前端渲染pdf文件解决方案-pdf.js
目录
一、前言
二、简介
1、pdf.js介绍
2、插件版本参数
三、通过viewer.html实现预览(推荐)
1、介绍
2、部署
【1】下载插件包
【2】客户端方式
【3】服务端方式(待验证)
3、使用方法
【1】预览PDF文件
【2】外部搜索条件触发pdf.js的搜索逻辑
四、把pdf渲染为canvas实现预览
1、安装
2、功能实现
【1】实现pdf预览
【2】实现pdf内容文本可选进行复制
【3】实现搜索,匹配内容高亮,并且可以跳转至匹配内容的位置
【4】获取pdf文件中目录的数据结构
一、前言
在前端开发中,渲染PDF文件一直是一项重要而挑战性的任务。而今,我们可以借助pdf.js库来轻松实现这一目标。pdf.js是一个开源的JavaScript库,它可以在浏览器中渲染PDF文件,实现了在网页上查看PDF文档的功能。它提供了丰富的API和功能,使得在前端页面展示PDF文件变得轻而易举。让我们一起探索pdf.js的奇妙之处,轻松实现前端PDF文件的渲染与展示吧!
二、简介
1、pdf.js介绍
pdf.js是一款基于JavaScript的开源PDF阅读器组件,可以在网页中直接显示和操作PDF文件,目前已知的前端渲染pdf组件都是基于pdf.js进行封装。
git地址:https://github.com/mozilla/pdf.js
注:开源且免费
2、插件版本参数
| 插件 | 版本 |
| Node | v22.13.0 |
| @types/react | ^18.0.33 |
| @types/react-dom | ^18.0.11 |
| pdfjs-2.5.207-es5-dist.zip (viewer.js使用方式) | 2.5.207 |
| pdfjs-dist (canvas渲染方式) | 3.6.172 |
三、通过viewer.html实现预览(推荐)
1、介绍
除了PDF预览,还待配套的工具栏,支持功搜索、缩放、目录、打印等功能~
Demo如图:

