365打卡第R3周: RNN-心脏病预测
🍨 本文为🔗365天深度学习训练营中的学习记录博客
🍖 原作者:K同学啊

🏡 我的环境:
语言环境:Python3.10
编译器:Jupyter Lab
深度学习环境:torch==2.5.1 torchvision==0.20.1
------------------------------分割线---------------------------------
import numpy as np
import pandas as pd
import torch
from torch import nn
import torch.nn.functional as F
import seaborn as sns#设置GPU训练,也可以使用CPU
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
df = pd.read_csv("data/heart.csv")df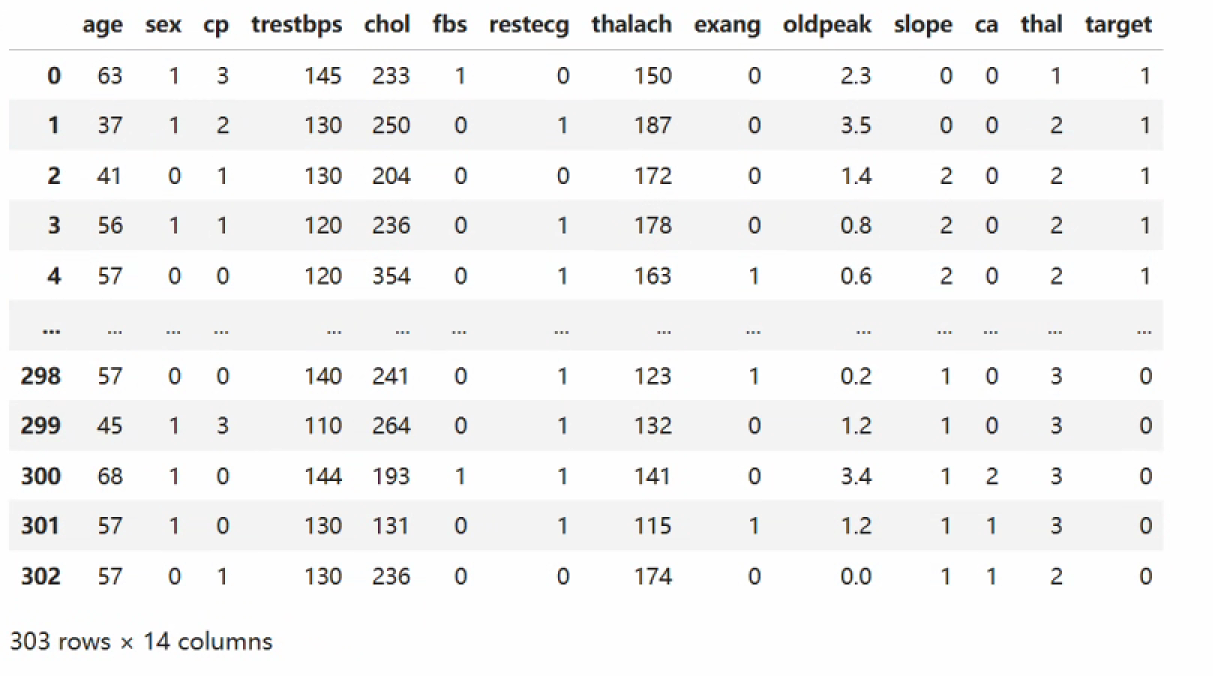
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_splitX = df.iloc[:,:-1]
y = df.iloc[:,-1]# 将每一列特征标准化为标准正太分布,注意,标准化是针对每一列而言的
sc = StandardScaler()
X = sc.fit_transform(X)X = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.int64)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.1, random_state = 1)X_train.shape, y_train.shapefrom torch.utils.data import TensorDataset, DataLoadertrain_dl = DataLoader(TensorDataset(X_train, y_train),batch_size=64, shuffle=False)test_dl = DataLoader(TensorDataset(X_test, y_test),batch_size=64, shuffle=False)
class model_rnn(nn.Module):def __init__(self):super(model_rnn, self).__init__()self.rnn0 = nn.RNN(input_size=13 ,hidden_size=200, num_layers=1, batch_first=True)self.fc0 = nn.Linear(200, 50)self.fc1 = nn.Linear(50, 2)def forward(self, x):out, hidden1 = self.rnn0(x) out = self.fc0(out) out = self.fc1(out) return out model = model_rnn().to(device)
model
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_lossdef test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_lossloss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.Adam(model.parameters(),lr=learn_rate)
epochs = 50train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = opt.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))print("="*20, 'Done', "="*20)
