从梯度消失到百层网络:ResNet 是如何改变深度学习成为经典的?

自AlexNet赢得2012年ImageNet竞赛以来,每个新的获胜架构通常都会增加更多层数以降低错误率。一段时间内,增加层数确实有效,但随着网络深度的增加,深度学习中一个常见的问题——梯度消失或梯度爆炸开始出现。
梯度消失问题会导致梯度值变得非常小,几乎趋近于零;而梯度爆炸问题则会导致梯度值变得非常大。这两种情况都会增加训练难度,并导致错误率上升,随着层数的增加,模型在训练和测试数据上的性能都会受到影响。
从下图可以看出,20层CNN 架构在训练和测试数据集上的表现均优于56层CNN架构。作者进一步分析了错误率,认为错误率是由梯度消失/爆炸引起的。
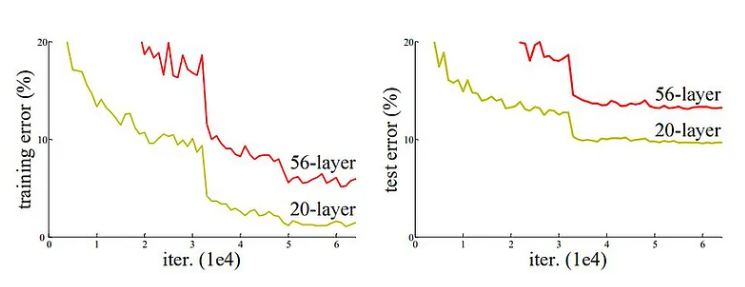
2015 年,微软研究院提出了一个划时代的网络结构——ResNet(残差网络),并提出了一个非常简单却极其有效的思想:
“如果某些层学不到什么有用特征,那不如直接跳过它们。”
一、ResNet简介
ResNet 的突破源于其使用了跳跃(或残差)连接,解决了长期存在的梯度消失和爆炸问题。这些连接使 ResNet 成为第一个成功训练超过 100 层的模型的网络,并在 ImageNet 和COCO目标检测任务上取得了最佳效果。
-
深度网络的挑战
在 ResNet 之前,非常深的神经网络面临两大挑战:
-
梯度消失:随着网络深度增加,反向传播过程中的梯度值趋于减小。这会减慢前几层的学习速度,从而限制网络在深度增加时学习有用特征的能力。
-
梯度爆炸:有时,在非常深的网络中,梯度会呈指数增长,导致数值不稳定,权重变得太大,从而导致模型失败。
这些问题导致深层模型的性能不如浅层模型。这种现象被称为“退化”,意味着添加更多层并不一定能提高准确率,反而往往会导致性能下降。
二、ResNet的创新点:跳过(残差)连接
跳过连接(或残差连接)的工作原理是,将较早层(例如,第 n-1 层)的输出直接添加到较晚层(例如,第 n+1 层)的输出。添加后,对结果应用 ReLU 激活函数。这意味着第 n 层实际上被“跳过”,从而使信息更容易在网络中流动。
这里 f(Xn-1) 表示卷积层 (n-1) 的输出被传递给 ReLU 激活函数
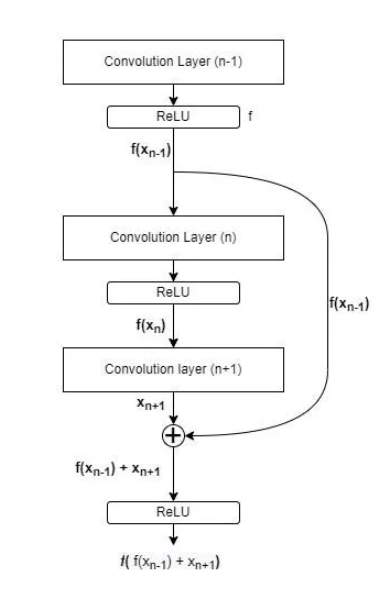
跳过连接的作用是确保即使第 n 层没有学到任何有用的信息(或输出为零),我们也不会丢失重要信息。相反,第 (n-1) 层的输出会向前传递,并与第 (n+1) 层的输出合并。
如果第 n 层没有增加价值,网络可以“跳过”它,从而保持一致的性能。如果两层都提供了有用的信息,那么将它们结合起来,就能利用两种信息源来提升网络的整体性能。
三、Resnet 的架构
以下是 Resnet-18 的架构和层配置,取自研究论文《图像识别的深度残差学习》(论文地址:https://arxiv.org/abs/1512.03385)
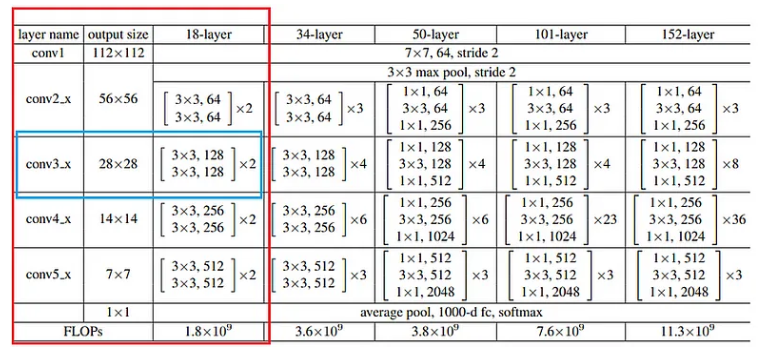
让我们选择 Conv3_x 块,并尝试了解其内部发生的情况。让我们使用卷积块和恒等块来理解这一点。
-
卷积块
目的:当输入和输出的尺寸(形状)不同时,使用卷积块,原因如下:
-
空间大小(特征图的高度和宽度)的变化。
-
频道数量的变化。
-
身份区块
目的:当输入和输出的尺寸(形状)相同时,使用身份块,允许将输入直接添加到输出而无需任何转换。
通过示例理解卷积和身份块,使用卷积和身份块的 Conv3_x 块数据流
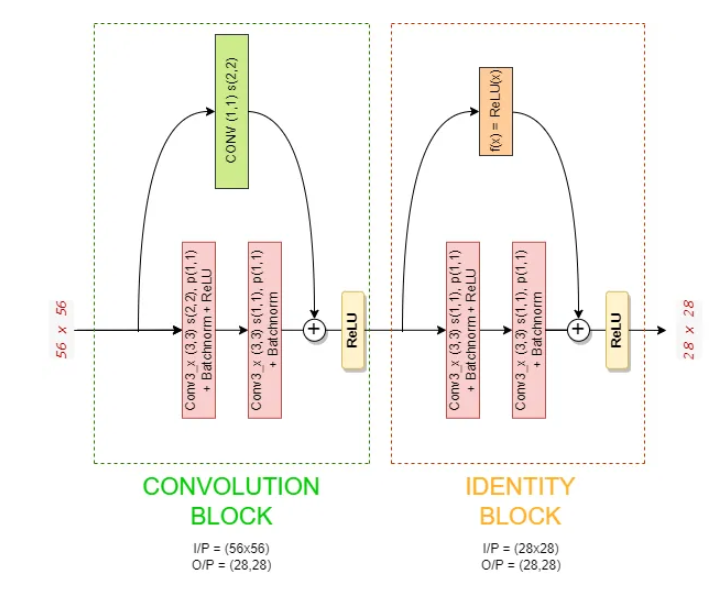
上图告诉我们 56x56 图像如何通过 Conv3_x 块传播的细节,现在我们将看看图像在这些块内的每个步骤中是如何转换的。
-
代码
class ResNet18(nn.Module):def __init__(self, n_classes):super(ResNet18, self).__init__()self.dropout_percentage = 0.5self.relu = nn.ReLU()# BLOCK-1 (starting block) input=(224x224) output=(56x56)self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=(7,7), stride=(2,2), padding=(3,3))self.batchnorm1 = nn.BatchNorm2d(64)self.maxpool1 = nn.MaxPool2d(kernel_size=(3,3), stride=(2,2), padding=(1,1))# BLOCK-2 (1) input=(56x56) output = (56x56)self.conv2_1_1 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_1_1 = nn.BatchNorm2d(64)self.conv2_1_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_1_2 = nn.BatchNorm2d(64)self.dropout2_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-2 (2)self.conv2_2_1 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_2_1 = nn.BatchNorm2d(64)self.conv2_2_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_2_2 = nn.BatchNorm2d(64)self.dropout2_2 = nn.Dropout(p=self.dropout_percentage)# BLOCK-3 (1) input=(56x56) output = (28x28)self.conv3_1_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3,3), stride=(2,2), padding=(1,1))self.batchnorm3_1_1 = nn.BatchNorm2d(128)self.conv3_1_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm3_1_2 = nn.BatchNorm2d(128)self.concat_adjust_3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(1,1), stride=(2,2), padding=(0,0))self.dropout3_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-3 (2)self.conv3_2_1 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm3_2_1 = nn.BatchNorm2d(128)self.conv3_2_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm3_2_2 = nn.BatchNorm2d(128)self.dropout3_2 = nn.Dropout(p=self.dropout_percentage)# BLOCK-4 (1) input=(28x28) output = (14x14)self.conv4_1_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3,3), stride=(2,2), padding=(1,1))self.batchnorm4_1_1 = nn.BatchNorm2d(256)self.conv4_1_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm4_1_2 = nn.BatchNorm2d(256)self.concat_adjust_4 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(1,1), stride=(2,2), padding=(0,0))self.dropout4_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-4 (2)self.conv4_2_1 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm4_2_1 = nn.BatchNorm2d(256)self.conv4_2_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm4_2_2 = nn.BatchNorm2d(256)self.dropout4_2 = nn.Dropout(p=self.dropout_percentage)# BLOCK-5 (1) input=(14x14) output = (7x7)self.conv5_1_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=(3,3), stride=(2,2), padding=(1,1))self.batchnorm5_1_1 = nn.BatchNorm2d(512)self.conv5_1_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm5_1_2 = nn.BatchNorm2d(512)self.concat_adjust_5 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=(1,1), stride=(2,2), padding=(0,0))self.dropout5_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-5 (2)self.conv5_2_1 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm5_2_1 = nn.BatchNorm2d(512)self.conv5_2_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm5_2_2 = nn.BatchNorm2d(512)self.dropout5_2 = nn.Dropout(p=self.dropout_percentage)# Final Block input=(7x7) self.avgpool = nn.AvgPool2d(kernel_size=(7,7), stride=(1,1))self.fc = nn.Linear(in_features=1*1*512, out_features=1000)self.out = nn.Linear(in_features=1000, out_features=n_classes)# ENDdef forward(self, x):# block 1 --> Starting blockx = self.relu(self.batchnorm1(self.conv1(x)))op1 = self.maxpool1(x)# block2 - 1x = self.relu(self.batchnorm2_1_1(self.conv2_1_1(op1))) # conv2_1 x = self.batchnorm2_1_2(self.conv2_1_2(x)) # conv2_1x = self.dropout2_1(x)# block2 - Adjust - No adjust in this layer as dimensions are already same# block2 - Concatenate 1op2_1 = self.relu(x + op1)# block2 - 2x = self.relu(self.batchnorm2_2_1(self.conv2_2_1(op2_1))) # conv2_2 x = self.batchnorm2_2_2(self.conv2_2_2(x)) # conv2_2x = self.dropout2_2(x)# op - block2op2 = self.relu(x + op2_1)# block3 - 1[Convolution block]x = self.relu(self.batchnorm3_1_1(self.conv3_1_1(op2))) # conv3_1x = self.batchnorm3_1_2(self.conv3_1_2(x)) # conv3_1x = self.dropout3_1(x)# block3 - Adjustop2 = self.concat_adjust_3(op2) # SKIP CONNECTION# block3 - Concatenate 1op3_1 = self.relu(x + op2)# block3 - 2[Identity Block]x = self.relu(self.batchnorm3_2_1(self.conv3_2_1(op3_1))) # conv3_2x = self.batchnorm3_2_2(self.conv3_2_2(x)) # conv3_2 x = self.dropout3_2(x)# op - block3op3 = self.relu(x + op3_1)# block4 - 1[Convolition block]x = self.relu(self.batchnorm4_1_1(self.conv4_1_1(op3))) # conv4_1x = self.batchnorm4_1_2(self.conv4_1_2(x)) # conv4_1x = self.dropout4_1(x)# block4 - Adjustop3 = self.concat_adjust_4(op3) # SKIP CONNECTION# block4 - Concatenate 1op4_1 = self.relu(x + op3)# block4 - 2[Identity Block]x = self.relu(self.batchnorm4_2_1(self.conv4_2_1(op4_1))) # conv4_2x = self.batchnorm4_2_2(self.conv4_2_2(x)) # conv4_2x = self.dropout4_2(x)# op - block4op4 = self.relu(x + op4_1)# block5 - 1[Convolution Block]x = self.relu(self.batchnorm5_1_1(self.conv5_1_1(op4))) # conv5_1x = self.batchnorm5_1_2(self.conv5_1_2(x)) # conv5_1x = self.dropout5_1(x)# block5 - Adjustop4 = self.concat_adjust_5(op4) # SKIP CONNECTION# block5 - Concatenate 1op5_1 = self.relu(x + op4)# block5 - 2[Identity Block]x = self.relu(self.batchnorm5_2_1(self.conv5_2_1(op5_1))) # conv5_2x = self.batchnorm5_2_1(self.conv5_2_1(x)) # conv5_2x = self.dropout5_2(x)# op - block5op5 = self.relu(x + op5_1)# FINAL BLOCK - classifier x = self.avgpool(op5)x = x.reshape(x.shape[0], -1)x = self.relu(self.fc(x))x = self.out(x)return x实现后,我们可以直接创建此类的对象并传递数据集的输出类的数量,并使用它在任何图像数据上训练我们的网络。
-
这些块为什么有用?
-
卷积块处理空间分辨率或通道数量的变化,同时保留残差连接。
-
身份块专注于在不改变输入维度的情况下学习附加特征。
-
它们共同作用,允许梯度流,即使某些层不能有效学习,也能使深度网络有效地训练
四、ResNet为何成为经典
ResNet的成功,不在于它堆了多少层,而在于它对“深层神经网络如何训练”这个根本问题给出了一个优雅解法:如果学不会,就跳过去!
这种看似简单的思想,却释放了深度学习的潜力,也为后续模型设计开辟了全新路径,DenseNet、Mask R-CNN、HRNet、Swin Transformer……都离不开它的残差思想。
所以,ResNet 不只是一种网络架构,更是一种范式的转变——这,正是它成为经典的原因。

