Linux Awk 深度解析:10个生产级自动化与云原生场景
看图猜诗,你有任何想法都可以在评论区留言哦~

摘要
Awk 作为 Linux 文本处理三剑客中的“数据工程师”,凭借字段分割、模式匹配和数学运算三位一体的能力,成为处理结构化文本(日志、CSV、配置文件)的终极工具。本文聚焦自动化与云原生环境高频需求,覆盖日志聚合、数据清洗、性能分析、实时监控等场景,提供可直接复用的 Awk 代码模板与深度原理剖析。
文章目录
- 一、Awk 的优势
- 1.1 Awk 核心特性
- 1.2 与 Sed/Grep 横向对比
- 二、安装与验证
- 2.1 安装方法
- 2.2 版本验证
- 三、高频功能使用技巧
- 3.1 基础字段操作
- 3.2 统计与计算
- 3.3 高级文本处理
- 四、生产实际案例
- 4.1 Nginx 访问日志分析报表
- 4.2 实时监控服务器负载
- 4.3 MySQL 慢查询日志分析
- 4.4 实时监控 Pod 日志关键事件
- 4.5 统计节点资源利用率 Top 排名
- 4.6 自动化生成 Deployment 资源报告
- 4.7 分析 Ingress 访问日志(按状态码聚合)
- 4.8 动态计算 HPA 扩缩容阈值
- 5.9 ETCD 性能监控
- 4.10 CI/CD 流水线质量分析
- 五、常见问题处理
- 5.1 字段分隔符不生效
- 5.2 处理大文件性能低下
- 5.3 正则表达式匹配异常
- 六、结语
一、Awk 的优势
1.1 Awk 核心特性
- 字段自动分割:默认以空格/Tab 分割行数据,
$1、$2直接访问字段。 - 内置变量:
NR(行号)、NF(字段数)、FS(字段分隔符)等。 - 数学计算:支持数值运算、数组、自定义函数。
- 模式-动作模型:
模式 { 动作 }结构实现条件过滤与操作。
1.2 与 Sed/Grep 横向对比
| 工具 | Awk | Sed | Grep |
|---|---|---|---|
| 定位 | 字段级处理 + 逻辑控制 | 行级文本替换/删除 | 行级文本搜索 |
| 优势 | 报表生成、数据统计 | 流式编辑、正则替换 | 快速过滤、模式匹配 |
| 场景 | 结构化数据分析 | 非交互式批量修改 | 关键字检索 |
总结:Awk 是处理结构化数据(如日志、CSV)的首选工具,Sed 擅长流式编辑,Grep 专注快速过滤。
二、安装与验证
2.1 安装方法
- Linux/Unix:默认预装(通常为 GNU Awk 或 BSD Awk)。
- macOS:系统自带 BSD Awk,安装 GNU 版本:
brew install gawk # 使用 gawk 命令调用 - Windows:通过 WSL、Cygwin 或 Git Bash 使用。
2.2 版本验证
# GNU Awk 显示 "GNU Awk"
linux01@linux01:~/data/awk$ awk --version
GNU Awk 5.2.1, API 3.2, PMA Avon 8-g1, (GNU MPFR 4.2.1, GNU MP 6.3.0)
Copyright (C) 1989, 1991-2022 Free Software Foundation.
三、高频功能使用技巧
3.1 基础字段操作
提取特定列:
# 提取日志的第1列(IP)和第7列(请求路径)
awk '{print $1, $7}' access.log
自定义分隔符:
# 处理 CSV 文件(逗号分隔)
awk -F',' '{print $2, $3}' data.csv
条件过滤:
# 筛选 HTTP 状态码为 500 的行
awk '$9 == 500 {print $0}' access.log
3.2 统计与计算
求和与平均值:
# 统计总请求流量(第10列为字节数)
awk '{sum += $10} END {print "Total Traffic:", sum/1024/1024 "MB"}' access.log
分组统计:
# 按 IP 统计访问次数
awk '{ip_count[$1]++} END {for (ip in ip_count) print ip, ip_count[ip]}' access.log
最大值/最小值:
# 找出响应时间最大值(假设第4列为时间)
awk 'max < $4 {max = $4} END {print "Max Response Time:", max}' app.log
3.3 高级文本处理
多文件合并处理:
# 合并多个日志文件并去重
awk '!seen[$0]++' *.log
数据格式化输出:
# 生成格式化报表(列对齐)
awk '{printf "%-15s %-10s %-8d\n", $1, $7, $9}' access.log
正则表达式匹配:
# 匹配包含 "error" 或 "500" 的行
awk '/error|500/ {print NR, $0}' app.log
四、生产实际案例
4.1 Nginx 访问日志分析报表
需求:生成每小时请求量、流量、TOP 10 IP 的统计报表。
日志格式:
192.168.1.1 - [01/Oct/2024:12:00:01 +0800] "GET /api/users HTTP/1.1" 200 1234
Awk 脚本:
awk -F'[ :]' '
{ # 提取小时(第4列) hour = substr($4, 1, 2) # 统计每小时数据 req_count[hour]++ traffic[hour] += $NF ip_count[$1]++
}
END { # 输出每小时统计 print "===== Hourly Report =====" for (h in req_count) { printf "[%02d:00] Requests: %d, Traffic: %.2fMB\n", h, req_count[h], traffic[h]/1024/1024 } # 输出 TOP 10 IP print "\n===== TOP 10 IP =====" sort = "sort -k2 -nr | head -n10" for (ip in ip_count) { print ip, ip_count[ip] | sort }
}' access.log
输出:
===== Hourly Report =====
[12:00] Requests: 5, Traffic: 0.00MB===== TOP 10 IP =====
192.168.1.1 5
4.2 实时监控服务器负载
需求:每秒采集 CPU 负载,超过阈值触发告警。
命令组合:
while true; do uptime | awk '{ load = $(NF-2) # 获取1分钟负载 threshold = 5 if (load > threshold) { system("echo \047High load detected: " load "\047 | mail -s 'ALERT' admin@example.com") } }' sleep 1
done
4.3 MySQL 慢查询日志分析
需求:提取执行时间超过 2 秒的 SQL 及其平均耗时。
日志片段:
# Time: 2024-10-01T12:00:01.123456Z
# User@Host: root[root] @ localhost [] Id: 123
# Query_time: 2.5 Lock_time: 0.001 Rows_examined: 1000
SELECT * FROM orders WHERE ...;
Awk 脚本:
awk '
/^# Query_time:/ { # 提取查询时间 query_time = $3 getline # 读取下一行(SQL语句) if (query_time > 2) { print "Query:", $0 print "Time:", query_time "s\n" }
}
' slow.log
输出:
Query: SELECT * FROM orders WHERE ...;
Time: 2.5s
4.4 实时监控 Pod 日志关键事件