import matplotlib.pyplot as plt
from datetime import datetime
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息current_time = datetime.now() # 获取当前时间plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 200 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()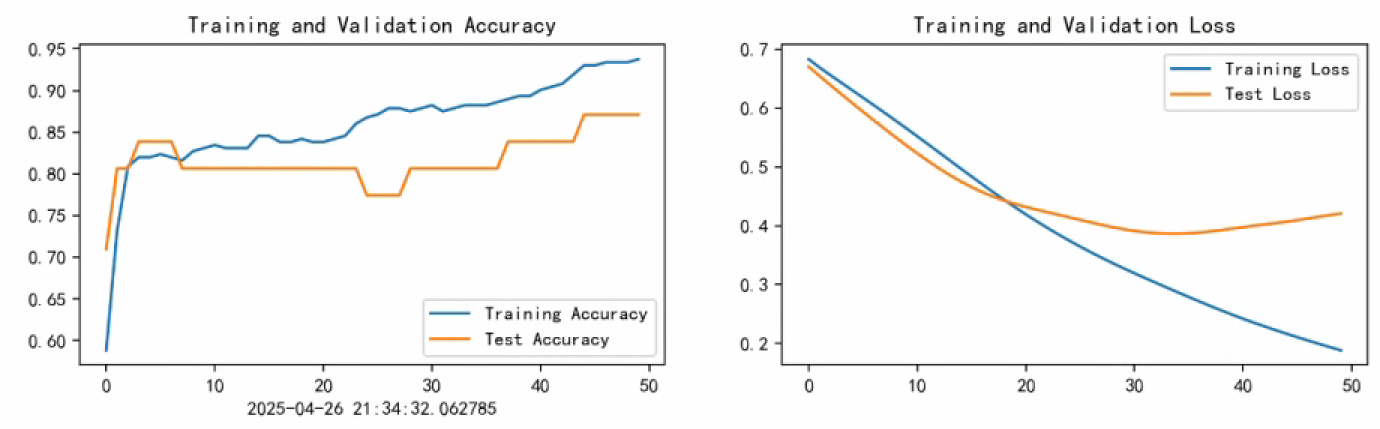
print("==============输入数据Shape为==============")
print("X_test.shape:",X_test.shape)
print("y_test.shape:",y_test.shape)pred = model(X_test.to(device)).argmax(1).cpu().numpy()print("\n==============输出数据Shape为==============")
print("pred.shape:",pred.shape)import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay# 计算混淆矩阵
cm = confusion_matrix(y_test, pred)plt.figure(figsize=(6,5))
plt.suptitle('')
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues")# 修改字体大小
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.title("Confusion Matrix", fontsize=12)
plt.xlabel("Predicted Label", fontsize=10)
plt.ylabel("True Label", fontsize=10)# 显示图
plt.tight_layout() # 调整布局防止重叠
plt.show()test_X = X_test[0].reshape(1, -1) # X_test[0]即我们的输入数据pred = model(test_X.to(device)).argmax(1).item()
print("模型预测结果为:",pred)
print("=="*20)
print("0:不会患心脏病")
print("1:可能患心脏病")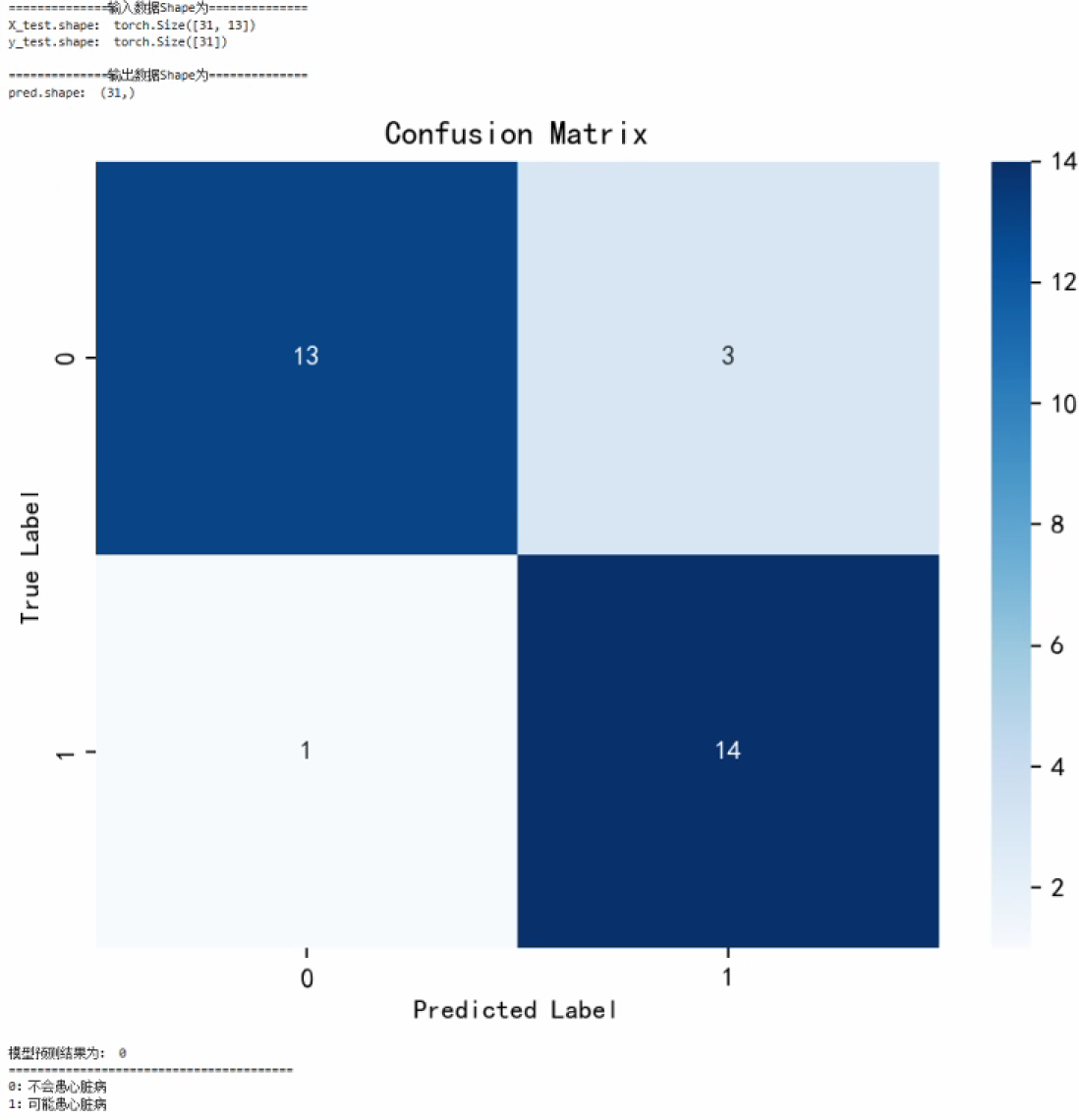
测试集预测准确率为87.1%,为了进一步提高模型性能,做了如下改进:
1、调整数据加载方式(启用Shuffle),打乱训练数据顺序,使每个batch的数据分布更均匀,提升模型泛化能力。
# 修改前(shuffle=False)
train_dl = DataLoader(..., shuffle=False)# 修改后
train_dl = DataLoader(..., shuffle=True)2、调整优化器和学习率
# 修改前
learn_rate = 1e-4
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)# 修改后
opt = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-5) # 增加L2正则
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(opt, 'max', patience=5) # 动态调整学习率

