现代网页设计中,轮播图是一种常见且实用的元素,能够在有限的空间内展示多个内容,吸引用户的注意力。下面将对上述代码中轮播图区域的实现方式进行详细介绍。 一、HTML 结构 <div class"carousel-c…...

如何确定置信水平的最佳大小
在统计学中,置信水平的选择并不是一成不变的,而是根据具体的研究目的、样本量、数据类型以及行业标准等因素来确定的。然而,在大多数情况下,95%的置信水平是最常用的。 选择95%置信水平的原因 平衡可靠性与精确性: •…...

Java基础第21天-正则表达式
正则表达式是对字符串执行模式匹配的技术 如果想灵活的运用正则表达式,必须了解其中各种元字符的功能,元字符从功能上大致分为: 限定符选择匹配符分组组合和反向引用符特殊字符字符匹配符定位符 转义号\\:在我们使用正则表达式去检索某些特…...

Maven 项目中引入本地 JAR 包
在日常开发过程中,我们有时会遇到一些未上传到 Maven 中央仓库或公司私有仓库的 JAR 包,比如第三方提供的 SDK 或自己编译的库。这时候,我们就需要将这些 JAR 包手动引入到 Maven 项目中。本文将介绍两种常见方式:将 JAR 安装到本…...