2、部署
【1】下载插件包
下载地址:https://github.com/mozilla/pdf.js/releases/tag/v2.5.207

【2】客户端方式
把下载后的pdfjs-2.5.207-es5-dist.zip解压后,放在项目中的public文件夹下
【3】服务端方式(待验证)
可将pdf.js包 放到服务器上 如:http://[ip]:[port]/static/pdfjs
3、使用方法
【1】预览PDF文件
1)客户端方式(基于React框架为例)
const viewPDF: React.FC = () => {// pdf文件路径,放在项目的public目录下const pdfUrl = '/A.pdf'; //pdf.js库的代码,放在项目的public目录下const pdfServerUrl = '/pdfjs-2.5.207-es5-dist/web/viewer.html'const url = `${pdfServerUrl}?file=${pdfUrl}`return <><h1>pdf 搜索(基于pdf-dist,pdf_viewer.html)</h1><iframe id='pdfIframe' src={url} width="100%" height="100%"></iframe></>;
}2)服务端方式(待整理)
【2】外部搜索条件触发pdf.js的搜索逻辑
- 跳转至第一个匹配的内容
- 匹配内容高亮
const viewPDF: React.FC = () => {// pdf文件路径,放在项目的public目录下const pdfUrl = '/A.pdf'; //pdf.js库的代码,放在项目的public目录下const pdfServerUrl = '/pdfjs-2.5.207-es5-dist/web/viewer.html'const url = `${pdfServerUrl}?file=${pdfUrl}`let pdfContentWindow: any = null; //缓存iframContentconst getPdfContent = () => {const pdfFrame: any = document.getElementById('pdfIframe');if (!pdfFrame) {return;}pdfContentWindow = pdfFrame.contentWindow;//pdf组件部分信息,包括:当前页码、总共页码等console.log('page===>', pdfContentWindow.PDFViewerApplication); }const onSearchForOut = (searchText: string) => {pdfContentWindow.postMessage(searchText, '*');pdfContentWindow.addEventListener('message', (e: any) => {// 高亮匹配结果pdfContentWindow.PDFViewerApplication.findBar.findField.value = e.data;pdfContentWindow.PDFViewerApplication.findBar.highlightAll.checked = true; pdfContentWindow.PDFViewerApplication.findBar.dispatchEvent('highlightallchange');//触发搜索项‘下一个’事件pdfContentWindow.PDFViewerApplication.findBar.dispatchEvent('again', false);}, false);}useEffect(() => {getPdfContent();setTimeout(() => {// 外部的搜索条件onSearchForOut('阳区CBD核心区')}, 3* 1000)}, []); return <><h1>pdf 搜索(基于pdf-dist,pdf_viewer.html)</h1><iframe id='pdfIframe' src={url} width="100%" height="100%"></iframe></>;
}四、把pdf渲染为canvas实现预览
1、安装
npm install pdfjs-dist --save2、功能实现
【1】实现pdf预览
import { Button } from 'antd';
import { useState, useEffect, useRef } from 'react';
import * as pdfjsLib from 'pdfjs-dist'; // 引入pdfjs-dist
const pdfUrl = '/zyk.pdf'; // pdf 文件路径,pdf文件存放于public目录下
const workerUrl = `/pdf.worker.min.js`; //webworker存放于public目录下
pdfjsLib.GlobalWorkerOptions.workerSrc = workerUrl;const viewPdf = (props: {height: string}) => {const {height} = props;const pdfContainerRef = useRef<any>(null);const [pagesList, setPagesList] = useState<any>([]);const scale = 2; // 缩放比例// 渲染单个页面const renderPage = async (page: any, pageNumber: number) => {const viewport = page.getViewport({ scale });const pageContentDom = document.createElement('div');pageContentDom.id = `pdfPage-content-${pageNumber}`;pageContentDom.style.width = `${viewport.width}px`;pageContentDom.style.height = `${viewport.height}px`;pageContentDom.style.position = 'relative';// 创建 Canvas 元素const canvas = document.createElement('canvas');const context = canvas.getContext('2d');canvas.id=`pdfPage-${pageNumber}`canvas.width = viewport.width;canvas.height = viewport.height;canvas.style.border = '1px solid black';pageContentDom.appendChild(canvas);pdfContainerRef.current.appendChild(pageContentDom);// 渲染 PDF 页面到 Canvasawait page.render({canvasContext: context,viewport,}).promise;};// 渲染 PDF 页面const renderPagesGroup = ( pages: any) => {pages.forEach(({page}:any, index: number) => {renderPage(page, index);});};// 加载 PDF 文件const loadPdf = async (url: any) => {const pdf = await pdfjsLib.getDocument(url).promise;const pages: any[] = [];for (let i = 1; i <= pdf.numPages; i++) {const page = await pdf.getPage(i);const textContent = await page.getTextContent();pages.push({page,textContent});}setPagesList(pages);renderPagesGroup(pages);};useEffect(() => {loadPdf(pdfUrl);}, []);return <><div><h1>PDF 搜索(基于@pdfjs-dist-自定义实现)</h1> <div><div style={{ height: height || '500px' }}>{/* PDF 容器 */}<div ref={pdfContainerRef} style={{ position: 'relative', height: '100%', overflowY: 'scroll' }} /></div></div></div></>
};export default viewPdf;
【2】实现pdf内容文本可选进行复制
...
//基于“【1】实现pdf预览”代码, 修改renderPage方法// 渲染单个页面const renderPage = async (page: any, pageNumber: number) => {const viewport = page.getViewport({ scale });const pageContentDom = document.createElement('div');pageContentDom.id = `pdfPage-content-${pageNumber}`;//add-begin: 文本可选则 为了文本层和canvas层重叠,利用组件库的类名(类名不能修改)pageContentDom.className = 'pdfViewer';pageContentDom.style.setProperty('--scale-factor', scale as any);//add-end: 文本可选则pageContentDom.style.width = `${viewport.width}px`;pageContentDom.style.height = `${viewport.height}px`;pageContentDom.style.position = 'relative';// 创建 Canvas 元素const canvas = document.createElement('canvas');const context = canvas.getContext('2d');canvas.id=`pdfPage-${pageNumber}`canvas.width = viewport.width;canvas.height = viewport.height;canvas.style.border = '1px solid black';pageContentDom.appendChild(canvas);createHeightLightCanvas(viewport, pageNumber, pageContentDom);pdfContainerRef.current.appendChild(pageContentDom);// 渲染 PDF 页面到 Canvasawait page.render({canvasContext: context,viewport,}).promise;//add-begin: 文本可选则const textLayerDiv = document.createElement('div');textLayerDiv.style.width = viewport.width;textLayerDiv.style.height = viewport.height;//为了文本层和canvas层重叠,利用组件库的类名textLayerDiv.className = 'textLayer';const textContent = await page.getTextContent();pdfjsLib.renderTextLayer({textContentSource: textContent,container: textLayerDiv,viewport: viewport,textDivs: [],});pageContentDom.appendChild(textLayerDiv);//add-end: 文本可选则};
【3】实现搜索,匹配内容高亮,并且可以跳转至匹配内容的位置
import { Button } from 'antd';
import { useState, useEffect, useRef } from 'react';
import * as pdfjsLib from 'pdfjs-dist'; // 引入pdfjs-dist
const pdfUrl = '/zyk.pdf'; // pdf 文件路径,pdf文件存放于public目录下
const workerUrl = `/pdf.worker.min.js`; //webworker存放于public目录下
pdfjsLib.GlobalWorkerOptions.workerSrc = workerUrl;const viewPdf = (props: {height: string}) => {const {height} = props;const [searchText, setSearchText] = useState('');const pdfContainerRef = useRef<any>(null);const [pagesList, setPagesList] = useState<any>([]);const [matchList, setMatchList] = useState<any>([]);const scale = 2; // 缩放比例const createHeightLightCanvas = (viewport: any, pageNumber: number, parentDom: any) => {// 为每页创建一个高亮层canvasconst highlightCanvas = document.createElement('canvas');highlightCanvas.id = `highlightCanvas-${pageNumber}`;highlightCanvas.className = 'highlightCanvas';highlightCanvas.width = viewport.width;highlightCanvas.height = viewport.height;highlightCanvas.style.position = 'absolute';highlightCanvas.style.top = '0';highlightCanvas.style.left = '0';highlightCanvas.style.zIndex = '1';parentDom.appendChild(highlightCanvas);}// pageNumber 页码(从0开始)const jumpToPage = (pageIndex: number) => {let beforeCanvasHeight = 0;for (let i = 0; i < pageIndex; i++) {const canvasParentDom = pdfContainerRef.current.querySelector(`#pdfPage-content-${i}`);let canvasParentHeight = canvasParentDom.style.height.replace('px', '');beforeCanvasHeight += Number(canvasParentHeight);}pdfContainerRef.current.scrollTo({top: beforeCanvasHeight, // 垂直滚动位置behavior: 'smooth'});}const getCurrentTextContentY = (canvas: any, match: any) => {// pdfjs 坐标系原点在左下角。