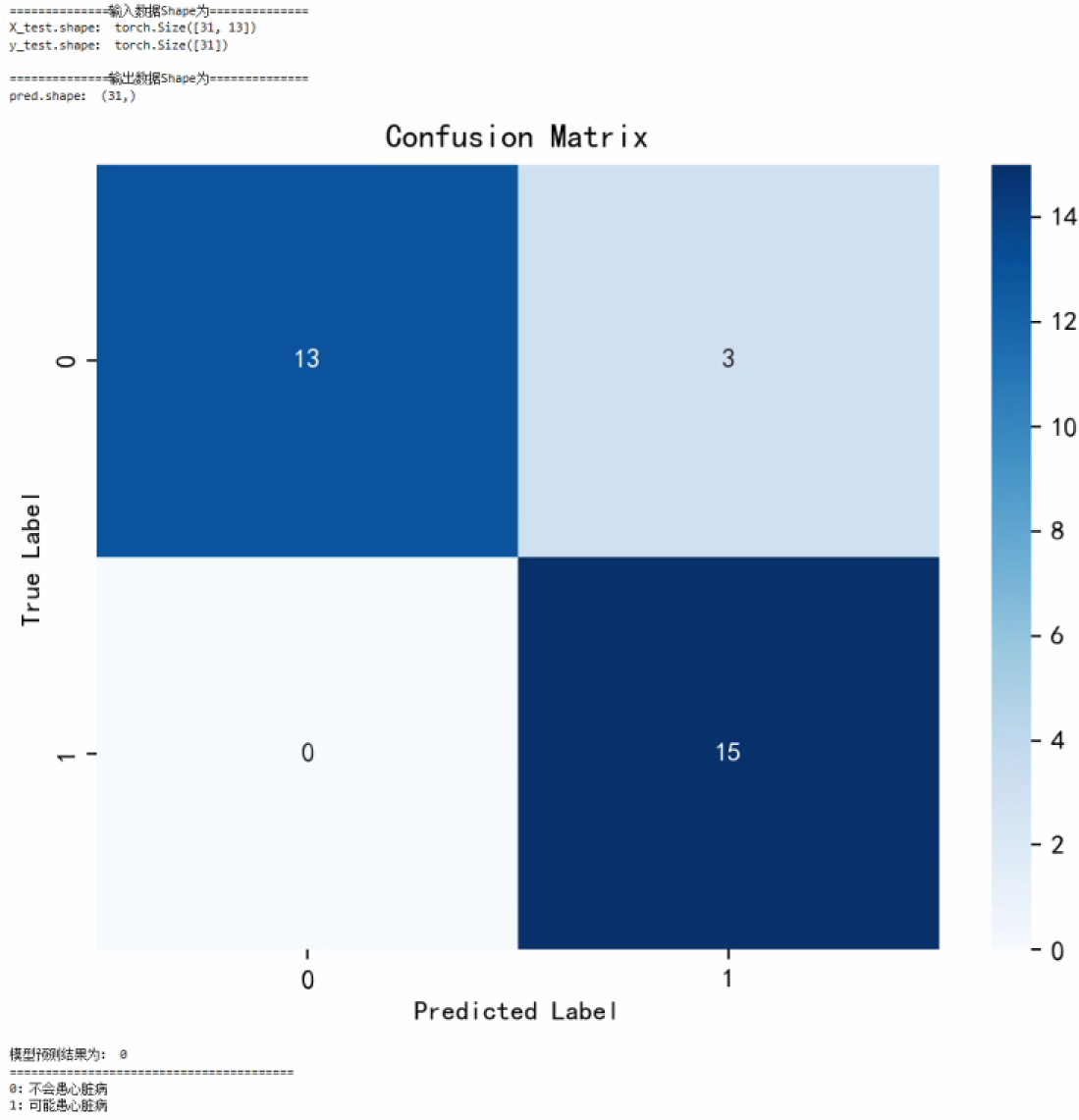
修改之后预测率最高超过了90%,预测准确率也有所提高
------------------小结---------------------------
循环神经网络(RNN)是一种专门处理序列数据的神经网络模型,其核心特点可归纳如下:
一、序列建模能力
RNN通过循环连接结构处理序列输入(如文本、语音、时间序列),每个时间步的隐藏状态(hidden state)不仅依赖当前输入,还继承前一时间步的状态。这种设计使其能够捕捉时间依赖性,例如句子中单词的上下文关系或股价的历史趋势。
二、参数共享机制
所有时间步共享同一组权重参数(如输入-隐藏层和隐藏-隐藏层矩阵),显著减少模型复杂度并提升泛化能力。这一特性使其能灵活处理变长序列,无需为不同长度输入单独设计网络。
三、记忆性与动态状态
RNN通过隐藏状态的递归更新实现记忆功能,理论上可保留无限长的历史信息。例如,在机器翻译中,模型能利用前文信息生成连贯的译文。但实际中受限于梯度问题,长程依赖能力较弱。
相关文章:
365打卡第R3周: RNN-心脏病预测
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 🏡 我的环境: 语言环境:Python3.10 编译器:Jupyter Lab 深度学习环境:torch2.5.1 torchvision0…...

