【C++11】右值引用和移动语义:万字总结
📝前言:
这篇文章我们来讲讲右值引用和移动语义
🎬个人简介:努力学习ing
📋个人专栏:C++学习笔记
🎀CSDN主页 愚润求学
🌄其他专栏:C语言入门基础,python入门基础,python刷题专栏,Linux
文章目录
- 一,左值和右值
- 二,左值引用和右值引用
- 1 对比异同
- 2 延长生命周期
- 3 参数匹配
- 三,右值引用和移动语义
- 1 左值引用主要使用场景
- 2 移动构造和移动赋值
- 3 不同优化下的拷贝构造优化效果
- 没有优化
- 优化1
- 优化2
- 4 不同优化下的拷贝赋值优化效果
- 没有优化
- 优化1
- 优化2
- 5 总结及移动语义的重要性
- 四,类型分类
- 五,引用折叠
- 六,完美转发
一,左值和右值
左值和右值最重要的区别:能不能取地址,能取地址的是左值,不能的是右值!
左值:
- 左值:一个表示数据的表达式,是一个具名的、有明确内存地址的对象,如:变量名,解引用的指针
- 可以出现在赋值符号的左边,也可以出现在右边。(如果有
const修饰,就无法修改,但是可以取地址)
右值:
- 右值:也是⼀个表示数据的表达式,常见的有:字面量,表达式返回时生成的临时变量,函数传值返回时的临时变量,你们对象…
- 不能出现在赋值符号的左边,不能取地址
示例:
常见左值,可以在=左边,可以取地址:
int* p = new int(0);int a = 10;const int c = a;*p = 10;string s{ "111111" };s[0] = 'x'; // 函数返回值为引用,也是左值
常见右值,不能在=左边,不能取地址:
10; // 字面量x + y; // 表达式返回中间生成临时变量fmin(x, y); // 传值返回中间生成临时变量string("11111"); // 匿名对象(具有常性)
二,左值引用和右值引用
1 对比异同
相同点:
- 左值引用是给左值取别名,右值引用是给右值取别名,语法层面都不开空间
- 从底层汇编上看,都是用指针实现的
不同点:
左值引用:
- 语法:
Type &r1 = x;,x是左值 const左值引⽤可以引用右值
右值引用:
- 语法:
Type &&rr1 = y;,y是右值 - 右值引用可以引用
move(左值)(move本质内部是进行强制类型转换,但是不改变原来变量的属性【这个属性指:左值 / 右值】) - 右值引用本身是左值,即:在上面的语法中:
rr1是左值
示例:
左值引用:
// 左值引用
int& ra = a;
const int& rc = c;
string& rs = s;
const int& rc = 10; // const左值引用 引用右值
右值引用:
const int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
string&& rr4 = string("11111");
string&& rr5 = move(s); // 引用move(左值)
double&& rr6 = move(rr2); // rr2是右值引用,属性是左值,要使用move才能被右值引用
2 延长生命周期
右值引用和const左值引用,可以延长临时变量/匿名对象的生命周期(普通的左值引用不行,因为临时变量具有常性)
示例:
double x = 1.1, y = 2.2;
// double& r1 = x + y; 报错:无法从“double”转换为“double &
const double& rr2 = x + y;
double&& rr3 = x + y;
rr3++; // 并且非 const 的右值引用可以修改
说明:x+y表达式计算的结果会先储存在临时变量中(这个临时变量存储在这个表达式所在的栈帧中),但是生命周期只有这一行。使用右值引用和const左值引用以后可以延长这个临时变量的生命周期,即:这一行结束以后不销毁,而是跟着rr2 / rr3
3 参数匹配
- 对于不同的引用类型,以及带
const和非const,都属于不同的类型,可以构成函数重载 - 根据实参传入的类型不同,编译器会选择最匹配的函数
const左值引用作为参数的函数,实参传递左值和右值都可以匹配
示例:
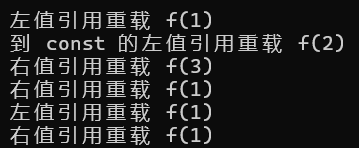
void f(int& x)
{cout << "左值引用重载 f(" << x << ")\n";
}
void f(const int& x)