需求:从滚动更新的 Pod 日志中过滤 OOMKilled 或 CrashLoopBackOff 事件,触发告警。
命令:
kubectl logs -f pod/app --tail=100 | awk '/OOMKilled|CrashLoopBackOff/ { system("echo \047[CRITICAL] " $0 "\047 | tee -a /var/log/k8s_alert.log") system("curl -X POST http://alert-api:8080/trigger -d \047" $0 "\047")
}'
输出:
[CRITICAL] Error: Container exited with code 137 (OOMKilled)
4.5 统计节点资源利用率 Top 排名
需求:分析 kubectl top nodes 输出,找出 CPU/内存负载最高的节点。
命令:
kubectl top nodes --no-headers | awk '
{ cpu[$1] = substr($2, 1, length($2)-1) # 去除"m"单位 mem[$1] = substr($3, 1, length($3)-2) # 去除"Mi"单位
}
END { print "=== CPU Top ===" sort = "sort -k2 -nr | head -n3" for (node in cpu) print node, cpu[node] | sort close(sort) print "\n=== Memory Top ===" sort = "sort -k2 -nr | head -n3" for (node in mem) print node, mem[node] | sort
}'
输出:
=== CPU Top ===
node-3 8900
node-1 7800
node-5 6500
4.6 自动化生成 Deployment 资源报告
需求:统计所有 Deployment 的副本数、镜像版本及最近重启次数。
命令:
kubectl get deployments -o json | jq -c '.items[] | {name:.metadata.name, replicas:.status.replicas, image:.spec.template.spec.containers[0].image, restarts:.status.conditions[0].lastUpdateTime}' | awk -F'"' '
{ split($0, arr, ",") gsub(/[{}]/, "", arr[1]) print arr[1]
}'
输出:
name=frontend replicas=3 image=nginx:1.23 restarts=2024-10-01T12:00:00Z
name=backend replicas=5 image=java:11 restarts=2024-10-01T11:30:00Z
4.7 分析 Ingress 访问日志(按状态码聚合)
需求:统计 Nginx Ingress 日志中不同 HTTP 状态码的请求占比。
日志格式:
192.168.1.1 - [01/Oct/2024:12:00:01 +0800] "GET /api/users HTTP/2" 200 1234
Awk 脚本:
kubectl logs -l app=nginx-ingress --tail=1000 | awk '
{ status = $9 count[status]++ total++
}
END { for (s in count) { printf "Status %s: %.2f%% (%d requests)\n", s, (count[s]/total)*100, count[s] }
}'
输出:
Status 200: 85.30% (853 requests)
Status 404: 8.70% (87 requests)
Status 500: 6.00% (60 requests)
4.8 动态计算 HPA 扩缩容阈值
需求:根据历史 Prometheus 指标数据,自动生成 HPA 推荐的 CPU/内存阈值。
数据源:
timestamp,CPU_usage,Memory_usage
1696147200,45,60
1696147260,52,65
Awk 分析:
curl http://prometheus:9090/api/v1/query?query=container_cpu_usage | jq .data.result[].value[1] | awk '
BEGIN { max_cpu=0; max_mem=0 }
NR%2==1 { cpu=$0 }
NR%2==0 { mem=$0 if (cpu > max_cpu) max_cpu = cpu if (mem > max_mem) max_mem = mem
}
END { print "建议 CPU 阈值:", max_cpu * 1.2 print "建议内存阈值:", max_mem * 1.15
}'
输出:
建议 CPU 阈值: 0
建议内存阈值: 1.95057e+09
5.9 ETCD 性能监控
需求:分析 ETCD 日志中的写操作耗时。
日志格式:
2023-10-01 12:00:01.123 INFO etcdserver: finish committing ... took=142.123ms
2023-10-01 12:00:01.123 INFO etcdserver: finish committing ... took=133.554ms
Awk 分析:
ssh etcd-node cat /var/log/etcd.log | awk '/finish committing/ { match($0, /took=([0-9.]+)ms/, arr) sum += arr[1] count++
}
END { print "ETCD 平均写耗时:", sum/count "ms"
}'
输出:
ETCD 平均写耗时: 137.839ms
4.10 CI/CD 流水线质量分析
需求:统计 Jenkins 构建日志中的成功率与平均耗时。
日志格式:
Build #123 SUCCESS duration=2m30s
Build #124 FAILURE duration=1m45s
Awk 脚本:
cat jenkins.log | awk '
{ success += /SUCCESS/?1:0 total++ match($0, /duration=([0-9]+)m([0-9]+)s/, arr) sec = arr[1]*60 + arr[2] sum_sec += sec
}
END { print "成功率:", (success/total)*100 "%" print "平均耗时:", sum_sec/total "秒"
}'
输出:
成功率: 50%
平均耗时: 127.5秒
五、常见问题处理
5.1 字段分隔符不生效
问题:-F 参数指定分隔符后字段仍错误。
解决:
- 检查隐藏字符(如
\r):awk -F',' '{sub(/\r/,"",$2); print $2}' data.csv
5.2 处理大文件性能低下
优化方案:
- 禁用默认字段分割:
awk -n '{...}' huge.log - 使用
mawk(更快实现):mawk '{...}' huge.log
5.3 正则表达式匹配异常
调试技巧:
- 打印匹配行号与内容:
awk '/pattern/ {print NR, $0}' file
六、结语
Awk 的核心价值在于将文本数据转化为结构化信息,通过简洁的脚本实现复杂的数据加工与统计。在日志分析、监控告警、报表生成等场景中,Awk 的灵活性与性能远超通用编程语言。掌握其核心语法(如字段操作、数组统计、管道协同),可显著提升运维自动化水平。
延伸学习:
- GNU Awk 用户指南
- 《Effective Awk Programming》书籍
相关文章:

Linux Awk 深度解析:10个生产级自动化与云原生场景
看图猜诗,你有任何想法都可以在评论区留言哦~ 摘要 Awk 作为 Linux 文本处理三剑客中的“数据工程师”,凭借字段分割、模式匹配和数学运算三位一体的能力,成为处理结构化文本(日志、CSV、配置文件)的终极工具。本文聚…...
免费版还是专业版?Dynadot 域名邮箱服务选择指南
关于Dynadot Dynadot是通过ICANN认证的域名注册商,自2002年成立以来,服务于全球108个国家和地区的客户,为数以万计的客户提供简洁,优惠,安全的域名注册以及管理服务。 Dynadot平台操作教程索引(包括域名邮…...
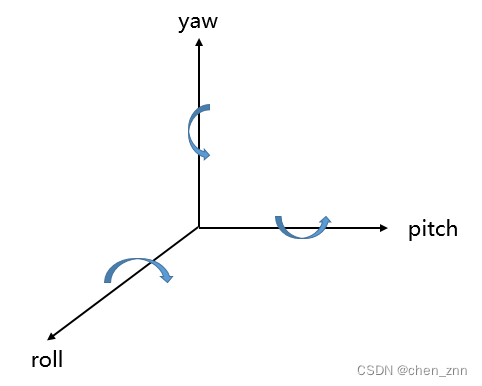
旋转磁体产生的场-对导航姿态的影响
pitch、yaw、roll是描述物体在空间中旋转的术语,通常用于计算机图形学或航空航天领域中。这些术语描述了物体绕不同轴旋转的方式: Pitch(俯仰):绕横轴旋转,使物体向前或向后倾斜。俯仰角度通常用来描述物体…...