1.1.1 用于排序规则的IComparable接口使用介绍
在C#中,IComparable 是一个核心接口,用于定义对象的自然排序规则。实现该接口的类可以指定其实例如何与其他实例比较大小,从而支持排序操作(如 Array.Sort()、List.Sort()). 1. 该接口CompareTo返回值含义:…...
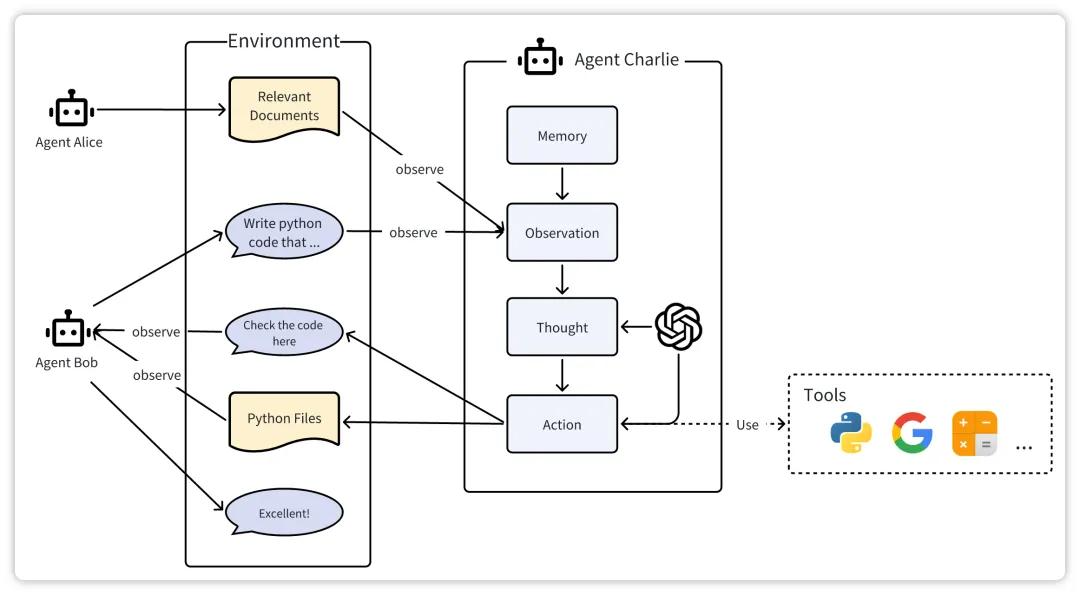
【实战】基于强化学习的 Agent 训练框架全流程拆解
一、引言 在人工智能蓬勃发展的今天,强化学习(Reinforcement Learning, RL)作为让智能体(Agent)在复杂环境中自主学习并做出最优决策的核心技术,正日益受到关注。从游戏领域中击败人类顶尖选手的 AlphaGo&a…...