{cout << "到 const 的左值引用重载 f(" << x << ")\n";
}
void f(int&& x)
{cout << "右值引用重载 f(" << x << ")\n";
}int main()
{int i = 1;const int ci = 2;f(i); // 调用 f(int&)f(ci); // 调用 f(const int&)f(3); // 调用 f(int&&),如果没有 f(int&&) 重载,则会调用 f(const int&)f(std::move(i)); // 调用 f(int&&)// 右值引用变量在用于表达式时是左值int&& x = 1;f(x); // 调用 f(int& x)f(std::move(x)); // 调用 f(int&& x)return 0;
}
运行结果:
三,右值引用和移动语义
1 左值引用主要使用场景
我们都知道:函数传值传参、函数传值返回、以及表达式计算结果后赋值…都需要先把原来的数据拷贝给临时变量,然后再由临时变量拷贝回给接收值。这样的效率是非常低的。
之前,我们为了减少这种拷贝就已经开始运用左值引用了,如:
- 使用cosnt 左值引用作为形参(直接使用别名,减少传值的拷贝)
- 使用左值引用作为函数返回值
但是,当函数内部,返回的是局部变量且函数结束后要被销毁时,我们无法通过左值引用来接收。
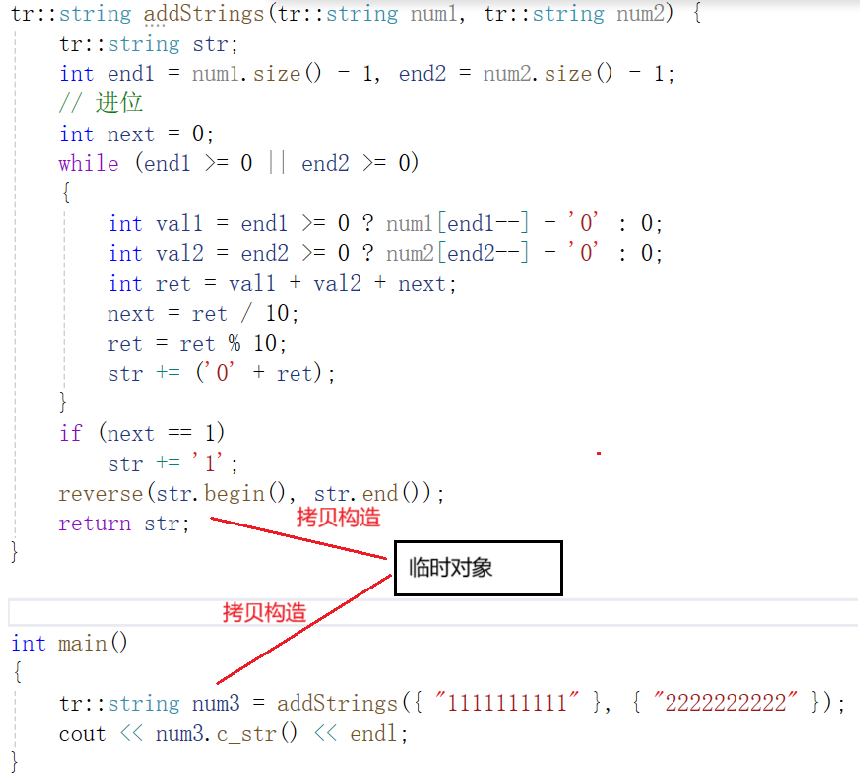
错误示例(注意如果要进行测试:这里是string不要用库里面的,因为库里面的已经实现了移动构造和移动赋值):
const tr::string& addStrings(tr::string num1, tr::string num2) {tr::string str;int end1 = num1.size() - 1, end2 = num2.size() - 1;// 进位int next = 0;while (end1 >= 0 || end2 >= 0){int val1 = end1 >= 0 ? num1[end1--] - '0' : 0;int val2 = end2 >= 0 ? num2[end2--] - '0' : 0;int ret = val1 + val2 + next;next = ret / 10;ret = ret % 10;str += ('0' + ret);}if (next == 1)str += '1';reverse(str.begin(), str.end());return str;
}int main()
{tr::string num1{ "2222222222" };tr::string num2{ "1111111111" };tr::string num3 = addStrings(num1, num2);
}
代码为 -1073741819 (0xc0000005)
程序会崩掉,为什么呢?
因为,在addStrings函数里面,str是一个局部对象,即使被引用绑定了,但是函数结束后,存储str的栈帧被销毁,str也会被销毁(无法达到延长生命周期的效果)
那难道就没有解决方法了吗?有的兄弟,有的!
在C++11之前,可以通过传输出型参数解决:
// 输出型参数
void addStrings(tr::string num1, tr::string num2, tr::string& num3) {int end1 = num1.size() - 1, end2 = num2.size() - 1;// 进位int next = 0;while (end1 >= 0 || end2 >= 0){int val1 = end1 >= 0 ? num1[end1--] - '0' : 0;int val2 = end2 >= 0 ? num2[end2--] - '0' : 0;int ret = val1 + val2 + next;next = ret / 10;ret = ret % 10;num3 += ('0' + ret);}if (next == 1)num3 += '1';reverse(num3.begin(), num3.end());
}int main()
{tr::string num1{ "2222222222" };tr::string num2{ "1111111111" };tr::string num3;addStrings(num1, num2, num3);cout << num3.c_str() << endl;