transform[5]代表y轴的基线,所以需要减去高度const {textBlock} = match;const { transform, height } = textBlock;return canvas.height - (transform[5] + height -2) * scale;}// 滚动到指定的匹配项const scrollToMatch = (match: any) => {const { pageIndex, matchList } = match;const firstMatchContent = matchList[0];// 获取滚动区域的高度const scrollHeight = pdfContainerRef.current.scrollHeight;console.log('滚动区域的高度:', scrollHeight);// 获取当前页码之前dom的高度let beforePageHeight = 0;for (let i = 0; i < pageIndex; i++) {const canvasParentDom = pdfContainerRef.current.querySelector(`#pdfPage-content-${i}`);let canvasParentHeight = canvasParentDom.style.height.replace('px', '');beforePageHeight += Number(canvasParentHeight);}// todo 继续计算 匹配项目的高度const currentPageCanvas = pdfContainerRef.current.querySelector(`#pdfPage-${pageIndex}`);const textContentY = getCurrentTextContentY(currentPageCanvas, firstMatchContent);const offsetTop = 50; //为了滚动目标文字不顶格const targetScrollTop = beforePageHeight + textContentY -offsetTop;pdfContainerRef.current.scrollTo({top: targetScrollTop, // 垂直滚动位置behavior: 'smooth'});};// 绘制高亮区域const drawHighlights = async (canvas: any, matchesList: MatchBlockItem[]) => {if (matchesList.length === 0) {return;}const context = canvas.getContext('2d');context.fillStyle = 'rgba(255, 255, 0, 0.5)'; // 黄色半透明填充matchesList.forEach((match: any) => {const {textBlock} = match;const { transform, width, height, str } = textBlock;// 获取每一个字符的宽度const charWidth = width / str.length;const lightWidth = (match.textEndIndex - match.textStartIndex) * charWidth;const lightHeight = height;const x = transform[4] + match.textStartIndex * charWidth;const y = getCurrentTextContentY(canvas, match);context.fillRect(Math.floor(x * scale), Math.floor(y), Math.ceil(lightWidth * scale), Math.ceil(lightHeight * scale));});};// 渲染单个页面const renderPage = async (page: any, pageNumber: number) => {const viewport = page.getViewport({ scale });const pageContentDom = document.createElement('div');pageContentDom.id = `pdfPage-content-${pageNumber}`;//为了文本层和canvas层重叠,利用组件库的类名pageContentDom.className = 'pdfViewer';pageContentDom.style.setProperty('--scale-factor', scale as any);pageContentDom.style.width = `${viewport.width}px`;pageContentDom.style.height = `${viewport.height}px`;pageContentDom.style.position = 'relative';// 创建 Canvas 元素const canvas = document.createElement('canvas');const context = canvas.getContext('2d');canvas.id=`pdfPage-${pageNumber}`canvas.width = viewport.width;canvas.height = viewport.height;canvas.style.border = '1px solid black';pageContentDom.appendChild(canvas);createHeightLightCanvas(viewport, pageNumber, pageContentDom);pdfContainerRef.current.appendChild(pageContentDom);// 渲染 PDF 页面到 Canvasawait page.render({canvasContext: context,viewport,}).promise;// 渲染文本框const textLayerDiv = document.createElement('div');textLayerDiv.style.width = viewport.width;textLayerDiv.style.height = viewport.height;//为了文本层和canvas层重叠,利用组件库的类名textLayerDiv.className = 'textLayer';const textContent = await page.getTextContent();pdfjsLib.renderTextLayer({textContentSource: textContent,container: textLayerDiv,viewport: viewport,textDivs: [],});pageContentDom.appendChild(textLayerDiv)};// 渲染 PDF 页面const renderPagesGroup = ( pages: any) => {pages.forEach(({page}:any, index: number) => {renderPage(page, index);});};// 加载 PDF 文件const loadPdf = async (url: any) => {const pdf = await pdfjsLib.getDocument(url).promise;const pages: any[] = [];for (let i = 1; i <= pdf.numPages; i++) {const page = await pdf.getPage(i);const textContent = await page.getTextContent();pages.push({page,textContent});}setPagesList(pages);renderPagesGroup(pages);};const findAllMatches = (text: string, pattern: string) => {// 创建正则表达式对象const regex = new RegExp(pattern, 'g');// 使用match方法找到所有匹配项const matches = text.match(regex);// 如果没有匹配项,返回空数组if (!matches) {return [];}// 创建一个数组来存储所有匹配的位置const positions = [];// 遍历所有匹配项,找到它们在字符串中的位置let match;while ((match = regex.exec(text)) !== null) {positions.push(match.index);}return positions;}// todo 优化参数个数,const getMatchesList = (items: any,currentItem: any, currentItemIndex: number,currentTextIndex: number, searchStr: string): MatchBlockItem[] => {let matchSearchList: MatchBlockItem[] = [];if(currentItem.str.length - (currentTextIndex + 1) < searchStr.length -1 ) {// 获取当前文本块中剩余字符,如果小于搜索字符长度,则继续查找下一个文本块let itemText = currentItem.str.slice(currentTextIndex); // 获取当前文本块中剩余字符let tempMatchSearchList = [{blockIndex: currentItemIndex,textStartIndex: currentTextIndex,textEndIndex: currentItem.str.length,// 由于统一使用slice截取,所以不包括最后一位textBlock: currentItem}]; // 存储后续文本块let index = currentItemIndex;const otherSearchLength = searchStr.length -1;while (itemText.length <= otherSearchLength) {index = index + 1;const currentOtherSearchLength = otherSearchLength - itemText.length; // 当前剩余搜索字符长度if (items[index].str.length > currentOtherSearchLength) {// 文本块的长度大于剩余搜索字符长度,则截取剩余搜索字符长度的字符itemText = `${itemText}${items[index].str.slice(0, currentOtherSearchLength+1)}`;tempMatchSearchList.push({blockIndex: index,textStartIndex: 0,textEndIndex: currentOtherSearchLength + 1,textBlock: items[index]})} else {// 文本块的长度小于剩余搜索字符长度,则截取全部字符, 继续itemText = `${itemText}${items[index].str}`;tempMatchSearchList.push({blockIndex: index,textStartIndex: 0,textEndIndex: items[index].str.length,textBlock: items[index]})}}if (itemText === searchStr) {matchSearchList = matchSearchList.concat(tempMatchSearchList);}}else {// 获取当前文本块中剩余字符,如果大于等于搜索字符长度,则截取当前文本块中搜索文本长度的字符const textEndIndex = currentTextIndex + searchStr.length;const text = currentItem.str.slice(currentTextIndex, textEndIndex); // 取出匹配字符所在文本块及后续文本块if (text === searchStr) {console.log('匹配到了:', currentItem, currentItemIndex)matchSearchList.push({blockIndex: currentItemIndex,textStartIndex: currentTextIndex,textEndIndex: textEndIndex,textBlock: currentItem})}}return matchSearchList;}// 查找文本的所有出现位置const findAllOccurrences = (items: any, searchStr: string): MatchBlockItem[] => {const firstSearchStr = searchStr[0];let matchSearchList: MatchBlockItem[] = [];for(let i=0; i<items.length; i++) {const currentItem = items[i];const currentMatchIndexList = findAllMatches(currentItem.str, firstSearchStr); // 获取当前文本块中第一个匹配字符的索引列表if (currentMatchIndexList.length > 0) {for(let j=0; j<currentMatchIndexList.length; j++){matchSearchList = [...matchSearchList, ...getMatchesList(items, currentItem, i, currentMatchIndexList[j], searchStr)];}}}return matchSearchList;};const clearHeightLightsCanvas = () => {const highlightCanvases = Array.from(pdfContainerRef.current.querySelectorAll('.highlightCanvas'));highlightCanvases.forEach((canvas: any) => {const context = canvas.getContext('2d');context.clearRect(0, 0, canvas.width, canvas.height);});}const handleSearch = async () => {clearHeightLightsCanvas()if (!searchText) {jumpToPage(0);return;}const newMatches: any = [];console.log('pagesList', pagesList)// todo 目前是按照每页来匹配,可能会匹配不到跨页的内容pagesList.forEach(async ({textContent}: any, pageIndex: number) => {const pageMatches = findAllOccurrences(textContent.items, searchText);newMatches.push({pageIndex, // 页面索引matchList: pageMatches, // 匹配项列表});})console.log('newMatches', newMatches);const isNotMatch = newMatches.every((match: any) => match.matchList.length === 0);if (isNotMatch) {alert('未找到匹配项');return;}/// 重新绘制高亮区域pagesList.forEach((_: any, pageIndex: number) => {const highlightCanvas = pdfContainerRef.current.querySelectorAll('.highlightCanvas')[pageIndex]; // 获取高亮层 Canvasconst currentMatches = newMatches.find((match: any) => match.pageIndex === pageIndex);drawHighlights(highlightCanvas,currentMatches?.matchList || []);});// 跳转const isExistItem = newMatches.find((match: any) => match.matchList.length > 0);if (isExistItem) {scrollToMatch(isExistItem);}};// 初始化 PDF.jsuseEffect(() => {loadPdf(pdfUrl);}, []);return <><div><h1>PDF 搜索(基于@pdfjs-dist-自定义实现)</h1><inputtype="text"value={searchText}onChange={(e) => setSearchText(e.target.value)}placeholder="输入要搜索的内容"/><Button onClick={handleSearch}>搜索</Button><div><div style={{ height: height || '500px' }}>{/* PDF 容器 */}<div ref={pdfContainerRef} style={{ position: 'relative', height: '100%', overflowY: 'scroll' }} /></div></div></div></>
};export default viewPdf;
【4】获取pdf文件中目录的数据结构
....
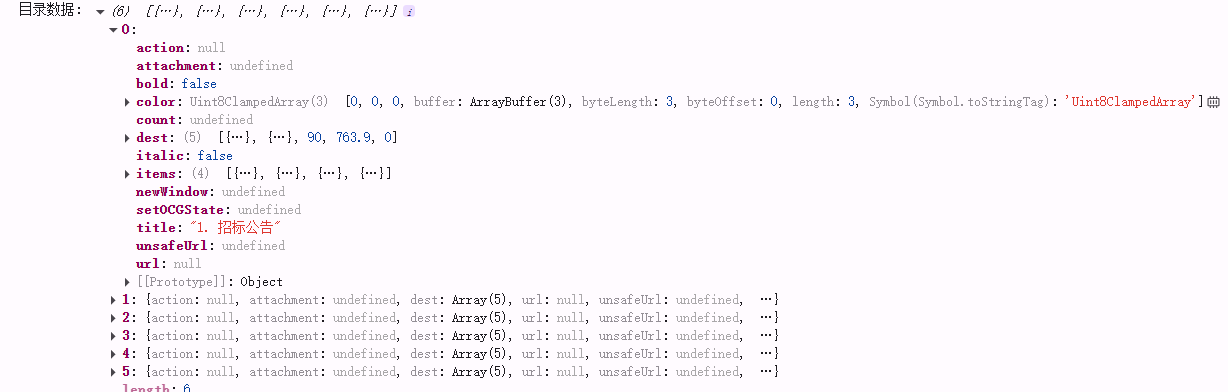
//基于‘【1】实现pdf预览’的代码const get= async (url: any) => {const pdf = await pdfjsLib.getDocument(url).promise;// 获取目录数据const pdfCatalogue= await pdf.getOutline();console.log('目录数据:', pdfCatalogue); };
...
相关文章:
前端渲染pdf文件解决方案-pdf.js
目录 一、前言 二、简介 1、pdf.js介绍 2、插件版本参数 三、通过viewer.html实现预览(推荐) 1、介绍 2、部署 【1】下载插件包 【2】客户端方式 【3】服务端方式(待验证) 3、使用方法 【1】预览PDF文件 【2】外部搜索…...