【音视频】⾳频处理基本概念及⾳频重采样
一、重采样 1.1 什么是重采样 所谓的重采样,就是改变⾳频的采样率、sample format、声道数等参数,使之按照我们期望的参数输出。 1.2 为什么要重采样 为什么要重采样? 当然是原有的⾳频参数不满⾜我们的需求,⽐如在FFmpeg解码⾳频的时候…...

Prompt 结构化提示工程
Prompt 结构化提示工程 目前ai开发工具都大同小异,随着deepseek的流行,ai工具的能力都差不太多,功能基本都覆盖到了。而prompt能力反而是需要更加关注的(说白了就是能不能把需求清晰的输出成文档)。因此大家可能需要加…...

设计心得——数据结构的意义
一、数据结构 在老一些的程序员中,可能都听说过,程序其实就是数据结构算法这种说法。它是由尼克劳斯维特在其著作《算法数据结构程序》中提出的,然后在一段时期内这种说法非常流行。这里不谈论其是否正确,只是通过这种提法&#…...

【Pandas】pandas DataFrame rdiv
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

Pycharm 代理配置
Pycharm 代理配置 文章目录 Pycharm 代理配置1. 设置系统代理1.1 作用范围1.2 使用场景1.3 设置步骤 2. 设置 python 运行/调试代理2.1 作用范围2.2 使用场景2.3 设置步骤 Pycharm 工具作为一款强大的 IDE,其代理配置在实际开发中也是必不可少的,下面介绍…...
)
GPU 加速库(CUDA/cuDNN)
现代数字图像处理与深度学习任务对计算效率提出极高要求,GPU 加速库通过硬件并行计算能力大幅提升数据处理速度。 一、CUDA 并行计算架构深度解析 1. 架构设计与硬件协同 CPU-GPU 异构计算模型CPU 作为主机端,主要负责逻辑控制、任务调度以及数据预处…...

Spring Native:GraalVM原生镜像编译与性能优化
文章目录 引言一、Spring Native与GraalVM基础1.1 GraalVM原理与优势1.2 Spring Native架构设计 二、原生镜像编译实践2.1 构建配置与过程2.2 常见问题与解决方案 三、性能优化技巧3.1 内存占用优化3.2 启动时间优化3.3 实践案例分析 总结 引言 微服务架构的普及推动了轻量级、…...

JAVA JVM面试题
你的项目中遇到什么问题需要jvm调优,怎么调优的,堆的最小值和最大值设置为什么不设置成一样大? 在项目中,JVM调优通常源于以下典型问题及对应的调优思路,同时关于堆内存参数(-Xms/-Xmx)的设置逻…...
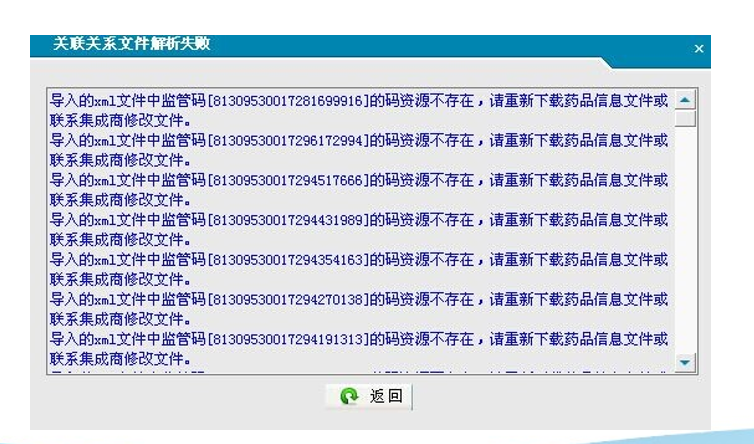
药监平台上传数据报资源码不存在
问题:电子监管码上传药监平台提示“导入的资源码不存在” 现象:从生产系统导出的关联关系数据包上传到药监平台时显示: 原因:上传数据包的通道的资源码与数据包的资源码不匹配。 解决方法:检查药监平台和生产系统的药…...
)
世界比较权威的新车安全评鉴协会(汽车安全性测试,自动驾驶功能测试)
NCAP是英文“New Car Assessment Program”的缩写,即新车评价规程,最能考验汽车安全性的测试,在自动驾驶发展迅速的现阶段,安全问题频发,自动驾驶相关功能显然也需要进行测试评价。 1. 欧洲新车安全评鉴协会ÿ…...
【Linux应用】交叉编译环境配置,以及最简单粗暴的环境移植(直接从目标板上复制)
【Linux应用】交叉编译环境配置,以及最简单粗暴的环境移植(直接从目标板上复制) 文章目录 交叉编译器含有三方库的交叉编译直接从目标板上复制编译环境glibc库不一致报错方法1方法2 附录:ZERO 3烧录ZERO 3串口shell外设挂载连接Wi…...