}
说明:
num3就是输出型参数,形参为num3的引用,直接在函数内部修改num3。但是这样的做法牺牲了一定的可读性。
还有其他做法吗?
有的兄弟,有的,那就是C++11的右值引用+移动语义!
2 移动构造和移动赋值
首先,我们先来讲讲移动构造和移动赋值的语法和写法:
- 移动构造:是⼀种构造函数,类似拷贝构造函数。要求第⼀个参数是该类类型的右值引用,如果还有其他参数,额外的参数必须有缺省值
- 移动赋值:是⼀个赋值运算符的重载,他跟拷贝赋值构成函数重载。移动赋值函数要求第⼀个参数是该类类型的右值引用。它们两个的关系就类似移动构造和拷贝构造的关系。
话不多说,直接上代码理解:
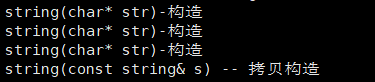
我们先看一个普通的拷贝构造:
string(const string& s):_str(nullptr)
{// cout << "string(const string& s) -- 拷贝构造" << endl;reserve(s._capacity);for (auto ch : s){push_back(ch);}
}
再看移动构造和移动赋值:
// 移动构造
string(string&& s)
{cout << "string(string&& s) -- 移动构造" << endl;swap(s);
}
// 移动赋值
string& operator=(string&& s)
{cout << "string& operator=(string&& s) -- 移动赋值" << endl;swap(s);return *this;
}
说明:
在这里,s是一个将要销毁的右值,直接swap把s的资源交换给了this(这里的代价比拷贝构造小的多,可能只是一个指针的交换等),然后s带着原来刚初始化的this的资源被销毁。
3 不同优化下的拷贝构造优化效果
首先我们要理解,什么时候,拷贝构造会被使用?
没有优化
当没有任何优化的情况下:
但是这里我调不出来,现在的编译器都优化的太好了。
优化1
优化版本1:
省掉临时变量,直接用str构造num3,{"1111111111"}这是同理,省掉了临时变量。
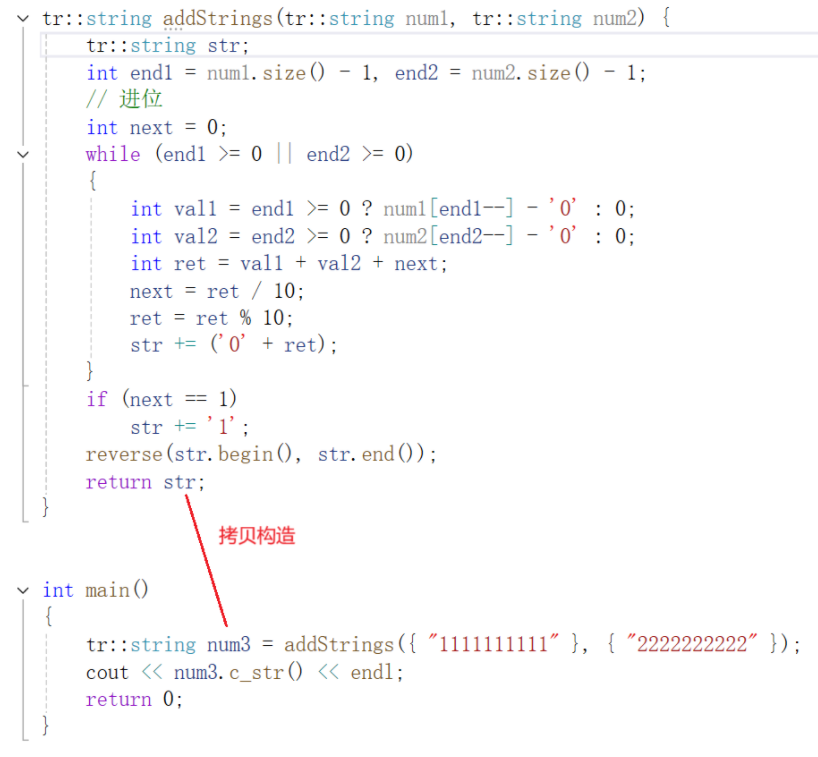
我们可以在Linux下用g++编译器来观察:g++ test.cpp -fno-elide-constructors(看别人都说:这是取消所有优化,但是我测试的效果任然是保留了这优化1的效果的)
测试结果:
说明:
- 前两个构造分别对应:用
{"1111111111"}和{"2222222222"}来构造num1和num2。优化掉了中间的临时变量:没有优化时是:先用{"1111111111"}构造临时变量,然后再用临时变量拷贝构造num1 - 第三个构造是定义函数内
str的时候的构造(即函数内第一条语句) - 第四个拷贝构造,就是优化1 的效果,直接省掉了临时变量,用
str直接拷贝构造num3
优化2
新版编译器都是到了优化2的程度:
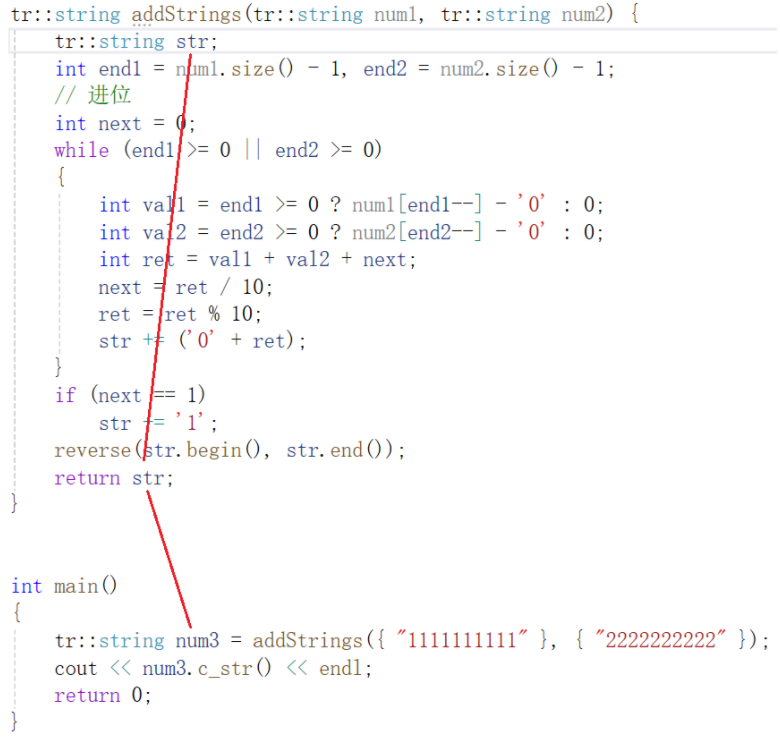
运行效果:
说明:
- 前两个和优化1 一样,不解释了
- 可见这里少了一个拷贝构造:编译器直接优化成:用把
str当num3的引用了,在函数内部直接就改了num3,减少了拷贝
4 不同优化下的拷贝赋值优化效果
刚刚我们看到了编译器的超强优化,大大避免了拷贝的出现。但是,能优化所有情况吗?答案是否定的,当出现拷贝赋值的时候,编译器不敢优化用临时变量拷贝赋值的那一步。
我们把代码改成这样:
tr::string num3;
num3 = addStrings({ "1111111111" }, { "2222222222" });
没有优化
如果没有优化:
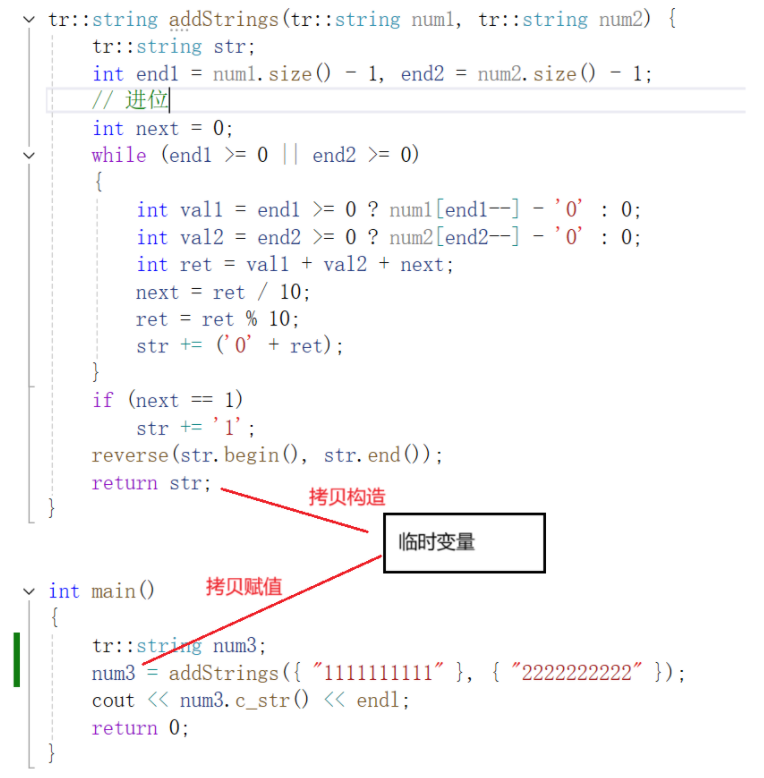
优化1
优化1:
没错,你没看错,和没有优化的效果是一样的,只是在传参那里会优化掉临时变量,但是传值返回并调用拷贝赋值这里一点也不会省
我们在Linux下运行优化1的效果:
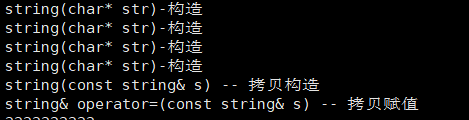
说明:
- 前四个构造分别对应:add外部
num3,{"1111111111"},{"2222222222"},add内部str - 拷贝构造:用返回值
str拷贝构造临时对象 - 拷贝赋值:用临时对象拷贝赋值外部的
num3
优化2
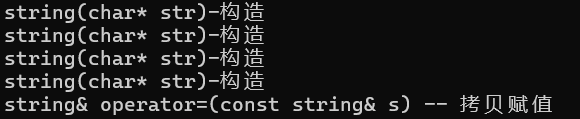