相关文章:
从梯度消失到百层网络:ResNet 是如何改变深度学习成为经典的?
自AlexNet赢得2012年ImageNet竞赛以来,每个新的获胜架构通常都会增加更多层数以降低错误率。一段时间内,增加层数确实有效,但随着网络深度的增加,深度学习中一个常见的问题——梯度消失或梯度爆炸开始出现。 梯度消失问题会导致梯…...

2025.4.26总结
今天把马良老师的《职场十二法则》看完后,感触极大,这们课程就是一场职场启蒙课。 虽然看过不少关于职场的书籍,但大多数是关于职场进阶,方法方面的。并没有解答“面对未来二三十年的职场生涯,我该怎么去看待自己的工…...
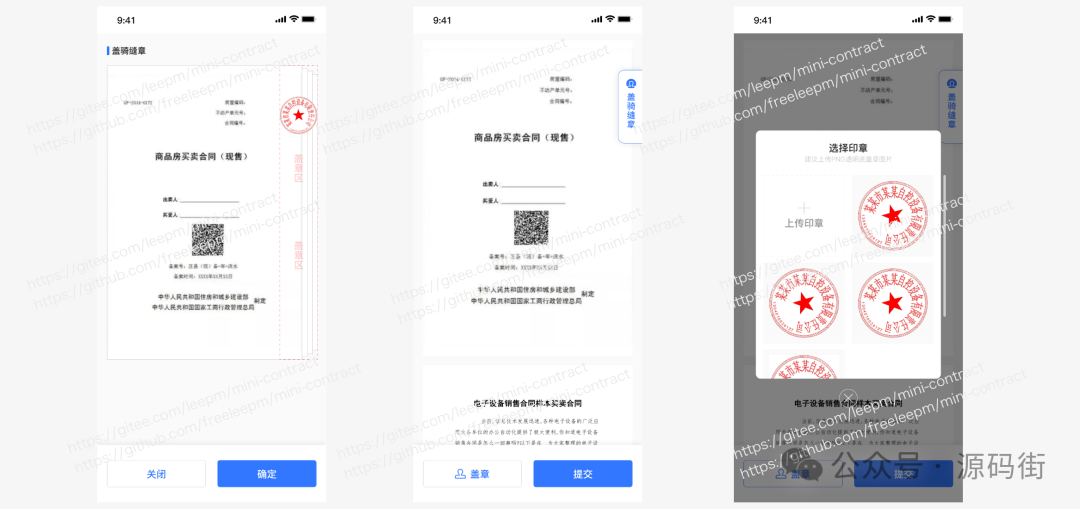
Uni-App 多端电子合同开源项目介绍
项目概述 本项目是一款基于 uni-app框架开发的多端电子合同管理平台,旨在为企业及个人用户提供高效、安全、便捷的电子合同签署与管理服务。项目创新性地引入了 “证据链”与“非证据链”两种签署模式,满足不同场景下的签署需求,支持多种签署…...