CentOS 7 磁盘阵列搭建与管理全攻略
CentOS 7 磁盘阵列搭建与管理全攻略 在数据存储需求日益增长的今天,磁盘阵列(RAID)凭借其卓越的性能、数据安全性和可靠性,成为企业级服务器和数据中心的核心存储解决方案。CentOS 7 作为一款稳定且功能强大的 Linux 操作系统&am…...
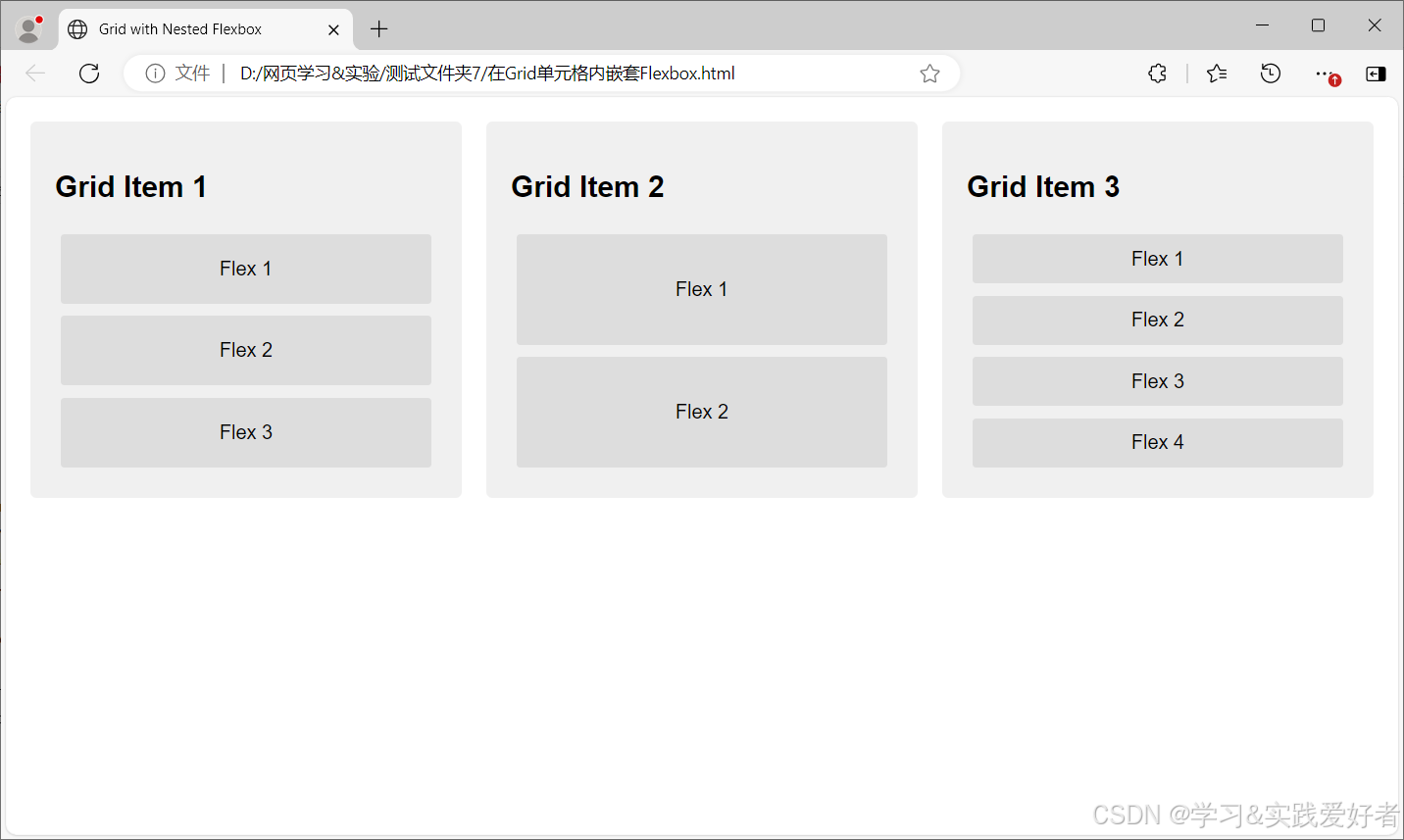
CSS3布局方式介绍
CSS3布局方式介绍 CSS3布局(Layout)系统是现代网页设计中用于构建页面结构和控制元素排列的一组强大工具。CSS3提供了多种布局方式,每种方式都有其适用场景,其中最常用的是Flexbox和CSS Grid。 先看传统上几种布局方式ÿ…...
FPGA设计 时空变换
1、时空变换基本概念 1.1、时空概念简介 时钟速度决定完成任务需要的时间,规模的大小决定完成任务所需要的空间(资源),因此速度和规模就是FPGA中时间和空间的体现。 如果要提高FPGA的时钟,每个clk内组合逻辑所能做的事…...