优化2以后:
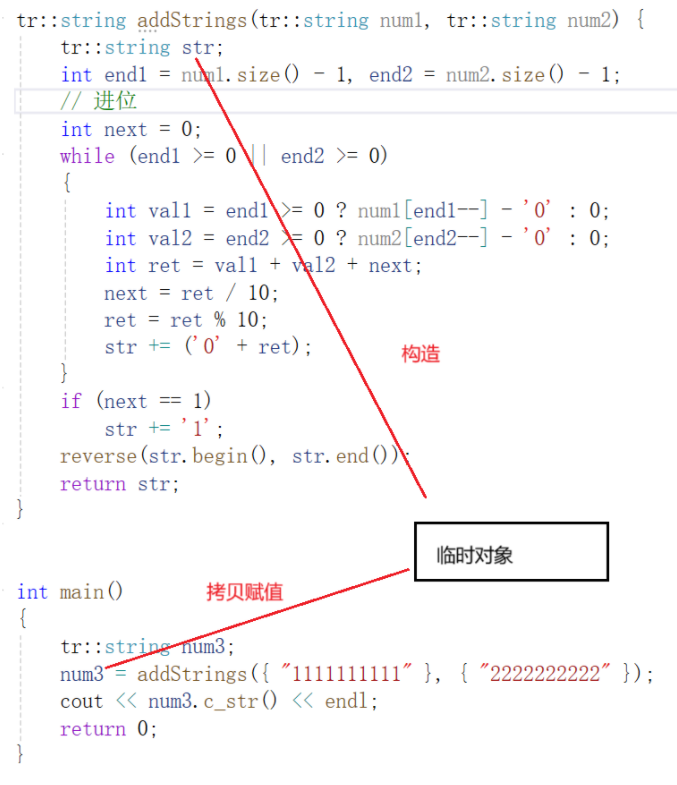
优化掉了,用str拷贝构造临时对象这一步(可以理解为,这时候str就是临时对象的引用)
但是,即使最大优化:临时对象到拷贝赋值这一步也不能省
我们在优化2的情况下运行代码,运行结果:
5 总结及移动语义的重要性
通过上面的优化我们可以发现:
在最强优化的情况下,如果只有构造操作,则两个拷贝构造会被直接优化掉。但是,如果是构造+赋值操作,则最多只能把拷贝构造给优化掉(即:和构造合并),但是用临时变量来拷贝赋值这一步无法优化。
所以这时候,右值引用+移动语义的意义就非常大了。因为移动构造和移动赋值的代价都特别小。
当我们实现了移动构造和移动赋值以后,对应的拷贝构造和拷贝赋值就会被替换成我们的移动构造和移动赋值。
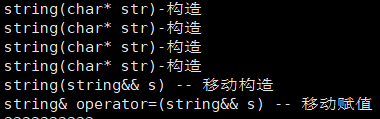
示例(优化1 下:构造 + 赋值运行结果)
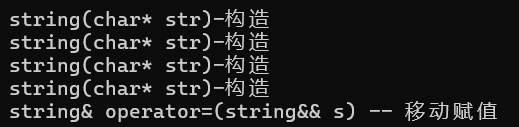
示例(优化2 下:构造 + 赋值运行结果):
移动构造和移动赋值的使用场景:
对于像string/vector这样的深拷贝的类或者包含深拷贝的成员变量的类,移动构造和移动赋值才有
意义,因为移动构造和移动赋值的第⼀个参数都是右值引用的类型,他的本质是要“窃取”引用的
右值对象的资源,而不是像拷贝构造和拷贝赋值那样去拷贝资源,从提高效率
在C++11以后,STL里面的容器也对此做了调整
比如vector的push_back
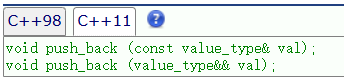
- 当实参是⼀个左值时,容器内部继续调用拷贝构造进行拷贝,将对象拷贝到容器空间中的对象
- 当实参是⼀个右值时,容器内部则调用移动构造,右值对象的资源到容器空间的对象上
四,类型分类
- C++11以后,进⼀步对类型进⾏了划分,右值被划分纯右值(pure value,简称prvalue)和将亡值
- 存右值和C++98中右值的概念相同
- 将忘值是指:返回右值引用的函数的调用表达式 或 转换为右值引用的转换函数的调用表达,如:
move(x)、static_cast<X&&>(x)【可以理解为:x是左值,且一直是左值属性,但是move(x)这一下,变成了将亡值,当右值】 static_cast<type>(x)是类型转换操作,在这里:type如果是左值引用,static_cast<type>(x)该将亡值就是左值属性,反之就是右值属性。而x是保留原来的属性- 范左值:左值和将亡值
五,引用折叠
C++中不能直接定义引用的引用如 int& && r = i; ,这样写会直接报错,通过模板或 typedef
中的类型操作可以构成引用的引用
引用折叠:当出现引用的引用时,只要有左值引用,那类型就是左值引用
示例(typedef):
typedef int& lref;typedef int&& rref;int n = 0;lref& r1 = n; // r1 的类型是 int&(左+左 = 左)lref&& r2 = n; // r2 的类型是 int& (左 + 右 = 左)rref& r3 = n; // r3 的类型是 int& (右 + 左 = 左)rref&& r4 = 1; // r4 的类型是 int&& (右 + 右 = 右)
示例(模板实例化):
函数f1和f2
// 由于引用折叠,且T& 是左值引用,所以:f1实例化以后总是左值引用
template<class T>
void f1(T& x)
{}// 由于引用折叠限定,且T&& 是右值引用,则f2实例化后可以是左值引,也可以是右值引用
template<class T>
void f2(T&& x)
{
}
实例化分析:
// 没有折叠->实例化为void f1(int& x)f1<int>(n);f1<int>(0); // 报错// 折叠->实例化为void f1(int& x)f1<int&>(n);f1<int&>(0); // 报错// 折叠->实例化为void f1(int& x)f1<int&&>(n);f1<int&&>(0); // 报错// 折叠->实例化为void f1(const int& x)f1<const int&>(n);f1<const int&>(0);// 折叠->实例化为void f1(const int& x)f1<const int&&>(n);f1<const int&&>(0);// 没有折叠->实例化为void f2(int&& x)f2<int>(n); // 报错f2<int>(0);// 折叠->实例化为void f2(int& x)f2<int&>(n);f2<int&>(0); // 报错// 折叠->实例化为void f2(int&& x)f2<int&&>(n); // 报错f2<int&&>(0);