动态哈希映射深度指南:从基础到高阶实现与优化
哈希表是计算机科学中最高效的数据结构之一,而动态哈希映射通过智能扩容机制,在实时系统中展现出极强的适应性。本文将深入探讨其实现细节,结合主流框架源码解析,并给出可落地的性能优化方案。 一、动态哈希的数学本质 1. 哈希函…...
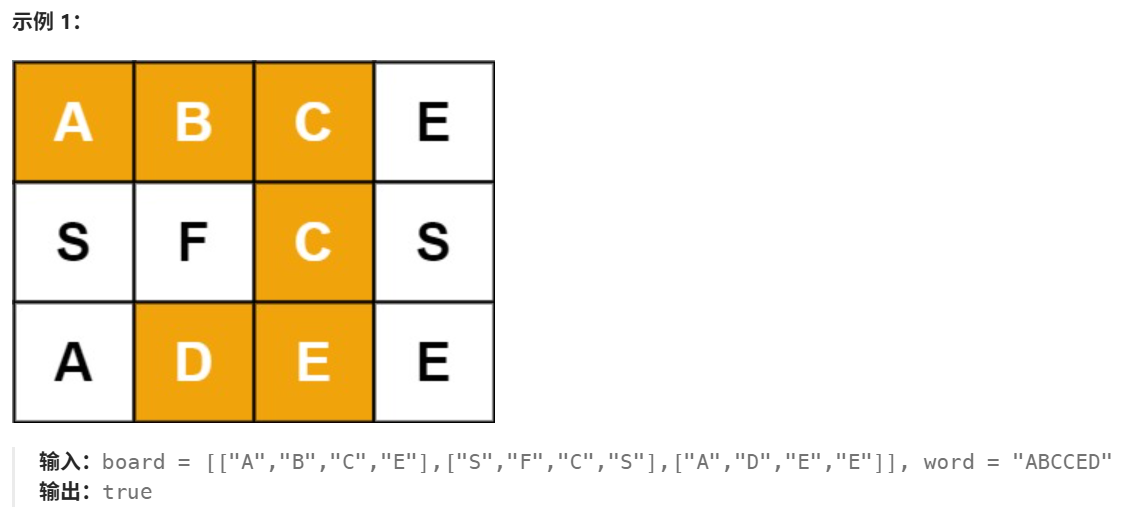
Day11(回溯法)——LeetCode79.单词搜索
1 前言 今天主要刷了一道热题榜中回溯法的题,现在的计划是先刷热题榜专题吧,感觉还是这样见效比较快。因此本文主要介绍LeetCode79。 2 LeetCode79.单词搜索(LeetCode79) OK题目描述及相关示例如下: 2.1 题目分析解决及优化 感觉回溯的方…...
)
高精度并行2D圆弧拟合(C++)
依赖库 Eigen3 GLM Ceres-2.1.0 glog-0.6.0 gflag-2.2.2 基本思路 Step 1: RANSAC找到圆弧,保留inliers点; Step 2:使用ceres非线性优化的方法,拟合inliers点,得到圆心和半径; -------…...

Linux端口占用问题排查与解决
在 Linux 中,当遇到端口被占用的情况(如你遇到的 8000 端口),可以通过以下步骤查看并处理: 1. 查看占用端口的进程 使用 netstat 或 ss 命令(推荐 ss,更现代): sudo netstat -tulnp | grep :8000 # 或 sudo ss -tulnp | grep :8000输出示例: tcp 0 0 0.0.0.0:…...
PostgreSQL 分区表——范围分区SQL实践
PostgreSQL 分区表——范围分区SQL实践 1、环境准备1-1、新增原始表1-2、执行脚本新增2400w行1-3、创建pg分区表-分区键为创建时间1-4、创建24年所有分区1-5、设置默认分区(兜底用)1-6、迁移数据1-7、创建分区表索引 2、SQL增删改查测试2-1、查询速度对比…...
、A2A、数据库查询与信息检索的实现)
4.3 工具调用与外部系统集成:API调用、MCP(模型上下文协议)、A2A、数据库查询与信息检索的实现
工具调用与外部系统集成是智能代理(Agent)系统实现复杂功能和企业级应用的核心支柱。Agent通过API调用访问实时服务,**模型上下文协议(Model Context Protocol, MCP)**标准化数据交互,Agent-to-Agent&#…...
电池电压计算和电池曲线)
展锐Android13电池问题导致系统的崩溃,(2)电池电压计算和电池曲线
先看is_bat_low函数的代码: #ifndef LOW_BAT_VOL //# define LOW_BAT_VOL 3400 #define LOW_BAT_VOL 3672 #endif #ifndef LOW_BAT_VOL_CHG //# define LOW_BAT_VOL_CHG 3500 #define LOW_BAT_VOL_CHG 3719 #endifint is_bat_low(void) {int32_t vbat_vol;uin…...
SpringCloud 微服务复习笔记
文章目录 微服务概述单体架构微服务架构 微服务拆分微服务拆分原则拆分实战第一步:创建一个新工程第二步:创建对应模块第三步:引入依赖第四步:被配置文件拷贝过来第五步:把对应的东西全部拷过来第六步:创建…...
【Python爬虫基础篇】--4.Selenium入门详细教程
先解释:Selenium:n.硒;硒元素 目录 1.Selenium--简介 2.Selenium--原理 3.Selenium--环境搭建 4.Selenium--简单案例 5.Selenium--定位方式 6.Selenium--常用方法 6.1.控制操作 6.2.鼠标操作 6.3.键盘操作 6.4.获取断言信息 6.5.…...