AI心理健康服务平台项目面试实战
AI心理健康服务平台项目面试实战 第一轮提问: 面试官: 请简要介绍一下AI心理健康服务平台的核心技术架构。在AI领域,心理健康服务的机遇主要体现在哪些方面?如何利用NLP技术提升用户与AI的心理健康对话体验? 马架构…...
)
Eigen稀疏矩阵类 (SparseMatrix)
1. SparseMatrix 核心属性与初始化 模板参数 cpp SparseMatrix<Scalar, Options, StorageIndex> Scalar:数据类型(如 double, float)。 Options:存储格式(默认 ColMajor,可选 RowMajor࿰…...

《AI大模型趣味实战》智能Agent和MCP协议的应用实例:搭建一个能阅读DOC文件并实时显示润色改写过程的Python Flask应用
智能Agent和MCP协议的应用实例:搭建一个能阅读DOC文件并实时显示润色改写过程的Python Flask应用 引言 随着人工智能技术的飞速发展,智能Agent与模型上下文协议(MCP)的应用场景越来越广泛。本报告将详细介绍如何基于Python Flask框架构建一个智能应用&…...
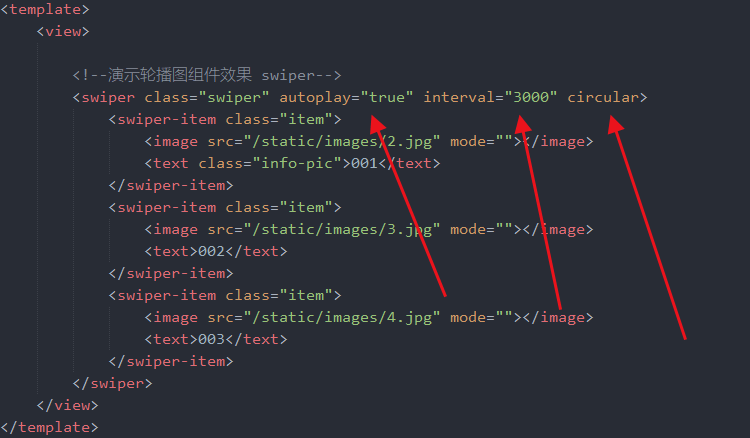
uniapp开发03-轮播图组件swiper的简单使用案例
uniapp开发03-轮播图组件swiper的简单使用案例!这个仅仅是官方提供的一个轮播图组件啊。实际上我们项目开发的时候,会应用到其他第三方公司的轮播图组件资源!效果更强大。兼容性更强。 废话不多说,我们直接上代码。分析代码。 &l…...

DAM-3B,英伟达推出的多模态大语言模型
DAM-3B是什么 DAM-3B(Describe Anything 3B)是英伟达推出的一款多模态大语言模型,专门用于为图像和视频中的特定区域生成详细描述。用户可以通过点、边界框、涂鸦或掩码等方式来标识目标区域,从而得到精准且符合上下文的文本描述…...

【虚幻C++笔记】碰撞检测
目录 碰撞检测参数详情示例用法 碰撞检测 显示名称中文名称CSphere Trace By Channel按通道进行球体追踪UKismetSystemLibrary::SphereTraceSingleSphere Trace By Profile按描述文件进行球体追踪UKismetSystemLibrary::SphereTraceSingleByProfileSphere Trace For Objects针…...