所以,当我们的模板写成右值引用的时候,这时候是万能引用模板。编译器可以根据我们传入的引用的类型不同,实例化成左值引用或者右值引用。(折叠的是:T& / T&&,但对于T本身而言,这种显式实例化:T传入什么就是什么)
一个万能模板的例子:
template<class T>
void Function(T && t)
{int a = 0;T x = a;//x++;cout << &a << endl;cout << &x << endl << endl;
}
int main()
{// 10是右值,推导出T为int,模板实例化为void Function(int&& t)Function(10); // 右值int a = 10;// a是左值,推导出T为int&,引用折叠,模板实例化为void Function(int& t)Function(a); // 左值// std::move(a)是右值,推导出T为int,模板实例化为void Function(int&& t)Function(std::move(a)); // 右值const int b = 8;// a是左值,推导出T为const int&,引⽤折叠,模板实例化为void Function(const int&t)// 所以Function内部会编译报错,x不能++Function(b); // const 左值// std::move(b)右值,推导出T为const int,模板实例化为void Function(const int&&// 所以Function内部会编译报错,x不能++Function(std::move(b)); // const 右值return 0;
}
但是这里要注意的是:T的类型由编译器推导。
因为T&&是右值引用,当传左值的时候,为了匹配左值,T会被推导成左值引用
六,完美转发
完美转发:让参数保持原有的属性传递。
通常使用在解决这样的问题:一个为右值的参数,在传递时变成了左值。
例如:
template<class T>
void Function(T&& t)
{Fun(t);
}
Function(10)
假如,传入的实参10是一个右值,形参t就是一个右值引用。
但是右值引用本身的属性是左值,即:Function里面的具名对象t是一个左值,再传入Fun的时候,传入的就是一个左值了。出现了属性的变化。
完美转发:
template<class T>
void Function(T&& t)
{Fun(forward<T>(t));
}
forward 的作用是根据模板参数 T 的推导结果,将参数以原始的左值或右值属性转发给其他函数。
forward是一个函数模板,原型是(本质是通过:引用折叠 + 强制类型转换实现的):
template <class _Ty>
_Ty&& forward(remove_reference_t<_Ty>& _Arg) noexcept
{ // forward an lvalue as either an lvalue or an rvalue
return static_cast<_Ty&&>(_Arg);
}
即:
- 当
Function传入10:则T被推导成int,forward返回的static_cast<int&&>(t)属性是右值,所以是以右值的属性转发给Fun - 传入一个左值
int x;:则T被推导成int&,forward返回的static_cast<int& &&>(t)发生引用折叠,变成static_cast<int&>(t),属性是左值,以左值的属性转发给Fun - 注意:
static_cast<_Ty&&>(_Arg)这玩意是一个整体,这是一个将亡值。
🌈我的分享也就到此结束啦🌈
要是我的分享也能对你的学习起到帮助,那简直是太酷啦!
若有不足,还请大家多多指正,我们一起学习交流!
📢公主,王子:点赞👍→收藏⭐→关注🔍
感谢大家的观看和支持!祝大家都能得偿所愿,天天开心!!!
相关文章:
【C++11】右值引用和移动语义:万字总结
📝前言: 这篇文章我们来讲讲右值引用和移动语义 🎬个人简介:努力学习ing 📋个人专栏:C学习笔记 🎀CSDN主页 愚润求学 🌄其他专栏:C语言入门基础,python入门基…...