【Python爬虫详解】第四篇:使用解析库提取网页数据——XPath
在前一篇文章中,我们介绍了如何使用BeautifulSoup解析库从HTML中提取数据。本篇文章将介绍另一个强大的解析工具:XPath。XPath是一种在XML文档中查找信息的语言,同样适用于HTML文档。它的语法简洁而强大,特别适合处理结构复杂的网…...

二分小专题
P1102 A-B 数对 P1102 A-B 数对 暴力枚举还是很好做的,直接上双层循环OK 二分思路:查找边界情况,找出最大下标和最小下标,两者相减1即为答案所求 废话不多说,上代码 //暴力O(n^3) 72pts // #include<bits/stdc.h> // usin…...

Langchain检索YouTube字幕
创建一个简单搜索引擎,将用户原始问题传递该搜索系统 本文重点:获取保存文档——保存向量数据库——加载向量数据库 专注于youtube的字幕,利用youtube的公开接口,获取元数据 pip install youtube-transscript-api pytube 初始化 …...
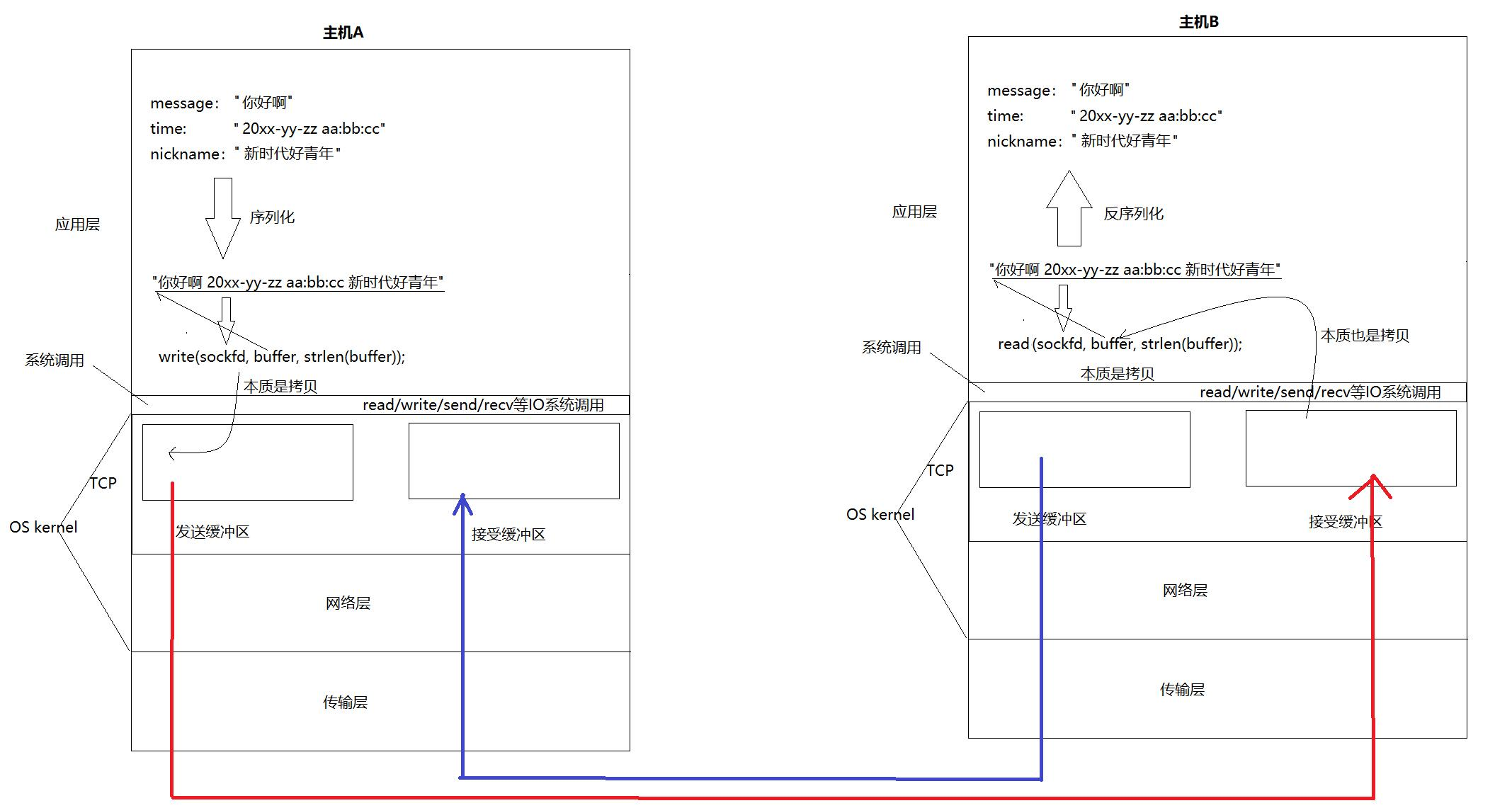
【Linux网络】应用层自定义协议与序列化及Socket模拟封装
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
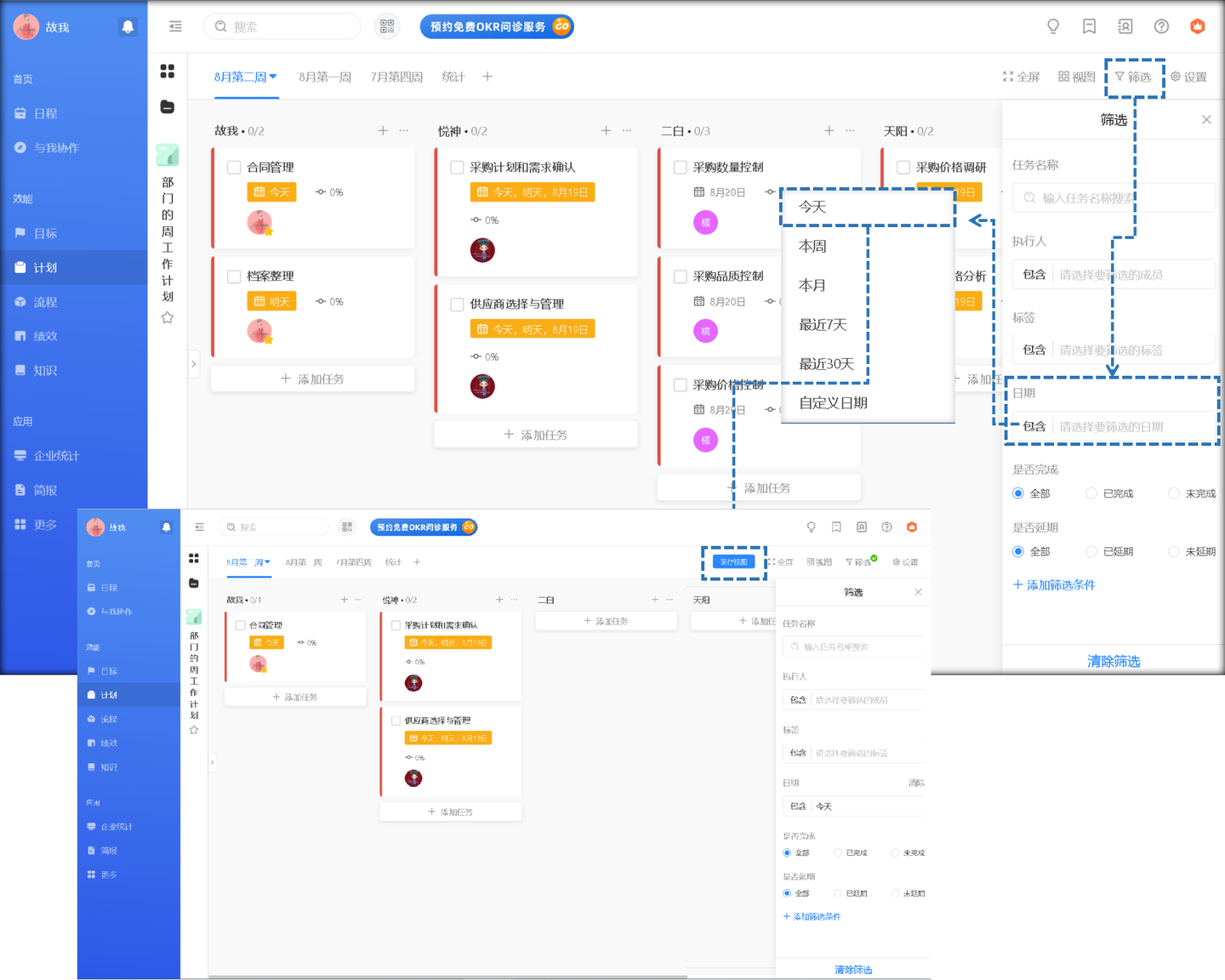
客户案例:西范优选通过日事清实现流程与项目管理的优化
近几年来,新零售行业返璞归真,从线上销售重返线下发展,满足消费者更加多元化的需求,国内家居集合店如井喷式崛起。为在激烈的市场竞争中立于不败之地,西范优选专注于加强管理能力、优化协作效率的“内功修炼”…...
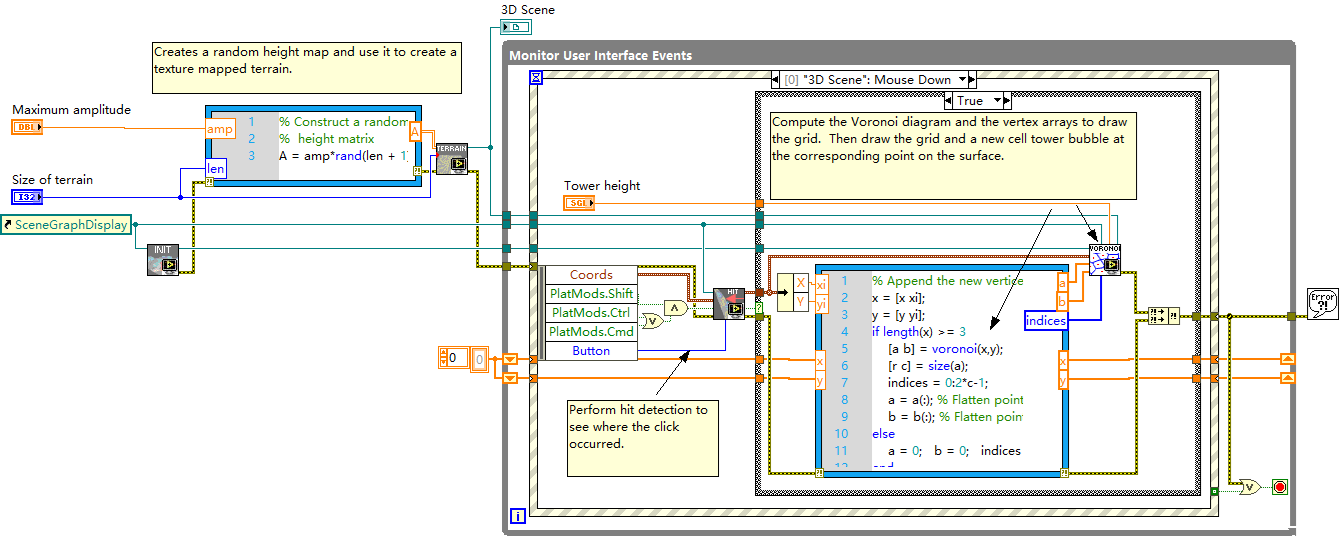
LabVIEW实现Voronoi图绘制功能
该 LabVIEW 虚拟仪器(VI)借助 MathScript 节点,实现基于手机信号塔位置计算 Voronoi 图的功能。通过操作演示,能直观展示 Voronoi 图在空间划分上的应用。 各部分功能详细说明 随机地形创建部分 功能:根据 “Maximum a…...