vue3 + element-plus中el-drawer抽屉滚动条回到顶部
el-drawer抽屉滚动条回到顶部 <script setup lang"ts" name"PerformanceLogQuery"> import { ref, nextTick } from "vue"; ...... // 详情 import { performanceLogQueryByIdService } from "/api/performanceLog"; const onD…...
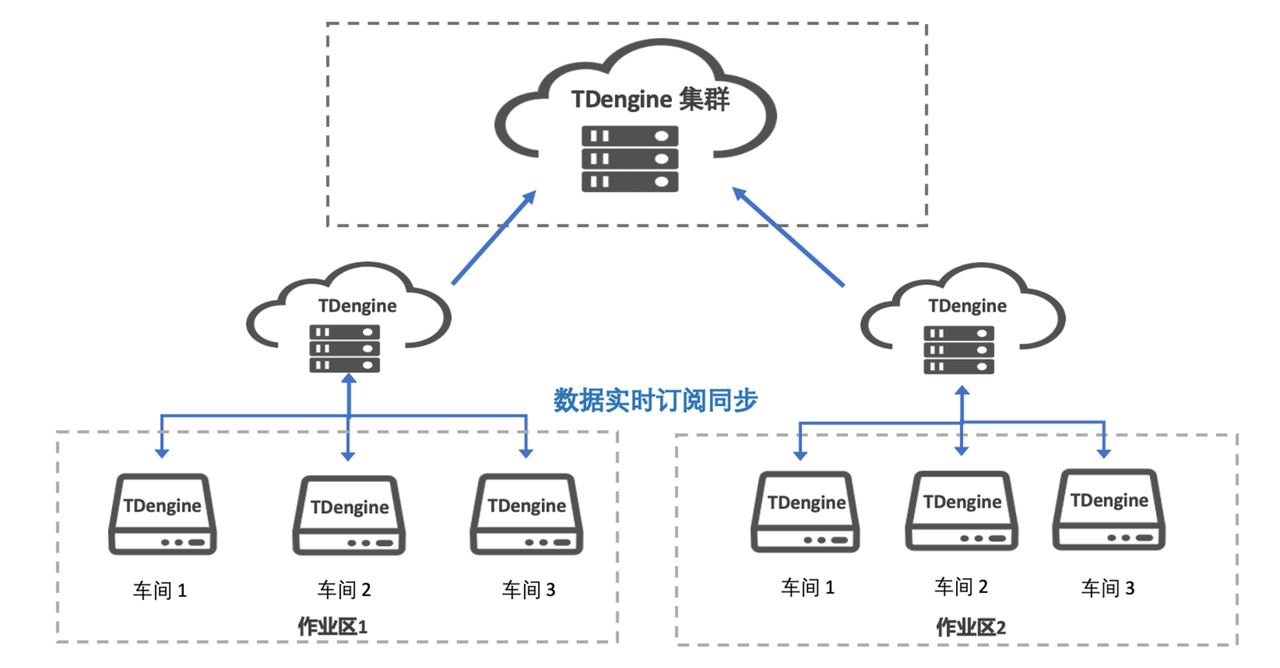
从边缘到云端,如何通过时序数据库 TDengine 实现数据的全局洞
在当今数字化转型加速的背景下,海量的数据生成和实时处理需求已成为企业面临的关键挑战。无论是物联网设备、工业自动化系统,还是智能城市的各类传感器,数据的采集、传输与分析效率,直接影响企业的决策与运营。为此,TD…...
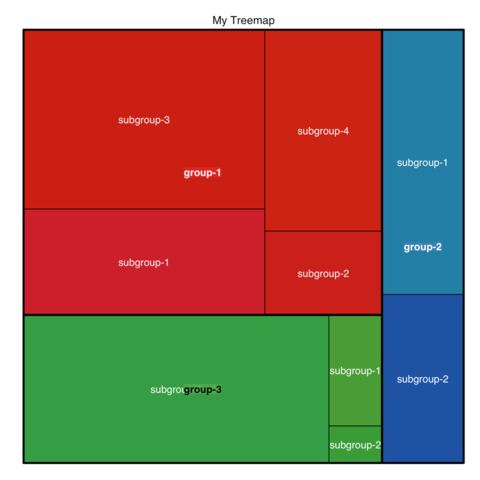
2025.04.23【Treemap】树状图数据可视化指南
Multi-level treemap How to build a treemap with group and subgroups. Customization Customize treemap labels, borders, color palette and more 文章目录 Multi-level treemapCustomization Treemap 数据可视化指南Treemap 的基本概念为什么使用 TreemapTreemap 的应用…...