【滑动窗口+哈希表/数组记录】Leetcode 3. 无重复字符的最长子串
题目要求 给定一个字符串 s,找出其中不含有重复字符的最长子串的长度。 子字符串是字符串中连续非空字符序列。 示例 1 输入:s "abcabcbb" 输出:3 解释:无重复字符的最长子串是 "abc",长度为…...

pytest 技术总结
目录 一 pytest的安装: 二 pytest有三种启动方式: 三 用例规则: 四 配置框架: 一 pytest的安装: pip install pytest # 安装 pip install pytest -U # 升级到最新版 二 pytest有三种启动方式: 1…...

java中的Selector详解
Selector(选择器)是Java NIO(非阻塞I/O)的核心组件,用于实现I/O多路复用,允许单个线程管理多个通道(Channel),从而高效处理高并发场景。 一、Selector的核心概念与作用 I/O多路复用 Selector通过事件驱动机制,监听多个通道的就绪状态(如可读、可写、连接建立等),无…...

DeepSeek 的长上下文扩展机制
DeepSeek 在基础预训练完成后,引入 YaRN(Yet another RoPE extensioN method)技术,通过额外的训练阶段将模型的上下文窗口从默认的 4K 逐步扩展至 128K。整个过程分为两个阶段:第一阶段将上下文窗口从 4K 扩展到 32K;第二阶段则进一步从 32K 扩展到 128K。每个阶段均采用…...