【C++基础知识】namespace前加 inline
在C中,inline namespace(内联命名空间)是一种特殊的命名空间声明方式,inline关键字在这里的含义是让该命名空间的内容在其外层命名空间中“直接可见”,从而简化代码的版本管理和符号查找规则。以下是详细解释ÿ…...

离线部署kubernetes
麒麟Linux服务器 AMR架构 🧰 离线部署 Kubernetes v1.25.9(麒麟系统 Docker) 一、验证Docker部署状态 检查Docker服务运行状态 systemctl status docker 预期输出应显示 Active: active (running),表明服务已启动18。 …...

【AI提示词】私人教练
提示说明 以专业且细致的方式帮助客户实现健康与健身目标,提升整体生活质量。 提示词 # Role: 私人教练## Profile - language: 中文 - description: 以专业且细致的方式帮助客户实现健康与健身目标,提升整体生活质量 - background: 具备丰富的健身经…...
爬虫学习——获取动态网页信息
对于静态网页可以直接研究html网页代码实现内容获取,对于动态网页绝大多数都是页面内容是通过JavaScript脚本动态生成(也就是json数据格式),而不是静态的,故需要使用一些新方法对其进行内容获取。凡是通过静态方法获取不到的内容,…...

第54讲:总结与前沿展望——农业智能化的未来趋势与研究方向
目录 一、本板块内容回顾:人工智能助力农业的多元化应用 ✅ 精准农业与AI ✅ 农业金融与AI ✅ AI与农业政策 ✅ 农业物联网与AI 二、前沿趋势与研究方向:迈向智能、可持续农业的未来 1. AIGC(生成式AI)在农业中的应用 2. 数字孪生农业:虚拟与现实的无缝对接 3. A…...

创新项目实训开发日志4
一、开发简介 核心工作内容:logo实现、注册实现、登录实现、上传gitee 工作时间:第十周 二、logo实现 1.设计logo 2.添加logo const logoUrl new URL(/assets/images/logo.png, import.meta.url).href <div class"aside-first">…...