蓝桥杯 15.小数第n位
小数第n位 原题目链接 题目描述 我们知道,整数做除法时,有时会得到有限小数,有时会得到无限循环小数。 如果我们把有限小数的末尾加上无限多个 0,它们就具有了统一的形式。 本题的任务是:在上述约定下,…...

用高斯溅射技术跨越机器人模拟与现实的鸿沟:SplatSim 框架解析
在机器人领域,让机器人在现实世界中精准执行任务是大家一直追求的目标。可模拟环境和现实世界之间存在着不小的差距,特别是基于 RGB 图像的操作策略,从模拟转移到现实时总是状况百出。 今天咱们就来聊聊 SplatSim 框架,看看它是怎…...
Transformer 架构 - 解码器 (Transformer Architecture - Decoder)
欢迎回到我们的 Transformer 系列教程!在上一篇中,我们详细探讨了 Transformer 的编码器,它负责将输入的源序列(比如源语言句子)转换为一系列包含丰富上下文信息的向量表示。 现在,我们将把目光投向 Transformer 的另一半——解码器 (Decoder)。解码器负责接收编码器的输…...

使用Intel Advisor工具分析程序
使用Intel Advisor工具分析程序 Intel Advisor是一款性能分析工具,主要用于识别代码中的向量化机会、线程化和内存访问模式等问题。以下是使用Intel Advisor分析程序的基本步骤: 安装与准备 从Intel官网下载并安装Intel Advisor(通常作为I…...
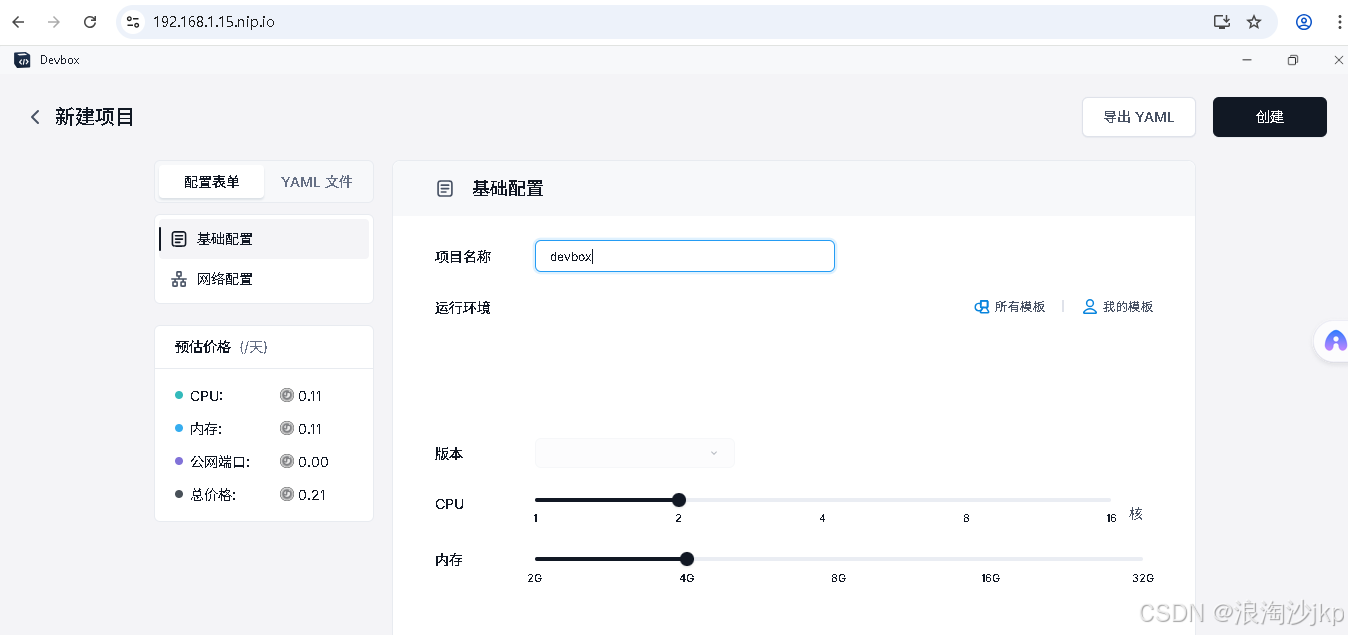
AI大模型学习十一:尝鲜ubuntu 25.04 桌面版私有化sealos cloud + devbox+minio,实战运行成功
一、说明 用了ubuntu 25.04,内核为GNU/Linux 6.14.0-15-generic x86_64,升级了部分image,过程曲折啊 sealos 能干啥 对集群生命周期进行管理,一键安装高可用 Kubernetes 集群,增删节点清理集群自恢复等 通过 sealos…...