【修复】Django收到请求报Json解析错误
Django收到请求报Json解析错误 场景分析解决 场景 在使用Postman发送Django的请求时,只能使用原来的json内容,如果修改json内容则会报json解析上的错误 分析 可能是有对请求内容的长度做了上报校验 解决 最终在请求头Headers里找到了Content-Length…...

openEuler对比CentOS的核心优势分析
openEuler对比CentOS的核心优势分析 在开源操作系统领域,openEuler与CentOS均占据重要地位,但随着CentOS维护策略的调整(如CentOS 8停止维护,转向CentOS Stream),越来越多的用户开始关注国产化替代方案。o…...

Python基于Django的全国二手房可视化分析系统【附源码】
博主介绍:✌Java老徐、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇&…...
VulnHub-DC-2靶机渗透教程
VulnHub-DC-2靶机渗透教程 1.靶机部署 [Onepanda] Mik1ysomething 靶机下载:https://download.vulnhub.com/dc/DC-2.zip 直接使用VMware导入打开就行 2.信息收集 2.1 获取靶机ip(arp-scan/nmap) arp-scan -l nmap 192.168.135.0/24 2.2 详细信息扫描(nmap)…...

n8n 中文系列教程_10. 解析n8n中的AI节点:从基础使用到高级Agent开发
在自动化工作流中集成AI能力已成为提升效率的关键。n8n通过内置的LangChain节点,让开发者无需复杂代码即可快速接入GPT-4、Claude等大模型,实现文本处理、智能决策等高级功能。本文将深入解析n8n的AI节点体系,从基础的Basic LLM Chain到强大的…...

Jest 快照测试
以下是关于 Jest 快照测试的系统化知识总结,从基础使用到底层原理全面覆盖: 一、快照测试核心原理 1. 工作机制三阶段 #mermaid-svg-GC46t2NBvGv7RF0M {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GC46t2NBvGv…...
)
Linux内核参数调优(TCP BBR算法实践)
Linux 内核参数调优中 TCP BBR 算法的深度实践指南,包含原理说明、操作步骤、性能验证及生产环境注意事项: 一、BBR 算法原理 核心思想 基于拥塞状态而非丢包:传统 CUBIC 算法依赖丢包判断拥塞,BBR 通过测量带宽 (Bandwidth) 和 RTT (Round-Trip Time) 动态调整发送速率。…...

计算机网络 | 应用层(1)--应用层协议原理
💓个人主页:mooridy 💓专栏地址:《计算机网络:自定向下方法》 大纲式阅读笔记 关注我🌹,和我一起学习更多计算机的知识 🔝🔝🔝 目录 1. 应用层协议原理 1.1 …...
MuJoCo 关节角速度记录与可视化,监控机械臂运动状态
视频讲解: MuJoCo 关节角速度记录与可视化,监控机械臂运动状态 代码仓库:GitHub - LitchiCheng/mujoco-learning 关节空间的轨迹优化,实际上是对于角速度起到加减速规划的控制,故一般来说具有该效果的速度变化会显得丝…...
:剖析用户价值与商业模式拼图)
精益数据分析(27/126):剖析用户价值与商业模式拼图
精益数据分析(27/126):剖析用户价值与商业模式拼图 在创业和数据分析的领域中,每一次深入学习都是一次成长的契机。今天,我们继续秉持共同进步的理念,深入研读《精益数据分析》,剖析用户价值的…...