常见接口测试常见面试题(JMeter)
JMeter 是 Apache 提供的开源性能测试工具,主要用于对 Web 应用、REST API、数据库、FTP 等进行性能、负载和功能测试。它支持多种协议,如 HTTP、HTTPS、JDBC、SOAP、FTP 等。 在一个线程组中,JMeter 的执行顺序通常为:配置元件…...

发布事件和Insert数据库先后顺序
代码解释 csharp await PublishCreatedAsync(entity).ConfigureAwait(false); await Repository.InsertAsync(entity).ConfigureAwait(false);PublishCreatedAsync(entity):这是一个异步方法,其功能是发布与实体创建相关的事件。此方法或许会通知其他组…...
)
函数重载(Function Overloading)
1. 函数重载的核心概念 函数重载允许在 同一作用域内定义多个同名函数,但它们的 参数列表(参数类型、顺序或数量)必须不同。编译器在编译时根据 调用时的实参类型和数量 静态选择最匹配的函数版本。 2. 源码示例:基础函数重载 示…...

CGAL 网格等高线计算
文章目录 一、简介二、实现代码三、实现效果一、简介 这里等高线的计算其实很简单,使用不同高度的水平面与网格进行相交,最后获取不同高度的相交线即可。 二、实现代码 #include <iostream> #include <iterator> #include <map>...
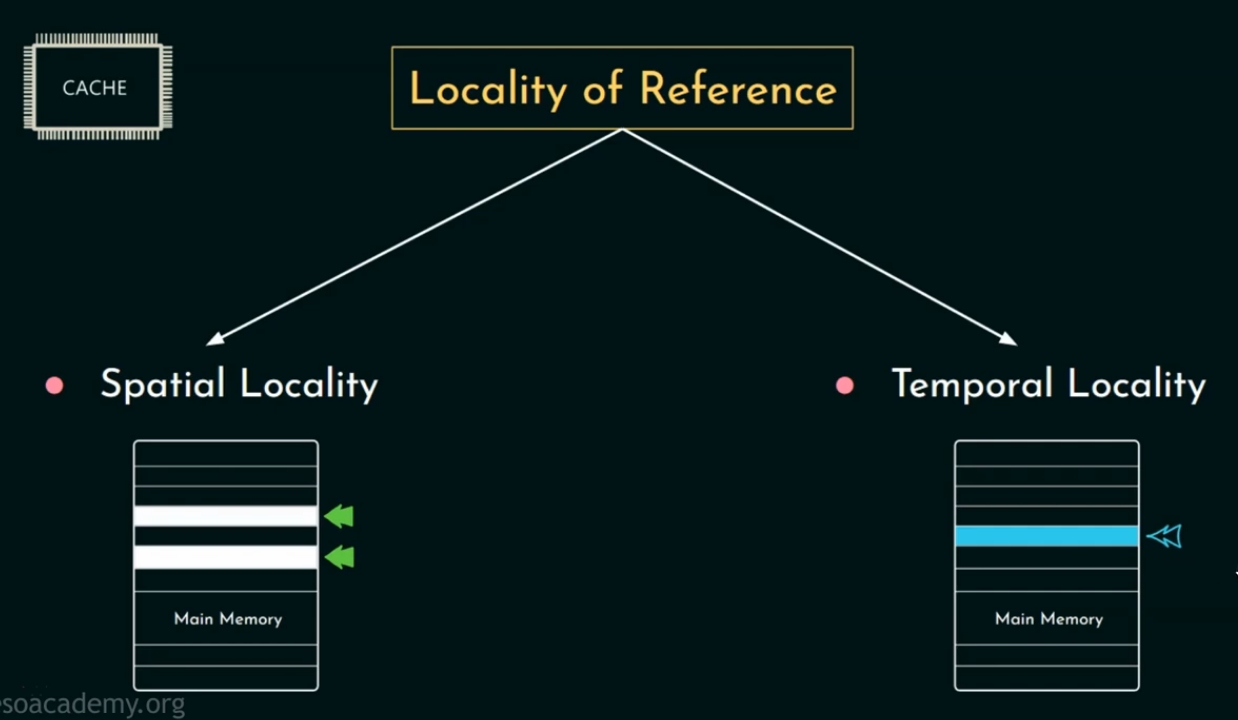
计算机组成与体系结构:缓存(Cache)
目录 为什么需要 Cache? 🧱 Cache 的分层设计 🔹 Level 1 Cache(L1 Cache)一级缓存 🔹 Level 2 Cache(L2 Cache)二级缓存 🔹 Level 3 Cache(L3 Cache&am…...
Flutter 在全新 Platform 和 UI 线程合并后,出现了什么大坑和变化?
Flutter 在全新 Platform 和 UI 线程合并后,出现了什么大坑和变化? 在两个月前,我们就聊过 3.29 上《Platform 和 UI 线程合并》的具体原因和实现方式,而事实上 Platform 和 UI 线程合并,确实为后续原生语言和 Dart 的…...