如何在 Python 项目中引入 Rust 函数
目录 1. 初始化 Python 项目2. 添加 Rust 开发工具3. 初始化 Rust 项目4. 开发模式构建5. 验证模块是否成功安装6. 测试 Rust 函数总结 (封面pid: 129416070) Python 是一门非常流行的编程语言,具有易于使用和开发的特点。然而,随着项目需求的增长和性能…...
聊聊SpringAI流式输出的底层实现?
在 Spring AI 中,流式输出(Streaming Output)是一种逐步返回 AI 模型生成结果的技术,允许服务器将响应内容分批次实时传输给客户端,而不是等待全部内容生成完毕后再一次性返回。 这种机制能显著提升用户体验ÿ…...
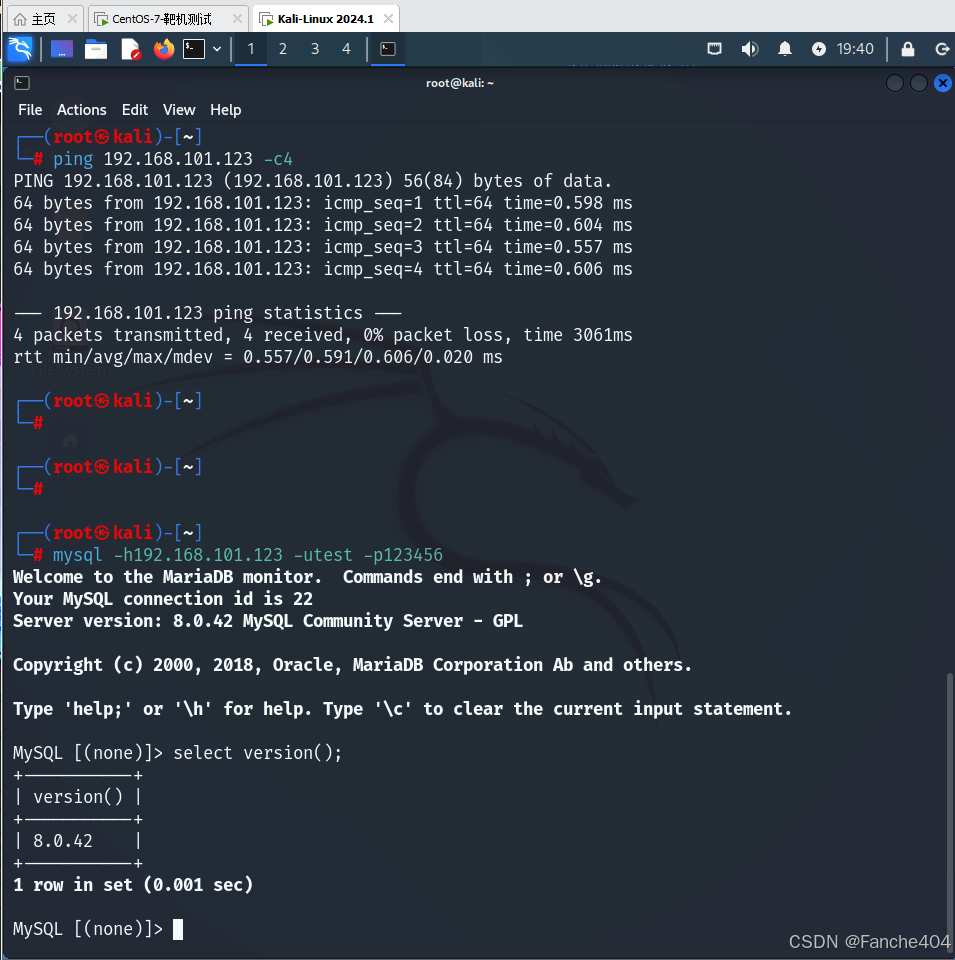
MySQL 8 自动安装脚本(CentOS-7 系统)
文章目录 一、MySQL 8 自动安装脚本脚本说明📌 使用脚本前提条件1. 操作系统2. 用户权限3. 网络要求 📌 脚本的主要功能1. 环境检查2. MySQL 自动安装3. 自动配置 MySQL4. 防火墙配置5. 验证与输出 📌 适用场景 二、执行sh脚本1. 给予脚本执行…...
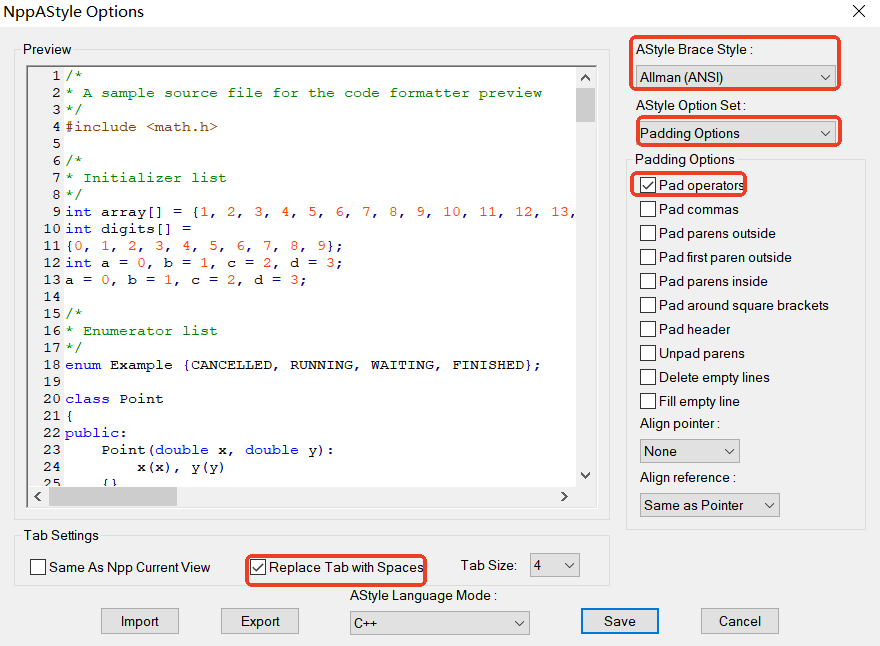
在Notepad++中使用NppAtyle插件格式化代码
参考链接:Artistic Style 使用教程(中文版) 1.下载NppAStyle插件(根据版本,选择32位或者64位) https://github.com/ywx/NppAStyle/releases 2.菜单栏中选择:插件->打开插件文件夹 创建文件夹…...