多语言笔记系列:共享数据
在笔记中共享数据(变量) 使用 .NET 交互式内核,可以在单个笔记本中以多种语言编写代码。为了利用每种语言的不同优势,您会发现在它们之间共享数据很有用。即一种语言的变量,可以在其它语言中使用。 默认情况下,.NET Interactive …...
如何使用SeedProd创建无缝的WordPress维护页面
不管您刚接触 WordPress ,还是经验丰富的站长,SeedProd 都是创建网站维护页面的得力助手。通过SeedProd,您可以轻松创建一个与网站风格一致、功能齐全的维护页面,让您的用户在网站维护期间也能感受到您的专业与关怀。本文将为您提…...
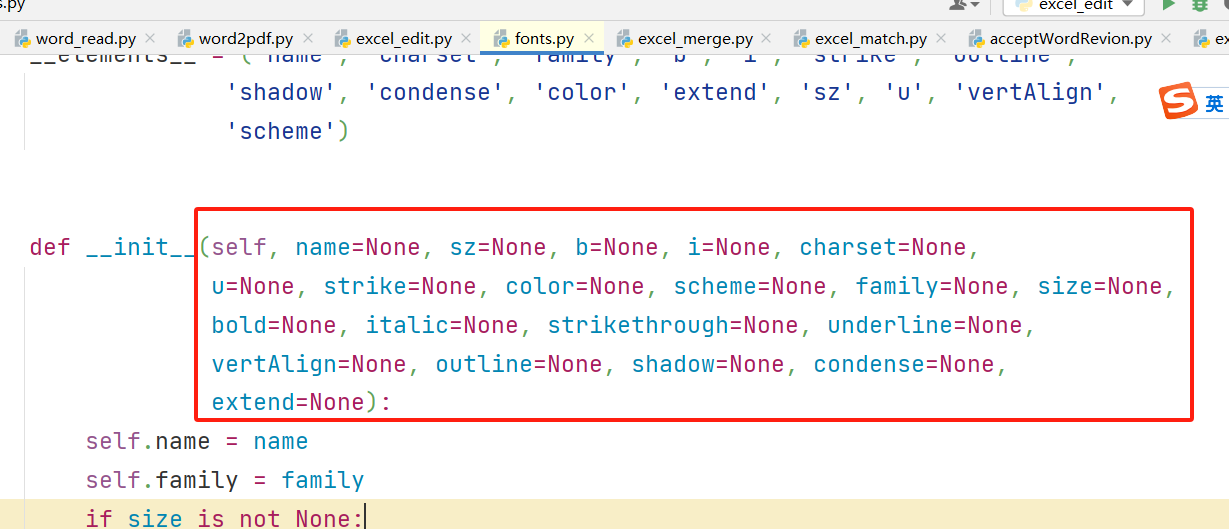
使用Python设置excel单元格的字体(font值)
一、前言 通过使用Python的openpyxl库,来操作excel单元格,设置单元格的字体,也就是font值。 把学习的过程分享给大家。大佬勿喷! 二、程序展示 1、新建excel import openpyxl from openpyxl.styles import Font wb openpyxl.…...

【PCB工艺】推挽电路及交越失真
推挽电路(Push-Pull Circuit) 推挽电路(Push-Pull Circuit) 是一种常用于功率放大、电机驱动、音频放大等场合的电路结构,具有输出对称、效率高、失真小等优点。 什么是推挽电路? 推挽是指:由两种极性相反的器件(如 NPN 和 PNP、NMOS 和 PMOS)交替导通,一个“推”电…...

告别手动映射:在 Spring Boot 3 中优雅集成 MapStruct
在日常的后端开发中,我们经常需要在不同的对象之间进行数据转换,例如将数据库实体(Entity)转换为数据传输对象(DTO)发送给前端,或者将接收到的 DTO 转换为实体进行业务处理或持久化。手动进行这…...

uv run 都做了什么?
uv run 都做了什么? uv run <命令> [参数...] 的主要作用是:在一个由 uv 管理或发现的 Python 虚拟环境中,执行你指定的 <命令>。它会临时配置一个子进程的环境,使其表现得如同该虚拟环境已经被激活一样。这意味着&am…...
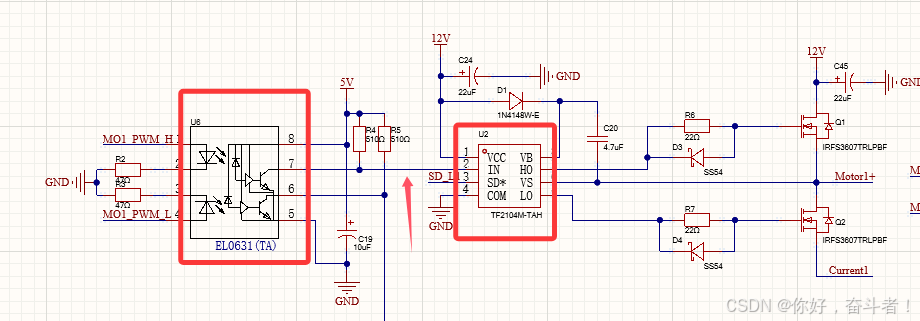
求解,如何控制三相无刷电机?欢迎到访评论
问题:通过一个集成的TF2104芯片控制H桥上桥臂和下桥臂,如何控制?还是说得需要PWM_UH和PWM_UL分开控制?...