C++学习:六个月从基础到就业——STL:分配器与设计原理
C学习:六个月从基础到就业——STL:分配器与设计原理 本文是我C学习之旅系列的第三十篇技术文章,也是第二阶段"C进阶特性"的第九篇,主要介绍C STL中的分配器设计原理与实现。查看完整系列目录了解更多内容。 引言 在之前…...
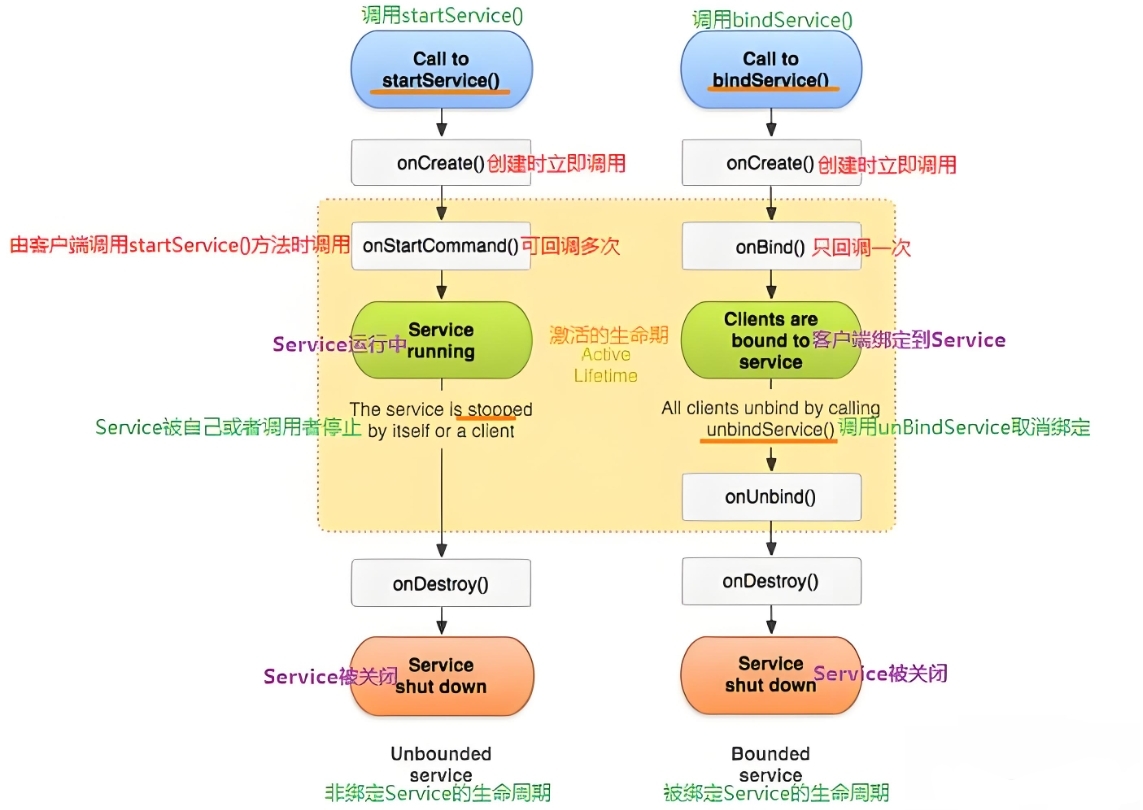
【Android】四大组件之Service
目录 一、什么是Service 二、启停 Service 三、绑定 Service 四、前台服务 五、远程服务扩展 六、服务保活 七、服务启动方法混用 你可以把Service想象成一个“后台默默打工的工人”。它没有UI界面,默默地在后台干活,比如播放音乐、下载文件、处理…...
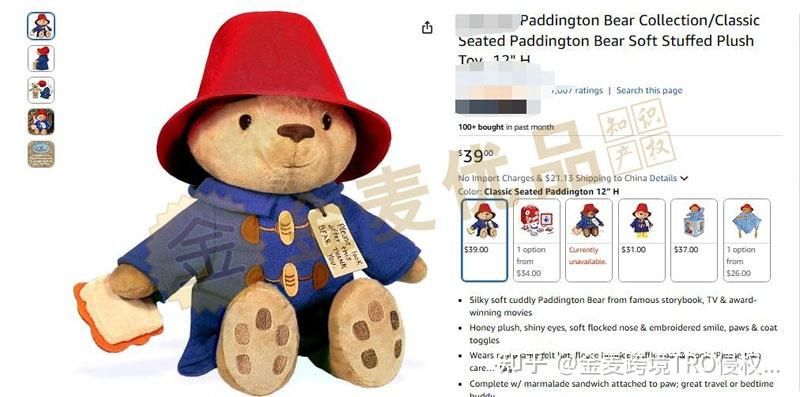
TRO再添新案 TME再拿下一热门IP,涉及Paddington多个商标
4月2日和4月8日,TME律所代理Paddington & Company Ltd.对热门IP Paddington Bear帕丁顿熊的多类商标发起维权,覆盖文具、家居用品、毛绒玩具、纺织用品、游戏、电影、咖啡、填充玩具等领域。跨境卖家需立即排查店铺内的相关产品! 案件基…...

spring-session-data-redis使用
spring-session-data-redis是spring session项目中的一个子模块,,他允许你使用Redis来存储http session,,从而支持多个应用实例之间共享session,,,即分布式session 原理: EnableRed…...
)
图论---LCA(倍增法)
预处理 O( n logn ),查询O( log n ) #include<bits/stdc.h> using namespace std; typedef pair<int,int> pii; const int N40010,M2*N;//是无向边,边需要见两边int n,m; vector<int> g[N]; //2的幂次范围 0~15 int depth[N],fa[N][1…...

WPF实现类似Microsoft Visual Studio2022界面效果及动态生成界面技术
WPF实现类似VS2022界面效果及动态生成界面技术 一、实现类似VS2022界面效果 1. 主窗口布局与主题 <!-- MainWindow.xaml --> <Window x:Class"VsStyleApp.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x…...

【安全扫描器原理】网络扫描算法
【安全扫描器原理】网络扫描算法 1.非顺序扫描2.高速扫描 & 分布式扫描3.服务扫描 & 指纹扫描 1.非顺序扫描 参考已有的扫描器,会发现几乎所有的扫描器都无一例外地使用增序扫描,即对所扫描的端口自小到大依次扫描,殊不知࿰…...