Neo4j 常用查询语句
Neo4j 常用查询语句 Neo4j 是一个图数据库,查询语言是 Cypher,它类似于 SQL 但针对图形数据进行了优化。Cypher 语法直观易懂,适合用来处理图数据。本文将介绍一些 Neo4j 中常用的查询语句,帮助你快速掌握图数据的操作方法。 一…...
LVGL模拟器:NXP GUIDER+VSCODE
1. 下载安装包 NXP GUIDER:GUI Guider | NXP 半导体 CMAKE:Download CMake MINGW:https://github.com/niXman/mingw-builds-binaries/releases SDL2:https://github.com/libsdl-org/SDL/releases/tag/release-2.30.8 VSCODE&…...
《USB技术应用与开发》第四讲:实现USB鼠标
一、标准鼠标分析 1.1简介 1.2页面显示 其中页面显示的“”不用管它,因为鼠标作为物理抓包,里面有时候会抓到一些错误,不一定是真正的通讯错误,很可能是本身线路接触质量不好等原因才打印出来的“”。 1.3按下鼠标左键 &#x…...
一、鸿蒙编译篇
一、下载源码和编译 https://blog.csdn.net/xusiwei1236/article/details/142675221 https://blog.csdn.net/xiaolizibie/article/details/146375750 https://forums.openharmony.cn/forum.php?modviewthread&tid897 repo init -u https://gitee.com/openharmony/mani…...

DataStreamAPI实践原理——计算模型
引入 Apache Flink 是一个框架和分布式处理引擎,用于在 无边界 和 有边界 数据流上进行有状态的计 算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。Flink可以处理批数据也可以处理流数据,本质上,流处理…...
得物业务参数配置中心架构综述
一、背景 现状与痛点 在目前互联网飞速发展的今天,企业对用人的要求越来越高,尤其是后端的开发同学大部分精力都要投入在对复杂需求的处理,以及代码架构,稳定性的工作中,在对比下,简单且重复的CRUD就显得…...
【算法】单词搜索、最短距离
单词搜索 这道题主要考察了深度优先遍历(DFS)算法。 我们通过几个简单例子来分析一些细节问题: 1. 要搜索的单词串:abc 搜索的过程中必须按照字母顺序,首先从矩阵中的第一个元素开始搜索,遇到字母a则开始深度优先遍历࿰…...
Python函数基础:简介,函数的定义,函数的调用和传入参数,函数的返回值
目录 函数简介 函数定义,调用,传入参数,返回值 函数的定义 函数的调用和传入参数 函数的返回值 函数简介 函数简介:函数是组织好,可重复使用,用来实现特定功能(特定需求)的代码…...
基于FFmpeg命令行的实时图像处理与RTSP推流解决方案
前言 在一些项目开发过程中需要将实时处理的图像再实时的将结果展示出来,此时如果再使用一张一张图片显示的方式展示给开发者,那么图像窗口的反复开关将会出现窗口闪烁的问题,实际上无法体现出动态画面的效果。因此,需要使用码流…...

【随笔】地理探测器原理与运用
文章目录 一、作者与下载1.1 软件作者1.2 软件下载 二、原理简述2.1 空间分异性与地理探测器的提出2.2 地理探测器的数学模型2.21 分异及因子探测2.22 交互作用探测2.23 风险区与生态探测 三、使用:excel 一、作者与下载 1.1 软件作者 作者: DOI: 10.…...

【人工智能】Python中的深度学习模型部署:从训练到生产环境
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 随着深度学习在各个领域的应用日益增多,如何将训练好的深度学习模型高效地部署到生产环境中,成为了开发者和数据科学家的重要课题。本文将…...

Rule.resource作用说明
1. 说明 作用 Rule.resource 用于定义哪些文件需要被当前规则处理。它是对传统 test、include、exclude 的更底层封装,支持更灵活的匹配方式。 与 test/include/exclude 的关系 test: /.js$/ 等价于resource: { test: /.js$/ } include: path.resolve(__dirname, ‘…...
来提高线程的复用率,减少线程创建和销毁的开销)
C++如何设计线程池(thread pool)来提高线程的复用率,减少线程创建和销毁的开销
线程池的基本概念与多线程编程中的角色 线程池,顾名思义,是一种管理和复用线程的资源池。它的核心思想在于预先创建一定数量的线程,并将这些线程保持在空闲状态,等待任务的分配。一旦有任务需要执行,线程池会从池中取出…...

从零开始使用SSH链接目标主机(包括Github添加SSH验证,主机连接远程机SSH验证)
添加ssh密钥(当前机生成和远程机承认) 以下是从头开始生成自定义名称的SSH密钥的完整步骤(以GitHub为例,适用于任何SSH服务): 1. 生成自定义名称的SSH密钥对 # 生成密钥对(-t 指定算法,-f 指定路径和名称…...
Maxscale实现Mysql的读写分离
介绍: Maxscale是mariadb开发的一个MySQL数据中间件,配置简单,能够实现读写分离,并且能根据主从状态实现写库的自动切换,对多个服务器实现负载均衡。 实验环境: 基于gtid的主从同步的基础上进行配置 中…...