【k8s系列7-更新中】kubeadm搭建Kubernetes高可用集群-三主两从
主机准备 结合前面的章节,这里需要5台机器,可以先创建一台虚拟机作为基础虚拟机。优先把5台机器的公共部分优先在一台机器上配置好 1、配置好静态IP地址 2、主机名宇IP地址解析 [root@localhost ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost…...

拼多多面经,暑期实习Java一面
项目中的设计模式 mysql连接过程,索引,分库分表场景,路由策略 redis使用场景,分片集群怎么搭建与路由,数据一致性 分布式锁怎么用的,具体使用参数 线程池怎么用的,过程 sql having 分布式事务 如…...

FramePack:让视频生成更高效、更实用
想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。 1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其…...
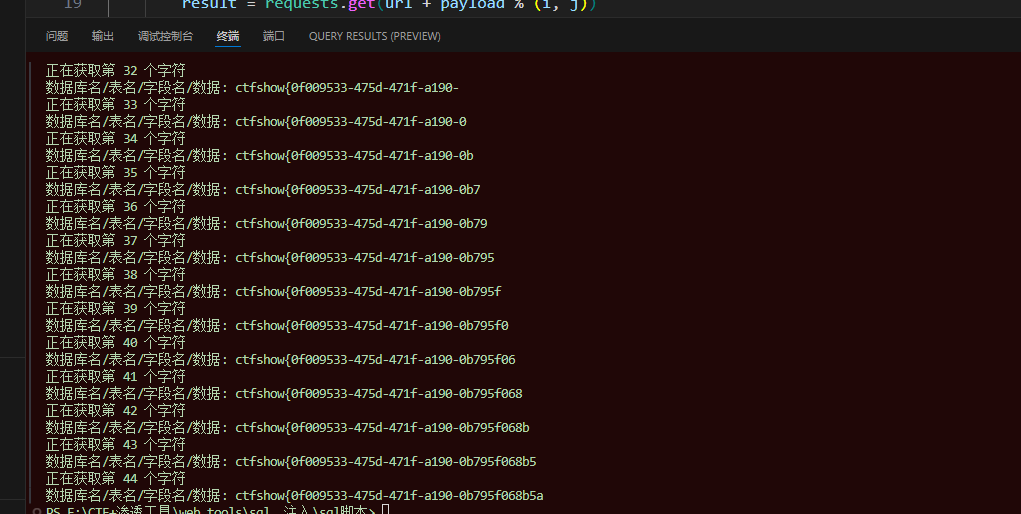
ctfshow web8
前言 学习内容:简单的盲注脚本的书写 web8 这个题目题目手动注入很麻烦 主要是他过滤了 union 空格和 过滤了union的解决方法 1、使用盲注(报错注入和盲注) 2、使用时间盲注 3、堆叠注入 盲注脚本的书写 首先他是有注入点的 然后熟悉requests包的使用 …...
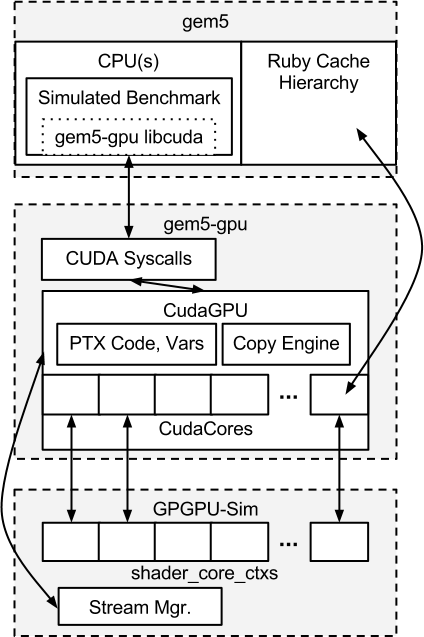
gem5-gpu教程03 当前的gem5-gpu软件架构(因为涉及太多专业名词所以用英语表达)
Current gem5-gpu Software Architecture 这是当前gem5-gpu软件架构的示意图。 Ruby是在gem5-gpu上下文中用于处理CPU和GPU之间内存访问的高度可配置的内存系统 CudaCore (src/gpu/gpgpu-sim/cuda_core.*, src/gpu/gpgpu-sim/CudaCore.py) Wrapper for GPGPU-Sim shader_cor…...
TDengine 查询引擎设计
简介 TDengine 作为一个高性能的时序大数据平台,其查询与计算功能是核心组件之一。该平台提供了丰富的查询处理功能,不仅包括常规的聚合查询,还涵盖了时序数据的窗口查询、统计聚合等高级功能。这些查询计算任务需要 taosc、vnode、qnode 和…...