Java ThreadLocal与内存泄漏
当我们利用 ThreadLocal 来管理数据时,我们不可避免地会面临内存泄漏的风险。 原因在于 ThreadLocal 的工作方式。当我们在当前线程的 ThreadLocalMap 中存储一个值时,一旦这个值不再需要,释放它就变得至关重要。如果不这样做,那么…...
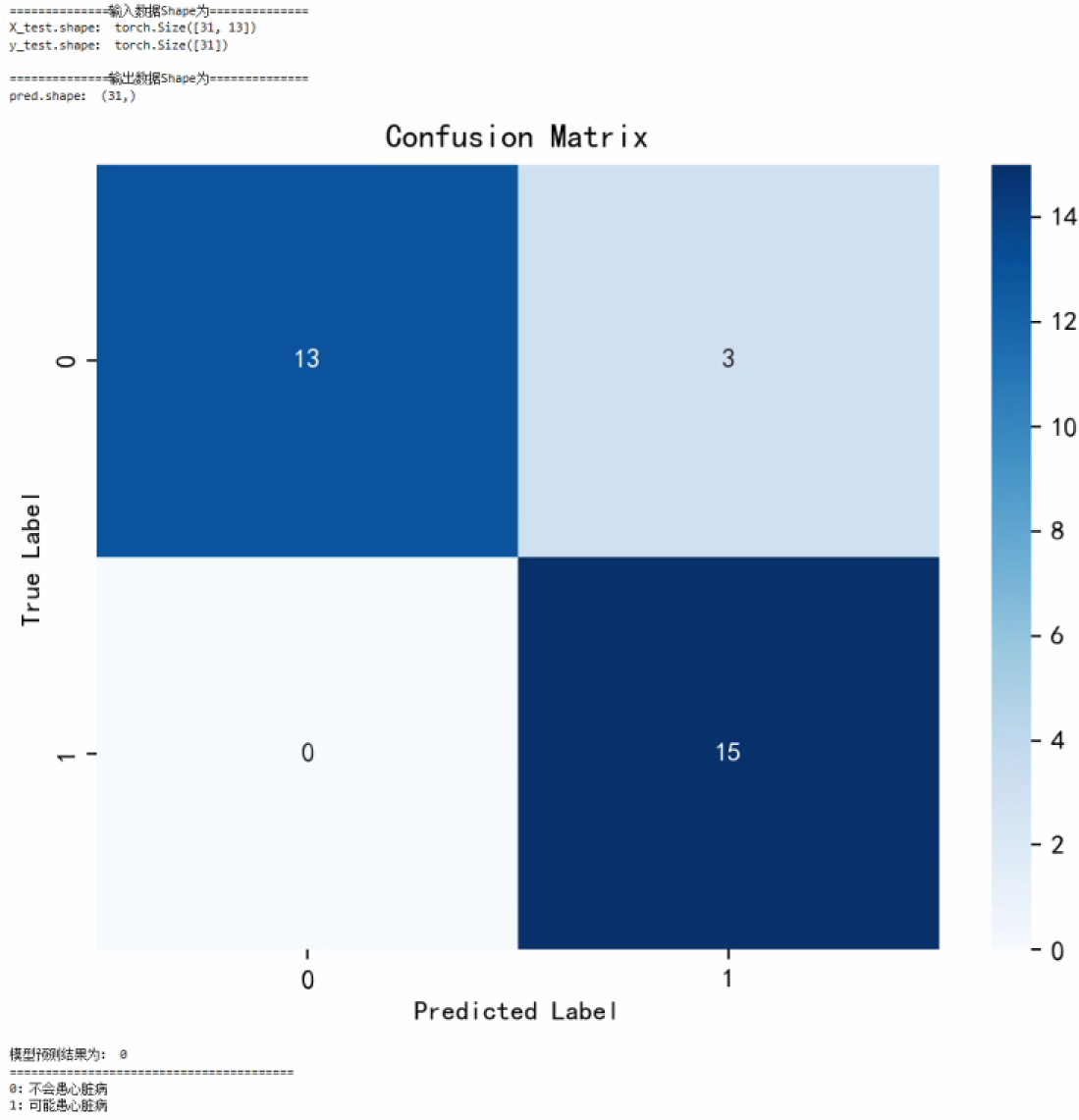
365打卡第R3周: RNN-心脏病预测
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 🏡 我的环境: 语言环境:Python3.10 编译器:Jupyter Lab 深度学习环境:torch2.5.1 torchvision0…...

1.1.1 用于排序规则的IComparable接口使用介绍
在C#中,IComparable 是一个核心接口,用于定义对象的自然排序规则。实现该接口的类可以指定其实例如何与其他实例比较大小,从而支持排序操作(如 Array.Sort()、List.Sort()). 1. 该接口CompareTo返回值含义:…...
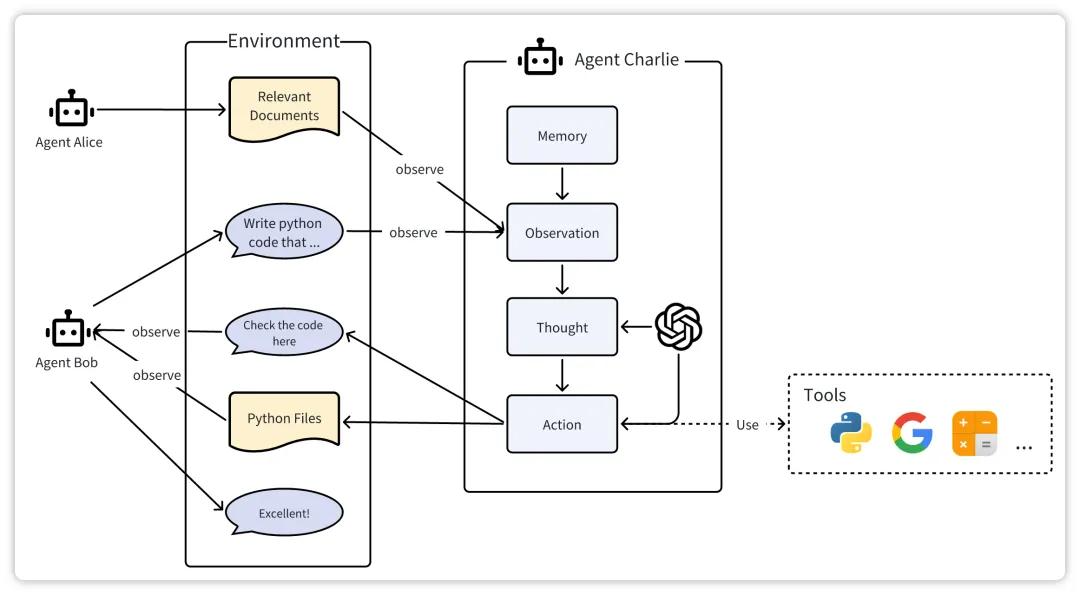
【实战】基于强化学习的 Agent 训练框架全流程拆解
一、引言 在人工智能蓬勃发展的今天,强化学习(Reinforcement Learning, RL)作为让智能体(Agent)在复杂环境中自主学习并做出最优决策的核心技术,正日益受到关注。从游戏领域中击败人类顶尖选手的 AlphaGo&a…...

【音视频】⾳频处理基本概念及⾳频重采样
一、重采样 1.1 什么是重采样 所谓的重采样,就是改变⾳频的采样率、sample format、声道数等参数,使之按照我们期望的参数输出。 1.2 为什么要重采样 为什么要重采样? 当然是原有的⾳频参数不满⾜我们的需求,⽐如在FFmpeg解码⾳频的时候…...

Prompt 结构化提示工程
Prompt 结构化提示工程 目前ai开发工具都大同小异,随着deepseek的流行,ai工具的能力都差不太多,功能基本都覆盖到了。而prompt能力反而是需要更加关注的(说白了就是能不能把需求清晰的输出成文档)。因此大家可能需要加…...

设计心得——数据结构的意义
一、数据结构 在老一些的程序员中,可能都听说过,程序其实就是数据结构算法这种说法。它是由尼克劳斯维特在其著作《算法数据结构程序》中提出的,然后在一段时期内这种说法非常流行。这里不谈论其是否正确,只是通过这种提法&#…...

【Pandas】pandas DataFrame rdiv
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

Pycharm 代理配置
Pycharm 代理配置 文章目录 Pycharm 代理配置1. 设置系统代理1.1 作用范围1.2 使用场景1.3 设置步骤 2. 设置 python 运行/调试代理2.1 作用范围2.2 使用场景2.3 设置步骤 Pycharm 工具作为一款强大的 IDE,其代理配置在实际开发中也是必不可少的,下面介绍…...
)
GPU 加速库(CUDA/cuDNN)
现代数字图像处理与深度学习任务对计算效率提出极高要求,GPU 加速库通过硬件并行计算能力大幅提升数据处理速度。 一、CUDA 并行计算架构深度解析 1. 架构设计与硬件协同 CPU-GPU 异构计算模型CPU 作为主机端,主要负责逻辑控制、任务调度以及数据预处…...

Spring Native:GraalVM原生镜像编译与性能优化
文章目录 引言一、Spring Native与GraalVM基础1.1 GraalVM原理与优势1.2 Spring Native架构设计 二、原生镜像编译实践2.1 构建配置与过程2.2 常见问题与解决方案 三、性能优化技巧3.1 内存占用优化3.2 启动时间优化3.3 实践案例分析 总结 引言 微服务架构的普及推动了轻量级、…...