AOSP Android14 Launcher3——点击桌面图标启动应用动画流程
在Launcher3中,点击桌面应用图标时,会有一个从 图标位置起始到全屏的动画过程,使得应用的打开过程不是生硬的启动过程。 这个动画具体是怎么实现的呢?本文对这个过程进行一个梳理 在Launcher中,动画大体上可以分为两类…...

windows端远程控制ubuntu运行脚本程序并转发ubuntu端脚本输出的网页
背景 对于一些只能在ubuntu上运行的脚本,并且这个脚本会在ubuntu上通过网页展示运行结果。我们希望可以使用windows远程操控ubuntu,在windows上查看网页内容。 方法 start cmd.exe /k "sshpass -p passwd ssh namexxx.xxx.xxx.xxx "cd /hom…...
【官方正版,永久免费】Adobe Camera Raw 17.2 win/Mac版本 配合Adobe22-25系列软
Adobe Camera Raw 2025 年 2 月版(版本 17.2)。目前为止最新版新版已经更新2个月了,我看论坛之前分享的还是2024版,遂将新版分享给各位。 Adobe Camera Raw,支持Photoshop,lightroom等Adobe系列软件&#…...

如何使用flatten函数在Terraform 中迭代嵌套map
简介 flatten 接受一个列表,并用列表内容的扁平序列替换列表中的任何元素。 > flatten([["a", "b"], [], ["c"]]) ["a", "b", "c"] > flatten([[["a", "b"], []], [&quo…...

原生 HTML 的`title` 属性修改触发事件为鼠标移入移出显示
HTML中title属性的适用范围 在 HTML 中,title 属性是全局属性(Global Attribute),这意味着它可以被应用到所有 HTML 标签上。无论是块级元素(如 <div>)、行内元素(如 <span>),还是表单元素(如 <input>),都可以添加 title 属性。 常见使用 title…...

【论文精读】Reformer:高效Transformer如何突破长序列处理瓶颈?
目录 一、引言:当Transformer遇到长序列瓶颈二、核心技术解析:从暴力计算到智能优化1. 局部敏感哈希注意力(LSH Attention):用“聚类筛选”替代“全量计算”关键步骤:数学优化: 2. 可逆残差网络…...
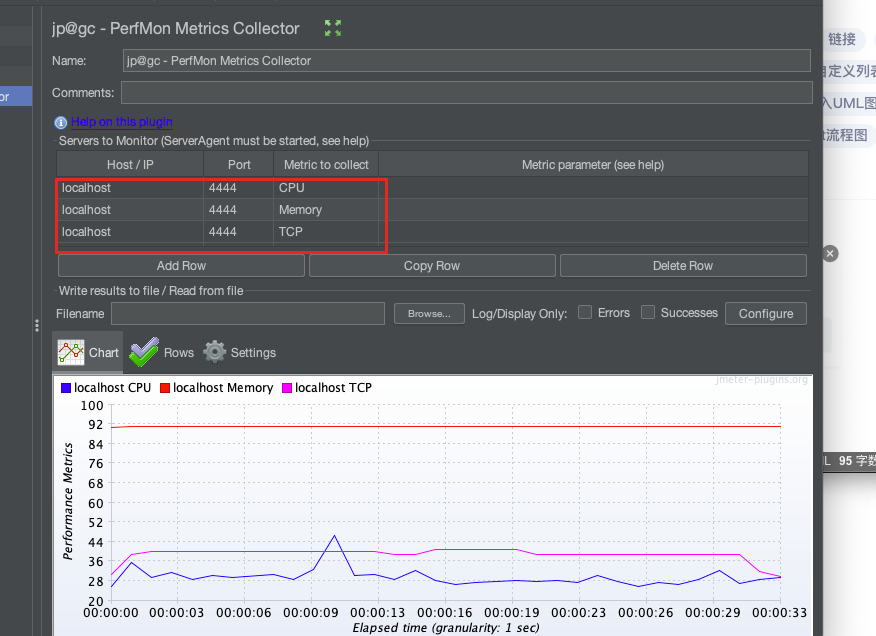
jmeter中监控服务器ServerAgent
插件下载: 将ServerAgent上传至需要监控的服务器,mac/liunx启动startAgent.sh(启动命令:./startAgent.sh) 在jmeter中添加permon监控组件 配置需要监控的服务器IP地址,添加需要监控的资源 注意…...

网络结构及安全科普
文章目录 终端联网网络硬件基础网络协议示例:用户访问网页 OSI七层模型网络攻击(Hack)网络攻击的主要类别(一)按攻击目标分类(二)按攻击技术分类 网络安全防御 典型攻击案例相关名词介绍网络连接…...

JVM虚拟机-JVM调优、内存泄漏排查、CPU飙高排查
一、JVM调优的参数在哪里设置 项目开发过程中有以下两种部署项目的方式: 项目部署在tomcat中,是一个war包;项目部署在SpringBoot中,是一个jar包。 (1)war包 catalina文件在Linux系统下的tomcat是以sh结尾,在windows系…...

安全复健|windows常见取证工具
写在前面: 此博客仅用于记录个人学习内容,学识浅薄,若有错误观点欢迎评论区指出。欢迎各位前来交流。(部分材料来源网络,若有侵权,立即删除) 取证 01系统运行数据 使用工具:Live-F…...
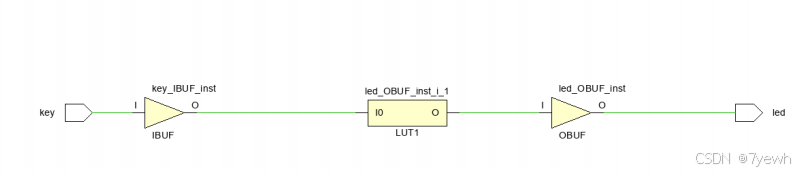
FPGA开发流程初识
FPGA 的开发流程可知,在 FPGA 开发的过程中会产生很多不同功能的文件,为了方便随时查找到对应文件,所以在开始开发设计之前,我们第一个需要考虑的问题是工程内部各种文件的管理。如 果不进行文件分类,而是将所有文件…...