JAVA JVM面试题
你的项目中遇到什么问题需要jvm调优,怎么调优的,堆的最小值和最大值设置为什么不设置成一样大? 在项目中,JVM调优通常源于以下典型问题及对应的调优思路,同时关于堆内存参数(-Xms/-Xmx)的设置逻…...
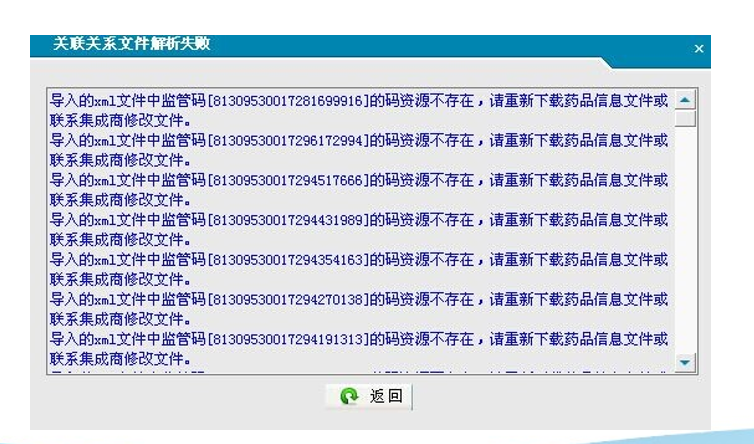
药监平台上传数据报资源码不存在
问题:电子监管码上传药监平台提示“导入的资源码不存在” 现象:从生产系统导出的关联关系数据包上传到药监平台时显示: 原因:上传数据包的通道的资源码与数据包的资源码不匹配。 解决方法:检查药监平台和生产系统的药…...
)
世界比较权威的新车安全评鉴协会(汽车安全性测试,自动驾驶功能测试)
NCAP是英文“New Car Assessment Program”的缩写,即新车评价规程,最能考验汽车安全性的测试,在自动驾驶发展迅速的现阶段,安全问题频发,自动驾驶相关功能显然也需要进行测试评价。 1. 欧洲新车安全评鉴协会ÿ…...
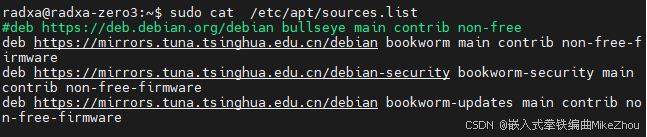
【Linux应用】交叉编译环境配置,以及最简单粗暴的环境移植(直接从目标板上复制)
【Linux应用】交叉编译环境配置,以及最简单粗暴的环境移植(直接从目标板上复制) 文章目录 交叉编译器含有三方库的交叉编译直接从目标板上复制编译环境glibc库不一致报错方法1方法2 附录:ZERO 3烧录ZERO 3串口shell外设挂载连接Wi…...

CentOS 7 磁盘阵列搭建与管理全攻略
CentOS 7 磁盘阵列搭建与管理全攻略 在数据存储需求日益增长的今天,磁盘阵列(RAID)凭借其卓越的性能、数据安全性和可靠性,成为企业级服务器和数据中心的核心存储解决方案。CentOS 7 作为一款稳定且功能强大的 Linux 操作系统&am…...
CSS3布局方式介绍
CSS3布局方式介绍 CSS3布局(Layout)系统是现代网页设计中用于构建页面结构和控制元素排列的一组强大工具。CSS3提供了多种布局方式,每种方式都有其适用场景,其中最常用的是Flexbox和CSS Grid。 先看传统上几种布局方式ÿ…...
FPGA设计 时空变换
1、时空变换基本概念 1.1、时空概念简介 时钟速度决定完成任务需要的时间,规模的大小决定完成任务所需要的空间(资源),因此速度和规模就是FPGA中时间和空间的体现。 如果要提高FPGA的时钟,每个clk内组合逻辑所能做的事…...

AI心理健康服务平台项目面试实战
AI心理健康服务平台项目面试实战 第一轮提问: 面试官: 请简要介绍一下AI心理健康服务平台的核心技术架构。在AI领域,心理健康服务的机遇主要体现在哪些方面?如何利用NLP技术提升用户与AI的心理健康对话体验? 马架构…...
)
Eigen稀疏矩阵类 (SparseMatrix)
1. SparseMatrix 核心属性与初始化 模板参数 cpp SparseMatrix<Scalar, Options, StorageIndex> Scalar:数据类型(如 double, float)。 Options:存储格式(默认 ColMajor,可选 RowMajor࿰…...